Many big data applications require real-time analysis of continuous data streams. Stream Processing Systems (SPSs) are designed to act on real-time streaming data using continuous queries consisting of interconnected operators. The dynamic nature of data streams, for example, fluctuation in data arrival rates and uneven data distribution, can cause an operator to be a bottleneck one. Scalability is an important factor in SPS, but detecting bottleneck operator correctly and scaling it without affecting application execution are challenging. A stateful operator such as aggregation or join makes scaling operation more difficult as it involves state management. Current research does not address the issue of scaling stateful operators efficiently as mostly stop application for handling state, which results in significant overheads to the performance. In this article, the key idea is to detect bottleneck operator correctly using the runtime bottleneck detection approach and then scale out this operator and manage its internal state in a way that we can achieve almost zero latency. During the bottleneck detection process, we have defined alarming_threshold, a parameter for the operators that can be bottleneck operators in the future and scale_out_threshold, when the operator is bottleneck. To scale out, we have presented two techniques, active backup and checkpointing, the former one will start a Secondary Execution (SE) in back end by partitioning state and input streams to multiple nodes at alarming_threshold; this SE will replace primary node at scale_out_threshold. In the latter technique, a State Manager (SM) module will start state checkpointing at alarming_threshold to external store and perform scale out by managing state and input stream at scale_out_threshold. The first approach will help us to achieve almost zero latency goal, while the latter one is a resource efficient technique. Our results show that both techniques are working while providing desired goals of reducing overall latency during scale out and improving resource utilization.
Introduction
There are a number of big data applications that require real-time and continuous complex analysis of heavy data streams without any latency. Typical applications are online social network analysis, including topic and trend follow-up, credit card monitoring system, Global Positioning System (GPS)-based monitoring system, and video surveillance systems. These applications require streaming data analytic platforms, which focus on velocity of data. Stream Processing System (SPS) supports continuous and complex analysis on big data while providing low latency, and for this purpose SPSs execute continuous queries. Some of these SPSs include Storm,1 Apache S4,2 and Apache Flink,3 designed to process data streams using a serial of operators at runtime to provide results in a very short span of time.
Streaming queries consisting of operators such as filter, join, aggregation, and some user-defined operators, which take input streams, perform desired logic and then deliver results as output. These operators can be stateful operators such as aggregation and join, and have some internal state as well as stateless operators. Input data streams are normally subject to fluctuation in data arrival rates and uneven workload variations, causing some operators to be overloaded and finally resulting as a bottleneck operator. It requires identifying the right bottleneck operator and then scaling the application by increasing or decreasing the number of instances of the operator. Stateless operators are somewhat easier to scale in or out with respect to stateful operators, as for the latter, it requires extra effort in terms of state management during scaling operations, as system has to ensure application semantics while dealing with the state of operator. The result of scaling operation should be cost-effective as well as efficient.
A horizontal scaling operation can be performed, but most of the current SPSs consider either operator stateless or put burden on application developer to handle state. Some research4,5 proposed methodologies for scaling a stateful operator, but their solutions are based on static configurations or heuristic-based assumptions, which may result in an improper scale operation; some others6 were also introduced to wait until some stateful operator fails due to overload and then perform failure recovery and scale out at the same time.
Previous works by Humayoo et al.7 and Zhai and Xu8 are related to finding a bottlenecked operator properly, using different execution-related parameters. We made some changes to fuzzy logic-based bottleneck detection8 to decide when we have to scale out and which operator requires scaling operation. This will help us to avoid improper scaling operation. In this research, we concentrate on efficient management of stateful operators by performing scaling operation as per requirement. In this regard, at first, we find out a bottleneck operator using the runtime bottleneck detection approach and during the bottleneck detection process we have defined alarming_threshold, a parameter for the operators that can be a bottleneck operator in near future and scale_out_threshold when the operator is bottleneck. After the bottleneck detection, we perform the scaling operation; for this, we have proposed two techniques, active backup and checkpointing. Our proposed solution handles the internal state of the bottleneck operator and then performs scaling operation for this operator dynamically.
In the active backup technique, we have introduced a Secondary Execution (SE) module to handle state of the stateful operator and its respective input streams. When an operator approaches the alarming_threshold SE, we will start active backup in back end by scaling out processing of this operator to multiple new nodes as per requirement. SE will split state of the primary operator and input streams on to new nodes in such a way that these new nodes will become a replica of the primary one. During all this, the primary operator will keep on working without any interruption. If operator hang-up due to bottleneck (at scale_out_threshold), this active backup will take over the primary operator. During all this we are not stopping application execution, but SE will start new nodes at back end and stop the bottlenecked operator.
We also propose a state checkpointing mechanism, as per requirement, as our second solution to handle scaling out a bottleneck operator. For this technique, State Manager (SM) module will use some external data store to checkpoint state of the operator reaching to alarming_threshold and once it reaches to scale_out_threshold, SM will scale out this operator, replaying checkpointed state, and finally running these new operators as part of the main application stream. This technique will result in efficient utilization of available resources.
We have implemented proposed techniques in Apache Storm, and our results show that we have achieved desired goals. The remainder of the article is organized as follows: the Bottleneck Detection section is related to bottleneck detection. The System Model section is about system model and the State Backup and Scale Out section presents our state management techniques. The Integration Design and Evaluation sections provide integration design and results, respectively. Related work is presented in the Related Work section and conclusion in the Conclusions section.
Bottleneck Detection
The reason behind the scale out operations in SPSs is bottleneck operators, as these operators increase overall latency in applications and do not allow SPSs to increase throughput. Most of the systems focus on how to scale out different types of operators based on an on-demand infrastructure or use some static measures of resource consumption, or some use heuristics to identify bottleneck operator.6 This may result in invalid detection leading to wrong scale out operation.
At first, it is required to find out the right bottleneck operator at runtime using proper measures of CPU utilization, memory usage, and data size, and then scale out only this operator. Zhai and Xu8 proposed a fuzzy logic-based runtime bottleneck inspection, and by using this technique, we can place some check on those operators that are going to bottleneck. In that research, we have used fuzzy logic-based runtime bottleneck inspection and during the process of defuzzification we calculated the center of gravity of output signal obtained after the evaluation of different rules. The output of defuzzification is a number range from 0 to 100, and it was divided into three sections corresponding to scale by imposing two thresholds (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \delta _1}$$
\end{document}, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \delta _2}$$
\end{document}), that is, a node can be chosen for scale out if O(x) > \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \delta _2}$$
\end{document} (scale-out threshold), or scale in when O(x) < \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \delta _1}$$
\end{document} (scale-in threshold) and keep unchanged in other cases.8
We have targeted \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \delta _2}$$
\end{document} and added another parameter, the scale from 0 to 100, and called it alarming_threshold (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \delta \prime _2}$$
\end{document}). We assume that operators which are at \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \delta \prime _2}$$
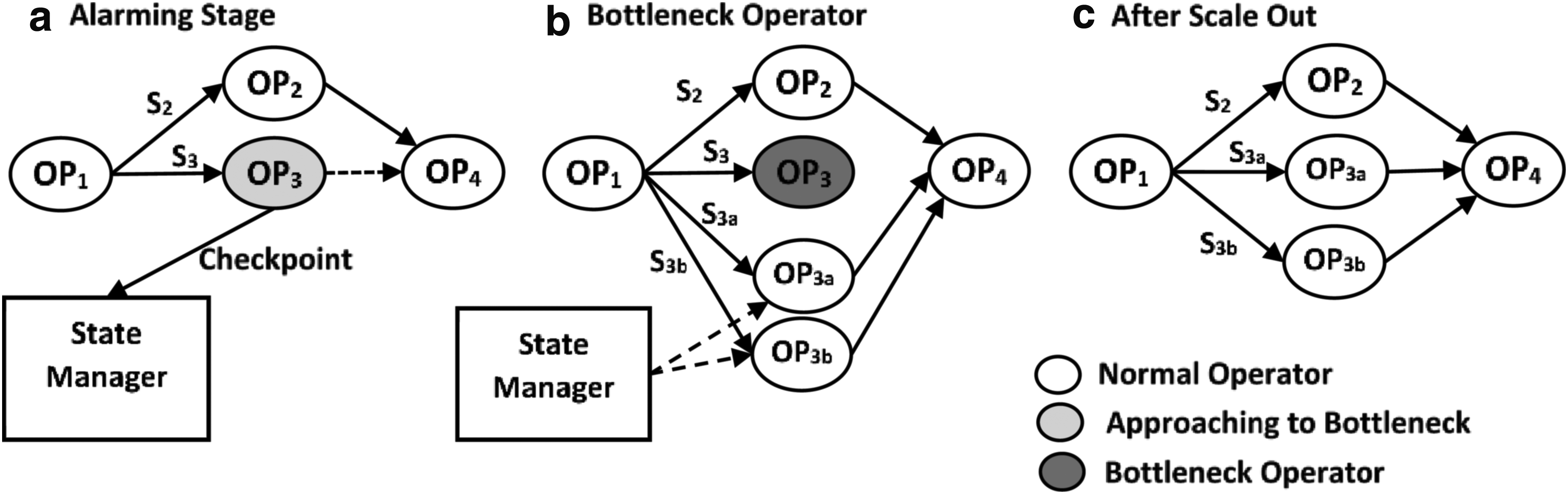
\end{document} can be bottleneck operators in near future, and at this stage, we start backing up state of this operator, as depicted in Figure 1.
Operator load.
For the algorithm presented by Zhai and Xu8 to test if the node is overloaded or not, we made slight changes to handle alarming threshhold.
From line 15, if statement checks for scale_out_threshold to test if node is bottleneck, then activate SE setup (described in the next section) as primary. And on line 18, if statement checks that either the node is approaching bottleneck or not in near future by checking alarming_threshold and if it happens, it starts SE as active backup server. We discuss working of SE in the Active Backup section. We also have to be careful about not using extra resources if current resources are working fine, so we added another check on node to test if SE was started in the past on approaching node at alarming_threshold, and now node is working as normal routine then stop SE as active backup; this is performed in line 20 and 21. Line 22 checks for when the system has to perform scale in by tracking scale_in_threshold. Details of bottleneck detection algorithm can be found in our previous article.8
System Model
Stream model
Data stream is an infinite sequence of tuples t (t\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\in$$
\end{document}S), which is denoted as S = (t1, t2, …, tn) and each tuple has the following schema t = (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\tau$$
\end{document}, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\kappa$$
\end{document}, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\upsilon$$
\end{document}); here \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\tau$$
\end{document} denotes logical time stamp of the tuple at which it is received, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\kappa$$
\end{document} is key field, and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\upsilon$$
\end{document} denotes value of the tuple. Figure 2 illustrates our stream model.
Stream model.
Operator model
A query Q, which consists of a network of operators, is defined by directed acyclic graph (DAG) denoted as Q = (O, S), where O is a set of operators and S is stream of tuples flowing between operators. Tuples are processed by operators that belong from some continuous stream S. An operator O takes n input streams denoted by set I = {s1, s2, …, sn}, processes their tuples, and produces one or more output streams. For ease of presentation we restrict to a single output stream. Working of an operator O can be defined using the following function: \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
f ( I , \tau , \theta ) = ( O , \tau , \theta )
\end{align*}
\end{document}
The function f accepts finite set of input streams I, processes their tuples up to time stamp \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\tau$$
\end{document}, and produces output stream O till timestamp \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\tau$$
\end{document}. Here \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\theta$$
\end{document} denotes state of the operator if operator is a stateful operator; in case of stateless operator, value of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\theta$$
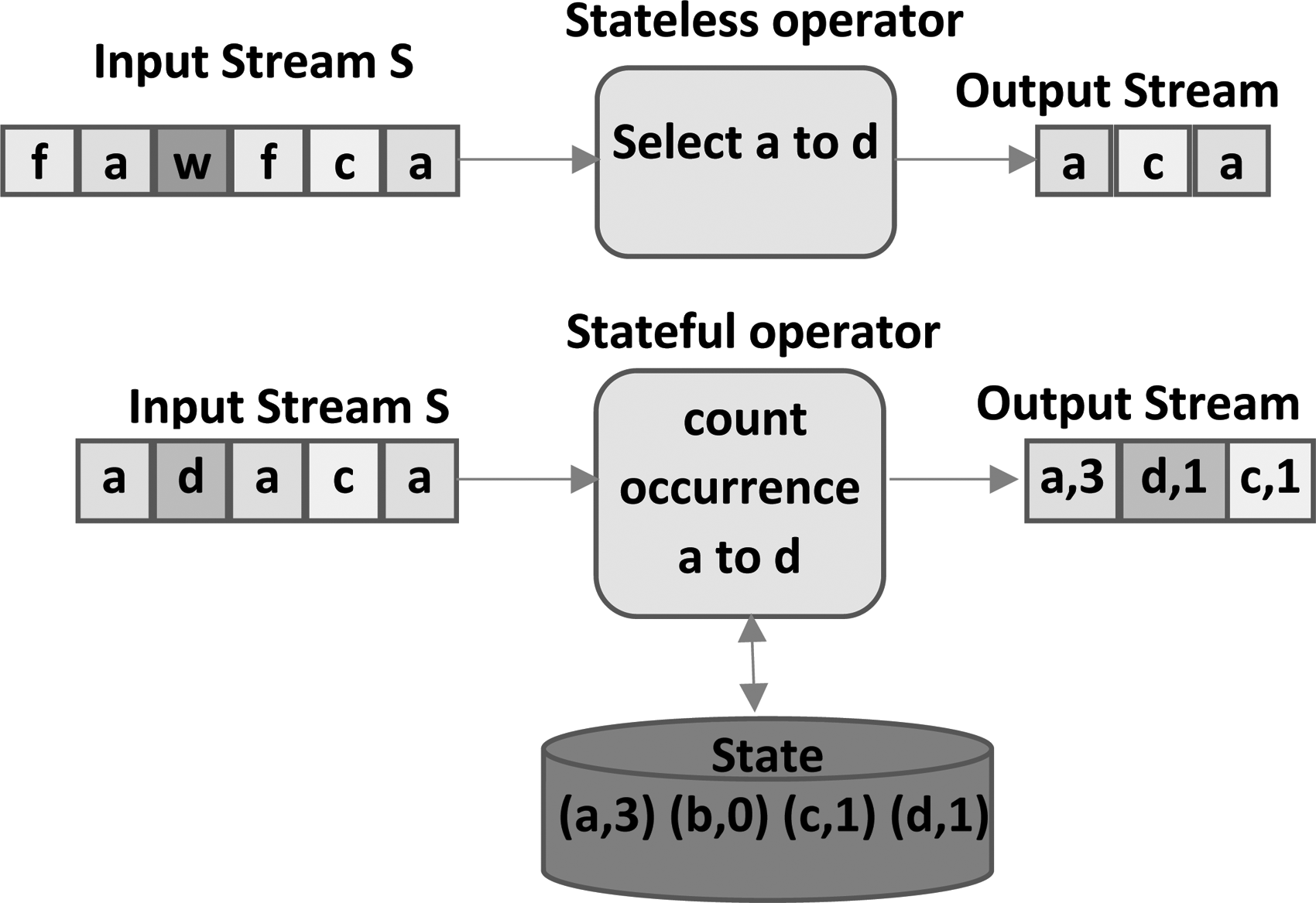
\end{document} will be null. Figure 3 illustrates our model for both stateless and stateful operators.
Operator model.
State model
Stateful operators are normally aggregation operators or join operators and in both of these operators, operations are performed based on some keys, and values of these keys manipulated accordingly. So, we can assume that these keys can be unique for these types of operators. This concept will help us to maintain state of the operator during processing and migration. We define state \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \theta _o}$$
\end{document} of an operator as a set of key/value pairs, that is, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \theta _o}$$
\end{document} = {(k1,v1), …}. Figure 4 illustrates concept of key/value state of an operator.
State model.
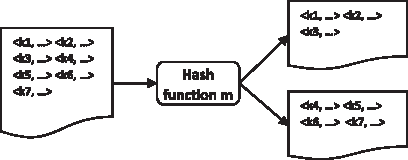
Each key is unique as well as independent of other keys and refers to a corresponding tuple key from the input streams; this will also lead to the independent state of each operator. Its associated value v stores the portion of processing state for that operator. While partitioning an operator to \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\eta$$
\end{document} new nodes, we also have to partition the key space to these new nodes so that each partitioned operator will be working independently from others. We can partition this key space using hash function \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$m:k \to [ 1 , \eta ]$$
\end{document}. Figure 5 shows partitioned states.
State partition model.
During execution at time t, the stateful operator OP has some memory M = (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\theta$$
\end{document}, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \kappa _{range}}$$
\end{document}, S) where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \kappa _{range}}$$
\end{document} is key range of OP and S is size of memory. During scale out, we have to decompose M = (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\theta$$
\end{document}, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \kappa _{range}}$$
\end{document}, S) to p partitions where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$p \in \mathbb{Z}$$
\end{document}. When M is decomposed, the resulting new partitions will also become state for newly partitioned operators. Furthermore, the composition of these partitions yields state of OP that is semantically equivalent to original. For two partitions, decomposition is shown in Equation (1).
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
compose ( {M ^{\displaystyle \prime}_0} , {M ^{\displaystyle \prime}_1} ) = M \leftrightarrow Decompose ( M , p ) = ( {M ^{\displaystyle \prime}_0} , {M ^{\displaystyle \prime}_1} ) \tag{1}
\end{align*}
\end{document}
We say partitions are semantically correct if read operation for some key \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\kappa$$
\end{document} is performed on partitioned state, the resulting output should be same if read operations are performed on original state.
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
Let \,M \prime = Decompose ( M , p )
\end{align*}
\end{document}
To scale out a bottleneck operator \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$O{P_{_i}}$$
\end{document}, we will split it into \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\eta$$
\end{document} new nodes based on the required degree of parallelism to resolve bottleneck. It is given by the following:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
O{P_i} = O{P_{i1}} , O{P_{i2}} , ..O{P_{i \eta }} \tag{2}
\end{align*}
\end{document}
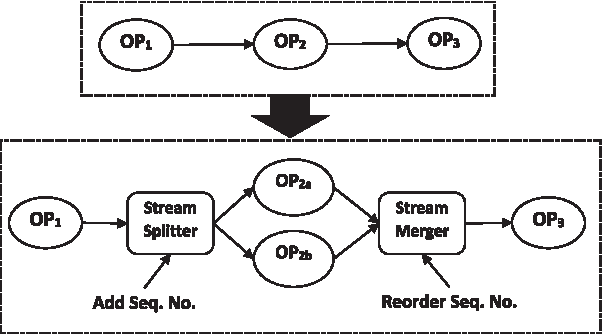
We will also partition state of the operator and its input streams. While partitioning input streams, we will add sequence number so that we can reorder these streams before forwarding these streams to the next operator, as depicted in Figure 6.
Operator scale out model.
To handle scale out for any operator OPi, a fair scale out means that resource allocation should be done well in time to solve the bottleneck.
For OPi at time t, currently assigned resources \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\Re$$
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$cu{r_{op}}$$
\end{document}(tk) \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\in$$
\end{document} [0, tk] are consumed, which can be cumulatively shown in Equation (3).
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
\Re cu{r_{op}} ( {t_k} ) = \int_0^{{t_k}} cu{r_{op}} ( t ) dt \tag{3}
\end{align*}
\end{document}
where curop(t) are the resources currently consumed by OPi at time t. To resolve the bottleneck, the total number of needed resources \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\Re nee{d_{op}}$$
\end{document}(tk) \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\in$$
\end{document} [0, tk] can be cumulatively defined as Equation (4).
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
\Re nee{d_{op}} ( {t_k} ) = \int_0^{{t_k}} nee{d_{op}} ( t ) dt \tag{4}
\end{align*}
\end{document}
where needop(t) is total required resources by OPi at time t. The fairness degree \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$f{d_{op}}$$
\end{document} for operator OPi at time tk is given by Equation (5).
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
f { d_ { op } } ( { t_k } ) = { \frac { \Re cu { r_ { op } } ( { t_k } ) } { \Re nee { d_ { op } } ( { t_k } ) } } = { \frac { \int_0^ { { t_k } } cu { r_ { op } } ( t ) dt } { \int_0^ { { t_k } } nee { d_ { op } } ( t ) dt } } \tag { 5 }
\end{align*}
\end{document}
To resolve a bottleneck, total needed resources \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\Re nee{d_{op}}$$
\end{document}(tk) are always greater than currently assigned resources \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\Re cu{r_{op}}$$
\end{document}(tk), and hence, the fairness degree \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$f{d_{op}}$$
\end{document}(tk) \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\in$$
\end{document} [0, 1] holds. It shows that if \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$f{d_{op}}$$
\end{document}(tk) = 1, then at time tk, all needed resources are provided, while a 0 value shows that the operator is still bottleneck because needed resources are not provided yet.
To obtain average fairness degree for an application [i.e., \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$F{d_{app}}$$
\end{document}(tk)] in which n operators are bottleneck at time tk, as given by Equation (6).
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
F { d_ { app } } { ( _k } ) = \frac { 1 } { n } \sum \limits_ { n = 1 } ^n f { d_ { opi } } ( { t_k } ) \quad \quad where \quad \quad f { d_ { op } } ( { t_k } ) \in [ 0 , 1 ] \tag { 6 }
\end{align*}
\end{document}
State Backup and Scale Out
State backup can be performed using active standby, passive standby, and upstream backup.9 In the active standby approach, both primary and secondary nodes are given same inputs and two nodes are processed similarly, meaning state and outputs are also the same. Output of primary node is connected to downstream node, while output of secondary node is not connected. In case of secondary takeover, it requires only connecting its output to downstream node, and this has almost nearly equal to zero delay but requires extra resources, and the cost is same as that of a primary server. In the passive standby approach, the backup server is always behind the primary server as the primary task saves its state periodically (checkpoint) to a permanent shared storage and this information is used to create state of secondary server when it takes over. So passive standby or checkpointing may offer some delay in overall system performance. The next section discusses how we have handled these techniques efficiently and effectively.
Active backup
Our active backup server technique is not as costly as that of a backup server for each primary server; rather, we are using this technique with slight changes. During bottleneck detection, when an operator approaches at alarming_threshold (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \delta \prime _2}$$
\end{document}), scale out is performed by starting secondary servers using SE module. This module will be responsible for partitioning state and input streams of primary server to new nodes. The benefit of active backup technique is that there is no need to store backup on upstream servers in the form of checkpoints, which may result in overloading the upstream server also. The other benefit is that there is no need to replay some tuples to achieve state similar to one running on primary server, which will result in time saving as well as delay avoidance. One problem of active backup technique is that it doubles the cost, but in our implementation the SE will not start any new nodes until we detect some operator approaching near to the bottleneck. So this means that we are not always running an extra server as backup of some primary server, rather we start an extra server only when it is required.
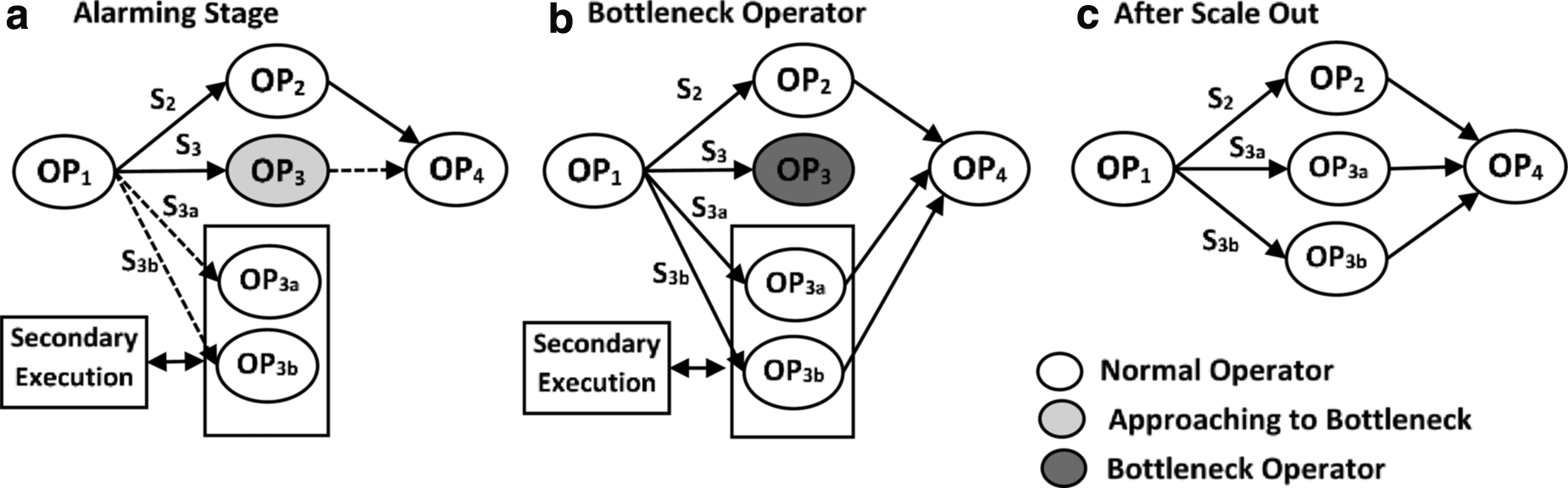
In Figure 7, the execution plan is shown with addition of SE module. As we are continuously tracking load of the node, suppose workload of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$O{P_3}$$
\end{document} is started to increase and at time t this operator approaches alarming_threshold (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \delta \prime _2}$$
\end{document}), now SE will start scale out by adding two new nodes OP3a and OP3b and when OP3 reaches scale_out_threshold, SE will replace primary server with new nodes. This active backup is not working all the time (i.e., from start of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$O{P_3}$$
\end{document}) and we are starting this active backup when OP3 will reach (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \delta \prime _2}$$
\end{document}); this will help us to reduce infrastructure cost and at the same time by using SE we are aiming to achieve zero latency in case of operator bottleneck.
(a–c) Active backup and secondary execution.
Regarding working of SE, first, we will copy state from primary node running OP3 and partition it further on two new nodes as OP3a and OP3b so that we can divide load and process OP3 with more speed (the number of new nodes can be increased or decreased as per requirement). We also have to partition data stream S3 into S3a and S3b accordingly so that both new operators should get their respective data streams for processing tuples. We should take care of splitting stream from tuple ti with time \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \tau _i}$$
\end{document}, which is the time when the state \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \theta _o}$$
\end{document} is copied to SE from OP3.
Algorithm 2 describes how state management is performed by first copying state and then by partitioning key space, the state itself, and incoming streams to new nodes in SE. During initialization when an operator reaches alarming_threshold, SE is started and copies state and time stamp \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\tau$$
\end{document} to SE (lines 1–3). As a single operator can process multiple input streams, there is a need to copy stream_ID and tuple_ID of respective streams to SE; this is performed using a loop in lines 4–6. After copying now, we have to divide key space from lines 7 to 14 and this is done by using a hash function to partition key space to \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\eta$$
\end{document} new nodes, all keys are partitioned evenly to new nodes in SE setup so that workload is divided evenly among all new nodes. In line 17, a new state \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\theta$$
\end{document} is created on each new node and we partitioned copied state \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \theta _{copy}}$$
\end{document} to \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\eta$$
\end{document} new nodes and assigned respective key value pairs (k,v) to the newly created state \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\theta$$
\end{document} (this is performed in lines 18 and 19). Finally, we have partitioned input streams of operator to available nodes in SE from lines 22 to 29; we have to be careful here that from incoming streams all tuples t should be routed to that \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \eta _i}$$
\end{document} node, having relevant partition of key space.
Checkpointing and scale out
Checkpointing saves state of operator to some storage, which allows it to be further processed in the form of scaling out an operator or restarting some failed operator from that stored state; this process is known as checkpointing. Castro Fernandez et al.6 performed scale out and fault tolerance in stream processing using operator state management, saying that operator state can be checkpointed periodically by the SPS and backed up to upstream servers. After bottleneck of some operators, this backup can be used to scale out, or in case of failure, recovery can be performed. The problem with this approach is that system is performing continuous checkpointing for every operator, which introduces an extra overhead on each operator. Also, the backup is stored on some upstream operator, which puts extra load on upstream operators. To handle this problem we are proposing a solution where continuous checkpointing is not allowed for every operator; rather, we are checkpointing only those operators that are approaching the alarming_threshold (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \delta \prime _2}$$
\end{document}) stage, and also not storing backup on upstream server.
We have introduced an SM module for the checkpointing and scale out technique to scale out the bottleneck operator. SM will handle the state first by storing its backup, which will be obtained by checkpointing the state and afterward partitioning this state to new nodes. The checkpointed state will contain (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \theta _o}$$
\end{document}, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \tau _o}$$
\end{document}, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \beta _{_o}}$$
\end{document}), where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \theta _o}$$
\end{document} is state of operator, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \tau _o}$$
\end{document} is time stamp of most recent tuple, which is processed and reflected in state, and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \beta _o}$$
\end{document} is buffer attached to the operator to temporarily hold tuples flowing from upstream operator to downstream operator. Remember the system will not always be doing checkpointing. The process of checkpointing will start when the operator approaches alarming_threshold (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \delta \prime _2}$$
\end{document}). The checkpoint state is executed now onward asynchronously and triggered at every checkpointing interval c, or after a user-defined event, for example, when the state has changed significantly. After the operator state was backed up, the processed tuples from output buffers in upstream operators can be discarded because they are no longer required to process.
Suppose, as shown in Figure 8, OP3 is near bottleneck, which means it is at alarming_threshold (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \delta \prime _2}$$
\end{document}), we have to start checkpointing for this operator to SM, and when this operator reaches at scale_out_threshold (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \delta _2}$$
\end{document}), SM will start new nodes OP3a and OP3b and partition the checkpointed state and tuples stored in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \beta _o}$$
\end{document} to new nodes and process these tuples. At the same time, also partition input streams and route the partitioned streams to new nodes and start processing new nodes.
(a–c) Checkpointing and scale out.
Algorithm 3 describes how the process of checkpointing and scale out works. On approaching some OP at alarming_threshold (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \delta \prime _2}$$
\end{document}), we start backing up its state using checkpointed state (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \theta _o}$$
\end{document}, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \tau _o}$$
\end{document}, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \beta _o}$$
\end{document}) and store it to SM (line 2). When operator O approaches to scale_out_threshold (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \delta _2}$$
\end{document}), the SM will start partitioning its key space to \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\eta$$
\end{document} new nodes by using a hashing mechanism (lines 4–11). Now SM will partition state of operator by obtaining a copy from the most recent checkpointed state; for this purpose, SM first creates an empty state on each new node (line 14) and then assigns key value pairs from \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \theta _0}$$
\end{document} to a newly created state (line 16), this will complete state partitioning process. Now we will distribute tuples stored in buffers \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \beta _o}$$
\end{document} toward the respective node (line 22) and process these tuples on that node (line 23). Now new nodes are ready to process input streams, but we will partition the input stream So to \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${S_ \eta }$$
\end{document} (lines 27–34). New nodes have started processing input streams for which they will produce some output streams; we have to make sure when output streams of new nodes and output streams of the bottleneck nodes are same, and once this is achieved, we will stop bottleneck node and route output streams of new nodes to downstream operator.
Integration Design
We have added our state management system using Apache Storm, which is a poplar stream processing system (SPS). It is a free and open source project under the umbrella of Apache Software Foundation.
Apache storm
Some key abstractions in Apache Storm include tuple, which is an ordered list of key/value pairs and a stream that is an unbounded sequence of tuples. A streaming application is represented by a topology called DAG that contains operators as nodes and links between operators denote flow of streams. Operators can be spouts or bolts, which contain actual processing logic; spouts represent the source of streams while bolts process input streams to produce results. Bolt can run functions such as filter, aggregate, join, or connectivity to some database.
There are two types of nodes in Storm Nimbus and Supervisor. Nimbus is master node and is responsible for scheduling tasks to worker nodes. Once scheduling is done, the plan is communicated to worker nodes using ZooKeeper,10 which is a shared memory service for communication among distributed systems. Supervisor is a slave node having one or more worker processes and it assigns tasks to workers, each task may run as single or multiple executors. A topology is submitted to Nimbus, which gathers tasks to be executed and distributes these tasks to available Supervisors. Storm parallelizes operators to increase the throughput.
Bolts are by default stateless and to handle stateful operators it requires maintaining state in the memory as Map or any other data structure, but when worker or node fails this state is lost. Currently, state persistence is only achieved through regular checkpointing to a remote Redis11 store. This feature was introduced in Storm 1.0.0, which has its own limitations, as described in the Bottleneck Detection section.
Integration with storm
Our proposed dynamic state management framework is a lightweight module integrated with Storm to check for bottleneck operator and then scale it out by handling state using our proposed approaches, that is, active backup and checkpointing and scale out. Currently, Storm has four kinds of built-in schedulers and also allows implementing your own scheduler to assign executors to workers. We run a customized scheduler by configuring the class to use the “storm.scheduler” config in storm.yaml and also implemented IScheduler interface in Storm default scheduler, hence replacing default scheduler of Storm.
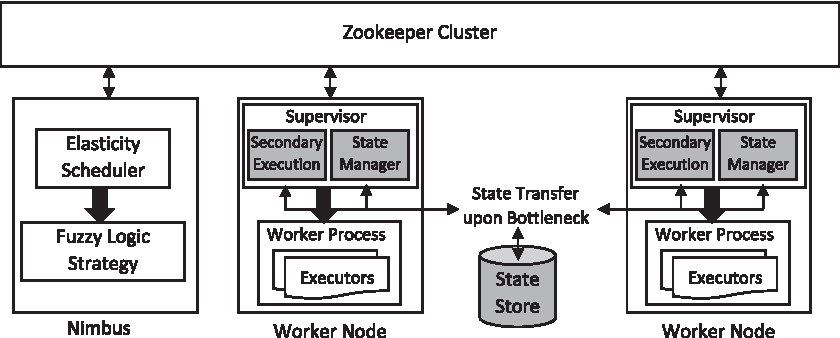
We used scheduler and fuzzy logic strategy modules from our previous work by Zhai and Xu.8 The SE module is responsible for scaling operations related to our active backup technique, while SM module will handle scaling operations for checkpointing and scale out technique. We have also added modules for state storage and retrieval where we have used in-memory data store Redis.11Figure 9 shows the architecture of system integration with Storm.
Integration with Storm, where newly added modules are highlighted in gray.
Evaluation
Next we evaluate our approach for dynamic state management for stateful operators in SPS. At first, we have tested the effectiveness of our approach using an application having stateful operators. Moreover, we tested our approach for application latency and application performance by analyzing throughput and latency measures. We have tested by enabling and disabling our approach and also by comparing the state persistence mechanism offered by Storm.
Experimental setup
We ran the experiments using Storm v1.1.2, using a cluster of three nodes, each configured with three worker nodes, and so, a total of nine workers are running. Among the three nodes, one machine is with 6 GB RAM and the other two having 4 GB RAM with Core i5 CPU at 2.30 GHz processors. We ran additionally Nimbus and Redis services on machine with 6 GB of RAM.
To test the effectiveness of our approach, we tested an application of frequent pattern detection, and for pattern generation, we have used an offline stream data producer, JSON-Data-Generator (JDG).12 This is an open-source project, which can generate a real-time stream of JSON data. We have integrated it with our application to generate different patterns, and a detector operator (stateful operator) maintains a counter for the appearances of these patterns.
Results
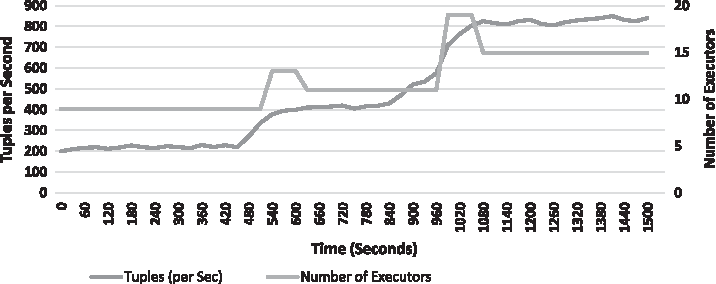
To test for elasticity, we have tested both of our techniques in the same manner described below. To test for elasticity, we configured stateful bolt to increase the number of executors to double in case of bottleneck, starting at two executors for spout and five executors for stateless bolt and two executors for stateful bolt. We started with simple workload 200 tuples per second and increased it continuously by almost doubling the rate after every 500 seconds. Figure 10 shows scale out for our active backup technique. It depicts that each time we increased load, bottleneck was detected and scale out operation is performed. After scaling it out, the number of executors was increased with respect to the scale out ratio set for stateful bolt. During the first scale out operation, the number of executors was raised to 13, but when the SE (in case of active backup) or in case of checkpointing option, our newly added executors taken over the bottlenecked operator number of executors became 11. This is because in our implementation we continue to run bottleneck operator until backup has taken over. Once backup nodes started to work as normal nodes, bottleneck operators were stopped to release the resources.
Scale out for active backup.
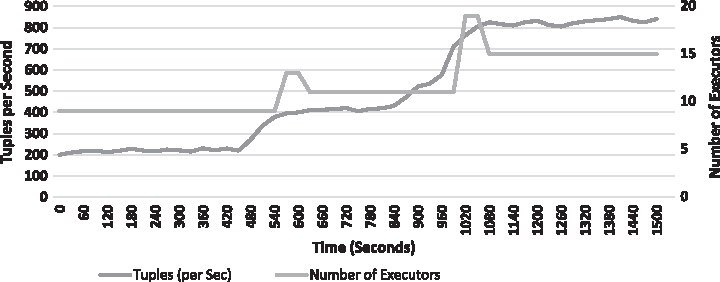
Figure 11 shows scale out for our checkpointing technique. Scale out behavior for both techniques is the same, but there is only difference of resource consumption. Checkpointing techniques use less resources compared with the active backup technique.
Scale out for checkpointing.
The fuzzy logic module is working in the system to find out the right bottleneck operator. Based on output of the system, we are using alarming_threshold (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \delta \prime _2}$$
\end{document}) and scale_out_threshold (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \delta _2}$$
\end{document}) to start out backup servers using SE module. We have tested alarming_threshold with respect to the percentage of time in which backup servers are running. Figure 12 shows that while using a lower value of alarming_threshold, it will increase percentage running time of our backup servers and if we select a 0 value it shows our servers are running all the time, which results in wastage of resources. On the contrary, if we are increasing the value of alarming_threshold and it approaches a high value (i.e., near to scale_out_threshold [\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \delta _2}$$
\end{document}]), it will result in efficient usage of resources. It is not wise to use high value of alarming_threshold approaching to scale_out_threshold (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \delta _2}$$
\end{document}), because SE needs some time to set up backup servers, as the percentage of time for running backup servers is decreasing. The scale_out_threshold (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \delta _2}$$
\end{document}) is totally dependent on status of the operator detected by the fuzzy logic module.
Effect of alarming_threshold.
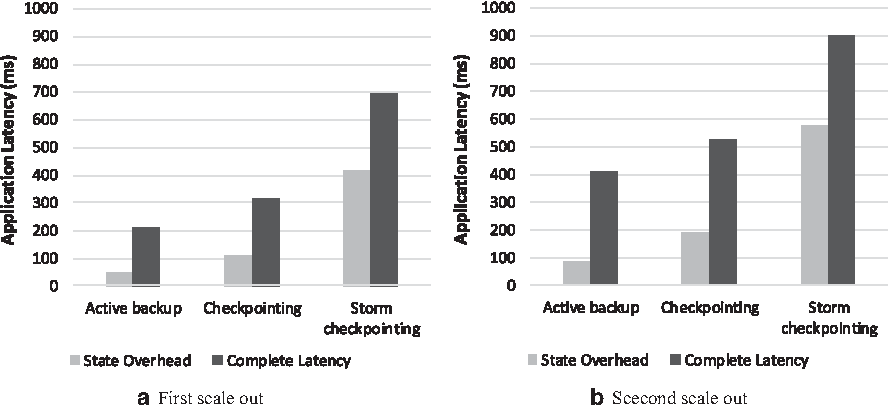
We have tested latency and compared it with the state checkpointing mechanism implemented by Storm 1.0.0. Keeping in mind that Storm still does not offer to scale out automatically, we have to restart topology with more resources to handle increased workload. This is clear in Figure 13 that when input rate is increased, latency for Storm checkpointing is increased with a very large rate until topology is restarted. On the contrary, when scale out is performed automatically using our techniques, the increased workload is handled efficiently. The throughput graph in Figure 14 shows that our techniques show more throughput when compared with Storm's checkpointing mechanism, where the overall throughput remains low. It is also clear that during high input, rate elasticity mechanism implemented using live migration technique shows better results among all other compared approaches. Around time 680 and 1050 seconds, throughput of Storm checkpointing approaches to zero due to restart of topology handle increased workload. Both of these results related to application latency and throughput prevail that both of our techniques are showing almost the same behavior, but the live migration approach is somewhat in a better position. This is due to the fact we are not starting state management tasks from start of application, but only when required. Results also show that latency in our checkpointing-based scale out mechanism is greater. This is because this technique requires replaying some tuples stored in buffers. This has supported our assumption that the live backup technique is better if low latency is required, but it will result in a bit more resource cost as we have to start live backup nodes before an operator is fully bottleneck. And if the user wants to have low resource cost and can afford latency during scale out, then he or she can use the checkpointing scale out mechanism.
Latency comparison.
Throughput comparison.
To explore state management overhead, we run the application continuously for 30 minutes by alternating low input rates and high input rates after every 5 minutes and calculated the latency occurred due to state management. Figure 15a and b shows that our techniques are performing better as latency for them is low with respect to Storm's checkpointing mechanism; this is because state checkpointing is performed after every second, which introduces extra overhead and results in more latency. On the contrary, our techniques only store and retrieve state when required, that is, when an operator approaches bottleneck.
(a, b) State management overhead.
Related Work
Scaling Distributed Stream Processing Systems (DSPSs) while considering state management for stateful operators have recently gained much interest in both academia and industry.5,6,13,14 Scaling out stateless operators can be performed by starting a new operator instance with a blank, but scaling operation of stateful operators requires state migration to preserve the consistency of the operations.15 One of the biggest challenges is to define a proper method to identify the bottleneck operator and then scale it out by offering lowest latency. Some work used the measure of CPU utilization of processing nodes as threshhold elasticity policy,6,13,16 but only one measure cannot prove that operator is bottleneck operator as CPU utilization can increase or decrease very frequently. Stela17 presented elasticity techniques for SPSs with creating a novel metric, ETP (effective throughput percentage), that accurately captures the importance of operators based on congestion and contribution to overall throughput. We have used the mechanism along with fuzzy logic system used by Frank et al.18 to detect bottleneck operator.8
Scaling with nearly zero latency is not a problem for stateless operators, but for stateful operators it is very difficult because it should be application transparent and with minimal overhead. Gulisano et al.13 describe how to partition state and decide when to scale out by monitoring incoming load and resource utilization, but migrating a stateful operator requires synchronization in state recreation protocol making a complex policy overall.
Castro Fernandez et al.6 proposed to checkpoint state of each stateful operator on upstream servers, and use threshold of each host for deciding when to scale out the bottleneck operator by allocating new servers. They have handled scale out and fault tolerance collectively by continuous checkpointing mechanism, which puts extra load on all operators, also storing backup on upstream servers may lead this to bottleneck resulting in an extra scale out. Also, during scale out, building state from checkpoints and replaying buffers takes time, resulting in latency. ChronoStream19 allows state migration by using distributed checkpointing to minimize size of state while transferring it to other nodes and claiming to achieve migration without service disruption. Their implementation requires expensive I/O accesses to local state store, resulting in delay.
Cardellini et al.5 enhanced Storm with automatic elasticity mechanism by introducing threshold at executor level, and also added distributed data store as independent module to handle migration mechanism of stateful operator. They are using the pause-and-resume approach that introduces latency, and distributed in-memory data store on each node puts extra load on the node and increases network traffic during state migrations. They have also introduced synchronization between nodes involved in migration and their upstream nodes and downstream nodes that defiantly effect working of other nodes, which are not bottleneck. They did not discuss how to partition state while scaling out. FlowDB20 integrates SPS by adding classic data management concepts, they made state of operator externally visible and queryable by storing it to in-memory data store on each node by implementing integrity constraints and transactional semantics for state updates. It is the responsibility of application developer to take care of implementing these constraints. It also requires locking mechanism on state for making state accessible to other operators.
Ding et al.4 proposed algorithms that support live and progressive migrations by migrating state among nodes within an operator. Their mechanism does not apply any synchronization barrier, but they stop processing of tasks involved in migration mechanism and start these tasks after their operator states are delivered. Tasks under migration must wait for corresponding operator states, leading to increased result response time for operators with large state. They handled this by introducing multiple minimigrations, which can increase network traffic. De Matteis and Mencagli21 present an interesting elasticity policy, which relies on a proactive and control-theoretic method that takes into account a limited future time horizon to choose the reconfigurations to be executed. The most popular open-source data stream processing frameworks, that is, Storm, Spark Streaming, and Flink, do not support elasticity. Yang and Ma22 investigate the internal architecture of Storm and proposed different strategies for relocating stateless executors, achieving a reduction of the application latency degradation.
E-Storm23 proposes a replication-based state management system in Storm by maintaining multiple active backups of state on different nodes to restore a lost state after node failure. The recovery module restores lost state by performing intertask state transfer, which only allows to recover lost state after JVM or some host crash. Their technique maintains multiple copies of state on different nodes from start of the application, resulting in extra resource consumption all the time. Also they are not handling scaling operation.
Storm also includes Trident, which can persist a state by applying a sequence of Trident transformations on the input data. However, this approach requires playing the stream as a sequence of microbatches causing constant latency overhead.
Conclusions
In this article, we designed and implemented two approaches, that is, active backup and checkpointing for state management to handle runtime scale out for a bottlenecked stateful operator. After detecting a bottlenecked operator correctly, our first technique enables SPSs to achieve nearly zero latency during scale out operation by using active backup technique, while the second one targets resource efficiency. We have integrated our approaches into Storm, a popular parallel SPS. The experimental results show effectiveness of our solution by providing live scale out and decreasing application latency by minimizing state management overhead. We also identified that overhead of state management is very low for both of our techniques as state management operations are performed only when required, compared with the checkpointing mechanism proposed by Storm that performs state management continuously.
As future work, we plan to add support for scale in operations to make the techniques truly elastic for an SPS. We will also explore the possibility to add support for fault-tolerance to our techniques, using active backup mechanism to provide fast recovery after a fault has occurred.
Footnotes
Acknowledgments
The research in this article was supported by Grant 61602037 from the Natural Science Foundation of China. The authors thank the reviewers for their comments.
Author Disclosure Statement
No competing financial interests exist.
Cite this article as: Mudassar M, Zhai Y, Liao L (2019) Efficient state management for scaling out stateful operators in stream processing systems. Big Data 7:3, 192–206, DOI: 10.1089/big.2018.0093.
NeumeyerL, RobbinsB, NairA, et al.S4: Distributed stream computing platform. In: 2010IEEE International Conference on Data Mining Workshops, Sydney, Australia, December 14, 2010, pp. 170–177.
DingJ, FuTZ, MaRT, et al.Optimal operator state migration for elastic data stream processing. arXiv preprint arXiv: 1501.03619. January 15, 2015.
5.
CardelliniV, NardelliM, LuziD.Elastic stateful stream processing in storm. In: IEEE International Conference on High Performance Computing and Simulation (HPCS), Innsbruck, Austria, July 18, 2016, pp. 583–590.
6.
Castro FernandezR, MigliavaccaM, KalyvianakiE, et al.Integrating scale out and fault tolerance in stream processing using operator state management. In: Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, New York, June 22–27, 2013, pp. 725–736.
7.
HumayooM, ZhaiY, HeY, et al.Operator scale out using time utility function in big data stream processing. In: International Conference on Wireless Algorithms, Systems, and Applications, Harbin, China, June 23–25, 2014, pp. 54–65.
8.
ZhaiY, XuW.Efficient bottleneck detection in stream process system using fuzzy logic model. In: 25th IEEE International Conference on Parallel Distributed and Network-Based Processing (PDP), St. Petersburg, Russia, March 6–8, 2017, pp. 438–445.
9.
HwangJH, BalazinskaM, RasinA, et al.High-availability algorithms for distributed stream processing. In: International Conference on Data Engineering (ICDE), Tokyo, Japan, April 5–8, 2005, pp. 779–790.
Redis, redis. 2015, Available online at https://redis.io (last accessed April24, 2018).
12.
EverWatch Corporation. everwatchsolutions.json-data-generator: Json Data Generator. 2016. Available online at https://github.com/acesinc/json-data-generator (last accessed March24, 2018).
13.
GulisanoV, Jimenez-PerisR, Patino-MartinezM, et al.Streamcloud: An elastic and scalable data streaming system. In: IEEE Transactions on Parallel and Distributed Systems, 2012, pp. 2351–2365.
14.
LiJ, PuC, ChenY, et al.Enabling elastic stream processing in shared clusters. In: IEEE 9th International Conference on Cloud Computing, San Francisco, CA, June 27–July 2, 2016, pp. 108–115.
15.
GedikB, SchneiderS, HirzelM, et al.Elastic scaling for data stream processing. IEEE Trans Parallel Distrib Syst. 2014; 25:1447–1463.
16.
HeinzeT, PappalardoV, JerzakZ, et al.Auto-scaling techniques for elastic data stream processing. In: 2014IEEE 30th International Conference on Data Engineering Workshops (ICDEW), Chicago, IL, March 31–April 4, 2014, pp. 296–302.
17.
XuL, PengB, GuptaI. Stela: Enabling stream processing systems to scale-in and scale-out on-demand. In: 2016IEEE International Conference on Cloud Engineering (IC2E), Berlin, Germany, April 4–8, 2016, pp. 22–31.
18.
FrankR, CastignaniG, SchmitzR, et al.A novel eco-driving application to reduce energy consumption of electric vehicles. In: IEEE International Conference on Connected Vehicles and Expo (ICCVE), Las Vegas, NV, December 2–6, 2013, pp. 283–288.
19.
WuY, TanKL. ChronoStream: Elastic stateful stream computation in the cloud. In: 2015IEEE 31st International Conference on Data Engineering (ICDE), Seoul, Korea, April 13–16, 2015, pp. 723–734.
20.
AffettiL, MargaraA, CugolaG.FlowDB: Integrating stream processing and consistent state management. In: Proceedings of the 11th ACM International Conference on Distributed and Event-Based Systems, Barcelona, Spain, June 19–23, 2017, pp. 134–145.
21.
De MatteisT, MencagliG. Keep calm and react with foresight: Strategies for low-latency and energy-efficient elastic data stream processing. ACM SIGPLAN Notices, 51; 8:2016.
22.
YangM, MaRT. Smooth task migration in apache storm. In: Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, Melbourne, Australia, May 31–June 4, 2015, pp. 2067–2068.
23.
LiuX, HarwoodA, KarunasekeraS, et al.E-Storm: Replication-based state management in distributed stream processing systems. In: IEEE 46th International Conference on Parallel Processing (ICPP), Bristol, United Kingdom, August 4–17, 2017, pp. 571–580.