
Abstract


Matthew P. Greving is Chief Scientific Officer at Nextval Inc., a company founded in early 2010 that has developed a discovery platform called MassInsightTM. He received his PhD in Biochemistry from Arizona State University, and prior to that he spent nearly 7 years working as a software engineer. This experience in solving complex computational problems fueled his interest in developing technologies and algorithms related to acquisition and analysis of high-dimensional biochemical data. To address the existing problems associated with label-based microarray readouts, he began work on a technique for label-free mass spectrometry (MS) microarray readout compatible with both matrix-assisted laser/desorption ionization (MALDI) and matrix-free nanostructure initiator mass spectrometry (NIMS). This is the core of Nextval's MassInsight technology, which utilizes picoliter noncontact deposition of high-density arrays on mass-readout substrates along with computational algorithms for high-dimensional data processing and reduction.
Dr. Greving, how would you summarize the scope of the major mass spectroscopy methods in use today in proteomics and drug discovery? What are the key advantages and limitations, and the main applications for these different MS systems?
(See Table 1)
Current Mass Spectrometry Platforms in Use for Proteomics and Drug Discovery
LC, liquid chromatography; MS, mass spectrometry; TOF, time of flight; Q, quadrupole; GC, gas chromatography; MALDI, matrix-assisted laser desorption/ionization; SIMS, secondary ion MS; NIMS, nanostructure-initiator MS; DESI, desorption electrospray ionization.
What factors contribute to the selection of the appropriate MS technology for a particular application?
One of the primary considerations is the application. Are you looking at metabolites, peptides, or whole proteins; bulk metabolites or proteins? How quantitative does the method need to be, and what throughput do you need? In all honesty, it also comes down to budget. These systems can range from the low hundreds of thousands of dollars to quickly approaching a million dollars. You need to balance what type of analysis you need to do and what you can afford.
Metabolomics has driven development in mass resolution because the large diversity of metabolites requires high resolution for identification. A lot of effort has also gone into developing MS/MS, which involves selecting a parent ion or set of parent ions, fragmenting those, and looking at the fragments. That is an essential capability for metabolomics because of the difficulty of identifying a metabolite.
In what direction is the technology evolving and what is driving this evolution?
While proteomics-related technology development is still a major effort, the fastest growing area of mass spectrometry technology development in recent time is related to metabolomics. The rapid growth of metabolomics has specifically driven development towards higher mass resolution, higher mass accuracy, and better MS/MS performance. The importance of these features is due to the chemical complexity of metabolites (when compared to proteins/peptides and DNA/RNA) and the difficulty in definitively identifying specific metabolites that are dysregulated in disease or upon therapeutic treatment. Along with the development of features that enhance metabolite identification have come significant improvements in the metabolite databases that facilitate identification. Some examples of this include The Scripps Research Institute Center for Metabolomics METLIN database and the Human Metabolome Database, which have progressed dramatically, even within just the last year.
In addition, due to the rise of “individualized” sample analysis versus pooled sample analysis, and the sample workload associated with the analysis of individuals, throughput enhancement is a major development effort in mass spectrometry. Significant throughput advances have been achieved in LC/MS-based analysis through the introduction of ultra-high performance liquid chromatography coupled to multiplexed sample injection into the mass spectrometer, with the potential to bring per sample acquisition times into time frames of a few minutes or less. However, this push for increased throughput has increased the spotlight on desorption/ionization approaches. In some laser desorption/ionization systems, lasers with firing frequencies well above 1 kHz have been demonstrated to be effective in getting acquisition times to well below 1 second per sample.
Finally, technology development is beginning to focus on coupling different “omics” methodologies—more of a “systems” approach to sample analysis. This is an area of development I am particularly excited about, and I think array-based technologies could play a significant role in a multi-omics systems approach to high-throughput data acquisition. I look forward to the discoveries I believe will arise out of this systems-based analysis.
How is MS being used in proteomics research in general and, specifically, to define and detect biomarkers? What is the focus of Nextval's work, and how does the company's technology and drug discovery services fit into this broad picture of proteomics/biomarker research?
In general, MS is being used either to identify biochemical pathway dysregulations related to disease or to monitor dysregulations that occur during and after treatment. This can be done in a targeted (where you know what you are looking for) or untargeted (where you monitor everything you can detect, then attempt to identify dysregulations) manner. Also, MS is being used to analyze a broad range of analytes from intact proteins all the way down to small molecules, and even metals in some cases. Nextval's focus is on providing a MS technology that has sufficient throughput to address the ever-increasing challenge of narrowing down the overwhelming number of samples (thousands to several hundreds of thousands or more) that are common in drug screening, analysis of individuals (versus pooled analysis), or systems biology-based approaches. Our aim is to reduce the number of samples to a more manageable level that can then be fed into existing systems for comprehensive characterization. Another goal for Nextval's technology is to achieve dramatic reductions in the sample volume, solvent consumption, and waste generation that is typically associated with the analysis of a large number of samples. This would not only reduce cost, but also make this research more environmentally friendly. Finally, in addition to increased throughput and reduced sample/waste costs, we feel that Nextval's MassInsight technology fits very nicely into a systems approach to analysis that combines multiple omics strategies (Fig. 1).
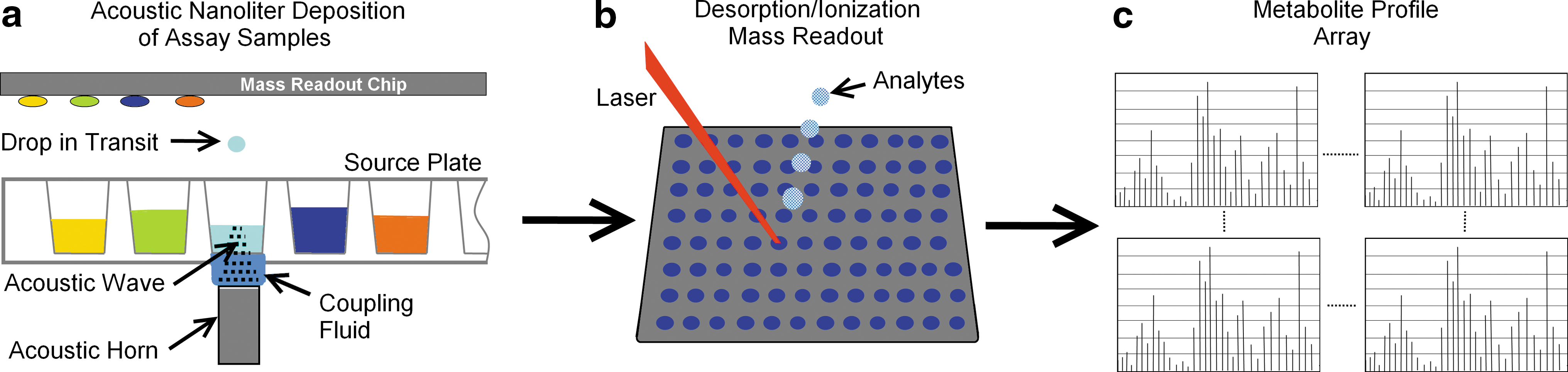
Nextval's MassInsight™ Platform.
What led you to pursue your chosen career path, and what educational and early work experiences contributed to your interest and involvement in MS technology and the applications you are now refining at Nextval?
At the most fundamental level, my interest lies in deconvolution and/or reduction of information complexity. Early on, this interest led me into software engineering, parallel computing, and algorithm development. I believe that algorithm development is one of the major unmet needs in the field of high-throughput, high-information content MS analysis, and I currently utilize my experience as a software engineer to address this unmet need. During my graduate work in biochemistry I gained significant experience with microarrays, including synthesis chemistry, assays, and data/statistical analysis. I fully recognized the power of arrays to deconvolve highly complex samples, but also saw shortcomings in label-based detection (typically fluorescence). During that work, I put significant thought into ways we could analyze arrays, still using laser scanning of the surface but without requiring a label. This led me to begin to explore the use of laser desorption/ionization, which essentially replaced the function of the laser in my initial experiments from exciting a fluorescent label to generating “label-free” ions. Nextval's technology is, in part, the result of this progression of ideas, along with ideas from my partners, who have brought some of the most powerful array deposition technology I have ever worked with into the picture.
How did you go about starting Nextval? What is the company's core Intellectual Property? How would you describe MassInsight?
Nextval was started by my partner, Joseph Cohen, to provide assay-ready plates to customers, an effort that exists within the company today and continues to gain momentum. The assay-ready plate product utilizes acoustic transfer. Last year, my partners Joe Cohen and Michael Nyman started exploring the idea of utilizing acoustic transfer for high-density array deposition and coupling this to label-free mass spectrometry readout. This is when I got involved and started looking at specific applications to which we could apply this idea.
At a high level, MassInsight is a platform that combines picoliter deposition of samples as high-density arrays, directly from assay source plates onto substrate(s) compatible with high-throughput desorption/ionization mass spectrometry readout. I would describe Nextval's MassInsight platform as a significant and potentially disruptive technology development. I would not describe MassInsight as a competitor to LC/MS or GC/MS, but instead as a complementary technology that addresses the “front-end sample number reduction” problem that is difficult to approach with LC/MS. How do you analyze 200,000 samples with mass spectrometry and reduce that to a manageable number? That is the question/challenge that MassInsight addresses. MassInsight fits very well into existing workflows and can dramatically increase throughput and reduce cost of the sample library analysis workflow. Using MassInsight, an intractable number of samples at the front end can be reduced to a set of leads in high-throughput, and those can then go through existing analysis methodologies for comprehensive characterization.
What were some of the technical issues you faced in the analysis of high-density microarray data?
The biggest technical challenges we face are mostly related to dealing with the diverse range of sample characteristics that exist in customer and collaborator samples. In one day we could be dealing with lysed cells in aqueous media in the morning, and then working with quality control analysis of a small molecule library in organic solvent in the afternoon. In addition, within each experiment, sample-to-sample (well-to-well) characteristics can also be quite diverse and affect the array spot characteristics. Without attention, this sample diversity could result in inter- and intra-array variability. We have worked out ways to deal with this and are continuing to see significant improvements. Another challenge related to sample variability is highly accurate quantitation; quantitation enhancement is a major effort within Nextval. Finally, dealing with the high-dimensionality, information-rich data that are obtained from complex samples represents another major technical challenge, and Nextval is developing algorithms related to deconvolution of these complex data sets.
Sample preparation is often overlooked as an important prerequisite when using advanced technologies. In what ways does sample preparation affect the use of microarrays and MS?
Sample preparation is one of the most important, if not the most important aspect of obtaining relevant data from a microarray or MS experiment, and this importance holds true with Nextval's MassInsight platform. At the very best, your data will be as good as your sample preparation, and my thought about sample preparation is that “less is more.” In other words, I feel that by minimizing the time and number of sample preparation steps involved, data quality and relevance will be improved. Sample preparation can dramatically affect variability, sensitivity, sample validity (i.e., cross contamination), and quantitation—this is true for microarrays, mass spectrometry, and a platform such as MassInsight, which combines microarrays and mass spectrometry. One of the major goals within Nextval is to reduce sample preparation, and to achieve this goal we have turned to noncontact acoustic deposition.
How is the emerging trend toward nanoflow LC-MS applications going to impact the field?
I think the push toward microfluidics is an important trend not only in mass spectrometry, but in other areas as well, such as synthesis. The solvent costs have gone through the roof, and environmental concerns are rapidly becoming an even a bigger issue, with waste disposal increasing in cost and regulatory measures becoming more stringent. So you're getting hit from both sides, the increasing cost of fresh solvent and the increasing cost of disposing of used solvent. Some of the new LC-MS technologies are really pushing toward less solvent use. The acoustic deposition technique we have integrated into our technology is the extreme case of minimal solvent use. We are dealing with very low source sample volumes. We recently did an experiment in 3456-well plates with 1 μl of working volume in the well, and we're printing on the order of hundreds of picoliters, maybe one nanoliter at the most, from that sample. We can get hundreds of assays from 1 μl of a source well. We are really pushing the limit of how-low-can-you-go in solvent use. We are now down to the low microliter of total solvent use per sample for these types of analyses with our platform.
What are MALDI-MS and NIMS and how are they different? What are the sensitivity and limitations of NIMS for the measurement of cellular metabolites? What are the gold standards for such measurements?
MALDI-MS utilizes a “matrix” in which the analytes are co-crystallized with an excess of a compound that absorbs laser energy and promotes ionization. NIMS is matrix-free and therefore does not utilize photoactive additives or analyte co-crystallization. With NIMS, laser energy is absorbed by the porous silicon surface, and a fluorous “initiator” that fills the pores promotes ionization. Because of the lack of a matrix, which causes significant background signal below 1000 m/z with MALDI, NIMS is particularly advantageous and sensitive for metabolite detection. For select metabolites or drugs, NIMS has extreme sensitivity, even into the yoctomole. This is the extreme case, but in general NIMS is highly sensitive with detection into the attomole range for some cellular metabolites.
What is meant by unbiased (untargeted) metabolomics? How many metabolites are present in a typical biological tissue? How close are we to classifying the majority of them?
Untargeted metabolomics essentially means that you perform the analysis without detection bias for a particular set of metabolites. Instead, you analyze as many metabolite features as you can detect, and this could easily be in the thousands of features for complex samples. Stating the number of metabolites present in a biological sample is tough because it is difficult to define the chemical limits of the term ‘metabolite.’ For example, is a peptide a metabolite? Should we limit the definition of a metabolite to a mass range? Also, I think these omics-based definitions blur even further in untargeted analysis because you are essentially looking at everything you can detect, which could even include small proteins. This starts to get into the “systems” approach in that you are not specifically looking at the metabolome or proteome, but instead are looking at everything you can detect in the “system.” Current estimates, however, are that the number of metabolites in biological samples is well into the thousands. There is a significant effort underway to classify the metabolome, but the difficulty arises from identifying unknown metabolites.
What are some of the challenges still to overcome in the use of MS-based technology for routine analysis in proteomics and metabolomics?
I think the key challenges facing MS-based technology are related to the throughput required for large-scale science (thousands of samples or more), the need to increase the amount of information extracted from complex biological samples, the challenge in detecting the low-level analytes in these complex mixtures that could be highly relevant to disease or treatment, and finally the computational algorithms required to deal with such information-rich data from large sample libraries.
What types of information can you obtain from a cellular assay or tissue sample with respect to the metabolites present, and how can this be used in drug discovery?
We can obtain information related to the metabolic pathways that are affected by disease or treatment. In addition, and just as important, we can obtain information about the metabolic pathways that are not affected by disease or treatment. From this one can gain insight into drug mode of action and biochemical pathways relevant to disease. Another potentially interesting area for such assays is getting to the question of “What does a healthy metabolic pattern look like for this specific individual?” and gaining insight into “What is ‘healthy’ variability for this individual's metabolic pattern?” Answering these questions will be important for personalized therapies and diagnostics.
What does the future hold for Nextval?
Nextval's MassInsight platform is still in the early phase of development, but the commercial response has been very positive. There are numerous application areas that this technology can be applied to and, to avoid the danger of becoming too diverse and spread too thin early on, Nextval is placing significant emphasis on applying the technology toward enzyme activity screening (either cell-based or in vitro enzyme assays) and quality control. The enzyme activity application of MassInsight is relevant to the drug discovery and industrial enzyme discovery markets, and we are working in both segments. The quality control application can be targeted to numerous market segments. One that we are focusing on involves monitoring compound library quality and stability over time to provide more confidence in the results from a screen and to provide data that help companies more efficiently manage their compound libraries. Beyond this initial focus, we are gradually working our way toward extracting higher information content and the multi-omics approach by coupling our MassInsight platform to other omics platforms, as well as developing the necessary analysis algorithms required for such information-rich data.