
Abstract
Despite its sequence variability and structural flexibility, the V3 loop of the HIV-1 envelope glycoprotein gp120 is capable of recognizing cell-bound coreceptors CCR5 and CXCR4 and infecting cells. Viral selection of CCR5 is associated with the early stages of infection, and transition to selection of CXCR4 indicates disease progression. We have developed a predictive statistical model for coreceptor selectivity that uses the discrete property of net charge and the binary coreceptor preference markers of the N6X7[T/S]8X9 glycosylation motif and 11/24/25 positive amino acid rule. The model is based on analysis of 2,054 V3 loop sequences from patient data and allows us to infer the most likely state of the disease from physicochemical characteristics of the sequences. The performance of the model is comparable to established sequence-based predictive methods, and may be used in combination with other methods as a supportive diagnostic for coreceptor selection. This model may be used for personalized medical decisions in administering coreceptor-specific therapies.
Introduction
T
The absence of the N6X7[T/S]8X9 glycosylation sequence motif has been proposed to favor binding to CXCR4, 22,23 and the presence of one or more positive amino acids at sequence positions 11, 24, or 25 has been proposed to also favor binding to CXCR4 (the 11/24/25 positive amino acid rule). 24 Glycosylation is also related to charge because of the presence of sialic acids, which carry negative charge, and affect the overall charge of the V3 loop, as discussed. 11 The presence of the glycosylation motif (and the charge glycosylation carries) can contribute to the evolutionary pressure for charge adjustments at other sites of the V3 loop sequence.
In this study we have analyzed V3 loop sequences with known coreceptor preference from patient samples, available at the Los Alamos HIV Databases. 25 Our analysis utilizes physicochemical information included in the sequences, such as net charge, the N6X7[T/S]8X9 glycosylation sequence motif, and the 11/24/25 positive amino acid rule, to develop a predictive statistical model for HIV-1 coreceptor selectivity.
Materials and Methods
We first retrieved 5,309 V3 loop sequences deposited at the Los Alamos HIV Databases 25 at the beginning of the study (June 27, 2011). The deposited sequences are derived from patient data and are associated with known coreceptor selection from experimental studies. 5,16,17,25 The sequence sample was reduced to 2,054 by filtering duplicate sequences belonging to the same patient and keeping only unique sequences per patient. Sequence analysis was performed using the amino acids within and including the disulfide bridge located at the base of the V3 loop. The sequences were 33–37 amino acids in length, with those associated with CCR5 having a length of 34–35 and those associated with CXCR4 or CCR5/CXCR4 (meaning dual or mixed coreceptor) showing larger length variability. Net charge was determined by counting the unit charges of positively and negatively charged amino acids. Arginines and lysines have charge +1, whereas aspartic and glutamic acids have charge −1. Given the high conformational variability (owed to lack of specific structure and solvent exposure of the V3 loop 9 ), we consider that histidines have a pK a close to that of free amino acids in solution (in the range of 6–6.5), and therefore they are neutral at physiological pH (at the range of 7–7.5). The presence or absence of the glycosylation motif and the 11/24/25 rule were determined as binary variables.
We used an ordered probit statistical model for quantitative estimation of coreceptor selectivity. Our underlying assumptions are (1) disease progression follows the coreceptor selection pattern in the order of CCR5 → CCR5/CXCR4 →CXCR4, and (2) that coreceptor selectivity can be inferred by the information found in the sequence of the V3 loop. The probit model depicts the coreceptor transition order, and can be used to predict probabilities for coreceptor selection given the properties of glycosylation motif, positive amino rule, and net charge. The model accounts for a discrete net charge integer variable and binary variables of 1 and 0 for the presence and absence, respectively, of the glycosylation motif and the 11/24/25 positive amino acid rule. These variables are not independent of each other, and they are all related to charge, as mentioned above. Let us call
where 1, 2, and 3 refer to progression in coreceptor state (CCR5, CCR5/CXCR4, and CXCR4, respectively), and μ1 and μ2 are unknown thresholds. We model the coreceptor selection as a function of a set of the following physicochemical characteristics of the V3 loop sequence: (1) the N6X7[T/S]8X9 glycosylation motif (denoted as Motif); (2) the 11/24/25 positive amino acid rule (denoted as Rule); and (3) net charge (denoted as Charge). For each individual sequence i
where ɛi
is a normal error term, independent and identically distributed (mean zero and variance 1). Under these assumptions, we obtain the probabilities of being in coreceptor state 1, 2 or 3, as follows:
where Φ is the cumulative standard normal distribution function.
The aforementioned model considers three coreceptor states, namely CCR5, CCR5/CXCR4, and CXCR4. But it can be argued that only two coreceptors physically exist, and therefore we can define an ordered variable yi
such that
The variable
The profile of our dataset of 2,054 sequences is shown in Table 1. The (Motif, Rule)=(1, 0) combination is most abundant (79.1% of total sum of sequences), with 87.5% of these sequences showing preference for CCR5. The (Motif, Rule)=(1, 1) combination is the second most abundant (11.5% of total sum of sequences), with 43.9% of these sequences showing preference for CCR5/CXCR4. The (Motif, Rule)=(0, 1) combination is the third most abundant (5.6% of total sum of sequences), with 61.4% of these sequences showing preference for CXCR4.
Number of counts (percent values) for coreceptor selection and (Motif, Rule) binary combination.
Refers to the sum of the three coreceptor selections for a given (Motif, Rule) combination. The percent value in parentheses refers to the specific (Motif, Rule) count with respect to the total count of 2,054.
The percent value in parentheses refers to the specific (Motif, Rule)/Coreceptor count with respect to the sum of the three coreceptor selections for the specific (Motif, Rule) given in the last column.
Refers to the total number of sequences showing preference for a given coreceptor selection. The percent value in parentheses refers to the specific coreceptor count with respect to the total count of 2,054.
The analysis for the three coreceptor model was performed using the dataset of Table 1, whereas the analysis for the two coreceptor model was performed using a reduced subset of the dataset, by excluding the 322 CCR5/CXCR4 entries.
To test the accuracy and robustness of the probit predictions, a second model was produced using the 1,368 sequences (of the 2,054 total sequences) that do not have an experimentally determined CD4 count assigned. The remaining 686 sequences with assigned CD4 counts were used as a test set for side-by-side comparisons with established methods, specifically geno2pheno[coreceptor] 27 and webPSSM. 28 The webPSSM predictions were performed using the subtype B x4r5 matrix, while the geno2pheno[coreceptor] predictions were performed using the original g2p coreceptor model with optimized cutoffs based on clinical data. Receiver operating characteristic (ROC) curve analysis based on the probit coreceptor probabilities was performed using the CD4 count dataset. A ROC curve for webPSSM CXCR4 preference was generated using the assigned score, while r5.pct was used to produce an ROC curve for CCR5 selection. Similarly, an ROC curve for CXCR4 selection was also produced for the geno2pheno[coreceptor] predictions using the assigned percentile; however, no CCR5 ROC curve was produced since the geno2pheno[coreceptor] server does not readily provide CCR5 analysis.
A final subset of the complete dataset, consisting of 317 sequences with assigned CD4 count and patient health status, was also identified. According to the Los Alamos HIV Databases, 25 the following disease states can be assigned to each sequence: (1) acute infection, (2) asymptomatic, (3) symptomatic, (4) AIDS, and (5) death; however, only states 1–4 are relevant for our analysis since sequences with a patient health status of death were excluded from this aspect of our results. The patient health subset was selected to allow comparisons between disease state and predictions for coreceptor selectivity. Three degrees of disease advancement have been assigned based on the patient health status: passed acute infection (patients in the asymptomatic, symptomatic, or AIDS states), passed asymptomatic phase (patients in the symptomatic or AIDS states), and AIDS.
Results and Discussion
Net charge is a significant factor in showing preference for CCR5, CXCR4, or CCR5/CXCR4, as shown by the statistical distributions of Fig. 1. The distribution that peaks at net charge of ∼3 denotes preference for CCR5 whereas the distribution that peaks at net charge of ∼5.5 denotes preference for CXCR4. An intermediate distribution denotes CCR5/CXCR4 preference, and marks the transition from CCR5 to CXCR4.
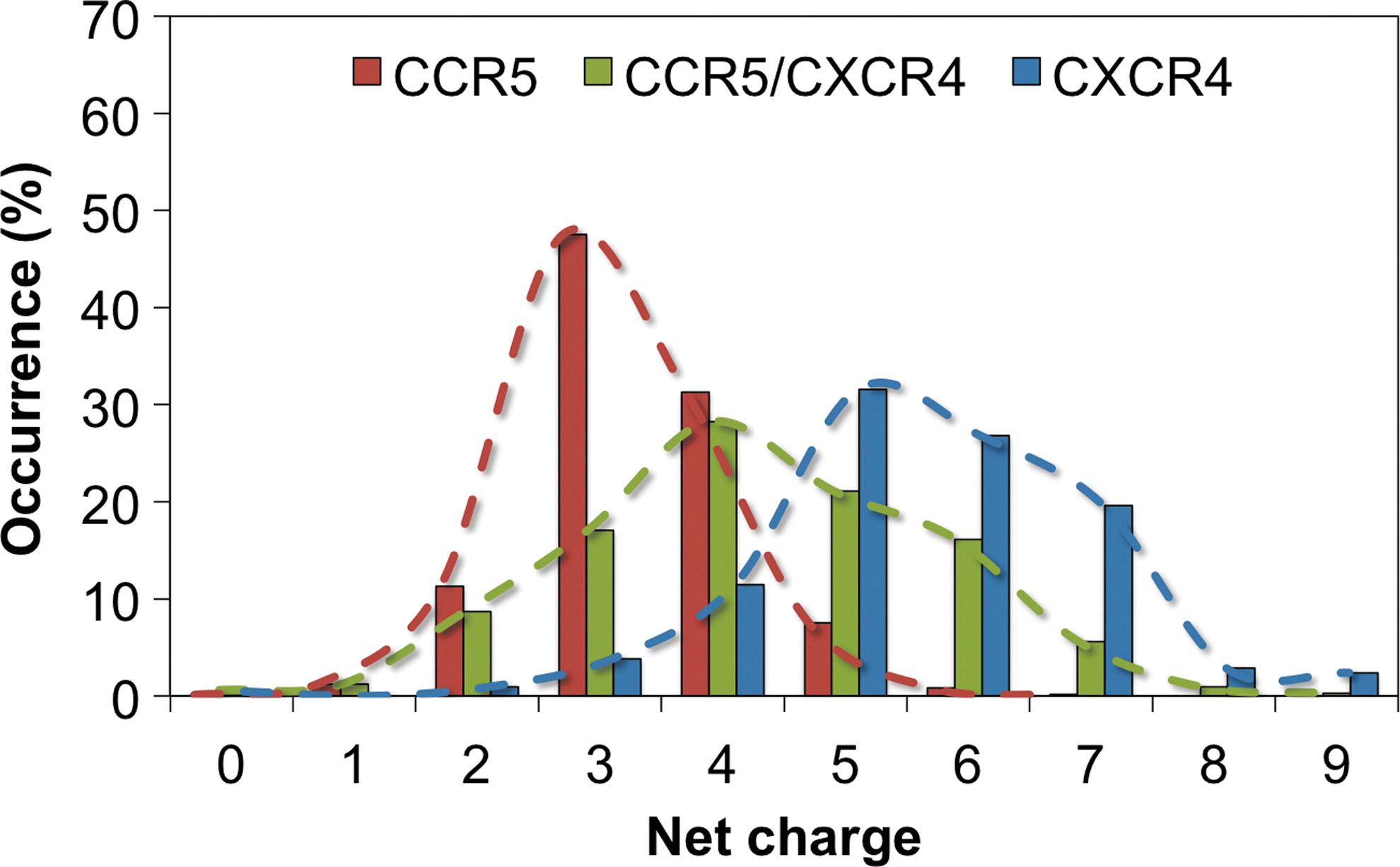
Charge distributions of V3 loop sequences with known coreceptor preference.
25
Color images available online at
We pursued further analysis that incorporates all known markers embedded in V3 loop sequences in order to develop a quantitative estimation model for coreceptor selectivity. We used the ordered probit statistical model to account for the discrete net charge data of Fig. 1, and coreceptor selectivity binary markers of the glycosylation motif and the 11/24/25 positive amino acid rule.
We consider that the preference for coreceptor selection is implicit in the observed V3 loop sequence. Our goal is to infer the most likely coreceptor selection from the physicochemical characteristics of the observed sequence. We constructed the predictive model based on the 2,054 V3 loop unique patient sequences with known coreceptor selections from experimental data deposited at the Los Alamos HIV Databases. 25
The estimated parameters of the ordered probit model described by Eqs. (1
)–(3) are summarized in Table 2. Interpretation of the
The ordered probit analysis was performed using the program EViews (Quantitative Micro Software, Irvine, CA;
Based on the analysis described above, the estimated model is
and the probabilities of being in coreceptor state 1, 2, or 3 are calculated as follows:
where Φ is the cumulative standard normal distribution function. Table 3 shows the comparisons of the sample and predicted data. The count of Column 3 corresponds to assigning a value of 1 for the coreceptor state (CCR5, CCR5/CXCR4, or CXCR4), predicted by the ordered probit model, and 0 for the other two states. The data show that the prediction accuracy for CCR5 coreceptor selection is higher than that for CXCR4 (98.2% versus 56%). Prediction for CCR5/CXCR4 selection is much lower (11.5%), as the model reclassifies 285 (out of 322) entries as showing preference for coreceptor CCR5 or CXCR4. This observation may reflect the fact that under the CCR5/CXCR4 category are placed both dual and mixed coreceptor selections. Use of the term “dual” implies the capability to bind to either CCR5 or CXCR4 coreceptors, whereas the term “mixed” implies a viral population that may contain combinations of CCR5-, CXCR4-, and/or dual-binding viral strains. Because of the physicochemical basis of our V3 loop analysis, it is likely that our predictive model can discriminate between dual and mixed coreceptor selection. This argument suggests that the predicted count for coreceptor state 2 (37 counts in Table 3) refers to dual CCR5/CXCR4 coreceptor selection.
Comparison of the predicted coreceptor assignments to the database assignments is shown in Table 4. A significant portion of the CCR5/CXCR4 and CXCR4 database assignments is reassigned (more frequently to CCR5), as discussed above. The origin of the reassignments is not understood at the moment, and possibly reflects the use of physicochemical properties (probit model) compared to the use of a variety of experimental methods by several different researchers in populating the database. This issue may be resolved in future work using self-consistent datasets derived from identical experimental methodologies, as well as time-dependent data from individual patients. Perhaps the most accurate experimental method to determine coreceptor selection depends on the use of cells that express CCR5 or CXCR4 only.
Count refers to predicted coreceptor assignments (reassignments) compared to the database assignments.
Italicized entries correspond to correct predictions. Boldfaced entries correspond to totals from the database assignment and probit reassignment. The rest of the entries correspond to lost (columns)/gained (rows) assignments.
Equations (6) and (7) can be used in predicting probabilities for coreceptor selectivity for a patient's experimentally derived V3 loop sequence, by simply assessing the presence or absence of the N6X7[T/S]8X9 glycosylation motif and 11/24/25 positive amino acid rule and by determining the net charge of the sequence (derived by summing the number of positively and negatively charged amino acids).
Figure 2 shows graphically the calculated probabilities as a function of net charge, glycosylation motif, and 11/24/25 positive amino acid rule. The calculated probabilities show that for (Motif, Rule)=(1, 0) there is a preference for CCR5 as charge decreases (Fig. 2A), whereas the opposite happens for (Motif, Rule)=(0, 1) for which there is preference for CXCR4 as charge increases (Fig. 2C). For (Motif, Rule)=(1, 1) charge is the dominant factor, and for (Motif, Rule)=(0, 0) charge is the only factor, in both cases favoring CCR5 as charge decreases and CXCR4 as charge increases (Fig. 2A and C). The probabilities for CCR5/CXCR4 preferences, marking the transition from CCR5 to CXCR4, are shown in Fig. 2B, and include the overlapping region between the probabilities for CCR5 and CXCR4 preferences.
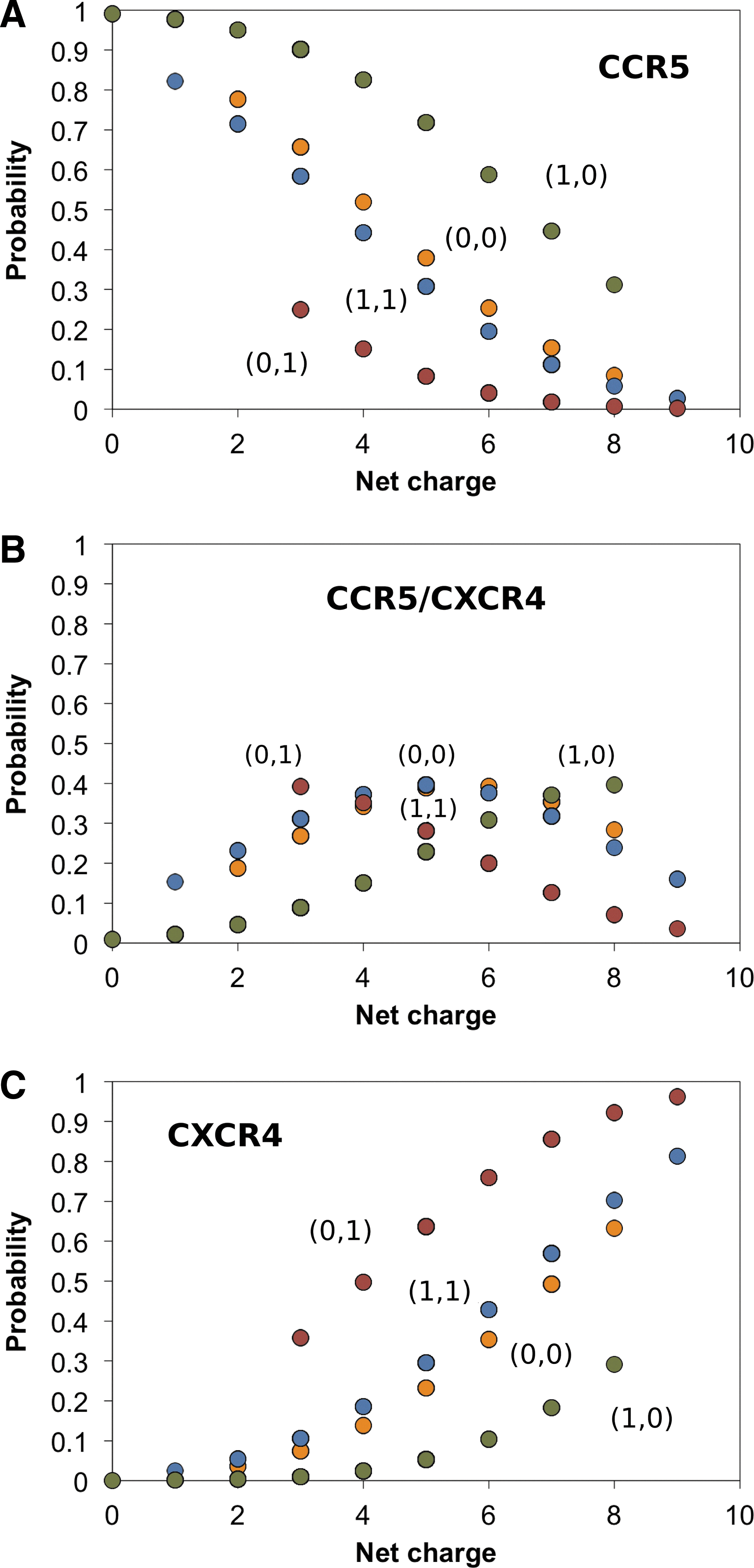
Probit analysis of V3 loop sequences using the three coreceptor disease model. Probabilities for coreceptor preference taking into account the property of net charge in the range 0–9 and the binary (1 for presence and 0 for absence) coreceptor markers of the N6X7[T/S]8X9 glycosylation motif (Motif) and the 11/24/25 positive amino acid rule (Rule), marked as (Motif, Rule) pairs.
The data of Fig. 2 suggest that the CCR5 preference when the glycosylation motif is present [case of (Motif, Rule)=(1, 0)] switches to CCR5/CXCR4 preference upon incorporation of a positive amino acid according to the 11/24/25 rule [and concurrent net charge increase, case of (Motif, Rule)=(1, 1)], and subsequently switches to CXCR4 preference upon loss of glycosylation capacity and concurrent net charge increase [case of (Motif, Rule)=(0, 1)]. Simultaneous loss of glycosylation capacity and positive charge at the 11/24/25 positions [least abundant combination of (Motif, Rule)=(0, 0)] shows no apparent preference for any of the coreceptor selections.
We have also performed the probit analysis using only two coreceptors, CCR5 and CXCR4, using Eqs. (4) and (5). The resulting estimated model is
and the probabilities of being in coreceptor state 1 or 2 are
The probit results are summarized in Fig. 3 and Supplementary Tables S1 and S2 (Supplementary Data are available online at
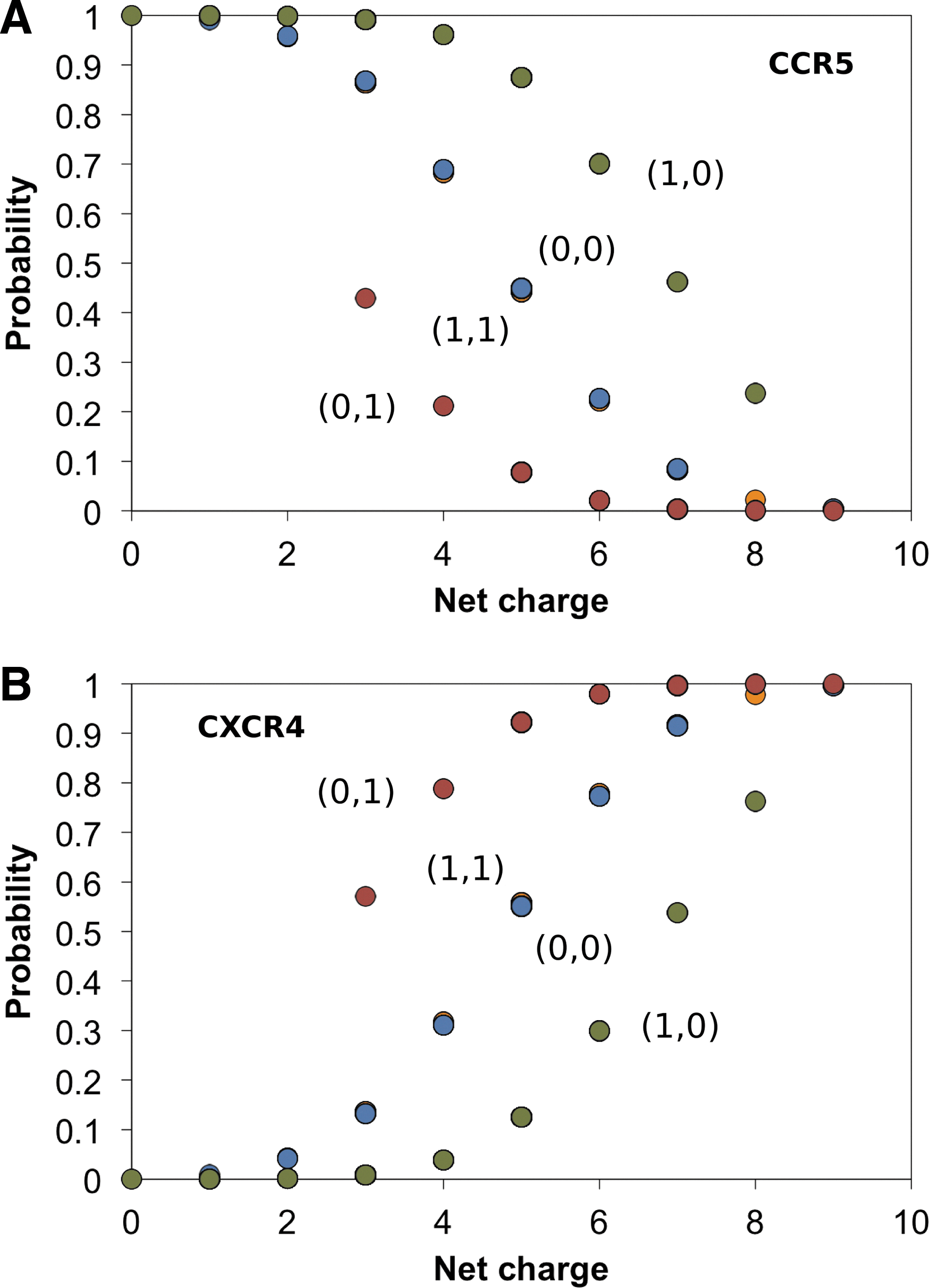
Probit analysis of V3 loop sequences using the two coreceptor model. The presentation of the data is similar to the presentation of Fig. 2.
The two phenotypic classes of HIV-1 strains are syncitia-inducing (SI) strains (infecting CD4+ T cells), and non-syncitia-inducing (NSI) strains (infecting macrophages and CD4+ T cells). The latter strains show preference for use of CCR5 for cell entry and are associated with the primary infection, whereas the former show preference for use of CCR5/CXCR4 or CXCR4 for cell entry and are associated with a rapid reduction in CD4 count and disease progression. Current laboratory tests to diagnose AIDS are CD4 counts, viral loads, and genotypic or phenotypic resistance tests. 26 With CD4 counts being a deposited parameter for a subset of the Los Alamos dataset, we have split the dataset of 2,054 sequences into a subset with associated experimental CD4 counts (686 entries) and a subset without available CD4 counts (1,368 entries). We used the subset without CD4 counts to test the robustness of the probit model and to train a model that could be used in blind prediction of the subset with CD4 counts.
The probit results for the three coreceptor model using the reduced dataset without CD4 counts are summarized in Supplementary Tables S3–S5, and they are similar to those with the complete dataset of 2,054 entries (Tables 2 –4). Figure 4 shows ROC curves for prediction of coreceptor selection for the CD4 count dataset, demonstrating rather high predictive values for CCR5 and CXCR4, but lower predictive value for CCR5/CXCR4. The poor prediction for CCR5/CXCR4 is potentially due to vagueness in the experimental methods used in determining a dual tropic virus, as is suggested by the fact that the probit model reclassified most of the CCR5/CXCR4 sequences. We also used the probit model trained with the subset without CD4 counts to evaluate the probit performance in comparison to predictions from existing popular servers, geno2pheno[coreceptor] 18,27 and webPSSM. 19,28 Figure 5A shows ROC curves for predictions of CXCR4 coreceptor selection for the CD4 count dataset, using probit, webPSSM, and geno2pheno[coreceptor]. Probit and geno2pheno[coreceptor] perform comparably, whereas webPSSM performs slightly better for this dataset. Figure 5B shows a similar analysis of predictions of CCR5 coreceptor selection for the CD4 count dataset, using probit and webPSSM, while the geno2pheno[coreceptor] web server does not directly predict CCR5. Both methods perform equally well for CCR5 prediction.

Accuracy of probit coreceptor preference predictions. Receiver operating characteristic (ROC) curve analysis for the three coreceptor preferences [color, area under the curve (AUC)]: CCR5 (magenta, 0.833); CCR5/CXCR4 (blue, 0.571); CXCR4 (black, 0.900). Color images available online at

Comparison of probit predictions with established methods.
Although it is known that as the infection/disease progresses a switch for coreceptor preference occurs, starting with selection of CCR5 and continuing with selection of CCR5/CXCR4 and CXCR4, 2 –5,10 –21 it is debatable if coreceptor selection may be predictive of disease state. To this end, we have analyzed the relationship between coreceptor selectivity and disease state, based on the probit predictions using the “patient health status” subset described in Materials and Methods. Figure 6 contains ROC curves illustrating the prediction of the AIDS patient health status based on preference for CXCR4, as assigned by probit, webPSSM, and geno2pheno[coreceptor]. CXCR4 preferences calculated by all three methods perform comparably well at predicting the AIDS status, with areas under the curve (AUC) of ∼0.7. Additionally, Fig. 6 also contains an ROC curve for AIDS status prediction based on experimentally assigned CD4 count, as a comparison. Surprisingly, the computationally predicted CXCR4 preferences perform similarly to CD4 count in assigning the AIDS status at high specificity values (>0.8).

Prediction of AIDS patient health status based on CXCR4 preference. ROC curve analysis for the prediction of AIDS patient health status based on CXCR4 preference, as predicted by (color, AUC) probit (black, 0.706); webPSSM (green, 0.620); geno2pheno[coreceptor] (blue, 0.708). For comparison a ROC curve for the prediction of the AIDS disease state based on CD4 count (red, 0.881) is also presented. Color images available online at
We have also performed analysis of the utility of probit predicted coreceptor preference in assigning degree of disease advancement. Supplemental Fig. S1 contains ROC curves for prediction of disease progression based on probit coreceptor preference, as well as CD4 count. CCR5 probability shows some predictive value for advancement passed the asymptomatic phase, and inversely predictive of the AIDS state. CCR5/CXCR4 probability has some predictive value for all three degrees of advancement, while CXCR4 probability shows the highest AUC for the prediction of the AIDS state. These results provide some evidence supporting the hypothesis that coreceptor selection may be indicative, but not a quantitative predictor, of disease state. Interestingly, despite these observed relationships between coreceptor selectivity and disease state, there is only a weak correlation between CD4 count and coreceptor selection. Supplemental Fig. S2 shows a graph of CD4 counts per coreceptor assignment (provided by the Los Alamos HIV Databases) for the CD4 count dataset of our sample, and Supplementary Table S6 shows the sample statistics. Although there is a trend in decreasing mean and median as we transition from selecting coreceptor CCR5 to CCR5/CXCR4 to CXCR4, there are many entries below the medically accepted threshold for AIDS diagnosis (200 counts) associated with CCR5 selection. The observations discussed above provide insight into the relationship between disease progression and coreceptor selection, and can serve as the foundation for the development of predictive models for HIV disease state progression.
The probit predictive model contributes to the available tools for the analysis of HIV sequence data and for the prediction of coreceptor selectivity, 18,19,29 –40 including web server tools geno2pheno[coreceptor] 27 and webPSSM. 28 What distinguishes probit from other methods is its simplicity. The probit model uses only three physicochemical characteristics that are embedded in the V3 loop genetic code, without dependencies of multiple adjustable parameters or heuristic arguments, and without the necessity for prior sequence alignments, nor a reliance on sequence templates.
Knowledge of coreceptor assignment provides information on the first contact point for viral entry, and therefore may be useful in determining medication targeting CCR5 or CXCR4 and at what ratio. Currently, there is one CCR5 entry drug clinically available and several CCR5 and CXCR4 entry drugs are in the pipeline. 41 –43 The need for CXCR4 entry drugs is evident, considering that development of drug resistance against CCR5 entry drugs is manifested as coreceptor switch from CCR5 to CXCR4. 42 The use of probit and other methods will be beneficial once the option of having both CCR5 and CXCR4 entry drugs becomes clinically available.
Conclusions
In practical terms, the predictive use of our model is demonstrated in Table 5, and the graphic presentation of the predictions is shown in Fig. 7. The predicted probabilities for selecting coreceptor CCR5, CCR5/CXCR4, and CXCR4, calculated using Eqs. (6) and (7), are shown in the net charge range of 0–10, and at the four (Motif, Rule) binary combinations described above. Table 5 can be used for quick and efficient assessment of coreceptor selection, and associated HIV-1 tropism, for an unknown V3 loop sequence.

The predictive use of the probit model. Graphic representation of predicted data corresponding to Table 5.
Probabilities for coreceptor selection, accounting for net charge in the range of 0–10 and the four (Motif, Rule) binary combinations.
Although charge alone is a strong marker for coreceptor preference at extreme charge values, it is a less definitive marker at intermediate charge values, where combinations of N6X7[T/S]8X9 glycosylation motif and 11/24/25 positive amino acid rule become discriminating factors (Figs. 2 and 7). The ordered probit model is useful to predict probabilities for CCR5, CCR5/CXCR4, and CXCR4 selection, using information for coreceptor preference that is found in the V3 loop sequence. Given the nature of viral infection and the fact that numerous viral strains with different coreceptor preferences may be present in a patient, a probabilistic model is suitable to assign percent coreceptor preference based on observed V3 loop sequences. The sequence-based analysis presented here can be used to predict coreceptor selection and may potentially be used to make personalized medical decisions, in addition to existing tools, for administration of drugs or combinations of HIV-1 entry drugs targeting CCR5 and/or CXCR4. Additional validation work with different experimental datasets, preferably using cells that express only one coreceptor, as well as predictive model refinement, will be necessary in reaching clinical applications.
Footnotes
Author Disclosure Statement
No competing financial interests exist.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.