
Abstract
With the advent of the new information technologies, the growth of online reviews regarding an organization or a company or any other sector has been playing a vital role in improving the sector plans and decisions. The vast significance of the online reviews that determine the sentiment polarity is the hectic challenge of the current scenario. Sentiment classification is a process of classifying the text according to the sentimental polarities of opinions, which has positive or negative. Thus, this article concentrates on presenting a novel method, named CAVIAR-Dragonfly optimization with Extended Naive Bayes (CDNB), for performing sentiment classification and affective state classification. At first, the BITS review from Twitter is subjected to preprocessing, which includes stop word removal and stemming. Then, the next step is the feature extraction, in which all the reviews are converted to a feature vector. After that, all the individual feature vectors are collected to form the feature matrix, which is applied to the proposed C-Dragonfly optimization algorithm, to perform the sentiment classification and affective state classification. The performance of the proposed method is analyzed using the Twitter Sentiment Analysis Training Corpus Data Set based on true positive rate (TPR), true negative rate (TNR), and accuracy. From the analysis, it can be shown that the proposed method yields the maximum TPR, TNR, and accuracy of 89.0934%, 72.3064%, and 79.3591% for sentiment classification and 84.2122%, 66.2187%, and 76.6249% for the sentiment affective state classification.
Introduction
The fast-growing developments in the field of information technology have increased the number of the web users and the Internet users' accounts to 3 billion in the world. The online users comment their views and express their experience on certain products and services via opinion posting in the social networks on various websites, which are very important to take effective decisions by the government, private, or by the consumers. 1 The public reviews made on the social networks enable the government in analyzing better decisions on a social issue and in addition, the social reviews help the company to forecast the market demand and weakness of a product. Moreover, it ensures the consumers to undergo better purchasing experience through the online reviews.2–4 The expanded growth of the user-generated contents in the website and the social networks such as Twitter, Amazon, and the trip advisors has paved the way for the users to express their opinions and views on products, services, events, and many others, and the power of the social networks has been increased. The above facility of expressing the views online has made the views much valuable that has led the sentiment classification, a hot topic in identifying the sentiment classes of the online texts. 5
Sentiment classification finds a valuable role in the day-to-day life of each individual, in the political environment, the production and release of certain products, 6 and commercial activities, which makes the emotion classification, and finding attacks is a challenging task. 7 Sentiment classification is the process of identifying the emotion whether it is positive or negative opinion for an opinion-laden text, which may be a product review, a blog post, an editorial, and so on.8,9 The positive or negative opinion is provided by the community regarding a product, a person, a political party, or a policy. The above opinion classification is simply a binary classification carrying two classes, namely the positive and the negative. The presence of complex scenarios introduces the neutral class that makes the task a single-label multiclass classification, or leads to the assessment of the sentiment strength as very positive, positive, fair, negative, and very negative, resulting in ordinal classification.10,11 Thus, sentiment analysis (SA) is the interesting criteria that classify the opinions and sentiments provided by humans in textual format.5,12
SA is the critical process that generates the subjective information from the text documents that are available online. Ensemble learning is considered the robust classification method, but a lot of approaches used feature engineering for developing the sentiment classifiers. 13 Sentence-level sentiment classification is the basic area in SA that aimed at deciding the sentiment polarity based on the textual content. 14 The major concern is to represent the user reviews correctly, 15 and the need for determining the emotions is of current interest. For instance, from the labeled data of a certain content, the adaptive classification of the social emotion depends on the classification of the readers' emotions of the unlabeled data in any other context. 16 Affective text analysis is the interesting area that is relevant for natural language processing, web, and multimodal dialogue applications. The term affective analysis corresponds to the representation of the emotions, 17 and the generated social emotions pave the way for document categorization; it is much useful for the users in selecting the related documents based on the preferences in the emotions, and in addition, it is valuable for a number of applications such as the contextual music recommendation. The research at present is focusing on the automatic prediction of the document emotions. It is known that each and every word neutrally possesses either the pleasant or painful emotion due to its semantic relationship with emotional concepts or categories. 18
This article proposes a novel algorithm named the CAVIAR-Dragonfly optimization with Extended Naive Bayes (CDNB) optimization algorithm, integrating the CAVIAR formula, dragonfly optimization algorithm, and the Naive Bayes (NB) algorithm to perform the optimized classification. Initially, the BITS review from Twitter is taken to perform the classification that enables effective decision-making of BITS. The reviews are subjected to stop word removal in which the stop words that are the useless words are removed from the review. It is then followed by the stemming process that determines the root word for all the created words. Then, the feature matrix is developed with each review being converted to individual feature vector. The feature vector comprises 10 features, namely punctuation marks, number of sentences present in the review, number of elongated words, nondictionary words, numerical values, hashtags of the review, and mean, variance, entropy, and information gain of the score vector. These features are combined to form the feature vector, and they are applied to the proposed CDNB algorithm that performs the sentiment classification and sentiment affect classification using the maximum value of the NB-based objective function and maximum posterior probability principle.
The major contributions of the article are as follows:
C-Dragonfly optimization algorithm: The proposed C-Dragonfly optimization algorithm is the integration of the standard dragonfly optimization algorithm and the CAVIAR formula in which the position update in the dragonfly optimization is based on the CAVIAR formula. The proposed algorithm performs the optimal sentiment classification and sentiment affect classification for which it uses the maximum fitness function. CDNB classifier: The CDNB classifier is used to determine the optimized model using the maximum posterior probability-based NB principle.
The article is organized as follows: A brief introduction to the article is presented in the Introduction section, and the Motivation section presents the related works with deep discussion of the existing methods and their advantages and elaborates the challenges of the work. In the Proposed Methodology section, the proposed method is discussed in detail with the algorithmic steps, the Results and Discussion section presents the results and discussion, and the Conclusion section concludes the article.
Motivation
This section discusses the motivation behind the development of the proposed CDNB optimization for sentiment and affect classification. Here, recent works related to the sentiment and affect classification are reviewed. Also, the major challenges to be taken for further work are also discussed.
Related works
Lin et al. 1 proposed a method for cross-lingual sentiment classification named Cross-Lingual JST (CLJST) and Cross-Lingual ASUM (CLASUM). Moreover, two unsupervised cross-lingual joint aspect/sentiment models were used for sentiment classification that made use of information/knowledge generated from a source language and contributed toward sentiment classification. The main advantages of the method include better accuracy, and it does not require parallel corpora, machine translation systems, and labeled sentiment texts, but showed poor robustness. Tang et al. 14 proposed a framework for performing the sentence-level sentiment classification, which is termed the joint segmentation and classification framework. The main advantage is that there are no syntactic or polarity annotations during segmentations, but the drawback is that it did not use any of the semantic compositional methods. Bollegala et al. 15 proposed a method named sentiment sensitive embeddings cross-domain. The objectives are framed based on the distributional properties, on the label constraints of the source domain documents, and on the geometric properties present in the unlabeled documents. Sentiment classification accuracies used as the metric joint optimization do not improve over the separately trained objectives, and the joint optimization strategy did not improve the performance. Ji et al. 19 proposed a method using the NB classifier that involves two steps. The personal tweets are differentiated from the nonpersonal tweets in the first step, and the personal negative tweets are removed from the personal non-negative tweets in the second step. The main advantage is that it possesses better measure of concern negation, but the irony in the tweets is not reported.
Shang et al. 20 proposed a method for sentiment classification termed the fitness proportionate selection binary particle swarm optimization (F-BPSO) that is the modification of BPSO. It uses fitness sum in the fitness proportionate selection step. The main benefit is that it provides a better feature subset than traditional feature selection techniques, but the addition of the free parameters reduces the accuracy. Rao 16 proposed a multilabeled sentiment topic model called the contextual sentiment topic model that performs the adaptive social emotion classification. It possesses the capacity to distinguish the context-independent topics from both background and contextual themes, but it did not consider the dynamic social emotions. Bao et al. 18 proposed a model termed the latent Dirichlet allocation that initially develops a set of latent topics from the emotions and then extracts the affective terms from each topic. This method considers each term in the document, but is suitable only for small-scale documents. Malandrakis et al. 17 proposed a model termed the fusion of n-gram models that do not require any linguistic resources other than the affective ratings, but it yields lower order n-gram ratings. Table 1 shows the literature review.
Literature review
CSTM, contextual sentiment topic model; NB, Naive Bayes.
Challenges
The various challenges in this research work are enlisted as follows:
The main challenge is that the sentiment classifiers are mainly trained to perform the classification of a similar topic or specific domain. Whenever the test data from different domains arrive, the classifier provides poor classification performance, for which the language and the words that express the sentiments vary depending on the topic.21,22
Insufficient label data lead to inaccurate training and affect the robustness of the classifier. In addition, they increase cost and time. 3
The main challenge is regarding the context-sensitiveness that occurs while using the trained model of a particular topic for any other context. 16
Feature selection is the most hectic challenge 20 as the transformed features should have a strong bond on the texts and context in the reviews.
In Ji et al., 19 the NB classifier was used for sentiment classification, which is applicable only for the data obeying the Gaussian data distribution. To make it suitable for all the data distribution, further optimization is required for the model characteristics.
Proposed Methodology
This section presents the proposed method of performing the sentiment classification and sentiment affect classification using the proposed C-Dragonfly optimization that uses the NB-based principle for classification. The novel CDNB algorithm possesses the following steps: Initially, the features of the review are extracted, and the model is generated by the NB classifier, and the classification is optimized by the CDNB classifier that performs the sentiment classification and the affect classification.
Proposed CDNB for classification
In this section, the algorithmic steps of the proposed CDNB algorithm are presented, and the steps involved in the sentiment and affect classification are discussed. Figure 1 depicts the process of optimization carried out using the CDNB optimization algorithm. The feature matrix generated from online Twitter reviews of BITS is fed to the proposed classifier that initially generates a number of models, and the best model is selected using the optimization algorithm. Once the best model is selected, the class value of the models is derived based on the maximum posterior probability function. For the selection of the best model, the objective function is framed that is based on accuracy, sensitivity, and specificity. The sentiment classification uses two classes, and the sentiment affect classification uses three classes.
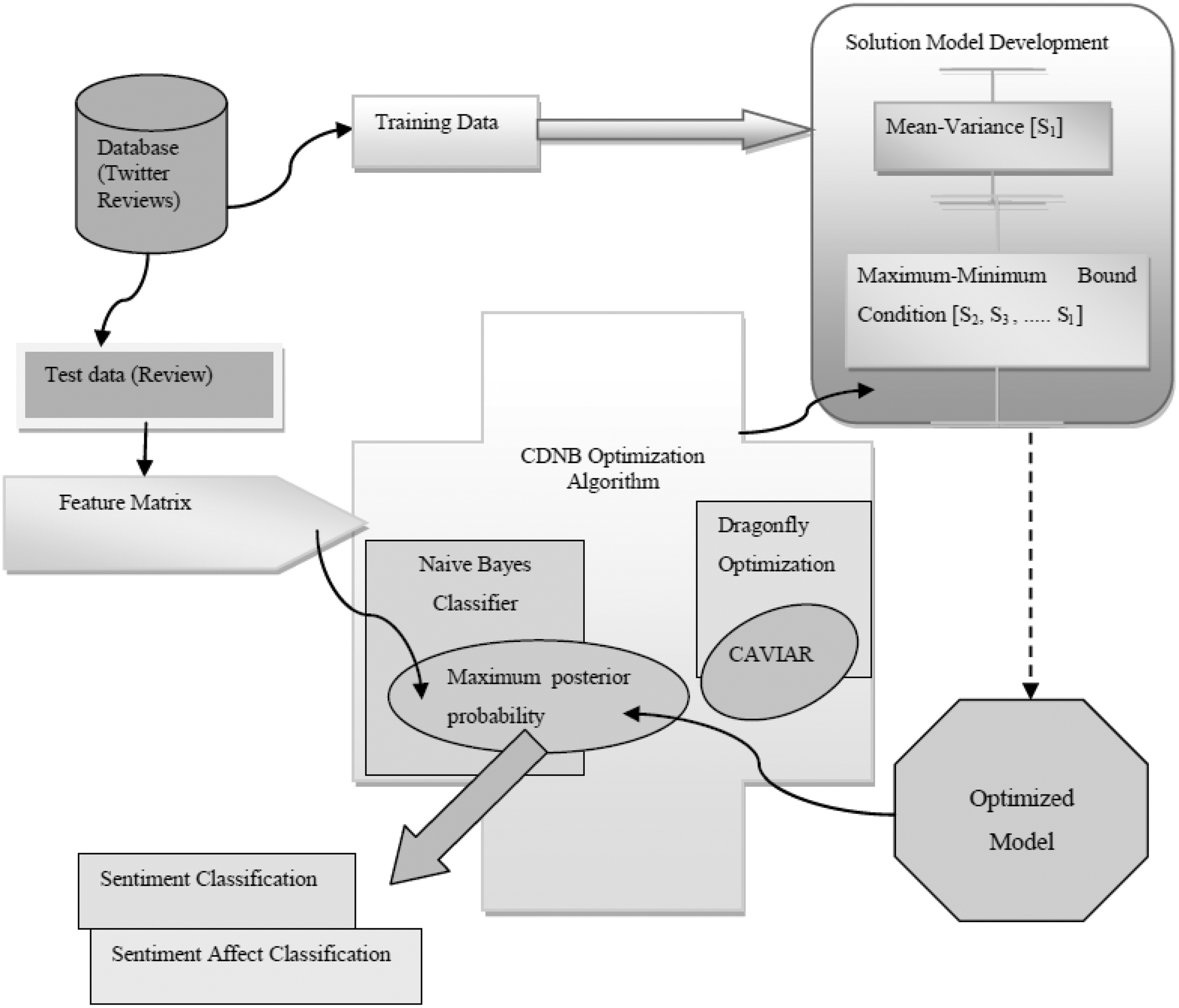
CDNB Optimization algorithm for sentiment classification and sentiment affect classification. CDNB, CAVIAR-Dragonfly optimization with Extended Naive Bayes.
Training phase
NB model creation
Once the features are extracted from the reviews, the solution model is generated using the NB that employs the maximum posterior probability concept. The representation of the solution models is as follows:
where
Optimizing the model
In this step, the generated models are optimally chosen using the novel proposed algorithm that employs the NB-based objective function. The following are the optimization steps.
Solution encoding
The solution encoding is the pictorial representation of the optimal solution determined using the proposed CDNB algorithm. The optimal classification of the training data enables the effective sentimental classification that may be either positive or negative, and in addition enables effective sentiment affect classification, which can be happy, love, or desire in case of positive class and anger, hate, or grief in case of negative class. The length of the solution vector is denoted as
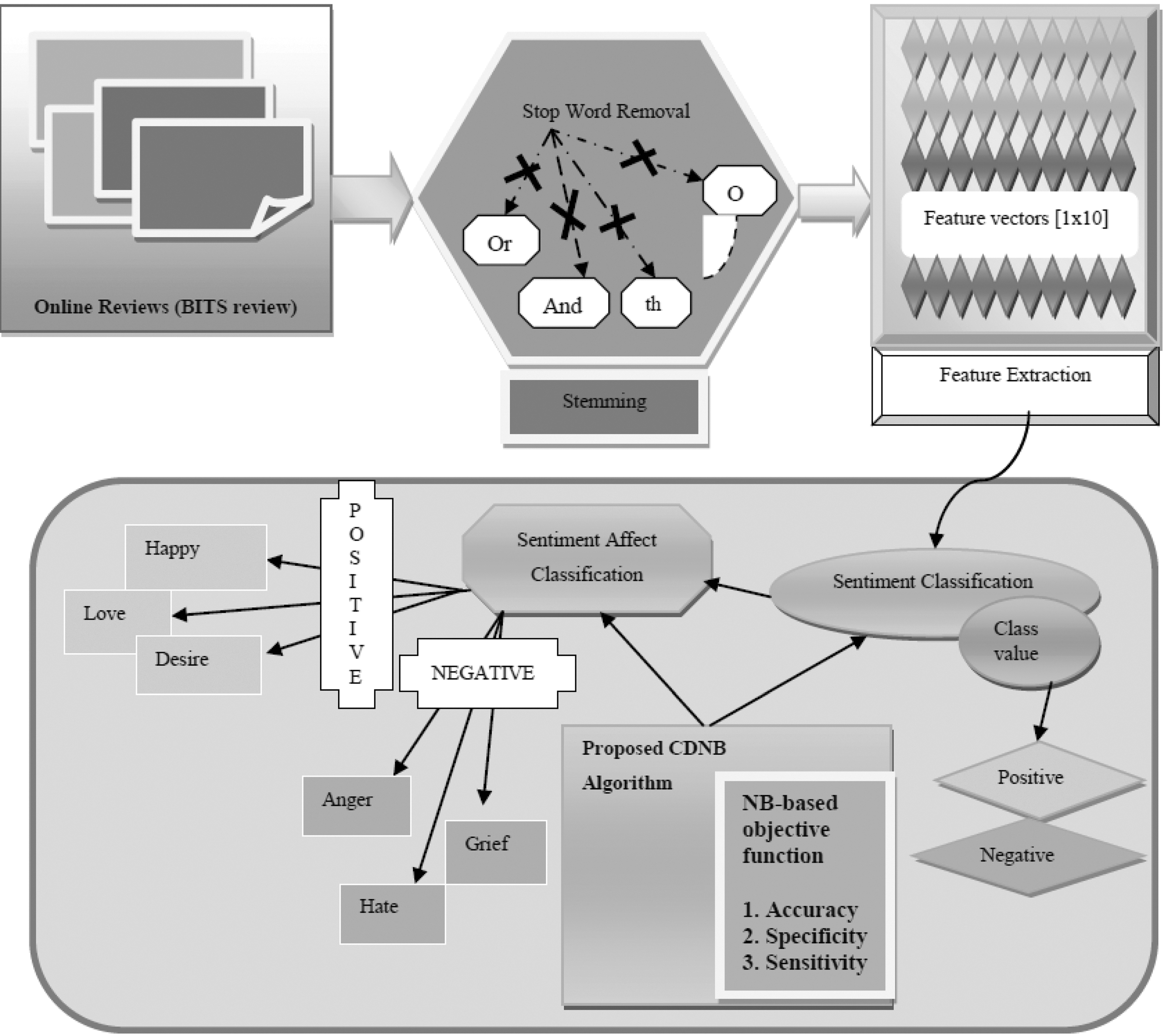
Block diagram of the proposed CDNB algorithm. NB, Naive Bayes.
NB-based objective function
The objective function depends on three parameters, namely the accuracy, sensitivity or true positive rate (TPR), and specificity or true negative rate (TNR). The accuracy, sensitivity, and specificity should be maintained maximum to maintain a maximum value of the fitness and they are evaluated based on the NB classifier principle. The NB obeys a maximum posterior probability strategy, which is followed in the calculation of accuracy, TPR, and TNR. The formula for the NB-based objective function is as follows:
where TP, TN, FP, and FN are the true positive, true negative, false positive, and false negative, and TP, TN, FP, and FN are determined to evaluate the fitness parameters. The fitness measure is evaluated for all the models generated in the classifier, and the model with the maximum fitness is selected as the best model.
Step 1: Read the training samples: The input samples are read by the classifier, and the input sample models are generated from the feature vector that carries M number of feature vectors corresponding to the individual reviews. The sample models generated for a feature vector are represented in Equation (1). The training models are developed based on the mean variance and the maximum/minimum bound principle, and this model is applied to the proposed CDNB classifier algorithm.
Step 2: Computing the posterior probability: The objective function is based on the maximum measure of fitness. The parameters of fitness depend on the posterior probability, and therefore, the posterior probability of the generated models is determined. The posterior probability of all the generated models is computed, and the computation is continued for all the sample models. Once the posterior probability of all the samples is computed, then the maximum probability is determined. The class corresponding to the maximum value of the posterior probability is assigned to the training sample.
Step 3: Generating the TP, TN, FP, and FN: Once the class is assigned to all the training samples or the models, the training model is matched with the classification model to determine the FP, FN, TP, and TN. Once the four parameters are determined, the fitness parameters, namely the accuracy, specificity, and sensitivity, are determined.
Step 4: Compute the fitness: The fitness is computed to select the best solution from the available models for which it uses the accuracy, sensitivity, and specificity parameters.
Proposed C-Dragonfly optimization algorithm
The C-Dragonfly optimization algorithm is a metaheuristic optimization algorithm, which is advantageous over the other evolutionary algorithms. The major advantages of the C-Dragonfly optimization algorithm are as follows. The information in the search space is collected and retained for future reference. Moreover, there are only a few control parameters in the search space, and they possess good flexibility. The convergence time of the proposed algorithm is very less due to the integration of the CAVIAR formula in the position update step of the standard dragonfly optimization algorithm. The proposed algorithm eases the optimal results in converging to the best solution. The proposed algorithm is based on the static and dynamic swarming behavior of the dragonflies. The proposed optimization algorithm follows the No Free Lunch (NFL) theorem. 23 Hence, it is more advantageous than the existing optimization algorithms. The static swarm of the dragonfly relies on the concept that the dragonfly takes a back and forth motion for hunting the prey, which is the exploration phase. In the static swarm, some of the dragonflies group themselves in the large group and move in the same direction for a long distance, which is the exploration phase of the dragonflies.
The principles followed in the swarm behavior are as follows. Separation that avoids the collision of the individual flies, alignment that corresponds to the matching of the velocities with each other, and cohesion that aligns the individual flies toward the center of the mass.
Initialization: The main step in the proposed CDNB algorithm is the initialization step in which the solutions are initialized, and initially, sample models are generated. The main aim of the total population is survival toward the fittest. The population or the sample models are represented in Equation (1).
SA 2 CD parameter update for determining the position: The intention of the swarm is to survive for which the individuals traverse in the direction of availability of food, and they flutter away from the enemies. The five main parameters are updated based on the behavior of the individual swarms once the population is initialized. The parameters updated are separation, alignment, cohesion, attraction, and distraction.
where X is the current position of the individual dragonfly, Xk is the position of the kth neighbor, and b be number of neighboring dragonflies with respect to the reference dragonfly. Bk denotes the separation parameter of the individual dragonflies.
where Dk refers to the alignment of the fth dragonfly and vk is the velocity of the kth neighbor.
where X is the current position of the individual dragonfly and Gk refers to the cohesion of the fth dragonfly.
Formulating the step vector: The position of the dragonfly is updated based on the step vector that determines the direction of the dragonfly, and therefore, the step vector of the dragonfly is updated as follows:
where a1, a2, a3, a4, and a5 are the weights of separation, alignment, cohesion, food factor, and enemy factor, respectively. These five weights are responsible for the effective tuning between the exploration phase and the exploitation phase and they balance the tuning process. a6 denotes the initial weight, T represents the iteration number. Bk, Dk, Gk, Ik, and Jk denote the separation, alignment, cohesion, attraction, and distraction coefficients of the fth dragonfly.
Calculating the objective function based on NB: The objective function is formulated based on the accuracy, specificity, and sensitivity shown in Equation (2) and the best solution depends on the maximum value of these parameters that is responsible for the maximum fitness value.
Updating the position of the food and the enemy: The main concept of the dragonfly optimization is the survival of the best such that they move toward the food and move away from the enemies finding a way for the survival of the dragonfly. The position of the food and the enemy is determined and based on that, the attraction and the distraction parameter is determined. The formula for calculating the attraction and distraction parameter is represented as follows:
where Ik represents the attraction of the dragonfly toward the food and
A new means of position update: -CAVIAR-based position update of the dragonfly: The position of the dragonfly is based on the step vector and is represented as follows:
The position update of the standard dragonfly optimization is presented by Equation (12). The integration of the CAVIAR equation
24
imputes the importance of the CAVIAR in the optimization process. The main importance is that the newly designed equation (18) describes the time-varying processes, and it determines the position of the dragonfly that changes position randomly based on the availability of food and the presence of enemies. The CDNB is the simplest method of predicting the current position of the dragonfly, easing the time complexity and converging to the optimal solution with a faster convergence rate. Using the CAVIAR equation, the following equation is obtained:
From the above equation, t is the prediction variable, and therefore, it is assumed as
Substitute Equation (13) in the above equation and now Equation (15) becomes
When the search mechanism is carried out using the random walk when there are no neighboring solutions, the position of the dragonfly is updated as shown below:
where
Termination: The above steps are repeated until the optimal solution is selected. The optimal position of the dragonfly carries the best solution that is processed for affect analysis. The affect analysis and sentiment classification follow all the above steps in determining the best class value and the corresponding affect factors of positive and negative class.
Testing phase
Posterior probability for testing
Whenever the test model arrives, the proposed CDNB classifier algorithm is applied to the test model to determine the positive and negative class in case of sentiment classification, happy, love, and desire for positive class or anger, hate, and grief for negative class. Let us consider the test data as t, and once the test data arrive the posterior probability of the test model is determined using the following formula:
where yt is the posterior probability of the test model and
where Ck is the kth class,
Proposed CDNB classifier for sentiment and affect classification
In this section, the proposed strategy of sentiment classification and the sentiment affect classification is presented. In general, sentiment classification reveals the ideas, experiences, grievances, problems of a product, or an organization, or government, and can enable effective decision-making process such that it benefits the society. The existing methods of classifying the emotions failed to provide optimal classification results and failed to recognize the emotions of the reviews. Therefore, a novel method named CDNB algorithm is proposed to perform the sentiment classification, and the sentiment affect classification that performs the optimal classification. The main objective of the work is to model the connections between the words and emotions to determine the exact emotions of the reviews that are expressed online. Figure 2 shows the block diagram of the proposed CDNB optimization algorithm to perform classification. Initially, the Twitter review of the BITS is taken for performing the classification. The classification of the BITS review determines the emotion of the person, who expressed the view that promotes taking effective steps in solving the issues of the environment such that it well benefits the organization. At first, the reviews are subjected to stop word removal in which all the meaningless words are removed from the sentence, and then, it is subjected to the stemming process that identifies the root words for all the words in the review sentence. Once the preprocessing step including the stop word removal and stemming is completed, the features are extracted. Each of the reviews is presented as a single-feature vector, and hence, the feature vectors for all the reviews are generated and sent to the proposed classifier that classifies as positive and negative for sentiment classification, happy, love, and desire for positive class or anger, hate, and grief for negative class. The classification result of the proposed classifier is determined optimally, and the results enable the institution to make effective decisions for the enhancement of the BITS environment.
Preprocessing the Twitter reviews of BITS
Consider the M number of reviews taken from the online Twitter reviews of BITS and represented as follows:
where rn refers to the nth review among the M number of online BITS reviews. Let us consider the nth review, which consists of m number of words. The number of words in the mth review is represented as follows:
The words in the reviews are subjected to preprocessing to enable effective emotion identification. The preprocessing stage involves two steps: namely, the stop word removal and the stemming process that processes the words present in the individual reviews and presents it to the feature extraction step.
Stop word removal
To avoid ambiguity and loading problems, the stop words are removed from the reviews such that it enables instant results and eases the process of feature extraction.
25
where s is the total number of words present in the nth review after the removal of the stop words.
Stemming
Stemming is the technique of reducing the inflected (or sometimes derived) words to their word stem, base, or root form, generally a written word form.
Development of the feature matrix
The filtered words are subjected to feature extraction for which all the reviews are converted to a feature vector and each feature vectors carries 10 features. The 10 features for every review are extracted, and the feature vector representation for the nth review is as follows:
where An is the feature vector corresponding to the nth review.
Once the individual words are applied to the SentiWordNet, two categories of the score, namely the positive score and negative score are updated. Using these score measures, the score vector is obtained based on the below condition:
where
The length of the score vector V is denoted as
where
where
where WH is the weighing coefficient and E is the entropy parameter. The features mentioned above are computed for all the reviews, and each review is converted into the feature vector of dimension
Sentiment classification by CDNB algorithm
The sentiment classification of the BITS review enables effective decision-making, and hence, the proposed method concentrates on the topic to perform an effective sentiment classification that returns any of the two classes, which is either positive or negative. Initially, the features are extracted from the review, and the features are provided to the NB classifier that generates the model based on the mean variance and maximum/minimum bound condition such that the number of possible models is generated. Then the posterior probability of the models is computed to determine the class label such that the class for the model depends on the maximum value of the posterior probability. The class label is either positive or negative. Therefore, the review can be categorized, and this makes better decisions.
Affect classification by CDNB classifier
The sentiment affect classification is performed to classify in which mood the user gives the reviews on BITS. The three classes referred for the positive class are happy, love, or desire, and the classes for the negative review may be anger, hate, or grief.
Figure 3 shows the proposed method of sentiment classification and sentiment affect classification.
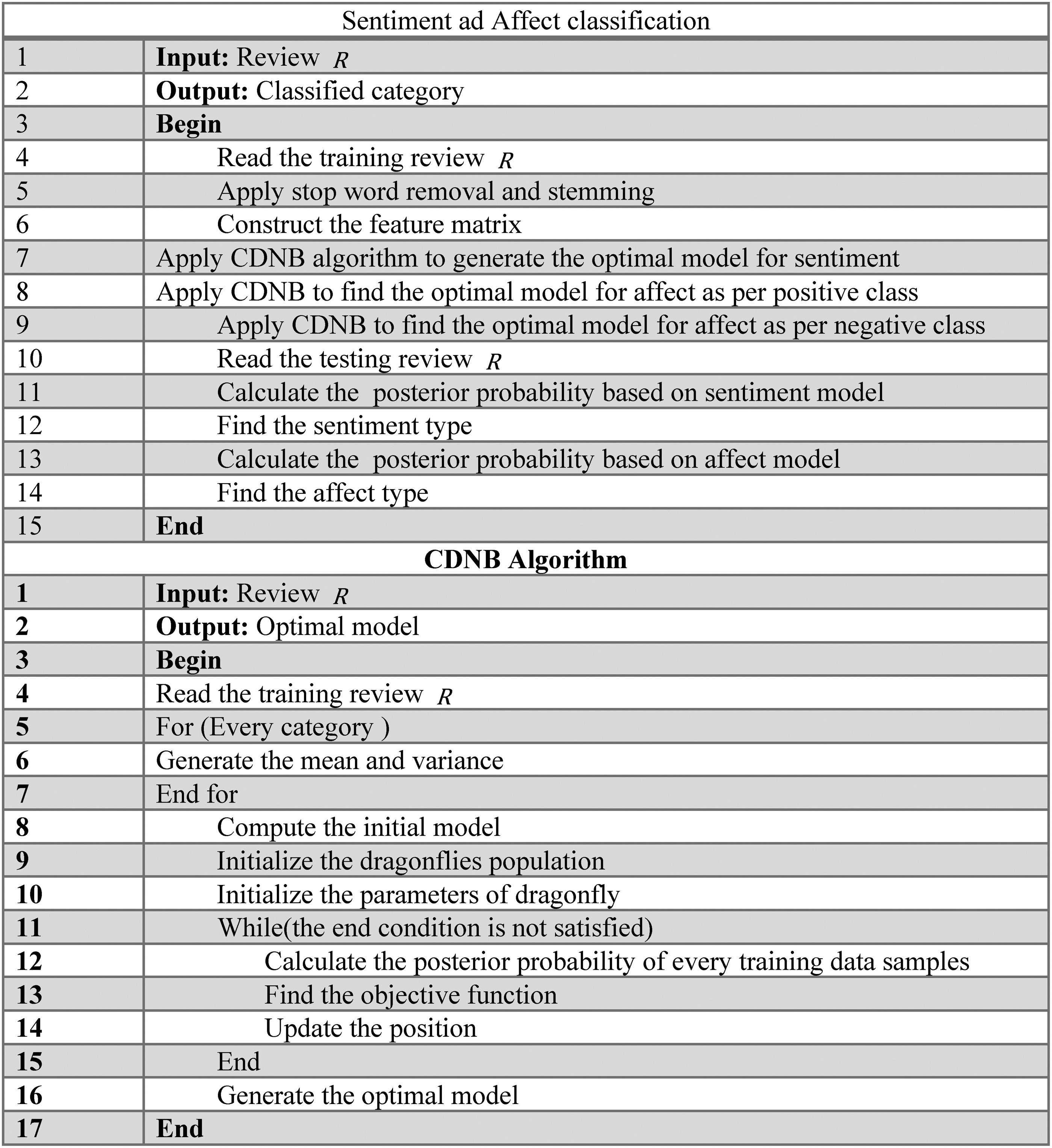
Pseudocode of the proposed CDNB optimization algorithm for sentiment classification and sentiment affect classification.
Results and Discussion
This section presents the performance analysis of the sentiment classification and the sentiment affect classification methods to prove the effectiveness of the proposed CDNB method along with the comparative analysis of the methods.
Experimental setup
For the experimentation, we utilize the Twitter Sentiment Analysis Training Corpus Data Set,
26
which is about the tweet of #BITS PILANI. The implementation is performed in the JAVA programming that runs in the Windows 8 OS with 4 GB RAM personal computer. The two setups used for analysis include the following: Setup 1: In setup 1, the values of
Research Questions:
Which preprocessing techniques are available for converting natural language text into appropriate format?
Is preprocessing a successful method to improve classification independent of implementation approach?
How to analyze the performance of the sentiment classification and affective state classification system?
Based on these research questions, the experimentation is done, and the performance of the proposed method is analyzed.
Data set description
The experiment is performed using the Twitter Sentiment Analysis Training Corpus Data Set. The data of the data set are collected from the University of Michigan Sentiment Analysis competition on Kaggle and Twitter Sentiment Corpus by Niek Sanders. The Twitter Sentiment Analysis Data Set contains 1,578,627 classified tweets with each row entered as 1 for positive sentiment and 0 for negative sentiment.
Evaluation metrics
The metrics used for evaluating the effectiveness of the proposed method include TPR, TNR, and accuracy.
Competing methods taken for comparison
The methods taken for comparison include the SentiWordNet, 27 NB, 19 and Naive Bayes with the dragonfly algorithm (NBDF). The effectiveness of the proposed method is proven by comparing the methods in terms of the performance metrics, such as TPR, TNR, and accuracy.
Performance analysis
The performance of both the sentiment and affect classification stages is analyzed using the parameters, such as TPR, TNR, and accuracy.
Using the setup 1
Sentiment classification
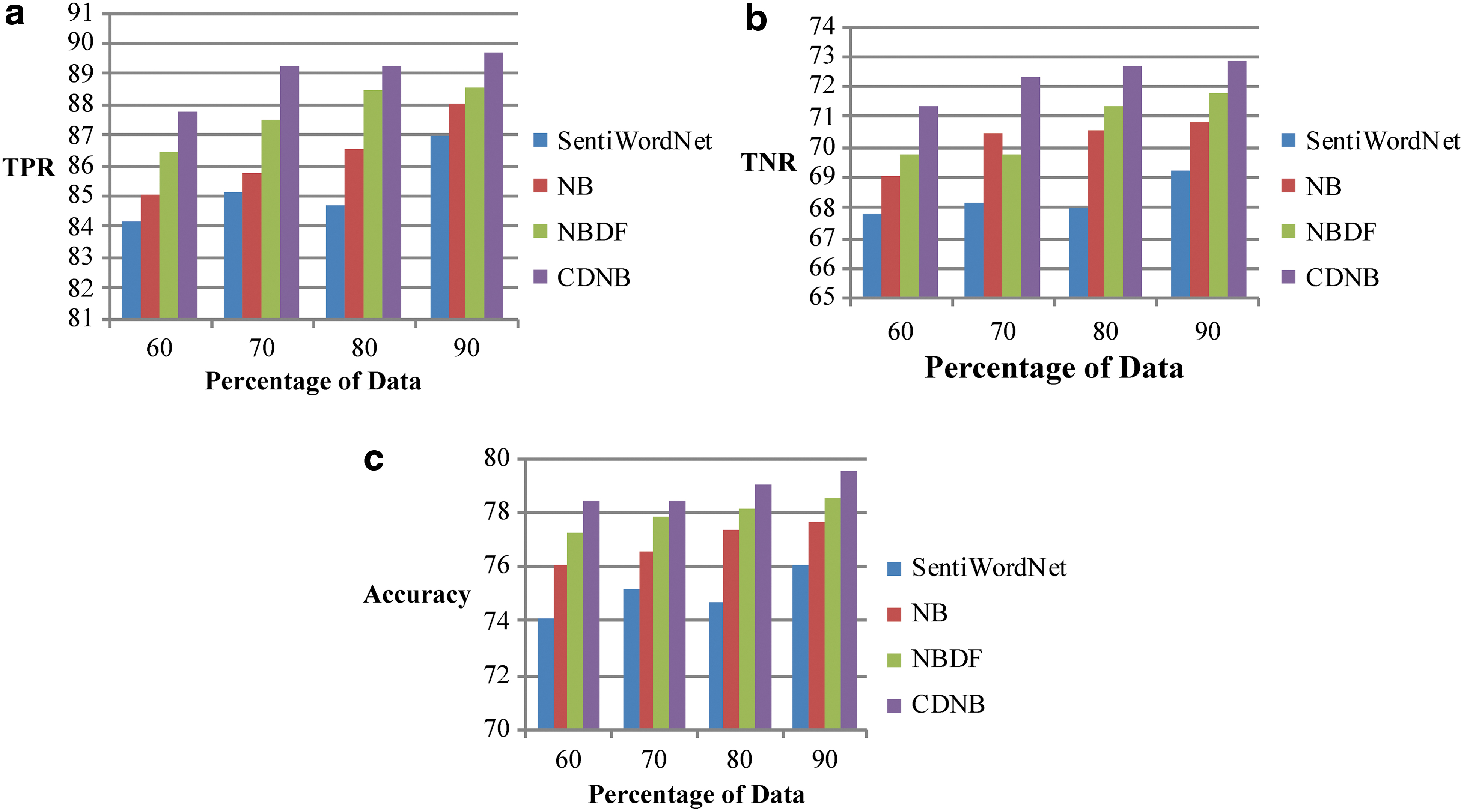
Figure 4 shows the comparative analysis of the sentiment classification methods in terms of the metrics, such as TPR, TNR, and accuracy. In Figure 4a, the TPR percentage of the classification methods is analyzed. When the percentage of the data is 60, the TPR obtained for the methods such as SentiWordNet, NB, NBDF, and the proposed CDNB is 84.17660%, 85.0419%, 86.4408%, and 87.7628%, respectively. The proposed method shows 4.09%, 3.1%, and 1.51% improved performance than the SentiWordNet, NB, and NBDF. With the increasing percentage of the data, the TPR percentage increases. The increase of the TPR percentage is noted from 60% of training data to 90% of training data. When the percentage of data is 90, the TPR of the methods, such as SentiWordNet, NB, NBDF, and the proposed CDNB, is 86.9399%, 87.9976%, 88.5063%, and 89.7066%, respectively. Here, the proposed method shows 3.08%, 1.91%, and 1.34% improved performance than the existing methods, SentiWordNet, NB, and NBDF, respectively. It is evident that the TPR percentage of the classification methods increases, but the proposed CDNB method of sentiment classification exhibits greater TPR when compared with the other existing methods.
Sentiment classification using the setup 1.
In Figure 4b, the TNR percentage of the classification methods is analyzed. When the percentage of the data is 60, the TNR obtained for the methods such as SentiWordNet, NB, NBDF, and the proposed CDNB is 67.8254%, 69.0331%, 69.7231%, and 71.3336%, respectively. With the increasing percentage of the data, the TNR percentage increases. The increase of the TNR percentage is noted from 60% to 90%, and when the percentage of data is 90, the TNR percentage of the methods such as SentiWordNet, NB, NBDF, and the proposed CDNB is 69.2538%, 70.8516%, 71.8159%, and 72.8849%, respectively. It is evident that the TNR percentage of the classification methods increases, but the proposed CDNB method of sentiment classification exhibits greater TNR when compared with the other existing methods.
In Figure 4c, the accuracy of the classification methods is analyzed. When the percentage of the data is 60, the accuracy obtained for the methods such as SentiWordNet, NB, NBDF, and the proposed CDNB is 74.1228%, 76.0686%, 77.1933%, and 78.3741%, respectively. With the increasing percentage of the data, the accuracy percentage increases. The increase of the accuracy percentage is noted from 60% to 90%, and when the percentage of data is 90, the accuracy percentage of the methods such as SentiWordNet, NB, NBDF, and the proposed CDNB is 76.0767%, 77.6144%, 78.5227%, and 79.555%, respectively. It is evident that the accuracy percentage of the classification methods increases, but the proposed CDNB method of sentiment classification exhibits greater accuracy when compared with the other existing methods. The preprocessing used in the proposed model helps to improve the performance of the classifier.
Sentiment affect classification
Figure 5 shows the comparative analysis of the sentiment affect classification methods in terms of the metrics, such as TPR, TNR, and accuracy. In Figure 5a, the TPR rate of the classification methods is analyzed. When the percentage of the data is 60, the TPR obtained for the methods such as SentiWordNet, NB, NBDF, and the proposed CDNB is 84.1766%, 80.3396%, 81.6248%, and 83.4495%, respectively. With the increasing percentage of the data, the TPR percentage increases. The increase of the TPR percentage is noted from 60% to 90%, and when the percentage of data is 90, the TPR percentage of the methods such as SentiWordNet, NB, NBDF, and the proposed CDNB is 86.9399%, 82.7225%, 83.27%, and 84.9071%, respectively. It is evident that the TPR percentage of the classification methods increases, but the proposed CDNB method of sentiment affect classification exhibits greater TPR when compared with the other existing methods.
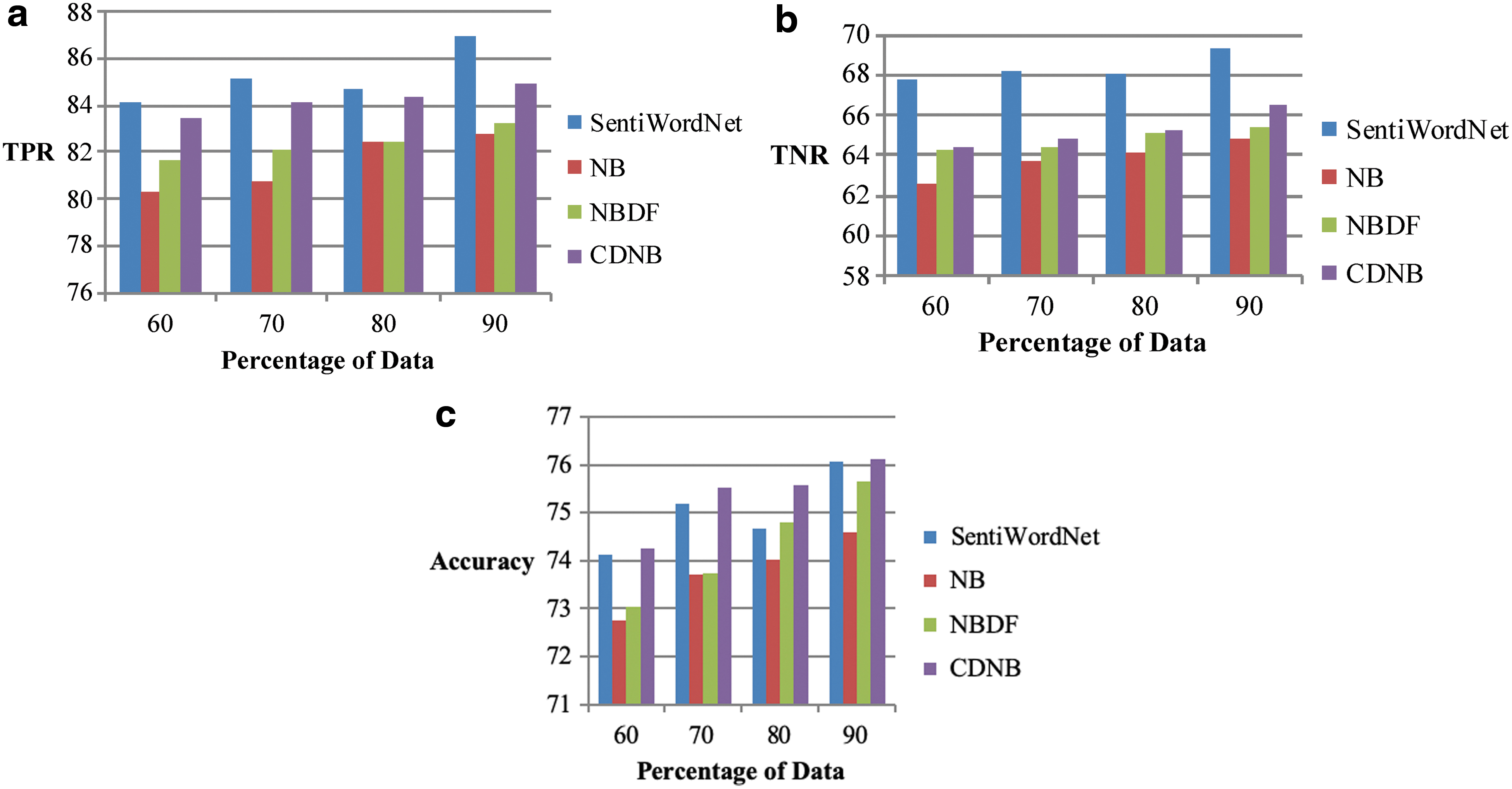
Sentiment affect classification using setup 1.
In Figure 5b, the TNR percentage of the sentiment affect classification methods is analyzed. When the percentage of the data is 60, the TNR obtained for the methods such as SentiWordNet, NB, NBDF, and the proposed CDNB is 67.8254%, 62.5604%, 64.3089%, and 64.4182%, respectively. With the increasing percentage of the data, the TNR percentage increases. The increase of the TNR percentage is noted from 60% to 90%, and when the percentage of data is 90, the TNR percentage of the methods such as SentiWordNet, NB, NBDF, and the proposed CDNB is 69.2538%, 64.8470%, 65.3725%, and 66.44%, respectively. It is evident that the TNR percentage of the classification methods increases, but the proposed CDNB method of sentiment affect classification exhibits greater TNR when compared with the other existing methods.
In Figure 5c, the accuracy of the sentiment affect classification methods is depicted with all the comparative methods. When the percentage of data is 60, the proposed model obtained an accuracy of 74.2602%, which is 0.19%, 1.65%, and 1.65% higher than the accuracy obtained by the existing methods, such as SentiWordNet, NB, and NBDF, respectively. With the increasing percentage of the data, the accuracy percentage increases. The increase of the accuracy percentage is noted from 60% to 90%, and when the percentage of data is 90, the accuracy percentage of the methods such as SentiWordNet, NB, NBDF, and the proposed CDNB is 76.07674%, 74.5915%, 75.6414%, and 76.1204%, respectively. It is evident that the accuracy percentage of the classification methods increases, but the proposed CDNB method of sentiment affect classification exhibits greater accuracy when compared with the other existing methods.
Using the setup 2
Sentiment classification
Figure 6 shows the comparative analysis of the sentiment classification methods in terms of the metrics, such as TPR, TNR, and accuracy. In Figure 6a, the TPR of the classification methods is analyzed. When the percentage of the data is 60, the TPR obtained for the methods such as SentiWordNet, NB, NBDF, and the proposed CDNB is 84.1766%, 86.3232%, 86.7547%, and 87.7552%, respectively. With the increasing percentage of the data, the TPR percentage increases. The increase of the TPR percentage is noted from 60% to 90%, and when the percentage of data is 90, the TPR percentage of the methods such as SentiWordNet, NB, NBDF, and the proposed CDNB is 86.9399%, 87.992%, 87.9972%, and 90.0516%, respectively. It is evident that the TPR percentage of the classification methods increases, but the proposed CDNB method of sentiment classification exhibits greater TPR when compared with the other existing methods.
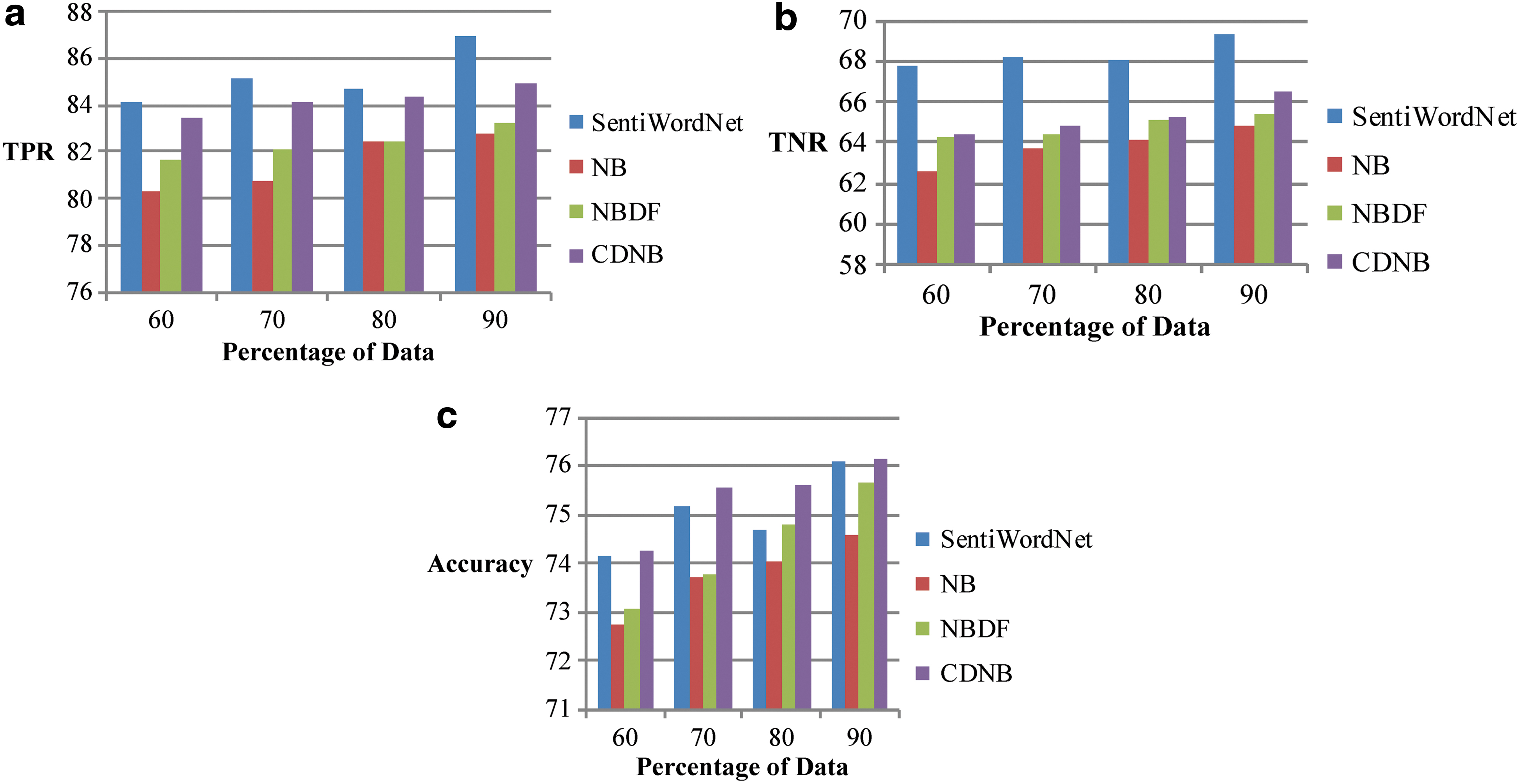
Sentiment classification using the setup 2.
In Figure 6b, the TNR percentage of the sentiment classification methods is analyzed. When the percentage of the data is 60, the TNR obtained for the methods such as SentiWordNet, NB, NBDF, and the proposed CDNB is 67.8254%, 68.7915%, 69.6040%, and 71.4195%, respectively. With the increasing percentage of the data, the TNR percentage increases. The increase of the TNR percentage is noted from 60% to 90%, and when the percentage of data is 90, the TNR percentage of the methods such as SentiWordNet, NB, NBDF, and the proposed CDNB is 69.2538%, 69.5766%, 71.8249%, and 72.78692%, respectively. It is evident that the TNR percentage of the classification methods increases, but the proposed CDNB method of sentiment classification exhibits greater TNR when compared with the other existing methods.
In Figure 6c, the accuracy of the sentiment classification methods is depicted with all the comparative methods. When the percentage of the data is 60, the accuracy obtained for the methods such as SentiWordNet, NB, NBDF, and the proposed CDNB is 74.1228%, 77.0156%, 76.5645%, and 77.9685%, respectively. With the increasing percentage of the data, the accuracy percentage increases. The increase of the accuracy percentage is noted from 60% of training data to 90% of training data. When the percentage of data is 90, the accuracy of the proposed CDNB model is 80.3420%, which is 5.31%, 2.82%, and 1.35% higher than the accuracy of the existing methods, such as SentiWordNet, NB, NBDF, respectively. It is evident that the accuracy percentage of the classification methods increases with the increase in the training data, but the proposed CDNB method of sentiment classification exhibits greater accuracy when compared with the other existing methods.
Sentiment affect classification
Figure 7 shows the comparative analysis of the sentiment affect classification methods in terms of the metrics, such as TPR, TNR, and accuracy. In Figure 7a, the TPR of the classification methods is analyzed. When the percentage of the data is 60, the TPR obtained for the methods such as SentiWordNet, NB, NBDF, and the proposed CDNB is 84.1766%, 80.7332%, 81.6768%, and 83.1231%, respectively. With the increasing percentage of the data, the TPR percentage increases. The increase of the TPR percentage is noted from 60% to 90%, and when the percentage of data is 90, the TPR percentage of the methods such as SentiWordNet, NB, NBDF, and the proposed CDNB is 86.9399%, 82.7646%, 83.9067%, and 84.8487%, respectively. It is evident that the TPR percentage of the classification methods increases, but the proposed CDNB method of sentiment affect classification exhibits greater TPR when compared with the other existing methods.
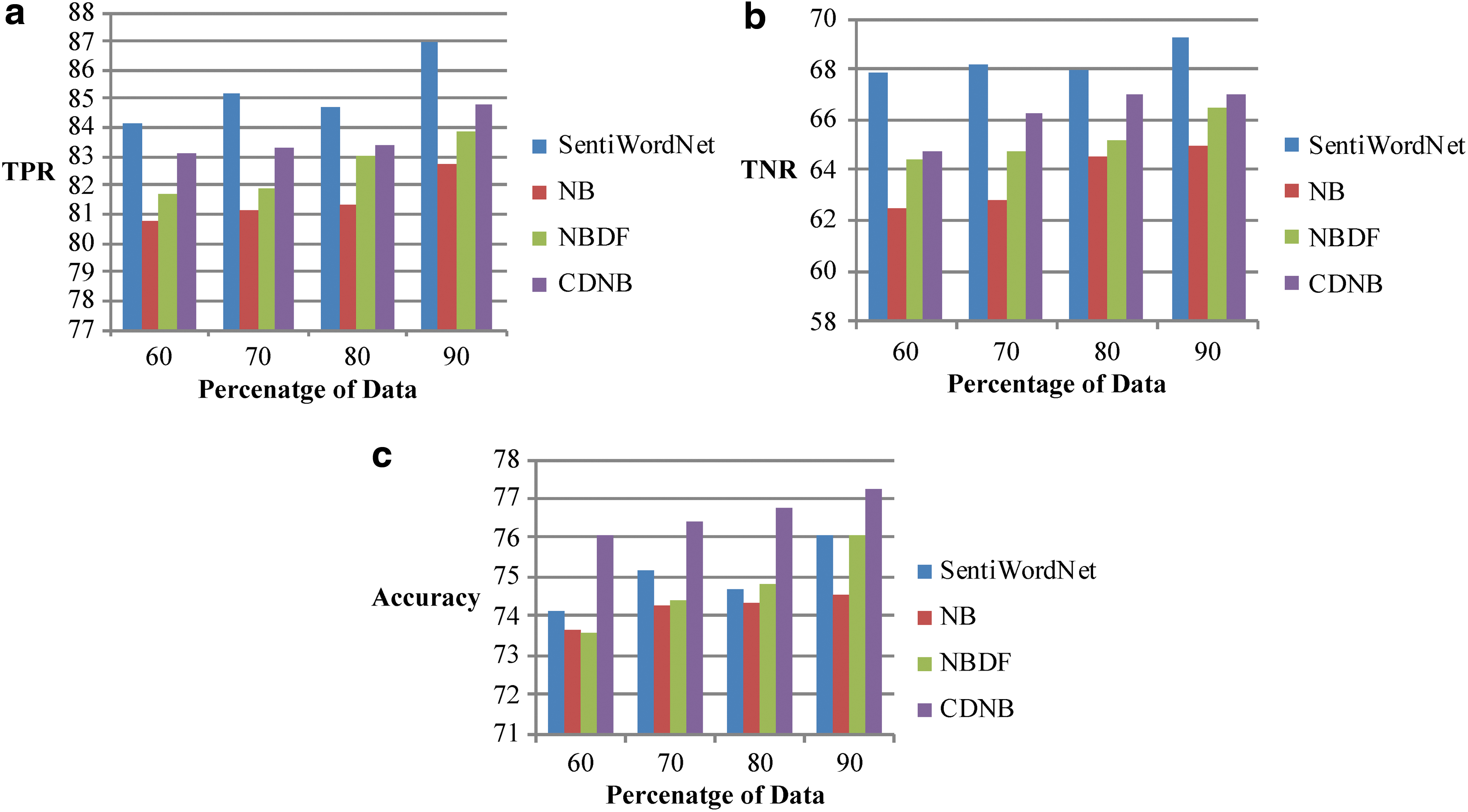
Sentiment affect classification using the setup 2.
In Figure 7b, the TNR percentage of the sentiment affect classification methods is analyzed. When the percentage of the data is 60, the TNR obtained for the methods such as SentiWordNet, NB, NBDF, and the proposed CDNB is 67.8254%, 62.5021%, 64.43372%, and 64.699%, respectively. With the increasing percentage of the data, the TNR percentage increases. The increase of the TNR percentage is noted from 60% to 90%, and when the percentage of data is 90, the TNR percentage of the methods such as SentiWordNet, NB, NBDF, and the proposed CDNB is 69.2538%, 64.9910%, 66.4977%, and 66.9749%, respectively. It is evident that the TNR percentage of the classification methods increases, but the proposed CDNB method of sentiment affect classification exhibits greater TNR when compared with the other existing methods.
In Figure 7c, the accuracy of the sentiment affect classification methods is depicted with all the comparative methods. When the percentage of the data is 60, the accuracy obtained for the methods such as SentiWordNet, NB, NBDF, and the proposed CDNB is 74.1228%, 73.6704%, 73.5917%, and 76.0811%, respectively. With the increasing percentage of the data, the accuracy percentage increases. The increase of the accuracy percentage is noted from 60% to 90%, and when the percentage of data is 90, the accuracy percentage of the methods such as SentiWordNet, NB, NBDF, and the proposed CDNB is 76.0767%, 74.5251%, 76.0490%, and 77.2505%, respectively. It is evident that the accuracy percentage of the classification methods increases, but the proposed CDNB method of sentiment affect classification exhibits greater accuracy when compared with the other existing methods.
Comparative discussion
The comparative discussion of the classification method is presented in Table 2. The metrics are compared in terms of the average TPR, average TNR, and average accuracy. The average TPR percentage of the sentiment classification using the methods, such as SentiWordNet, 27 NB, 19 NBDF, and CDNB, is 85.24201, 87.1521, 87.7192, and 89.0934, respectively. Here, the proposed method shows 4.32%, 2.18%, and 1.54% improvement than the existing methods, such as SentiWordNet, NB, and NBDF, respectively. The average TPR percentage of the sentiment classification using the proposed CDNB method is greater than all other methods. Similarly, the average TPR percentage of sentiment affect classification using the proposed CDNB method is 84.2122, which is 1.15%, 3.13%, and 1.87% greater than other methods. The average TNR percentage for sentiment classification using the SentiWordNet, 27 NB, 19 NBDF, and CDNB is 68.29894, 70.2333, 70.6812, and 79.3591, whereas for the affect classification, the average TNR percentage is 63.2989, 63.8265, 65.1921, and 66.2187. The greater accuracy is determined using the proposed method that is 79.359 for sentiment classification and 76.6249 for affect classification.
Comparative analysis of the sentiment classification and affect classification methods
The bold values represent the best performance.
CDNB, CAVIAR-Dragonfly optimization with Extended Naive Bayes; NBDF, Naive Bayes with the dragonfly algorithm; TNR, true negative rate; TPR, true positive rate.
From the analysis, it can be shown that the proposed CDNB model has maximum performance than the existing methods. The reasons for the improved performance of the proposed model are that it is the straightforward process of predicting the current position of the dragonfly and converges to the optimal solution with a faster convergence rate. Due to the integration of the CAVIAR formula in the position update step of the standard dragonfly optimization algorithm, the convergence time of the proposed algorithm is very less. Also, the proposed model follows the NFL theorem, which increases the overall performance.
Conclusion
This article proposes a novel CDNB model for sentiment classification and affective state classification. The proposed CDNB performs the classification based on the proposed C-Dragonfly optimization and the maximum posterior probability-based NB principle. This novel C-dragonfly algorithm is the integration of the CAVIAR formula in the standard dragonfly optimization algorithm. Once the optimized model is determined using the proposed model, it employs the maximum posterior probability-based classification that classifies the data as positive or negative. In addition, it performs affective state classification that enables the effective decision-making process. The proposed method exhibits maximum TPR, TNR, and accuracy percentages of 89.0934%, 72.3064%, and 79.3591% for the sentiment classification and 84.2122%, 66.2187%, and 76.6249% for the sentiment affective state classification. In the future, we will utilize more data sets to analyze the performance of the proposed classifier.
Footnotes
Author Disclosure Statement
No competing financial interests exist.
Funding Information
No funding was received from any organization or agency.