
Abstract
As high-throughput approaches in biological and biomedical research are transforming the life sciences into information-driven disciplines, modern analytics platforms for big data have started to address the needs for efficient and systematic data analysis and interpretation. We observe that radiobiology is following this general trend, with -omics information providing unparalleled depth into the biomolecular mechanisms of radiation response—defined as systems radiobiology. We outline the design of computational frameworks and discuss the analysis of big data in low-dose ionizing radiation (LDIR) responses of the mammalian brain. Following successful examples and best practices of approaches for the analysis of big data in life sciences and health care, we present the needs and requirements for radiation research. Our goal is to raise awareness for the radiobiology community about the new technological possibilities that can capture complex information and execute data analytics on a large scale. The production of large data sets from genome-wide experiments (quantity) and the complexity of radiation research with multidimensional experimental designs (quality) will necessitate the adoption of latest information technologies. The main objective was to translate research results into applied clinical and epidemiological practice and understand the responses of biological tissues to LDIR to define new radiation protection policies. We envisage a future where multidisciplinary teams include data scientists, artificial intelligence experts, DevOps engineers, and of course radiation experts to fulfill the augmented needs of the radiobiology community, accelerate research, and devise new strategies.
Introduction
The field of biomolecular radiation research is experiencing a significant transformation during recent times, with high-throughput technologies used to address questions about the response of biological systems to radiation at the molecular level, including genomics, epigenomics, transcriptomics, and proteomics. 1 This intense activity has generated novel insights into the mechanisms with which organisms respond to high- or low-dose ionizing radiation (LDIR). 2 The latter, defined as LDIR, has a particular significance for our present lifestyles across global communities, as it involves facets of human health, radioprotection, and safety on a wider scale. 3
The amount of LDIR we receive today has been increasing, due to a number of factors including medical diagnosis, 4 radiation-based therapies, 5 increased air travel, 6 and long-distance effects of nuclear accidents.7,8 The significance of LDIR research extends beyond Earth, 9 as health effects on astronauts due to long-term exposure to cosmic radiation will become of paramount importance for future space flights,10,11 and ultimately space colonization. Among the greatest risks involving radiation, especially in outer space environments, relate to cancer and damage to the central nervous system (CNS),12,13 topics of intense interest.
The study of LDIR effects on the CNS is a genuine challenge due to the inherent difficulties of studying brain and behavior—as brain research cannot be invasive and behavior is affected at the time of the study, translating molecular signatures into phenotypes, and behavioral patterns—during or after exposure. 14 Thus, despite significant progress in understanding the effects of LDIR on various cell lines in vitro and their health implications, 15 these studies need to be extended to the brain and the CNS, where knowledge of LDIR impact remains limited.
Consequently, it is not surprising that the number of publications for LDIR effects on various tissues and/or cell lines generally, and on the brain specifically, has been constantly increasing. High-quality data sets obtained by genome-wide experiments have started to transform the field of LDIR research to a genomics subdiscipline, giving rise to typical big data issues. These data form the basis upon which a systems approach can integrate the genome-wide structure and function of LDIR response, in the same manner as genomics feeds into systems biology. 16 Therefore, we can now contemplate the birth of systems radiobiology, where high-throughput experiments provide the structure of the components and the systems approach offers appropriate frameworks for the analysis and simulation of the dynamics of biological responses.
The production of genomics data has been characterized as a “four-headed beast”: acquisition, storage, distribution, and analysis. 17 Evidently, it is not straightforward to address all these challenges within a single, monolithic technological framework. In fact, an apt combination of contemporary approaches in data science will be able to advance computational activities forward so that research results can be translated into applied clinical and epidemiological practice.
Various technologies relating to data production and storage have been on the rise in recent years. Large complex data sets are inherently difficult to navigate, and both cloud storage and special programming interfaces (e.g., software development kits) remain the methods of choice for big data analysis and distribution. The analysis step is probably one of the most demanding problems we are faced with; this facet also affects LDIR research, especially in its ever-increasing genomics context. Software solutions for data analytics provided by academic efforts and commercial companies typically involve cloud-based systems while software development is shifting toward the use of artificial intelligence and related algorithmic approaches.
Herein, we provide an overview on the current state of LDIR brain research and analyze specific challenges for big data analysis and interpretation, connected to the growth of systems radiobiology, following a more familiar interplay of bioinformatics and systems biology, as well as legacy, epidemiology, environment, and biomaterial data sets. 18 Elements of this exposition might also be relevant to radiomics (large-scale radiobiology with medical imaging) and regardless of dose or organ, thus impacting not only radiation safety but also the clinical realm and therapy.
Literature Growth
Hundreds of radiobiology studies took place in the past half-century or so (Fig. 1). Until recently, these studies were primarily gene-centric and tissue-specific in that they have measured effects of LDIR on the responses of a handful of genes and usually in a single tissue or typically a cell line. 19 This is exemplified by the limited number of genes known to be affected in those detailed studies—for instance, we have managed to explore the literature, in a by no means exhaustive review, and have managed to identify 40 genes across vertebrates (mostly model organisms, and human) whose expression has been shown to respond to low-dose radiation in a range of experimental setups, with varying measurements of dose and amounts of radiation (Table 1). These invaluable studies form the basis upon which important steps were made toward a better understanding of radiation responses in biological systems, and mammalian species in particular. 20 From a methodological point of view, these findings might form a key resource for genomics experiments, as they represent a gold standard, which will need to be corroborated by high-throughput studies. In other words, the gene-centric experiments provide an estimate of the coverage of the genome-wide response, as they would need to be detected in those experiments.

Total numbers of publications per year in PubMed®; blue line-left y-axis: total number of publications; green bars-right y-axis, publications related to LDIR effects on the brain. LDIR, low-dose ionizing radiation.
A list of 40 genes that have been studied in low-dose ionizing radiation experiments affecting the vertebrate brain
The list has been generated from a quasi-systematic review of the literature and contains 47 records (genes CA1, CaMKII, ICAM-1, Ku70, and p54 are listed twice and CREB is listed three times, thus corresponding to 7 additional records). Column names: “gene” refers to the gene name reported (not always using a unique nomenclature), “species” is the model species or human, “dose” is given as reported, and “pmid” is the PubMed® identifier for the corresponding publication. The list is sorted by pmid, which roughly corresponds to chronological order, therefore time of discovery for a specific gene.
A cursory review of the literature reveals a trend for both general LDIR research and brain-oriented studies, with the total number of relevant publications exhibiting a general trend for growth, at least in absolute numbers (Fig. 1). For the particular analysis shown here, we have searched the literature following the guidelines of the PRISMA protocol (“Preferred Reporting Items for Systematic Reviews and Meta-Analyses”) to collect all relevant publications.21,22 The text mining search is used in conjunction with two search engines, PubTator 23 and Correlation Engine.24,* One potential future plan might be the deployment of a text mining suite for literature scans, so that the contents always remain updated—a general issue of wider relevance. This step can be performed with minimal effort, by executing a semi-automated scan of the literature. Text mining technology might also be used to create relationship links for molecules and other terms recorded in data warehouses, such as BRIDE. 25 Additional experimental data will be continually contributed, once relevant studies are published in peer-reviewed journals. We have discovered 39 articles related to LDIR effects on the brain (Fig. 1). Of these, a total of 32 articles contain gene-related information—still low but expected to rise quickly in the near future.
Another common trend shared with the general genomics literature is that, increasingly, LDIR-related articles have started to contain extensive supplementary archives, with large data sets of genomics, transcriptomics, or proteomics experiments. In contrast to previous years, where publications addressed a small number of genes and their responses, genome-wide experiments provide significant information-rich results that need to be deposited to open access archives—these have not been used too widely in the LDIR field (e.g., FigShare, etc.). At present, most of this information is available via specialized databases for radiation research, such as StoreDB, 26 a major effort that records complex and complete information for radiobiology experiments.
Software Architectures
Herein, we provide a short perspective of big data frameworks for systems radiobiology throughout the data cycle—most of these features are arguably relevant for other types of -omics and systems biology research. We remark that, as much useful these frameworks can be for data science in general and computational genomics in particular, they offer significant opportunities for radiobiology research, as the nature of radiation experiments may push their boundaries in terms of data representation, complexity, and computational efficiency. These frameworks are designed to ensure minimum goals for computation, namely the integration of heterogeneous data, the acceleration of analysis and reproducibility, the application of latest analysis tools, and knowledge transformation into applications. The components of an idealized framework are shown in Figure 2, addressing the needs for knowledge extraction from complex data sets. 27 Indeed, LDIR experiments produce heterogeneous and multidimensional data sets; one of their hallmarks is that measurements may be coupled with other complex parameters or metadata, for example, developmental stage, tissue specificity, and standardized behavioral experiments in animals, recording intricate patterns of movement and interaction “phenotypes.” Cloud computing and tools such as data lakes will help us manage these complex heterogeneous data beyond traditional storage and analytical tools, which can no longer provide the agility and flexibility required to deliver relevant analyses. We describe the modules of this idealized framework below.
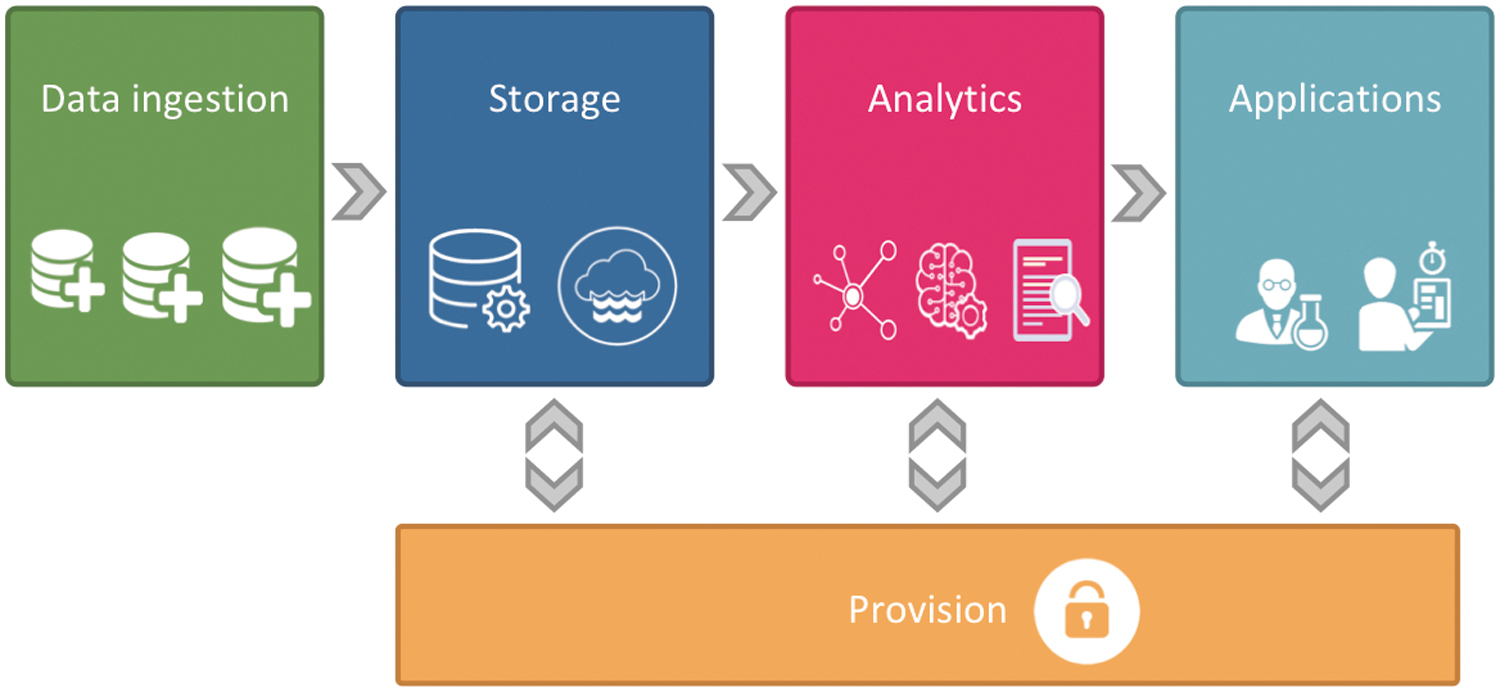
An outline of an idealized big data analytics framework architecture, also relevant for big data applications in systems radiobiology.
The first module, “data ingestion,” primarily addresses the discovery phase where decisions are made about those data sets from public databases that need to be integrated with experimental results. A strict software requirement is to extract data from several heterogeneous resources (e.g., web, ftp, REST application programming interfaces [APIs] etc.) and provide support for both structured and unstructured data formats.
The second module, “store,” concerns storage and is typically referred to as a “data lake.” Data lakes represent a new concept for the big data domain. 28 Using a data lake architecture, it is possible to gather massive amounts of raw data from different sources in a central location. Data lakes are optimized storage for big data analytics workloads. They differ from the data warehouse concept as they store unprocessed data, for which aims are not defined and maintenance is minimal, compared with data warehousing where processed data are stored with defined aims and higher maintenance costs. † Data can be stored either as structured or unstructured. While it is relatively easy to deposit raw data into a data lake, it can be much harder to always be aware of all content details for downstream analysis. 29 Therefore, a data catalog is required to develop a metadata management system to search and understand the features of all available information, along other components. 30 To push the analogy a bit further, it is argued sometimes that without a sophisticated metadata management system, there is always a danger to convert a data lake into a “data swamp.” 31
The “provision” phase is an additional multithreaded layer, concerning data security and user access restrictions to a data lake. It is implemented through user authorization, data control access on different levels, and encryption capabilities to secure sensitive data, with standard protocols.
The third module, “analytics,” evidently relates to the downstream data interpretation needs. In the analysis phase, we can use analytics engines such as Hadoop 32 and Spark. 33 Well-established tools and techniques such as machine learning and network analysis may be applied to search for patterns among heterogeneous data sets. The cloud's capability for scalability with the on-demand use of computation-intensive clusters reduces processing times, while usage costs remain low as the pay-as-you-go charging model is usually applied.
The final module, “applications,” allows end users to interact with the enriched data sets in various ways. Batch or interactive queries, web APIs, and multipurpose notebooks are some of them. Finally, the research results can be presented clearly with web visualization dashboards-notebooks, such as Apache Zeppelin. 34
The implementation of this framework represents an optimal integrated approach for systems radiobiology and genomics, and beyond. The framework is batch-oriented for data processing, while it is possible to add appropriate modules to perform streaming analysis and real-time analytics. While these systems are not readily available, at least in the academic realm, we must admit that they represent a sort of a wish list, in our past, joint efforts to address the data analytics phase of the
This data integration phase for
Data Analysis
Indeed, data availability for LDIR effects on the brain, and other tissues or cell lines, has also been increasing dramatically. High-quality -omics and next-generation sequencing experiments under various conditions and time–dose combinations produce high volumes of data and new challenges for interpretation through the use of techniques based on big data analytics. Data sets from current experiments can be integrated with publicly available data resources to enrich existing results and obtain further novel insights related to this domain. All this information from several data sources can be represented as a network graph. 37
As an example, we provide a representation of proteomics experiments on the mouse brain, 38 enriched with additional information. The present case shows that irradiation to a single dose of 500 mGy may cause developmental neurotoxic effects, both male and female mice, manifested by a lack-of, or reduced, capacity to habituate an unfamiliar environment (behavioral phenotype). Moreover, irradiation to a dose of 350 mGy seems to be a tentative threshold for induction of this type of neurotoxicity. For demonstration purposes and to reduce the complexity of visualization, we created three data-enriched networks with Cytoscape. 39 For those doses (20, 500, and 1000 mGy, 24 hours after exposure), we have added information for gene and chromosome identity, and phenotypes (including those describing disease) (Fig. 3). Obviously, several data layers can be added as we see fit, for example, metabolic pathways, gene ontology terms, expression levels, tissue specificity, and others. The specific example illustration is original in the sense that phenotypes and chromosome information are added to the standard attributes (gene, dose, time—fixed here at 24 hours) and is intended to sketch out how data integration and visualization can be coupled to aid interpretation of large-scale data, a common theme in data-intensive fields such as genomics. 40 This approach can help us understand hard-gained costly results and implicit relationships hidden in relevant connections, through exploratory data analysis. 41
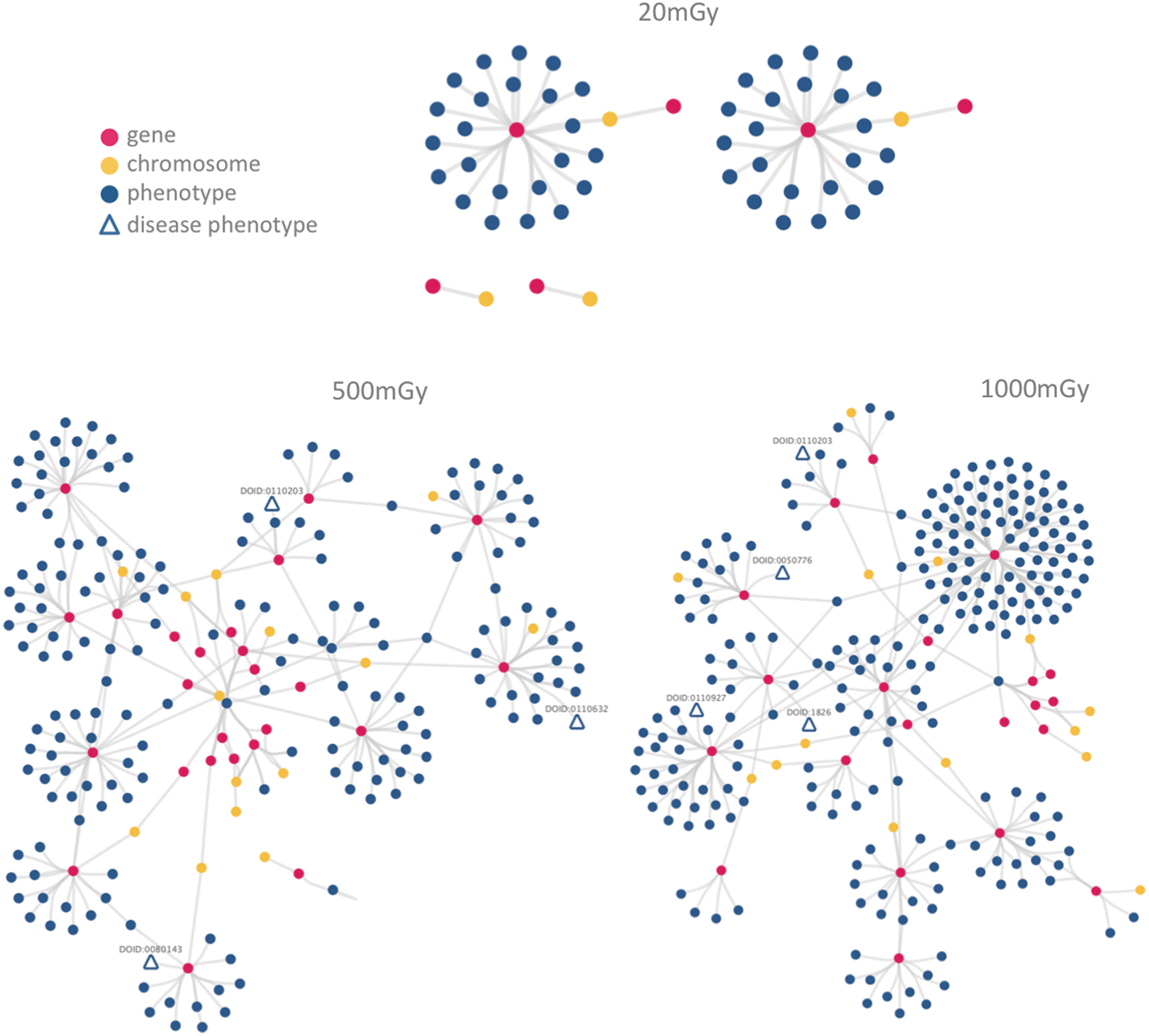
Visualization of three states, representing the experimental results discussed in Data Analysis section. Genes are depicted by red circles, and the chromosomes in which those genes are found are depicted by yellow circles, phenotypes are depicted by blue circles, while disease phenotypes are marked by open blue triangles. For instance, in the simple 20 mGy state, there are four networks covering six genes, which belong to four chromosomes (the top networks contain two genes each on the same chromosome, whereas the bottom simple networks with only two nodes contain genes with no association with known phenotypes or diseases). A more complex picture emerges at the 500- and 1000-mGy states: DOIDs are provided for disease phenotypes in these complex networks. For more information, please see Data Analysis section. DOIDs, disease ontology identifiers.
It is evident that certain genes influenced by exposure to 500 and 1000 mGy are known to be associated with certain human diseases, in contrast to those responding at 20 mGy, where there are no such cases (Fig. 3). Three genes associated with diseases for the dose of 500 mGy are as follows: Cox6a1 (12q24), implicated in a Charcot–Marie–Tooth disease recessive intermediate D 42 (DOID:0110203); Tubb3 (16q24), involved in congenital fibrosis of the extraocular muscles 43 (DOID:0080143); and Chkb (22q13), implicated in megaconial-type congenital muscular dystrophy 44 (DOID:0110632). At 1000 mGy, the relevant genes are four: Cox6a1 (as above—corroborating this result; DOID:0110203), Aldh5a1 (6p22) associated with epilepsy 45 (DOID:1826)—among other diseases, Gdi1 (Xq28) involved in nonsyndromic X-linked intellectual disability 46 (DOID:0050776), and Acta1 (1q42) associated in nemaline myopathy 347 (DOID:0110927).
The above findings provide a basis upon which further biological investigations can be performed, thus extending our understanding of LDIR effects in a highly precise manner. This short story provides a sketchy example of data drilling into big data of high complexity for systems radiobiology and the knowledge extraction steps that help us focus on specific targets and their associated networks. To qualify for a big data perspective, readers need to imagine the above example multiplied by 100-fold, with dozens of experimental conditions (time–dose), and multiple hundreds of genes, coupled with expression and variation information.
Conclusions
Certain individual molecules represented by genes or proteins that have been discovered by high-throughput biology experiments can serve as specific biomarkers for LDIR response in mammalian tissues, including the brain. The ultimate goal of molecular and computational systems biology is to generate objective detailed models of complex associations at the molecular level that can be correlated with the phenotypes under consideration, for health and disease management. For complex phenotypes, single-molecule patterns might indicate possible involvement of genes or proteins in a particular condition, but they might not suffice to provide the required specificity and robust validation elements for diagnosis, prognosis, and/or monitoring. We thus need to maintain a view toward a systems radiobiology approach and prepare for a phase of intense use of relevant tools and algorithms to analyze emerging large data sets. Future developments for big data analytics in radiobiology omics will require intelligent solutions and rules that establish a framework for openly sharing data resources on a large scale, akin to similar efforts. 48 Data resources such as StoreDB will have a central role to play in those efforts. 26
Despite progress on many fronts, key challenges remain. As mentioned above, we draw from brain radiobiology specifically—where difficulties are associated with the limited range of possible experiments and the analysis of animal behavior. Even if we suppose an explosion of useful data and research results, the implementation of better reporting processes can be a significant obstacle. Open science standards—first and foremost—will need to be adopted, with seamless information flow from publications and their data supplements to open data collections and databases. 49 Requirements for appropriate minimal information standards and wider community efforts should be encouraged, facilitating reproducibility and comparison across different experimental designs. 50 Finally, dedicated software platforms with some characteristics outlined above can be deployed and made available for the scientific community.
It is important to emphasize that many processes, tools, and techniques are already in a mature phase that facilitates and indeed encourages exploitation of big data approaches. Thus, systems radiobiology research teams should consider a closer association with data scientists, as the field is both amenable to and in need of high-performance computing and big data analytics. Commercial services currently offered by some of the largest cloud providers—Amazon, 51 Google, 52 IBM, 53 Microsoft 54 —are indeed simplifying future implementations of the proposed, idealized framework presented here, and similar incarnations and designs. In addition, implementation and operations will require knowledge on DevOps to be able to ensure the proper functioning of all framework modules and solicit analytical solutions for scientists on demand. These envisaged developments will necessarily have to follow progress elsewhere, in fields as diverse as radiation biology, systems biology, bioinformatics, and software engineering. For the latter, surprisingly, there is also a constant need for open science, that is, open access, data, source. 55
It is somewhat paradoxical that some of the above issues have been raised before, in the data-intensive field of genomics, in particular data integration and re-annotation, prompted years ago. 56 This is indeed encouraging, as there is vast experience that can be readily adopted, 40 in the specific case of systems radiobiology. In conclusion, we believe that the field of radiation research and safety is now entering a new big data phase, where some of the considerations above will need to be endorsed widely, for a successful future.
Footnotes
Authors' Contributions
All authors have contributed toward the generation of data, analysis of results, and writing the article; they have approved the submitted version and endorsed the submission. The funding sponsors had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the article, and in the decision to publish the results.
Acknowledgments
We thank all
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This work has been supported by the collaborative European project