
Abstract
Abstract
The goal of customer retention campaigns, by design, is to add value and enhance the operational efficiency of businesses. For organizations that strive to retain their customers in saturated, and sometimes fast moving, markets such as the telecommunication and banking industries, implementing customer churn prediction models that perform well and in accordance with the business goals is vital. The expected maximum profit (EMP) measure is tailored toward this problem by taking into account the costs and benefits of a retention campaign and estimating its worth for the organization. Unfortunately, the measure assumes fixed and equal customer lifetime value (CLV) for all customers, which has been shown to not correspond well with reality. In this article, we extend the EMP measure to take into account the variability in the lifetime values of customers, thereby basing it on individual characteristics. We demonstrate how to incorporate the heterogeneity of CLVs when CLVs are known, when their prior distribution is known, and when neither is known. By taking into account individual CLVs, our proposed approach of measuring model performance gives novel insights when deciding on a customer retention campaign. The method is dependent on the characteristics of the customer base as is compliant with modern business analytics and accommodates the data-driven culture that has manifested itself within organizations.
Introduction
In modern business analytics, special attention is given to the personal characteristics of customers, which highlights the data-driven culture that has manifested itself within organizations. 1 Classification problems represent one application of business analytics that exist in both industry and academia. Whether it is credit scoring, 2 churn prediction, 3 or website classification, 4 the common goal is to build well-performing predictive models that correctly classify as many instances as possible. The consequences of incorrectly classifying instances are not always very severe, but the possibility of large losses for the companies that rely on these models should not be overlooked. When designing a retention campaign for customer churn prediction (CCP), including a customer who does not intend to churn will not affect the company very much, while failing to identify a potential churner, who subsequently leaves the firm, will cause losses. However, not all customers have the same value to the company, and a retention action for some might not be profitable at all. When the companies are selecting a churn prediction model to use for their campaign, it is important to take these concerns into account and base the selection on a model performance measure that is tailored to the situation. 5
As organizations are concerned about their profit, it is reasonable to choose a performance measure that maximizes the expected profit of the potential retention campaign. The recently proposed state-of-the-art maximum profit (MP) 3 and expected maximum profit (EMP) 5 measures were developed with this objective. The latter measure of binary classifier performance has been adapted for CCP 5 as well as credit scoring, 6 in addition to having been incorporated in the construction of the classification model itself 7 and for feature selection. 8 In the case of customer churn, the measure takes into account the costs and benefits of the retention campaign, and optimizes the expected profit in addition to giving the fraction of the customer base that should be included in the campaign to achieve that MP. These values are computed using various parameters, such as customer lifetime value (CLV), the cost of contacting a customer, the cost of the retention offer, and the probability that a customer included in the campaign accepts the retention offer. Since this last parameter is typically not known and even difficult to estimate, the EMP models it with a random variable after a beta distribution. The other parameters are, however, assumed to be known. In particular, the CLV is considered fixed and equal for all customers.
CLV has been a popular research topic for some years. 9 It is defined as the present value of all the future cash flows attributed to a customer's relationship with an organization and offers the advantage to assess the financial value of each customer, with the aim of identifying the most profitable customers and to nurture long-term relationships. 10 However, as has been demonstrated in the literature, CLV is not straightforward to assess. 11 Owing to the different types of customer relationships and transaction occasions, CLV needs to be carefully modeled while taking into account the problem setting. In addition, there are both deterministic and stochastic models, which either estimate CLV purely based on historic data or model the various components of CLV using probability distributions. 12 A common and inaccurate assumption that is often made when CLV is estimated concerns the heterogeneity of the customer base. 13 Although most studies focus on a point estimate of CLV, the literature has recognized the importance of the volatility of CLV. Estimating the variance of the customers' lifetime values is important because the customer base of most companies is by no means uniform, and customers of different levels have different needs, which should be addressed at an individual level for proper customer relationship management.13,14 The EMP measure, as proposed by Verbraken et al., assumes a fixed and equal CLV for all customers.
In this article, we introduce a new way of incorporating customer heterogeneity in the earlier introduced EMP measure by allowing the CLV to vary on a subject basis. We demonstrate how this can be achieved when individual CLVs are available and—in the case when they are not—how estimates can be obtained. The result is a distribution of EMP values to which we apply bootstrap techniques to generate confidence intervals to help distinguish between good and bad models. We apply our techniques to two real-life data sets and five benchmark data sets using six distinct classification techniques and to demonstrate the usefulness of our approach, compared with the standard EMP measure and the commonly used area under the ROC (receiver operating characteristic) curve (AUC) and top decile lift measures. Since our method explicitly takes into account the variability of the customer base, it has the advantage over the traditional EMP measure to provide a range in performance, which can be beneficial when selecting a model for a retention campaign.
The rest of this article is organized as follows. In the next section, we discuss the theoretical background to our work, including both measuring of classifier performance and the computation of CLV. Subsequently, we present our extension to the EMP measure, which is the main contribution of our article. In the Empirical Evaluation section, we apply the proposed techniques to a collection of data sets and compare the results with other measures. Finally, we discuss the managerial implications of our results, limitations of our study, and opportunities for future research.
Theoretical Background
Measuring model performance
Evaluating the performance of a binary classifier is vital when comparing different models and selecting the best one. Here, we describe the fundamental terminology and methods of this process followed by a description of the more advanced H-measure and EMP measure.
In the case of customer churn, the goal of a classifier is to correctly identify potential churners, and thus assign a label to each customer as churner, denoted here by 0, and nonchurner denoted by 1.
5
After applying a binary classifier, such as logistic regression (LR), to a customer churn data set, the result is typically a score for each customer in the range [0;1], which can be interpreted as the probability of churning. By determining a cutoff value
To display classifier performance independent of the cutoff point t, the ROC curve is often used.
15
It graphically displays the trade-off between a classifier's true positive rate (sensitivity) and false positive rate (
The AUC is a numerical value between 0.5 and 1 that summarizes the ROC curve and is used to compare the performance of different models. A higher AUC value means a better performance of the classifier. Although AUC is very popular for model evaluation, it fails to take into account the cost of misclassification, which can be problematic in the case of class imbalance. In addition, it has been argued that the AUC is an incoherent measure of aggregated classification performance because the probability density that is implicitly assumed when calculating the AUC depends on the empirical score distribution of the classifier itself. 16 However, it is not incoherent when interpreted as a way of evaluating classifier performance in terms of class discrimination. 17
As an alternative, Hand proposed the H-measure, which minimizes the expected loss of a classifier, or the average classification loss, given by the function
where
where
In the case of building churn prediction models, companies tend to be more concerned about profits than losses. Therefore, Verbeke et al.
3
proposed the MP measure as an alternative to the loss minimizing H-measure. The expression for the profit of a retention campaign originates from Neslin et al.
19
and is given by
This equation describes the profit of a retention campaign based on the flow of customers from and to the customer base, taking into account the fraction of churners (
Assuming that
and neglecting A leads to the average classification profit of a classifier for customer churn
which means that
Verbraken et al. assumed that all the parameters could be estimated, except
The value of EMP can be computed using an empirical convex hull.5,16 Finally, based on these calculations, the expected profit maximizing fraction for customer churn is given by
and represents the optimal fraction of the customer base that should be targeted in the campaign to achieve the EMP. The fraction is an advantageous side product of the EMP measure, since a cutoff does not have to be determined explicitly. We refer to the MP measure as the standard EMP.
The last performance measure we apply when evaluating our models is the top decile lift. 18 It is commonly used for customer churn models as it compares the ratio of churners in the 10% of customers with the highest predicted probabilities to the ratio of churners in the actual customer base. Thereby, it represents how much better a prediction model is at identifying churners, compared with a random sample of customers.
Customer lifetime value
CLV, defined as the net present value of the cash flows attributed to the relationship with a customer, is a popular research topic as well as being important in the industry.10,12,20 One of the first general overviews of the CLV literature identified three categories of CLV research directions, namely development of models for calculating CLV, models of customer base analysis, and normative models of CLV, which are mostly used to understand the issues with CLV. 21 Most studies mainly distinguish between deterministic and probabilistic models, making a point of the former being more suitable for individual calculations, whereas the latter are more adequate for estimating CLV at the cohort level, because they take into account the heterogeneity of the customer base as a whole. 22
Aside from the modeling approach, the customer base is generally regarded as having two dimensions, the type of contract and transaction occasions. The first dimension describes the relationship with the customer, which is either contractual or noncontractual. An example of the first is a customer who has an account in a bank or a telecommunication customer with a fixed contract. Noncontractual relationships are, for example, a customer of a supermarket. The second dimension is the time of purchase, which can be either discrete or continuous. This is illustrated with examples given in Table 2. Each of these settings requires a different modeling approach.
There are numerous challenges of computing and using CLV, with many issues and various components that affect those issues. 11 When CLV is computed, it is often assumed that the customer base is homogeneous, which has been shown to be invalid.22,23 Although most studies focus on estimating the mean value of CLV, it is widely acknowledged in the literature that the variance of CLV is more important.12,24 To account for this, McCarthy et al. 14 proposed a novel way to derive, predict, and validate the variance of CLV using a combination of stochastic models.
Applications where customers are assumed permanently lost once they terminate their relationship with a company are called “lost for good.” Alternatively, “always a share” scenarios assume that customers, who typically do business with multiple organizations, yet always stay with the firm to a certain extent.
25
Gupta et al.
12
presented a universal expression for computing the “lost for good” CLV in terms of the price pt paid by the customer at time t, the cost ct of servicing the customer at time t, the discount rate r, the probability rt of a customer being alive at time t, the acquisition cost AC, and the time horizon T with
This expression can be used to compute CLV for both types of relationships, and transaction occasions, and its components can be modeled with both deterministic and stochastic approaches. Multiple derivations exist, where the expression has been simplified and the different components computed in various ways. However, in practice, the most common way to compute CLV is by means of recency-frequency-monetary (RFM) variables.
The type of customer base we consider in this study is contractual and continuous and the relationship is furthermore viewed as “lost-for-good.” Therefore, in the empirical evaluation of this article, CLV is computed in a similar manner as in Glady et al.
9
using a deterministic approach. There, CLV of customer i at time t is defined as the sum of cash flows CF
where r is the discounting factor, h the time horizon for which CLV is calculated, q the number of products that contribute to the final value, and the net cash flow
where
Modeling Variable EMP
Incorporating the heterogeneity of CLV in the EMP
In the EMP measure,
As before, we disregard A and use the same substitution to get the average classification profit
where
where t is the optimal threshold as before. Note that in the case of constant CLV,
Therefore, we proceed to compute separate EMP values for each instance in the vector of the CLV. Summary statistics of the EMP vector can be explored to gain insights into the customer base. In the following analyses, we compute both mean and median values of the EMP vector to estimate model performance. We refer to this version as
Estimating the EMP distribution
Estimating CLV each time a churn prediction model needs to be evaluated may not be feasible. However, once the values have been calculated once, there is knowledge about their distribution that can be exploited in subsequent computations of the EMP. To this end, we assume that each CLV is a random variable that follows a beta distribution of the second type, or
When the prior distribution of the CLVs is known, the parameters of the distribution can be calculated using either the maximum likelihood method or the method of moments.
26
Since the maximum likelihood equations for the
respectively. This system of equations can be solved for
To obtain a vector of CLV for the customers, we draw a sample of size N from the distribution
In addition, bootstrap methods can be used to estimate confidence intervals for the sample statistics of the
Evaluating CLV of customers correctly can be a time-consuming and difficult task that may not be beneficial when it is only needed to measure the performance of churn prediction models. When an organization knows neither the CLV of their customers nor its prior distribution, it is still possible to make use of the methods we have proposed here. To do so, reliable estimates of parameters
Empirical Evaluation
Data sets and CCP modeling
We demonstrate the usage and benefits of our new approach for churn prediction. Table 3 provides a summary of the data sets that we use in our experiments. The first data set (Bank) was provided by a retail bank in Belgium. It spans 3 years of information about the usage of products and services for >0.5 million customers, aggregated at a monthly level. Being rich in the number of features, this data set offers a high potential for accurate estimation of CLV of the customers. In addition, knowledge of actual churners and their churn dates is available.
The second data set (Telco) comes from a telecommunications company in Belgium. It consists of both customer information, such as demographics, usage, and handset data, and call detail records (CDRs) spanning 6 months for >1 million customers with postpaid contracts. The CDRs, which are logs of phone call traffic used for billing purposes, are used in the estimation of the CLV. This data set has a similar churn rate as the Bank data set, with a high class imbalance.
The remaining five data sets are publicly available and have been used in a number of studies.3,28 They are both limited in number of observations and features but are included here to demonstrate how our method can be used when CLV is not computable.
For the two real-life data sets, we build churn prediction models following standard methods 29 using the binary classifiers LR, decision trees (DTs), and random forests (RFs). These classifiers were chosen because of their popularity in both academia and industry. 5 LR and DTs are intuitive and easy to interpret and are, therefore, held in high regards, especially in fields where black box models are not feasible. RFs have been shown to be very powerful when it comes to accurate predictions, but being an ensemble of DTs, it is difficult to comprehend the underlying model. 6 In addition, we use extreme gradient boosting (XGB), artificial neural networks (NN), and support vector machines (SVMs) with radial basis function kernels to predict churn in the data sets D1–D5, to further evaluate our proposed approach. These are all powerful techniques that have been successfully used in the literature to predict churn.31–33
Except for the Bank data set, the other data sets were randomly split into training set with 70% of the observations and a validation set with the remaining 30% of observations. The Telco data set spans 6 months, and the first 3 months of the data were viewed as the historical information about the customers and used as attributes to predict churn in the last 3 months. Because of the long timeframe of the Bank data set, the first 1.5 years was used for training and the last 1.5 years for validation, resulting in an out-of-time experimental setup. When applicable, models were trained using 10-fold cross-validation on the training set to tune parameters, and subsequently evaluated by applying the final models to the validation sets.
To evaluate model performance, we use AUC, H-measure, top decile lift, and EMP, with default values for the parameters, that is, CLV = €200, d = €10, f = €1,
Figure 1 shows an overview of each step of the empirical evaluation.
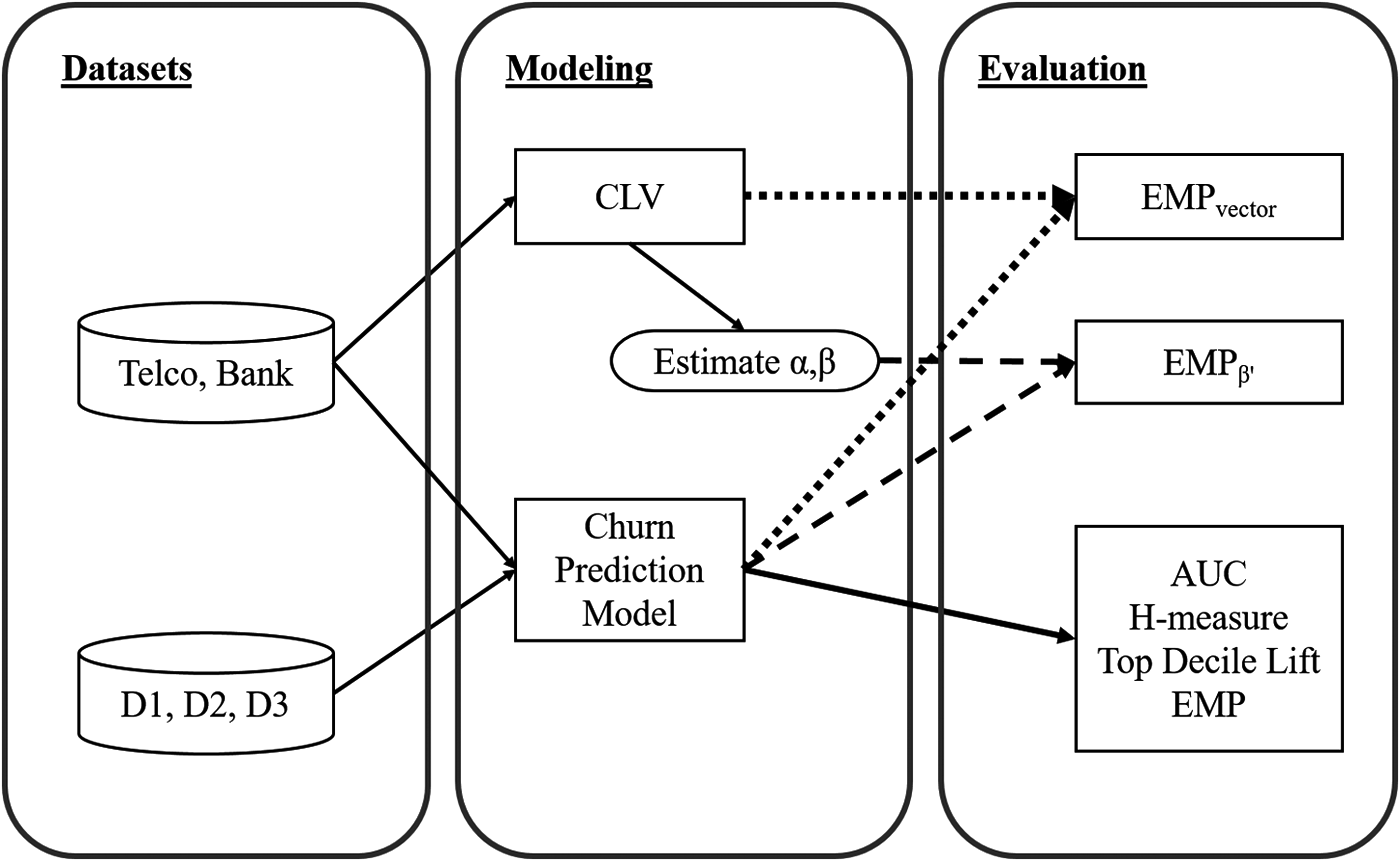
The experimental setup. AUC, area under the ROC curve; CLV, customer lifetime value; EMP, expected maximum profit.
Estimating CLV and distribution parameters
We need the customers' lifetime values to obtain a distribution for the EMP. As the Bank and Telco data sets contain rich enough information to estimate CLV, we proceed using Equations (2) and (3). For the Bank data, we considered the usage of a single product—bank accounts—for a time horizon of 6 months with the aggregated account balance at the end of the month and total amount debited during the same month. In these calculations, we assume that the product yield
In the case of Telco data sets, the CLV was computed with data from the last 3 months, based on contract information from the telecommunication provider. For postpaid contracts, the monthly subscription fee is €15, and includes unlimited number of text messages and 120 minutes of phone calls. Each additional minute costs €0.15. A decision was made to omit the discounting factor in these calculations because the time period was only 3 months.
The five remaining data sets in Table 3 do not contain enough information to compute CLV. As we know they are from the telecommunication industry, we can still apply our suggested approach if we have knowledge about the distribution of CLV in similar businesses. Four additional CDR data sets, originating from a telecommunication provider in Belgium, were, therefore, used to compute CLV as described for the data set Telco to estimate reference values of parameters
CDR, call detail record.
The parameter estimates given in Table 4 show that estimates for the
The parameter estimates can be used as a reference by telecommunication providers that wish to evaluate their churn prediction models using
Results when CLV is known
First of all, we look at Figure 2, which demonstrates the value of the regular EMP and EMP fraction as a function of CLV for the data set Telco. What these figures show, especially the first one, is that there is a linear relationship between these two parameters, and, therefore, that using a fixed CLV may give predictable results. This relationship is not as strong for the EMP fraction, but it is noticeable that it converges to 1 when the CLV gets close to 50,000.
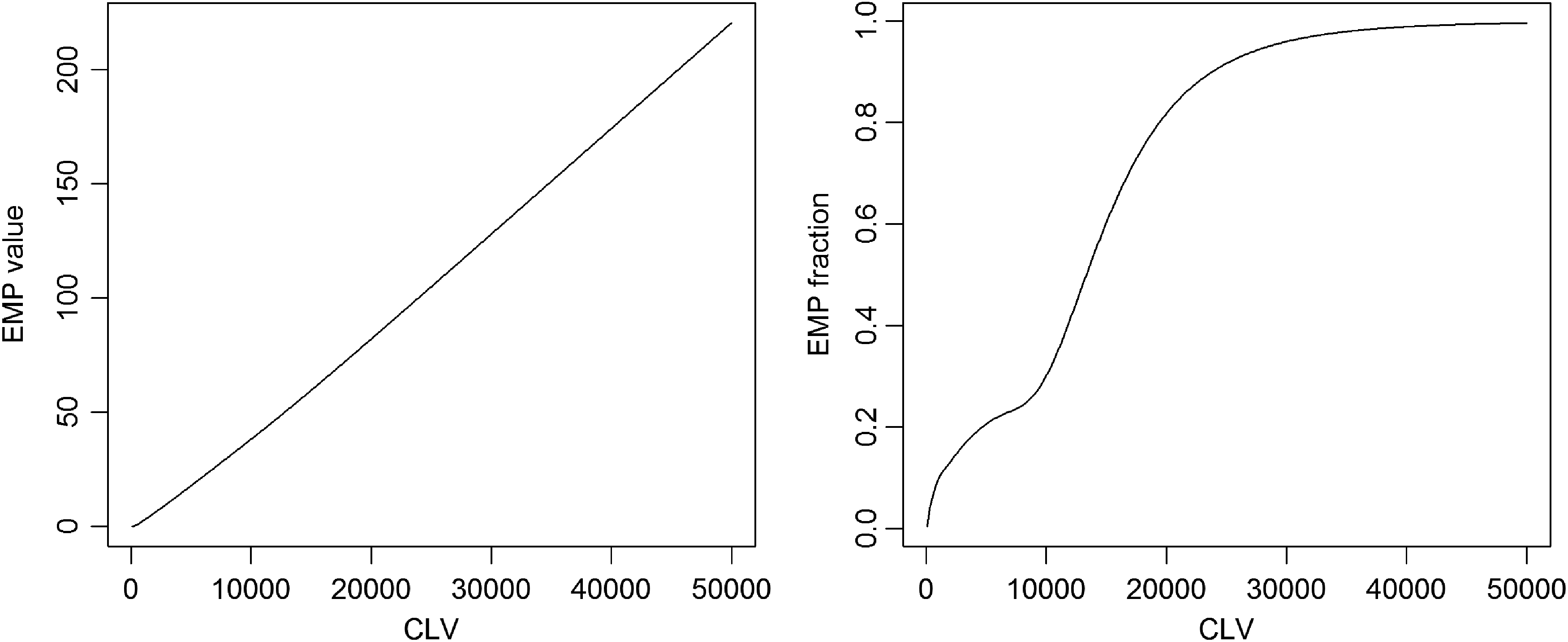
EMP and EMP fraction as functions of CLV.
Next, we look at the comparison of the performance measures for the data sets wherein the CLV is computable, namely the data sets Telco and Bank, see Table 5. The table shows the performance of the three types of models LR, DT, and RF measured in AUC, H-measure, top decile lift, and the regular EMP measure. We used the computed vector of CLV to compute
AUC, area under the ROC curve; DT, decision tree; EMP, expected maximum profit; LR, logistic regression; RF, random forest.
The various performance measures given in Table 5 do not agree on the best model. For the Telco data set, for example, DT outperforms in terms of top decile lift but performs worst when measured in terms of AUC and H-measure. The LR model scores worst when measured in terms of top decile lift and EMP, but second best according to all other measures. Even the mean and median values of
Results when CLV is unknown
We already mentioned that in cases when CLV cannot be computed, for example, when the appropriate data are not available, our method can still be applied. We demonstrate this in the case of telecommunication providers using the five additional data sets, D1, D2, D3, D4, and D5 in Table 3. They all originate from the telecommunication industry, and we used the
The model performance measured in terms of AUC, H-measure, top decile lift, and the standard EMP as well as mean and median of
The highest value for each performance measure within each data set is underlined. In the case of AUC, the values that are not significantly worse than the best one, at the 95% confidence level, based on the test by DeLong et al. 33 For the other measures, only the highest value is underlined.
NN, artificial neural networks; SVM, support vector machines; XGB, extreme gradient boosting.
We conclude this section by looking at the distribution of the performance values. Figure 3 shows a combination of a boxplot and scatterplot for five of the six performance measures in Table 6. Each boxplot displays the distribution of one performance measure and by connecting the measurements of the same model (dotted lines), we obtain a visualization of the correlation between the performance measures. Based on this figure, we make the following observations. First, the fact that the lines between the AUC and the H-measure hardly cross indicates that they are highly correlated. This confirms earlier research.
18
Next, the lines between AUC, top decile lift, and EMP cross to a great extent, and are thus not correlated. This means that they measure the performance in alternative ways. Finally, there is almost a one-to-one correspondence between the EMP measure and the
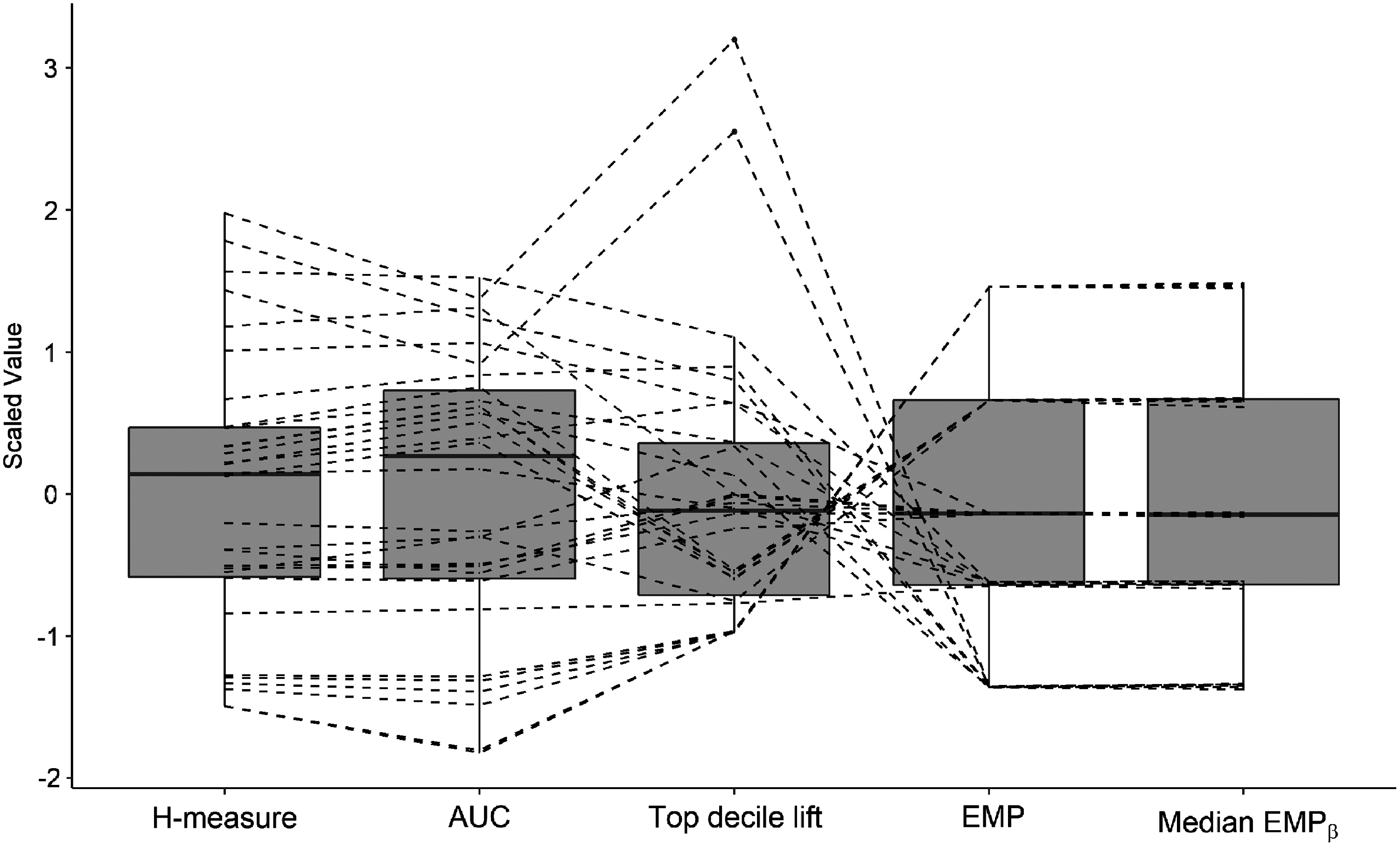
Boxplot and scatterplot showing the correlation among the performance measures.
Managerial Implications
Customer retention is a prevailing problem in many businesses, which makes the design and implementation of campaigns that target the most likely churners an essential part of their operations. From a business perspective, it is furthermore important to not overlook the churners that are most profitable for the business—should they remain. The EMP measure provides a way to assess the profitability of a retention campaign, but with the disadvantage of assuming equal CLVs. To gain deeper insights into customer behavior, our approach shows how the measure can be personalized, thus tailoring the performance measurement to the variability in individual CLVs.
Customer data within organizations have reached unprecedented volumes and keep growing every day. As a result, computing individual CLVs to use in the EMP measure might not be feasible each time a churn prediction model is implemented, since extracting and preparing the data are time consuming and costly. However, as we have demonstrated, the operational costs can be reduced by estimating the parameters of the CLV distribution once and applying the EMP measure with simulated values. Although individual CLVs may be subject to change, the collective CLV distribution typically remains stable for a longer time period. This approach furthermore allows for the computation of confidence intervals for our proposed
Table 7 shows 95% confidence intervals for both mean and median of the
Furthermore, organizations that do not have the opportunity or the resources to compute lifetime values of their customers can make use of our approach. By relying on parameter estimates from similar businesses, they can achieve estimates for EMP and their corresponding confidence intervals, as we demonstrated for telecommunication companies. Table 7 gives the confidence intervals for the mean and median

Confidence intervals for median
The EMP measure is not only applicable for evaluating churn prediction models. It can be applied to credit risk modeling, time series forecasting, and, consequently, provides increased model interpretability, enhances operational efficiency, and adds value to other businesses as well.
Conclusion
Measuring the performance of CCP models is an important task, especially in organizations that, in addition to being concerned about their own profit, strive to retain their customers in saturated and competitive markets such as telecommunications and banking. In addition, the effectiveness of implementing such models can be increased if the way in which they are measured is tailored toward the problem at hand. This is the case for the EMP measure, which computes the EMP of a retention campaign. This measure of model performance depends on the CLV and it is, therefore, feasible to take into account its naturally occurring variability and heterogeneity when estimating model performance.
We have demonstrated how this can be achieved, both when individual CLVs have been computed and when information about their distribution is available. The results are presented in both cases. When CLV is known, we can compare both mean and median value of the EMP vector to other performance measures, and when the distribution is known, confidence intervals can be extracted to further distinguish actual separation in performance between two models. This extension to the expected maximum profit measure is therefore more informative, as it can be used by practitioners to determine whether there is a significant difference between the performance of two models in terms of EMP. Our proposed extension of measuring the EMP accommodates the data-driven culture that has manifested itself within organizations. It can aid in selecting the best performing model for deployment in retention campaigns. By taking into account the variability in CLV, it focuses on the heterogeneity of customers as is compliant with modern business analytics. Even for on-going customer retention and attrition in fast moving markets, we have demonstrated how the prior knowledge about customers' lifetime values can be used to conveniently measure model performance, in a way that is most beneficial for the company.
We conclude this article with a discussion about its limitations that can be used as a foundation for future research. First, the CLVs were computed in a simple way, since the goal was only to demonstrate how to use them in the EMP measure. In a real-life setting, they should be modeled more carefully. In addition, we have assumed that the CLV follows a
Footnotes
Acknowledgments
The research was funded by the Flemish Fund for Scientific Research (FWO) and a Belgian bank.
Author Disclosure Statement
No competing financial interests exist.