
Abstract
Abstract
MapReduce (MR) computing paradigm and its open source implementation Hadoop have become a de facto standard to process big data in a distributed environment. Initially, the Hadoop system was homogeneous in three significant aspects, namely, user, workload, and cluster (hardware). However, with growing variety of MR jobs and inclusion of different configurations of nodes in the existing cluster, heterogeneity has become an essential part of Hadoop systems. The heterogeneity factors adversely affect the performance of a Hadoop scheduler and limit the overall throughput of the system. To overcome this problem, various heterogeneous Hadoop schedulers have been proposed in the literature. Existing survey works in this area mostly cover homogeneous schedulers and classify them on the basis of quality of service parameters they optimize. Hence, there is a need to study the heterogeneous Hadoop schedulers on the basis of various heterogeneity factors considered by them. In this survey article, we first discuss different heterogeneity factors that typically exist in a Hadoop system and then explore various challenges that arise while designing the schedulers in the presence of such heterogeneity. Afterward, we present the comparative study of heterogeneous scheduling algorithms available in the literature and classify them by the previously said heterogeneity factors. Lastly, we investigate different methods and environment used for evaluation of discussed Hadoop schedulers.
Introduction
Since the past few years, there has been an enormous growth in the rate of data generation from various sources ranging from scientific world to business enterprises. For instance, particle accelerators in high-performance computational physics generate a massive amount of data every hour for scientists. Furthermore, in the field of business analytics, enterprises are analyzing petabytes of data each day to make an appropriate business decision. As of 2013, the total amount of data in the world has been estimated to be 4.4 zettabytes that are expected to rise precipitously to 44 zettabytes by 2020. 1 And, according to IBM marketing cloud study, 90% of data were created since 2016. 2
This huge volume of data generated in recent years has posed many challenges for researchers to design efficient systems to process it, especially, in a distributed environment. A seminal article by Ghemawat and colleagues 3 triggered the research in the thirst area of distributed data processing. The authors explained two new technologies, namely, Google File System (GFS) and MapReduce (MR) computing paradigm. Both of these technologies have been used in the Google's data center to generate web indexes for search engine application. In the same line, Apache Software Foundation has created its own open source version of MR framework, known as Hadoop MapReduce, widely used by many organizations at their data centers. Besides Hadoop MR, various other data processing frameworks are also available, for example, Google Pragel, 4 Apache Giraph, 5 Spark,6,7 Storm, 8 Samza, 9 and Microsoft Dryad. 10 Each framework is entirely based on different computing paradigms and further suitable for a specific type of application. Among various aforementioned data processing frameworks, Hadoop MR is the most prevalent. 11 Initially, the use of Hadoop was limited to periodic execution of large batch jobs at various data centers. However, with the growing development of the Hadoop framework makes it useful for graph processing and machine learning application too.
Essentially, Hadoop is an ecosystem where MR can be seen as one of the core components. Other components include Hadoop Distributed File System (HDFS), 12 Pig, 13 Hive, 14 Mahout, 15 and ZooKeeper. 16 In recent years, the Hadoop framework has undergone various modifications and improvements. Four versions of Hadoop have been released since inception, namely, Hadoop 0.x, Hadoop 1.x, Hadoop 2.x, and more recently Hadoop 3.x. Here, Hadoop 0.x and Hadoop 1.x use slot-based resource management system, whereas Hadoop 2.x and Hadoop 3.x employ a fine-grained container-based resource management system known as YARN (Yet Another Resource Negotiator).
Scheduling in Hadoop—The performance of a Hadoop framework is greatly influenced by its scheduler module. The MR scheduler has to cater various quality of service (QoS) requirements of two stakeholders of Hadoop system, namely, Hadoop user and Hadoop administrator. The QoS requirements that need to be improved through scheduling may include makespan, response time, availability, throughput, energy efficiency, security, and resource utilization. In a shared environment, the scheduler first selects a user among many whose job needs to be executed. Usually, a user has multiple jobs with different characteristics in its JobQueue, so the next step is to select a job for processing. Once a job is selected, its map, reduce, and straggler tasks are scheduled next for execution. Here, different scheduling algorithms can be used at each step depending on the objective to be achieved.
Theoretically, MR task scheduling is a strongly NP-hard problem for optimizing various QoS parameter under different system model assumptions and constraints.17–20 In July 2008, the Hadoop scheduler was refactored from JobTracker (JT) logic that made it a pluggable component and ultimately triggered the innovation in this domain. 21 More precisely, the pluggable component facilitates a user to design or customize its own scheduler, thereby, improving the overall performance in terms of responsiveness, throughput, and job completion within a given time constraint. Background of Hadoop and MR scheduling are discussed in Background and Scheduling in Hadoop MR section in detail.
Scheduling in heterogeneous environment—The applicability of Hadoop framework has now shifted from long batch jobs to interactive ad hoc queries, graph processing, machine learning applications, etc. This leads to create a set of heterogeneous users and workload, competing for the cluster resources. Moreover, induction of different configurations of machines into existing Hadoop cluster leads to creating cluster/hardware * heterogeneity. Therefore, three main heterogeneity factors, namely, user, workload, and cluster (hardware) exists in a Hadoop system (see Heterogeneous Hadoop Environment and Scheduling Challenges section for details). The occurrence of any of these heterogeneity degrades the performance of Hadoop schedulers as initially identified by Zaharia et al. 22 The authors considered a limited form of hardware heterogeneity and showed that it adversely affects the straggler detection by the scheduler.
The standard Hadoop distribution (released by Apache) addresses the issue of only user heterogeneity through a number of in-built schedulers, for example, FAIR, Delay scheduler, Dominant Resource Fairness (DRF), and Capacity Scheduler (CS). However, workload and cluster heterogeneity are not considered by any of them in scheduling decisions. † It is worth mentioning here that the YARN cluster manager in Hadoop 2.x and 3.x facilitates the allocation of the exact amount of resources required by different MR jobs that have heterogeneous resource demand. 23 Thus, only YARN-based Hadoop implicitly handles the issues of workload heterogeneity up to some extent. However, particularly the in-built scheduler of YARN does not explicitly consider workload heterogeneity while making scheduling decisions like older Hadoop versions. For example, Hadoop (all versions) does not avoid running jobs competing against the same resource (e.g., Central Processing Unit [CPU], disks) on the same machine. Ideally, in case of heterogeneous workload, the scheduler should allocate the resources of a machine to the jobs that have orthogonal resource requirement. The survey article classifies the heterogeneous Hadoop schedulers on the basis of the type of heterogeneity addressed.
Related work—A handful of literature survey work24–31 has attempted to study various MR scheduling algorithms. Authors in Refs.24,25 studied some MR scheduling algorithms on the basis of different QoS parameters such as data locality, fairness, and deadline adherence and presented a comparative analysis. However, their study is limited to only a few algorithms. In contrast, authors in Refs.26–30 presented their study without any classification. Among these previous works, Tiwari et al. 31 presented the most comprehensive survey of MR schedulers in which various MR schedulers have been analyzed on the basis of a proposed multidimensional classification framework. Nevertheless, the existing surveys are somewhat comprehensive, the issue of heterogeneity is still unaddressed. Their classification is mostly based on the QoS parameters being optimized. Hence, the need is to study the Hadoop MR schedulers based on various heterogeneity factors addressed by them. Our aim is to study various heterogeneous Hadoop schedulers and analyze them on various parameters.
The rest of the survey article is organized as follows. Background and Scheduling in Hadoop MR section presents the background knowledge of MR programming paradigm and scheduling issues, especially, in its open source implementation, that is, Hadoop. Various heterogeneity factors of a Hadoop system and scheduling challenges in the heterogeneous environment are explained in Heterogeneous Hadoop Environment and Scheduling Challenges section to prepare the context of subsequent analysis being presented. Study of Scheduling Algorithms in Heterogeneous Environment section analyzes various heterogeneous scheduling schemes classified on the basis of the heterogeneity factor being considered while making scheduling decisions. Lastly, Conclusion section concludes the article.
Background and Scheduling in Hadoop MR
In this section, we briefly describe the essence of the MR programming paradigm and its most popular open source implementation Hadoop (see Refs.32–37 for other MR implementations). Furthermore, we discuss the various MR scheduling entities and the role of schedulers to enhance the QoS performance of a Hadoop system. In the end, we outline major differences between scheduling in slot-based and container (YARN)-based Hadoop. An advanced reader may skip this section and proceed to next section.
MR programming paradigm and its Hadoop implementation
The MR programming paradigm,
3
originally developed at Google, is an algorithmic design technique like divide and conquer. It is well suited for a wide variety of structured, semistructured, and unstructured data processing applications. The Map and Reduce functions in classical functional programming (e.g., Lisp) inspire the basic design idea of Google's MR. An MR computation is defined as a collection of user-defined Map and Reduce functions, which expect the input data to be a set of key–value pair
In the literature, various implementations of MR programming paradigm are available. The right decision depends upon the application and environment. Google implemented this programming methodology for large clusters of commodity PCs (i.e., distributed memory multicomputer architecture) connected with switched ethernet. 3 In its master-slave architecture, data are stored in the GFS.3,38 Other than Google MR, various frameworks that implement Google's MR methodology in their own way are Apache Hadoop, QtConcurrent, 32 Phoenix, 33 Skynet, 37 Twister, 34 Disco, 35 Misco, 36 etc., specifically for either multiprocessor or multicomputer architecture. Among these, Hadoop is the most widely used implementation. A key benefit of Hadoop is its automatic failure handling feature, thus, hiding the complexity of fault tolerance from a programmer. In case a node crashes, Hadoop reruns its tasks on a different machine.
Hadoop MR implementation
As mentioned, Hadoop is a dominant open-source implementation of MR methodology targeted for clusters of commodity hardware connected in master-slave architecture. The latest version of Hadoop ecosystem 39 has the following four core components: Hadoop Common, HDFS, Hadoop YARN, and Hadoop MapReduce. Hadoop Common provides functional infrastructure for Hadoop framework, whereas HDFS is an open-source implementation of GFS and provides scalable distributed file system support. Hadoop YARN is a novel general framework for job scheduling and cluster resource management. YARN can serve as a runtime environment for MR as well as for other big data processing frameworks. 40 And finally, the Hadoop MR provides runtime support library to execute MR jobs written in JAVA.
The two main versions of Hadoop framework, namely, Hadoop 1.x and Hadoop 2.x, are being used extensively in huge data centers. Both differ in the way computing resources (CPU, memory, and I/O resources) are managed and allocated to jobs. In Hadoop 1.x, a fixed portion of node's overall capacity is presented to the job for allocation in the form of slots. Precisely, a slot is an abstraction of all individual resources available in a node. Moreover, the resource manager (which also performs job scheduling) and MR libraries are provided as a single package in Hadoop 1.x. The two main daemons, JT and TaskTracker (TT), are collectively responsible for resource management, job scheduling, and task progress monitoring.
To improve the performance and scalability, later version of Hadoop framework, that is, Hadoop 2.x, introduced the YARN generic cluster manager that separates resource management functionality and MR library into two different modules and facilitates the Hadoop system for a variety of distributed data processing framework other than MR, for example, Spark and MPI. YARN introduced the concept of a container, a logical collection of multiple resources available in a node. Two main daemons in Hadoop 2.x, namely, ResourceManager (RM) and NodeManager (NM), are responsible for cluster management and scheduling. Task management and monitoring are handled by each job's individual ApplicationManager (AM), which facilitates the scalability of Hadoop systems. 40 It is noted that two more versions of Hadoop framework are available, namely, Hadoop 0.x and Hadoop 3.x, which are based on slots and containers (YARN), respectively.
Scheduling in Hadoop MR
A small submodule within the JT/RM logic known as Scheduler performs the scheduling in Hadoop. It plays an important role in the overall performance of Hadoop and schedules three main entities, namely, users, jobs, and map/reduce tasks. The process of scheduling is to allocate computing resources (either in the form of slots or containers) to various scheduling entities. The MR scheduler is usually triggered by two events: (i) whenever a new job is submitted to job queue of the system and (ii) whenever JT receives a heartbeat message from a worker node. The heartbeat messages are periodically sent by worker nodes to inform the number of free slots it has.
Whenever a scheduler is triggered, it first selects a user for scheduling followed by job selection from a list of jobs submitted by that particular user. Afterward, the scheduler allocates resources to map or reduce tasks of the selected job. Depending upon the Hadoop version, a resource may be coarse grained or fine grained. On the basis of the scheduled entity, an MR scheduler may be classified as level 1 (user level), level 2 (job level), and level 3 (task level). Different scheduling algorithms can be used at each level based on the objectives to be achieved. It is noted that a single scheduling algorithm may or may not work at more than one level, for example, FAIR and CS work at the user and job level, whereas FIFO works only at job level in the scheduling hierarchy.
An MR scheduler caters various QoS requirements of two main stakeholders, Hadoop user and administrator, in a Hadoop system. Both stakeholders have their own quality requirements. For instance, a Hadoop administrator is concerned about throughput and resource utilization of a system, whereas an end user (customer, domain/business analyst, or auditor) expects good response time, service level agreement (SLA) adherence, minimum completion time, etc. for their jobs. Usually, an MR scheduling problem is mathematically formulated as optimization problem, for example, Linear Programming (LP) in which QoS requirements are either maximized or minimized. 17 Scheduling in Hadoop is a complex task and shown to be NP-hard in nature 20 even in the restricted environment where all nodes are homogeneous and all resource requirements of tasks are similar.
From the mentioned discussion, we may precisely conclude that MR scheduler allocates computing resources in the form of slots/containers to various users, jobs, and map/reduce tasks to achieve various QoS objectives.
Scheduling in slot-based versus container-based Hadoop
The scheduling in slot-based Hadoop framework (i.e., Hadoop 0.x and Hadoop 1.x) differs from the container-based framework (i.e., Hadoop 2.x and Hadoop 3.x) due to different resource management systems. In slot-based Hadoop, two daemons, namely, JT and TT, are responsible for resource management, entity scheduling, and progress monitoring of tasks. The JT is a server daemon that is mainly responsible for resource management and scheduling. In contrast, the TT, a client daemon, is responsible for task's management and progress monitoring. The node that hosts JT daemons is called server node, whereas nodes that run TT daemons are called workers. In slot-based Hadoop, a submodule called scheduler within the logic of JT handles scheduling of various entities.
A logical abstraction called slot collectively represents various computing resources in a node, that is, CPU, memory, disk, and network bandwidth. In other words, a slot is a fixed fraction of a computing node in the cluster. 41 The scheduler allocates computing slots (i.e., map and reduce slots) to various scheduling entities, which are decided by Hadoop system administrator and is usually set equal to the number of computing cores in a node. In each node, there are separate slots for map and reduce tasks, that is, a map slot cannot be used for executing a reduce task and vice versa.
Hadoop 2.x and Hadoop 3.x introduce a general purpose cluster manager called YARN like Mesos. 42 Google Brog, 43 Omega, 44 and Sparrow 45 are some more examples of generic cluster managers. YARN manages computing resource, schedules entities, and monitors the progress of tracks. To facilitate different services, it employs two daemons, namely, RM and NM, similar to JT and TT of slot-based Hadoop framework, respectively. RM does not perform job progress monitoring and management, rather it is handled by AM. The motive is to increase the scalability of Hadoop cluster up to 10,000 nodes. The most important feature that YARN introduces is the fine-grained resource management and the concept of containers. A container can be thought of as a complete machine with multiple resources, for example, CPU, memory, disk, and network bandwidth. Currently, only CPU and memory are supported by standard Hadoop distribution. The size of containers, that is, a total number of virtual CPUs and memory size allocated to a task can be set exactly according to task's demand unlike map/reduce slots.
Heterogeneous Hadoop Environment and Scheduling Challenges
A Hadoop system can be described by three factors, namely, user, workload, and compute cluster.46,47 As the number of users, machines, and jobs are increasing day by day, all three factors have become heterogeneous, which turn out to be a concern while designing schedulers. This section first discusses various heterogeneity factors in Hadoop that affects the performance of a system. Later, we describe various challenges to design Hadoop scheduler in the presence of such heterogeneity factor.
Heterogeneity factors in Hadoop
A number of users mostly share a single large Hadoop cluster, where each user has a different priority and resource demand to execute his or her jobs, thus leading to user heterogeneity in the system. Furthermore, each user has different types of jobs (e.g., CPU- or I/O intensive) to be executed on the large cluster that causes workload heterogeneity. Furthermore, given the large size of clusters dedicated to data-intensive applications, it is not always possible or even desirable to have a cluster with a single type of machine. Over time, machines with different configurations are inducted into the existing Hadoop cluster, ultimately causing hardware heterogeneity. Through the literature survey, a heterogeneous Hadoop system can be defined on the basis of the following factors (Fig. 1).
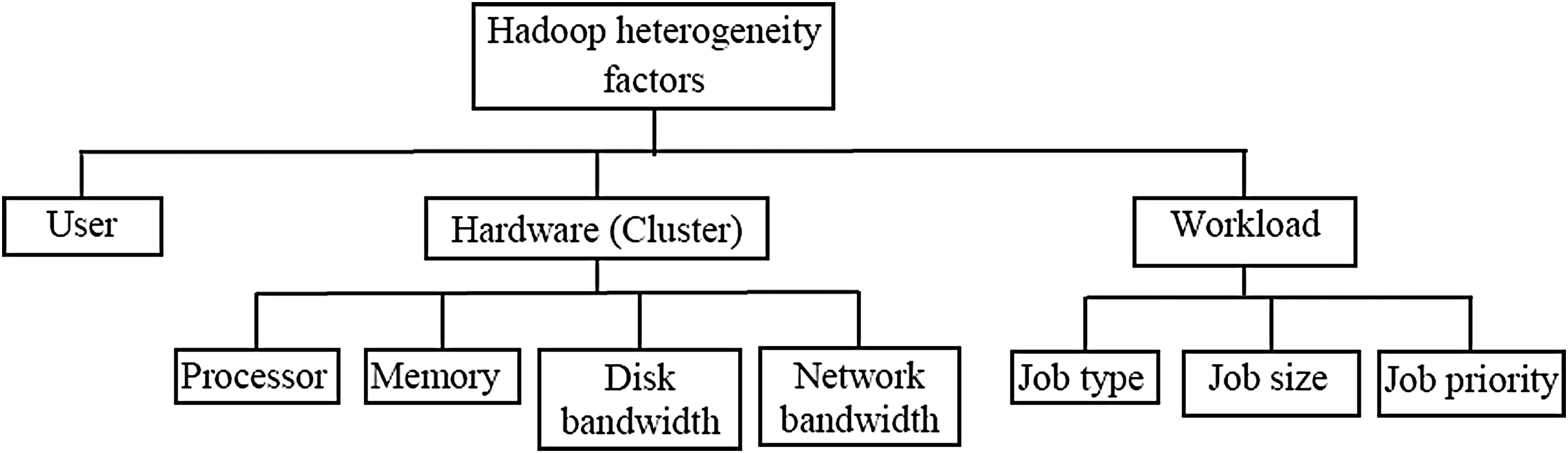
Heterogeneous Hadoop factors.
A. User: Initially, Hadoop was designed to optimize the performance of batch jobs such as generating indexes from web crawl for search engine application. However, its applicability to a wide variety of real-time problems leads to growing demand for sharing Hadoop clusters among multiple users. 48 Hadoop may assign a priority and a minimum share of cluster resources to each user based on a particular policy (e.g., the pricing policy in Sandholm and Lai 49 ). Moreover, an ad hoc user usually needs the quick response to an interactive query, whereas a batch job user has no time constraint. Different users with different priority, varying deadline constraint, and minimum share requirement of resources lead to user heterogeneity. As we see later, Fairness 48 is the main QoS parameter to measure the performance of scheduling algorithms in the heterogeneous user environment.
B. Hardware or cluster: A cluster is a group of networked machines (nodes), where each machine has a computational (CPU), memory (RAM), network, and a data storage unit. The CPU may consist of more than one processing core, where each core operates at a specified execution rate. The memory and data storage units have fixed capacity and are attached to CPU at a specified data transfer rate. Furthermore, nodes communicate with each other with fixed network bandwidth. Under this observation, cluster heterogeneity has the following subcategories:
(i) Processor heterogeneity: It occurs when different nodes have CPUs with different processing power. In all Hadoop systems, cores within a CPU are homogeneous (i.e., cores within a single CPU have same clock cycle rate).
50
(ii) Memory heterogeneity: It occurs when the nodes have different size of main memory and/or attached to CPU at a different bandwidth. (iii) Disk heterogeneity: It occurs when the nodes have diverse disk bandwidth, for example, a node may have an optical hard disk drive (HDD) and another may have a solid state drive (SSD), which has higher bandwidth than HDD. It may be noted that size of the disk does not count in heterogeneity, unlike memory because generally disk size does not affect the performance of a computer system. (iv) Network heterogeneity: It occurs when the nodes have varying network bandwidth. Nodes may be connected through the diverse generation of networking hardware (i.e., LAN cables, N/W cards, and switches) that causes different bandwidth.
A Hadoop system may consist of partial or full hardware heterogeneity. It is possible that nodes with a similar type of CPUs may have memory units with varying bandwidths. The cluster-level heterogeneity (partial or full) may also occur in virtual cluster setup that can be built upon private data center or over clouds. Although virtualization technology can isolate CPU and memory performance effectively between Virtual Machines (VMs), heterogeneity may arise because I/O devices (disk and network) are shared between VMs. 22 For instance, only disk level heterogeneity has been considered in Zaharia et al., 22 while neglecting CPU and memory heterogeneity.
C. Workload: The set of all MR jobs that are executed on Hadoop cluster is collectively known as a workload. In a workload, each job has a number of map and reduce tasks with the fixed demand of each resource type available in a node. Through the literature review, workload heterogeneity may have the following subcategories:
(i) Job type: A job could be CPU intensive, I/O intensive, or a mix of both. Understanding the nature of such jobs enables the scheduler to schedule its map and reduce tasks in an efficient manner to have better parallelism with less resource contention.
(ii) Job size: The size of a job is typically measured as the number of maps and reduce tasks required to finish that job. The number of map tasks typically depends on the size of input data to be processed, whereas the number of reduce tasks (usually one-fourth of map tasks) is set by the user. Different jobs process the different amount of data that leads to heterogeneity in job sizes.
(iii) Job priority: In shared environments with multiple jobs, priorities are used to ensure that a customer's interactive and other important jobs get more resources to finish as fast as possible. An interactive ad hoc query and the small job always have high priority in comparison with long batch jobs. Jobs with different priorities lead to job priority heterogeneity.
Scheduling challenges in heterogeneous Hadoop environment
In the beginning, the Hadoop was homogeneous in all three heterogeneity aspects. However, as Hadoop became popular, its scheduler's implicit assumption of homogeneous system has become obsolete in modern data centers, especially in the virtualized environment. Considering such heterogeneity factors by Hadoop schedulers while making scheduling decision is a tedious task. In this subsection, we discuss various scheduling challenges faced by MR scheduler in a heterogeneous environment. Following challenges have been identified through the literature survey.
Stragglers detection: Stragglers are slow map or reduce tasks as compared with other tasks. They occur in homogeneous environment due to faulty hardware or heavy load on a node where the tasks have been scheduled. 22 Such tasks prove to be a bottleneck in job's overall progress, decreasing the makespan (i.e., completion time of the last job), thereby, reducing the overall throughput of a system. The jobs with a deadline constraint perform very poorly in the presence of stragglers. A speculative copy (back up copy) of the slow task should be started afresh on a different node to overcome the problem. 22 In a heterogeneous environment where different nodes may have different computational power, a task may be slow because it was scheduled on a node with less processing power rather than due to faulty or overloaded node. Hence, it becomes a challenge to identify stragglers and decide the corresponding number of speculative copies in a heterogeneous cluster.
Achieving fairness: In a shared cluster, fairness is an important feature to be supported by an MR framework. Fairness ensures each user/job gets equal (or weighted) amount of computing resources. The standard Hadoop schedulers such as FAIR 48 and CS 51 take the number of slots assigned to a user/job as a metric of share and ensure fairness by assigning a same number of slots to every user. In a heterogeneous cluster environment, the number of slots might not be an appropriate metric of fair share because slots may have different computational power. Thus, it is needed to define fairness metric in a heterogeneous environment entirely in a different way as in Medley 52 and ProgressShare 53 schedulers.
Handling heterogeneous workload: In case the map tasks of two CPU-intensive jobs are scheduled on one node, both will compete for the CPU and may take longer execution time. In contrast, if the tasks of a CPU- and an I/O-intensive job are scheduled on the same node, both can run in parallel without hindering each other's performance. The MR environment is commonly shared to execute different types of jobs. Hence, scheduling algorithms must schedule tasks with orthogonal resource requirement on the same node to utilize different configuration of hardware.
Finding best node for a task: Efficient task allocation usually improves the overall performance of a system. The I/O intensive tasks must be scheduled on a node with high disk bandwidth. The relationship between job characteristic and node capability is called job affinity and is sometimes referred to as fitness metric. 54 This metric has been defined in different ways in the literature.50,52,54 Overall, it defines the suitability of a task being scheduled on a particular node. It is always desirable to find the best match between jobs (tasks) characteristic and nodes capability to exploit the heterogeneity of hardware. In the presence of hardware and workload heterogeneity, the challenge is to find out the best match.
Handling data locality: Data locality is the most advantageous feature of the MR framework. It ensures that computations are assigned to a node where data reside. Therefore, data locality helps to reduce the network traffic and thereby improves the job execution time because disk bandwidth is better than network bandwidth. However, to exploit the hardware heterogeneity, the tasks are placed on a suitable node avoiding data locality for efficient computation. This results in degradation of data locality parameter and hence becomes a challenge for Hadoop schedulers to optimally achieve job affinity while maintaining data locality.
Study of Scheduling Algorithms in Heterogeneous Environment
In this section, we study various MR scheduling algorithms for Hadoop that have been designed specially to address different heterogeneity factors. The algorithms have been classified according to the heterogeneity factors considered in scheduling decision. Figure 2 shows the classification tree used in the study of scheduling algorithms. The algorithms in each category have been explained in a separate subsection with specific challenges. Some scheduling algorithms address the issues of more than one heterogeneity factor, for example, COSHH (Classification and Optimization-based Scheduler for Heterogeneous Hadoop) 47 scheduler considers user, cluster, and workload heterogeneity while making the scheduling decision. These types of algorithms have been discussed in the last subsection where most of them consider two heterogeneity factors simultaneously, namely, workload and cluster in their scheduling decision. This is a natural combination as the hardware heterogeneity can easily be exploited through heterogeneous workloads having diverse resource demand.

Classification of heterogeneous Hadoop MapReduce schedulers.
Scheduling algorithms for user heterogeneity
Earlier Apache Hadoop was mainly designed for a single user to run large batch jobs such as generating web indexes and mining log data. A single FIFO queue was maintained for the same. As Hadoop is to be shared by multiple users now, single job queue (i.e., FIFO queue) becomes a bottleneck in performance and responsiveness that further affects the fairness of the system. In a shared cluster environment, a user with a small job may get starved for a long time if the job is submitted after a long batch job. In large systems, simple algorithms like FIFO can cause severe performance degradation, particularly when multiple users sharing the cluster having heterogeneous needs. 55 Two popular MR schedulers, namely, FAIR and CS, work on a similar approach to cater the need of heterogeneous users to maintain fairness. The standard Hadoop distribution includes these two schedulers in all versions. Fairness is the main performance objective in heterogeneous multiuser environment, which otherwise cannot be achieved by FIFO. Although fairness implies that each user and job get a proportional number of slots to run its tasks, the same does not hold true for heterogeneous cluster/hardware environment where different slots may have different computational power [discussed in Scheduling algorithm for cluster (hardware) heterogeneity subsection].
FAIR 48 and CS 51 are two early pluggable schedulers as soon as the scheduler in Hadoop became a pluggable component. 56 Separating the scheduler logic from JT module led to innovation in this domain. Developed as a special multiuser scheduler for in-house usage by Facebook and Yahoo, the two schedulers were later included in Hadoop distribution and undergone several improvements ranging from security to better resource utilization. FAIR and CS both are designed separately for slot-based and YARN-based Hadoop. The description here is in the context of slot-based Hadoop framework. The difference between FAIR and CS is minimalist. The FAIR as well as the CS equally distributes the compute resources among users/jobs to achieve fairness. FAIR allocates one pool to each user and the resources (slots) are divided equally among all the pools. It uses a generalization of max-min fairness 57 with a minimum guarantee to allocate slots across pools. However, CS uses queues instead of pools, in which each queue is assigned to an organization, and resources (slots) are divided among these queues. Additional security mechanisms are built to control access to the queues so that each organization can access only its queue and cannot interfere with another organization's queues, jobs, or tasks.
Both FAIR and CS guarantee a minimum share of resources for a pool or queue. If a pool does not receive a minimum share for a long time, FAIR pre-empts the most recently started task of an over-allocated job from some other pool. This ensures that long batch jobs do not block the execution of some production jobs and also that a smaller number of resources are wasted (those spent in the pre-empted task). Similarly, CS limits running/pending tasks and jobs from a single queue. To maximize resource utilization, it allows reallocation of resources of a free queue to queues with full capacity. Whenever jobs arrive in that queue, running tasks are completed and resources are given back to the original queue. It also allows priority-based scheduling in an organization queue. FAIR schedules jobs within a pool based on priority, first come first serve, or fair-share basis. Both schedulers aim to assign a fair share to users, which means resources are assigned to jobs such that all users receive, on average, an equal share of resources over time. Therefore, the fair sharing and capacity scheduling algorithm only takes user heterogeneity into account.
FAIR 48 scheduler improves the response time and throughput in comparison with FIFO scheduler. However, it suffers from the data locality issue because in the FAIR scheme, tasks are assigned to slots as soon as they become available to maintain the fairness among users compromising with data locality as identified by Zaharia et al.48,55 To address the conflict between locality and fairness, Zaharia et al. 55 extended their FAIR 48 scheduler, used a simple algorithm called Delay scheduling, 55 and proposed a scheduler essentially known as Hadoop Fair Scheduler (HFS). 55 According to Delay scheduling scheme, if data locality is not achieved, job, which is scheduled in next turn, cannot launch its map or reduce task to a free slot. Rather, it waits for some time and allows other jobs to launch their task. After some time, if data locality constraint is met, the job is scheduled immediately. Thus, Delay scheduling achieves nearly optimal data locality by deferring the immediate allocation of slots to tasks while preserving fairness in a variety of workloads and can double the throughput. Delay scheduling can also be combined with FIFO, BalancedPools, 58 HScheduler, 59 or any other queuing policy that produces a sorted list of jobs. HFS was developed as an extension to FAIR and later included in a standard Hadoop 0.21 framework.
In fine-grained YARN cluster manager (i.e., in Hadoop 2.x and Hadoop 3.x), achieving fairness for multiple heterogeneous users is a complex task and well received by DRF
41
scheduler. Initially, DRF was proposed for Mesos cluster manager,
42
however, later adopted in Hadoop framework after inclusion of general purpose YARN cluster manager. DRF further generalizes the concept of max-min fairness to multiple resource types that leads to better throughput. It is noted that max-min fairness generalization is also used by FAIR
48
for only single resource type. The intuition behind DRF is that in a multiresource environment, the allocation of a user should be determined by the user's dominant share, which is the maximum share that the user has been allocated for any resource. The maximum among all shares of a user is called that user's dominant share and the resource corresponding to the dominant share is called the dominant resource. Different users may have different dominant resources. For example, if user A runs CPU-heavy tasks and user B runs memory-heavy tasks, DRF attempts to equalize user A's share of CPUs with user B's share of memory. DRF satisfies a number of desirable properties identified for any fairness scheme in the multiresource fine-grained environment. In particular, DRF fulfills all four essential properties that include sharing incentive, strategy proofness, Envy freeness, and Pareto efficiency.
41
Each scheduling decision in DRF can be made in
Although FAIR, CS, and Delay schedulers were initially built for slot-based Hadoop framework, all were modified later and included in YARN-based Hadoop framework where multiple resource types are available for allocation as compared with single slot-based abstraction. Table 1 summarizes the already discussed scheduling algorithms on the basis of QoS objectives, SLA adherence, scheduling entity, etc. where QoS objective(s) refer to most important QoS metric(s) aimed to improve by particular scheduling algorithm. In case, the scheduling problem is formulated mathematically as an optimization problem, it refers to the parameter being minimized or maximized. The static/dynamic characteristic describes whether the particular scheduler is static (in which all jobs arrive at time zero) or dynamic (where jobs arrive over time). Mathematical formulation column describes whether the scheduling problem has been formulated as an integer linear program or not. Table 2 summarizes the various quality metrics and base algorithm(s) that have been used in comparison while experimentally evaluating the algorithms. The mentioned discussion of table attributes applies to Tables 3–8.
DRF, Dominant Resource Fairness; HFS, Hadoop Fair Scheduler; SLA, service level agreement; YARN, Yet Another Resource Negotiator.
Capacity scheduler was developed by Yahoo, Inc. who did not publish any research article.
Naïve Fair refers original FAIR scheduler.
CPU, Central Processing Unit.
AET, Approximate End Time; ATAS, Adaptive Task Allocation Scheduler; IP, Integer Program; LATE, Longest Approximate Time to End; MTSD, MapReduce Task Scheduler for Deadline; SAMR, Self-Adaptive MapReduce.
Hadoop speculative refers default speculative technique in Hadoop framework at the time of evaluation of respective scheduling algorithms.
JATS, Job-Aware Task Scheduling; RAS, Resource-Aware Adaptive Scheduling.
CASH, Context-Aware Scheduler for Hadoop; COSHH, Classification and Optimization-based Scheduler for Heterogeneous Hadoop; ESAMR, Enhanced Self-Adaptive MapReduce scheduling; MR, MapReduce; VM, Virtual Machine.
Observations
Fairness is the main QoS objective while designing scheduling algorithm for heterogeneous multiuser environment by allocating an equal number of slots to each user. However, this method fails to work in a heterogeneous cluster environment where slots on different machines may have different computing power (CP). Multiuser environment results in heterogeneous workload as various users execute jobs with different resource demand. However, none of the algorithms already explained, except DRF, addresses the workload heterogeneity. The awareness of DRF for heterogeneous workload is due to YARN. DRF explicitly does not consider workload heterogeneity in its scheduling process. As far as scheduling hierarchy is considered, all discussed algorithms work at both user and job levels.
Scheduling algorithm for cluster (hardware) heterogeneity
A different configuration of computer hardware is a common phenomenon in data centers as a new machine becomes available every year. The induction of new machines in data centers results in heterogeneous Hadoop cluster at hardware level. The Hadoop implicitly assumes that all nodes in the cluster are homogenous and make scheduling decision accordingly. In the literature, various scheduling algorithms have been proposed to overcome the problem of hardware heterogeneity. In this subsection, such types of scheduling algorithms are discussed. We note that straggler detection in heterogeneous hardware environment is a difficult task. Most of the algorithms in this subsection address the straggler detection problem especially in a heterogeneous cluster environment to improve the overall response of the system.
To improve the response time of jobs, Hadoop incorporates the mechanism of speculative execution. It identifies the slow tasks called stragglers and speculatively runs its copy (also called “backup task”) on different nodes to finish the computation faster. The tasks may be slow due to different reasons such as heavy system load, faulty hardware, and process deadlock. To identify a slow task, Hadoop monitors tasks progress using a progress score between 0 and 1 using Equation (1),
22
where M is the number of key–value pairs that have been processed and N is the number of key–value pairs that need to be processed for map task. In the same manner, M′ is the number of key–value pairs that have been processed and N′ is the number of key–value pairs that need to be processed in any particular phase of reduce task. A task is marked as a straggler, in case it has run for at least 1 minute and its ProgressScore (PS) is less than the average for its category minus 0.2 (standard Hadoop distribution uses value 0.2). While computing the PS for reduce task, a multiplicative term “1/3” is used because a reduce task has three phases, namely, shuffle (copy), sort, and reduce. Hadoop implicitly assumes that cluster is homogeneous and each node executes the task at the same speed, that is, tasks make progress linearly. It further uses these assumptions to identify the stragglers and decides when to speculatively re-execute stragglers. Hence, in a heterogeneous cluster environment, Hadoop scheduler(s) need to be redesigned considering hardware heterogeneity. A heterogeneous cluster consists of diverse CP machines. Hence, the reason for a slow task may also be a low CP node if the task is scheduled on it. Given this, straggler detection is a challenging task due to ambiguity in reason for its creation. This problem also arises in clouds because cluster heterogeneity frequently occurs in virtualized cloud computing infrastructure such as Amazon EC2 and Google.
22
Longest Approximate Time to End (LATE), proposed by Zaharia et al., 22 is one of the early MR scheduling algorithms proposed for the heterogeneous cluster to identify and schedule straggler tasks. The LATE scheduler decides re-execution of stragglers speculatively to improve response time in a cloud environment. Native Hadoop scheduler considers all stragglers equally low in terms of speed. However, LATE prioritizes the speculative tasks. It selects the fast node for straggler execution and binds the number of speculative tasks using a threshold to prevent thrashing. The algorithm first calculates the PS of a task using Equation (1) (like native Hadoop scheduler). Thereafter, it calculates the ProgressRate of each task as ProgressScore/T, where T is the amount of time the task has been running for. Then, a new heuristic, “time to completion” (commonly referred as TimeToEnd) of the task, is estimated as (1 − ProgressScore)/ProgressRate. The heuristic serves to prioritize the stragglers, that is, tasks with high completion time are speculatively re-executed first. A different technique to estimate the completion time may also be incorporated into LATE. It is noted that authors have created heterogeneity through virtualized Hadoop cluster over the cloud and private data center. Furthermore, LATE also improves the performance of speculative execution in a homogeneous environment.
By focusing on estimated time left rather than ProgressRate as explained earlier, LATE speculatively executes only those tasks that improve job response time, rather than any slow task. However, LATE scheduler adopts a static method to compute the TimeToEnd heuristic, which is further used to identify slow tasks. As a result, LATE does not perform so well in a heterogeneous environment. The Hadoop default, LATE, and BASE 60 speculative scheduling algorithms assume equal execution time at all stages of reduce tasks and consider 33% completion of a reduce task while calculating its ProgressScore. The algorithms further assume only one stage in map task. Such assumptions may not always hold true because the time taken by each map and reduce stage depends on the type of node.
To further improve the performance, Self-Adaptive MapReduce (SAMR) scheduling algorithm, proposed by Chen et al., 61 estimates the time left for tasks to complete on a given node using dynamic stage weights. The algorithm adjusts the weight of map and reduce tasks using previous (historical) information. The TT reads the historical stage weight information stored on every node in xml format and utilizes it to tune the stage weights of currently running task and finally updates the historical database with current value. SAMR speculatively schedules the slow tasks with highest estimated time left.
The SAMR algorithm also identifies slow and fast TTs (i.e., nodes) dynamically using the mathematical expression established in Chen et al. 61 and classifies them into slow and fast TTs using the parameter SLOW_TRACKER_CAP. The scheduler never launches backup tasks on slow nodes, ensuring that the backup tasks will no longer be slow. The experimental results show that SAMR significantly decreases the execution time up to 25% and 14% when compared with Hadoop default scheduler and LATE scheduler, respectively. 61
Chen et al. 62 proposed another variant of SAMR, called HAT 62 (History-based Auto-Tuning), which uses historical data on each node to adjust the weights of the map and reduce phases. Using the updated value of weights, the progress score of tasks is calculated (refer Chen et al. 62 for a detailed description). Based on the accurately calculated progress of tasks, HAT estimates the remaining time of tasks and further launches backup tasks for those with longest remaining time. The limitation of SAMR and HAT scheduling algorithms is consideration of heterogeneous hardware only while calculating the stage weight of tasks.
Yang and Chen
63
make an improvement on the original speculative execution method of Hadoop (called as Hadoop speculative in the literature) and LATE Scheduler by proposing a new scheduling scheme known as Adaptive Task Allocation Scheduler (ATAS). The ATAS adopts more accurate methods (due to refined Approximate End Time [AET] calculation) to determine the response time and backup tasks that effectively increase the system's ability to respond. It finds out the straggler through more reasonably calculated AET heuristic of each task. The speculative execution is based on the principle of launching backup tasks for map/reduce tasks that have longest expected execution time in the computing process. AET of the ith task is computed as shown in Equation (2), where AvgProgress represents the average speed of task execution and k is the serial number of the reduce stage. AvgProgress of a task is computed as Progress/T where T represents the task execution time.
The scheduler divides the cluster nodes into two sets, namely, QuickNode and SlowNode, based on speed. The QuickNode is prioritized with the allocation of backup tasks. The authors conducted three different simulation experiments where the execution time of LATE Scheduler and ATAS is reduced by a maximum of 12% and 30%, respectively. Furthermore, the average tasks throughput is increased by a maximum of 13% and 33%, and the average tasks latency is reduced by a maximum of 25% and 36%, respectively, in comparison with Hadoop speculative. Thus, ATAS can effectively enhance the overall processing performance of MR in a heterogeneous cloud environment.
Mashayekhy et al.
64
proposed a framework to improve the energy efficiency of MR applications over heterogeneous machines while satisfying the SLA. The problem of energy-aware scheduling of a single MR job has been modeled as an Integer Program (IP) called Energy-aware MapReduce Scheduling (EMRS-IP) with a deadline as a constraint (refer Mashayekhy et al.
64
for detailed expressions for constraints). Equation 3 shows the objective function of the formulated IP where M and R are the set of map and reduce tasks of the application, A and B are the set of map and reduce slots, respectively, on heterogeneous machines,
Two heuristic algorithms have been proposed to solve EMRS-IP, called EMRS algorithms: EMRSA-I and EMRSA-II. The algorithms find the assignment of the map and reduce tasks to the machine slots to minimize the overall energy consumption while executing the application. Both heuristics take the energy efficiency differences of machines into account and use a metric called energy consumption rate (ecr), which is calculated for each slot. The metric characterizes the energy consumption of each machine and induces an order relation among the machines. EMRSA-I calculates energy consumption rate metrics
The MapReduce Task Scheduler for Deadline (MTSD) algorithm presented by Zhou and colleagues 65 is first of its kind that prioritizes and schedules jobs to meet their response time SLAs in a heterogeneous environment. The algorithm takes hardware heterogeneity into account while making scheduling decisions. MTSD introduces a classification algorithm that classifies the nodes in a multilevel hierarchy according to their computing capacity. The fastest nodes are placed on the highest level, whereas slowest node is assigned to the lowest level. Furthermore, the data are distributed on different levels proportionally, that is, the nodes at the highest level will get a maximum proportion of data that may improve data locality and completion time. The algorithm further uses the remaining time of partially completed tasks and estimated task execution time on the slowest nodes to compute the required number of map and reduce slots. Tables 3 and 4 summarize various attributes of studied schedulers in this subsection.
Observations
In the presence of heterogeneous hardware, straggler detection is quite a cumbersome task. All proposed algorithms to identify stragglers in heterogeneous cluster environment are dynamic in nature and none of them have been mathematically formulated as an optimization problem. Furthermore, each algorithm including Enhanced Self-Adaptive MapReduce scheduling (ESAMR) (discussed in Scheduling algorithm for multiple heterogeneity factors subsection) identifies stragglers by calculating a heuristic value commonly referred as TimeToEnd. Unlike LATE, SAMR and ATAS algorithms identify the slowest nodes and classify them dynamically. According to the information of the slow nodes, both schemes do not launch backup tasks, thus, ensuring that the same will not be slow tasks anymore.
Scheduling algorithm for workload heterogeneity
A workload is a collection of various MR jobs that could be either CPU or I/O intensive, or both. As discussed in Heterogeneity factors in Hadoop subsection, jobs in a workload may have different size and priority. The heterogeneity in workload may complicate the scheduling decision in Hadoop. One simple technique to achieve better performance is to distribute the different types of jobs uniformly on every node in the cluster. For example, if the map tasks of two CPU-intensive jobs are scheduled on one node, both of them will compete for CPU and take a longer time to finish. In contrast, if the tasks of a CPU-intensive job and an I/O-intensive job are scheduled on the same node, both can run in parallel without having an impact on each other's performance.
Polo et al. proposed RAS 66 (Resource-aware Adaptive Scheduling for MapReduce Clusters) scheduler in which a slot is fixed for a specific type of job. The algorithm extends the abstraction concept of “task slot” to “job slot” and uses profiling information from previous execution of jobs. The job slot is an execution slot bound to a particular job as well as task type (either map or reduce) within that job. The algorithm considers completion time goals as soft deadlines being submitted by users. RAS has four main components: (i) Job Status Updater, (ii) Job Time Completion Estimator, (iii) Placement Algorithm, (iv) Job Utility Calculator. The Job Status Updater keeps track of average task length of job and later used in estimation of completion time for each job. The second component, job time completion estimator, estimates the number of map tasks allocated simultaneously to meet the deadline for a job. The placement algorithm forms possible placement matrices after examining the tasks on different TTs and their resource allocation. In contrast, the job utility calculator gives a utility value for the placement matrix P. The matrix value Pj,tt represents a number of tasks of job j placed (scheduled) on TT tt. The placement algorithm selects best placement choice and thereafter task scheduler enforces the placement decision. The entire focus of RAS is on Memory, I/O, and CPU; however, it can be easily extended to include parameters such as storage capacity and network bandwidth.
Tian et al. 67 proposed a scheduler called Triple-Queue that overlaps CPU- and I/O-bound tasks to improve the overall utilization of the cluster. As the name implies, Triple-Queue scheduler maintains three separate queues, namely, wait queue, CPU-bound queue, and I/O-bound queue for incoming jobs. It employs a workload predict mechanism called MR-Predict, which automatically predicts the class of a new coming job and inserts the jobs into the corresponding queue. Whenever a new job arrives, it is first kept in the wait queue. The Triple-Queue scheduler takes a different approach by first allocating the map tasks of a new job to an available slot. The scheduler then moves the job to a CPU-bound or a disk I/O-bound queue using the execution data of job (precisely if a job spends most of its time doing computation on CPU, it is moved to CPU-bound queue otherwise to I/O-bound queue). The scheduler continuously monitors the execution times of tasks to move jobs dynamically from one type of queue to another. Such a scheme has been shown to achieve a 30% improvement in the overall throughput over the default single-queue scheduler. However, the scheme explored a limited form of workload heterogeneity.
The Job-Aware Task Scheduling (JATS) algorithm, proposed by Nanduri et al.,
68
uses a task vector
Nanduri et al.
68
considered the following features to train the classifier: (i) hardware specifications of TT (Φ), (ii) network distance between the nodes of task execution and the corresponding data split of the task (
Another algorithm that considers workload heterogeneity into account is LsPS, 71 which is actually an improvement of FAIR scheduler. FAIR maintains a separate job queue for each user and divides the resources fairly among all users so that each user gets an equal amount of slots that leads to better response time. However, one major drawback of the FAIR scheme is that it does not consider job size of the user while distributing slots. Multiple users have heterogeneous resource demand and to maintain better fairness to improve overall response time, slots must be allocated to users according to job size. Therefore, LsPS adaptively adjusts the slot shares among all active users such that the share ratio is inversely proportional to the ratio of their average job sizes. For example, in a simple case of two users, if their average job size ratio is equal to 1:2, the number of slots assigned to the first user will be twice that to the second user. Consequently, LsPS implicitly assumes higher priority to users with smaller jobs, resulting in better response time. At job level, LsPS dynamically tunes the scheduling scheme for jobs within an individual user by leveraging the knowledge of job size distribution. Whenever job size has high variance, the LsPS algorithm uses FAIR scheduler at the job level. As soon as the job sizes become close to each other, FIFO scheduler is used.
To the best of our knowledge, PRISM 72 (Fine-Grained Resource-Aware Scheduling for MapReduce) scheduler is first of its kind that considers phase-level scheduling within a task. The phase-level scheduling refers to the consideration of different characteristics of various phases (mapping, shuffling, sorting, merging, and reduce) of a map and reduce task in scheduling decision. Other heterogeneous workload schedulers such as RAS, 66 HaSTE, 54 and JATS 68 perform scheduling at the task level only. Various phases of map and reduce tasks are the finest level of granularity possible for scheduling. Zhang et al. 72 find out that even a single task of a job usually has highly varying resource requirements during their lifetime, for example, shuffle phase of reduce task is highly I/O intensive, whereas reduce phase is CPU intensive. Motivated by this observation, they proposed a fine-grained resource-aware scheduler that coordinates task execution at the level of phases. Job profiling plays a significant role in these techniques as in ARIA 73 and BalancedPools. 58 Whenever a particular phase of a task finishes execution, it asks permission from the NM to start the next phase. Afterward, NM forwards the request to the scheduler that uses the current progress information and the phase level resource requirement to take a decision. On the basis of the information, the scheduler either allows the task to continue its next phase or launches a new task.
The drawback of the PRISM scheduler is that it pauses a task at runtime and thus delays the completion of the current task as well as all the subsequent tasks. Besides this, the authors claim that the performance of PRISM is dependent on the accuracy of the profiler. Any standard profiler such as Starfish 74 can be plugged into PRISM. A less efficient profiler that extracts wrong insights from profiled data could degrade the performance. It is worth mentioning that it is not clear what kind of heterogeneous jobs were used during the evaluation of PRISM. Tables 5 and 6 summarize the various attributes of scheduling algorithms discussed in this subsection.
Observations
We observe that in the presence of heterogeneous workload, resource utilization gets most adversely affected. Hence, mostly schedulers that address workload heterogeneity focus to improve resource utilization parameter. Most algorithms discuss only job type heterogeneity except LsPS 71 and PRISM, 72 which consider job size and phase-type heterogeneity, respectively. To the best of our knowledge, a scheduler that addresses workload of jobs with different priority level has not been proposed in the literature.
Scheduling algorithm for multiple heterogeneity factors
Consideration of multiple heterogeneity factors in Hadoop system while making scheduling decision is gradually becoming a common phenomenon. In the literature, few algorithms such as DySacle, 50 Medley, 52 and COSHH 47 consider more than one heterogeneity factor simultaneously. One type of heterogeneity is usually exploited with the help of another heterogeneity factor to increase the performance of scheduling process. For instance, to exploit the hardware heterogeneity of cluster nodes, a mixed workload of jobs with diverse resource demand is used. In this scenario, jobs with heterogeneous resource demand can be efficiently allocated the suitable resources. We illustrate a potential advantage of considering multiple heterogeneities by an individual scheduling technique as follows. Assume a heterogeneous Hadoop cluster consisting of two types of machines. The first type of machines (say type 1) have a high-performance CPU with a moderate speed optical disk drive, whereas the second type of machines (say type 2) have a low-performance CPU and a fast SSD. If a workload comprising two jobs is executed on the cluster where one of the jobs is CPU intensive and other is disk intensive, scheduling a CPU-intensive job to type 1 machines and disk-intensive job to type 2 machines will lead to better performance despite data transfer overhead. The default Hadoop scheduler does not consider hybrid heterogeneity and assigns jobs favoring only data locality.
In Scheduling algorithm for cluster (hardware) heterogeneity subsection, we discussed the drawback of SAMR 61 scheduling algorithm that it only considers the hardware heterogeneity. However, different types of jobs may have a different map and reduce stage weights. Even, for the same type of jobs, different data sets may lead to different weights. SAMR algorithm does not consider stage weight variations due to workload heterogeneity. To overcome the drawbacks of SAMR, Sun et al. 75 proposed an ESAMR algorithm to improve the speculative re-execution of slow tasks in MR. To identify slow tasks more accurately, ESAMR considers the type of job and the input data size along with the node type while calculating weights for map and reduce task stages. The algorithm divides the historical stage weights information of tasks on each node into k clusters using a machine learning technique, that is, k-means clustering algorithm. The number k depends on characteristics of the data set (i.e., stage weights information). When executing a job on a node, ESAMR classifies the job's tasks into one of the clusters and uses the cluster's weights to estimate the time left to completion (i.e., TimeToEnd) of job's tasks on the node. Experiments show that taking the heterogeneity of workload along with cluster into account while estimating the TimeToEnd heuristic of a task produces least error as compared with SAMR and LATE. One drawback associated with ESAMR is that the k-means clustering algorithm introduces time overhead. Moreover, the algorithm does not consider the work done by the straggler task and starts the execution of the new task from scratch.
Yan et al. 50 also considered hardware (CPU type) and workload heterogeneity while proposing DyScale scheduling algorithm for a Hadoop cluster in which each node has a heterogeneous multicore processor(s). DyScale aims at exploiting these heterogeneous cores within a single chip for achieving a variety of performance objectives. Authors have assumed that each chip has few fast cores and more slow cores. They further considered two types of jobs that are as follows.
(i) Short interactive jobs that need to be completed in less amount of time.
(ii) Long batch jobs that are throughput oriented.
The two different pools of virtual resources are constructed from heterogeneous physical cores. One is made up of fast cores of every node in the cluster and second is made up of slow cores. Each pool has its own job queue, namely, InteractiveJobQueue for short interactive jobs and BatchJobQueue for long batch jobs. Jobs in InteractiveJobQueue are scheduled over a fast pool of resources so that they can be completed in short time, whereas jobs submitted to BatchJobQueue are assigned resources from a slow pool of resources. The job ordering/scheduling within both job queues can be performed through any one of the existing techniques, for example, FIFO and HFS. 55 Furthermore, resource allocation within the queue may be handled by ARIA SLO-driven scheduler. 73 It is worth mentioning that heterogeneous core chips are not yet available, although expected to be used in the near future. 50
Fairness metric needs to be redefined in the situation where the cluster is made up of heterogeneous machines. The number of slots might not be an appropriate metric of the share in a heterogeneous cluster because all the slots are not the same. Even some slots are more suitable for a particular job due to its microarchitecture. Furthermore, slots of a node with added hardware accelerator like Graphical Processing Unit (GPU) are more suitable for the specific type of job, for example, Cypto.
52
Lee et al.
52
redefined the fairness metric of delay scheduler
55
and proposed a new scheduler called Medley for a multiheterogeneous environment. The Medley scheduler exploits the fact that a particular job runs faster on a specific node. Before achieving the fairness among the jobs, the scheduler establishes the relationship between job and slot through a fitness metric called Computing Power (CP). It is defined as the relative processing power of a slot for a particular task. It is worth mentioning that the CP of any slot is job dependent. Furthermore, the scheduler proposes a new fairness metric called Progress Rate (PR) as a ratio of the aggregate CP of slots. Mathematically, PR of a job j is defined in Equation (5).
where Sj is a set of all slots currently allocated to job j and S is a set of all slots available in the cluster. Medley scheduler allocates the appropriate number of specific slots to the tasks of a particular job, so that PR of each job reaches 1. It is worth mentioning that combined PR of all jobs may be >1.
The same fairness and fitness (job affinity) metric used in Lee et al. 52 are further utilized by Lee et al. 53 with just different names, namely, PS and Computing Rate (CR). The authors have proposed two schemes, one for VMs allocation (i.e., for virtual cluster setup) and second for MR job scheduling in the cloud. Given the fluctuating resource demands of MR workloads, the data analytics cluster must scale according to demands. To that end, authors suggested a resource allocation strategy similar to the previous work of Chohan et al. 10 The scheme divides available machines into two virtual pools, namely, core nodes and accelerator nodes virtual pool. Core nodes are general purpose VMs with a disk for storage, whereas accelerator nodes are diskless machines with dedicated GPUs. Size of each pool is dynamically adjusted according to needs of incoming jobs to reduce cost and improve utilization. Job affinity (job/instance type relationship) has been taken into consideration while allocating resources for the cluster. It is quantized using the relative speed of each instance type i for a particular job j, which is called computing rate and denoted as CR(i, j). If a task of job j runs twice faster on the instance i1 than on i2 (i.e., finishes in half of the time), then CR(i1, j) is twice of CR(i2, j). CR is determined during the calibration phase of a job execution in which at least one map task is scheduled on every slot. By using the computing rate information and the cost of each instance type, the cloud driver can make a decision on which instance type to use. It guides to have a good mix of different instances that minimize the cost to maintain the cluster. Once the cluster has been set up, jobs are scheduled achieving fairness using ProgressShare metric of Medley scheduler in a heterogeneous environment.
Like DyScale,
50
Medley
52
and ProgressShare
53
scheduling algorithms, ThroughputScheduler proposed by Gupta and colleagues
76
also tries to schedule the best task for a slot through job/task affinity or fitness property. The algorithm reduces the overall job completion time on a cluster of heterogeneous nodes. It schedules the task on the node whose capability (e.g., relative CPU and disk I/O speeds) optimally matches the task requirement. The algorithm works in two phases (i) explore phase and (ii) exploit phase. In the explore phase, the algorithm learns node characteristics in offline manner by running probe jobs and then job resource profile is built using a Bayesian active learning scheme in online mode without interrupting production use of the cluster. The characteristics/capabilities of the server are described by a corresponding vector
The Context-Aware Scheduler for Hadoop (CASH) 77 assigns tasks to the nodes that are most capable of satisfying the tasks' resource requirements like ThroughputScheduler. CASH also learns resource capabilities and resource requirements, however, in offline mode, to enable efficient scheduling. The scheduler categorizes each node into “CPU-resources” and “I/O-resources” buckets by comparing their CPU and I/O benchmark results with the results of a baseline machine. It also classifies map and reduce tasks of jobs into CPU-bound and disk I/O-bound classes by comparing their execution rates (from history logs) with the speed/bandwidth of available resources. It is observed that this scheduler relies heavily on historical and benchmark data for appropriate scheduling, which may not exactly match the current job and resource scenario.
Rasooli and Down 47 proposed a scheduling algorithm called COSHH, which considers all three heterogeneity factors in making scheduling decisions. First of all, the algorithm classifies the jobs using k-means clustering algorithm on the recorded execution times. When a new job arrives, the classification approach specifies the job class to which the job belongs, and stores the job in the corresponding queue. If the job does not fit any of the current classes, the list of classes is updated to add a class for the incoming job. Next, the optimization approach is used to find an appropriate matching of job classes and resources. An optimization problem is defined based on the properties of the job classes and features of the resources. The algorithm determines the allocation matrix for jobs using an LP approach by maximizing resource utilization. Constraints for LP formulation are execution rates of different job classes on different resources, arrival rates of these job classes, and capacity of the available nodes. At the time of a scheduling decision, the COSHH algorithm uses the set of suggested job classes for each resource and considers the priority, required minimum share, and a fair share of users to make a scheduling decision. In this scheme, data are replicated on the resource where the task will be executed to increase data locality. We note that COSHH also uses the concept of job affinity to exploit the hardware heterogeneity.
Yigitbasi et al. 78 proposed an energy-efficient algorithm called EESched for scheduling heterogeneous workload to the heterogeneous cluster consisting of high- and low-power machines. This algorithm provides an opportunity to save energy by intelligently placing jobs on its corresponding energy-efficient machine. Based on the initial experiments, the authors derived the fact that I/O bound workloads have better energy efficiency on low power nodes, whereas CPU bound workloads achieve better energy efficiency on high-power nodes. Another fact was derived that a map task is more CPU intensive, whereas a reduce task is more I/O intensive. The energy-efficient scheduler EESched used the mentioned two facts to select an energy-efficient node for a given task. The metrics used for measuring the energy efficiency of nodes are defined as records/joule and IOPS/watt.
Other than EESched, Yigitbasi et al. 78 have proposed two more energy-efficient scheduling heuristics, namely, EESched+Locality and Run Reduce Phase on Wimpy Nodes (RoW). 78 In EESched, a TT tt (i.e., worker nodes) is assigned a task t if it is a most energy-efficient task for tt and tt also has the input split required by the task t. In contrast, RoW scheme has been proposed only for scheduling reduce tasks. It schedules the reduce tasks on wimpy nodes that are more energy efficient for I/O bound workloads/tasks. The main advantageous feature of the EESched scheme is that it does not require workload characteristics as a priori. All discussed schedulers in this subsection are summarized in Tables 7 and 8.
Observations
We observed that the concept of job affinity (or job fitness) has been used extensively in most of the algorithms which simultaneously address workload and cluster heterogeneity. Job affinity describes how much a job is fit for a resource to be scheduled to complete its execution faster. However, in Ref., 78 job affinity/fitness is achieved to reduce overall energy consumption. Hence, job affinity is aimed to achieve various QoS objectives. Jobs are scheduled at best-matched node generally at the cost data locality to achieve better job fitness. Hence, there must be a trade-off between achieving job fitness and data locality. Most of the schedulers50,52,53,75,76 that consider multiple heterogeneity factors are task-level schedulers except COSHH. And, mainly two QoS parameters are targeted by these schedulers that are job completion time and fairness.
Conclusion
In early stages of the Hadoop system, it was homogeneous in every aspect. Recently, the diverse applicability of Hadoop system on massive data volume has grown rapidly. This leads to heterogeneity at the user and workload level. Furthermore, induction of new and powerful servers into existing data center creates heterogeneity at the hardware level. Till now, heterogeneity is the most neglected part in designing of Hadoop scheduling algorithms. Hadoop system heterogeneity limits the performance of its scheduler and adversely affects the overall system usability.
In this survey article, we discuss three factors that cause heterogeneity in Hadoop system. Then, we discuss various challenges in designing Hadoop schedulers in the presence of those factors. Till now, various MR scheduling algorithms have been proposed aiming to overcome the performance degradation due to system heterogeneity. The article classifies various Hadoop schedulers on the basis of heterogeneity factor they address. Recently, multiple heterogeneity consideration among Hadoop schedulers has become common where usually hardware heterogeneity is exploited by heterogeneous applications. All surveyed heterogeneous scheduling algorithms have been analyzed and compared on various parameters. In the end, Appendix Table 1 has been included to compare the methods and environment used for evaluation of studied schedulers.
Footnotes
Acknowledgment
This work is financially supported by Ministry of Electronics and Information Technology, Government of India, under the Visvesvaraya PhD scheme for Electronics and IT.
Author Disclosure Statement
No competing financial interests exist
Abbreviations Used
| Approach used for evaluation | Cluster heterogeneity (if any) created through | Workload used | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Algorithm | Simulation | Prototype | Physical cluster | Virtualized cluster | Cloud | Single job at a time | Set of jobs | Name(s) of jobs/benchmark | Experimental scale | Hadoop version used |
| FAIR A1 | — | ✔ | NA a | — | ✔ | Facebook's production work-load | Refer table 1 of 6th section in Zaharia et al. A1 | Not given | ||
| Capacity A2 | Research article not available. Originally developed at Yahoo, Inc. and later included in Hadoop framework with continuous refinements. | |||||||||
| Delay/HFS A3 | — | ✔ | NA a | — | ✔ | Hive | Refer table 1 of 4th section in Zaharia et al. A3 | Modified Hadoop 0.20 | ||
| DRF A4 | ✔ (For macro-benchmark) | ✔ (For micro-benchmark) | NA a | — | ✔ | NA | 48 node Mesos cluster over EC2 | NA (Mesos cluster used) | ||
| LATE A5 | — | ✔ | — | ✔ | ✔ | ✔ | — | Sort, Grep, WordCount | Refer Zaharia et al. A5 for details | Not given |
| SAMR A6 | — | ✔ | — | ✔ | x | ✔ | — | Sort, WordCount | 5 PMs, 8 VMs | 0.19.1 |
| ATAS A7 | — | ✔ | — | ✔ | — | ✔ | — | MinuteSort, Grep, WordCount | 10–15 PCs | 0.20.2 |
| 10–60 VMs | ||||||||||
| 3 clusters | ||||||||||
| EMRSA A8 | — | ✔ | ✔ | — | — | ✔ | — | TeraSort, PageRank, K-means clustering (only one at a time) | 4 nodes, 64 processor, 80 GB RAM and 4 TB disk | Not given |
| MTSD A9 | — | ✔ | ✔ | — | — | — | ✔ | WordCount, Join and Girdmix | 18 nodes heterogeneous cluster | Not given |
| Triple-Queue A10 | — | ✔ | Homogeneous cluster | — | ✔ | TeraSort, GrepCount, WordCount | 6 nodes (2 Quard Core CPU, 4 GB RAM, 2 Disk)/node | MRv1 | ||
| JATS A11 | — | ✔ | ✔ b | — | — | — | ✔ | Terasort, Grep, Web crawling, Wordcount, Video file format conversion | 12 nodes | MRv1 |
| Intel core 2 Duo, 2.4 GHz | ||||||||||
| 80 GB–2 TB | ||||||||||
| 2/4 GB RAM | ||||||||||
| LsPS A12 | ✔ | ✔ | — | — | ✔ | — | ✔ | WordCount, PiEstimator, Grep, Sort | 12 node m1.large instances in EC2 with (7.5 GB, 850 GB)/node | MRv1 |
| RAS A13 | — | ✔ | ✔ | — | — | — | ✔ | Sort, Combine, Select | 22 nodes 2.8 GHz Intel Xeon each having 2 GB of RAM | 0.23 |
| PRISM A14 | — | ✔ | Homogeneous cluster | — | ✔ | Gridmix 2, PUMA | 10 nodes (4-cores, 8 GB RAM, 100 GB Disk)/node | 0.20.2 | ||
| ESAMR A15 | — | ✔ | ✔ | — | — | ✔ | — | Sort, WordCount | 6 node physical cluster | 0.21 |
| DyScale A16 | ✔ | — | ✔ | —- | —- | —- | ✔ Set of same type of jobs at a time | Facebook workload suit | 25, 40 and 70 nodes homogeneous and heterogeneous cluster both | MRv1 |
| Medley A17 | ✔ A18 | — | Heterogeneous cluster created through simulation | — | ✔ | NA | Three different types of nodes are used | MRv1 | ||
| ProgressShare A19 | — | ✔ | — | — | ✔ | — | ✔ | Crypto, Sort | 2 VMs (1 with GPUs) | MRv1 |
| ThroughputScheduler A20 | — | ✔ | ✔ | — | — | — | ✔ | WordCount, PiEstimator, Grep, RandomWriter, self created I/O-intensive job | 5 nodes heterogeneous cluster | YARN |
| CASH A21 | Mumak A22 | ✔ | Heterogeneous cluster created through simulation and physical cluster both | — | ✔ | WordCount, TeraSort | 5 nodes heterogeneous cluster | 0.20.2 | ||
| COSHH A23 | ✔MRSIM A24 | — | Heterogeneous cluster created through simulation | — | ✔ | Facebook and Yahoo workloads | 6 node heterogeneous cluster, table 3 in Ref. | 0.21 | ||
| Yigitbasi et al. A25 | — | ✔ | ✔ | — | — | — | ✔ | WordCount, Sort and Nutch | 20 Atom +3 SNB Intel nodes | 0.20.0 |
Although a virtual cluster over EC2 has been used in evaluation that creates heterogeneity, it has not been addressed in scheduling scheme.
Heterogeneous cluster used only in evaluation.
ATAS, Adaptive Task Allocation Scheduler; CASH, Context-Aware Scheduler for Hadoop; COSHH, Classification and Optimization-based Scheduler for Heterogeneous Hadoop; CPU, Central Processing Unit; DRF, Dominant Resource Fairness; ESAMR, Enhanced Self-Adaptive MapReduce scheduling; GPU; HFS, Hadoop Fair Scheduler; JATS, Job-Aware Task Scheduling; LATE, Longest Approximate Time to End; MTSD, MapReduce Task Scheduler for Deadline; PC; RAS, Resource-aware Adaptive Scheduling; SAMR, Self-Adaptive MapReduce; VM; YARN, Yet Another Resource Negotiator.