
Abstract
The outstanding performance of deep learning (DL) for computer vision and natural language processing has fueled increased interest in applying these algorithms more broadly in both research and practice. This study investigates the application of DL techniques to classification of large sparse behavioral data—which has become ubiquitous in the age of big data collection. We report on an extensive search through DL architecture variants and compare the predictive performance of DL with that of carefully regularized logistic regression (LR), which previously (and repeatedly) has been found to be the most accurate machine learning technique generally for sparse behavioral data. At a high level, we demonstrate that by following recommendations from the literature, researchers and practitioners who are not DL experts can achieve world-class performance using DL. More specifically, we report several findings. As a main result, applying DL on 39 big sparse behavioral classification tasks demonstrates a significant performance improvement compared with LR. A follow-up result suggests that if one were to choose the best shallow technique (rather than just LR), there still would often be an improvement from using DL, but that in this case the magnitude of the improvement might not justify the high cost. Investigating when DL performs better, we find that worse performance is obtained for data sets with low signal-from-noise separability—in line with prior results comparing linear and nonlinear classifiers. Exploring why the deep architectures work well, we show that using the first-layer features learned by DL yields better generalization performance for a linear model than do unsupervised feature-reduction methods (e.g., singular-value decomposition). However, to do well enough to beat well-regularized LR with the original sparse representation, more layers from the deep distributed architecture are needed. With respect to interpreting how deep models come to their decisions, we demonstrate how the neurons on the lowest layer of the deep architecture capture nuances from the raw fine-grained features and allow intuitive interpretation. Looking forward, we propose the use of instance-level counterfactual explanations to gain insight into why deep models classify individual data instances the way they do.
Introduction
The past decade has seen an explosion of interest in deep learning (DL) techniques. Experimental research has demonstrated significant improvements over conventional machine learning techniques in fields such as object recognition1–3 and natural language processing.4,5 DL techniques automatically create efficient distributed representations. 6 By stacking nonlinear functions, hidden and complex data patterns can be learned with substantially less human feature engineering. The increased success of DL can be attributed to (1) an immense increase in available data, (2) increased chip processing capabilities and the use of graphics processing units (GPUs) for faster parallel computations, (3) declining costs of hardware, and (4) advances in machine learning research on DL, such as the introduction of new methods for avoiding overfitting.7,8
Since the initial successes of DL, it has also been successfully applied to high-dimensional data such as toxicological data,9,10 biomedical data, 11 and recommender systems.12,13 This raises the question whether the superior performance of DL also extends to other types of data and applications, 14 especially to data where nonlinear models have not excelled in prior research. Specifically, this study assesses the use of DL for classification with big sparse behavioral data. The application to such data is promising, due to their high dimensionality and the intuitively likely presence of important latent structure.
As people act in our digitally instrumented world, computer systems often record the trails we leave behind. These form behavioral big data. Let us define behavioral big data following Shmueli 15 : “very large and rich high-dimensional data on human actions and/or interactions.” Customer transactions with a bank, web surfers' webpage visiting behavior, mobile phone users' visited locations, and Facebook “likes” are just a few examples where each unique merchant, webpage, location, or liked page can correspond to a raw feature. Such data provide significant potential to support predictive analysis. 16 In prior research, such data have been shown to be remarkably predictive and can reveal a person's personality traits, 17 interest in banking products, 18 interest in a news article, 19 interest in a mobile ad, 20 credit default risk, 21 tendency to churn, 22 or tendency to commit fraudulent activities. 23
What is different from traditional classification settings is that such ultrahigh-dimensional behavioral data also are ultrasparse. 24 When modeling a web surfer's web visiting behavior, the collection of all possible webpages one can visit is huge. However, humans face a limit on their “behavioral capital” 24 ; for example, among all possible webpages, a person can only visit a limited number due to resource restrictions (mainly time in our example); among all possible merchants, a person can only transact with a limited number. The resultant behavioral data, therefore, are extremely sparse.
Predictive modeling from behavioral data is complicated by the fact that the processes generating the data are not well understood and often do not align with the assumptions on which our traditional modeling techniques are based.15,25 Traditionally, machine learning research for very high-dimensional data mostly employs shallow models, 7 which contain one layer for transforming the raw input features, in a linear or nonlinear manner, into a specific feature space. Examples of such techniques are linear or kernalized support vector machines. 26
When confronted with data from complex real-world processes such as human behavior, many researchers have questioned whether shallow techniques will suffice.7,27 In particular, behavioral data are suspected (by social scientists as well as machine learning researchers) to contain complex, distributed, and hierarchical relationships between its features.28,29 A distributed representation transforms the raw features through many-to-many relations into a new representation, which is able to capture fine-grained similarities between the independent features. At the lowest level, a user can be represented by each movie he or she has watched. On a higher level, a subset of movies can be telling of the person's (latent) interests. One group of movies can, for example, represent whether a user has an affinity with LGBT topics, whether he has an interest in sports, or whether he favors director Alfred Hitchcock. On an even higher level, these interests can reveal political preferences or religious beliefs. For example, a person watching movies such as Brokeback Mountain or Cowspiracy can be estimated to have a more liberal mindset. This line of thinking follows the value–attitude–behavior model 29 used in behavioral science, which states that people's social cognitions resulting in actions are organized in a compositional structure. Values are one's stable beliefs on the highest level of abstraction and are constructed of basic beliefs, which, in turn, give rise to value orientations. The latter influences a person's attitude, which finally leads to concrete human behavior.
The main drawbacks of DL methods, in contrast, are three. (1) The lack of solid theory as to why they work so well makes applying them highly dependent on the skill of the engineers and/or massive trial and error. 7 (2) The inner workings of a complex learned deep network are generally considered to be difficult to understand (at best).30–32 (3) Learning accurate deep networks from large data can be extremely time and resource consuming.32,33
In previous research specifically focusing on high-dimensional behavioral data, DL has been applied to movie preference data 12 and e-commerce activity data 34 (although in these cases through applying dimensionality reduction techniques). In this article, we build deep predictive models using the complete behavioral feature space and we allow the opportunity for the models to exploit all the information inherent to the data.
This study contributes to the literature in four ways: (1) first, this study presents a careful report on a systematic application of DL to big behavioral data; (2) second, we analyze the performance of DL techniques and compare it with the performance of well-regularized logistic regression (LR) (previously shown to excel on this sort of data) to assess whether and when DL can provide significant performance improvements; (3) third, we provide guidance for researchers and practitioners regarding the practical implementation details that work well (or not) for such data; and (4) finally, we attempt to give a high-level preliminary insight into why deep models work well on behavioral data and how they can be interpreted.
In what follows, first we give a brief overview of DL. We discuss in detail the specific architectural and training choices used for the experiments, paying particular attention to hyperparameter (HP) selection. We present the behavioral data used to evaluate and compare. We then present and discuss the result of comparing the predictive performance with the reigning best machine learning method for data such as these, as revealed by multiple prior studies.
DL Overview
When using DL for classification,7,14,35 we have a data set D, an indexed set of n data points
with modeling HPs
The final classification performance of the learned model is tested on a separate test set
The DL algorithm is applied to a particular network architecture (of which a concrete example is shown in Fig. 1) and minimizes the loss function
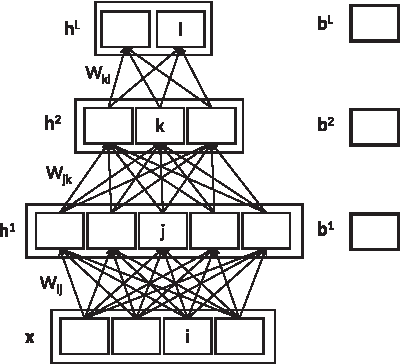
Example of a deep learning network with two hidden layers
Next, the gradient of the error is used in a backward pass to update the model's parameters W and
where
The objective function (2) of the DL problem formulation does pose difficulties. It defines a nonconvex optimization space characterized by multiple local optima, contributing to an inherently complex learning process. Using a local optimization technique such as SGD may result in the model getting stuck at local optima and thus may result in poor generalization performance. 27 Moreover, with a large number of layers and many hidden units, the number of model parameters can be massive, which requires a large amount of data to properly control complexity and not overfit. † ,37
A second difficulty faced by DL algorithms is that the algorithms and the models they produce are often condemned to being black boxes, due to the many layers, many learned parameters, and the models' cascading nonlinearities.
DL architecture and training
For this study, we apply DL following the best practices recommended by existing articles, practical guides, and textbooks (as well as we can).
‡
DL architectures are characterized by a large number of HPs.35,36 The values of the HPs associated with a machine learning model f are selected based on their (joint) performance on the separate out-of-sample validation set
where
To select appropriate values for the HPs in an empirical setting, a structured method is needed to search the HP space. 35 When DL models are trained in the literature, HPs often are chosen either based on researchers' experience in the specific field or through a structured or heuristic exploration of the HP space, such as manual search, grid search, or random search. 35 We are training deep neural networks on a sort of data where there is little specific experience to rely on for selecting HP values. (Reporting on such an experience for this sort of data is one contribution of this article.) Moreover, although they share similar characteristics, this study applies DL to many different data sets, for which separately optimized HPs should be used. 35
Bergstra and Bengio
35
observe that from the large collection of all HPs, usually only a small subset is relevant (referred to as low effective dimensionality). Their study empirically and theoretically demonstrates that nonadaptive random HP search is more efficient than manual search and/or grid search in high-dimensional search spaces. Although a high-dimensional grid may give even coverage over the grid, the coverage in the separate subspaces is less-evenly distributed. In contrast, random search counterintuitively explores a wider range in each of the subspaces. Therefore, we use random HP search
35
to evaluate 100 parameter configurations on the validation data
After selecting the best HP configuration, five-fold cross-validation 37 is used on the remaining data. During learning, progress is monitored by calculating the negative log likelihood on a separate part of the training set, which is used to prevent overfitting by early stopping. 40 Finally, the AUC is calculated on a separate test set after the learning is complete. We repeat this procedure for each of the five folds, resulting in five different AUC estimates measured on the test set. In other words, each iteration of cross-validation produces one estimate of generalization performance; thus, the AUC reported in our study is the average AUC on the test set measured over the five folds.
We ran the random HP search procedure and the actual learning algorithm on Amazon Web Services (AWS) g2.2xlarge instances with the Theano framework for DL. 41 These instances have 8 virtual CPUs, 15 GB RAM, and 1 Nvidia grid GPU.
Unsupervised pretraining
Unsupervised pretraining was one of the main reasons for the increased attention toward DL starting in 2006, due to significant classification performance improvements. 42 This pretraining phase uses a stack of representation learning algorithms (such as restricted Boltzmann machines [RBMs] 36 ) and separately optimizes the learned representation of each layer in an unsupervised manner. The goal is to use the learned representation of the unsupervised stage for a classification task with the same input data distribution. The idea behind greedy layer-wise pretraining originates from the following two beliefs: (1) the initial parameters can have an effect on the quality of the parameter optimization process and subsequently influence model performance during model fine tuning, and (2) the representation learned by a generative model on unlabeled input data can also be a good representation for a subsequent classification task. 27
Previous research has demonstrated the immense value in pretraining a neural network.40,42 Erhan et al. 40 empirically analyze the effect of pretraining and conclude that it mainly acts as a regularizer, influencing the starting point of the supervised training step. However, the study by Erhan et al. 40 was performed before the widespread use of many modern DL-related concepts such as rectified linear units (ReLUs) 43 and only takes into account the relationship with the number of layers.
We let the use of pretraining be a HP. In the random HP search, we choose to either pretrain the network or not through the use of a RBM. 36
Number of layers and number of hidden units
Both the number of hidden layers and the number of units they incorporate have an impact on the generalization capacity of the network. The HP search attempts to manage the critical trade-off between generalization ability on the one hand and overfitting on the other. For each HP combination, a number of hidden layers between 1 and 8 is selected; for each layer, a number of hidden units is drawn log-uniformly between 18 and 2000. Both ranges are based on HP values used by Bergstra and Bengio. 35
Minibatch size
Most modern optimization algorithms for DL do not use the entire training set at once, instead choosing more than one but fewer than all training examples at a time, 38 which is referred to as a minibatch. Choosing the size of the minibatch for SGD is a two-criteria trade-off influencing convergence and training time. When increasing the size of the batch, more efficient use can be made of the parallel matrix–matrix multiplications on the GPU. 36 Although the stochastic gradient estimates become more reliable with larger minibatch sizes, using fewer batches reduces the number of weight updates, thereby reducing optimization convergence. 36
In contrast, closely approximating the true gradient by increasing the size of the minibatch might not be the best choice to spend computation time in a nonconvex optimization space. Instead, exploring the search space with frequent updates may be a more appropriate tack, as a smaller minibatch size has been shown to increase generalization performance. 44 Furthermore, a small minibatch size acts as a regularizer, introducing noise when approximating the gradient through a smaller number of training set instances. 36
Following the literature,35,36 our HP search chooses the size of the minibatch randomly with equal probability between 20 and 100. In each epoch, each fold is randomly shuffled before minibatches are selected to speed up convergence. 36
Nonlinear activation function
The activation function of a neural network brings nonlinearity into the learning procedure. When choosing an activation function, care must be taken regarding the saturation of the activations and overly linear behavior. 14 If activations in the network become too saturated during learning, the gradients do not propagate well and units become inactive. If the functions behave in a linear manner, complex interactions will not be learned. 14 We consider the three most commonly used nonlinearities: the sigmoid, the hyperbolic tangent, and the ReLU. The HP selection randomly chooses one. These nonlinear activation units are elaborated in detail in Appendix A1.
Learning rate
The learning rate of the SGD optimization algorithm can influence convergence toward an optimum. If the learning rate is set too high, optima can be overlooked and the loss function will increase. In contrast, too small a learning rate results in very slow convergence.
Our random HP search algorithm draws an initial learning rate
Data
To evaluate the predictive performance of DL on large-scale behavioral data, we use behavioral data sets from prior research. We start with the collection presented by De Cnudde et al. 45 to benchmark machine learning methods on this sort of data. (De Cnudde et al. 45 did not compare with DL.) To this collection we add a collection of data sets predicting personal traits based on the things people “like” on Facebook.17,25,46,47
The MovieLens and YahooMovies data sets, for which we predict the ages and the genders of the users, contain data regarding which movies are rated by which users. The task for the larger MovieLens10m data set is to predict the genre of a movie based on the users rating it. This multiclass classification task is translated into 18 binary classification problems. The Ecommerce data set provides product viewing data on an e-commerce website from which the genders of the users are to be inferred. Shopping transactions in the TaFeng data set are used to predict users' ages. In the BookCrossing data set, books are rated by the members of the BookCrossing community, and based on these ratings, the ages of the users are predicted. The LibimSeTi data set contains ratings of dating profiles from which the genders of the users are to be inferred. In 2015, the KDD Cup challenge KDD2015 constituted the prediction of massive open online courses dropout based on fine-grained course interaction data. The Fraud data set contains financial transactions between companies to determine whether a company is involved in corporate residence fraud. 23 A consumer's interest in an online car advertisement is to be predicted based on his or her website viewing behavior in the Car data set. In the Flickr data set, users have tagged pictures as their favorites, from which a picture's number of comments is to be predicted. Lastly, the Facebook data sets include users “likes” of pages on Facebook from which the following target variables are to be predicted: intelligence, religion (Christian vs. Muslim), satisfaction with life, political belief (liberal vs. conservative), gay for male and female users, and gender. Table 1 lists the main characteristics of these data sets, and as one can observe, the dimensionality and the sparsity (measured as one minus the percentage of matrix entities that are “active,” which means that they are not zero) both are extremely high. The number of active elements reports the actual number of nonzero matrix entries.
Behavioral data sets
The target variables are all binary. The table is sorted by number of features.
MOOC, massive open online courses.
What to Compare Against?
De Cnudde et al. 45 present a comparative study of 11 widely used classification techniques applied to high-dimensional sparse behavioral data sets. They compare variations of support vector machines, naive Bayes, LR, and a relational classifier called pseudosocial network (PSN). For details regarding the techniques and their parameters, and the results, please see their article. 45 Their results show that LR with L2-regularization and batch gradient descent (LR-BGD-L2) produces overall the best results (significantly) in terms of AUC, as compared with the other shallow learners. Therefore, for our main results we compare DL with LR-BGD-L2. Note that despite LR-BGD-L2 being the best performer overall, for some specific data sets, other shallow learners such as PSN performed better than LR-BGD-L2. Thus, for completeness, Appendix A2 in Appendix A2 presents a comparison of DL with all the shallow classifiers compared in the article. 45 Please note that this prior benchmarking result is corroborated elsewhere; for example, the studies by Clark and Provost 47 and Chen et al. 46 also concluded (in different contexts) that compared with other non-DL methods, L2-regularized LR performed best on this sort of data.
Results and Discussion
To assess the performance of DL on behavioral data, we perform three analyses. First, we compare DL with LR-BGD-L2. The goal is to examine whether and (if so) when deep techniques are preferable for big behavioral data. Second, we dig deeper and analyze the influence of HP values on the classification performance for DL networks. Here, the goal is to get insight into the influence of choices of learning network architecture, characteristics of the optimization process, and unsupervised preprocessing. Third, we provide a preliminary view into why DL techniques perform well on behavioral big data and how they can be interpreted. To this end, we focus on the representation learning to try to understand the representations learned from these big behavioral data sets. The results and interpretations of these analyses are presented in each of the next subsections.
Performance of deep versus shallow learning
Table 2 gives the HP configuration for which the “best” results with DL are reached for each data set. (For all data sets, the best parameters come from nonpretrained models, hence, we have not included these HP results as an extra column.) Note that these configurations are not necessarily the best possible configuration for that data set. The configuration shown is the best performing configuration based on the selection procedure described previously. Different selection procedures or more computation could potentially lead to better classification performance. However, the computation time is already very high (2–3 days)—in both an absolute sense and relative to the competing LR—and the results (presented next) are unequivocal.
Best hyperparameter configuration for each data set from the random hyperparameter search procedure for the deep learning classification techniques
ReLU, rectified linear unit.
Table 3 gives the performance of the models learned with LR-BGD-L2 compared with the performance of those learned with DL. For each data set, the best classifier is denoted in boldface. At the bottom, the table also gives the average rank of the techniques (with the best-performing technique receiving rank 1) and the number of times it performs best. It is clear that, overall, DL is learning at least as well as or better than L2-regularized LR. DL has a lower average ranking (1.12 in contrast to 1.88) and it achieves a much higher number of wins (34 times in contrast to 4 times).
Predictive performance of the models in terms of area under the ROC curve for binary behavioral data sets
The highest achieved performance for a data set is indicated in boldface. The table is sorted by maximum AUC.
AUC, area under the curve; DL, deep learning; LR-BGD-L2, logistic regression with batch gradient descent and L2-regularization.
However, we can observe the hint of an interesting phenomenon, which may deserve further research. Specifically, for the three data sets with the lowest signal-from-noise separability (defined next), data sets BookCrossing to TaFeng given in Table 3, DL consistently results in lower classification performance. We say “a hint” because drawing a solid conclusion from three data sets is dubious; however, these results do concur with the results from prior research. Perlich et al. 48 show that the suitability of linear (in particular, LR) versus nonlinear learning methods depends on the signal-from-noise separability of the data set. In particular, Perlich et al. 48 propose that the maximum AUC (max-AUC) achieved by any classification method is a good proxy for the ability of machine learning to produce models that separate signal from noise in a data set.
Figure 2 plots the difference between the AUC of DL and LR-BGD-L2 against the maximum AUC achieved by either DL or LR-BGD-L2. Points above the horizontal line (where y = 0) are data sets for which DL performs better. The graph clearly shows two regimes: first, when the max-AUC is high (0.8 and above), DL performs much better than LR for many data sets, and second, there is no data set for which DL performs worse than LR. When the max-AUC is <0.75, DL does not outperform LR. Curiously, the study by Perlich et al. 48 also showed a regime change at max-AUC = 0.8. Again, we do not have enough data sets in the lower separability regime to draw any clear conclusion; however, many popular DL successes are on data where the inherent signal-from-noise (SNS) separability is high. (Besides using max-AUC as a proxy, we can ask: how well can a human do the task?)
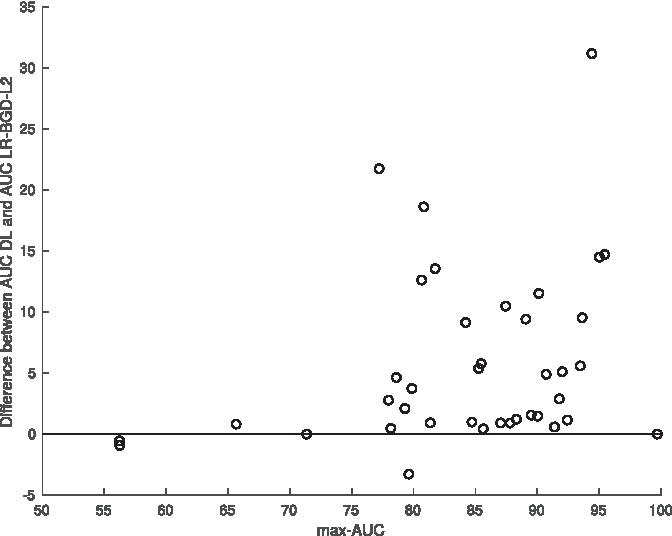
Difference between AUC of LR-BGD-L2 and DL plotted against max-AUC. Dots above the horizontal line denote data sets where DL outperforms LR-BGD-L2. AUCs are represented as percentages. AUC, area under the curve; DL, deep learning; LR-BGD-L2, logistic regression with batch gradient descent and L2-regularization.
We use the Wilcoxon signed-rank test to make a formal statistical comparison between the performance of DL and LR-BGD-L2. 49 For extrapolating the findings of this test to a larger population of behavioral data sets, ideally the data sets should form a random and representative sample of the population of all possible behavioral data sets. However, our data collection consists of multiple multitarget problems (Facebook, YahooMovies, and MovieLens), which are subsets of prediction problems with the same input vectors but different target variables. This may result in consistency regarding the performance of their classifiers. We take two different approaches, both used by De Cnudde et al., 45 to address this. The first approach selects a random data set from each multitarget problem to represent the others. For example, of all seven classification problems using the Facebook data, only a randomly chosen problem is used for the statistical comparison (e.g., Facebook_political). The second approach assigns equal partial weights to the multitarget data sets in order for all information to be present in the analysis. For example, each of the seven classification tasks that makes the use of the Facebook “Like” data will only weigh a small bit in the total comparison. More specifically, the weight can be divided equally over the classification tasks that use Facebook data, such that each task gets a weight of 1/7th in the comparison. From Table 4 we conclude that both approaches lead to the same statistical conclusions, and for this reason, we only discuss the latter. Concretely, the test is performed with a sample size of 13 data sets.
Pairwise comparison between deep learning and L2-regularized logistic regression using (1) a random, representative sample or (2) a weighted approach for multiple multitarget problems
SNS, signal-to-noise.
We find a p-value of 0.0212, which shows that DL performs marginally statistically significantly better than LR-BGD-L2. However, the performance improvement does not reach a 1% significance level. This can be attributed to (1) the additional complexity of DL merely resulting in marginal performance improvements on some data, 50 which thus do not contribute to statistical power, and (2) DL performing worse for low-SNS data, as discussed earlier.
To formalize the latter, we repeat the test using only the data sets that exceed the signal-from-noise separability threshold of 80% given in Perlich et al. 48 and we find a p-value of 0.0078. This shows that for high-SNS data sets, DL performs significantly better at a 1% significance level. Compared with the previous test results, the p-value is smaller (0.0078 in contrast to 0.0212); thus, we conclude that the signal-from-noise separability of the data set should be considered when deciding whether to invest significant resources in applying DL to big behavioral data. §
The focus of the experiments was to compare the predictive performance of DL with the method that has been reported repeatedly to be the best method for high-dimensional sparse behavioral data—appropriately regularized well-optimized LR. Besides the scientific interest, such a comparison has practical import, for example, to give guidance into whether applying DL often may be worth the cost, since DL requires much more computational (and engineering) effort than LR. The results given show that for high-signal-from-noise-separability data sets, DL indeed generally yields better generalization performance (in terms of AUC). However, prior research also showed that LR is simply the overall best “shallow” method, not universally the best; other computationally efficient modeling techniques sometimes perform much better. Figure 3 shows the difference in performance between DL and the best shallow method reported for each data set by De Cnudde et al. 45 (all of those being relatively efficient computationally). We see that by this comparison, DL excels on fewer data sets (compared with Fig. 2), generally performing marginally better or on par with the best shallow method. Nevertheless, in terms of the number of wins, DL still outperforms the best shallow learner (27 in contrast to 11, see Appendix A2). The maximum difference in AUC between DL and the best shallow learner shown in Figure 2 is achieved when predicting intelligence quotient from the Facebook data, which indicates that DL is learning something nonlinear that is important for this task. This comparison has a serious limitation however: we cherry-picked the best method, which potentially suffers from overestimation of generalization performance due to statistical multiple comparisons. An interesting follow-up would be to conduct a careful study, choosing the best shallow method for each data set by cross-validation (the choice of shallow technique then becomes a HP). That way the generalization performances could be compared on equal footing, as well as the computational efforts required (note that running a whole bunch of shallow methods, and choosing the best using cross-validation, is not necessarily so computationally efficient, even if the individual techniques are).
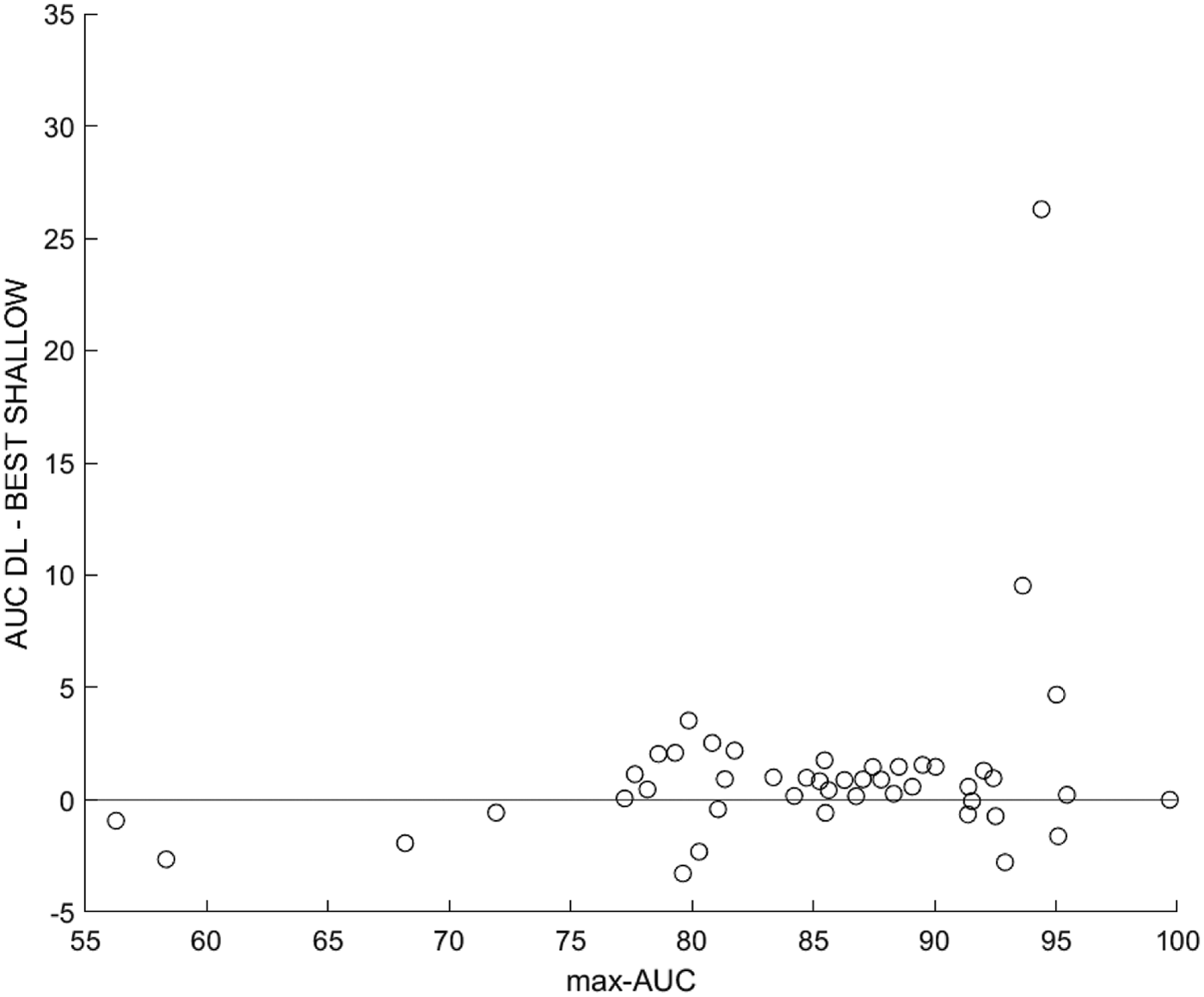
Difference between AUC of the best shallow model (chosen from 11 shallow classifiers) and DL plotted against max-AUC. Dots above the horizontal line denote data sets where DL outperforms the best shallow model.
Influence of HPs
When training the DL models and evaluating their generalization capacity, no improvement is found when using pretraining. Figure 4 shows the test classification error on the MovieLens1m data set for 500 different random configurations for which only the pretraining flag was changed. (Note that this figure is representative of the remaining data sets). It is clear from this comparison that not pretraining the network results in marginally lower test classification error on average, and more strikingly, substantially lower variance. Furthermore, pretraining the network substantially increases the training time, which already is very high for these data.

Test classification error for the MovieLens1m data set for predicting gender without pretraining (left) and with pretraining (right).
The fact that unsupervised pretraining does not improve classification performance is in line with prior non-DL results. Unsupervised dimensionality reduction, through techniques such as singular-value decomposition (SVD), non-negative matrix factorization, or latent Dirichlet allocation, often is used to create distributed representations upon which traditional machine learning methods are applied (see, for example, the original article using the Facebook data 17 ). Research has shown, though, that for sparse high-dimensional data such as those that are the subject of this article, such unsupervised “pretraining” does not tend to improve classification performance for LR. 47 We will return to the topic of distributed representation learning later. Thinking about the Fraud data set as an example, the reason for inferior performance of pretraining could be the following. The instances are companies and the features constitute one aspect of a company's behavior, namely, its transactions with other companies. The model needs to learn to predict another aspect of that company's behavior, namely, whether that company would commit corporate residence fraud. When pretraining a model in an unsupervised manner, a generative model learns the variations present in the input data without taking into account the target classification. The applications for which DL has proven superior such as image recognition likely require higher level feature engineering, as individual pixels usually carry almost no predictive information. Moreover, for an image of a cat, everything in the (cat part of) image is related to being a cat. For fraud detection from company behavior, all the company's behavior generally is not related to fraud (hopefully). Rather than integrating all the data into a set of pieces of a cat, the learner must find those pieces that are indeed related to fraud. Therefore, supervised representation learning winning out over unsupervised representation learning might not be surprising.
Figure 5 shows the test classification error for the MovieLens1m data set when varying the nature of the activation function for 500 random parameter settings. (Again, this figure is representative of the remaining data sets). Overall the tanh nonlinearity gives the best results. This result is found on the bulk of the data sets in this study. Although ReLUs do create faster models and could be recommended in very high-dimensional settings for reducing computational complexity, they result in lower predictive performance.
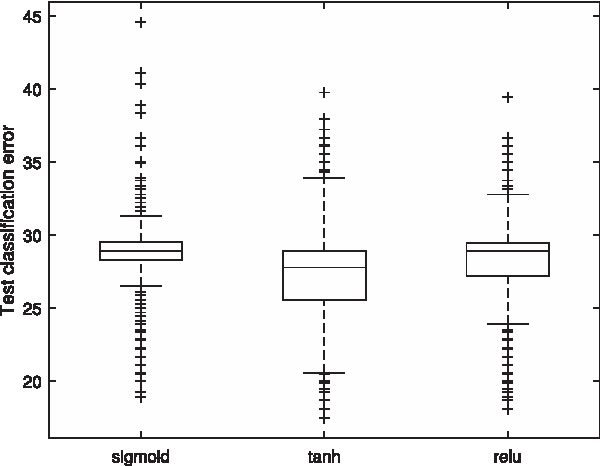
Test classification error for the MovieLens1m data set for predicting gender with the sigmoid nonlinearity (left), the tanh function (middle), and the ReLU nonlinearity (right). ReLU, rectified linear unit.
Considering that ReLUs create sparse models, this result is in line with non-DL prior work, 24 which shows that when analyzing high-dimensional behavioral data for predictive purposes, a very large number of the fine-grained behavioral features contribute to the final prediction. Thus, sparse models do not perform as well. Prior work also has reported that for this sort of data, learning linear models with L1-regularization (thus creating sparse models) underperforms modeling with L2-regularization.45,47 Taken in tandem, these results make sense: L2-regularization is better suited when many features are relevant. 51
Finally, when looking at the effect of the number of hidden layers on the test classification error shown in Figure 6, no consistently better-performing setting can be found for a single data set (MovieLens1m), as well as over all data sets (see the configurations in Table 3). Practitioners should, therefore, test several configurations with a varying number of hidden layers and choose the best-performing architecture.
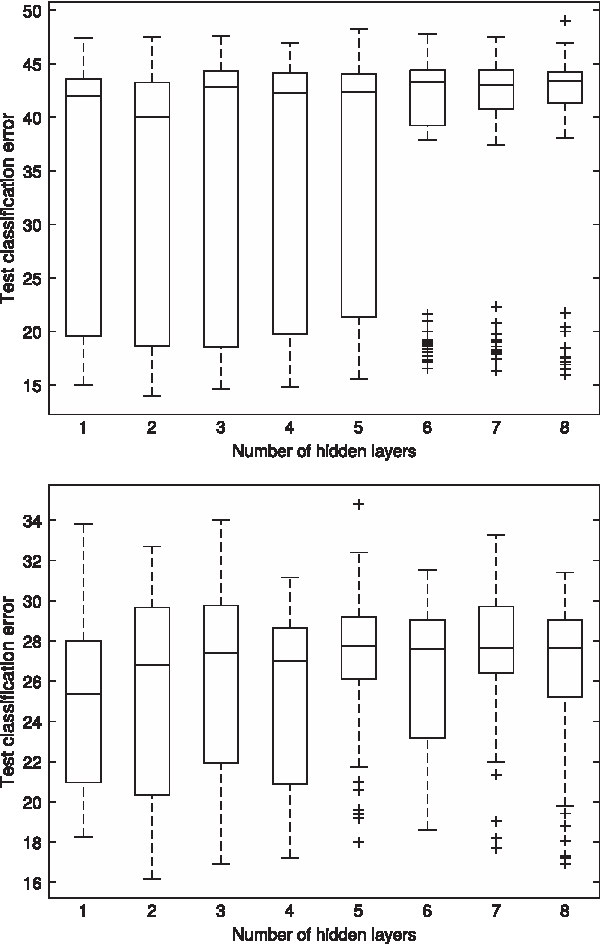
Test classification error for the MovieLens1m data set dependent on the number of hidden layers for predicting age (top) and predicting gender (bottom).
Interpreting deep versus shallow models
In some settings, model comprehensibility is mandatory before a model can be deployed; in others, explaining why the model predicts what it does can help acceptance within an organization.52–55 One of the advantages of linear shallow classifiers lies in their comprehensibility. The weights given by the model to each of the input features can be inspected and interpreted by humans. Such “global” explanations give insight into how the model works. Instance-level explanations explain why individual cases were classified in a certain way. 55 For linear models, fast optimal methods exist for explaining the classification of individual instances. 55
Table 5 lists the features with the highest weights given by LR with L2-regularization for the following classification tasks: predicting (1) gender and (2) age from movie rating data and predicting (3) liberal political beliefs and (4) high intelligence from Facebook like data. A careful interpretation of the features and their relation to the classifications are beyond the scope and purpose of this article. However, we would like to illustrate that despite the inability to simply list out the “most highly weighted” features for the DL models, as we can with linear models, we still have options for interpreting them.
Features with largest coefficients for logistic regression with L2-regularization
The higher scores indicate higher probability of being (1) male when predicting gender for the MovieLens data set, (2) young when predicting age for the MovieLens data set, (3) liberal when predicting political preference for the Facebook data set, and (4) high IQ when predicting intelligence for the Facebook data set.
Before focusing on the options for the DL models, let us examine the top-weighted features in the LR models. When predicting whether a user is male based on movie-rating data, we can see that higher weights are given to movies that one might suspect were targeted toward male viewers, such as Starship Troopers, Star Trek, and Apollo 13. Looking at the weights that are discriminative for identifying younger viewers, we can see horror movies such as Scream and I Know What You Did Last Summer as well as other movies that it is hard to argue were not target to younger viewers such as The Princess Bride and Willy Wonka and the Chocolate Factory. For the Facebook data set, features such as Barack Obama, The Daily Show, and The Colbert Report are generally associated with a liberal mindset. When predicting whether a user has a high IQ, TV shows such as The Big Bang Theory and Lost receive higher weights.
In contrast to the case with shallow models, the multiple layer nonlinear structure of DL models does not lend itself to direct interpretation. We now demonstrate two approaches to gain insight into the workings of the DL models. First, we can examine some of the neurons in the network, and try to interpret the nuances in the higher level “constructed features” generated from the low-level representation. Second, we illustrate how instance-level explanations can increase understanding of why a DL model classifies individual data instances as it does.
As mentioned previously, the DL models learn distributed representations based on compositionality in the fine-grained features. Each neuron in this multilayered setting assigns weights to lower-level concepts and thus allows for a complex many-to-many combination of all features on different levels. In contrast, shallow techniques such as LR and support vector machines can be viewed as consisting of one neuron, assigning feature weights on one level only (Table 5). To illustrate, Table 6 shows five neurons in the first hidden layer of the best-performing architecture (Table 2) and the features for which they are most activated when predicting gender for the MovieLens1m data set.** At the risk of repeating ourselves, we emphasize that we are not claiming that our interpretation here is in any sense correct, and even where present, any associations between features and classes are statistical not absolute. Our goal is to illustrate the methods: we apply our own interpretation as part of that illustration. (We do assert that a careful research study into the effectiveness of such interpretations for a concrete explanation goal would be valuable.)
Features with largest coefficients for five neurons in the first layer in the deep network for predicting gender on the MovieLens data set
Each neuron captures additional fine-grained information. The “cluster names” at the bottom show our interpretation of these neurons, based on the highest weight features.
So, with all of the bias that we bring to the interpretation, each of the five neurons seems to capture a separate nuance of the relationship between movies and gender (see our interpretations in the bottom row of Table 6). Neuron 1 for example captures an aspect of genre by assigning higher weights to romance and drama movies. Neuron 2 focuses on action movies and comedies, which we believe to be favored by male viewers, while neuron 4 discriminates toward “male-oriented” drama movies (more specifically, dramas involving space, war, and other dangerous situations). Neuron 3 becomes active for sport movies, and neuron 5 identifies movies that one might consider to be preferred by female viewers—specifically, movies about love, romance, and relationships, among other things. (Note that Breakfast at Tiffany's and Little Women are explicitly called out in Wikipedia's entry for the “Chick Flick” movie genre; note also the critique of this as a genre, also discussed in the Wikipedia entry. †† )
For the Facebook like data set, Table 7 shows four neurons of the first layer of the deep model for predicting a liberal mindset and the features for which these neurons have high weights. It is unclear here exactly what each neuron might be representing, but they do seem to be grouping “likes” by some sort of similarity. Neuron 1 shows several comedy shows and movies. Neuron 2 has several rock bands (plus Jim Croce, interestingly). Neuron 3 seems to select for hobbies, and Neuron 4 again for rock bands—but of a later era (and Rascal Flatts is a country band).
Top features with highest coefficients for four neurons in the first layer in the deep network for predicting a liberal mindset from the Facebook data set
Each neuron captures additional fine-grained information (our interpretation, bottom row).
Despite the possibility that such interpretations are meaningful, especially with the latter example, we do not get a good idea of why these neurons would be helpful for predicting the target variable—liberal mindset. Also, this approach becomes infeasible when a much larger number of neurons are present. 28 Moreover, it is insufficient to only interpet first-layer neurons as higher-level concepts are derived from lower-level concepts, and the cascading nonlinearities are not addressed by this sort of explanation. That being said, these examples illustrate that deep architectures capture potentially complex concepts, with more structure and nuance than we see with linear models.
Another approach to disentangle the inner workings of deep classification models is by examining instance-level explanations. 55 Global explanations are particularly challenging for ultrahigh-dimensional behavioral data. But the sparseness of the data provides an advantage when examining instance-level explanations. If we care about what is there in the data that leads the model to classify as it does, we can look specifically for counterfactual explanations of the classification,46,55,56 which report those features that cause the network to classify the instance as it does. An instance-level counterfactual explanation is a minimal (irreducible) set of features such that removing those features would change the predicted class of that specific instance.
Carefully examining instance-level explanations for deep-learned networks from behavioral data is beyond the scope of this article (and would be a very interesting article in itself). However, it is straightforward to show what such explanations would look like. Consider the Facebook like data. An instance-level explanation will focus on explaining why a certain Facebook user is classified as a specific class of interest (e.g., “high intelligence” or “female”). As an illustration, Figure 7 shows the reason why a certain instance (Facebook user Julie in our example) is classified as highly intelligent: if Julie would not have liked “Antwerp.ai,” “Cowspiracy,” and “Black Mirror,” then her predicted class would change from highly intelligent to medium intelligent. In other words, if the data for Julie had not contained likes for these pages, her predicted class would not have been “high intelligence.” Note that we follow the procedure described by Martens and Provost 55 to generate explanations.

Example explanation why Facebook user Julie is classified as highly intelligent.
As explained in detail by Martens and Provost, 55 there are many reasons why explanations are necessary for data-driven decision-making systems. For example, automated decision-making systems often need to be justified to the stakeholders who will approve their use. Particular decisions may be called into question and, therefore, need to be explained. Machine learning engineers may need to improve or debug a deployed system. In all these situations, explanations for decisions can be substantially informative. A careful study of explanation approaches for DL from large sparse behavioral data is an important topic for future research.
Why DL performs well
Finally, to gain added insight into why DL works well on behavioral big data, we now demonstrate the added value of the deep models' distributed feature representation. Recall that previously we discussed how learning unsupervised distributed feature representations has been shown not to be helpful for improving LR models. DL learns a distributed representation (the first layer of the deep architecture). However, the backpropagation through the deep architecture means that the distributed representation learning is supervised. Thus, it may be that the distributed representation learned at the first layer is the main source of the power of the DL.
To examine how much value is provided by the supervised learning of a distributed representation for the sparse raw features, we transform the original highdimensional data sets onto three reduced-feature data sets and assess their prediction capability. More specifically, we build an LR-BGD from each reduced feature space. We compare the following three models:
An LR-BGD model where the features are the first-layer distributed features learned by DL (Table 2). An LR-BGD model that uses L1-regularization to identify relevant features, with the regularization parameter set in the same way as with LR-BGD-L2 mentioned previously. A feature with a corresponding nonzero weight thus is being used by the model. An LR-BGD model that uses as features the distributed representation created through SVD. This representation is similar to that created by DL, but learned without referencing the target variable (i.e., unsupervised).
‡‡
For this experiment, we chose the same number of SVD dimensions as first-layer DL features in the DL architecture (Table 2).
The results of this analysis are given in Table 8. Among the three alternative LR methods, the method with the largest AUC is shown in bold. For 33 out of 39 data sets, the latent features learned by DL result in better predictive performance than the selected or latent features resulting from the other two approaches. This demonstrates the value of the distributed representations learned by DL in a supervised manner, and gives preliminary insight as to why DL techniques perform well on behavioral big data.
Area under the ROC curve reached with logistic regression (LR; rightmost three columns) by transforming the original high-dimensional datasets onto a reduced feature set by taking the first-layer neurons as features for the LR (DL-layer1-LR), by applying feature selection through L1-regularization (L1-LR), and by creating an unsupervised distributed representation through singular-value decomposition-LR
Bold indicates the highest achieved AUC for that dataset by the reduced feature sets (excluding the DL model built from the original, high-dimensional dataset).
These are compared here with the AUCs with the full DL.
SVD-LR, singular-value decomposition-logistic regression.
However, as given in Table 8, for every single data set the prediction capability of the entire DL model remains higher than using any of the reduced-dimensionality feature sets. For this reason, we conclude that the higher layers in the deep architectures add considerable value for modeling the complex nonlinear dependencies present among the independent behavioral features.
In addition, when comparing the performance of the model built from the DL first-layer neurons against the full LR-BGD-L2 model (Table 3), we observe that the full LR-BGD-L2 model outperforms the reduced feature model (in terms of AUC), which is in line with prior findings. 47 Nevertheless, these results suggest further research directions in terms of using the distributed nature of first-layer neurons (and by consequence, higher-level neurons) for purposes of feature engineering. For example, typically tree-structured models do not work well for this sort of data, due to the extremely high dimensionality and need for nonsparse models. However, what about an ensemble of trees built on the deep-learned distributed representation?
Conclusion
In the past, DL has shown significant performance improvements for tasks from image classification, speech recognition, and natural language processing. This article performs a detailed study examining whether these improvements also extend to behavioral big data. We demonstrate the usefulness of the supervised learning of deep distributed representations of fine-grained behavioral features, while shedding light onto when and why DL performs well and how these models might be interpreted. As a practical contribution, we provide guidance regarding favorable HP configurations for learning these models.
A head-to-head comparison between DL and LR shows that DL achieves a statistically significant performance improvement over well-regularized LR. However, in a less rigorous comparison with shallow techniques beyond LR, although DL still comes out on top, in many cases the marginal improvements of the more complex models overall are quite small. Investigating when DL performs better, the results suggest that DL is not better in problem settings where the data are characterized by low SNS separability. This line of inquiry requires further research.
To (partially) open up the black box, we first investigate the distributed representations learned by the deep models and illustrate how the nuances captured by first-layer neurons can be interpreted. Although not all neurons are easily interpretable and domain knowledge is needed, this demonstration suggests directions for further research. Moreover, it provides an avenue for decision makers to obtain insight and intuitions into the lowest level of the behavioral hierarchy. Second, we suggest instance-level explanations for interpreting deep models as an approach worth exploring in future research.
The distributed and nonlinear nature of deep models may explain why DL works well on complex behavioral data. More specifically, we demonstrate that the first-layer features learned in a supervised manner by DL yield higher prediction accuracy (AUC) than other methods for reducing features (yet not as high as well-regularized LR using the full shallow feature set). This supports the added value of supervised learning of distributed representations for behavioral data.
On a more practical level, we have tried to provide insight into the implementation characteristics of DL on behavioral data. The multitude of HPs can be overwhelming for researchers and practitioners when applying DL for this or any new application. Two HPs are found consistently to achieve better results. First, dense representations throughout the models achieve better predictive performance, more specifically by employing tanh activation functions. Second, using an unsupervised pretraining phase does not improve performance in this discriminative setting. Apparently, unlike in tasks such as object recognition, the input variations learned through the pretraining phase do not contribute substantially to the final classification task. This can be due to an inappropriate underlying generative process, not tailored toward human behavioral data and/or the subsequent prediction task. Another explanation is that the unsupervised learning cannot efficiently grasp the important variations in the complex data without taking into account the target variable. Future research could focus on developing an unsupervised generative process that fits the process of human-generated behavior better. However, since the target variable is often not clearly related to the input data, it seems worthwhile to focus on supervised pretraining, so that input data variations can be explicitly related to the variable of interest.
This article demonstrates the usefulness of DL for behavioral big data and underlines its potential in future applications with this type of data. The performance improvements must be considered in tandem with the drawbacks in terms of additional computational and implementational complexity. This hurdle might currently render them infeasible in a practical setting—for our results it often took multiple days for training on the very fine-grained data sets. As the availability of GPU units on cloud computing instances becomes more widespread and Theano's support for multiple GPU use becomes less experimental, the computation time could be improved substantially. (One still must consider paying for this computation.) In contrast, in practice big behavioral data may be much larger than the data sets analyzed in this article—which will make DL methods even harder to apply, but also may render them more accurate, as the relative performance of linear and nonlinear methods is critically related to the amount of training data. 48 As a future study, it would be interesting to see a learning curve analysis to see whether we might expect substantial increases in generalization performance with DL for high-dimensional sparse behavioral data (cf. the usual learning curve performance of shallow learning on such data 24 ).
Footnotes
Author Disclosure Statement
No competing financial interests exist.
Funding Information
Sofie De Cnudde and Yanou Ramon thank the Research Foundation-Flanders for supporting this research. Sofie De Cnudde has received funding from the Research Foundation-Flanders under the Grant number G031914. Yanou Ramon has obtained a PhD Research Fellowship from 2018–2022.
Foster Provost thanks Andre Meyer for a Faculty Fellowship and the NYU/Stern Fubon Center for supporting research in Data Analytics and AI.