
Abstract
At present, due to the introduction of the big data era, numerous numbers of data are generated consistently. Many applications utilize big data platforms, namely Spark, Hadoop, Amazon web services, and so on, since these platforms use several parameters for tuning that further enhance the operating performances. It requires a long duration of time to tune the parameters because of the complex relationship and large quantity of parameters. As a result, the building of such parameters and performance optimization at a particular duration of time becomes a challenging task. Several auto-tuning approaches are developed to achieve an optimal design. However, these approaches increase the computation time and minimize the efficiency of the cluster. It is necessary to tune the parameters automatically with low computational and processing time as well as to improve the performance of the system. In this proposed approach, a novel automatic parameter tuning system named as Opt. Tuner is proposed to select the Hadoop configuration parameters with less computational time. The optimization of the proposed approach is achieved by the Flower Pollination Algorithm. Here, a chaotic mapping along with Opposition-Based Learning is introduced for population initialization to form a novel Oppositional Chaotic Flower Pollination Algorithm. The main motive of this initialization phase involves in generating better individuals and to guide the search agent more quickly. In this novel approach, 15 configuration parameters are considered for auto-tuning. Finally, the performance of the proposed approach utilizes the wordcount and sort application to investigate the exhibition and proficiency of diverse databases.
Introduction
Nowadays, the IT business is continuously developing, and big data is one of them. Big data has drawn dynamically more ideas among the headways of the scattered space. Due to the enhancement in the World Wide Web, it explores a high-dimensional data that guide the growth of the business model and create an incredible trade opening. Since big data is more complex and enormous, the regular handling apparatus such as storing, regulating, and examining at a suitable length becomes a difficult task. In the case of pre-engineered, inadequately organized and poorly characterized delineation of the huge extent of data, big data is utilized to tackle all those drawbacks. Therefore, big data refers to the information that manages the programming advancements and the conventional data set. 1
The clustering of tremendous or immense database forms a high-dimensional data that cannot be prepared to utilize the standard framework. Therefore, big data is employed to investigate various apparatus, its system, and its structure and turns the entire subject into a simple structure. Also, big data is capable of dealing with the structure regarding the uptime and downtime as well as the combined joining information from all systems. For a better understanding of the initial constraints, Big Data technology needs item equipment for data stockpiling and examination. Moreover, big data contains a copy of the original data to crosswise over other groups. Hence, big data technology requires the examination of data regarding data combinations and data crosswise over other machines. 2
Hadoop is a structure that can be accessed freely, and it was launched by a software foundation named “Apache.” The fundamental operations of the Hadoop framework is based on two concepts, namely parallel processing theory regarding various batch operations and distributed computing concepts. Several components combine to form a Hadoop structure, namely MapReduce meant for processing of data, YARN meant for resource management in association with clustering, and HDFS (Hadoop Distributed File System) for storing the data. 3 The fault-tolerant storage system is referred to as the Hadoop file distributed storage system. Here, the large files with numerous data nodes from the local storage are distributed across the cluster. The Hadoop framework is the most prominent technology for storing, processing, and analyzing the big data.
The HDFS and the MapReduce are the center advancements of the Hadoop framework. The HDFS provides the usage of huge memory constraints, whereas the MapReduce provides the extreme reach of big data regarding figuring. As the integration of both MapReduce and HDFS, it helps in the execution of different undertakings and highly arranged affiliation. Due to several advancements in the Hadoop framework, numerous movements and contradictions are made reliable. MapReduce becomes more realistic in dealing with big data, and its operation is based on parallel processing related to HFDS. MapReduce is an integration of three slaves and one master. Classically, the mapping task runs on the data nodes of a similar structure whenever the data exist. During MapReduce operation, if one of the nodes is loaded heavily, it prefers another data node from the same rack. 4 The MapReduce concept involves four processes, namely splitting, mapping, shuffling, and reducing, to obtain the final output as shown in Figure 2. The MapReduce framework is utilized in several applications to process very large proportions as well as massive clustering of data in an ideal way. The MapReduce concept relies on java for the program model and its methodology. 5 In recent years, evolutionary methods have been performed a better performance for engineering problems.6–8
In the present study, to enhance the system performance and to tune the parameter automatically, a novel Opt. Tuner is utilized in selecting the Hadoop configuration parameter with very low computational time. The optimization is accomplished by the Flower Pollination Algorithm (FPA). Also, this approach utilizes the chaotic mapping strategy to initialize the population. The parametric metrics, such as sort applications and wordcount, are utilized to examine the efficiency of the system. The contribution and organization of the proposed approach are summarized as follows:
Demonstrating an automatic parameter tuning system to construct the Hadoop configuration parameters for big data jobs. Utilizing the FPA for auto-tuning with low computational and processing time. Determination of a novel Oppositional Chaotic Flower Pollination Optimization approach to guide the search agent more quickly and to generate better individuals during population initialization.
The rest of the article is organized as follows. Review of Related Works section overviews the past writing, which focused on the big data analytics stages. Proposed Approach section introduces the overview of the MapReduce framework, its parameter configuration, and tuning; also this section provides the description regarding the formulation of a Flower Pollination Optimization algorithm. In addition to this, the population initialization using chaotic mapping and the tuning of optimal parameter configuration using Oppositional Chaotic Flower Pollination Algorithm (OCFPA) is described. Results and Discussion section gives the outcome, and the data set parameters are analyzed for the test results. At last, in the Conclusion section, the conclusion of the article is presented.
Review of Related Works
In this section, various research works have been focused based on the big data analytics stages. Here, the programmed tuning of parameters in the big data stage is one of the interesting issues. To gain a better understanding, several relevant research areas and its related works summarize the following section.
Herodotou and collegues9,10 proposed a streamlining approach based on the cost that provides design analysis and proposals to the consumers. Here, an automatic tuning system named Starfish was introduced to analyze the big data. Also, the starfish was built over the Hadoop for better tuning performances and self-tuning. This proposed approach overcomes several challenges regarding numerous tuning knobs in Hadoop. The main motive of this research approach is that it utilizes a straight forward direct model for automatic parameter tuning.
Shi et al. 11 introduced a tuner known as MR Tuner that facilitates holistic optimization intended for MapReduce purposes. Along with MR Tuner, a new producer-transporter-consumer was proposed to characterize the parallel implementation and trade-offs between various tasks. An efficient algorithm was also designed to examine and execute the complex parameters. The experimental results revealed that this approach provides better tuning parameters with high efficiency than other methods.
Song et al. 12 constructed an offset-based execution model that uncovers the connection between the processing time of use and GPU execution constraints. Numerous approaches were introduced in isolating the power and identifying their root source. Here, several hardware performances along with the machine learning technique was introduced along with the GPU architecture to develop an accurate power prediction. Also, this proposed approach identifies the performance regarding power and their root source for memory access patterns and several complex calculations. The experimental results revealed that the proposed approach is more robust and accurate when compared with all other approaches.
Bakratsas et al. 13 developed a Hadoop MapReduce performance based on Solid State Drives and Hard Disk Drives. Here, two complex operations, namely wide network and local operations, were performed in the network. Moreover, these types of networks are utilized in various complex processing applications. The hard disk drives and the solid-state drives are implemented by means of these complex operations to provide better optimization results. The results obtained from this proposed approach provide real network data.
Wu and Gokhale presented profiling and performance analysis-based system (PPABS), 14 which consequently adjusts the system parameter arrangements that depend on executed business profiles in Hadoop. This framework involves analyzer and recognizer parts. The analyzer prepares their proposed system to arrange the businesses having equivalent display into a ton of indistinguishable classes. It uses K-means++ to gather the occupations and copied toughening to find perfect settings. The first run the new position on a little data set using default plan settings and a short time later applies the model affirmation technique to describe it. Each class has the best game plan parameter arrangements.
A MapReduce performance model for Hadoop 2.x was proposed by Glushkova et al. 15 Although there are several approaches that provide a better system, efficiency was introduced for Hadoop 1.x, but such efficient approaches are not well suited for modeling the Hadoop 2.x. Therefore, this approach was introduced to provide a better performance model for Hadoop 2.x. Also, the cost model was minimized with an enhanced accuracy value rate, and this proposed approach was compared with various other existing approaches to provide an efficient performance model.
Qureshi et al. 16 proposed a low-cost Hadoop cluster for analyzing the image and the performance of the robotics under a cloud-based environment. This article is proposed to examine the effectiveness of robotic applications regarding the back-end cloud computing framework. The low-cost Hadoop cluster was utilized while computing and designing of the system. The experimental results of this proposed approach revealed that the Hadoop cluster for image analysis was obtained at a very low cost with an enhanced accuracy rate.
Proposed Approach
The proposed strategy utilizes a novel Opt. Tuner for parameter tuning at a very low computational time. Also, the OCFPA is employed, thereby obtaining an optimal parameter tuning framework.
MapReduce framework
A Hadoop MapReduce framework utilizes a map function to process the data set part, which is also referred to as mappers. Then, the mapped data set is reduced by means of reducers to provide better optimization results from the mappers. Accordingly, a large data set is split among the mapper and the reducer by a MapReduce function. 17 Figure 1 describes how a MapReduce is employed in executing the cluster group.
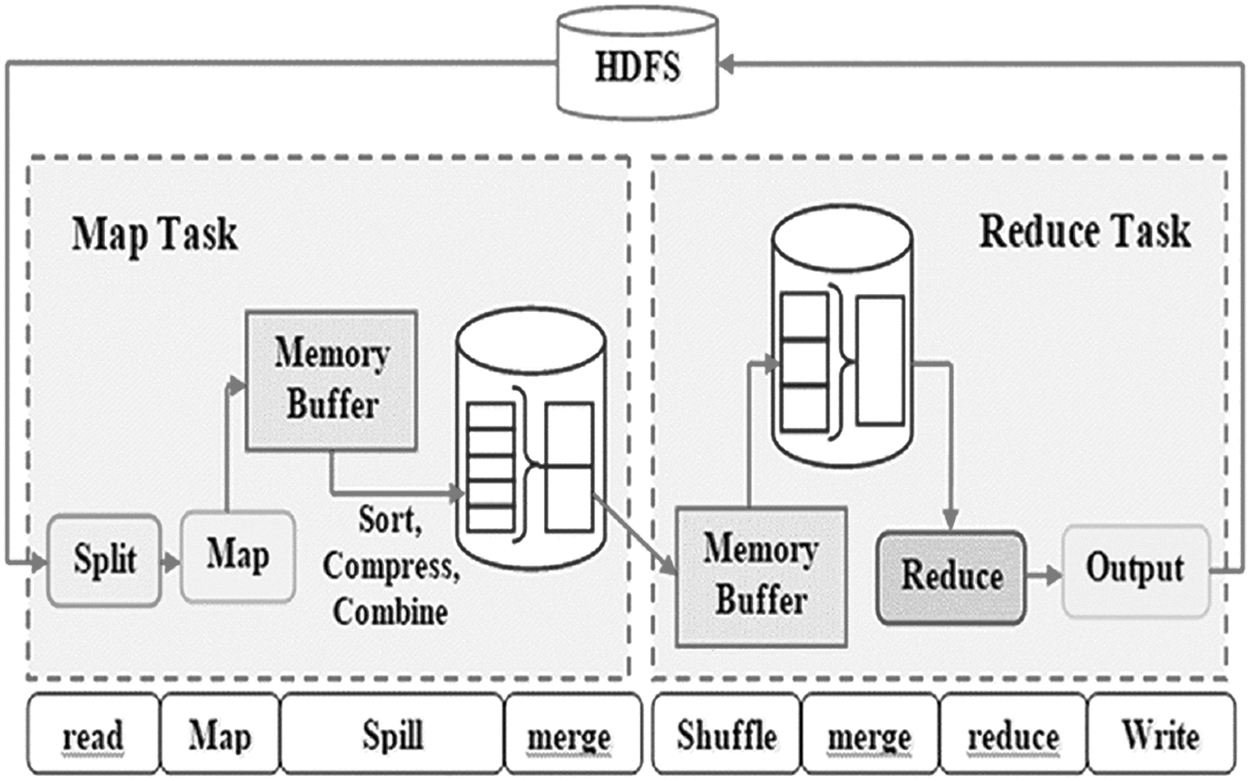
Execution of a MapReduce job.
A Hadoop MapReduce framework utilizes a slave design in which each individual hub deals with several other slave hubs. The Hadoop dispatches a MapReduce framework sensibly, and the data set regarding the information is transformed into separate data parts. Likewise, the divided data are prepared and mapped by using a mapping task. Here, a task scheduler is responsible for arranging and executing the data during the mapping process. Also, each individual task scheduler contains a predefined number of tasks for execution, namely mapping execution and reducing process. A number of mapping tasks are executed in a large spacious area, and the map reducing process takes place in a diverse manner in the form of waves. Soon after the completion of the map undertaking framework, the reducing process takes place that helps in processing the transitional data and delivers the optimized output.
The MapReduce comprises several phases as shown in Figure 1, namely Read, map, collect, and spill. In the read phase, the initial key values are created, and the input data are read from the HDFS file system. The function of the mapping phase is to create the map output and to process the default built-in functions. Then, the intermediate data are collected for grouping and dividing in the collect phase. Therefore, to generate spills, the grouping and compressing process takes place for writing the data in the memory disk. Then, the split files are then merged into a single mapping file.
The reducer phase comprises of shuffle, merge, reduce, and write phases. In the shuffle phase, the data are transmitted from the mapper nodes to the reducer nodes. In the merge section, the input data for the reduce function are created that also combine the sorted blocks from various mappers. Then, the processed data or file is rebuilt to generate the final output in the reduce section. Finally, after the compression process, the final output is written to the HDFS file system. Here, in this article, the assisting stage executives employ in optimizing the Hadoop MapReduce framework. Let us consider p be the executing program framework, d be the info data having the parameter settings as c that utilizes the group asset r of the Hadoop framework.
Let us assume the job j = <p, d, c, r>, here the task or job done is represented by j, the data or information is denoted as d. The distributed infrastructure of the bunch asset is denoted as r. Then, the stage layer of the argument is denoted as c. The major objective of the proposed approach is to tune the parameter to deal with several quantities of various projects with low computational time.
Parameter configuration
In the MapReduce framework, there are more than 130 parameters available. Among them, some specific configuration parameters decide the performance of the task. Apart from that, from the proposed Hadoop framework, 15 parameters are chosen for executing the framework. Such argument setup specification determines the way that how a framework task ought to be executed and particularly the best framework to process the data at each phase. The configuration parameters comprise four execution phases regarding the related elements, namely memory capacity phase, data compression phase, parallelism phase, as well as job flow trigger point phase.
The packing of maps and assignment reduction regarding the data yielding is established in the data compression phase. However, if the argument is set as valid, then it invests more amount of energy in packing as well as decompressing the data. There are two major principles in parameter configuration tuning, namely increasing the tuning task without the influence of the framework and design arguments. Also, different qualities with a huge number of frameworks are utilized. The design parameter configurations are listed in Table 1.
List of arguments for tuning
The proposed approach also comprises two major phases, namely the optimizer and the indicator. The function of the indicator is to access the demonstration of the MapReduce employment system. The indicator phase is made of a few submodels that employ artificial intelligence (AI) computation.
Parameter tuning
There are more than 130 tuning parameter configurations in the Hadoop framework. This configuration parameter allows the user in managing the Hadoop framework at various stages while executing. Moreover, the core parametric configuration comprises the major impact regarding the effective performance of the Hadoop framework. The tuning parameters are mentioned as follows:
io.Sort.Factor: The io.Sort.Factor defines the file or stream number that is to be combined while sorting operation and task mapping. The system has a constant value rate as 10, and if the constant rate is increased, then the physical memory usage is also enhanced with a minimized operating cost of the input–output process.
io. Sort. mb: While executing the job, the hard disk fails to map the output task and instead the memory buffer maps the output task. The io.Sort.mb parameter specifies the size of the memory buffer. The constant value of the system is set as 100 MB. The parameter configuration value of Java_Opts ranges from 30% to 40%.
io. sort. spill. percent: The io.sort.spill.percent supports in determining the initiation of the spill process. Here, the data from the memory are transferred to the hard disk.
mapreduce. map. combine. minspills: The default value specifies the memory of the mapreduce.map.combine.minspills to combine the output task. The system comprises the constant value rate as 3.
mapreduce. map. tasks and mapred. reduce. tasks: This parameter significantly affects the exhibition of the Hadoop work. The constant value of the system is set as 1. The ideal estimation of the argument subjects to the information size and the quality of the data set having very fewer spaces in a Hadoop group. Also, the diminish tasks reduce the overhead while setting up the tasks. 18
Mapreduce. tasktracker. map. tasks. maximum and mapreduce. tasktracker. reduce. tasks. Maximum: The argument characterizes the quantity of the guide and diminishes errands that can be processed at the same time on each group hub. Expanding the estimations of these arguments builds the usage of physical memory and CPUs of the group hub that improves the exhibition of a Hadoop work.
mapred. child. java. opts: The mapred. child. java. Opts provides the greatest size regarding the physical memory of the JVM for every job. The constant value of the system is set as 200. The parameter configuration value of mapred. child. java. opts ranges from 256 to 2048.
mapreduce. reduce. shuffle. input. buffer. Percent: While shuffling, the memory measured in percentage assigns a reducer to store up the mapping results. The default value of the system is assigned as 0.70.
map. reduce. parallel. Copies: This configuration represents the transferring of a parallel number of data in a reduce stage. The parameter configuration value may range from 1 to 20.
mapred. compress. map. output and mapred. output. Compress: Here, in the mapred.compress and mapred.output configuration, the Boolean qualities are utilized to decide if the guide yield and the decreased yield should be packed.
dfs. block. Size and dfs. Replication: The dfs. block. Size helps in processing the size of the data while mapping the task. The dfs. Replication represents the replication of a block number.
Formulation of OCFPA
In this proposed approach, a novel automatic parameter tuning system named as Opt. Tuner is proposed to select the Hadoop configuration parameters with less computational time. The optimization the proposed approach utilizes FPA. Also, a chaotic mapping strategy is introduced in initializing the population. Thus, the OCFPA is employed in optimal tuning with less computational time.
Flower Pollination Algorithm
The FPA works under the principle of natural pollination. The candidate solution is similar to that of the pollen or the flower. While optimizing, the biotic, as well as the cross-pollination, utilize the diffusion process in which the movement in pollen is estimated by means of Levy Flight. 19 The probability distribution is carried out by means of a Levy distribution factor that comprises a heavy or intense power-law tail where the anomalous diffusion processes are described. A very long movement from the actual location in anomalous diffusion is caused by means of infinite mean and variance. Therefore, exploring the search space becomes highly effective.
The random generation of the initial population to establish the best solution is the starting process of the FPA. The type of pollination should be established initially to predetermine the rate of probability. The probability value may range from
From Equation (1), the best solution I at time T is denoted as
The standard gamma value having the index
The two random sample equations taken from the Gaussian normal distribution having the mean value as zero is represented as u, v. Then, the expression for the local pollination as well as the consistency rate of an FPA is represented in Equation (4).
From Equation (4), the probability value may range from
OCFPA-based approach
The main intention of the hybrid optimization algorithm involves the optimal and automatic tuning of the Hadoop configuration parameter, thereby minimizing the objective roles of execution times during the process of task scheduling. Therefore, an oppositional chaotic flower pollination approach is implemented to obtain the best optimal configuration parameter.
Motivation of hybridizing the algorithm
In this section, a novel automatic parameter tuning system named as Opt. Tuner is proposed to select the Hadoop configuration parameters with less computational time. Also, the population is initialized by using two strategies, namely chaotic mapping and Opposition-Based Learning (OBL) algorithm as mentioned in the below section. Therefore, to achieve better optimization results, the proposed approach employs an FPA. The initial candidate from the wider search space is implemented by initializing the population by means of two methodologies, namely OBL methodology and chaotic mapping technique. The initialization of the population is mentioned in the pseudocode described below. The random variable employs a chaotic map for initializing the population as described in the algorithmic steps 1 and 2. The evolutionary equation for chaotic mapping is obtained by the following expression:
From Equation (4), the fixed value for the iterations is 300, that is, K = 300. The initial value for the chaotic mapping is selected randomly. The algorithmic steps for initializing the population in accordance with the chaotic mapping and OBL are described in the following section.
The flowchart representation for parameter tuning based on optimal chaotic flower pollination particle swarm optimization algorithm is shown in Figure 2.
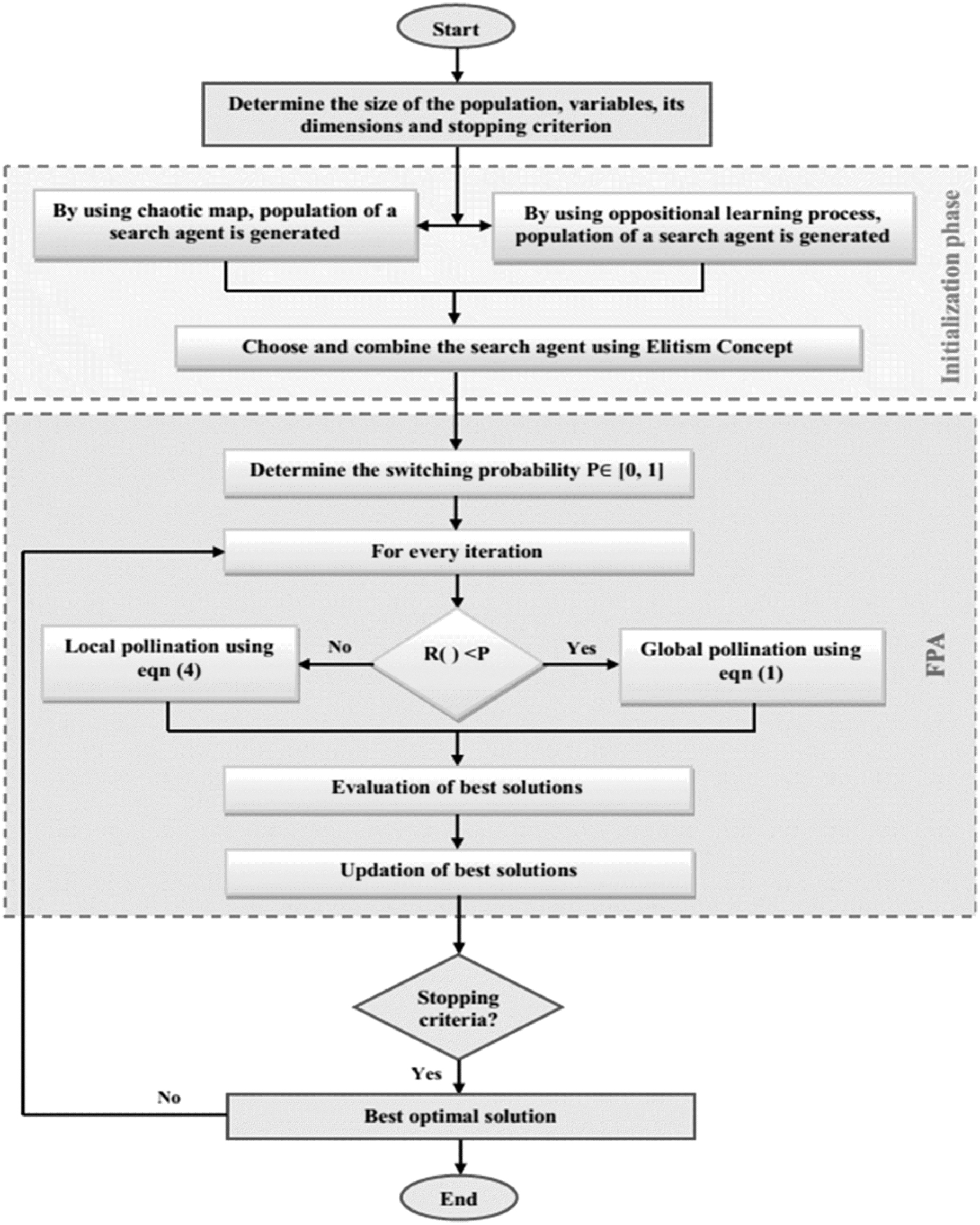
Flowchart representation of OCFPA approach. OCFPA, Oppositional Chaotic Flower Pollination Algorithm.
OCFPA-based configuration parameter tuning strategy
This section describes the OCFPA to tune the Hadoop configuration parameters so as to obtain the best optimal solution.
Initializing population
The random variable employs a chaotic map for initializing the population and it is mentioned in Equation (5). Consequently, the quantity of emphasis is stabled to the estimation of 300 and arbitrarily picked the underlying worth CH (0). Based on OBL, an additional set of oppositional population is denoted as
The population Initialization by means of random distribution approach along with the FPA is achieved and it is mentioned in Figure 2. Let us consider the size of the population be n = 100 having the dimensional value as 3. It is very well noted that the solution obtained during population initialization is distributed across numerous search area with better exploration potential.
Evaluation of fitness function
The parameters for tuning can be described as x0, x1… xn and the time is taken for total processing or execution will be presented as follows:
Here, 15 configuration parameters of the Hadoop framework will be used for the tuning process. The parameters and their range are explained in Table 1. Here, the oppositional chaotic flower pollination particle algorithm is employed in tuning the parameters. The algorithm for OCFPA-based Configuration Parameter Tuning Strategy is described in the following section.
Steps involved in the proposed approach
In this article, an FPA along with the chaotic mapping and the oppositional learning process is implemented in the automatic tuning of the parameter configuration. The algorithmic description is represented in Pseudocode 3.
Results and Discussion
We have developed and conveyed the proposed tuning framework for the Hadoop investigational setup. The group comprises a tiny server and an additional eight homogeneous cutting edge servers. The tiny server incorporates a 4 GB memory, dual-center 2.53 GHz processor, 1 Gbps system card, and 500 GB hard disk.
Famous big data benchmarks, for example, Hibench, 20 CloudSuite, 21 just as BigDataBench, 22 incorporate various commonplace big data applications, for example, sort, page rank google, and wordcount. Here, 15 big data applications are selected, in which each individual big data is compared with 2 distinctive data set estimates individually. Along these lines, there are 30 unique remaining tasks that are to be used to assemble the design store. Here, we have referenced the application and the comparing data sets.
Performance analysis for various benchmark functions
In this section, to improve the performance of the proposed OCFPA-based auto-tuning parameter configuration, five mapping functions are employed in building the proposed OCFPA. Therefore, the details based on chaotic mapping are tabulated in Table 2. In addition to this, to estimate the exploitation capability of the proposed OCFPA algorithm, five unimodal benchmark functions are involved. Table 3 provides the detailed description regarding the classical benchmark functions. Table 4 provides the performance analysis for various benchmark functions. From the table, it is noted that the proposed approach provides best results for Circle, Logistic, and Chebyshev maps. 23
Description of various chaotic maps
Details of benchmark functions
Performance analysis of each map when applied to Oppositional Chaotic Flower Pollination Algorithm
Experimental analysis
Figure 3 demonstrates the effect of the quantity of reducing the task on job efficiency. There is a substitution among the fixed cost brought about in setting up to reduce the tasks and exhibiting the gain while using the assets. At first, expanding the number of minimum assignments better uses accessible assets, which prompts in diminishing the execution time. In any case, an enormous number of reducing assignments bring about a huge cost in the arranging procedure, which leads to a prolonged implementation period.
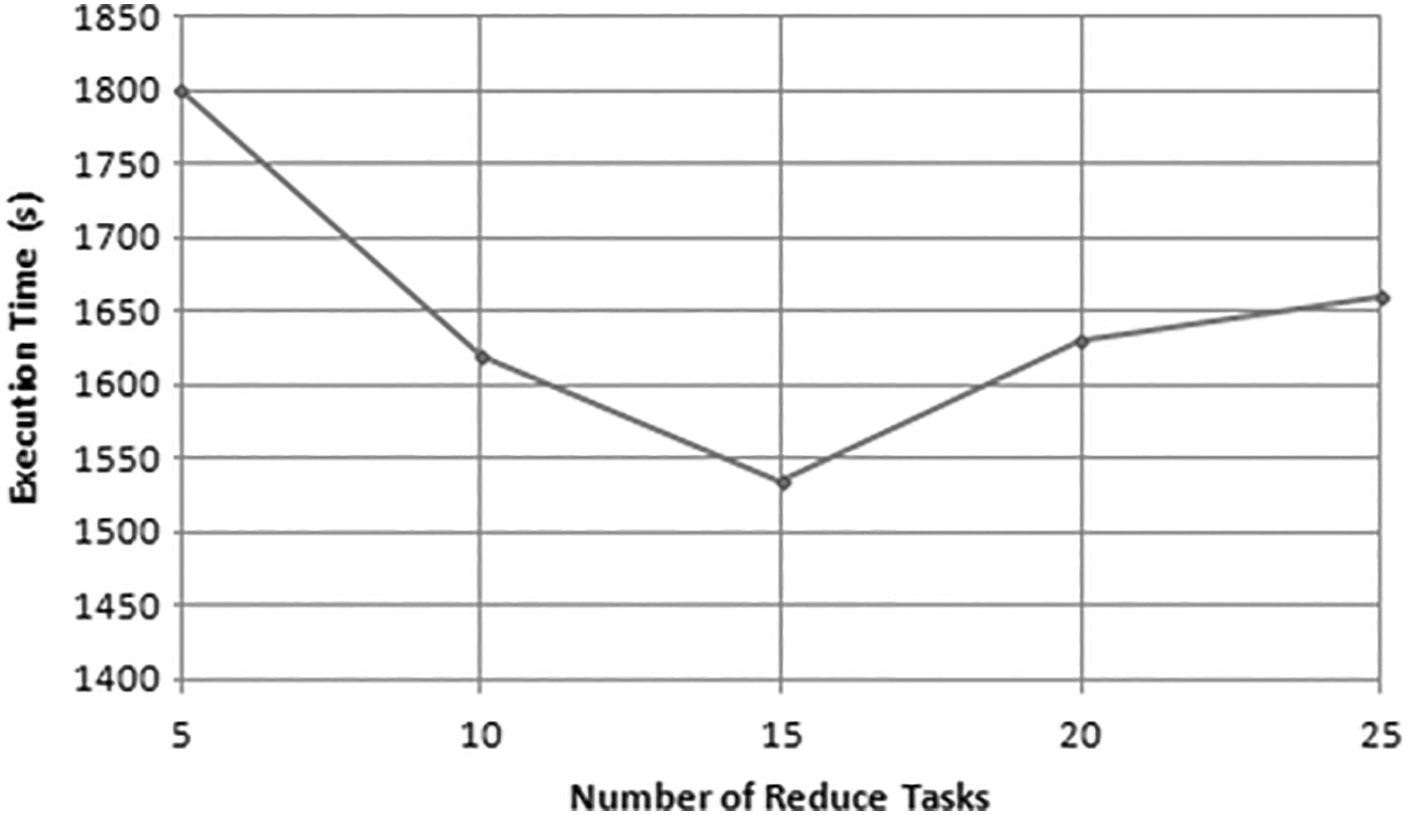
Analysis of reduced tasks versus execution time.
Expanding the quantity of mapping as well as reducing their spaces superiorly uses accessible assets, which prompts a diminished processing time as shown in Figure 4 when the slot quality incremented once or twice. However, the resources may be utilized in excess when the quantity of spaces expands, which creates a delay in task processing.
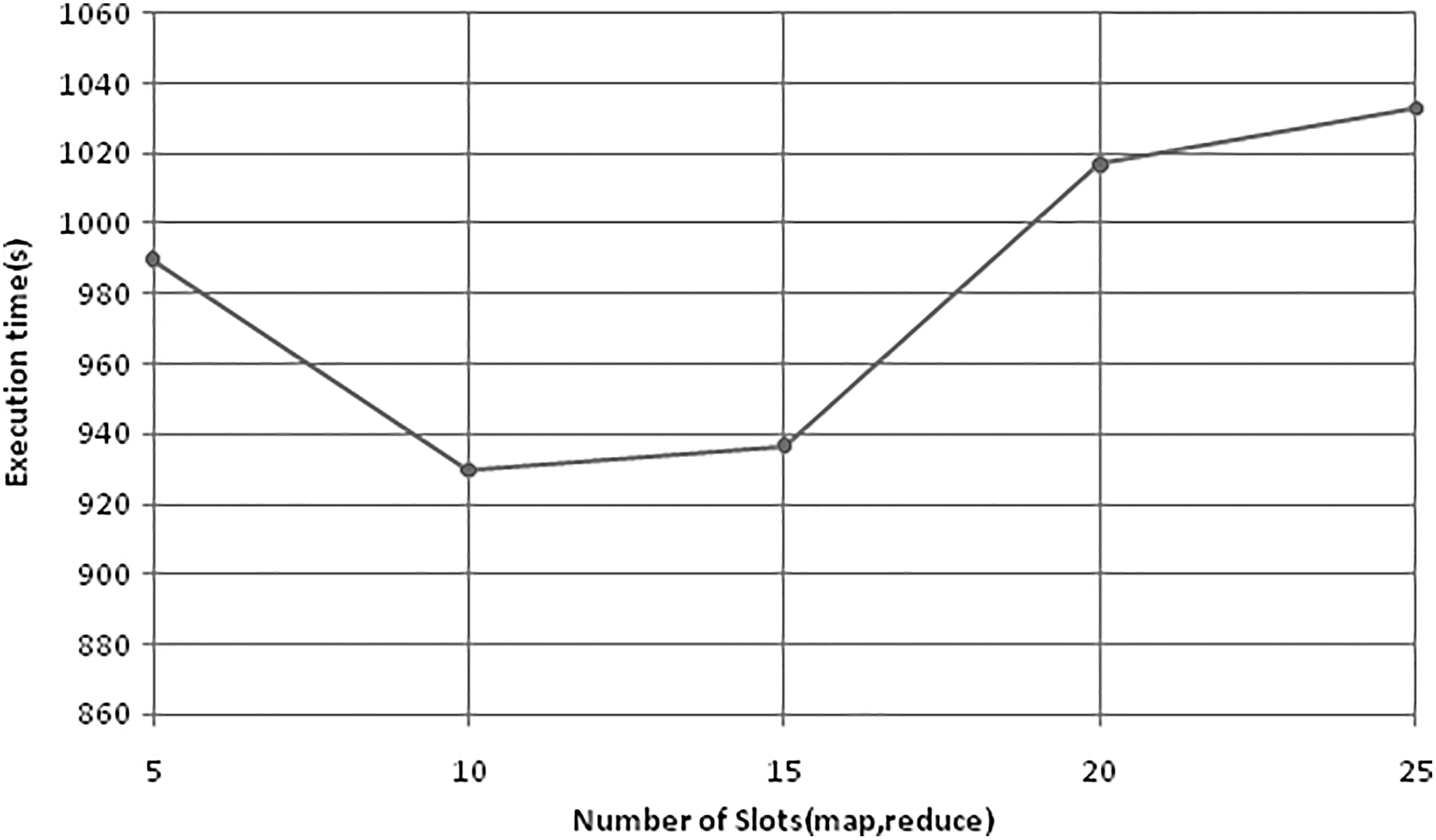
Impact of number of map and reduce slots versus execution time.
Expanding the estimation of the “Java_opts” parameter uses extra memory, in which it automatically reduces the execution time and it is described in Figure 5. For this situation, a separate hard disk is utilized as a virtual memory that creates delay while executing.

Impact of Java opts parameter versus execution time.
Figure 6 demonstrates the effect of the pressure argument regarding the exhibition of a Framework. The outcomes produced by guide assignments or diminish undertakings can be packed to reduce the rate of overhead in crosswise over a system as well as IO tasks, which prompts a diminished processing time. It is significant that the exhibition hole between the instance of utilizing the pressure and the instance of utilizing the original highlight gets huge with an expanding size of the information.
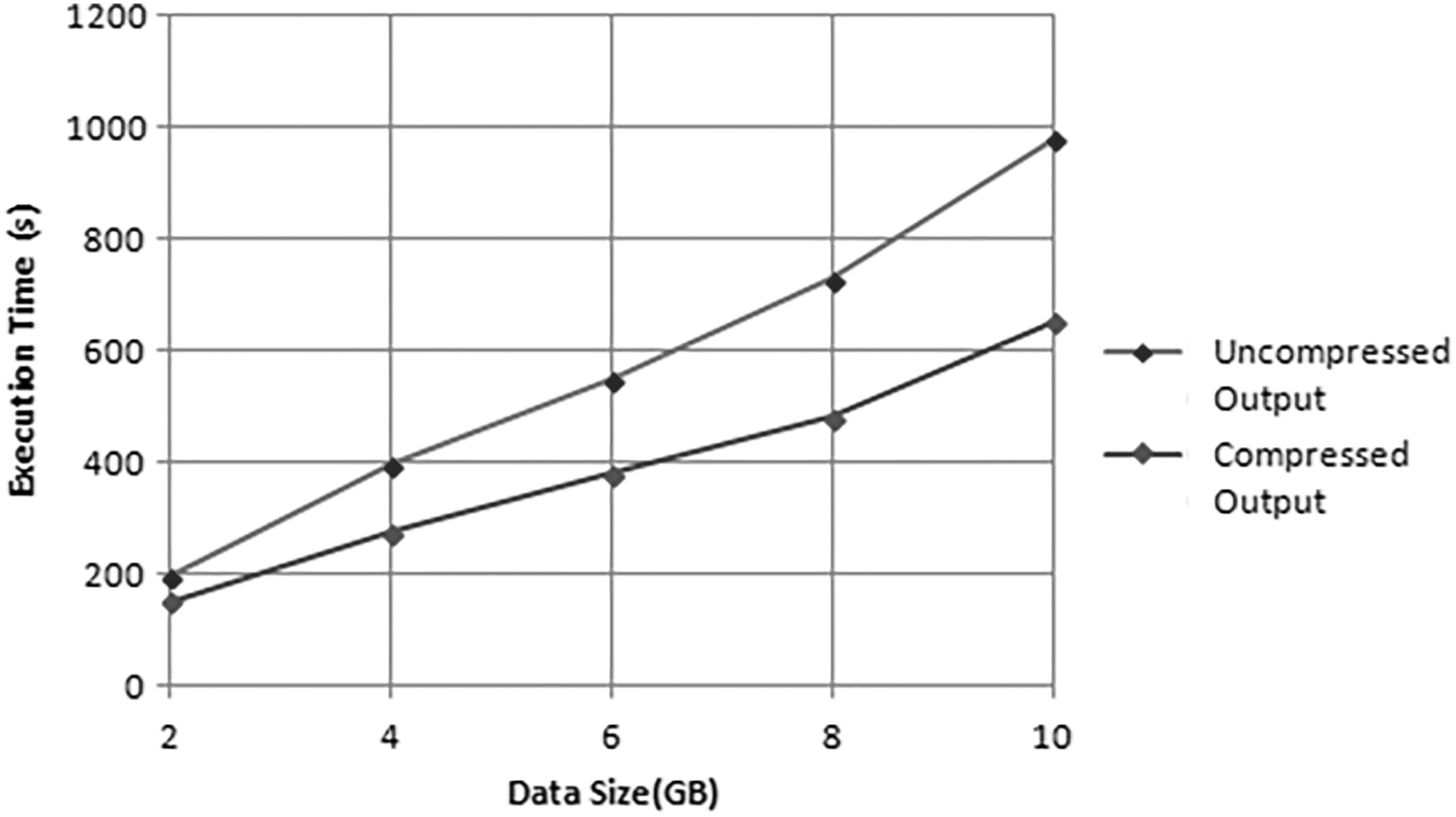
Impact of compression parameter.
Comparative analysis
At first, the presentation of the proposed framework is contrasted and compared with a sort of parameter tuning framework mr.Moulder, 24 starfish,9,10 PPABS, 22 and particle swarm optimization (PSO). 25 Among different applications, wordcount and sort are utilized to investigate the exhibition and proficiency.
In this research, the quality of the parameter tuning framework is examined with varying ranges of databases. The most popular applications such as sort and wordcount are selected and used with seven distinctive sizes (1–64 Gb) to create two arrangements of employments. At that point, for each activity, we execute it under the design prescribed by the proposed research and contrast the activity execution and the presentation under the ideal arrangement attained by comprehensively looking through the setup space, just as the exhibition under the default setup. The outcomes are presented in Figure 7. So as to contrast the presentation of employments and distinctive data set measures naturally, we utilize the metric “Execution time per GB” rather than “Execution time” on the vertical hub. For Wordcount, with different sizes of data, the exhibition below the basic specification is much more awful than the other two, although the mean percentage error (MPE) between employment execution under proposed framework's suggested setup and the ideal execution of the activity is around 3%. Correspondingly, while sorting, the MPEs are under 4%. This recommends our proposed strategy can effectively distinguish applications and hold changes in data set size well. The presentation of the MPE of mr.Moulder framework is 4% for Sort and 5% for wordcount, which is marginally higher than our proposed framework.

Execution time analysis for different applications on different sizes of data set
Figure 8 describes a plot of the real execution and the optimal execution for employments in the flood of our proposed tuning framework. It tends to be seen that the focuses are in all respects firmly circulated along the straight line, demonstrating that the proposed framework can effectively suggest the ideal setup for occupations with known applications.
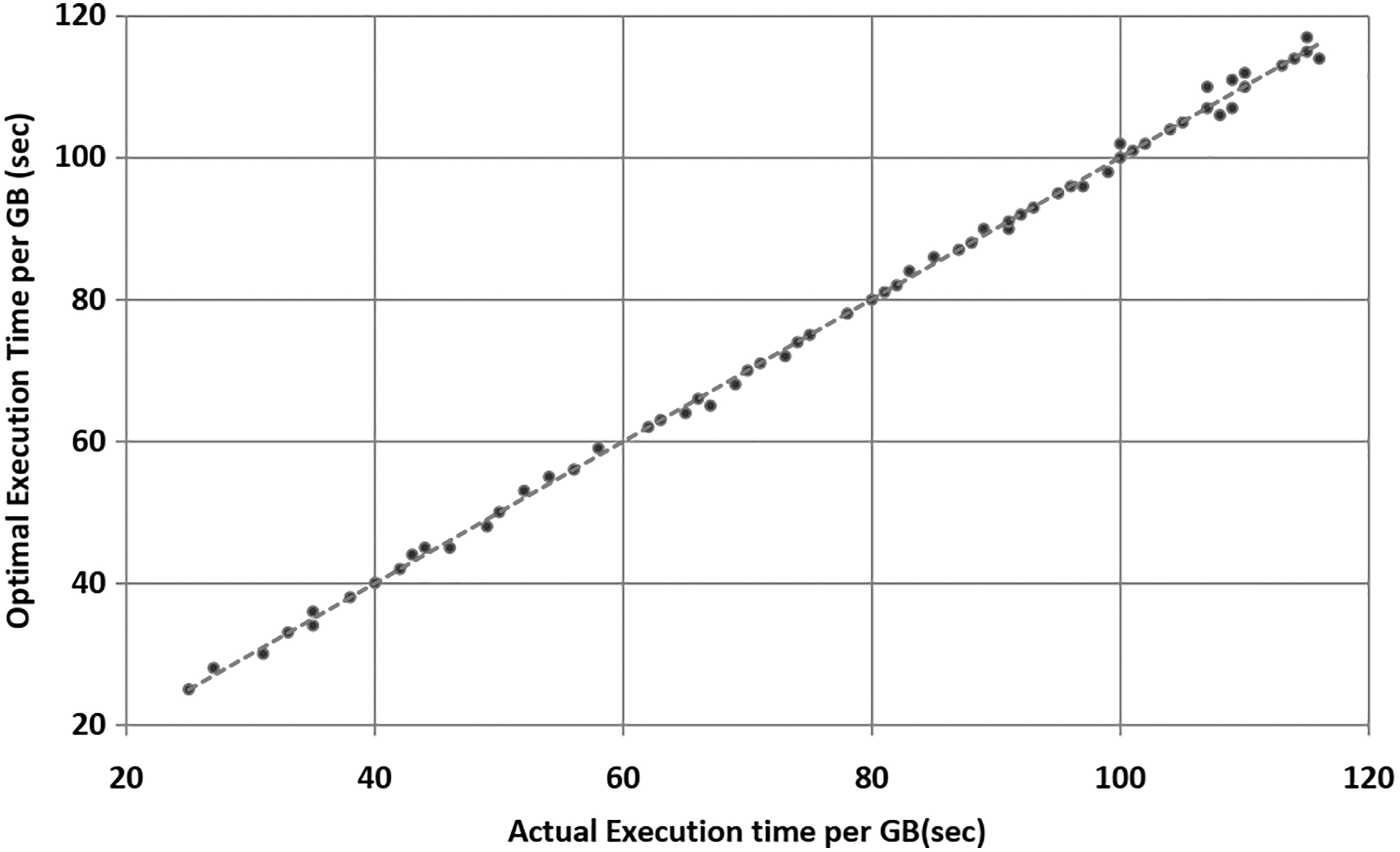
Scatter plot for job stream.
Figure 9 presents the processing time of every application in various designs. It tends to be seen that the performance of the conventional setup is low. In the prescribed setups, the efficiency of the Starfish setup9,10 is more deplorable than the remaining methodologies over 10%. The performance of our proposed technique design is slightly higher than PPABS 14 and mr.Moulder 22 while these two methods have next to no distinction in execution (inside 1%).
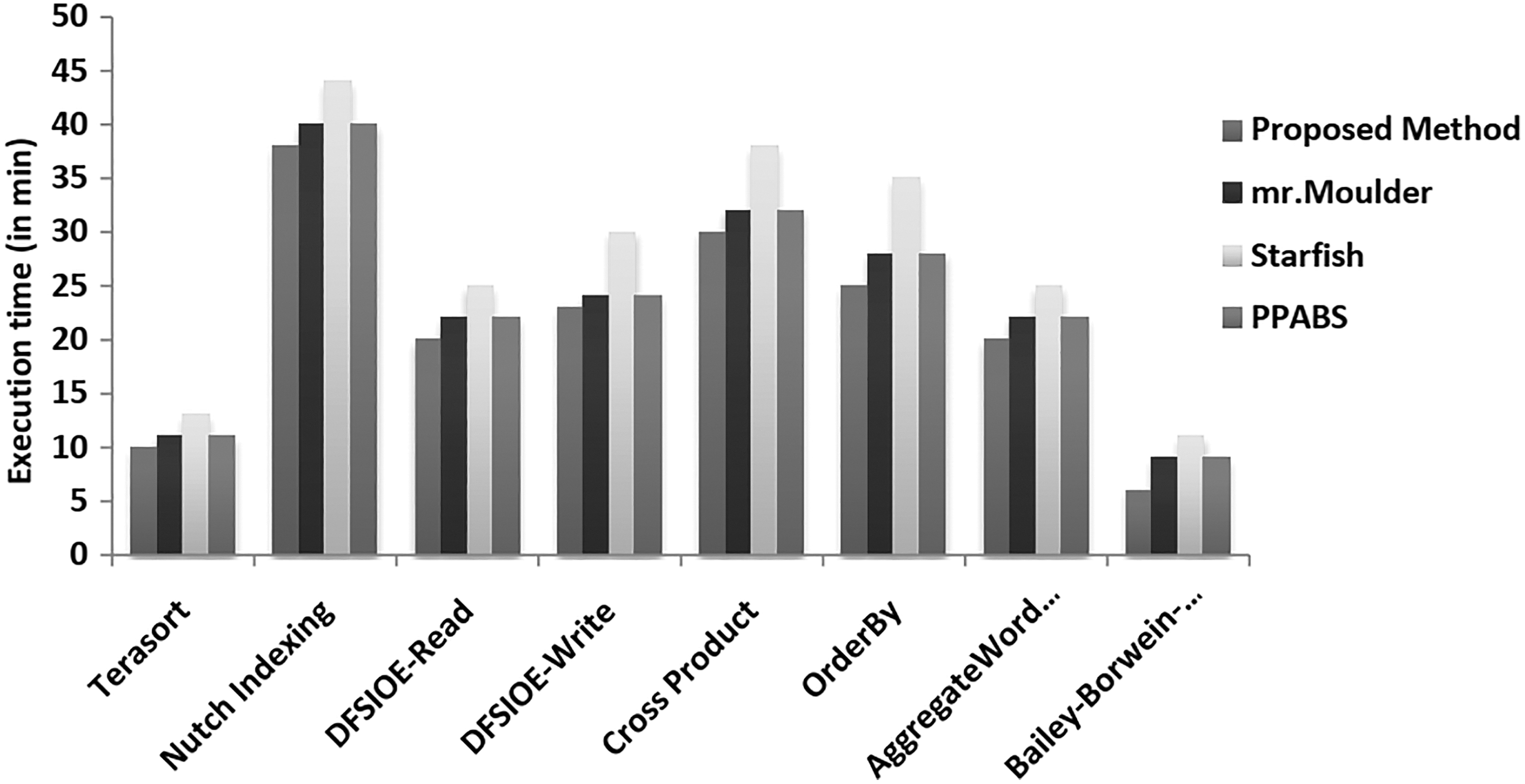
Job execution time.
Figure 10 presents the cumulative processing time analysis. It is noted that the bend of Starfish is the most noteworthy, whereas the bend of the proposed strategy is clearly lesser than the others. In particular, utilizing the proposed framework, the last combined handling time of the activity stream is around 2 hours not as much as utilizing mr.Moulder, which is the subsequent best.
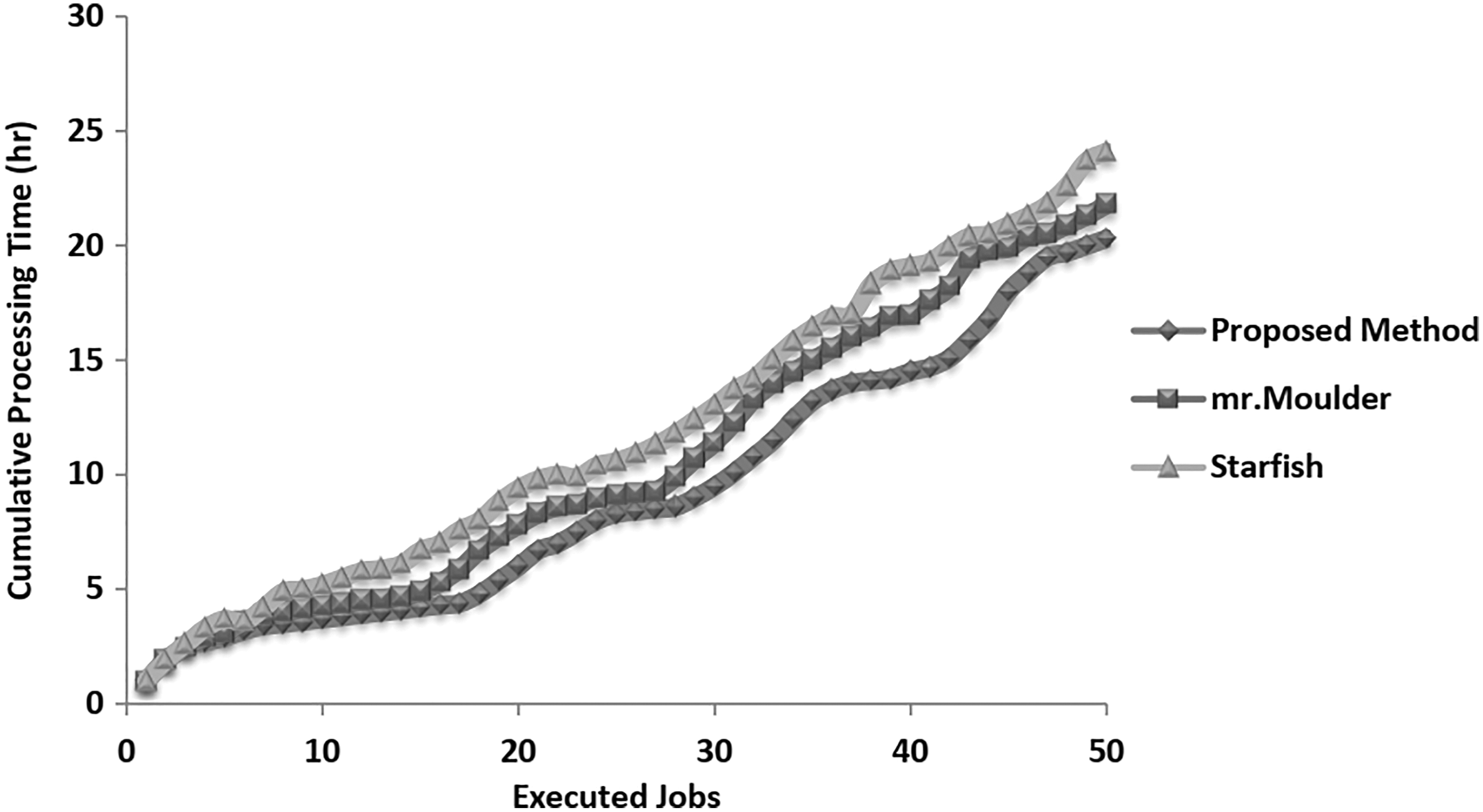
Cumulative processing time analysis.
The comparative analysis of processing time over existing methods such as mr.Moulder and starfish is presented in Figure 11. Both the applications are given to the Hadoop framework with eight virtual machines (VMs) to execute the data on different sizes varying from 5 to 20 GB. The applications are executed multiple times with selected parameter ranges and the time taken for total processing was estimated. The detailed analysis is given in Figures 11 and 12, individually.
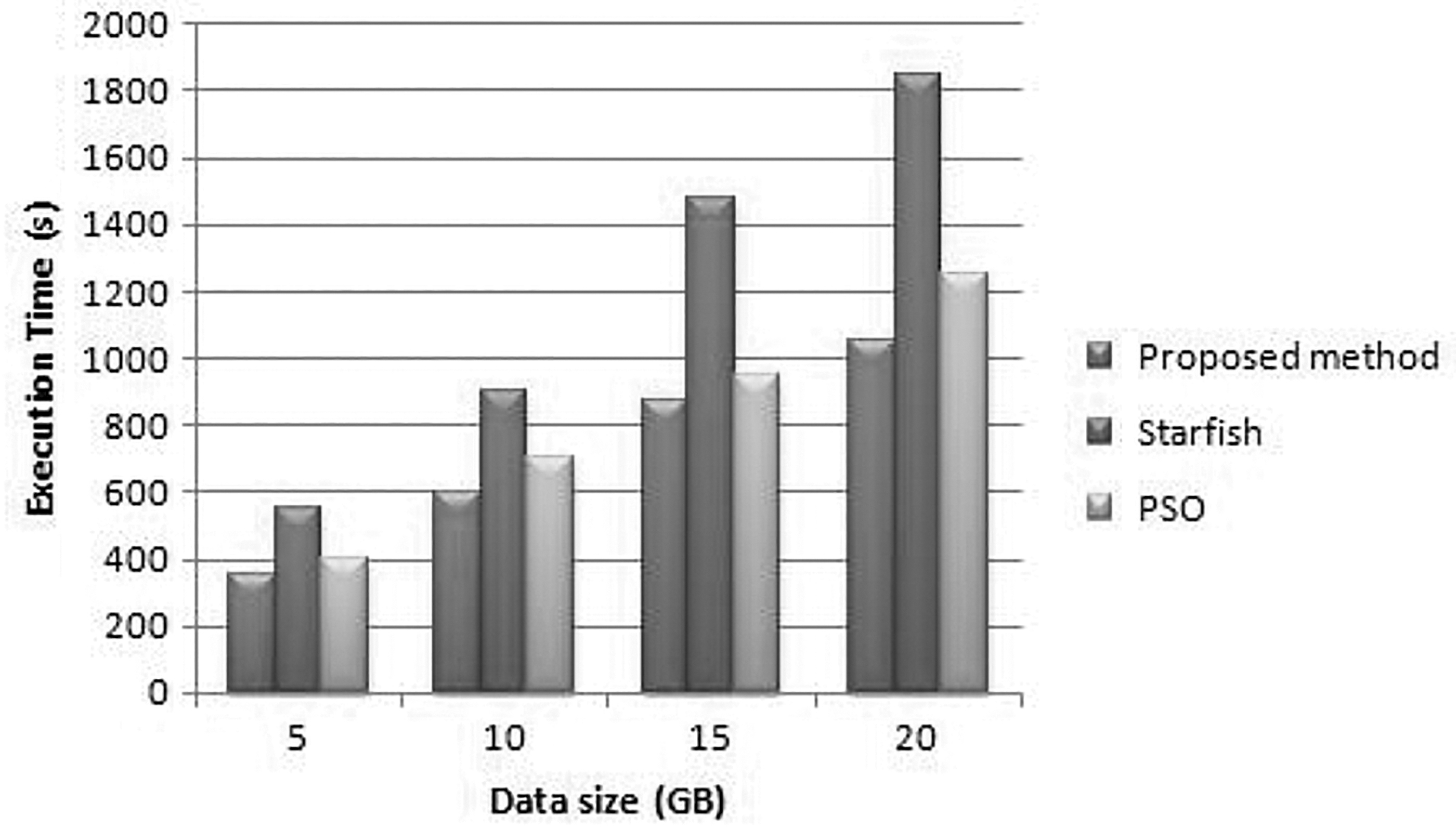
Wordcount performance applications on eight virtual machines.
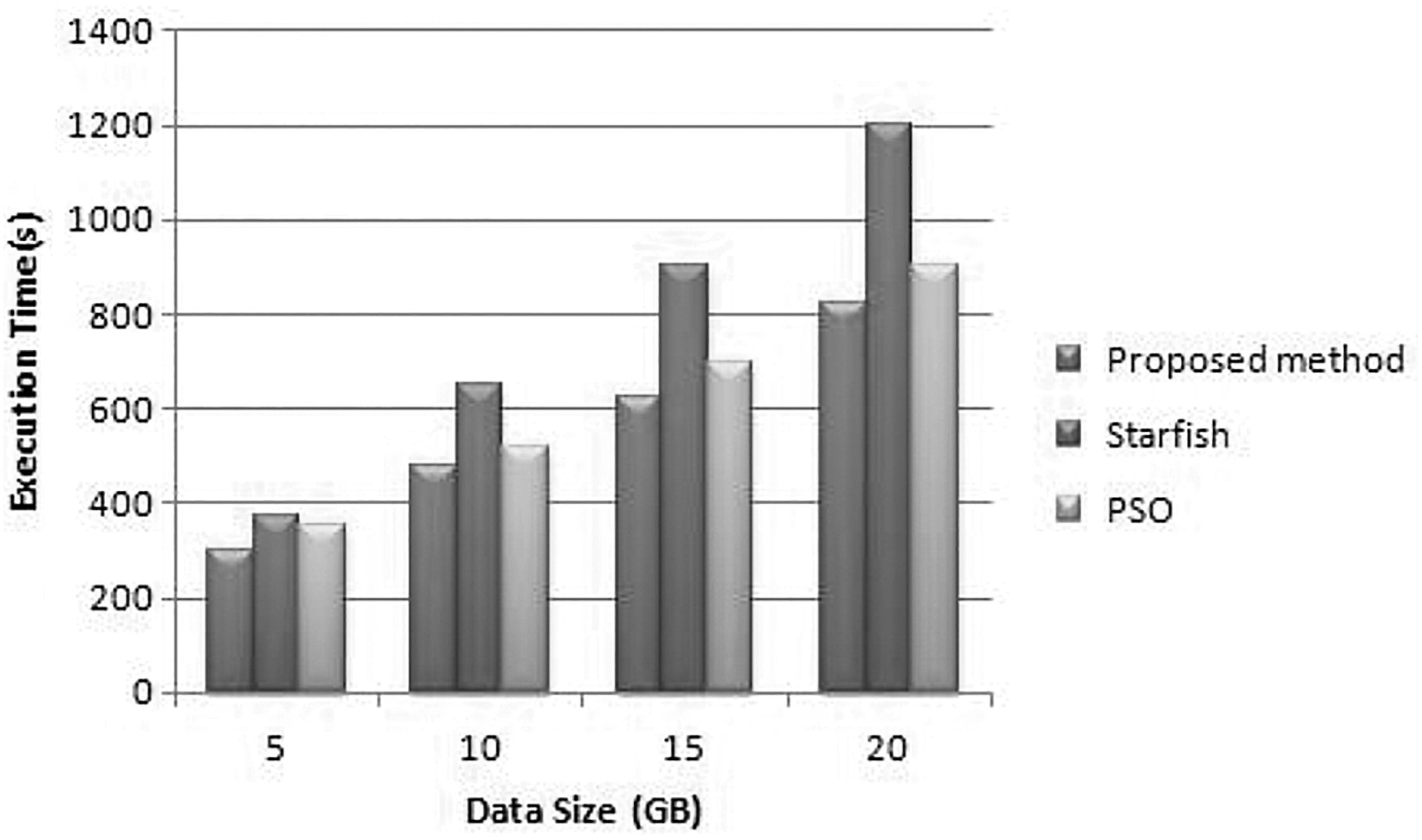
Sort application performances on eight virtual machines.
It very well may be seen that by and large, the actualized proposed technique improves the presentation of the “WordCount” application by a normal of 67% in the four information situations contrasted and the current Hadoop parameter settings, 30% contrasted and Starfish, and 6% contrasted and PSO. 20 The improvement achieves a limit of 71% having the information size of 20 GB. The exhibition development of the proposed streamlining on the “Sort” application is all things considered half above the default specification.
We have additionally assessed the experimentation of the proposed optimization of Opt. Tuning framework that takes a shot at another Hadoop bunch designed with 16 VMs. From Figures 13 and 14, it very well may be seen that the proposed work progress the presence of the two applications by and large by 65% and 86% contrasted and PSO and starfish Hadoop settings, individually. In wordcount application, the efficiency achieves a limit of 88% when the data size is 35 GB. The performance additions of the proposed work over the model and PSO on both applications are 20% and 21%, better individually. For this situation, a huge database with varying sizes of 25 to 40 GB was utilized.
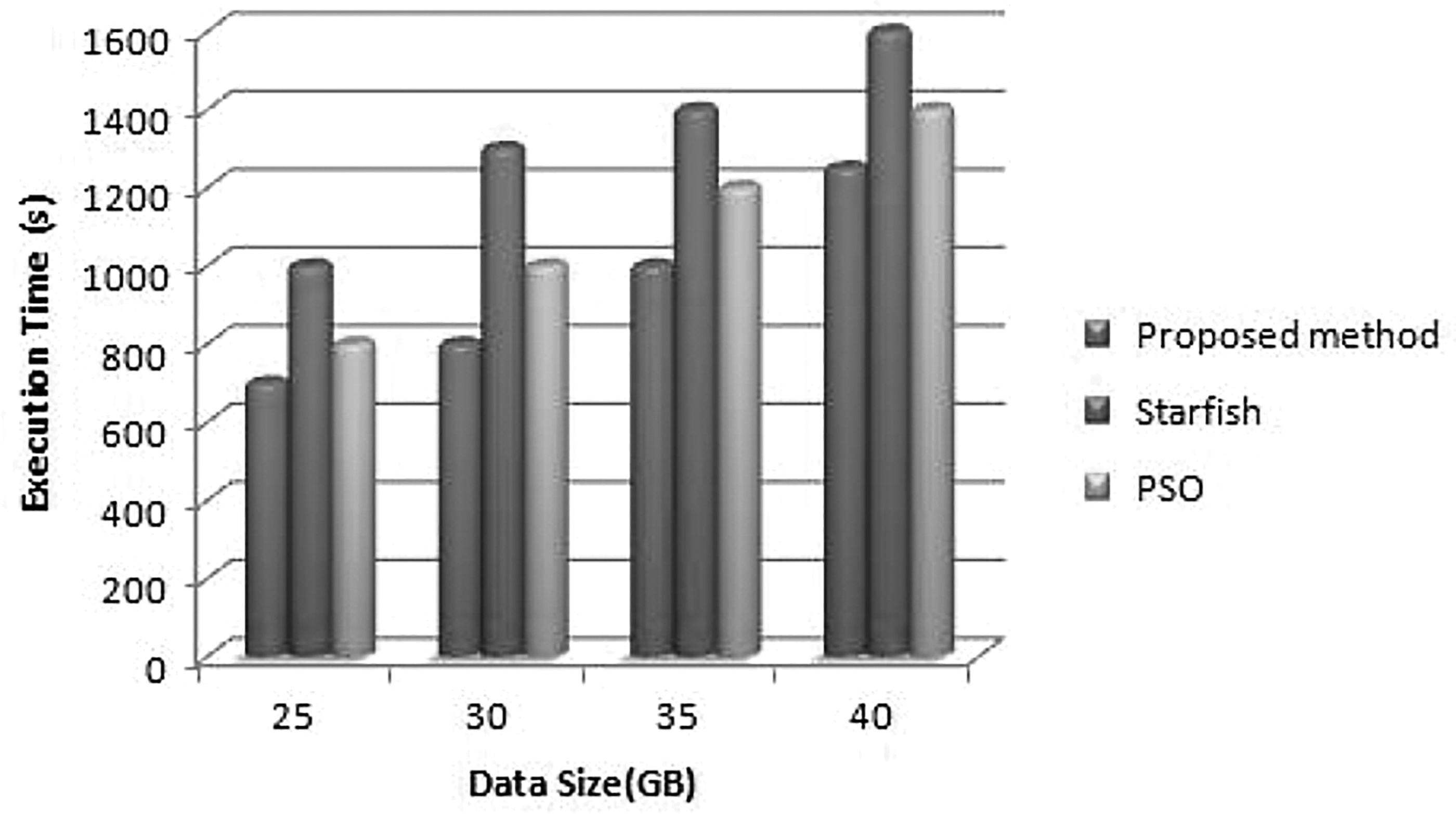
Wordcount application performances on 16 virtual machines.
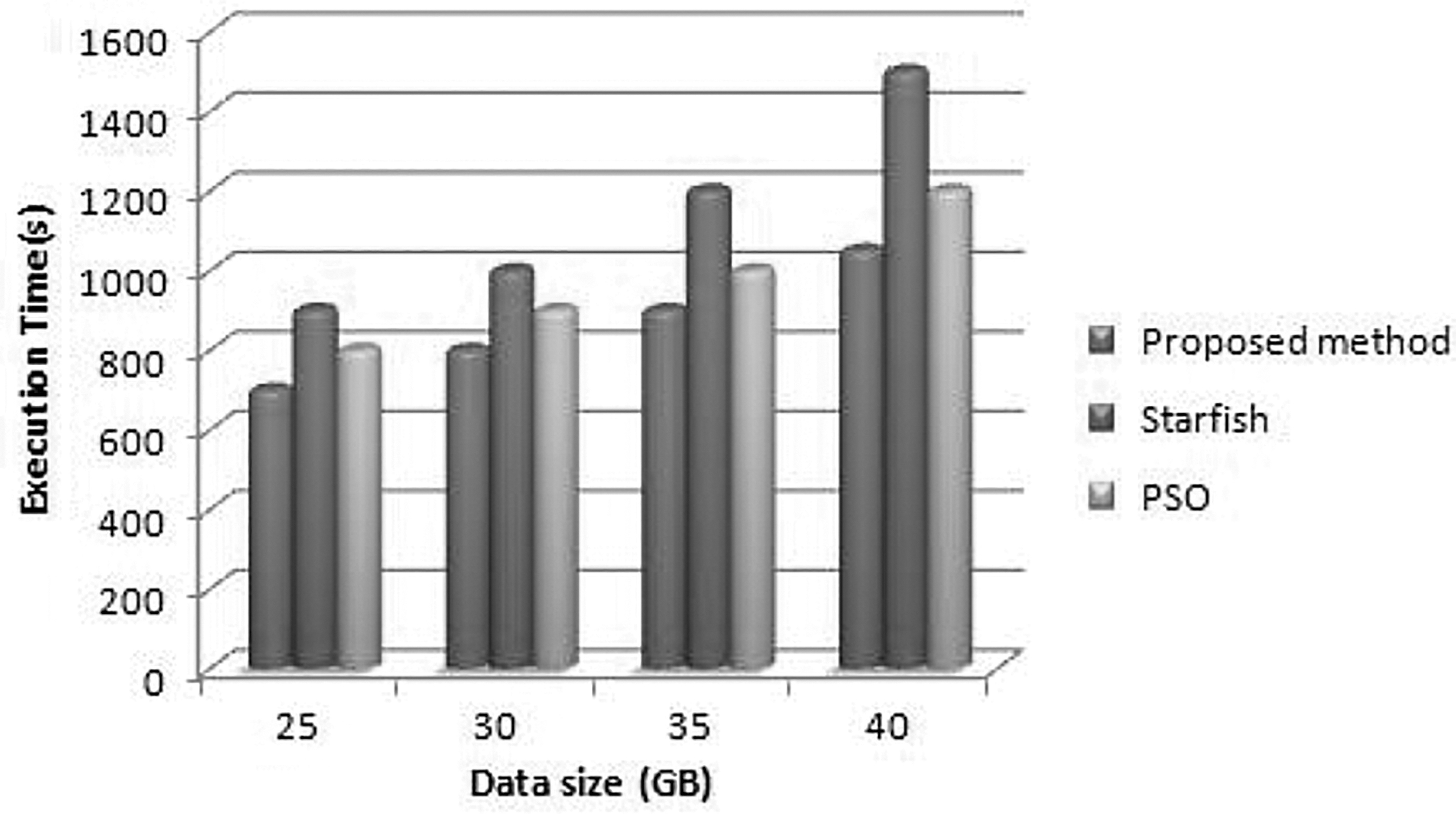
Sort application performances on 16 virtual machines.
Conclusions
MapReduce configuration parameter tuning is one of the significant methodologies for improving employment execution in huge information handling stages. Be that as it may, it is unreasonable to calibrate the parameters physically. Here, an optimal parameter tuning framework is presented in which endeavors a progressively extendable setup that archives to give a few applicants improved designs to a new position, to arrange parameters optimally for enormous information employments. For an ideal tuning process, OFPA calculation is utilized. The presentation is dissected with an existing tuning framework with certain applications, for example, wordcount and sort.
Later on, we intend to bring this system into the multioccupant environment and investigate the parameter assurance instrument when various occupations run simultaneously. Additionally, we are likewise keen on displaying the connection between occupation execution, asset utilization, and parameter design.
Footnotes
Author Disclosure Statement
No competing financial interests exist.
Funding Information
No funding was received.