
Abstract
Intelligent transportation system (ITS) is an advance leading edge technology that aims to deliver innovative services to different modes of transport and traffic management. Traffic flow prediction (TFP) is one of the key macroscopic parameters of traffic that supports traffic management in ITS. Growth of the real-time data in transportation from various modern equipments, technology, and other resources has led to generate big data, posing a huge concern to deal with. Recently, deep learning (DL) techniques have demonstrated the capability to extract comprehensive features efficiently, using multiple hidden layers, from such huge raw, unstructured, and nonlinear data. Nonlinearity in traffic data is the major cause of inaccuracy in TFP. In this article, we propose a flow strength indicator-based Chronological Dolphin Echolocation-Fuzzy, a bioinspired optimization method with fuzzy logic for incremental learning of deep belief network. Technical indicators provide flow strength features as an input to the model. Hidden layers of DL architecture consequently learn more features and propagate it as an input to next layer for supervised learning. The degree of membership to the features is identified by the membership functions, followed by weight optimization using Dolphin Echolocation algorithm to fit the model for the nonlinear data. Experiments performed on two different data sets, namely Traffic-major roads and performance measurement system-San Francisco (PEMS-SF), show good results for the proposed deep architecture. The analysis of the proposed method using log mean square error and log root mean square deviation acquires a minimum value of 2.4141 and 0.61 for the Traffic-major roads database taken for the time step duration of 1 year and a minimum value of 1.6691 and 0.5208 for PEMS-SF data set for the time step interval of 5 minutes, respectively. These positive results demonstrate key importance of our traffic flow model for the transportation system.
Introduction
An effective traffic management system for road transportation depends on successful development and deployment of accurate traffic flow prediction (TFP) techniques in intelligent transportation system (ITS). Rapid developments in society have contributed to the massive existence of traffic in urban areas affecting transportation that lead to vehicle congestions or accidents 1 and generation of huge traffic data. Traffic data in transportation is increasing exponentially based on autonomous sources, heterogeneous characteristics, and evolving complex associations.2,3 ITS uses various sensing devices including loops, cameras, mobile probes, or road-embedded to collect the values of these traffic data for the parameters, such as flow, density, and speed. Unlike other networks, road transportation networks are complex with abundant nonlinear data. 4 Thus, the primary intention of ITS is to resolve the issues related to the road transportation by means of system engineering ideas, synergistic technologies to enhance and develop the transportation intelligently.1,5 Macroscopic parameters of traffic flow information such as flow, speed, and density govern road transportation in ITS, which is essential for individual travelers, business sectors, and government agencies. 6 Therefore, it is clear that an accurate and timely traffic flow information in traffic management is essential for the successful exploitation of ITS. 7 TFP is an important task of ITS applications 1 based on the historical, current, and real-time data. TFP helps users to do an effective planning and avoid hectic impacts of traffic on the road links by providing alternate travel options to degrade traffic congestion, minimize carbon emissions, and enhance the efficiency of the traffic operation. 8 Apart from dealing with the complex and dynamic traffic data, 1 prediction of traffic in an online and real-time environment provides solution to control and manage various traffic conditions.9,10 Numerous mathematical models and classical Machine Learning algorithms were developed to deal with irregularity of traffic data. These models fail to capture the uncertainty and nonlinearity of time series data due to the traditional feature extraction method, 11 where the features are handcrafted for every new set of training data, which increases the cost and time consumed by the model. Another problem is to obtain prior knowledge of specific domains for feature extraction and selection process.
Effective traffic control and operations are affected due to the inherent nonlinearity, uncertainty, and complexity, as these factors degrade the accuracy of prediction. 12 An accurate prediction of traffic flow data on a particular road link supports ITS. Traffic information can be analyzed based two entities: first, based on the time series data known as temporal information, and, second, based on the junctions, links, and regions, known as spatial information. Temporal information provides support to find long-term and short-term TFP. Separate learning for different spatial segments makes the computational process complex and inefficient. ITS needs more accurate method to address both spatiotemporal traffic information.
All these issues led us to develop a novel method for predicting the traffic flow with better accuracy. The main objective of this research was to deal with the huge set of nonlinear traffic data for long-term and short-term TFP considering the spatiotemporal parameters. The proposed TFP method consists of two major steps. In the first step, leading and lagging indicators find the flow strength features of input data. Consequently, in the second step, granular features are extracted using the hidden layers fuzzified and integrated with Dolphin Echolocation (DE) optimization method for the prediction of traffic flow using deep belief network (DBN).
Traffic flow strength indicators
The role of these indicators is to predict traffic flow strength features effectively for the initial input data, and consequently, features are extracted by the deep architecture to understand the correlation between irregular nonlinear data. The indicators employed for evaluating and extracting the strength of the traffic flow include Momentum (MOM), Relative Strength Index (RSI), Commodity Channel Index (CCI), Average Directional Movement Index (ADX), and Triple Exponential Moving Average (TEMA). These indices are computed to represent the features of the input data.
Incremental Chronological Dolphin Echolocation-Fuzzy DBN
The main aim of this research was to focus on TFP using DBN, which is trained by proposing an optimization algorithm, named flow strength indicator-based Chronological Dolphin Echolocation-Fuzzy (CDE-Fuzzy) algorithm. The proposed algorithm inherits the features of input data and propagates in deep net to extract newer features. These features are fuzzified with fuzzy membership functions to obtain chronological data that are integrated in the weight update process of the DE algorithm that converges to obtain global optimal solution in DBN. The experimental results demonstrate that the proposed method for TFP outperforms the existing methods.
The rest of this article is organized as follows: The proposed strategy is explained in the Methodology section, whereas the Results and Discussion section deliberates the experiments and results of the proposed method, providing a comparative analysis. Finally, the Conclusion section concludes the article.
Literature review
This section provides reviews of the literature on various TFP techniques applied on the traffic data set obtained from various sources for addressing issues related to forecast accuracy, nonlinear data, long-term and short-term TFP, and spatiotemporal information.
Lv et al. 8 developed a method, named deep learning (DL) approach with stacked Autoencoder-based TFP that was capable of yielding better prediction performance using logistic regression predictor, which may be extended with powerful predictor for further improvement in the performance. It has considered the spatiotemporal features but not applied and tested on huge data from different public open traffic data sets. Wibisono et al. 13 established a method of predicting the traffic using “Fast Incremental Model Trees–Drift Detection (FIMT-DD)” that provides spatial traffic information and imposes a minimum error experience over the trained model but requires sufficiently huge traffic data to predict error performance for the traffic condition accurately. Hu et al. 14 developed a method that solves the nonlinearity in data pattern using Particle Swarm Optimization in Support Vector Regression with better prediction results in the presence of noises. The model is applicable for the short-term traffic flow prediction. It specifies temporal information but does not address the extraction of spatial features to predict the traffic flow. Li et al. 12 developed a method named “Multivariate Data Fusion” with Bayesian theory and radial basis function to deal with chaotic characteristics of traffic flow. The study addresses about short-term TFP accurately but fails to deal with congested traffic conditions (nonlinearity) using multiple measures. Xia et al. 9 developed a “Map Reduce-based Nearest Neighbor” approach that improved the efficiency and scalability of TFP, saved memory consumption, and reduced the computational costs. However, the method does not address the nonlinearity for large training samples. Zhao and Su 1 modeled a Gaussian Process Dynamical Model (GPDM) that performs better and offers significant improvements in traffic prediction performance. The demerit of the method is that it cannot use the mixtures of GPDMs to model time series. Oh et al. 15 developed the Multifactor Pattern Recognition Model, which offers a highly reliable prediction. However, the method cannot handle heavy traffic congestion, which leads to the problem of nonlinear data pattern. Vasantha Kumar and Vanajakshi 16 developed a Seasonal Autoregressive Integrated Moving Average (SARIMA), a data-driven model, that employs limited input data for TFP. Limited spatiotemporal information is learnt for traffic prediction. In the study by Yanchong et al., 17 an approach was developed for predicting short-term traffic flow using the wavelet analysis and neural network (NN). Here, the traffic flow data was partitioned into low- and high-frequency signals through wavelet decomposition. Then, back propagation NN processes the decomposed signal for the prediction.
A hybrid automaton modeling was developed by Banjanović-Mehmedović et al. 18 under varying platooning conditions with nonlinear autoregressive network (NARX) NN-based prediction in ITS. Hybrid automaton considers the nonlinear dynamics of every vehicle and provides a better forecasting using the NARX prediction. Huang et al. 11 introduced a deep architecture for TFP, which employs a stack of Restricted Boltzmann Machines (RBMs) at the bottom with a regression layer at the top. The DBN-based TFP is effective for unsupervised feature learning. However, the problem of how to employ temporal information in TFP is a challenge in this approach. In addition, this approach shows constraints for real-time applications.
Koesdwiady et al. 19 developed a complete prediction architecture, which includes DBNs and data fusion for developing a perfect TFP in San Francisco, Bay Area. This method utilized the weather data and a traffic flow history. This method guaranteed better prediction and management of traffic strategies. Yang et al. 20 introduced a stacked Autoencoder Levenberg-Marquardt model for traffic flow forecasting. This model was designed by the Taguchi scheme for developing an optimized structure and discovering the traffic flow features via layer-by-layer feature granulation with a greedy layer-wise unsupervised learning algorithm. This model had higher performance in traffic flow forecasting. Jia et al. 21 analyzed the performance of the long short-term memory (LSTM) and DBN for performing the short-term traffic speed prediction with the rainfall impact. The DL discovered the complex features of the traffic flow pattern under a variety of rainfall conditions. Tian and Pan 22 proposed a model named Long Short-Term Memory Recurrent Neural Network (LSTM RNN), which took the benefits of the three multiplicative units in the memory block for finding the optimal time lags energetically. This prediction model avoids gradient vanishing–exploding problem for nonlinear data, obtains higher accuracy, and generalizes well. Luo et al. 23 introduced a spatiotemporal traffic flow model combined with k-nearest neighbor (KNN) and LSTM network, which is named KNN-LSTM model. KNN was used to select mostly related neighboring stations with the test station and to capture spatial features of traffic flow. LSTM was used to mine temporal variability of traffic flow, and a two-layer LSTM network was applied to predict traffic flow respectively in selected stations. The final prediction results were attained by result-level fusion with rank-exponent weighting approach. However, the method produces good prediction accuracy, but further improvement is required due to the nonlinearity caused by weather, incident, and other factors.
Summary and motivation
The issues observed from the existing work need improvement in terms of forecasting accuracy. A development of unified model is required to handle big data, computational cost involved, effects of nonlinear traffic data on traffic condition, and exploration of spatiotemporal traffic dependency, as well as, to address the challenges in long-term TFP.
Multifaceted algorithms are developed in TFP using parametric and nonparamedic approach, 24 but it is difficult to state the dominance of one algorithm over the other. Since each model uses different techniques, considering limited contextual factors, environment affects, and available data set. 25 Of the context researcher started exploiting hybrid methods, 26 the existing methods were compared to predict traffic flow accuracy integrating newer concept to identify the features embedded8,27 in the collected spatiotemporal traffic data.
With the popularity and capability of DL methods, which address massive data, DL methods stand as a good option for handling the learning process associated with the complex nonlinear data carrying high-dimensional features 28 and optimized structure. 29 DL deals with problems such as classification, dimensionality reduction, natural language processing, motion modeling, and object detection.30,31 DL algorithms exhibit multiple-hidden layer for unsheathing the inherent features of data from the lowest to the highest level. 25 Eventually, it is clear that using DL algorithms, we can predict the traffic flow without any prior knowledge of the traffic despite its complexity 8 and exhibit better performance.
These capabilities led us to work more on a DL model to develop a novel method for predicting the traffic flow with better accuracy. In this article, we explore a DL approach with technical indicators, fuzzy membership functions, and bioinspired optimization algorithm over DBN for TFP.
Methodology
The major concern for the TFP model is to deal with the huge raw data obtained from various resources. Some of the standard data set provides well-structured data. The raw data obtained through the data set need to be preprocessed based on the problem domain, algorithmic approach, and computational need. Generally, the characteristics of traffic data are nonlinear due to the contextual factors such as traffic incidents, constructions, public events, and weekdays in the time series data. Prediction based on historical, current, and real-time data contains the traffic data of the road links at various places. Even though there are many techniques employed in predicting the traffic flow, the prediction accuracy is yet another factor to be concentrated. The proposed method predicts the traffic flow through the extraction of the traffic flow strength features from the time series data. The traffic flow features are given as input to the CDE-Fuzzy-based DBN model.
The traffic flow predictor uses DBN tuned by CDE-Fuzzy algorithm, which inherits the advantages of fuzzy membership and chronological property integrated in the DE algorithm. Figure 1 shows the block diagram of the TFP method using the proposed CDE-Fuzzy DBN.

Block diagram of the CDE-Fuzzy DBN technique for TFP. CDE-Fuzzy, Chronological Dolphin Echolocation-Fuzzy; DBN, deep belief network; TFP, traffic flow prediction.
Extraction of traffic flow strength features
This section deliberates the traffic flow technical indicators and the procedure to compute the flow strength features as an initial input to the proposed model for predicting the flow. Generally, technical indicators 32 are employed for computing the stock exchange flow and proven effective predictors of features, such as change in price, stock trend, buy and sell, signal and noise elimination, and data smoothing in stock prices. 33 Thereby, assure the prediction of the close pricing of the stocks prevailing in different markets. We have used these stock-based technical indicators for extracting flow strength features of the traffic data. The extraction of initial traffic flow strength features is obtained by modeling the traffic indicators that effectively help in tuning the input data for the proposed model. Subsequently, features are extracted in the deep net by the hidden layers for accurate prediction of flow. Generally, traffic flow indicators come under two major classes: leading, an input-oriented indicator, and lagging, an output-oriented indicator. Using the historical traffic flow data, the leading indicators ensure the prediction of the traffic flow in the future, whereas the lagging indicators help to identify the change in traffic flow. We have used five indicators, namely MOM, RSI, CCI, ADX, and TEMA. 32 The indicators, such as MOM, RSI, and CCI, are leading indicators that help to extract features and provide information for the future traffic flow. ADX is a lagging indicator that measures the up and down of traffic flow based on past data. TEMA reduces the lags between the indicators and helps in smoothing the flow fluctuations, thereby predicting the traffic flow without the lag associated with the traditional moving average. Modeling of flow strength features using the indicators is explained below.
Momentum
MOM refers to the rate of rise or falls in the traffic flow rate and represented by Equation (1).
where Tt is the traffic flow rate at the time t,
Traffic flow rate is defined as the number of vehicles passes through a given point per hour on the roadway. 34
Relative Strength Index
RSI is the measure of the change in the traffic flow rate over time t by comparing the magnitude of the recent increase and decrease of the traffic flow rate. The RSI formula is given as
where
The traffic flow rate-up is the difference between the traffic flow rate at time t and time
Commodity Channel Index
CCI is the measure of the variation in the typical traffic flow rate relative to the predefined moving average to the 1.5% of the normal deviation from that average. The CCI is defined as
where
The normal deviation is defined as
Equation (7) is computed as the average of the difference between the absolute value of the typical traffic flow rate and the predefined moving average that is the average of the typical traffic flow rate.
Average Directional Movement Index
ADX is the indicator that defines the strength or weakness of the flow trend irrespective of increase or decrease in the traffic flow rate based on the plus and minus directive index. When the traffic flow rate increases, the difference between the present high and previous high values of the traffic flow rate is considered as a plus directive index. Similarly, when the traffic flow rate decreases, the minus directive index is determined as the difference between the present low and previous low values of the traffic flow rate. The plus directional movement is determined as
where
where
where
where n is the total time interval. The directive index is based on the traffic flow rate-up and the traffic flow rate-down. If the traffic flow rate-up exceeds the traffic flow rate-down and exceeds zero, the plus directive index is notified as the traffic flow rate-up or else it becomes zero. When the traffic flow rate-down is greater than the traffic flow rate-up and exceeds zero, the minus directional index is notified as the traffic flow rate-down or else it becomes zero. TR is the ratio of the directive index to the total number of traffic instances in the time series database.
Triple Exponential Moving Average
TEMA is a measure that smoothens the variations in the traffic flow rate, filters out the volatility, and makes the ability to determine the trends with minimum lag. It is the ratio of the traffic flow rate at the time t to the traffic flow rate at the time
where
The traffic strength indicators are organized as the feature vector of dimension
where F1 indicates the MOM feature, F2 specifies the RSI feature, F3 indicates the CCI feature, F4 refers to the ADI feature, and F5 specifies the TEMA feature. The extracted flow features obtained from the traffic data are given as input to the deep net model.
CDE-Fuzzy algorithm for training the DBN
The traffic flow input data from the data set are incremental as the traffic data keeps on updating frequently. DBN is capable of dealing with unsupervised prelearning for incremental data. Hence, the prediction model based on the DBN serves as a better platform to train and test in predicting the traffic flow based on the historical traffic flow data. The traffic flow data is dynamic in nature and varies with time, insisting the need for better classification for the incremental data. The proposed DBN is fine-tuned with the supervised learning, which uses target labels to perform regression analysis and paves an effective platform to predict the future traffic using the core features obtained by the indicators.
The developed CDE-Fuzzy algorithm, which is the integration of Chronological and fuzzy theory in the DE optimization algorithm, trains the DBN. The DE algorithm 35 inherits the sophisticated bio sonar system such that the dolphin's track discriminate, locate the prey, and thereby solve the prey-intercept objective. Sonar is an attractive mechanism in dolphin employed to avoid the obstacles and locate the prey in the search space. Dolphin generates the clicks and evaluates the energy of the captured click to locate the distance of the prey from the dolphin. Dolphin concentrates on the particular target by increasing the generation of clicks. Thus, the DE algorithm local investigation optimizes the parameters and supports global exploration for effective computation. The optimization algorithm offers a flexible solution and is suitable for solving the multiple constraint objective functions, but the convergence requires further improvements due to the existence of nonlinear data. 36 So, to improve the convergence rate, the proposed algorithm inherits the advantages of fuzzification through the degree of membership functions to the features obtained from the technical indicators under chronological order in DE optimization algorithm. The fuzzy concept 37 gains significance because of its flexibility to precisely categories each traffic feature. It does this by emphasizing on imprecise and incomplete traffic data and models the nonlinear functions with arbitrary functions. Fuzzy holds simple computations and covers a large range of traffic features in the updating process.
Derivation of the update rule using the proposed CDE-Fuzzy-based algorithm
The CDE-Fuzzy algorithm for computing the optimal weights of the DBN is developed by modifying the update rule of the DE algorithm using the fuzzy and chronological concept. The developed update rule ensures a better convergence rate and thereby enhances the flexibility and stability with high prediction accuracy. The standard equation of DE is given as
Rearranging the above equation, we get
where
The fuzzy triangular memberships are given as
where p, q, and r are the lower, middle, and center boundary. The three vertices of the membership functions arep, q, and r of
The Gaussian fuzzy
where μ is mean and σ is the standard deviation.
The membership functions utilize any structure for its applicability in the real-time applications.
The position of the
where
Substituting Equation (18) in Equation (15), we get
Based on the chronological concept, the position of dolphin in
The chronological concept uses historical records so that the prediction using the proposed CDE-Fuzzy algorithm becomes effective and accurate. The chronological concept is merged in the DE algorithm through the substitution of Equations (19) and (15) in Equation (20) as
Algorithmic steps
The algorithmic steps of the CDE-Fuzzy weight optimization are depicted in Algorithm 1.
Pseudocode of CDE-Fuzzy weight optimization
Prediction of the traffic flow using the proposed CDE-Fuzzy DBN
This section deliberates the prediction of the traffic flow using the CDE-Fuzzy algorithm-based DBN.
The architecture of DBN
The importance of time series DBN 39 is to extract and recognize the patterns underlying in the data sequences. DBN is trained on the labeled data to minimize the error and thereby to predict the traffic using the outputs previously recorded to assure better prediction accuracy. The basic structure of DBN consists of multiple RBMs and a Multi-Layer Perceptron (MLP) layer. An individual layer of RBM and MLP resembles the architecture of NN. The layers are constructed with the interconnection of the neurons. In the incremental DBN, we have considered two RBM layers, and the input to the RBM1 is the feature vector corresponding to the traffic flow data. The inputs are multiplied with the weights of the parametric features to produce the output of the hidden layer, which forms the input to the RBM2. The inputs in RBM2 are processed with the hidden weights of RBM2 to obtained inputs to the MLP layer, which processes the weights and determines the final output. The weights of the DBN are updated using the CDE-Fuzzy Algorithm 1 until it converges to global optima. The architecture of the incremental DBN is depicted in Figure 2.
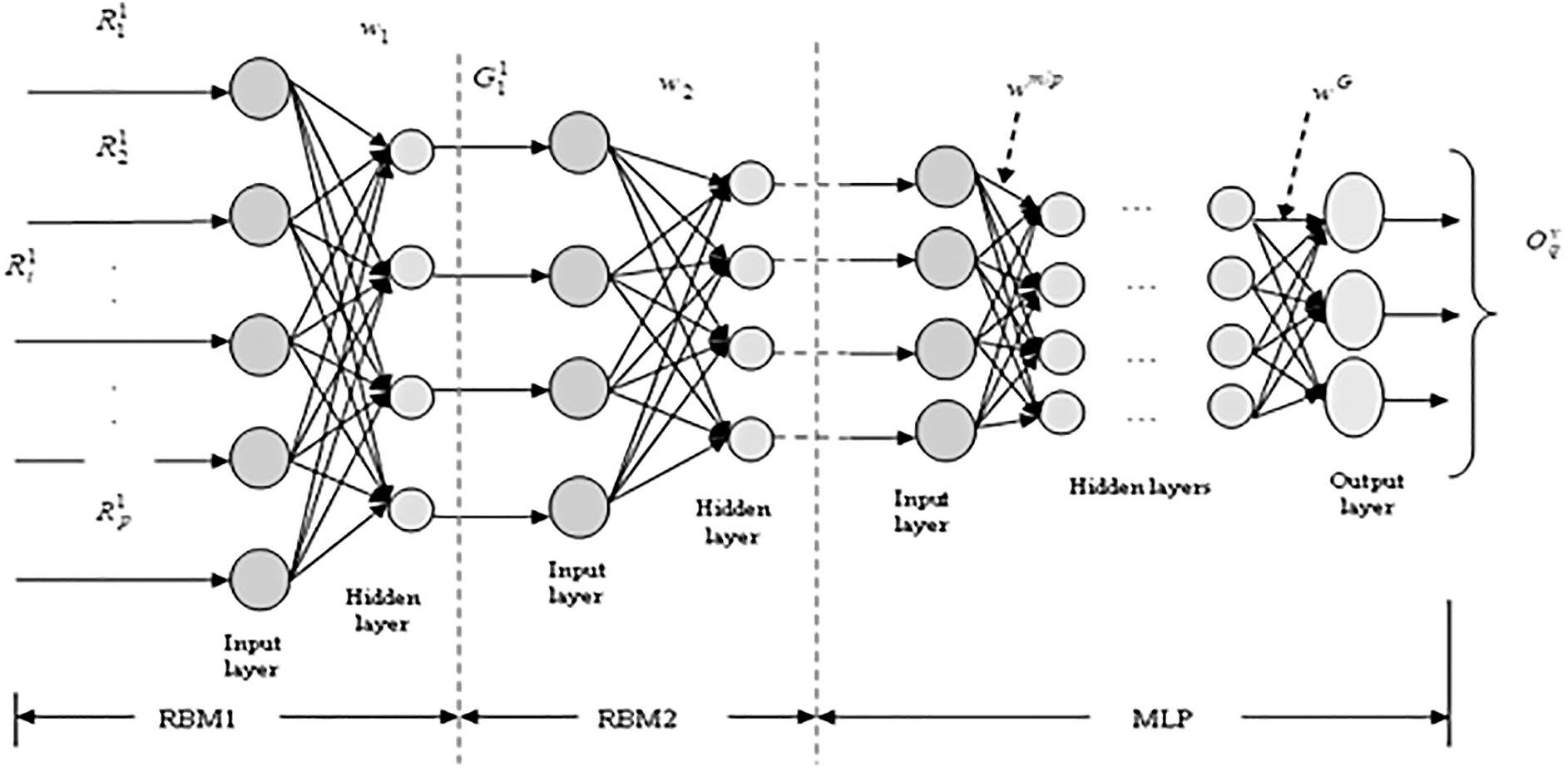
The architecture of incremental DBN model.
The mathematical model of the incremental DBN is framed as follows: There are two RBM layers, RBM1 and RBM2, and the input to the RBM1 is the feature vector (traffic flow strengths features) of the incoming traffic flow data. The input and the hidden neurons in the input layer of RBM1 are given as
where
The biases in the hidden and the input layer of RBM1 equal to the total neurons in both the layers. The weights of the RBM1 are given as,
where
where
The output from RBM1 is provided as input to the RBM2, and the output of RBM2 is computed similarly based on the equations shown above. The output from RBM2 is represented as
where y is the total number of input neurons in the MLP layer. The hidden neurons of MLP are given as,
where m specifies the total number of hidden neurons in the MLP. The bias of the hidden neurons is given as
where S is the number of output neurons in the MLP layer. The weights between the input and the hidden layers are represented as
where
where
Thus, the output of MLP is computed as
where
(a) Training phase of RBM layers: The training of the RBM1 and RBM2 layers is performed based on the CDE-Fuzzy algorithm that derives the weights to obtain minimum error.
(b) Training of MLP layer: The steps involved in training the MLP layer are listed below:
Step 1: Randomly generate the weight vectors wG and
Step 2: Read the input vector
Step 3: Calculate J and Oq based on Equations (33) and (35), respectively.
Step 4: Compute the error of the MLP layer using the estimated and target output as given below
where Oq is the attained output, g is the expected output, and
Step 5: Update the weight using the proposed CDE-Fuzzy-based algorithm: The weights of the MLP layer are updated based on the Equation (21), which is the update derived using the CDE-Fuzzy algorithm. The CDE-Fuzzy algorithm derives the optimal weights for predicting the traffic flow.
Step 6: Calculate the average error function
Step 7: Repeat steps 2 to 6, until the best weight vector is determined.
The CDE-Fuzzy-based DBN predicts the traffic flow optimally and supports the decision-making in an effective way.
Results and Discussion
This section depicts the results and discussion of the proposed model for predicting the traffic flow and the effectiveness of the CDE-Fuzzy DBN method using the comparative analysis.
Experimental setup
The experimentation is performed using the MATLAB tool, and the analysis is progressed using the Traffic-major roads 40 and performance measurement system-San Francisco (PEMS-SF) 41 data sets. Table 1 shows the parameters used for the experimentation.
Parameter description
CDE-Fuzzy, Chronological Dolphin Echolocation-Fuzzy; DBN, deep belief network; KNN, k-nearest neighbor; LSTM, long short-term memory; NARX, nonlinear autoregressive network; NN, neural network; RNN, recurrent neural network.
Data set description
The proposed method is evaluated using two standard data sets, Traffic-major roads 40 and PEMS-SF. 41 The intention of using these two data sets is to evaluate the proposed method for both long-term and short-term TFP. Preprocessing for the data set is done to scale under the activation function.
Data set 1: Traffic-major roads
The description of the database Traffic-major roads 40 considered for the analysis (long-term prediction) is given below. The traffic data consists of 11 vehicle categories, count point, year, count point locations, iDir (direction of flow), hour, and count for all motor vehicles. The count points provide the spatial information of traffic condition in that location. The vehicle categories include bus, cars, two-rigid axle Heavy Goods Vehicle, Light Goods Van, Pedal Cycles, Two-Wheeler Motor Vehicles (2WMV), All Motor Vehicles, three-rigid axle Heavy Goods Vehicle, four or more rigid axle Heavy Goods Vehicle, three and four-articulated axle Heavy Goods Vehicle, five-articulated axle Heavy Goods Vehicle, and six or more articulated axle Heavy Goods Vehicle. There are about 208 local unique authorities, with each authority possessing 19,130 unique count points for the successive years between 2000 and 2015 for all the vehicle categories. For training, 70% of samples are taken initially, and 30% of remaining samples are tested with incremental intervals.
Figure 3 depicts the partial map showing various count points, taken from the dft.gov.uk website. In addition, the map plotted for all data points in the data set is provided as shown in Figure 4. It is observed that data points are dense in some region and sparse at various other places. It gives a clear picture of nonlinearity in the traffic data with respect to time. The challenge is to deal with nonlinear data at count points in various regions and forecast future flow in that region. The proposed CDE-Fuzzy DBN model uses technical indicators to derive traffic flow strength features, followed by optimization to solve prediction problems in such areas.
Partial map showing various count points.

Map plot of data points in the data set.
Data set 2: PEMS-SF data set
The second data set is taken from PEMS-SF 41 that exhibits multivariate characteristics. It consists of a total of 440 instances and 138,672 attributes that have real characteristics. The proposed CDE-Fuzzy DBN model is given to the data collected from the Caltrans Performance Measurement System (PEMS) database. Marco Cuturi, who is the creator of the data set, has downloaded data from the California Department of Transportation PEMS website for 15 months (January 1, 2008, to March 30, 2009), illustrating the occupancy rate of various car lanes in the San Francisco bay area. The data collected in an interval of 10 minutes, considering every day as a single time series data having dimension 963 with span 6 × 24 = 144. Excluding the data on all the public holidays, the database contains 440 time series data. Hence, the database includes 963 × 144 = 138.672 attributes for every data record. Similar to data set 1, here too, the experiment is carried out by considering 70% of samples for training and the remaining for testing on an incremental basis.
Performance index
To evaluate the performance of the proposed technique, we use two performance indexes, which are the log mean square error (LMSE) and the log root mean square error (LRMSE).
Log mean square error
Mean square error (MSE) is based on the average of the error between the observed value and the predicted output of the classifier from the classifier. The formula for the MSE is updated in Equation (37), with LMSE,
42
obtained by taking the log of the MSE.
where Oq is the actual output, g is the expected output, and
Log root mean square error
Root mean square error (RMSE) is defined as the measure of the observed values and the predicted values. The RMSE is the square root of MSE, and the LRMSE
43
is computed as the log of the RMSE value as shown in Equation (38).
where Oq is the actual output, g is the expected output, and
Relative error
The relative error of two methods is the absolute value of the error between the methods. The significance of using relative error is to specify the percent improvement of the proposed method when compared with the existing methods. The relative error of
where
Comparative methods
The methods used for analysis include DBN, 11 Deep Network using Autoencoder, 8 Wavelet NN, 17 NARX LM, 18 RNN, 22 KNN-LSTM network, 23 and CDE-Fuzzy DBN without technical indicators, and the results of the existing methods are compared with the proposed CDE-Fuzzy DBN method of TFP.
Comparative analysis
This section demonstrates the comparative analysis using two data sets based on LMSE and LRMSE with respect to the time steps in either years or interval of 5 minutes. Totally, three sets of analysis are carried out through varying the number of hidden layers as 1, 2, and 3, respectively, using the two data sets. While analyzing the performance of each set, the best performance has been obtained using three hidden layers, which is provided in this section.
Analysis based on data set 1
The analysis using the data set 1 is discussed based on the performance metrics and the time step duration given in years for long-term TFP.
With the number of hidden layers = 3
Figure 5 shows the analysis for all vehicle types in terms of LMSE and LRMSE using three hidden layers. Figure 5a shows the analysis using LMSE. The LMSE values for the methods CDE-Fuzzy DBN, DBN, Wavelet NN, NARX-LM, Deep Network using Autoencoder, RNN, KNN-LSTM, and CDE-Fuzzy DBN without technical indicators when the time step duration is 1 year are 2.4141, 3.5755, 3.8373, 3.2980, 3.0998, 2.9506, 3.7296, and 2.6254, respectively. In the fifth year, the value of LMSE for CDE-Fuzzy DBN, DBN, Wavelet NN, NARX-LM, Deep Network using Autoencoder, RNN, KNN-LSTM, and CDE-Fuzzy DBN without technical indicators are 2.4815, 3.6908, 3.9594, 3.3969, 3.0614, 3.0387, 3.5996, and 2.6136, respectively. It is observed that CDE-Fuzzy DBN has a low value of LMSE compared with the existing methods.
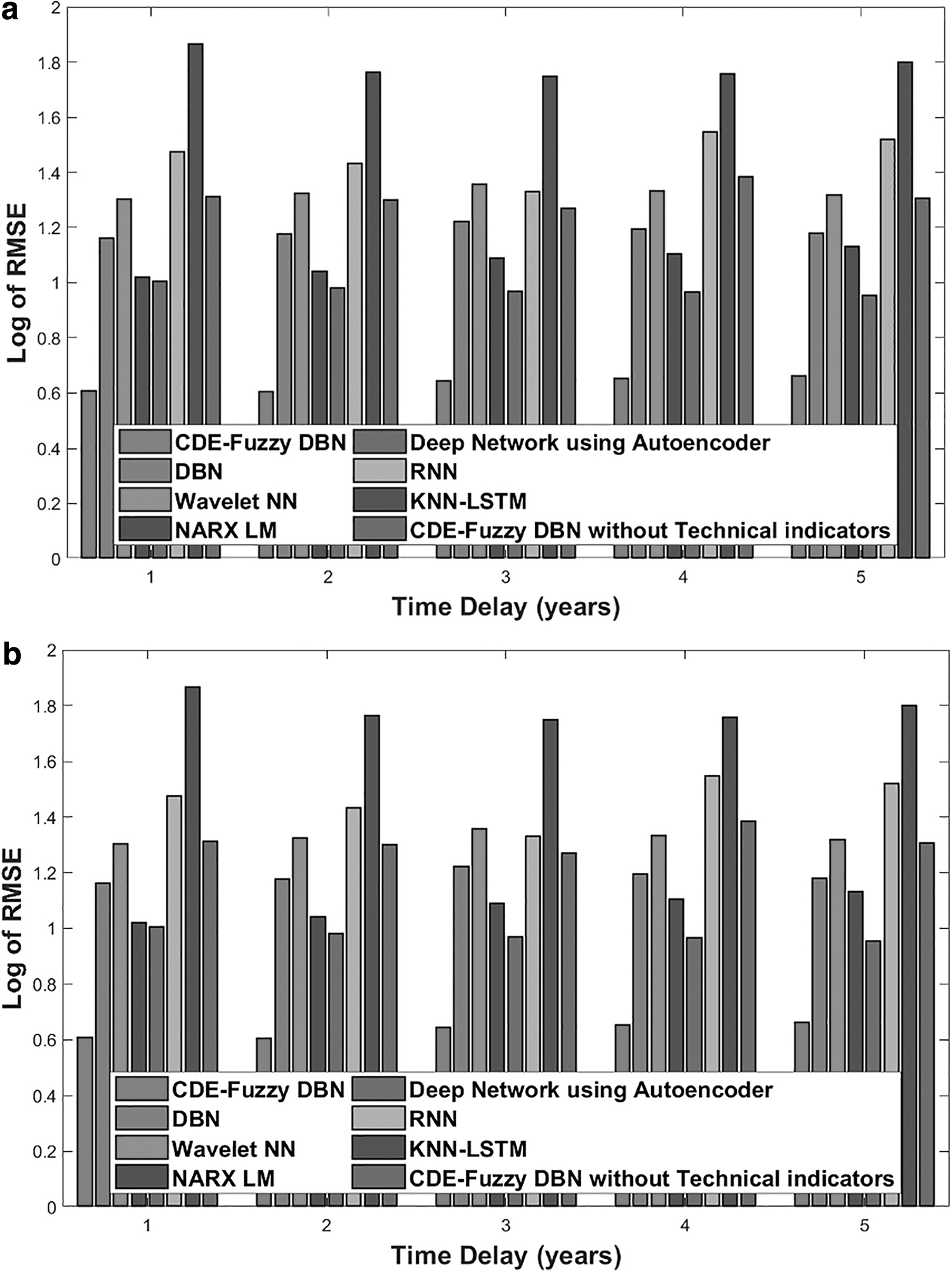
Performance analysis using three hidden layers.
It is observed that CDE-Fuzzy DBN has a low value of LMSE compared with the existing methods. Figure 5b depicts the comparative analysis in terms of LRMSE for all vehicles with three hidden layers. The relative error of CDE-Fuzzy DBN with respect to DBN, Wavelet NN, NARX-LM, Deep Network using Autoencoder, RNN, KNN-LSTM, and CDE-Fuzzy DBN without technical indicators are 47.5%, 53.16%, 40.20%, 39.45%, 58.65%, 67.29% and 53.53%, respectively, when the interval is 1 year.
Analysis based on data set 2
The analysis using data set 2 is demonstrated in this section, and the time step interval is 5 minutes for short-term TFP.
With number of hidden layers = 3
Figure 6 shows the analysis using PEMS data in terms of LMSE and LRMSE using three hidden layers. The analysis of LMSE is enumerated in Figure 6a that demonstrates the variance of LMSE for the time step intervals of 5, 10, 15, 20, and 25 minutes. The LMSE of the methods is found to be decreasing upon an increase in the time duration from 5 to 25 minutes. The LMSE for CDE-Fuzzy DBN at the interval of 5 minutes is 1.6690 and 1.7178 at the interval of 25 minutes represents that the method makes effective results. Additionally, the second-best classifier that offers less LMSE is the CDE-Fuzzy DBN without technical indicators, offering LMSE of 1.8745 at the interval of 5 minutes and 1.7496 at the interval of 25 minutes. The relative error of CDE-Fuzzy DBN is 20.78% with the DBN and 66.29% with the wavelet NN for interval of 25 minutes. Figure 6b depicts the comparative analysis based on the LRMSE. The LRMSE values of CDE-Fuzzy DBN, DBN, Wavelet NN, NARX-LM, Deep Network using Autoencoder, RNN, KNN-LSTM, and CDE-Fuzzy DBN without technical indicators are 0.5456, 0.7801, 1.5275, 1.3147, 1.1293, 1.2363, 1.9192, and 0.8748, respectively, when the interval is 25 minutes. The graph makes it clear that the CDE-Fuzzy DBN acquires a less value of LRMSE for all the intervals when compared with the existing methods.

Performance analysis using three hidden layers.
Comparative discussion
Table 2 shows the analysis of the TFP methods using data set 1 and data set 2 based on the best performance values obtained by the comparative methods. The analysis using the instances for both the data sets depicts useful information. It can be observed that the proposed method CDE-Fuzzy DBN outperforms rest of the techniques due to the technical indicators and optimization method used. CDE-Fuzzy DBN without technical indicators shows the second best results for the metrics LMSE and LRMSE. From Table 2, it is depicted that the proposed CDE-Fuzzy DBN acquired a minimum value of LMSE and LRMSE for both the data sets.
Comparative analysis of the prediction methods using data set 1 and data set 2
LMSE, log mean square error; LRMSE, log root mean square error.
Conclusion
We propose a DL approach with technical indicators, fuzzy membership functions, and bioinspired optimization algorithm over DBN for TFP. Unlike existing techniques, which utilize shallow methods, our proposed TFP method uses an incremental CDE-Fuzzy-optimization-based DBN reliable for long-term and short-term TFP consisting of huge set of nonlinear data. The usage of technical indicators adds value to the work as it is capable of dealing with the nonlinear spatial and temporal correlation from the traffic data, which is incremental in nature. The prediction involved two major steps: In the first step, we applied the indicators to extract the flow strength features using MOM, RSI, CCI, ADX, and TEMA, and in the second step, the traffic flow is predicted using the DBN classifier, trained using the CDE-Fuzzy algorithm. The optimal weights for the DBN are computed using the CDE-Fuzzy algorithm, modeled by incorporating the fuzzy concepts in the DE algorithm. The experimental analysis performed on standard data set shows that the proposed CDE-Fuzzy DBN model outperforms the rest by solving uncertainty of nonlinearity in traffic flow data. The results obtained by the proposed method guarantee accurate traffic management in ITS. For future work, it will be interesting to investigate an improvement over DL with hybrid method and utilize the concept for transfer learning to predict the traffic flow in homogenous spatial links with inadequate data.
Footnotes
Author Disclosure Statement
No competing financial interests exist.
Funding Information
No funding was received.