
Abstract
Laboratory informatics is defined as the specialized application of information technology to optimize and extend laboratory operations. Rising with the tide of informatics in general, laboratory informatics is one of the fastest growing areas of laboratory-related technology. However, this technological growth has outstripped the expertise of the ones who stand to gain most from it: scientists and other end users in the laboratory. This gap could be bridged by specialists in laboratory informatics who are well grounded in the scientific basis of lab operations, yet also trained in informatics and its particular applications in the lab. However, formal educational programs in laboratory informatics are lacking. To set an educational agenda, laboratory informatics must be delineated as a field, and based on that delineation, a curriculum must be developed that meets the standards of higher education. To address these issues, this paper gives an overview of informatics, describes the context of laboratory informatics in this setting, explains the emergence of laboratory informatics as a distinct field, sets the place for laboratory informatics in higher education by suggesting the nature and scope of the curriculum, and briefly describes the laboratory informatics initiative at Indiana University.
Introduction
The use of the term informatics is rapidly proliferating both in and out of science. 1 This term is used variously to denote information management, information science, information technology, computational modeling, software engineering, artificial intelligence, and even digital art, when these technologies are used for specific purposes in particular fields. The diverse application of this term reflects the breadth and ramification of the subject. However, the term's widespread appropriation by so many different disciplines has clouded its meaning. To correct this, a comprehensive representation of informatics is called for.
Laboratory informatics is defined as the specialized application of information technology to optimize and extend laboratory operations. It encompasses data acquisition, lab automation, instrument interfacing, laboratory networking, data processing, specialized data management systems (such as chromatography data systems), laboratory information management systems, scientific data management (including data mining and data warehousing), and knowledge management (including the use of electronic laboratory notebooks). Laboratory informatics has risen with the tide of informatics in general and is one of the fastest growing areas of laboratory-related technology. This growth is fueled by the commoditization of hardware and software, the integration of laboratory instrumentation and data systems, and the convergence of automation and information technologies. However, this technological growth has outstripped the expertise of the ones who stand to gain most by it: scientists and other end users in the laboratory. This gap could be bridged by specialists in laboratory informatics who are well grounded in the scientific basis of lab operations yet are also trained in informatics and its particular applications in the lab. However, formal educational programs in laboratory informatics are lacking. To set an educational agenda, laboratory informatics must be delineated as a field, and on the basis of that delineation, a curriculum must be developed that meets the standards of higher education, consistent with the typical expectations for related programs in science and engineering.
To address these issues, this paper gives an overview of informatics, describes the context of laboratory informatics in this setting, explains the emergence of laboratory informatics as a distinct field, sets the place for laboratory informatics in higher education by suggesting the nature and scope of the curriculum, and briefly describes the laboratory informatics initiative at Indiana University.
An Overview of Informatics
Informatics is broadly defined as the study of the specialized application of computer science, information technology, and information science to particular disciplines in the arts, sciences, and professions. Moreover, informatics studies the dynamics of human-computer interaction and studies the impact of information technology on individuals, organizations, and societies. By its scope, informatics encompasses computer science, information technology, and information science, yet it is distinct from any of these. Computer science studies the fundamental principles of computing, with focus on the computer itself. Information technology is directed toward the general deployment of computer-based systems. Information science is concerned with the structure, storage, retrieval, and dissemination of information. Informatics, on the other hand, incorporates the characteristics of these fields, yet transcends them in that informatics is more applied than computer science, more basic than information technology, and more technical than information science. Moreover, informatics is also concerned with the human side of these technologies: what they can do for—and to—people.
Categorization of Informatics
To categorize informatics, it must be placed in the larger context of all computer-related activities. We start with a two-dimensional field, the axes of which range from small scale to large scale. The ordinate is the technical dimension, and its range is from a single computer interface (small scale) to large computational systems (large scale). The abscissa is the human dimension, ranging from the individual (small scale) to society (large scale). The technical dimension is associated with information technology; the human dimension, with information science in the broad sense of the term. With the origins of these axes set in the middle, a Cartesian field is created, onto which computer-related activities can be mapped (Fig. 1).
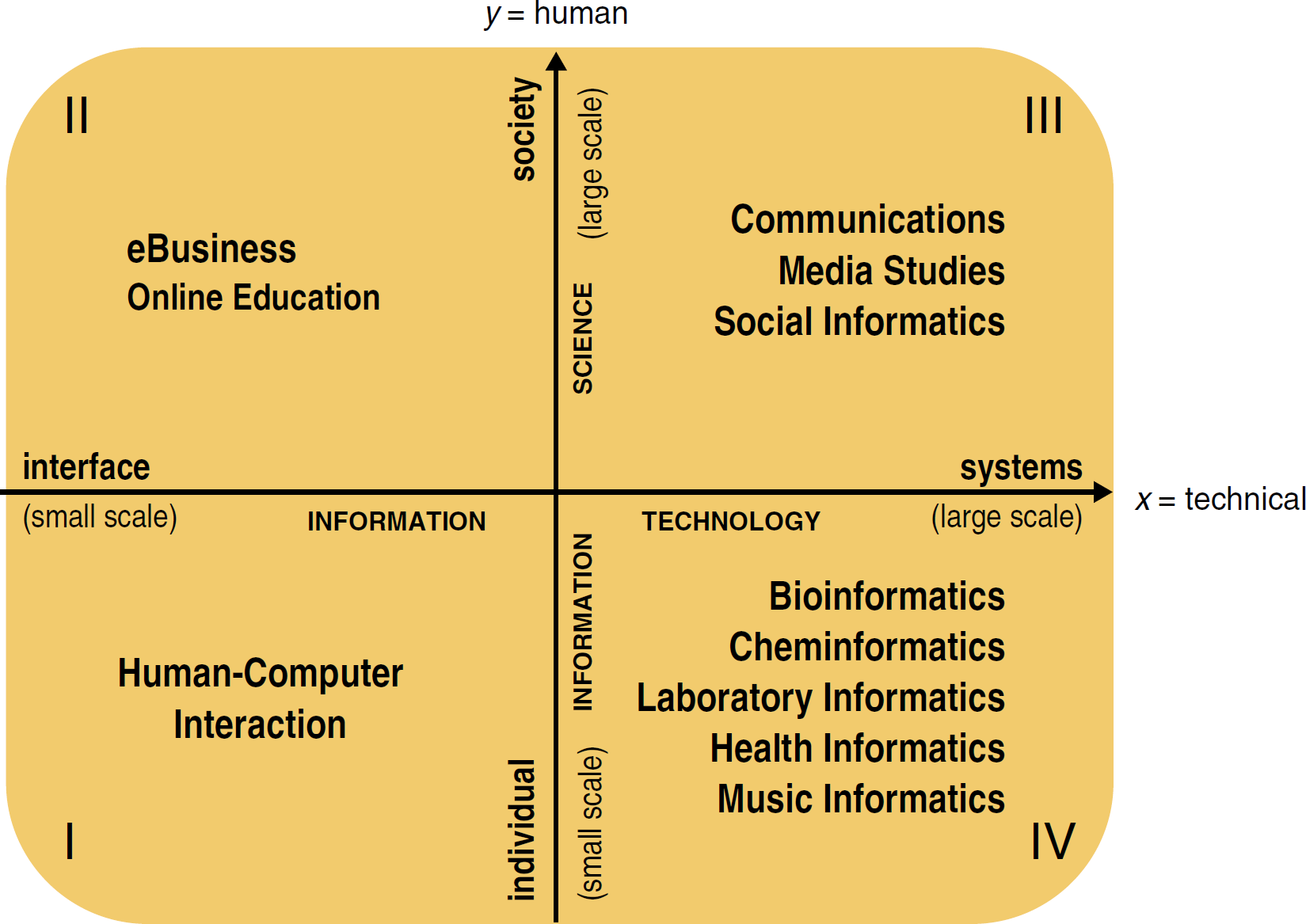
Mapping of computer-related activities.
This field has four quadrants. Quadrant I concerns computers and humans, in both cases on the small scale—the one-on-one experience of an individual working with a desktop computer, for example. This quadrant is the realm of human-computer interaction, the formal study of how people use computers and ways to improve such use. Quadrant II deals with computers on the small scale and humans on the large scale—many people using computers individually, as occurs with e-business (online auctions, banking, and shopping) and, increasingly, with online education and distance learning. The dynamics in Quadrant III concern large-scale computer-based systems and large numbers of people, with emphasis on the effect of pervasive computing and media technology on people. The fields of communication, media studies, and social informatics are most interested in these dynamics. Finally, in Quadrant IV, the interplay involves individuals or small groups dealing with large-scale computing; for example, a molecular biologist working with impossibly large data sets or a chemist trying to locate compound information that is hidden somewhere in hundreds of heterogeneous databases. This is the home of bioinformatics, cheminformatics, and health (or medical) informatics, to name the most well-known fields. However, this quadrant is also home to fields outside of science—music informatics, to give but one example—that confront the same issues.
The fields in Quadrant IV all have binomial names in which prefixes, adjectives, or adjectival nouns signifying the underlying discipline are used to modify the term informatics: bioinformatics, cheminformatics, geoinformatics, health informatics, music informatics, and so on. This reflects the discipline-centered nature of these fields, in which the relevant informatics tools are at the service of the discipline and in the hands of the discipline's practitioners. In the above fields, for example, the practitioners are scientists, health care professionals, and musicians, respectively. These informatics fields are collectively referred to as discipline-centered informatics, domain-centered informatics, domain informatics, or simply, if less accurately, informatics. For simplicity, this article will use the last term. To this category, we can add the main subject of this paper, laboratory informatics.
It is important to note that informatics is not simply additive in nature; that is, it is not just some domain (discipline-specific) knowledge plus some information technology; rather, it is the synthesis of domain knowledge with specialized tools that have been developed or optimized to advance the underlying discipline in some specific way.
Commonalities and Differences within Informatics
Informatics has five major functions, all of them acting upon data: transformation, integration, analysis, synthesis, and representation. In transformation, raw data are rendered into a usable state through filtration, normalization, and so on. Examples include ratio normalization of arrays in bioinformatics, enhancement of diagnostic imaging in health informatics, and digitization of recorded music in music informatics. Integration involves pooling data from disparate sources and in heterogeneous formats into coherent, accessible datasets. In bioinformatics, for example, this could be devising access methodology to multiple databanks with numerous contributors and users. 2 A current push in health informatics is for integration of clinical data from many sources—prior medical records, clinical lab results, and so on—into electronic medical records. In music informatics, an example might be coding musical data into standardized typologies. 3 Analysis can be in the traditional sense of post hoc scrutiny of results that are obtained from hypothesis-driven, deterministic models, but increasingly, analysis can consist of hypothesis-free discovery by new methods of data mining. For example, a major goal in bioinformatics is to extract hidden information from large and dense data sets by using artificial intelligence. 4 A current research focus in health informatics is to use standardized medical coding, culled from thousands of patient records, to discover previously unrecognized associations between symptomatology and disease. 5 In music informatics, computational analysis can be used to trace the evolution of melodic forms over time by using pattern recognition. 3 Synthesis seeks to discover functional and causal relationships and emergent behaviors across a wide range of phenomena, on a scale that can only be achieved by computational means. This is the contribution of bioinformatics to structural biology. 6 In health informatics, there are efforts to develop global electronic medical records. 7 In music informatics, computational tools might be used to identify and classify transcultural musical forms. Finally, representation presents a coherent model that summarizes the relationships of the underlying data. Prediction of protein folding in bioinformatics, mapping of clinical information extracted by natural language programming in health informatics, and digital generation of music in music informatics 8 are all examples of representation.
A comparative analysis of informatics brings out the commonalities of the subsumed fields. One shared characteristic is the highly specialized use of information technology for discipline-specific purposes, in which the discipline comes first and the technology second. Another characteristic is that all fields must confront the management of massive amounts of heterogeneous data, which calls for highend solutions in networking, data storage, and so on. Third, these fields all contribute to research in their underlying disciplines by providing analysis of data in completely new ways, often turning from a priori prediction to a posteriori discovery. Last, the fields within informatics put emphasis on the novel use of data visualization, both for primary analysis and secondary dissemination. (In the case of music informatics, of course, this so-called visualization can be temporal as well as spatial.)
However, in addition to commonalities between these fields, there are also differences. This might come as a surprise, considering that all of these fields draw upon fundamentally the same technology. In fact, the differences between these fields are actually more significant than their similarities. The reasons for this are professional, technical, and even cultural, based on such factors as the types of data used in the field, the particular problems that challenge each field, and what pursuits are most valued by their practitioners. Although it is obvious that this is true when comparing bioinformatics with, say, music informatics, this is even true for those fields that might appear more closely aligned. The intentions and goals of bioinformatics, for example, differ entirely from those of health informatics, as do the kinds of tools used and their methods of application. (Here, health informatics is used to connote clinical information as opposed to the information of basic biomedical research. Occasionally, medical informatics is used to connote the latter type of information, or even to conflate both types. As with any emerging field, the nomenclature is not yet fully standardized.)
Some specific examples include the following: (1) bioinformatics uses highly specialized software and information systems in the study of genomics and proteomics, but these specific tools are of no use in geoinformatics; (2) in health informatics, mobile networking and bedside access to information (say, electronic medical records accessible by tablet PCs) are of great interest, but these are of little or no interest in bioinformatics; and (3) data pipelining and high-throughput screening are technologies that are important in cheminformatics but are unimportant in music informatics. In general, although the fields within informatics share the same basic enabling technology, they are surprisingly distinct and different from each other. The significant difference between these fields has practical implications for informatics education, which are discussed further in this paper.
The Origin of Informatics
There is an increasing disparity between data load—the raw data generated from new technologies—and information capacity—the ability to manage and make sense of all the new data (Fig. 2). This disparity is termed the information gap. In genomic research, for example, a single study can produce >106 data points, far beyond the capacity of any human to analyze with traditional techniques. Moreover, this is more than a mere problem of scale. Simply providing more equipment for data processing and storage is not sufficient. New tools are needed. In addition, bridging the information gap requires a thorough understanding of the information itself. This can only be accomplished by having a solid grounding in the underlying discipline. This is where informatics comes in. A common premise of informatics is that the best informaticians are those who have formal training in the underlying field; for example, chemistry for cheminformatics, health sciences for health informatics, and music for music informatics.
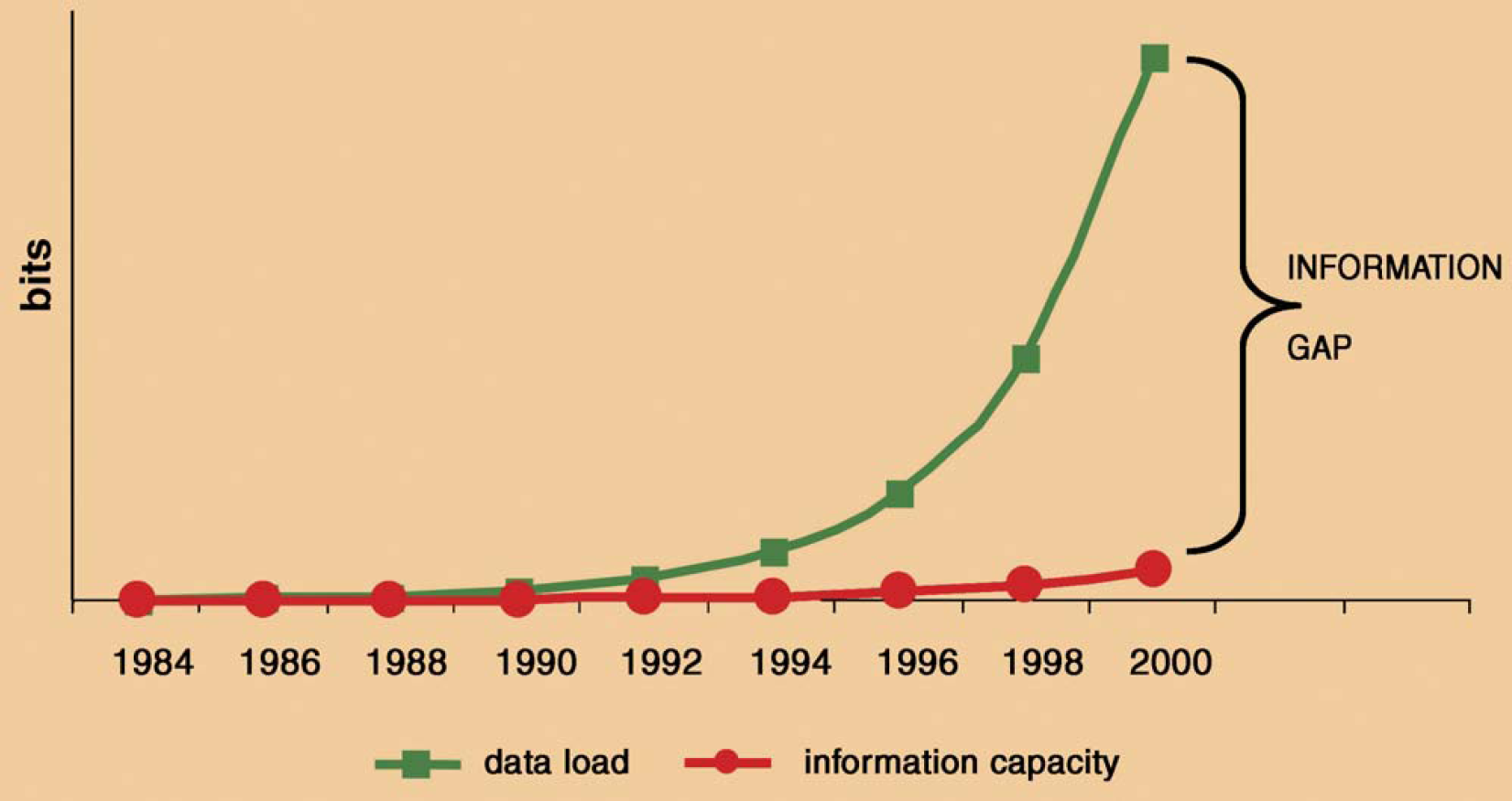
The growing information gap.
Structural Hierarchy of Informatics
The central purpose of informatics is the transformation of data into information and of information into knowledge. A datum, Latin for “something given,” is an irreducible unit of meaning, usually an alphanumeric value of something measured or observed. Here, irreducible is meant in the practical sense of simplest form. Information consists of constellations of data embedded in a matrix of rules and context. Take, for example, two items of data, the words man and bag. These data can be strung together and modified by the use of syntactical rules—the preposition with and the definite article the—to form “the man with the bag.” This phrase is now a data constellation, a group of related data. Place this constellation in context—say, “Christmas”—and the transition from data to information is obvious. (Another example of the difference between data and information is encryption, wherein data are freely accessible but cannot be turned into useful information without a key that provides the necessary rules and context.) Knowledge is the conscious awareness of associated information. The operators that transform information into knowledge are analysis, integration, and dissemination. In analysis, data are in effect assigned further meaning, the obvious example being statistical analysis, which declares true differences and trends within an acceptable probability. In integration, knowledge is created when disparate information is brought together by logical and rational association. Although this process occurs in individuals, knowledge creation also requires dissemination—the sharing of information—so that others may make new associations and thereby contribute to the knowledge pool.
In developing his theory of information, Shannon (summarized by Boisot and Canals 9 ) assigned three levels of concern, or interest: the concern at level 1 is with data transmission and fidelity; at level 2, with the meaning of the data; and at level 3, with the effect of the data. He characterized level 1 as a technical problem, level 2 as a semantic problem, and level 3 as an “effectiveness” problem, often social in nature. Shannon's informational levels correspond to the structural hierarchy of informatics. The technical problem of level 1 deals with pure data, the semantic problem of level 2 deals with information, and the effectiveness problem of level 3 deals with knowledge.
The Emerging Field of Laboratory Informatics
Within the realm of informatics, laboratory informatics is rapidly emerging as a distinct specialty. The following sections delineate this field's content on the basis of a model of laboratory data flow, organize this content according to the structural hierarchy of informatics, and suggest a curriculum for laboratory informatics based on this content.
The Scope of Laboratory Informatics
Laboratory informatics can be approached from the standpoint of data flow in the laboratory. In the diagram shown in Fig. 3, the overall data flow is from left to right in three major stages that loosely correspond to the structural hierarchy of informatics: data, information, and knowledge. In the first stage (data), laboratory instruments and workstations generate primary, raw data, which is a process that is often augmented by automated systems for sample preparation, robotic sample handling, and so on. Instrument interfacing via parallel and serial ports allows data to move to the second stage (information), involving laboratory information management systems and specialized data systems that are optimized for particular instruments (e.g., chromatography data systems). During this process, raw data are modified by signal filtration, mathematical transformation, and so on, according to set rules, including standard operating protocols. By using a laboratory information management system in conjunction with a database, data are assigned to tables with meaningful attributes, thereby adding context. Thus, data are transformed into information. In the third stage (knowledge), this information is analyzed by using software to perform tasks such as peak detection and profile recognition, comparative statistics, “discovery” visualization, and data mining. On the basis of the results of these analyses, conclusions are drawn and new associations made that, although often still written in paper notebooks, are increasingly being entered in electronic laboratory notebooks. By design, electronic laboratory notebooks can be fully collaborative. Many personnel can interact with the notebook at different levels, facilitating sharing and dissemination. With these technologies and methods, information is converted into knowledge.
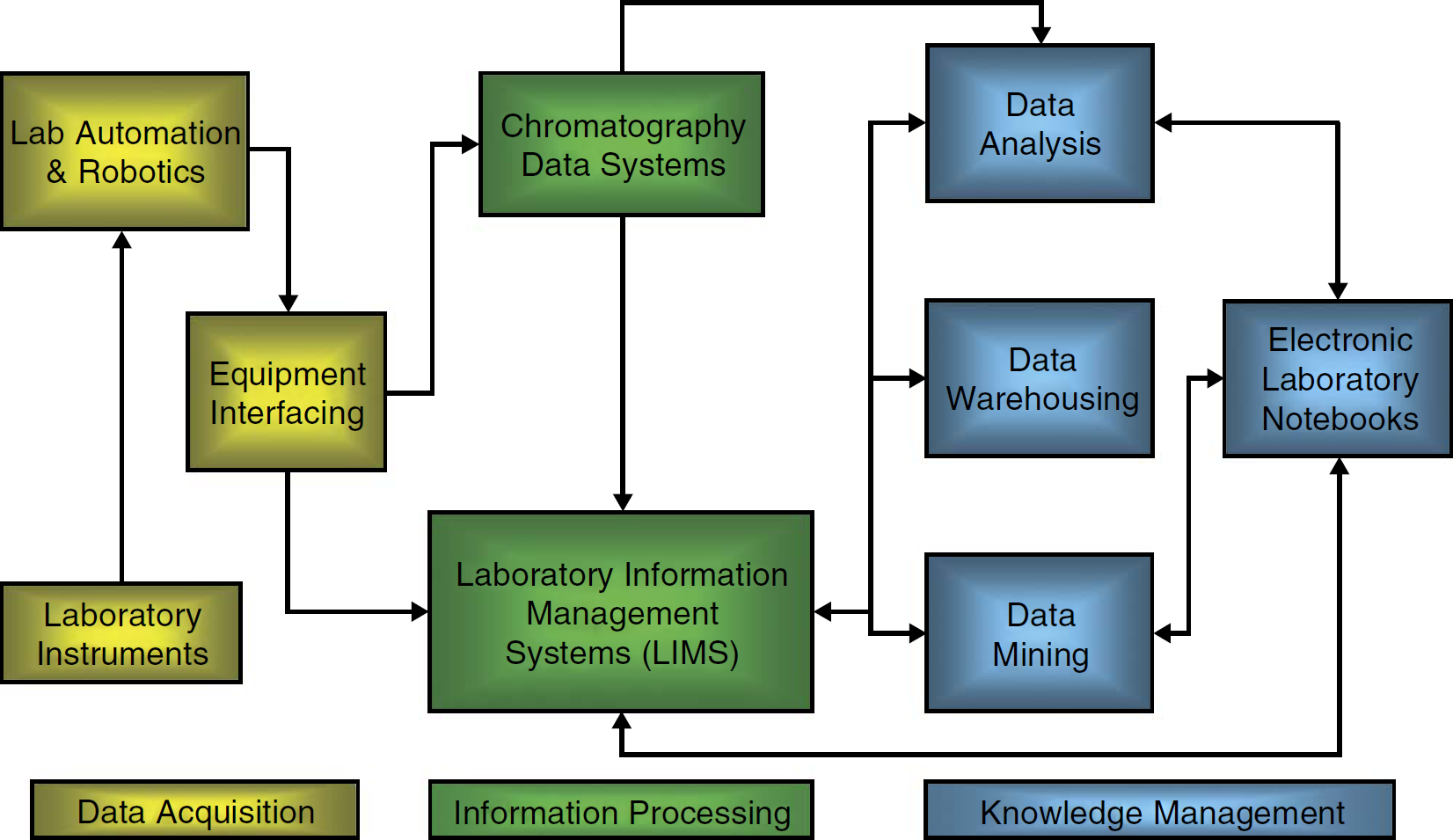
Data flow in the laboratory.
On the basis of this data flow model, subjects falling under the purview of laboratory informatics can be grouped as in Table 1.
Subject content of laboratory informatics

The Impetus for Laboratory Informatics
The final output of any laboratory, operating in any industry, is information. Similar to the other fields of informatics, laboratory informatics arose from a widening information gap. This gap was caused by the astonishing developments in information technology, the convergence of laboratory instrumentation, allowing potentially seamless data flow, and the explosion of data created by unprecedented advances in laboratory automation. Laboratory instruments have evolved from manually operated, stand-alone devices into digitally controlled, network-aware systems that are at once autonomous and cooperative. Laboratory automation has advanced to the point that even common, bench-top instruments have automated functions in everything from sample handling to data analysis. Consequently, modern scientific output has extended the informational demands of labs far beyond simple data processing. Software applications for various laboratory operations, once hugely expensive and difficult to use, are evolving into affordable, off-the-shelf packages. This puts sophisticated information systems within reach of even the smallest labs. Furthermore, in the pharmaceutical and other industries, federal agency regulations to maintain data integrity, security, and validity are driving laboratories to adopt solutions provided by new developments in laboratory informatics. Finally, the relentless push to improve productivity through increased automation will justify further expenditures in laboratory informatics.
An Educational Model for Laboratory Informatics
Laboratory informatics is rapidly developing as a field, heretofore without benefit of formal educational support. Of the people now working in a capacity related to laboratory informatics, most have had a long and winding road in getting to their current position. As pioneers in an emerging field, they have had to obtain knowledge and skills in this area on a per-need basis. They might have a formal education in a laboratory-based science, with information technology grafted on, or they might be information technologists who have specialized in supporting laboratory operations, with a passing understanding of the underlying science. Neither situation is ideal. Yet the long-term demand for these specialists will continue to increase. The time is right to bring laboratory informatics into higher education and establish a formal curriculum.
In informatics, the best educational model is one in which individuals already possessing a formal education in a discipline are trained in informatics as it applies to that discipline. This works best at the graduate level. Students can enter a graduate program in informatics with undergraduate degrees in a related discipline. Because they enter the program with a solid knowledge base in the discipline, their studies can concentrate on subjects related to informatics in general and the relevant discipline-specific informatics in particular. For example, in the case of laboratory informatics, an individual with an undergraduate degree in a laboratory-based science (e.g., chemistry, microbiology, or clinical laboratory science) could seek a graduate degree in laboratory informatics. The alternate pathway would be for someone trained in information technology to obtain further education in a laboratory-based science as well as specific training in laboratory informatics. However, this alternate pathway is not equivalent, because the individual must obtain far more education in a laboratory-based science to be adequately knowledgeable in the discipline. Usually this is a case of impossible prerequisites. To take a course in biochemistry, for example, one must have taken organic chemistry, which in turn requires a course or two in general chemistry, and so on.
The level of graduate education for laboratory informatics, that is, the type of degree obtained, should be based on the intended result. For laboratory informatics, emphasis would be on professional practice, which is consistent with one of the major objectives of a Master of Science degree. Typically, this degree requires 30 to 36 credit hours, consisting of both coursework and advanced, individual work for so-called capstone credit, most often a research project and subsequent thesis.
The curriculum in laboratory informatics should be set by the general requirements for the degree and by the field's subject content. The general requirements include those subjects that anyone with an advanced degree in informatics, regardless of their particular field, would be expected to know. These subjects include a general overview of informatics, spanning all of its subsumed fields, information theory, information management (including database design), data security, informatics project management, and an introduction to informatics research. In addition, students should be aware of the social and economic impact of the information revolution.
For the core curriculum in laboratory informatics, much of its content is derived from mapping the general data flow in the laboratory (Fig. 3) and is organized by the structural hierarchy of informatics (Table 1). In addition, there are subjects that surround the data flow that deal with the conditions under which data flow occurs. Such subjects include regulatory compliance, systems validation, and quality assurance and control.
The technical knowledge needed by laboratory informaticians requires a solid understanding of current laboratory software applications, corporate databases and information technology systems, operation support software, manufacturing support software, and the general classes of equipment that are used in analytical, research, and production laboratories. The technical skills needed by laboratory informaticians should include the ability to configure and maintain hardware operations relating to all aspects of data management. Programming skills should include the ability to design, program, test, debug, and modify programs in languages used in the laboratory. Project management skills, including establishing requirements and specifications for software and hardware implementation, are also necessary.
Last, graduate education at its best is not simply more coursework continued after undergraduate study. The single greatest factor that distinguishes graduate education from undergraduate education is its requirement for advanced individual scholarship, research, or professional practice. For laboratory informatics to be accepted in academe, it must be held to the same academic standards as its counterparts in science, engineering, and computer science. Moreover, one of the hallmarks of a true profession is that its own practitioners contribute to the professional body of knowledge through scholarship and research. Therefore, it is essential that graduate study in laboratory informatics include this component. This activity should culminate in a final document, the thesis.
Here, then, is a summary of possible subjects to be included in a curriculum for a graduate program in laboratory informatics. (Each subject listed does not necessarily represent a separate course.)
Prerequisite:
Bachelor's degree in chemistry or other laboratory-based science
General requirements:
Overview of informatics
Information theory
Information representation
Information organization
Information management
Social and economic impact of information
Database structures and models
Interfaces and networks
Data security
Informatics project management
Major requirements:
Programming
Data acquisition
Laboratory automation
Instrument interfacing
Laboratory networking
Data transfer protocols
Data processing
Instrument-specific data systems
Data integration systems
Database management systems
Laboratory information management systems
Scientific data management
Statistics and data analysis
Data mining
Scientific visualization
Electronic laboratory notebooks
Scientific dissemination
Data archiving and warehousing
Knowledge management
Thesis requirements:
Introduction to informatics research
Individual scholarship in laboratory informatics
Individual research in laboratory informatics
Individual professional practice in laboratory informatics
Thesis preparation
Thesis defense (or presentation)
In 2002, the Indiana University School of Informatics founded on its Indianapolis campus the Laboratory Informatics Graduate Program, the first of its kind in the country. Curriculum development for this program was supported by a grant from the Alfred P. Sloan Foundation under its Professional Science Masters Program. A current list of courses offered in the curriculum is given below. The first cohort of graduate students was admitted in fall of 2003. Efforts are currently underway to expand the curriculum to include clinical laboratory informatics. The Laboratory Informatics Graduate Program is a positive first step in establishing laboratory informatics in higher education. Its structure is as follows.
Common Informatics Core (6 credit hours [cr]):
INFO I501 Introduction to Informatics (3 cr)
INFO I502 Information Management (3 cr)
Laboratory Informatics Core (12 cr):
CHEM 699 Chemical Information Technology (3 cr)
INFO I510 Data Acquisition and Laboratory Automation (3 cr)
INFO I511 Laboratory Information Management Systems (3 cr)
INFO I512 Scientific Data Management and Analysis (3 cr)
Electives (12 cr total; some examples below):
CHEM 621 Advanced Analytical Chemistry (3 cr)
CHEM 629 Chromatography (3 cr)
CSCI 503 Operating Systems (3 cr)
CSCI 504 Concepts in Computer Organization (3 cr)
CSCI 536 Computer Networks (3 cr)
CSCI 541 Database Systems (3 cr)
CSCI 590 Topics in Computer Science (1–3 cr)
INFO I503 Social Impact of Information Technology (3 cr)
INFO I505 Informatics Project Management (3 cr)
INFO I540 Data Mining for Security (3 cr)
INFO I550 Legal & Business Issues in Informatics (3 cr)
INFO I553 Independent Study in Chemical Informatics (1–3 cr)
INFO I575 Informatics Research Design (3 cr)
INFO I590 Topics in Informatics (1–3 cr)
STAT 511 Statistical Methods I (3 cr)
STAT 513 Statistical Quality Control (3 cr)
Capstone (6 cr):
INFO I693 Thesis/Project (1–6 cr; can be repeated for a total of 6 credits)
Conclusion
It is widely recognized that we have entered a new historical epoch, the Information Age, which is as significant and climactic as the Industrial Revolution that preceded it. Economists speak of the new information economy, in which knowledge workers have become the dominant labor force, cosmologists frame their theories of the universe in terms of its information content, and biologists categorize organisms according to their genetic information. Once considered the ancillary descriptor of phenomena, information itself has become the central object of study. Higher education is embracing this revolution by forming new schools and departments, or expanding existing ones, that offer programs in computer science, information technology, information science, and informatics. Laboratory informatics will certainly be part of this academic transformation, to the benefit of laboratories everywhere.