
Abstract
Background:
In light of the widespread use of breast milk pumping, or, “pumping,” mothers are seeking clear, adequate breast pumping guidelines. We aimed at characterizing the information in web pages that mothers might find online when searching for answers related to breast pumping.
Materials and Methods:
We used Google to search for answers to 10 questions about pumping that mothers might ask. This search used Boolean search. We screened the first three pages of search results for each computer Google search. Each eligible hit (web pages) was evaluated for accuracy, readability, and credibility of its source.
Results:
Our search strategy produced 241 hits eligible for analysis. The majority of these contained accurate, readable information and were authored by credible sources. The proportion of eligible hits from questions that had a quantifiable (numeric) answer, (e.g., number of days that refrigerated milk remains safe for consumption) differed significantly (p = 0.024) from searches that did not. Search inquiries related to milk supply adequacy produced a disproportionately high number of inaccurate hits.
Conclusion:
Our findings indicate that accurate and credible information about breast pumping is accessible on the internet. However, practitioners should be aware that inaccurate information is present among mothers' likely hits. Our findings also underscore the fact that there are aspects of breast pumping that do not yet have guidelines available, and that these areas warrant further research. In addition, there is a need for guidelines that reflect the individual nature of the experience of breast pumping.
Introduction
Given the increasing use of milk expression,1,2 mothers are turning to the internet to answer their questions about pumping. Two studies conducted by Yamada et al.3,4 detail the information that women seek online about milk expression. However, only limited research has been done to ascertain what women find when they search for answers to their questions. It is essential for health care providers to be aware of the quality of information that women access online so that they can anticipate misconceptions that may arise and provide women with appropriate counseling. Inaccurate information may lead to practices that could adversely affect mothers and/or their infants. For example, the improper collection and storage of pumped breast milk could potentially expose infants to harmful pathogens.5,6 It is also important that researchers understand the gaps that exist in the literature so as to target future research into the practices and implications for pumping and feeding pumped milk.
We aimed at characterizing the information that mothers might find on the internet by conducting a scoping review of questions previously identified as common among pumping mothers seeking information online.3,4 Specifically, we aimed at characterizing the accuracy of available information as compared with established guidelines, when available, as well as its readability and the credibility of its sources. Secondarily, we aimed at determining whether any relationship existed among the accuracy, readability, or credibility of available information.
Methods
Study design
To investigate what information was available online about pumping, we chose to conduct a scoping review, which is designed to map the volume and characteristics of the existing literature on a given topic. This afforded us flexibility in the collection and evaluation of data obtained from a variety of publication types. 7 From September of 2018 to May of 2019, we collected data related to 10 questions that reflect the concerns about pumping that lactating mothers search online to answer (Table 1). We developed this list of questions by refining a set of 32 questions reported in 2 studies conducted by Yamada et al.,3,4 who identified the main questions that mothers seek answers to online by using data collected from posts in an online pregnancy forum (Fig. 1). Questions from this previous work were excluded from our analyses if they were not related to the storage, production, or preparation of pumped milk or if their answer would have been subjective in nature (i.e., “How do I deal with the guilt I feel for deciding to stop pumping?”).

Flowchart depicting the process of narrowing 32 questions from Yamada papers into 10 questions used for this study.
Summary of Questions with Corresponding Boolean Search Terms and Available Recommendations
Insufficient recommendations regarding alcohol and caffeine transmission.
Domperidone is not approved by the Food and Drug Administration and thus not prescriptible by physicians in the United States.
HM, human milk.
We conducted Google searches for 10 remaining questions by using research conducted by Hirsch et al. 8 as the framework for our search strategy. Boolean search terms were constructed by using straightforward language to reflect real searches that mothers might conduct to answer their questions about pumping. Hits were then scored on the accuracy of their information when compared with published scientific literature, readability, and the credibility of their source.
We were interested to know whether there were relationships between any two of our measured constructs. We were namely interested in identifying whether any relationship existed between the number of eligible hits for each question and accuracy, the number of eligible hits for each question and credibility, or accuracy and credibility. For example, we posited that credible sources might provide more accurate information than sources that were less credible. Another one of our goals was to compare “identification” questions (e.g., “What are potential causes of a decrease in my pump output?”), which were about finding a fact or a distinct answer, with “process” questions (e.g., “How should my milk be thawed?”), which were about how to go about doing something. We expected that identification questions would have higher accuracy because process questions tended to have longer, more complex answers. We also wanted to compare the accuracy of questions that had quantitative (numeric) answers with the accuracy of those questions with qualitative answers. We expected that questions with quantitative answers would have higher accuracy, because numeric recommendations are less subjective and thus may be less likely to include incorrect or incomplete information.
Data collection
We identified keywords and their synonyms from each of the 10 questions and used them to generate a set of Boolean search terms (Table 1). We retained the interrogative word (e.g., “what”) from the source question at the front of the Boolean terms for each search. A health care professional who works closely with lactating mothers (S.R.G.) verified the search terms. Question 5 was split into two searches, because we thought that mothers would be unlikely to include alcohol and caffeine in one search.
Diagnostic searches using Boolean terms revealed that Google and Bing differed little in the results obtained for a given search. Based on Google's number of unique monthly visitors, its dominant share of the search market, and the fact that it is the most popular search engine worldwide,9,10 we chose to use Google as the exclusive search engine in this research.
Our diagnostic searches revealed that duplicate and irrelevant links tended to show up after the third page of Google search results. For this reason, we only extracted hits (individual links) from the first three pages of search results. We used Zotero 11 software to create a separate database for each question's population of hits. Modifications to Zotero's database enabled us to repurpose categories to document relevant data for each hit, including its location within the Google search result pages, the web address, and author credentials. We then exported the data from Zotero to a spreadsheet for evaluation according to the scoring system.
Data preparation and scoring
Two reviewers (R.M.M. and K.A.C.-B.) independently screened individual hits (Fig. 2). We excluded hits for the following reasons: (1) duplicate web page, (2) dead or inaccessible link, (3) irrelevant to search query, (4) non-English language, (5) commercial product page, (6) forum, or (7) video. We excluded commercial product pages, because they were deemed primarily promotional rather than advisory. We excluded forums, because their content was often self-contradictory and embedded in sublayers, making it difficult to identify a primary message or author. We excluded videos, because we were unable to transcribe video content into a written format for analysis.
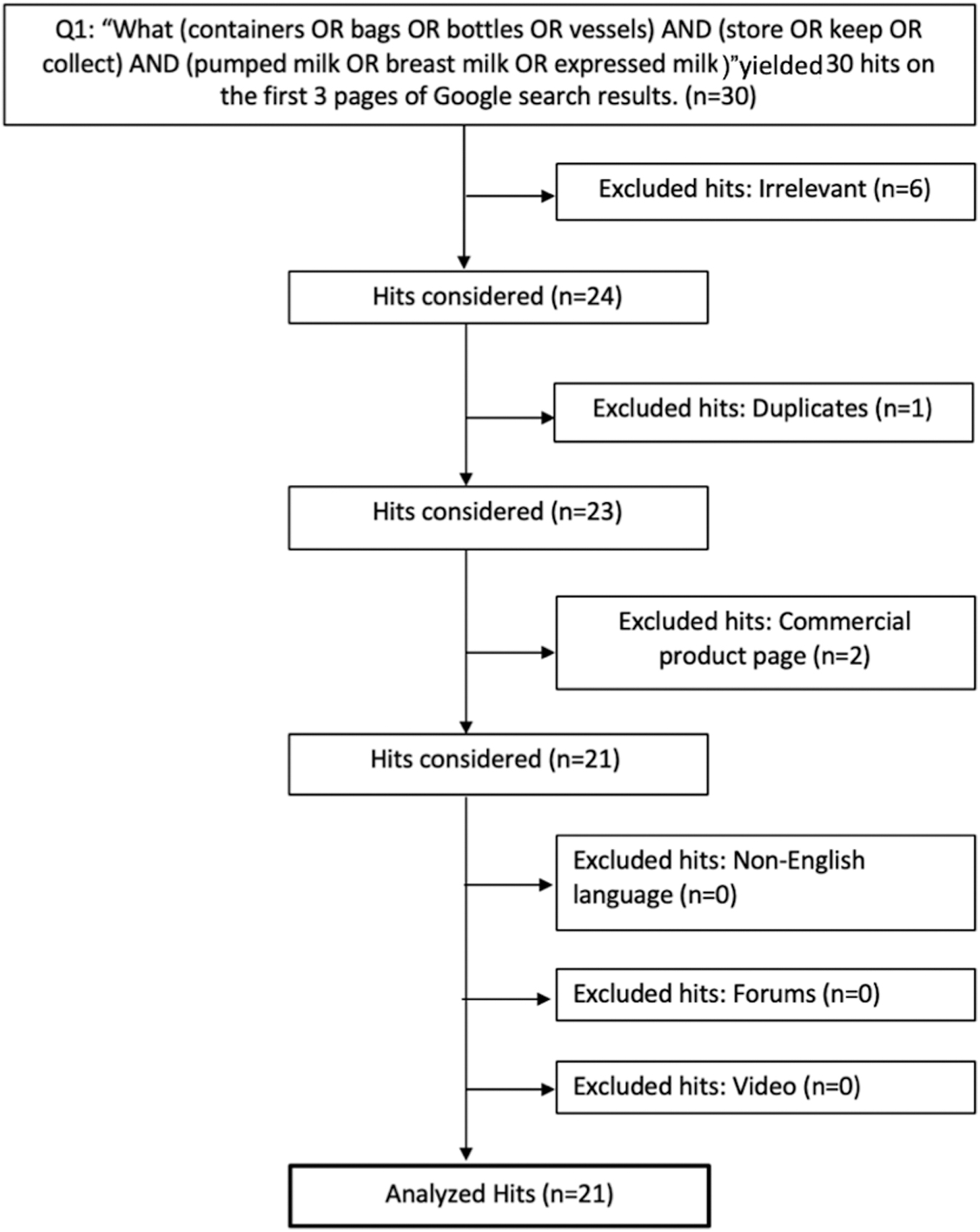
Inclusion flowchart of hits for Question 1. This figure models the process we went through for every question's population of hits to determine which hits would be scored and included in the final analysis.
We conducted a literature review for each of the 10 questions. The review identified a combination of scientific studies and professional guidelines to generate a set of appropriate answers to each question (Table 1). We devised a comprehensive scoring system based on the answers we obtained to evaluate information obtained from each hit. Our criteria of interest were accuracy, readability, and credibility. We defined accuracy as a measure of two discrete scoring dimensions: completeness and correctness. We defined readability as how easy a page is to comprehend, quantified by a score on the Flesch Reading Ease Score Test. 12 We defined credibility as the possession of professional credentials that indicated expertise in lactation (i.e., International Board of Lactation Consultant, Doctor of Medicine, Doctor of Philosophy, Certified Nurse Practitioner, etc.) or an association with a professional organization recognized as a source of expertise (i.e., National Institutes of Health, Centers for Disease Control and Prevention, and the Academy of Breastfeeding Medicine).
The two reviewers first scored each of the eligible results independently for completeness and correctness. They then reached consensus on a “final” score, to minimize errors and ensure consistency in scoring practices. We scored completeness on a 2-point scale, with 0 assigned if two or more components of a recommendation were missing, 1 if a single component was missing, and 2 if nothing was missing. For example, hits for Question 1 were scored a 2 if they indicated glass and hard plastic containers should be used and that materials containing BPA and other toxins should be avoided for the storage of pumped milk (Table 1). We scored correctness on a similar 2-point scale, with 0 assigned for two or more incorrect statements, 1 if a single component was incorrect, and 2 if everything on the page was correct. We then summed scores for correctness and completeness to yield a final “accuracy” score (0–4) (Table 2).
Summary of Descriptions of Hit Population Characteristics and Question Classifications
Process questions were those that asked how to go about doing something. Identification questions were those that inquired about a fact and sought a direct answer.
Quantitative answer questions were those that had a quantifiable recommendation. Qualitative answer questions were those that did not have a quantifiable recommendation.
To assess readability, we chose the Flesch Reading Ease Score Test 12 in Microsoft Word. It provided the most extensive scoring range for readability, evaluated the entire text, and is the current standard for many governmental agencies (Table 2). This test applied the following algorithm to an entire body of text: 206.835 − 1.015 (total words/total sentences) −84.6 (total syllables/total words). The scores range from 0 to 100. One hundred indicated a fifth-grade reading level whereas <30 indicated a reading level of a college graduate.
We scored credibility via independent analysis and subsequent discussion. We assigned scores on a binary scale: 1 indicated a credible source, and 0 indicated a source that was not credible (Table 2). Credibility was determined by affiliation with an appropriately credentialed author or reputable organization.
After scoring each hit, we determined the mean accuracy, readability, and credibility scores population of hits for each question. We calculated the proportion of accurate sources by counting the number of hits that received a score of 3 or 4 for accuracy. We also calculated the proportion of credible sources in each population of hits by counting the number of hits that received a score of 1 for credibility. We then compared these scores across all 10 questions.
Data analysis
The scores for each hit and population of hits were analyzed by descriptive statistics (number, proportion, and mean). We were interested to determine whether any relationships existed between the accuracy scores, readability scores, credibility scores, and proportion of eligible hits. We conducted multiple linear regression analyses within R software 13 to determine whether there was a relationship between any two of these four variables and, if so, how strong it was. To discern whether there was any difference between variables at a significance level of p < 0.05, we conducted two-tailed analyses of variance in Excel software. We also did a series of t tests to compare the accuracy scores and credibility scores of hits within each question to determine whether they differed at a significance level of p < 0.05.
Results
Our search strategy produced 340 hits, which were assessed for eligibility. On average, 31 hits made up the population of each question. We excluded 99 hits and included the remaining 241 for scoring and analysis (Table 1). We excluded hits because they were irrelevant (61), a duplicate (25), a forum (6), a product page (5), a dead link (1), or a video page (1). Figure 2 presents an example of the exclusion process for a single question.
Characteristics of available information
The mean accuracy of hits across all questions was 3.1 out of 4. Question 8 had the lowest mean accuracy score (2.4) whereas Questions 4 and 6 had the highest (3.6). We considered hits with an accuracy score of 3 or 4 accurate. The mean proportion of accurate hits was 77%. Percentages ranged from the lowest (38%, Question 8) to the highest (9.9%, Question 4). The mean proportion of credible hits was 55%. Question 7 had the lowest (44%), and Question 1 had the highest (62%).
The mean readability of eligible hits across all questions was 64%, falling in the category of “Standard” (accessible to those with education of grade 8–9 or above). Question 5a produced hits with the lowest average readability of 54, falling in the category of “Fairly Difficult” (accessible to those with education of grade 10–12 or above). Question 1 produced hits with the highest average readability of 73%, falling in the category of “Fairly Easy” (accessible to those with education of grade 7 or above).
Question type and characteristics of available information
There was a significant difference (p < 0.03) in the proportion of eligible hits between questions with quantitative answers (80 ± 10) and qualitative answers (63 ± 9.4) conditions. There was no significant difference, however, in scores for accuracy for questions with quantitative answers (3.3 ± 0.20) and questions with qualitative answers (2.9 ± 0.45; p < 0.10). Nor was there a difference in average readability scores (p = 0.024) or the proportion of credible hits (p = 0.300) (Table 3).
Summary of Scoring Methods Applied to Each Hit
Accuracy was defined as a function of both correctness and completeness. A score of 2 indicated complete correctness, and a score of 2 indicated full completeness. A score of 1 was applied if a hit was authored by a credible source, 0 if not. Readability was assessed by using the Flesch Reading Score Test in Microsoft Word, 10 with 100 being the most readable.
There was no difference in scores for the accuracy for process questions (3 ± 0.2) and identification questions (2.9 ± 0.5). Nor was there a difference in average readability scores (p = 0.989), the proportion of credible hits (p > 0.10), or the proportion of eligible hits between process and identification questions (p > 0.10) (Table 3).
Relationships among characteristics of available information
There was a difference in the accuracy score between the credible (4 ± 0.4) and non-credible groups (3 ± 0.8) for Question 5b, conditions; t(18) = −2.45, p < 0.04 (Table 4). There was not a significant difference for the other questions.
Summary of Findings from Statistical Tests
Process questions are those that asked how to go about doing something. Identification questions were those that inquired about a fact and sought a direct answer. Quantitative answer questions were those that had a quantifiable recommendation. Qualitative answer questions were those that did not have a quantifiable recommendation.
Hits were assessed by using author credentials as either “credible” or “non-credible.”
There was a positive correlation between the proportion of eligible results and the proportion of accurate results, but the relationship was not significant. There was a negative correlation between the proportion of eligible results and the proportion of credible sources, but the relationship also was not significant.
Discussion
The findings reported here provide insight into what mothers may find when they search for answers to questions about pumping online. It is possible to find accurate, readable, and credible, answers to questions within the first three pages of Google search results. However, mothers may have to sort through inaccurate information to find reliable answers. These findings indicate that health care providers must be able to anticipate what answers women may be receiving to address their concerns. Our findings also revealed gaps in the literature regarding caffeine recommendations and galactagogues, which suggests the need for further exploration of these subjects. Policymakers should note the lack of evidence on these issues and make an effort to communicate the uncertain nature of certain recommendations to mothers.
The low accuracy of answers to questions about milk supply adequacy highlights the lack of information that is readily available to educate women on the individual nature of pumping. This finding adds to the growing body of literature focused on pumping adequacy. Previous work3,4 revealed that pumping adequate volumes of milk was a major concern for mothers. Women turned to the internet to answer questions about adequacy. Question 8, which inquired about potential causes of low output, and Question 10, which inquired about techniques for increasing output, may have been difficult to answer online because many factors can affect milk output. Women may also conceptualize “adequate” amounts of milk differently based on their personal needs and, as such, a wide variety of answers were likely to arise. When counseling lactating mothers, health care providers should be aware of the diversity of women's concerns and the gaps in online information about pumping.
The difficulty that we experienced in compiling recommendations or guidelines relevant to several questions indicates a lack of consensus in the literature and the potential need for further research in those areas. For example, despite an extensive search, we could not identify a consolidated list of effective galactagogues in any scientific or academic publication (Question 10). Though many purported galactagogues have been studied, the results were conflicting. In addition, we found that there was insufficient information on alcohol intake in the literature to establish comprehensive recommendations (Question 5a). The Centers for Disease Control and Prevention indicates that guidelines about alcohol consumption and pumping can vary based on a mother's weight, metabolism, rate of alcohol intake, and whether or not alcohol was consumed with food 13 . We also found disagreement in the literature about what constitutes “low to moderate” amounts of caffeine (Question 5b). Sources cited different upper limits, which reflects the lack of available research on the relationship between maternal caffeine intake and infant health. These findings signal areas in which further research may be needed to supply health care providers with clear recommendations that they can use to counsel lactating mothers.
We also found that women ask several questions about pumping that cannot be answered by information available in the literature and thus require clinical consultation. In developing our list of 10 questions from the 2 studies by Yamada et al.,3,4 we recognized that 12 of the 32 potential questions were unlikely to have established recommendations or guidelines because they were subjective. In conducting our research, we found that Question 7, which inquired about the ideal frequency of pumping and ideal milk volume production, fell into this category as well. This finding suggests the need for health care providers to examine answers to questions pertaining to breast pumping beyond those addressed in this study, because mothers may still be searching online for answers to them.
This study has several limitations. The implications of our study may or may not be generalizable to all groups of women, because our questions came from a cohort of women with unidentified demographic characteristics. However, our findings represent what any woman using the internet would find if she performed the same searches regardless of her personal characteristics. We also used broad search terms to seek answers, potentially limiting information that mothers may have found by using terms more specific to their needs. A more elaborate searching technique may have been useful to determine the hits that would be produced by using different combinations of search terms for each question. We also limited our sample size for each question to the first three pages of hits. Though the small sample size may limit the generalizability of results for each question, our search strategy likely reflected the approach that mothers use, for a few look at results after the first three pages. In addition, our scoring method had no precedent, making potential faults difficult to identify. Given that the internet is a dynamic and evolving medium, the data we captured may not reflect what will be present online at a future time. Despite this, we felt that the established recommendations and guidelines themselves are not likely to change rapidly because active research in this field is limited. Finally, because we limited data collection to hits produced by computer-based searches, it is possible that the characteristics of available information differ in phone-based searches. 14 As phones play an increasingly important role in finding, using, and tracking health information, further research is needed to investigate this possibility and its potential implications. 14
This study also has several strengths. These findings likely present the first insights into what women find online when searching for answers to questions about breast milk pumping. Our search terms were designed to mimic mothers' search patterns and were verified by a medical professional who works closely with lactating mothers. We are confident that this searching strategy gave us the answers that mothers are likely to find online when they perform similar computer searches. We also used novel scoring methods that enabled us to score multiple characteristics for each hit.
Conclusions
The findings presented here characterize the information that women are likely to find when searching online for answers to questions about breast pumping. Although the internet contains quality information for certain questions, this is not the case for other questions. Our findings suggest that there are questions for which recommendations or guidelines are possible but not available. These are areas in which further research may be worthwhile to establish clear recommendations or guidelines. Our findings also identify the information health care providers should anticipate mothers may be accessing online. Further, these findings indicate the need for more clarity of language in recommendations to women. The continuous evolution of the practice of breast milk feeding in all of its forms indicates the need to adopt complex language to facilitate communication among everyone involved. 15 Further work is needed to establish more appropriate, consistent language among recommendations or guidelines and to fill gaps in the supporting literature where possible.
Footnotes
Acknowledgments
The authors thank Efe Airwele and Jessica Martin for their participation in the first phase of this research progress. They also thank Rei Yamada for her previous work that informed this study as well as her consultation during the early phase.
Disclosure Statement
No competing financial interests exist for all authors.
Funding Information
We received no external funding for this research.