
Abstract
Abstract
The ability of automatically recognizing and typing entities in natural language without prior knowledge (e.g., predefined entity types) is a major challenge in processing such data. Most existing entity typing systems are limited to certain domains, genres, and languages. In this article, we propose a novel unsupervised entity-typing framework by combining symbolic and distributional semantics. We start from learning three types of representations for each entity mention: general semantic representation, specific context representation, and knowledge representation based on knowledge bases. Then we develop a novel joint hierarchical clustering and linking algorithm to type all mentions using these representations. This framework does not rely on any annotated data, predefined typing schema, or handcrafted features; therefore, it can be quickly adapted to a new domain, genre, and/or language. Experiments on genres (news and discussion forum) show comparable performance with state-of-the-art supervised typing systems trained from a large amount of labeled data. Results on various languages (English, Chinese, Japanese, Hausa, and Yoruba) and domains (general and biomedical) demonstrate the portability of our framework.
Introduction
One important area of human language technology is the area of information extraction (IE). Systems, which perform IE, start from natural language inputs, usually in the form of a document set, and attempt to identify the various entities and events being described in each document. These extracted entities are then used to create knowledge bases or other tools that allow later systems to access the unstructured text through collections of the extracted entities, or to enhance systems for search, postprocessing, etc. IE systems that extract only a small number of entity types are referred to as coarse grained, those that can extract many more entity types, as we describe hereunder, are known as fine-grained IE systems. When the inputs can come from only one known domain and the system can be specialized to that area, the IE system is known as a “closed domain” system; when the documents can come from any domain, not necessarily known in advance, the system is referred to as an “open domain” system.
Open-domain IE remains a challenging and costly task. Previous IE programs mainly focused on a small set of predefined coarse-grained types and closed domains. For example, a commonly used test set, known as MUC-7, 1 was based on the three most common types: person, organization, and location. The representation used in that corpus, Automatic Content Extraction (ACE), separated geopolitical entities from (natural) locations and introduced weapons, vehicles, and facilities. These entity types are very useful for many downstream natural language processing (NLP)2–10 and information retrieval11–14 tasks. However, such manually defined type schemas often fail to generalize to new domains, such as the biomedical domain. In addition, traditional IE methods are highly dependent on human annotations, so they suffer from poor scalability and portability when moving to a new language, domain, or genre.
Considering these challenges, we have developed a new “Liberal” IE paradigm, which can simultaneously discover a domain-rich schema and extract information units with fine-grained types efficiently. It allows a “cold-start” (or minimal supervision from existing knowledge bases) and can be adapted to any domains, genres, or languages without any human annotated data. The only input to a Liberal IE system is an arbitrary corpus from any domain or topic. The output includes a schema, which contains a flexible hierarchy of types with multilevel granularities and is customized for the specific input corpus.
In this research, we demonstrate a new Liberal IE paradigm by showing automatic discovery of fine-grained entity types. Recent work15,16 suggests that using a larger set of fine-grained types can lead to substantial improvement for these downstream NLP applications. To demonstrate the motivations of our unsupervised fine-grained entity-typing framework, let us begin by considering the following examples, which motivate several heuristics that have guided our approach:
In E1, mentions such as Mitt Romney, George Romney, Detroit, and Michigan are commonly used and have no type ambiguity. That is, their types can be easily determined by their general semantics. Our first intuition is the following.
However, many entities are polysemantic and can be used to refer to different types in specific contexts. For example, Yuri Dolgoruky in E2, which generally refers to the Russian prince, is the name of a submarine in this specific context. Likewise, OWS in E3, which refers to Occupy Wall Street, is a very novel emerging entity. It may not exist in the word vocabulary, and its general semantics may not be learned adequately because of its low frequency in the data. Such types are difficult to capture with general semantics alone, but can be inferred by their specific contexts, such as nuclear submarines, equip, commission, activists, and protest. Thus, our second intuition is the following.
In E4, MEK, HER2, HER3, and pHER3 are biomedical domain-specific entities. Their types can be inferred from domain-specific knowledge bases (KBs). For example, the properties for pHER3 in biomedical ontologies include Medical, Oncogene, and Gene. Therefore, we derive the third intuition.
Based on these heuristics, we have developed an unsupervised fine-grained entity-typing framework that combines general entity semantics, specific contexts, and domain-specific knowledge. Because it does not need a predefined typing schema, manual annotations, or handcrafted linguistic features, this framework can be easily applied to new domains, genres, or languages. The types of all entity mentions are automatically discovered based on a set of clusters, which can capture fine-grained types customized for any input corpus.
We compare the performance of our approach with state-of-the-art name tagging and fine-grained entity-typing methods, and show the performance on various domains, genres, and languages. The results are comparable to state-of-the-art systems that are much more complex and handcrafted.
Related Work
Several recent studies have focused on fine-grained entity typing. Fleischman and Hovy 17 classified person entities into eight fine-grained subtypes based on local contexts. Sekine 18 defined more than 200 types of entities. The abstract meaning representation (AMR 19 ) defined more than 100 types of entities. Fine-Grained Entity Recognizer (FIGER) 16 derived 112 entity types from Freebase 20 and trained a linear-chain conditional random field (CRF) model 21 for joint entity identification and typing. Gillick et al. 22 and Yogatama et al. 23 proposed the task of context-dependent fine-grained entity typing, whereby the acceptable type labels are limited to only those deducible from local contexts (e.g., a sentence or a document). Similar to FIGER, this work also derived the label set from Freebase and generated the training data automatically from entities resolved in Wikipedia. Lin et al. 24 proposed propagating the types from linkable entities to unlinkable noun phrases based on a set of features. Hierarchical Type Classification for Entity Names (HYENA) 25 derived a very fine-grained type taxonomy from Yet Another Great Ontology (YAGO) 26 based on a mapping between Wikipedia categories and WordNet synsets. This type structure incorporated a large hierarchy of 505 types organized under five top level classes (person, location, organization, event, and artifact), with 100 descendant types under each of them. Although these methods can handle multiclass multilabel assignment, the automatically acquired training data are often too noisy to achieve good performance. In addition, the features they exploited are language dependent, and their type sets are rather static.
Our work is also related to embedding techniques. Turian et al. 27 explored several unsupervised word representations including distributional representations and clustering-based word representations. Mikolov et al. 28 examined vector space word representations with a continuous space language model. Besides word embedding, several phrase embedding techniques have also been proposed. Yin and Schütze 29 computed embeddings for generalized phrases, including both conventional linguistic phrases and skip bigrams. Mitchell and Lapata 30 proposed an additive model and a multiplicative model. Linguistic structures have been proven useful to capture the semantics of basic language units.31–34
Socher et al. 33 designed a Dependency Tree Recursive Neural Network (DT-RNN) model to map sentences into compositional vector representations based on dependency trees. Hermann and Blunsom 32 explored a novel class of combinatory categorial autoencoders to utilize the role of syntax in combinatory categorial grammar to model compositional semantics. Socher et al. 34 designed a recursive neural tensor network to compute sentiment compositionality based on the Sentiment Treebank. Huang et al. 31 proposed to induce event schemas based on compositional event structure representations. Compared with these efforts, in this work, we attempt to compose the context information to infer the fine-grained types. Considering not all contexts are meaningful, we carefully selected specific types of relations to capture concept-specific local contexts instead of sentence-level or corpus-level contexts.
Approach Overview
Figure 1 shows the major components of our system, which can automatically discover fine-grained entity types based on entity linking techniques and distributed semantic representations. It takes the boundaries of all entity mentions as input and produces a type label for each mention as output. The framework starts from learning three kinds of representations:
(1) a general entity distributed representation based on global contexts, (2) a specific context representation based on local context words, and (3) a knowledge representation, to model domain-specific knowledge for each mention.

Approach overview (solid boxes are required whereas the dotted boxes are optional).
For example, Figure 2 shows how these three types of information can be used to infer the type of “pHER3.” It shows how the type of pHER3 (Gene) can be inferred from similar words (e.g., erbB3, HER3) based on general semantics, specific context words such as “phosphorylated,” as well as the properties from KB, e.g., oncogenes.

Information that can be used to infer the type of pHER3.
After learning general and context-specific semantics, we apply unsupervised entity linking to link entity mentions to a domain-specific knowledge base. Based on the linking results, we can determine the knowledge representation and extract a type path for each entity mention, which can be linked to KB. Finally, we use these three representations as input to a hierarchical X-means clustering algorithm 35 and incorporate an optimal partition search algorithm to discover the optimal clustering and typing results.
Representation Generation
General entity representation
Based on Heuristic 1, we can infer the types of most entity mentions. For example, “Mitt Romney” and “John McCain” are both politicians from the same country, “HER2” and “HER3” refer to similar “ERBB (Receptor Tyrosine-Protein Kinase),” and thus they have the same entity type “Enzyme.”
We start by capturing the semantic information of entity mentions based on general lexical embedding, which is an effective technique to capture general semantics of words or phrases based on their global contexts. Several models30,36–38 have been proposed to generate word embeddings. Here, we utilize the Continuous Skip-gram model 36 based on a large amount of unlabeled in-domain data set.
Specific context representation
General embeddings can effectively capture the semantic types of most entity mentions, but many entities are polysemantic and can refer to different types in various contexts. For example, “ADH” in the biomedical domain can be used to refer to an enzyme “alcohol dehydrogenase” or a disease “atypical ductal hyperplasia”; “Yuri Dolgoruky” may refer to a Russian prince or a submarine. In addition, novel or uncommon entities may not exist in the word vocabulary or their semantic embeddings may not be adequately trainable. To solve these problems, based on Heuristic 2, we propose to incorporate specific contexts to infer the entity type.
Considering E2 again, the type of “Yuri Dolgoruky” can be inferred from its context-specific relational concepts such as “nuclear submarines” and “equip.” In this work, we use AMR 19 to carefully select the meaningful context words. AMR captures a whole sentence's meaning in a rooted, directed, labeled, and (predominantly) acyclic graph structure. The AMR language contains rich relations, including frame arguments (e.g., :ARG0 and :ARG1), general semantic relations (e.g., :mod, :topic, and :domain), relations for quantities, date entities, or lists (e.g., :quant, :date, and :op1), and the inverse of all these relations (e.g., :ARG0-of and :quant-of). We carefully select eight entity-related relation types (:ARG0, :ARG1, :ARG2, :ARG3, :conj, :domain, :topic, and :location) from AMR for entity typing.
Figure 3 depicts the context-specific representation generation for “pHER3” in the example E4. Given an entity mention, for example, “pHER3,” we first select its related concepts. For each AMR relation, for example, :ARG1, we generate a representation based on the general embeddings of these related concepts. If a related concept does not exist in the vocabulary, we randomly generate a vector for this concept. If there are several argument concepts involved in a specific relation, we average their representations. For example, we average the representations of “HER3” and “HER2” to get the representation for “Conj” relation. We concatenate the vector representations of all selected relations into one single vector. Although we have carefully aggregated and selected the popular relation types, the representation of each entity mention is still sparse. To reduce the dimensions and generate a high-quality embedding for the specific context, we utilize the sparse autoencoder framework 39 to learn more low-dimensional representations.
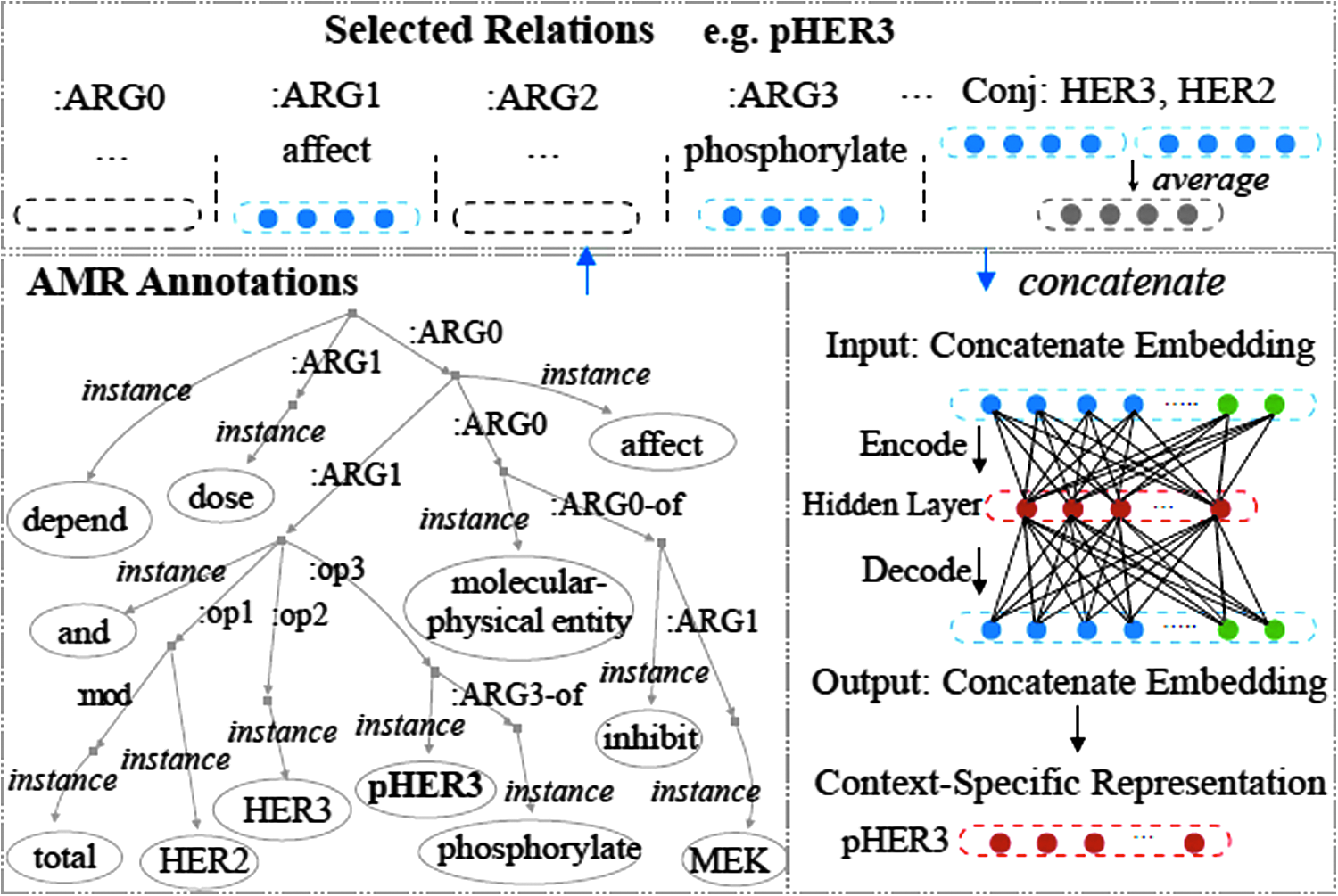
Context-specific representation generation for pHER3 based on AMR annotation. AMR, abstract meaning representation.
Knowledge representation
Existing broad-coverage knowledge bases such as DBpedia, Freebase, or YAGO, as well as domain-specific ontologies such as BioPortal and NCBO can provide useful knowledge for inferring specific fine-grained types. For example, in DBPedia, both properties (e.g., birthPlace, party for
Next we utilize a domain- and language-independent entity linking system 41 to link each mention to existing KBs to determine its knowledge representation. This system is based on an unsupervised collective inference approach and selects the most confident candidate (confidence score >0.95) as the appropriate entity for linking; mentions selected according to this criterion are referred to as highly linkable in subsequent sections. If a mention cannot be linked to a KB (i.e., it is not highly linkable), we will assign a random vector as its knowledge representation, and later, this vector will be used for all the similar mentions. In our experiments, about 77.7% entity mentions in the general news domain and about 71.4% in the biomedical domain can be linked to KBs with high confidence.
Joint Linking, Hierarchical Typing, and Naming
Hierarchical typing
For an entity mention
Given the set of all mentions M, we select highly linkable mentions (confidence score >0.95)  , where
, where 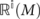 represents the partition of M based on vector representation set V at layer i.
represents the partition of M based on vector representation set V at layer i.

Algorithms 1 and 2.
For each layer i, to get further partition set  based on
based on  , we define
, we define
We then define an objective function O that evaluates a certain layer of partition set 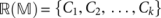 :
:

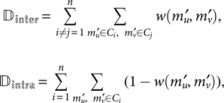
where
Hierarchical typing naming
The entity linking system described in the Knowledge Representation section can extract highly linkable entity mentions and their corresponding type name paths. Considering the examples in the Introduction section again, we can link the entity mention
For a specific cluster C, the mentions within this cluster are denoted as MC and the highly linkable mentions are
where
We combine these two metrics and choose nC as follows: for each cluster C we define
Experiments and Evaluation
In this section, we present an evaluation of the proposed framework on various genres, domains, and languages, as well as a comparison with state-of-the-art systems.
Data
We first introduce the data sets for our experiments. To compare the performance of our framework against state-of-the-art name taggers and evaluate its effectiveness on various domains and genres, we first conduct experiments on AMR data sets, which include perfect mention boundaries with fine-grained entity types. For the experiment on multiple languages, we use data sets from the DARPA LORELEI program and foreign news agencies. The detailed data statistics are summarized in Table 1.
As our approach is based on word embeddings, which need to be trained from a large corpus of unlabeled in-domain articles, we collect all the English and Japanese articles from the August 11, 2014, Wikipedia dump to learn English and Japanese word/phrase embeddings and collect all the articles of the 4th edition of the Chinese Gigaword Corpus to learn Chinese word/phrase embeddings. For the biomedical domain, we utilize the word2vec model, which is trained based on all article abstracts from PubMed and full-text documents from the PubMed Central Open Access subset. We also collect all entities and their properties and type labels from DBpedia and more than 300 biomedical domain-specific ontologies crawled from BioPortal 42 to learn knowledge embeddings.
Evaluation metrics
Our framework can automatically discover many fine-grained types. Some of the types can be mapped to the human annotated types, while some cannot. Therefore, in addition to mention-level precision, recall, and F-measure, we also exploit standard clustering measures of purity, F-measure, and entropy to evaluate the performance of new entity types (which are defined in Appendix 3).
Comparison with state-of-the-art systems
We compare with two high-performing name taggers, Stanford NER 43 and FIGER, 16 on both coarse-grained types (person, location, and organization) and fine-grained types. We utilize the AMR parser developed by Flanigan et al. 44 and manually map AMR types and system-generated types to three coarse-grained types. To compare identification results, we design a simple mention boundary detection approach based on capitalization features and part-of-speech features. We compare the performance of our system with both perfect AMR and system AMR annotations with the performance of NER and FIGER. We conduct the experiments on English news data set and link entity mentions to DBPedia. 45 The mention-level F-scores are shown in Table 2.
Based on perfect AMR.
Based on system AMR.
AMR, abstract meaning representation.
Besides these three coarse-grained types, there are also many new types (e.g., vehicle and medium) discovered by fine-grained entity typing approaches. We compare our framework with FIGER based on its 112-classes classification model. The cluster-level F-scores are shown in Figure 5.
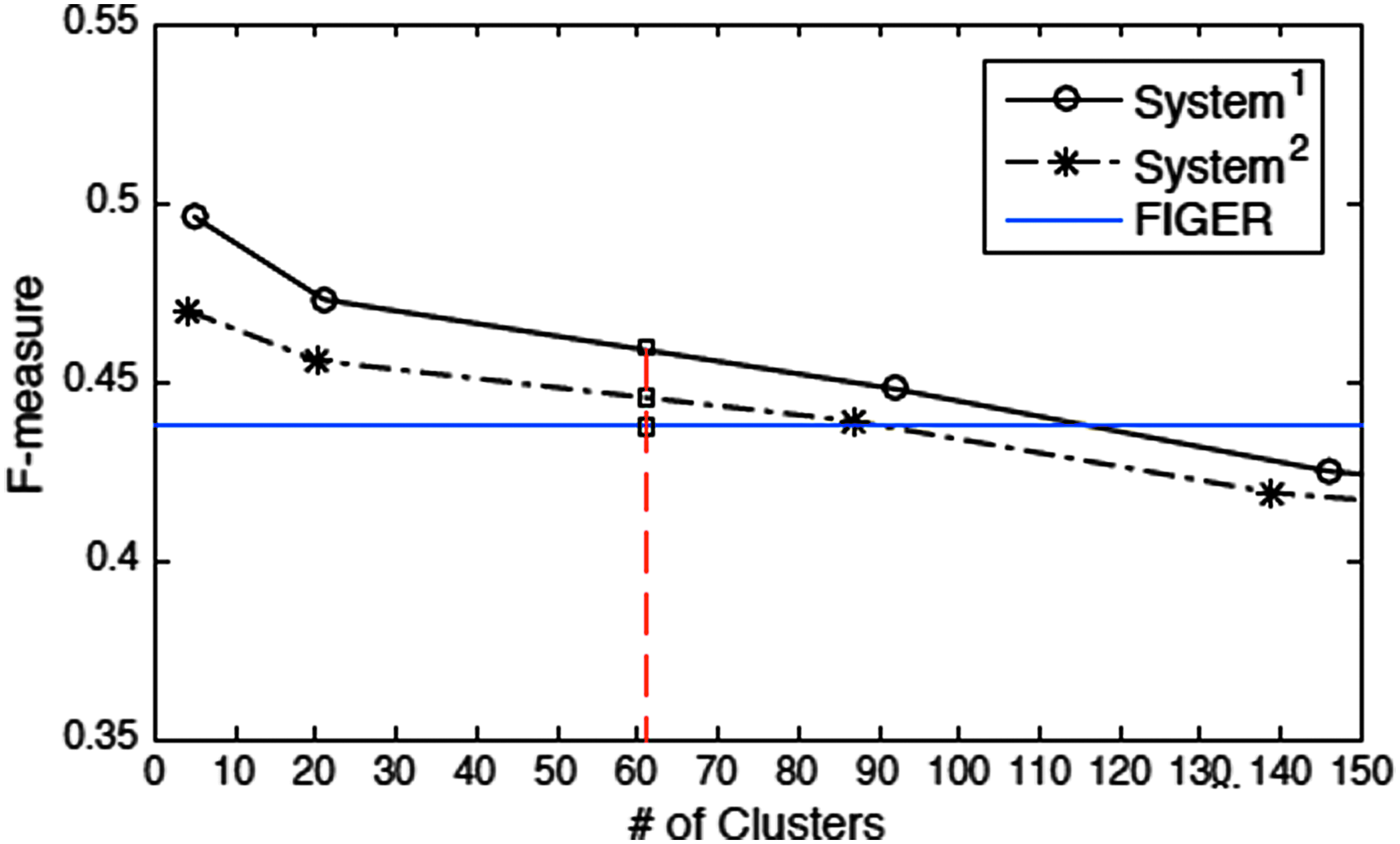
Fine-grained cluster level F-score comparison (the red dashed line shows the same number of clusters for comparison).
From Table 2 we can see that, on coarse-grained level, compared with Stanford NER, which contains many features and is trained on about 945 annotated documents (∼203,000 tokens), our approach with both system AMR and perfect AMR achieved comparable performance. Compared with FIGER on coarse-grained level, our approach with system AMR and perfect AMR also achieved better results. Figure 5 shows the fine-grained level performance. The number of clusters, to some extent, can reflect the granularity of fine-grained typing. Although we cannot directly map the granularity of FIGER to our system, considering that the classification results of FIGER are highly biased toward a certain subset of types (about 60 types), our approach with both system AMR and perfect AMR should slightly outperform FIGER, which is trained based on 2 million labeled sentences.
Both Stanford NER and FIGER heavily rely on linguistic features, such as tokens, context n-grams, and part-of-speech tags, to predict entity types. Compared with lexical information, semantic information is more indicative to infer its type. For example, in
Comparison on genres
For comparison between news and discussion forum genres, we utilize perfect entity boundaries and perfect AMR annotation results to model local contexts and link entity mentions to DBpedia. 45 Figure 6 shows the performance.

Typing results for different genres and domains with perfect AMR (the red dashed line shows the same number of clusters for comparison).
We can see that our system performs much better on news articles than discussion forum posts, because of two reasons: (1) many entities occur as abbreviations in discussion forum posts, which brings challenges to both entity typing and linking. For example, in the following post: The joke will be on
In addition, our system can outperform the FIGER system, of which the results are focused on about 50 types on the discussion forum data set, on both Purity and F-measure. As discussed in the Comparison with State-of-the-Art Systems section, FIGER is trained based on a rich set of linguistic features. When it is applied to a new informal genre, feature generation cannot be guaranteed to work well. Our system is mainly based on semantic representations, which will not be affected by the noise.
Comparison on domains
To demonstrate the domain portability of our framework, we take the biomedical domain as a case study. For fair comparison, we used perfect AMR semantic graphs and perfect mention boundaries. Figure 6 compares the performance for news and biomedical articles.
As shown in Figure 6, our system performs much better on biomedical data than on general news data. In an in-depth analysis of the experiment results, we found that most of the entity mentions in the biomedical domain are unique and unambiguous, and the mentions with the same type often share the same name strings. For example,
Figure 7 shows the ambiguity comparison results between the general news and biomedical domains. Owing to the low ambiguity of the biomedical domain, the general semantic representation and knowledge representation can better capture the domain-specific types of these entity mentions. This analysis can also be verified by the final optimal weights for three kinds of representations
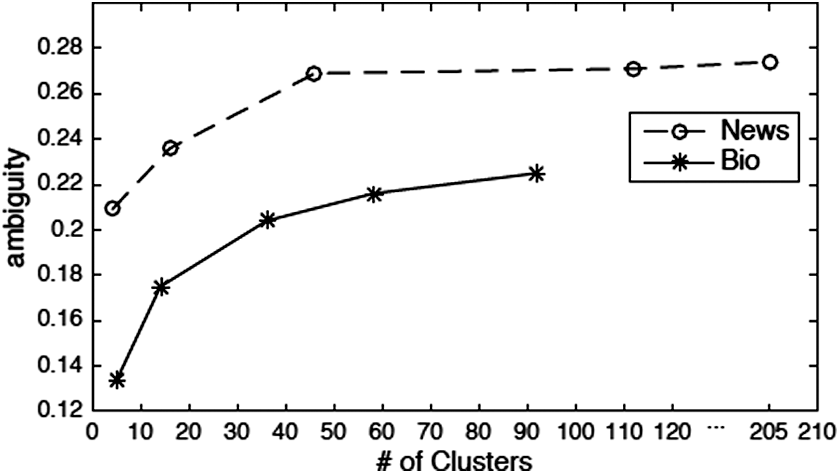
Ambiguity comparison for different domains.
Comparison on languages
Our framework is also highly portable to new languages. Different languages may have different linguistic resources available. For example, English has rich linguistic resources (e.g., AMR) that can be utilized to model local contexts, whereas some languages (e.g., Chinese and Japanese) do not. To evaluate the impact of the local contexts on entity typing, we compare the performance based on AMR and the embeddings of context words that occur within a limited-size window. In our experiment, the window size is 6. Figure 8 shows the performance on English, Chinese, and Japanese news data sets.

Typing results for various languages.
Figure 8 shows that our framework on Chinese and Japanese also achieved comparable performance as English. The main reason is that entities in Chinese and Japanese have less ambiguity than English. Almost all of the same name strings refer to the same type of entity. Based on the ambiguity measure in the Comparison on Domains section, the ambiguity is lower than 0.05 both for Chinese and Japanese.
In addition, for low resource languages, there are not enough unlabeled documents to train word embeddings, and KBs may not be available for these languages. In this case, we can utilize other feature representations such as bag-of-words tf-idf instead of embedding-based representations. To prove this, we apply our framework to two low-resource languages: Hausa and Yoruba. The mention-level typing accuracy with perfect boundary is very promising: 85.42% for Hausa and 72.26% for Yoruba.
Conclusions and Future Work
In this work, we demonstrated a new Liberal IE paradigm. Using fine-grained entity typing task as a study case, for the first time, we show an unsupervised framework, which incorporates entity general semantics, specific contexts, and domain-specific knowledge to discover the fine-grained types. This framework takes the human out of the loop and requires no annotated data or predefined types. Without the needs of language-specific features and resources, this framework can be easily adapted to other domains, genres, and languages. We also incorporate a domain- and language-independent unsupervised entity linking system to improve the clustering performance and discover corpus-customized domain-specific fine-grained typing schema.
Our framework achieves performance comparable to state-of-the-art entity typing systems trained from a large amount of labeled data. The results are encouraging considering the simplicity of our system. In ongoing research, we are extending the Liberal Information Extraction framework to other tasks, such as Event Extraction and Relation Extraction, to automatically induce schemas without the need for predefined types and human annotation.
Footnotes
Acknowledgments
We would like to thank Kevin Knight and Jonathan May (ISI) for sharing biomedical AMR annotations. This work was supported by the U.S. ARL NS-CTA No. W911NF-09-2-0053 and DARPA DEFT No. FA8750-13-2-0041, and in part by NSF IIS-1523198, IIS-1017362, IIS-1320617 and IIS-1354329, and NIH BD2K grant 1U54GM114838.
Author Disclosure Statement
No competing financial interests exist. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation here on.