
Abstract
Abstract
The proliferation of new data sources, stemmed from the adoption of open-data schemes, in combination with an increasing computing capacity causes the inception of new type of analytics that process Internet of things with low-cost engines to speed up data processing using parallel computing. In this context, the article presents an initiative, called BIG-Boletín Oficial del Estado (BOE), designed to process the Spanish official government gazette (BOE) with state-of-the-art processing engines, to reduce computation time and to offer additional speed up for big data analysts. The goal of including a big data infrastructure is to be able to process different BOE documents in parallel with specific analytics, to search for several issues in different documents. The application infrastructure processing engine is described from an architectural perspective and from performance, showing evidence on how this type of infrastructure improves the performance of different types of simple analytics as several machines cooperate.
Introduction
Big data1–17 refers to datasets that cannot be processed in a single machine using current tools and that require specific facilities to analyze, capture, curate, search, store, visualize, or update information.18–23 Typical datasets are found in areas such as the Internet search, finance,24–36 urban informatics, and business informatics.37,38,39 Currently, big data are also characterized by five V's, namely volume, variety, velocity, variability, and veracity. In addition, there is a number of technologies associated to the big data ecosystem, such as Hadoop, Map–Reduce, and a more initiative called Apache Spark that provide a good substrate to develop applications that offer different coverage to different needs of populations.
In relationship with big data, Internet of things (IoT) produce in the services to our everyday life offering better quality services, such as instant communication to express service deliveries. Fusion among big data and IoT may have positive impacts in next-generation big data and analytics; see Refs.37,38,40 The fusion of data has advantages in healthcare, finance, security, transportation, and education. There are many sources and we need to understand that the combination of software and hardware is important because devices may generate petabytes of data. In all this integration, there is a lack in works that deal 27 with the definition of proper architectures. In Ref. 27 authors indentify development of efficiency solutions, as one of the keys to produce synergic models that combine big data with information coming from IoT. In some cases, aggregations have to be taken into a time-critical dimension, see Ref. 13
More specifically, the list of challenges in the development of these applications26–29 is large and includes the definition of efficient solutions able to offer efficient solutions to process data in parallel derived from the specific nature of the different big data engines. In addition, most of those architectures require being interoperable with current cloud and IoT initiatives,30–33,39,41–57 or be able to interoperate with current open-data initiatives. In this context, the contribution deals with the integration of a big data tool for the domain of open-data analytics.
More and more, official institutions release data in open-data format free and available to everyone that wants to use them1–3 as IoT entities with information that can be processed later. The list of sites supporting this type of paradigm is large and includes a bunch of open-data government initiatives spread around the world. In some cases, open-data also includes scripts to enable concerned citizens to download information automatically. One example of them is the official gazette of the Spanish government, namely Boletín Oficial del Estado (BOE) 10 in Spanish, which is published every day, except on Sundays, and gathers data from different sources grouping years and months in repositories that can be processed later.
BOE publishes decrees from Spain's Parliaments and Spanish regional parliaments. It consists of five sections: general provisions, authorities and personnel, other provisions, administration justice and other provisions, and ads. The gazette is openly accessed in PDF, HTML, and XML format from its main site. 10 In many cases, the processing of this data was done with tools that run in single machines and only recently it has been taken into consideration the use of big data engines as mean to speed up different operations on them.37,38 Potentially, big data technologies1,5,9offer support to perform analytics in parallel using map–reduce-enabled nodes, which reduce computation times remarkably. Big data offer a huge storage space that may be processed by several machines grouped as a cluster of machines of special interest to data scientists. 6 Also, fusion is relevant to determine strange patterns that can be processed later.
In the particular case of BOE documents, there are some social initiatives that use this open information to access data and offer independent analysis, like CIVIO, 11 a non-profit social platform in charge of controlling public powers, using the information included in BOE. None of those initiatives has taken advantage of a big data cluster neither to reduce processing times nor to carry out any type of complex analysis on these data; they are devoted to increase transparency on public infrastructure. Also, none of the approaches offered fusion blocks able to integrate a fusion architecture in charge of making the most of the different architectural elements, nor study the improvements in performance it may have. This is exactly one goal in BIG-BOE: to offer reduced computation times with parallel map–reduce interactions. In addition, BIG-BOE provides a generic tool that can be used to design different analytics running on a big data lake. BIG-BOE offers the possibility of storing large amounts of data that may be consequently used for other purposes, while CIVIO is a particular approach designed for a specific purpose. The approach is also beneficial for other similar approaches that may adopt similar solutions.
The rest of the article is described as follows. First, it is a state-of-the-art exploring the initiatives that influenced this work, in Related Work section. Then, the architecture is described, taking into account the different supported functionalities, and a simple use case application introducing the architecture is presented in Architecting Big-BOE section. Lastly, the document explores the performance of different types of analytics carried out on BOE documents to illustrate the performance one may expect from this type of infrastructure, in a small microbenchmark and a large benchmark (see Empirical Evaluation section). Lastly, the article concludes highlighting most related pieces of work, in Conclusions and Future Work section.
Related Work
Related architectures
BIG-BOE also has commonalities with the T-Hoarder software used to detect public transport breakdowns on user microblogging information described in Ref. 12 T-Hoarder is an engine to crawl, process, and display analytics from Twitter. However, T-Hoarder does not have a support like the one included in Hadoop or Spark to process large amounts of data in parallel. The crawler of BIG-BOE has commonalities with T-Hoarder since both operate over Internet data sources. However, data processing runs in parallel in BIG-BOE, whereas in T-Hoarder it does not.
BIG-BOE is related to the lambda architecture 5 that offers a scalable approach to process large amounts of data. As many applications for lambda architectures, BIG-BOE has a crawling phase, which stores all information in write-only file systems, and a batch processing engine, which process these data in parallel. The BIG-BOE architecture uses a canonical technology to store BOE documents: the Hadoop Distributed File System (HDFS) 15 and process data with Spark. 4 BOE documents are published once a day. The BIG-BOE crawler checks if all BOE XML documents for each day are complete or not. In other lambda architectures, data source inject information at a high rate, whereas in BIG-BOE changes happen daily.
Another piece of related work is a scalable and predictable architecture for high-speed, distributed stream processing described in Refs.14,38 The architecture is based on a previous parallel architecture for distributed real-time Java engine described in Ref. 13 BIG-BOE is also inspired in the engine described in Refs.14,38, which offers the possibility of processing millions of messages in parallel. In BIG-BOE the architecture described in Refs.14,38 is enhanced with a map–reduce batch engine useful to process HDFS data offline in a predictable way, extending the testbeds described in Ref. 13 for application with different offline analytics. The main difference between the proposed architecture and previous initiatives13,14,38 is the representation domain. BIG-BOE is designed for efficiency while previous initiatives have been designed to offer time-critical performance.
Lastly, another influential work is Ref. 7 which describes a three-layer architecture to look for large financial datasets. The first element is in charge of data acquisition, which supports crawlers and harvesters. Using a layered approach, BIG-BOE's architecture defines four layers (analytics, services, tools, and resources) to perform a similar functionality for the BOE gazette domain. From the perspective of Ref. 7 , BIG-BOE is of interest because it may be used to improve performance.
There are some industry standards that use common workloads. For the most part, common big data workload remains an alien concept. For instance, Yahooo designed YCSB to be benchmarked for key-value of NoSQL database. Also, in Spark benchmarks are difficult because their workloads are explained rapidly, with each major release and even with some releases. For instance, Spark Stream on reads and writes to files that is difficult to cataloging as end-to-end stream system. Several big data benchmarks sort the speed for 100 TB and 1 PB. From the context of the BIG-BOE results may be interesting to add in YCSB and Spark new cases that come from natural language processing and with the advantage of these types of domains.
Relationship with other MapReduce application
In terms of performance the type of application developed is similar to the grep application that it is included in many big data systems. 42 Internally both systems use this type of facility to select from a large dataset to look for a candidate dataset. In both cases, performance of the plain map–reduce described in the benchmark and the BOE are similar, offering speed in range of MB/s. Only in some scenarios optimized in configuration for the BIG-BOE, the BIG-BOE is able to outperform the performance of the benchmark (see Table 1). While in others the cost of the middleware is much higher than benefits obtained from fusion.
BOE, Boletín Oficial del Estado.
Architecting Big-BOE
The requirements for BIG-BOE comprise two main functionalities. The first is to have a module able to crawl data from web-pages to be later stored in a HDFS filesystem. The second refers to the possibility of processing BOEs stored in the HDFS repository, to look for documents with certain pattern using regular expressions. The architecture that meets these requirements is shown in Figure 1. It is based on several previous layered models defined in the context of industrial architectures 13 and distributed stream processing architectures,14,38 which have been modified to integrate a crawling subsystem and a cluster of map–reduce nodes. In addition, the engine includes a module able to parallelize computations that run on the cluster, by creating multiple small and efficient computations that run on parallel and are able to reduce the inefficiencies of Apache Spark. Previous solutions have not been optimized for a specific domain and potentially, they are more inefficient with the BIG-BOE approach.
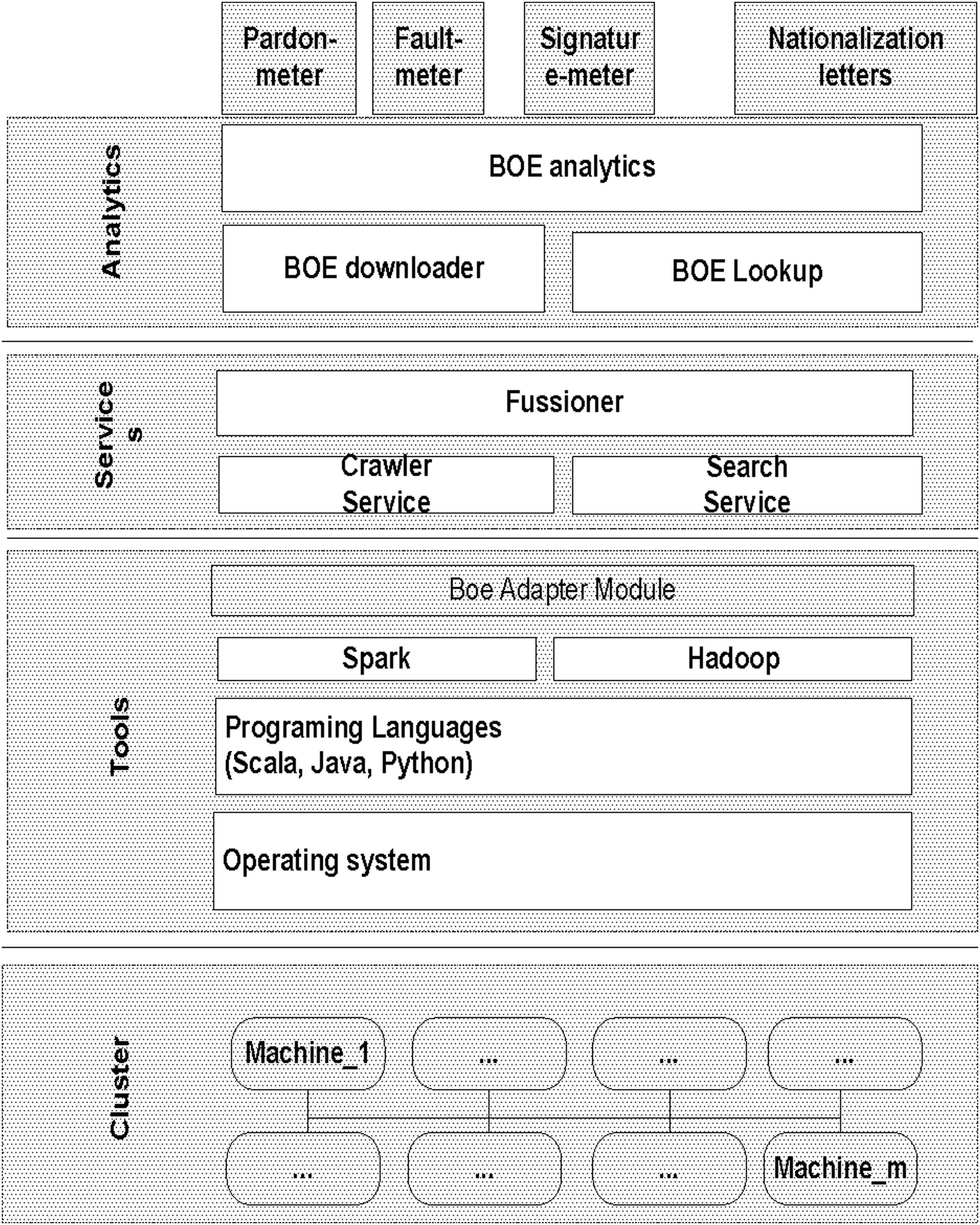
Big-BOE layered architecture and its integration fusion engine able to combine data from different sources. BOE, Boletín Oficial del Estado.
BIG-BOE consists in four main layers:
- At the top of the architecture it is the analytic application. Analytics are composed of different modules in charge of performing different stages of an application in parallel. In the specific case of BIG-BOE, the application has two main modules: one in charge of crawling data from web-pages (to be stored in a local repository), and another in charge of looking for documents with particular patterns. - The Services layer is the second level of the architecture. This layer is in charge of implementing services. In the case of our application, it is possible to define at least two domain services for crawling and searching data on the repository. In addition, there is a fusion model that basically combines data coming from different sources intelligently (i.e., it is able to preprocess data that are used much more efficiently as are merged with other blocks). - Services run on tools. Tools refer to Apache Spark,
4
which provides a low-level engine able to manage popular big data repositories (i.e., Hadoop). The stack uses Spark–Python as a main programming model to implement lookup services that process HDFS-allocated BOE documents. At this level, there is also an adaptor module that splits large applications in smaller ones to gain time. This module is able to speed up the performance of the system. - Resources are at the bottom of the stack. Typically, they refer to a cluster of homogeneous machines on which run analytics, sent by Spark engines. In our particular case, they are custom machines (i.e., BIG-BOE does not use ultra-powerful machines), reducing cluster computational costs. Our evaluation cluster consists of several machines in a laboratory equipped with general purpose nodes.
The crawler (Fig. 2) connects to the BOE web-page to download all documents that belong to a time period (e.g., 1 day and 1 year). These documents are publically available as XML files. In total 1 year of BOE consists of <54,000 XML documents, each one of them referring to one page of the official gazette. After checking that all pages are properly described as XML files, the page is stored in the HDFS 15 storage, in a generic directory (BIG_BOE/data/year/), which is accessed later to process data.

Crawling phase in BIG-BOE. In the case of BOE, data may come from IoT sensors that report to the Internet Storage system that it is typically in the cloud. HDFS, Hadoop Distributed File System; IoT, Internet of things.
The search engine (Fig. 3) is in charge of displaying all BOE documents that contain certain pattern, described as a regular expression. 16 Regular expressions have two key features for big data applications: (1) they are known to be of linear time complexity 19 ; and (2) they can be used to extract pieces of information that match the regular expression from big datasets as illustrated by the case study presented in the article. Regular expressions can be used in scenarios to produce the list of documents that contain the name of a person in BOE or to look for another XML document property. Internally, the process may be divided into three different stages:

Search phase in BIG-BOE.
- The first is in charge of creating the Resilient Distributed Data 4 corresponding to the dataset.
- The second filters XML files which do not match the pattern.
- Lastly, the third performs a summary with the results obtained after the execution (i.e., how many documents have certain property). These data are displayed out up to a maximum of 100 documents to offer a summarized report.
The example included in (Fig. 2) shows the structure of an official publishing system for any time of information, coming from physical systems that publish information periodically, such that it is the price of some products that have maximum prices regulated. A classical example is the price for sugar, milk, and other first necessity items.
Once that has been populated for the crawling system, it is time to use the system; one way is build applications that make the most of the proposed data to create models. In our particular case, the system consists of simple analytics, mainly taken from those proposed by CIVIO service (Fig. 3). In all cases, the applications seem to operate in the same way: they first load data that are cleaned later, to be processed and fissioned later to produce high value information coming from the IoT data.
The following listing shows a simple hello word search that consists of an analytic that counts the number of documents with the BOE word inside (see Listing 1).
Using this type of simple interface for regular expressions, one may carry out simple analytics as having to count the number of documents with certain pattern. However, it can be also useful to perform some other type of complex analytic. For instance, this type of analytic is powerful enough to look up for official pardons, which are published in BOE and weird XML tags.
The Listing 2 shows the internal of the developed application that support the analytic. The analytic returns the list with all different elements for the processing that are used to check if they admit the pattern or not. The algorithm is the following:
1. It accesses data stored in a file that can be local or remotely, hosted in an HDFS system (see line 16). 2. Then, it looks in each BOE document if the web page matches or not the regular expression sent in the command line. 3. For the given dataset, it prints the number of documents that have the defined pattern. 4. They also print a sample list with 200 elements, at most.
Empirical Evaluation
A prototype of the BIG_BOE engine was developed with the following goals:
1. To discover the computational patterns offered by this type of infrastructure for a set of four analytics proposed by the authors. 2. To evaluate the performance one may expect from the use of splitting techniques on the BOE dataset. 3. To be able to compare its performance against other approaches that do not take into account the nature of the data that are to be processed.
Empirical evaluation stack
Using the engine, four types of analytics have been designed (Fig. 4; Table 2), the first looks for official pardons, and the second looks for problems in the XML content delivered by the BOE, a third that looks for royal decrees signed by the king, and a fourth that looks for nationalization letters. All of them are similar in complexity (i.e., there is not 10 times in difference among of an order in time).
Software stack used in the implementation. Configuration parameters are explained in Table 2.
Our current version of BIG-BOE runs on a Spark 1.5 stack supported by a Hadoop 2.4 filesystem on a set of machines interconnected with 2 GB/s optical fiber. On top of the application BIG-BOE has a crawler to download online data from BOE and another application to process these data in parallel using a Spark standalone cluster. The resulting evaluation stack is shown in Figure 5.

Network and machines used to evaluate BIG-BOE. Running in a cluster of 64 machines with another machine servicing and storing data.
All machines in the cluster (64) are similar (each one contributes 4 cores to the cluster and 1024 GB of RAM memory) to process Spark partitions, and correspond to the type of machines one use in a university laboratory. All machines are in the same network segment interconnected with a 2 GB/s optical network; they are common-off-the-shelf machines not specifically tuned for big data analytics.
The open-data dataset consists of all the 2015 BOE XML documents published. This 1-year dataset contains close to 54,000 BOE documents (53,875 documents exactly). BOE documents are relatively small (their sizes are in the 1–10 KB range).
On the dataset four types of analytics were carried out:
1. The first is a pardon-meter (“indultometro”) application in charge of collecting all official pardons (based on Ref.
11
). As the original application, the goal is to obtain a list with the name of all indults published in BOE. This consists in looking for a regular expression for all elements with a particular Spanish header: “Real Decreto.* indult.*” equivalent to “Royal Decree.* pardon.*.” 2. The second refers to an application that looks for BOE issues in the XML translations from the original documents (generated from different official administrations) to the <table> element included in the schema of the BOE. Most times documents are properly translated, but this is not always the case. For those tables which are not properly generated, the engine that generates XML creates a <img/> tag. To measure the amount of documents affected by the anomaly, a new analytic has been developed to look up for pages with this pattern, expressed with a “<img/>” regular expression in BIG-BOE. As a part of the results, the bug has been reported to the BOE assistance service, which has been properly addressed by the service. 3. The third refers to looks for all documents generated for different ministers, which are summarized. The goal is to obtain a list with all documents generated for the life of a certain minister. This type of document is published in the BOE. To summarize this information one may resort to the use of regular expressions and filters for each different type of analytics. 4. The fourth refers to an application that retrieves information from the nationalization letters. These nationalization letters are published in BOE and may be prefiltered using regular expressions to filter those letters of interests. For each document, the system defines a summary with the name of the person that received the letter.
Table 2 summarizes the results obtained after the experiment. Our engine found 65 official pardons and 2397 pages with wrong tags in a total of 53,875 BOE consecutive pages. A summary analysis of the results shows that the performance of the engine changes with the number of BOEs processed by second from 29 to 280 depending on the number of cores used to support the analytic, which translates into 675% speed-ups, due the existence of a big data cluster infrastructure. This number reduces the time required to process a dataset from 31 (with a single core machine) to a minimum of 4 minutes, as the big data infrastructure runs with 32 cores. Those initial 6 × speed-ups may increase up to 45 × if 5 years of BOE are explored concurrently in the cluster. This advantage cannot be achieved in a single machine, which requires a larger amount of time to process the same amount of documents.
Performance meters
All four analytics are close in performance, as it is explored in the rest of this section.
Pardon-meter analytic
Results have found 65 official pardons for the proposed dataset, all of them identified with regular expressed and checked manually to verify results. The evaluation measured the total time required to process all BOEs, which are stored in the HDFS filesystem, accessible through a 2 GBs optical fiber network.
Changing the number of cores that support the architecture, the experiment calculates the total time required to process all documents and output the result, the speed of the system (measured as BOE documents per second), and the efficiency of the engine (dividing speed by the number of cores) (see Fig. 6). Our empirical results for the pardon-meter analytic showed that with 16 cores the engine is able to offer acceptable efficiency.
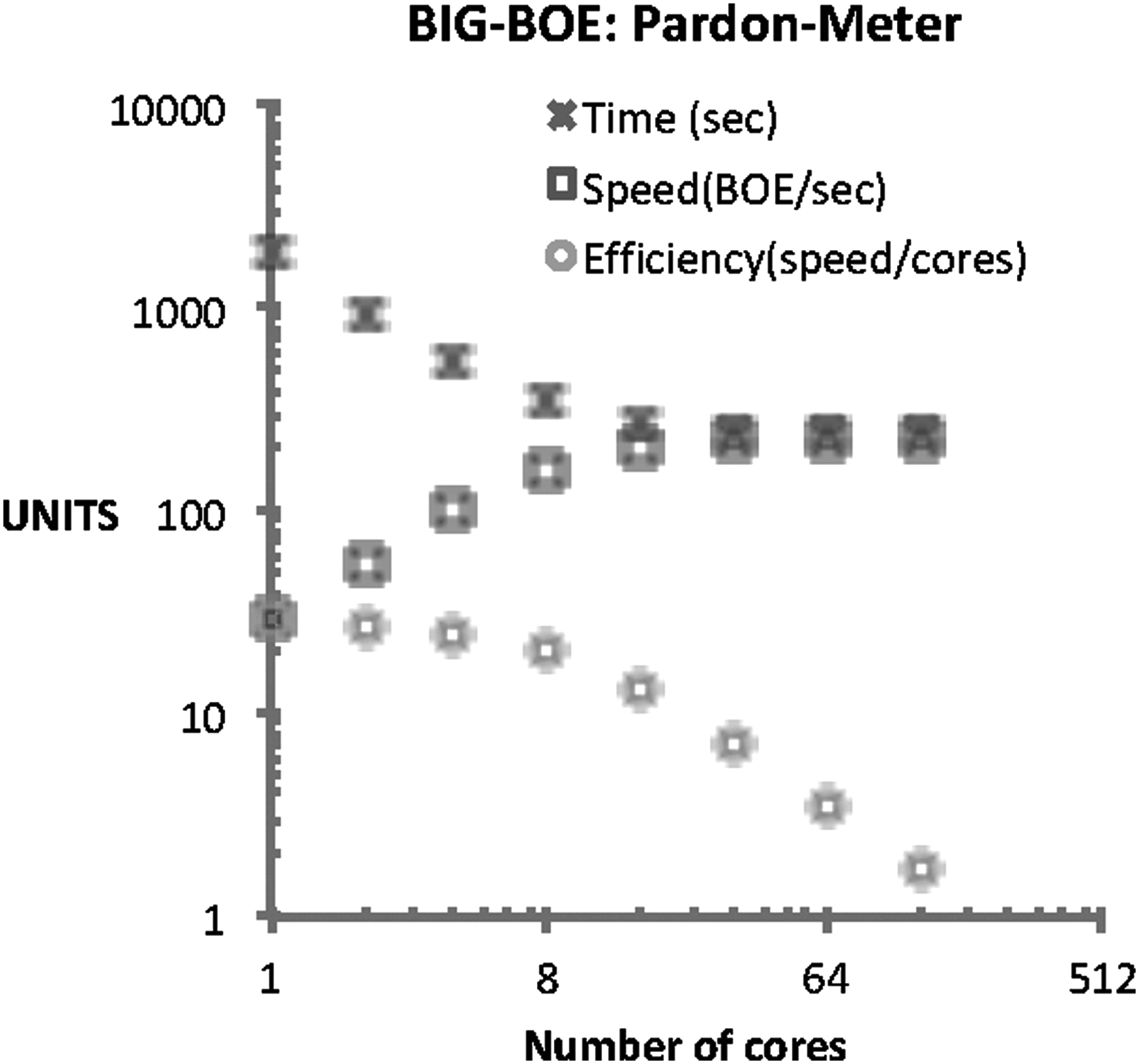
Pardon-Meter results. Network and machines used to evaluate BIG-BOE. Running in a cluster of 64 machines with another machine servicing and storing data.
Over 16 cores, the system increases performance marginally requiring also a huge number of cores. More in detail:
- Experiments show how the time required processing our 1-year BOE dataset decreases (from 31 to 4 minutes) as the number of cores available to support the system increases. However, over 16 cores (which refer to 4.4 minutes), the system is not able to speed up the search as it does with <16 cores. - The speed increases as the number of cores does (from a minimum of 29 to a maximum of 224 BOEs/s). With 16 cores, the maximum speed reaches 90% of its maximum speed (i.e., 200). Again, from 16 cores increases in speed are also possible at higher computational costs. - Lastly, efficiency is always decreasing function (starting in 29 BOEs/s per core and decreasing to 1.75 for 128 cores). Likewise, efficiency per core degrades to less than half its maximum with 16 cores.
Empty image analytic results
Another type of application refers to the number of BOE documents that have associated to the <img/> tag. In our dataset, BIG-BOE identified that 4.5% of the documents have this anomaly, which has been properly reported to the BOE services. The problem in XML generation is due to source documents, which are not properly formatted for the tool-chain. However, most failures do not affect most important sections (Section I: General Provisions) and have been reduced over the years.
The evaluation results (Fig. 7) show how the processing time reduces with the number of cores from 34 to 3.2 minutes, as the number of cores increases. They also show that speed ranges are higher than in for pardon-meter analytic (in the 37–280 range). This increase of 33% in performance is mainly due to the use of a simple regular expression. Efficiency for fault detector ranges from 37.5 to 2.9 BOEs/s per core, which is also higher for the previous analytic.
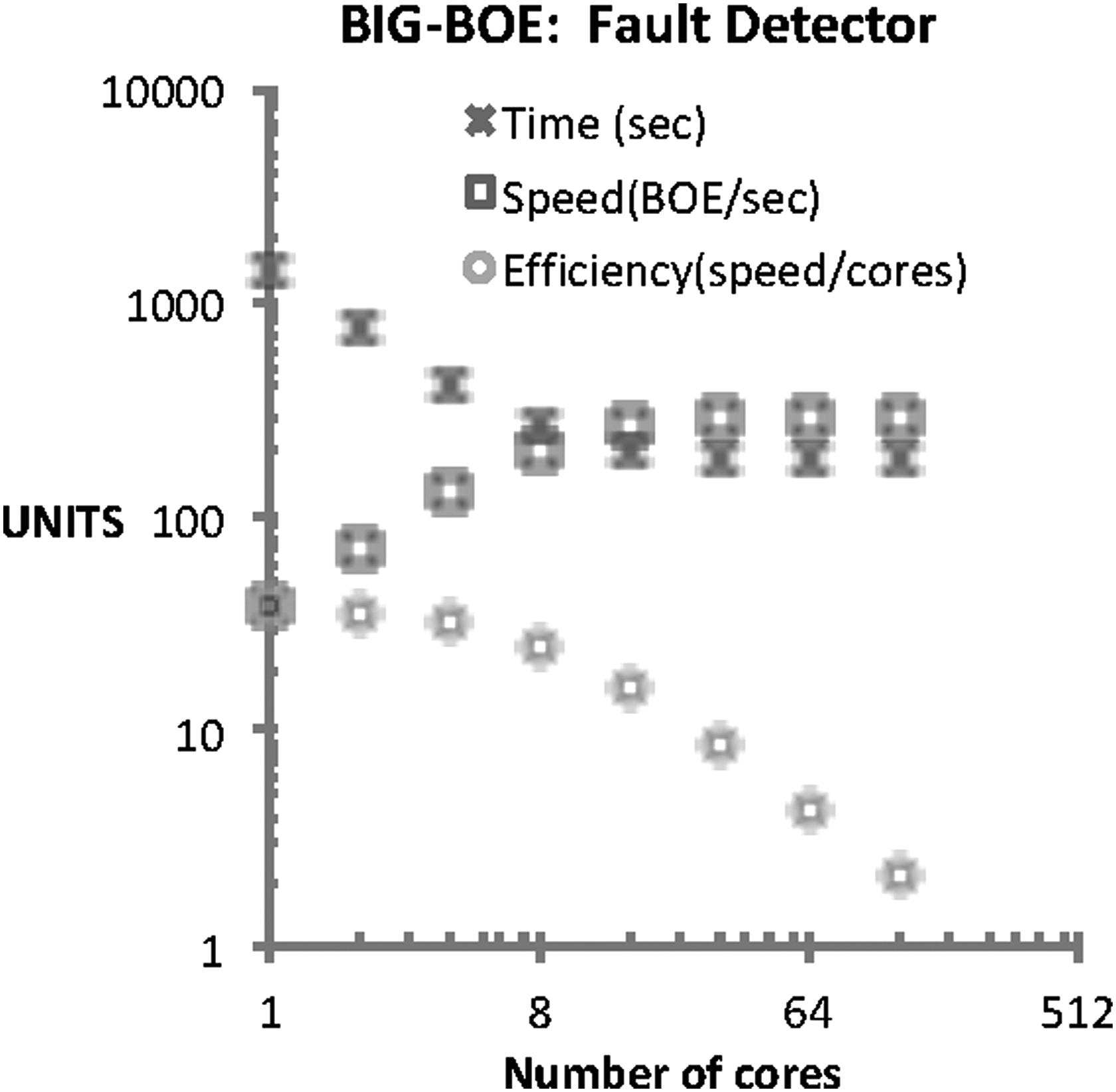
Fault detector results. Network and machines used to evaluate BIG-BOE. Running in a cluster of 64 machines with another machine servicing and storing data.
Signature analytic results
The signature application produces a report with information on the amount of documents, which refer to real decrees signed by the king, who has a specific XML tag: <firmado_el_rey>, that may be easily processed by the infrastructure. Then those documents are classified according to the different roles of the ministers of the cabinet. For the reference dataset, the application generates the name of the minister with more issued royal decrees. In this case, the performance is similar to the previous cases and the dataset generated includes 1273 documents signed by the king, in cooperation with his ministers. Results are shown in Figure 8.
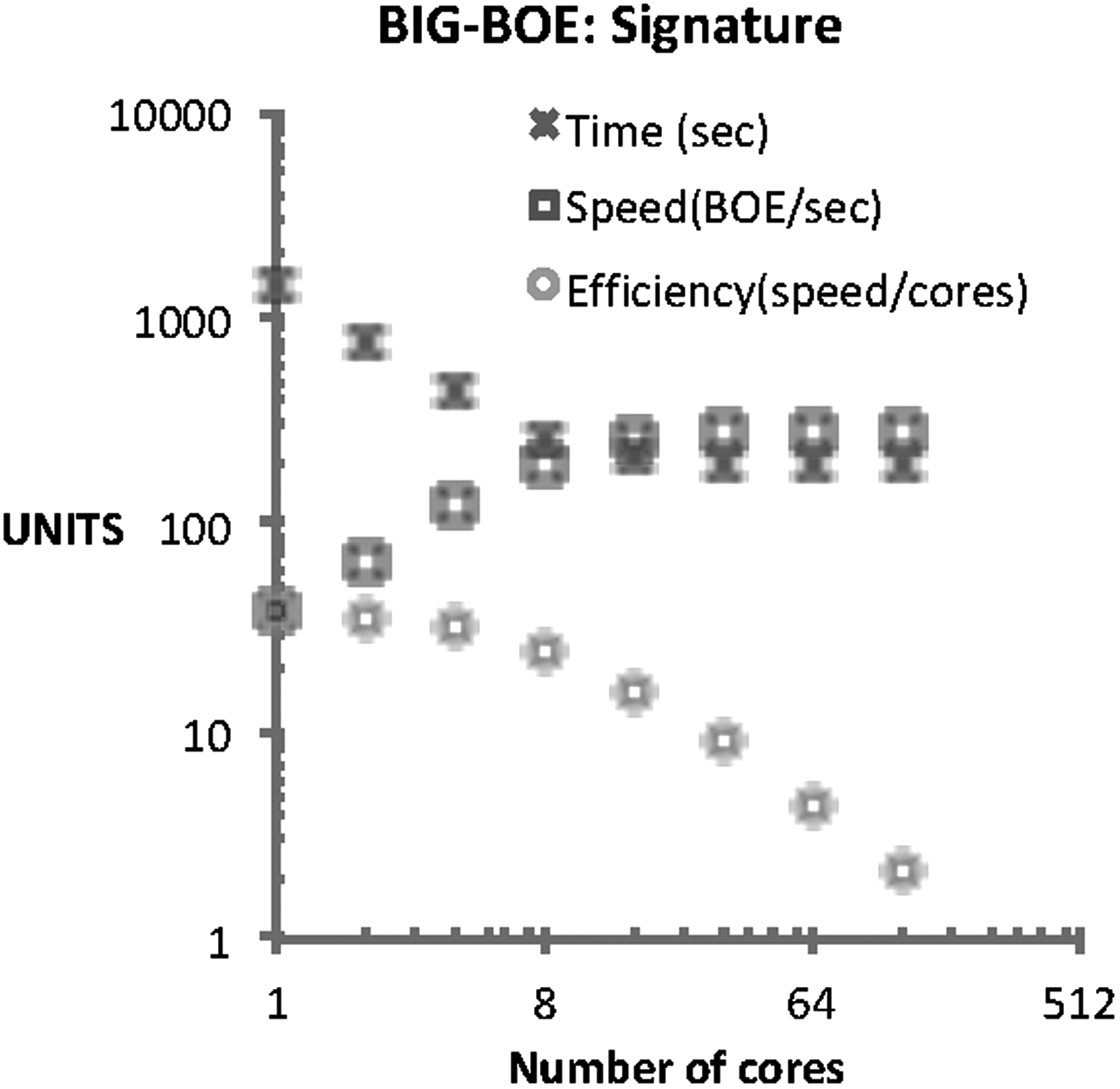
Signature results. Network and machines used to evaluate BIG-BOE. Running in a cluster of 64 machines with another machine servicing and storing data.
Nationalization letters results
The last experiment refers to the nationalization letters, which are also published in BOE. Like in previous cases, they can be filtered using regular expressions to produce an output. The final report generated includes the name of the person, which is extracted from the text. The 2015 year, produced 27 nationalization letters, each of them published in BOE and detected for the application. In this case, the performance measured in BOEs/s is better than in the case of the signature case, because the application does not require a large computational stage. Results are graphically shown in Figure 9.
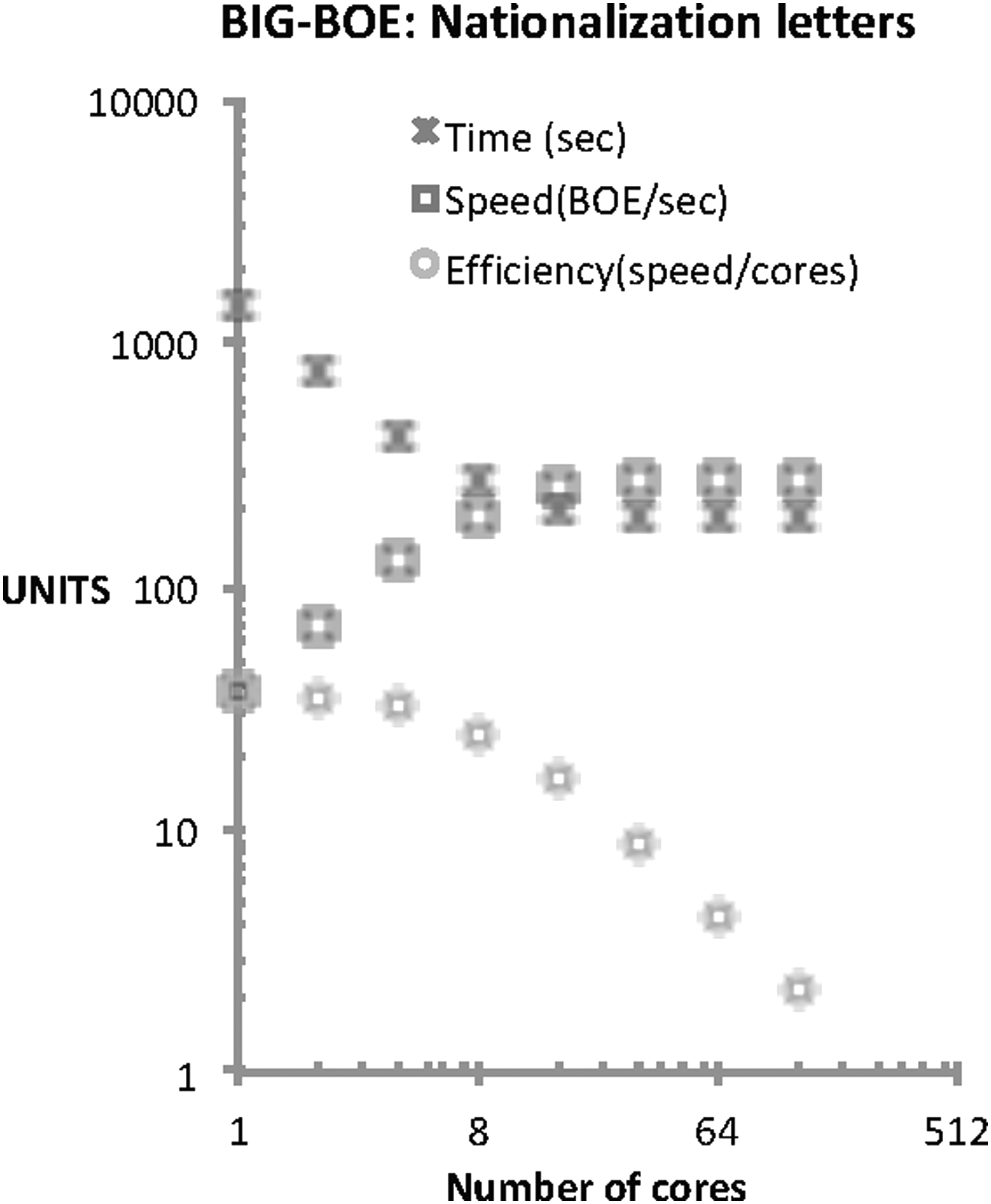
Nationalization letters. Network and machines used to evaluate BIG-BOE. Running in a cluster of 64 machines with another machine servicing and storing data.
Scalable performance in Big-BOE
Performance was optimized to adapt BIG-BOE to the characteristics of the environment. Extending the initial scenario from 5 to 256 years and the number of machines connected, the curve of performance was obtained for all these cases with a number of machines ranging from 1 to 64 machines (showed in the legend in Fig. 8). Using these data, the basic performance curve was obtained showing the efficiency of the system. The efficiency is measured as the ratio among the speed of the system (where machines contribute the same to solve the problem) divided by the number of machines used to support the system. Then, inefficiency is calculated as:
Inefficiency is of special interest in cases where the experiment is interested in emphasizing the bad results. Results (Fig. 9) for the basic configuration shows that inefficiency increases with the number of machines. For more than 4 machines, performance decreases to <52% of the available CPU time to <1% with 64 machines. So to increase performance, the application was split into different clusters, each one of them with four machines to avoid this problem. In addition, the application was split into eight segments, which run in parallel increasing I/O performance.
Results for a configuration of four tasks (Fig. 10) show that the inefficiency decreases to a negative number (meaning that the result improves the ideal scenario). Empirical numbers are close to −300% of the available time, meaning improvements in the response time of the application in × 3. Results also show how the efficiency also experiences an improvement of × 7 in comparison with the ideal case due to the optimization designed for the engine.
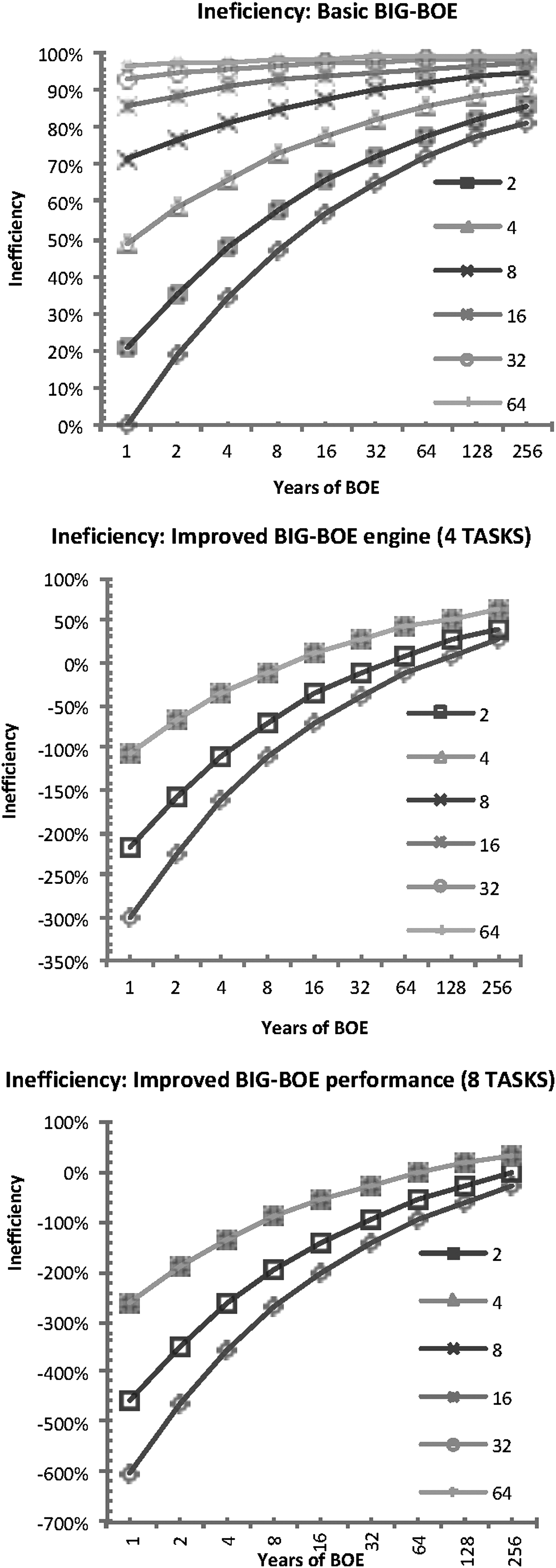
Different inefficiency patterns for the basic configuration (plain configuration without any facilities) and two optimized scenarios with a mini-cluster configuration of four machines and 4 and 8 concurrent BIG-BOE engines. Improvements are in the range of several orders in magnitude, as compared with the default engine. Network and machines used to evaluate BIG-BOE. Running in a cluster of 64 machines with another machine servicing and storing data.
Although, they have been checked against the proposed dataset and analytics, there are many other applications that may benefit from the proposed engine in a proper way, using an efficient configuration of the cluster.
Fusion
To join data coming from different sources, we use direct fusioners that are able to merge data and results in a proper way (Fig. 11). The idea is these types of applications are that the fustiness receives data from different sources, which are part of sparse block of data that are lately reported and stored to be processed. Figure 12 offers performance results and the reduction on performance that can be computed as part of this mechanism. In comparison with Figure 10, about 1/16 and 1/10 of the total reduction is experienced due to inefficiency. Those results seem useful to other similar systems, because the type of analytics in all cases experienced are similar.
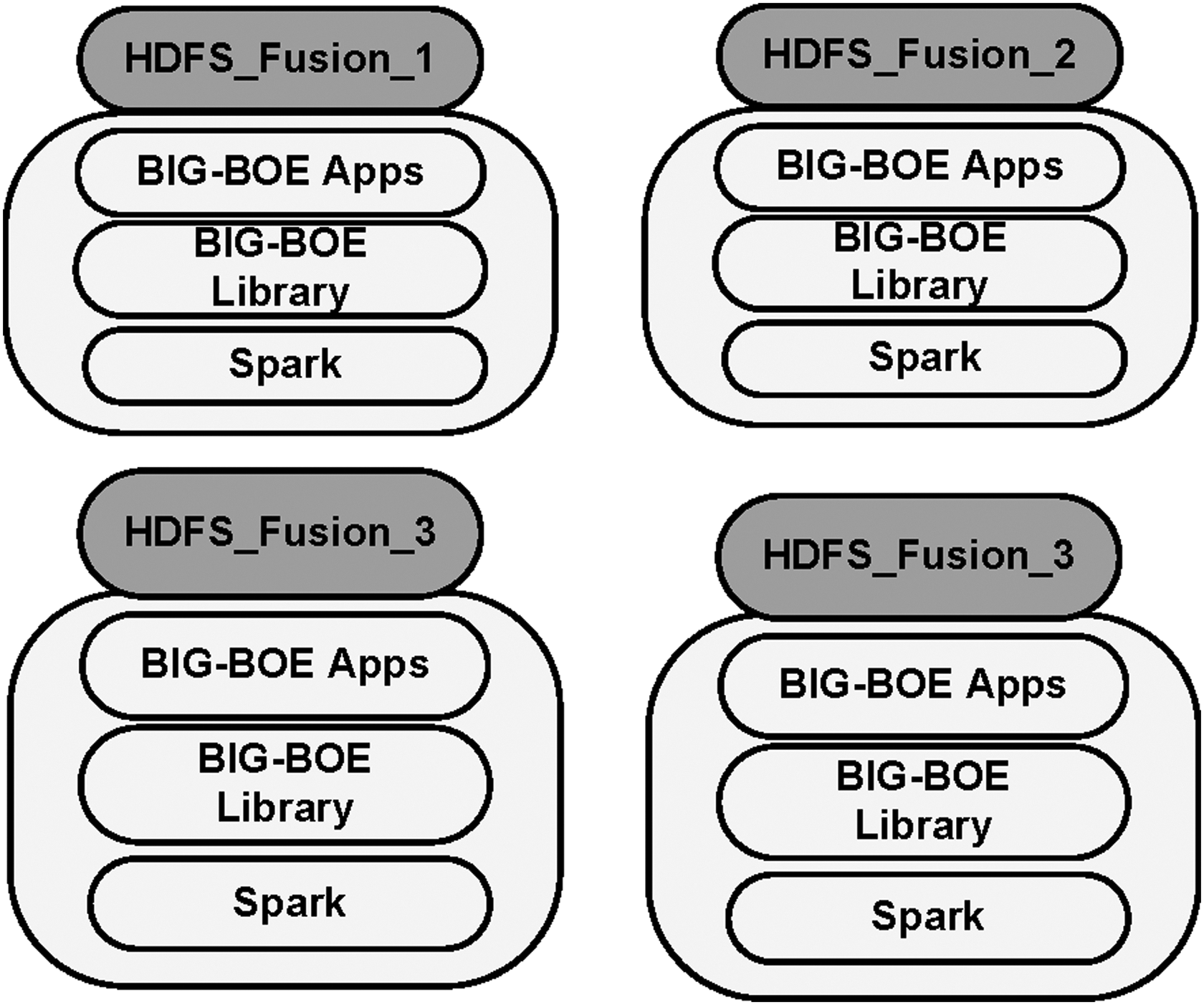
Clusterized approach and the use of fusion to properly combine the information of different nodes. Logically, each fusioner has a directory associated, where data are temporally stored.
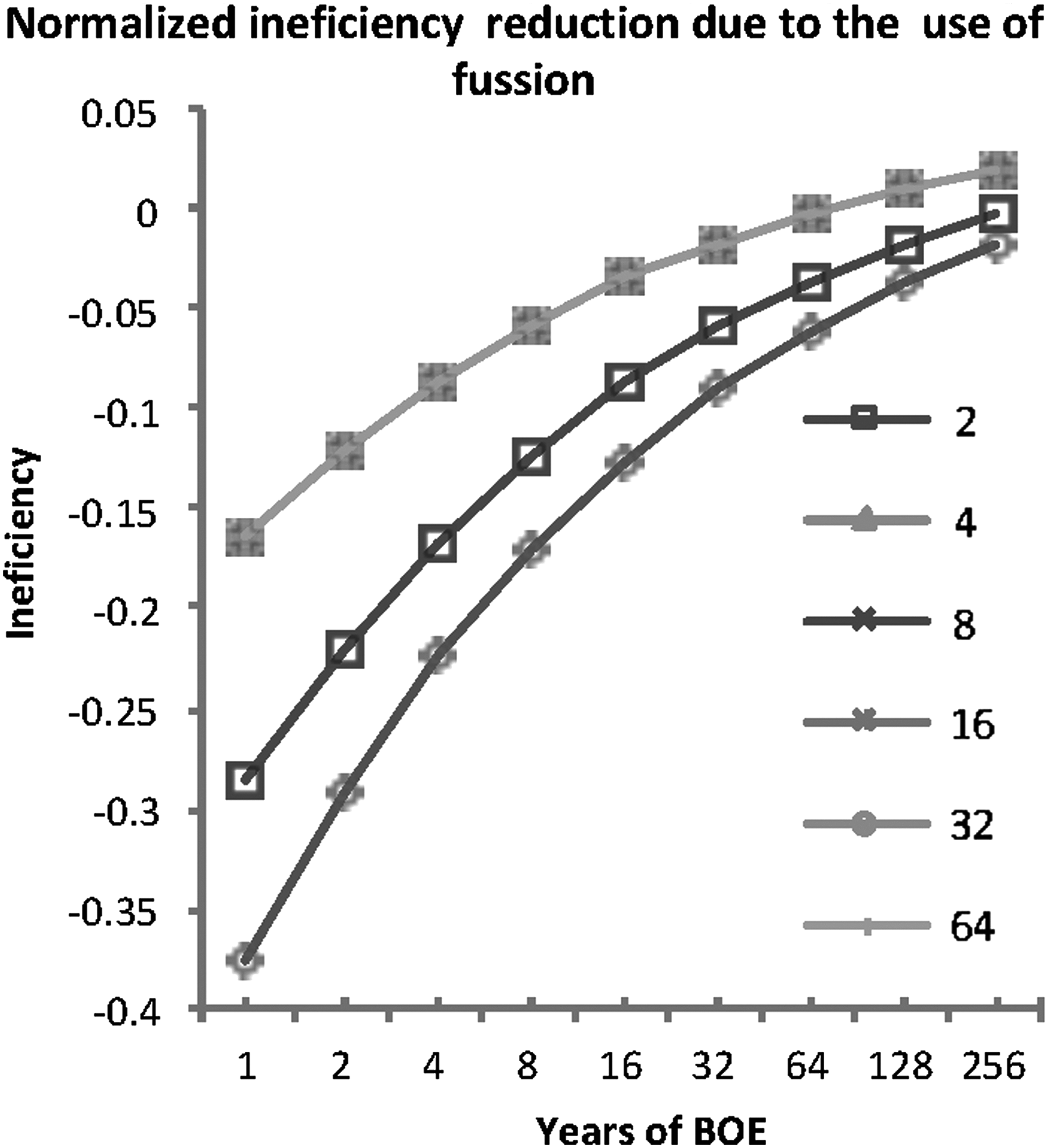
Contribution on the reduction of the inefficiency caused for the use of the fusion technique.
Comparison against other similar techniques
BIG-BOE was compared against other techniques designed in the context of Refs.13,14 that offer plain engines that do not offer the hierarchical model proposed in this article. The results show that the use of a technique such as the one described may improve the response time, in terms of efficiency in at least 30% of the total time. This improvement in overhead that it comes with is mainly due to the serialization costs and the overhead associated with the use of a real-time engine. The improvement increases with the number of tasks that have to be processed in parallel (Fig. 12). Probably those results also show that those applications may be defined in Refs.14,28 would fully be benefited from the use of the typical model included in the engine to process data.
Conclusions and Future Work
Open data and IoT create a chance for automatic data processing to extract relevant information using publically available information sources. It also opens the door to process these data with big data infrastructure to perform parallel analytics on data to speed up operations. In this context, BIG-BOE-BOE was introduced as an architecture and case study for processing open datasets with big data technology. BIG-BOE enables us to process different BOE datasets in parallel using common off-the-shelf big data technology. Furthermore, the empirical evidence enabled us to reduce the analytic processing times several times, a relative small dataset (1 year), which are enlarged as the data increases to several years. These time reductions are relevant for analytics that have to meet deadlines or for systems interested in using idle infrastructure to execute parallel computations with certain temporal constraints.
In relationship with BIG-BOE, our ongoing work splits into two main research lines. The first relies on a technological plane and consists of the use of cloud computing services via their integration in our BIG-BOE stack. 17 Our main goal is to measure the technological overhead caused by virtualization on the cost of different BOE analytics, looking for increased scalability. The second research line is extending the support of BIG-BOE fusion to other official gazettes, from other countries and regions of Europe.
Footnotes
Acknowledgments
This work has been partially supported by “Distributed Java Infrastructure for Real-Time Big-data” (Grant No. CAS14/00118). It has been also partially funded by eMadrid (Grant No. S2013/ICE-2715), HERMES-SMARTDRIVER (Grant No. TIN2013-46801-C4-2-R), and AUDACity (Grant No. TIN2016-77158-C4-1-R).
Author Disclosure Statement
No competing financial interests exist.