
Abstract
Online analytical processing (OLAP) approach is widely used in business intelligence to cater the multidimensional queries for decades. In this era of cutting-edge technology and the internet, data generation rates have been rising exponentially. Internet of things sensors and social media platforms are some of the major contributors, leading toward the absolute data boom. Storage and speed are the crucial parameters and undoubtedly the burning issues in efficient data handling. The key idea here is to address these two challenges of big data computing in OLAP. In this article, the authors have proposed and implemented OLAP on Hadoop by Indexing (OOHI). OOHI offers a simplified multidimensional model that stores dimensions in the schema server and measures on the Hadoop cluster. Overall setup is divided into various modules, namely: data storage module (DSM), dimension encoding module (DEM), cube segmentation module, segment selection module (SSM), and block selection and process (BSAP) module. Serialization and deserialization concept applied by DSM for storage and retrieval of the data for efficient space utilization. Integer encoding adopted by DEM in dimension hierarchy is selected to escape sparsity problem in multidimensional big data. To reduce search space by chunks of the cube from the queried chunks, SSM plays an important role. Map reduce-based indexing approach and series of seek operations of BSAP module were integrated to achieve parallelism and fault tolerance. Real-time oceanography data and supermarket data sets are applied to demonstrate that OOHI model is data independent. Various test cases are designed to cover the scope of each dimension and volume of data set. Comparative results and performance analytics portray that OOHI outperforms in data storage, dice, slice, and roll-up operations compared with Hadoop based OLAP.
Introduction
Rapid expansion and digitization in almost every sector have increased the opportunities for innovation in tools and technologies. This advancement has resulted into massive amount of data growth, giving birth to big data. Social media, internet, manufacturing, finance, sensors, health care, astronomy, bioinformatics, oceanography, retail industries, and education field have witnessed enormous amount of data.1,2 Storage, management, and processing of this huge volume of data become crucial. These challenges have opened up new doors of research and invention for “big data” computation and techniques. Data warehouse and big data are the keys to the insight of business intelligence. 3 Big data capturing, storage, processing, and analysis have turned out to be very expensive. Academicians and industry experts have stepped up to make this process inexpensive and more efficient. 4 Direct beneficiaries of improved data management are the supermarket sector, banking, health care, engineering, and communications sectors. Data originating from these sources would demand efficient storage methodologies. 1 Data generated from these heterogeneous sources tend to have different formats and sizes. 5 To deliver a clear vision to end user, data warehousing works on the concept of extract, transform, and loading a variety of data, which are different in terms of type and volume at a central standard storage block, typically over a nonvolatile platform.
Manifold increase in the volume of data has led to the ever-increasing expectations of faster processing speeds. This matter has motivated the authors, toward an attempt to improvise the online analytical processing (OLAP) structure considering big data environment. Parallelism and distributed processing environment play a vital role in dealing with volume of big data. 6 OLAP over big data is a hot topic of discussion for academicians and industry experts to undertake and come up with groundbreaking results. Typical OLAP engine follows relational OLAP (ROLAP) architecture, which is highly dependent on relational database management system approach. Multidimensional OLAP (MOLAP) is the most suitable OLAP configuration for big data, as it executes on concept of multidimensional array. 4 Map reduce programming model is used to address performance challenges of distributed environment. It is a highly recommended programming model to deal with colossal scale data handling algorithms. All the alternate solutions to achieve MOLAP have used cloud-based Hadoop data warehouse systems such as HBase and HadoopDB. On the contrary, this study is targeted to present a new approach called OLAP on Hadoop using Indexing (OOHI) MOLAP system for big data.
This article aims to provide a unique approach to resolve an existing problem. It will be addressed by provisioning of faster query responses to an OLAP in multidimensional environment. Distributed environment and applied parallelism are being used to store comparatively a massive volume of data. Innovative system architecture has been proposed to deploy OLAP querying on large amount of data very quickly. Hadoop platform with map reduce programming model is deployed to ensure scalability and fault tolerance. Data loading module, data storage module (DSM), data hierarchy encoding module, cube segmentation module, segment selection module (SSM), and block selection and process (BSAP) module are major building blocks contributing toward the enhanced performance in OLAP.
The rest of the article is organized as follows. The Literature Survey section discusses the literature survey; the Proposed OOHI Model section describes proposed OOHI model, including DSM, dimension encoding module, cube segmentation module, SSM, and BSAP module. Detailed system architecture is presented in the System Architecture section. This study also demonstrates the map reduce job for OLAP process, experimental setup, data set details, and test cases with achieved results to visualize the actual output scenarios in the Implementations section.
Literature Survey
Various research articles and literature were studied to achieve following objectives followed by detail discussion on each objective.
Identification of OLAP approach on variety of big data with applications and methodologies.
Methods used for precomputation of OLAP cube and application of special data structure to boost OLAP performance.
Existing methodologies to optimize data storage.
Implementation techniques to speed up the OLAP query.
Impact of implementation platform on the performance of OLAP query.
Past 15 years of literature on data set, methodology, and applications on OLAP was studied rigorously to achieve objective 1. Research trends on OLAP for the various topics such as big data warehouse augmentation, OLAP on big data, OLAP with uncertain data, OLAP on geospatial data are popular. As per the studied literature, to achieve objective 1, variety of big data is classified as shown in Figure 1.
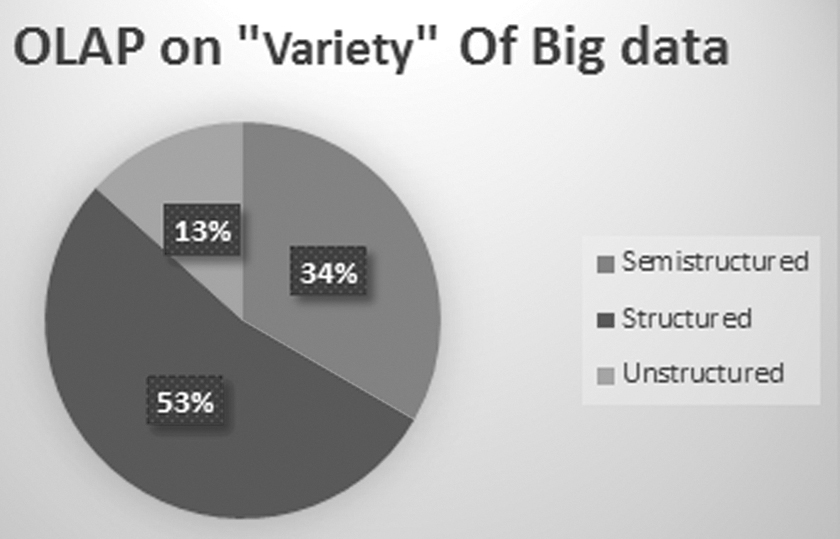
OLAP on variety of big data. OLAP, online analytical processing.
Exhaustive study of relevant technical articles was carried out to collect aforementioned details. Application-oriented literature with objectives and methodologies is summarized in Table 1. Most appropriate techniques and applications for semi-structured, structured, and unstructured data set are mentioned in detail.
Applications and methodologies for online analytical processing on variety of big data
AATM, Advanced Air Traffic Management; ASDI, Aircraft Situation Display to Industry; ASQL, Array SQL; CAN, Controller Area Network; DBLP, Digital Bibliography and Library Project; ETL, extract-transform-load; EXODuS, Exploratory OLAP over Document Stores; GPS, Global Positioning System; IAAU, International Ataturk Alatoo University; IR, Information Retrieval; LLC, sports database company; MPP, massively parallel processing; OIL; OLAP, online analytical processing; OLTP, online transactional processing; RDBMS, relational database management system; SOLAP, spatial OLAP; SPSS, Statistical Package for the Social Sciences; x-DFM, extended dimensional fact model; XML, extensible markup language.
Use of precomputation and data compression aids in the process of optimization of OLAP performance. It can be optimized through precomputation and proposed map reduce framework for query algorithm. 22 Retrieval of data cubes from Bigtable with comparison of different approaches is also described. It shows the map reduce framework and HBase implementation environment for Bigtable to handle scalability issue. 23 Genetic algorithm has been used to improve data selection. To store the data effectively, only happening cubes from all data cubes have been selected to reduce query cost. Greedy approach has been applied to optimize the storage cost, which will directly affect OLAP performance, 24 which fulfills objective 2.
Besides precomputation, data structure also support to optimize data storage. Data warehouse was built through cloud platform with the support of online transactional processing and OLAP. 22 Indexing and partitioning were the core techniques for online transactions and to provide data analytical functionality. Revolutionary work for combining OLAP and data mining is presented by Han et al. 22 The author has optimized the work of two layers with theoretical framework for OLAP and mining functions into a single entity, which greatly supports today's requirement. New data structure is designed based on the concept of short message service. Abstract model is demarcated, which is able to manage multidimensional tables and data using query algebra and advanced fact constellation schema. 14 All the above literature illustrate an impact of special data structure in process of OLAP to achieve objective 3.
Objective 4 refers to get good speed up of OLAP query exploring various platforms. Features and functionalities of Hadoop Distributed File System (HDFS) are possessed to store large volumes of data, with Structured Query Language (SQL)-based skills for analytics. 25 Combination of DBMS and map reduce has been successfully demonstrated as HadoopDB for analytical queries on OLAP. 26 MOLAP systems are very well defined on OLAP4cloud and HBaseLattice. Use of indexing approach will improve OLAP performance; OLAP4cloud work on this principal to enhance OLAP performance and to improve storage cost. Avatara is the Hadoop-based OLAP engine; with the provision of low latency and high throughput, it offers online analytic support with the managed high traffic of website. 4
Hybrid OLAP architecture is one of the key ideas to boost OLAP performance and enhance ability for adaptive computation to observe impact of platform. Hybrid OLAP deliberately designed on CPU, GPU, and memory subsystems to optimize query response times. 27 Proficient database design conceptualized on partitioning with replication designed by Lee et al. 28 Literature imparts that big data and OLAP are keys to provide better insight. Each of SQL and NoSQL should be supported for the new framework of OLAPing. Hadoop based OLAP (HaOLAP) is very well-known Hadoop development method to achieve OLAP operations such as slice, dice, roll-up, and drill-down operations. 4
Security and data quality management are also popular areas of data warehouse and OLAP. Although, a lot of research efforts have already been made in this area, only a few of them were found to be efficient and fruitful. Security is applied layer wise and at each stage in the protocol with encryption techniques. 23
Still there are hazards and scope of enhancement in the following area:
For multidimensional, heterogeneous big data, effective data storage support is required. Existing methodology can be emerged on Hadoop and Cloud Computing platforms to process data in distributed environment. Better data analytic tools can be implemented with the convergence of artificial intelligence and machine learning.
Proposed OOHI Model
This section describes proposed OOHI model with all minute details such as store, retrieve, encode, and decode all the dimensions and measures. OLAP cube is divided into fixed data size chunks. All the chunks will be processed to achieve distributed work using map reduce framework. Figure 2 shows the visualization of data in multidimensional view. 25 The division of cube into chunks to achieve parallelization is shown in Figure 3. To utilize the distributed data environment, model chunking has been used in OOHI. 4
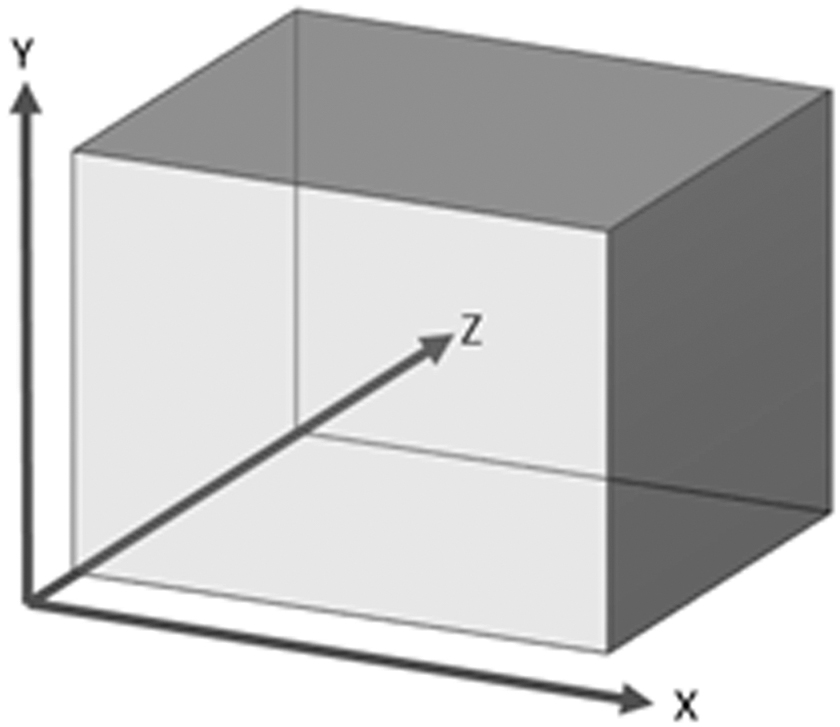
Multidimensional data cube.
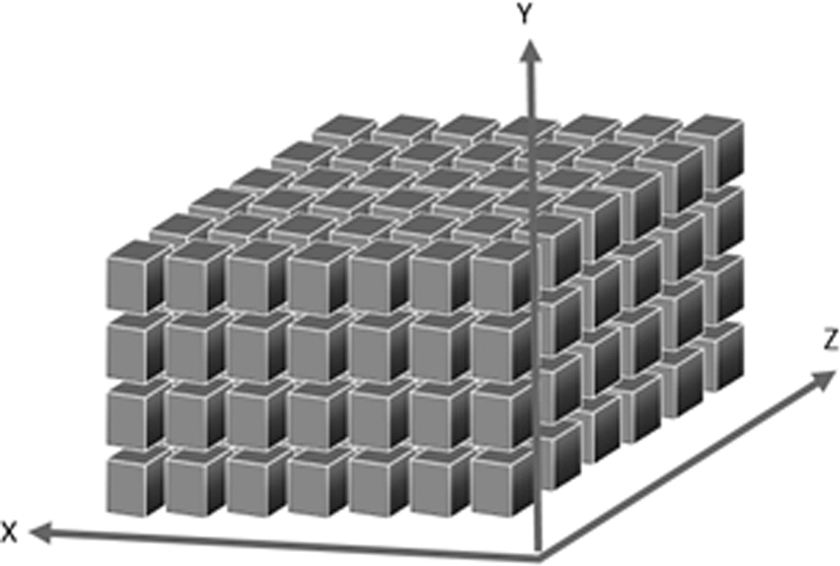
Visualization of partitioned cube.
Series of relevant modules and algorithms have been used for computation of OLAP cube. DSM offers a worthy storage technique for big data. Data encoding module has adopted integer encoding technique to encode each dimension corresponding to each level in the concept hierarchy. 8 In response to the user query, selection of only specific chunks from the whole cube is described in detail in cube segmentation and SSM. Once the set of blocks are identified by the segment selection method, it is further processed by BSAP module for slice and dice operations.
Data storage module
It is highly essential to serialize the data for reduced storage costs, required by OLAP in big data. In MOLAP, cube storage demands comparatively more space, as it uses multidimensional array. In OOHI, data have been extracted directly from the database server and stored in serialized manner, which will take key and value instead of storing n-dimensional data and its value. 26 The chunk file and the cells of block are serialized for resolution and deserialize for request-query from user. Chunk file is fundamentally the map file given to responsible mapper. Logically, cube cells and chunk files are associated with the values of multidimensional array itself; however, they are actually the map file of HDFS.
Let X be the multidimensional array of n dimensions as {D1, D2, D3, …, Dn}; coordinates of array values are denoted as {P1, P2, P3, …, Pn}, their serialization results into the index as per Equation 1. Computed index shall be considered for further processing.
Figure 4 represents the visualization of paging concept. Each of the dimension has been encoded as a page. Instead of storing the values using multidimensional array, it can be serialized as a key. Conceptually storage of data achieved through serialization and retrieval of data has been achieved through deserialization. Core functionality of the deserialization process is to calculate the coordinates of the dimensions. The procedure of deserialization is described in Equation 2:
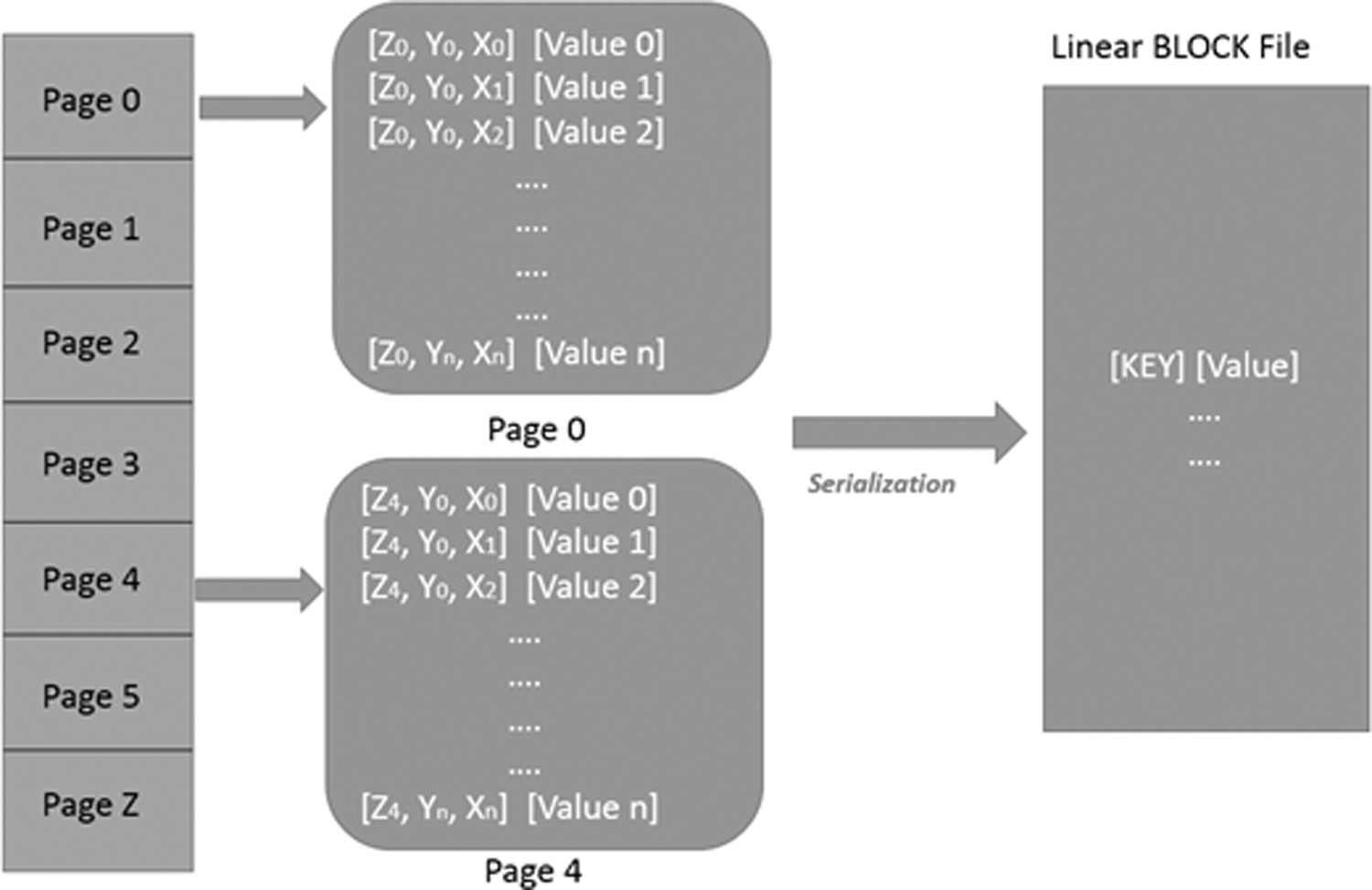
Serialization.
Dimension encoding module
Dimension hierarchy encoding is broadly classified into two categories, namely integer encoding method and binary encoding method. In binary dimension hierarchy encoding method, binary value of each level of the hierarchy is considered. 27 As shown in Figure 5, a concept hierarchy of time dimension includes year, month, and day. Each level has been represented by binary digit. Binary encoding of 31.1.1968 is 001000111111. (Binary encoding of 1968 is 001, January is 0001, and 31 is 11111). If 1.2.1968 is encoded as 001001000001 and 31.1.1968 as 001000111111, then the difference between these numbers is two (2), the difference may increase for more number of years. Disjointedness in the binary encoding leads to sparsity problem in multidimensional array.

Binary encoding of dimension hierarchy.
Integer encoding method will not break up the level-wise data. As shown in Figure 6, integer value is assigned to year, month, and day of each year in the time dimension. Although storage and retrieval of level-wise information is bit easy in binary encoding, the authors adopted integer encoding to avoid sparsity problem in multidimensional big data.
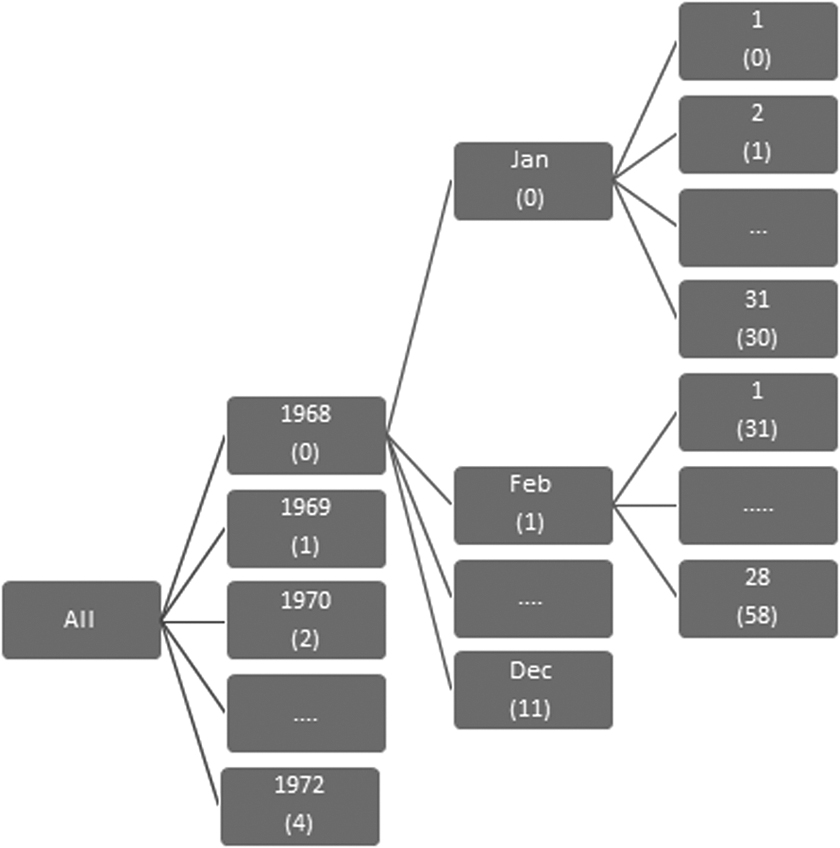
Integer encoding of dimension hierarchy.
Segment selection module
It is highly required to divide the cube into segments to process parallelly. In OOHI, the authors have applied cube segmentation method to divide whole cube into small segments. Effectually, list of chunks shall be considered as input file to map reduce program. The selection of chunk size is critical as bigger chunks will increase parallelism and smaller chunks will increase scheduling cost. It can be derived by considering all the query conditions (support) and possibility and occurrence of each condition (confidence). Considering simple random sample for all possible query conditions and map reduce features such as number of map tasks processed per second, the file addressing time and the scheduling time are as per figured out in Table 2.
Symbols used in cube segmentation
Average OLAP query execution time can be achieved by finding the average number of chunk for available dimensions for query conditions and time affected to execute map reduce task according to Equation 3. According to Equation 4, selection of average number of chunks depends on the intersection between the confidence and the probability of occurrence of query condition at dimension. Mapper task and file addressing time have been considered to find out time affected by map reduce process, according to Equation 5. If we identify the size of chunk that minimizes AVGt, then it will be the perfect chunk size.
Once the whole cube is divided into chunks, it is important to select the targeted segments for the given query to reduce the search space. In OOHI, the SSM has been used to select the targeted segments followed by BSAP. Important operation of OLAP mainly includes slice, dice, roll-up, drill-down, and pivot. Roll-up and drill-down operations are treated as an aggregation and the combination of query, whereas slice and dice operation is treated as query range operation. 28 To view the cube in altered way, pivot operation is being used. 21 In this operation, it is essential to deal with the query range. In OLAP, dimensions are queried and referred by query condition, as defined by the selected dimension. Range specifies a query range of cells in objective or the target dimension, where range is multidimensional tuple.
Let {D1, D2, D3, …, Dn} be the dimensions involving target query and an ordered pair <pi, qi>, (where pi<qi) be the given query range on dimension Di.
Then, Range R = {<pi, qi> | i ∈ [1, n]}
Let us take the range of query be <(p1, p2, p3, …, pn)>, <(q1, q2, q3, …, qn)>, so each pair from (p1, q1), (p2, q2) to (pn, qn) are the coordinator of the segment be (c1, c2, c3, …, cn) and the segment size be (y1, y2, …, yn). According to Equation 6, coordinates found match with the range would be processed by map reduce job.
Exemplification
Cube C = [372, 256, 500].
If input query is [70, 40, 50] to [170, 200, 150].
Starting point is [70/62, 40/64, 50/72] means [1, 0, 0] and end point is [170/62, 200/64, 150/72] means [2, 3, 2].
According to Equation 3; start point
As a result, we will get all the chunks having {[1, 0, 0], [1, 0, 1], [1, 0, 2], [1, 1, 0], [1, 1, 1], [1, 1, 2], ……., [2, 3, 2]}, which will be serialized as {28, 29, 30, 35, 36, 37, …….., 79}
BSAP module
HaOLAP and other existing algorithms scan each chunk to match the query and process whole chunk, 4 whereas OOHI model selects only the required chunk value and not the whole chunk. Figure 7 shows the cube after applying chunking and further processed by map reduce process to achieve parallelization. Data retrieval from the query range will select all the affected chunks from the cube, as shown in Figure 8. BSAP module contributes at this stage to process required cells only and not the whole chunk. According to Figure 8, 16 chunks are selected, but few chunks should be processed partially, half, quarter, and few of them are required to be processed whole. Seek operation has been performed on each selected chunk and processed according to BSAP module. Various seek operations to reach to a cell value are designed after rigorous calculations on OLAP cube.

Partitioned cube.

Selected chunks to process query.
The BSAP algorithm aims to pass the selected chunk data to mapper as a list of selected cell values. The iterative process provides selected input to record reader. All the existing approaches including HaOLAP check each selected chunk line by line or apply the brute force method to find the query match. BSAP will calculate the buffer size first and corresponding seek operations will be applied as described in Table 3. The pointer has to reach to a cell of chunk required by user query by previously mentioned modules. Once pointer has reached to the end coordinate, program will start reading information or the values till the pointer reaches to the end. After deliberate calculations on each position of cells in the chunk and in the block, many important equations and variables are presented, as shown in Table 3.
Naming conventions used in block selection and process
Algorithm: BSAP
Input: User Input: QSi to QEi, File Input: SSi to SEi
BSAP algorithm
seek_Block(Fseek)
For i = 0 to |Z′|
For j = 0 to |Y′|
a. seek_Block(Bseek)
b. read_Block(Block_data)
c. Block_data = [block_end * element size – block_start +1],
. Block_start = Max (QSx, SSx), Block_end = Min (QEx, SEx)
d. skip_Block(Aseek)
End for
skip_block(Nseek)
End for
For the multidimensional query start and query end, tuples are notified by the symbols QSi and QEi. After applying segmentation on cube, OLAP is divided into the fixed size segments. So, each segment start and end tuple are described by the variables SSi and SEi as generated by cube segmentation module. Here, i represents the dimensions used for multidimensional query. When query start/end value is more than segment start/end, then the whole segment have been selected. Every precondition is examined for selected chunks of the cube, and it is represented in Table 4.
Symbols with equations used in block selection and process
First seek operation can be used for skipping all the cells to reach the first cell value as asked by the user. Here, slice operation indicates two-dimensional operation. Seek to next slice is required to reach the next slice, before seek is used to reach the target block. Once required cells are gathered and sent to the mapper for aggregation, seek operation is performed to skip all the rest of elements from the blocks. Exemplification and algorithm have been mentioned for three dimensions. The BSAP algorithm is standardized according to multidimensions. Each operation used in the BSAP algorithm is clearly mentioned in Table 3. The authors have presented the BSAP algorithm for n dimensions and we have exemplified it for three dimensions.
Logical conditions to apply seek operations are mainly (1) P′ = total elements in x direction and (2) P″ = total elements in y direction.
System Architecture
In this section, the authors have described importance and configuration of OOHI system architecture. Shared disk, shared memory, and shared nothing architecture are the keys to develop big data solution. To provide good scalability with the commodity machines, the authors have selected shared nothing architecture. 29 To ensure the parallelism and distributed environment, Hadoop framework with map reduce programming model has been chosen. OOHI includes mainly three components as job server, schema server, and Hadoop cluster.
As shown in Figure 9, OOHI architecture contains a separate processing module for the database collection. Extract-transform-load process will be performed on data sources. Separate code was written for extracting raw data and to store the metadata. Input data are in the parse-able format. Cube schema, dimension, and cube metadata are stored in schema server to verify the validity of the queried data and to reduce the cost of searching unavailable data. All the measures associated with dimensions are stored in Hadoop cluster. When end user or OLAP client fire a query for slice operation, the application node will run a map reduce job to find the match criteria and to assign the asked operation. Detailed role of each component is as follows:
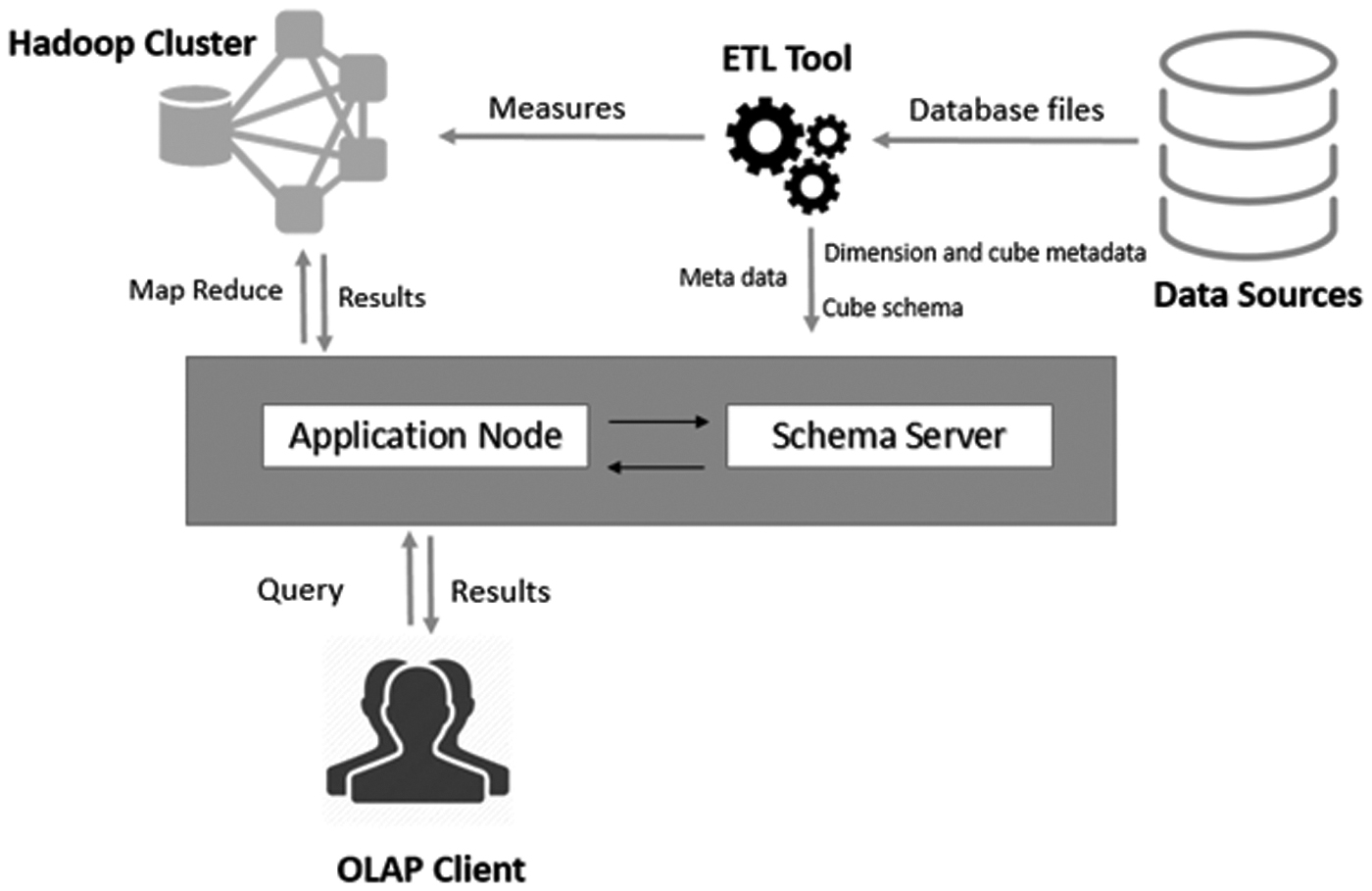
System architecture. ETL, extract-transform-load.
Job server: Application node is also known as job server. It is the heart of the whole system as it processes OLAP commands fired by user, check for the validity of the command and available resources, call suitable node of Hadoop cluster to process and send processed output to the client. Job server first validates the input with the support of schema server by checking the available metadata and dimensions. With the ensurity from the schema server, job server invoke a command to start map reduce process on Hadoop cluster. Meanwhile map reduce job running on Hadoop cluster, job server observe the progress of the process. Once the job is accomplished by the map reduce job, job server gather the metadata of the cube to generate the resultant cube.
Schema server: Schema server is responsible for storing and maintaining metadata. Both metadata for cube and dimensions are stored in XML format. Dimension's metadata includes number of dimensions and levels of each dimension. Cube metadata includes the path, file structures, and identifiers. Schema server is answerable for all the queries coming from job server.
Hadoop cluster: All the measures are deposited in Hadoop cluster. It looks after all the map reduce instance and the distributed environment by HDFS. The queries submitted by the job server will be run by Hadoop cluster. Initially, data loading map reduce job is run to load measures to Hadoop environment and to keep metadata to schema server. Data loading is one time job and thereafter whenever job request comes from the job node, Hadoop cluster will process it according to dimension encoding technique, dimension traversal technique, cube segmentation, chunk selection, and BSAP methodology mentioned in previous sections.
Implementations
In this section, the authors have described execution processes of aforementioned algorithms. That includes map reduce job explanation with comprehensive flowchart, experimental setup, and test cases with results in depth as follows:
Detailed job for OLAP process (see the Map Reduce Job for OLAP Process section)
Master–slave configuration, experimental setup, and data set description (see the Experimental Setup section)
Design of test cases including data storage, dice, slice, and roll-up operation queries and results (see the Test Cases and Results section)
Map reduce job for OLAP process
Data loading, data storage, and OLAP process described in earlier sections are designed as per map reduce framework. Figure 10 depicts the map reduce job for OLAP process described as follows:
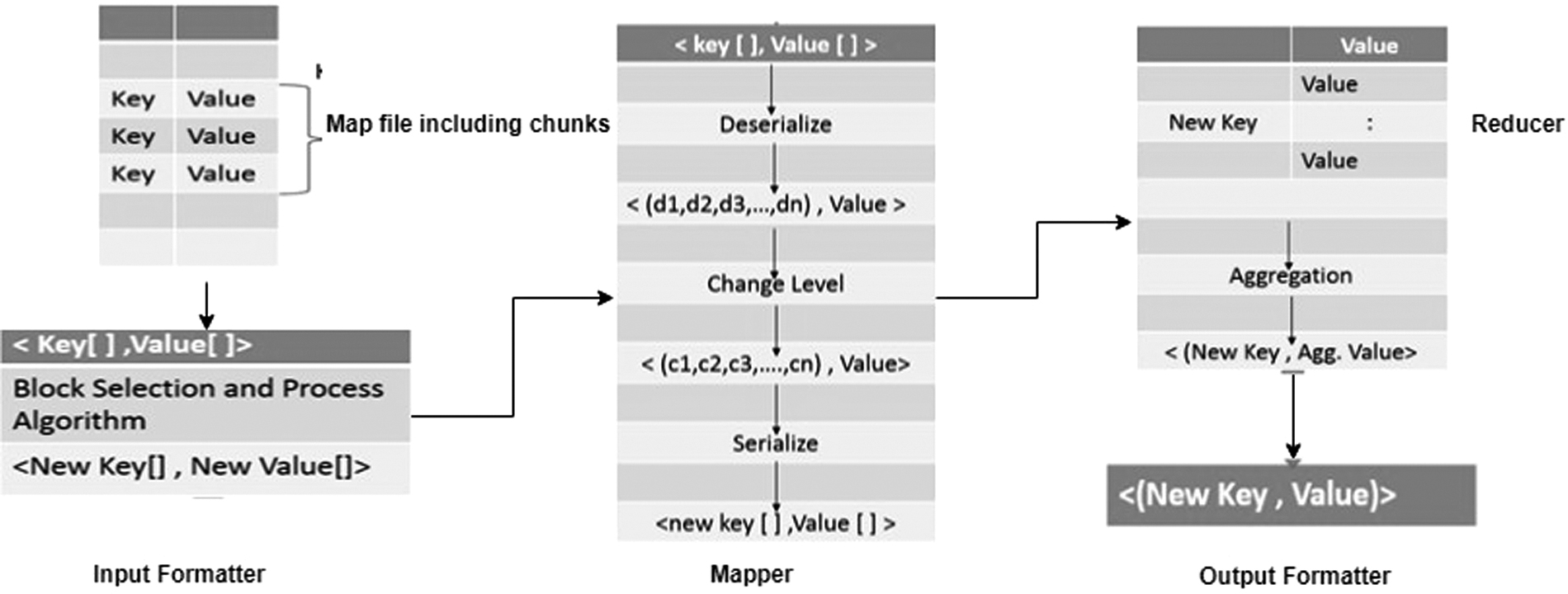
Map reduce job to perform OLAP process.
Data loading implementation involves two phases. The first phase loads data to HDFS and second phase generates chunk files through map reduce process. Every map reduce job consists of four components, namely input formatter, mapper, reducer, and output formatter. 30 Input formatter takes the raw data and applies the parsing logic to separate measures of dimensions, levels of dimensions, and metadata. Note that the original data files loaded into HDFS is in the XML format. Mapper work on the each sentence; line number and the value, referred as <key, value>. Furthermore, obtained <key, value> pair is serialized according to DSM. New key as index is generated and passed to the reducer. Reducer is responsible for sorting and shuffling the available data.
After the completion of the data loading process, OLAP process kicks in. Generated chunk files are processed by map reduce job to perform OLAP process. First, the query quadruple has been submitted by client and then processed to verify deterministic failures. As shown in Figure 10, input formatter takes data from SSM as a chunk file. Each coordinator of the cell is deserialized according to Equation 2. After deserialization, value will be associated with each coordinate and verified by each query condition. If all coordinates of the cell have been found to match with query condition, then it is serialized again and passed to mapper. The unmatched cell coordinates would be removed from the database. <M_Key_in, M_Value_in> is the input key value pair for the mapper and <M_Key_out, M_Value_out> is the output key value pair for the mapper. Similarly, reducer deals with <R_Key_in, R_Value_in>, as input key value pair and output as <R_Key_out, R_Value_out> key value pair. As a part of input formatter, record reader processes set of serialized cells and values. Once BSAP module finalizes the list of chunks, it passes the array of chunks to mapper. Unlike HaOLAP algorithm, in OOHI array of the chunks are processed to seek an intended position of cell rather than searching whole chunks to identify the cell position using BSAP. Main objective of the mapper for the whole process is to change the level according to the concept hierarchy of the dimensions.
To change the level of dimension coordinates of the cells are required, so mapper performs the deserialization of the obtained <M_Key_in, M_Value_in>, where each key value pair is deserialize in its original coordinate values mentioned as <d1, d2, …, dn, value>. According to the passed query, level of dimension has been changed to match the query. Obtained changed dimensions have been serialized again to perform aggregation by reducer. Now mapper generates new key value pair as <M_Key_out, M_Value_out> that generates serialized coordinates for the new key produced by changed level. Reducer start processing with key value pair as <R_Key_in, R_Value_in>. Furthermore, it also applies aggregation on obtained values for the key and aggregated value that would be assigned to the key. <R_Key_out, R_Value_out> is the output of reducer and it is located as new chunk file into mapper. R_Key_out remain unchanged throughout process of reducer. 28
Experimental setup
Execution of OOHI has been carried out on three node set up by commodity computers of 64 bit operating system having 8 GB RAM, windows 10, core i5 CPU, 120 GB hard disk (built in), and extra 1 TB hard disk. One of node in cluster worked as Hadoop master and rest of the two nodes worked as Hadoop slave. Competitors for the comparison of OOHI model have been selected based on parallel processing ground and map reduce programming framework. It is the most suitable architecture for big data processing. 11 OLAP implementations include either ROLAP or MOLAP. In the proposed model, we adopted MOLAP. Hence, MOLAP, Hadoop, and map reduce framework motivated us to select HaOLAP as competitor of OOHI. HaOLAP is the well-known approach aiming for improvement in storage cost and effective query performance. It is already been compared with all the advanced data warehouse solutions such as Hive, HBaseLattice, OLAP4cloud, and HadoopDB. HaOLAP have been proved as the better approach. 4 Source code of HaOLAP is available on https://github.com/MarcGuo/HaoLap website and source code of OOHI implementation is available on https://github.com/Jigna-Nirma/OOHI website.
We used oceanography data from Intergovernmental Oceanographic commission of UNESCO (IODE international oceanographic data and information exchange). We downloaded 11 years of data and total 900 files total size of database is 10 GB. From the XML files, we dig out three-dimensional data as follows:
Three dimensions (T, A, D) where T represents Time, A represents Area, and D represents Depth.
T has 5 levels, which are Year, Season, Month, Day, and Slot. Slot refers to morning, afternoon, and evening of a day.
A has 7 levels, which are 1°, 1/2°, 1/4°, 1/8°, 1/16°, 1/32°, and 1/64°. 1° quadrangular is the area whose length of side is 1° of the longitude and the latitude. The earth could be divided into 360 × 180 1° squares and 4 × 360 × 180 1/2° squares and so on.
D has 3 levels, which are 100, 50, and 10 m. One hundred meters of layer represents the depth of ocean, which is separated per 100 m.
Although type of application does not affect the performance of OOHI, it has been tested on oceanographic data and online shopping data. Results of both the data sets are similar, and hence, we have not included the online shopping results. The alterations between the applications from various domains mainly contain the volume of the dimension values and the sparsity of measures. The whys and wherefores we consider the territory of application do not affect the performance of OOHI are as given below:
OOHI has been implemented on map reduce programming framework. Massive amount and variety of dimensions can be handled by map reduce framework.
In OOHI, the mapping of measures and dimensions can be achieved by computing the complexity of traversing dimension and it is O(1). Hence, amount of dimension does not affect the performance of roll-up, dice, and slice in OOHI.
OOHI does not store the measure whose value is NULL. Thus, OOHI avoids the sparsity of measures.
Test cases and results
Test cases are designed to cover scope of all the three dimensions of our data set. The size of data set is presented as Si (1 ≤ i ≤ 3), as shown in Table 5. Experiments have been divided into three different subsets of original data set. Dimension selection in the experiment plays very critical role. To visualize the volume impact of OOHI, we worked with the data set range from 106 to 108, resulting into 5 million data elements to 160 million data elements, as shown in Table 5.
Oceanography data subset description
Data storage, dice, slice, and roll-up operations queries have been described, as shown in Table 6. As far as dice experiment is concerned, we designed C1, C2, and C3 as cube operations. Each of the dice operation performed on data set described in aforementioned oceanography data subset description. SQL type query is mentioned for OLAP operations. We performed experiment on each SiCj (1 ≤ i, j ≤ 3) and observed query performance time in seconds. Selection of query is important in test cases, and hence, all the dimensions are covered in cube queries. We designed the combination of time, area; time, depth; area, depth in queries C1, C2, and C3 accordingly. Basically, nine test cases are designed for each experiment. In the slice operation, we designed SL1, SL2, and SL3 as slice operations. Like dice operation, slice operation parameters also have been executed as SiSLj. Logically slice operation involves operation on one dimension, and other two dimensions have been kept as it is. Table 6 shows variations of slice operation queries on time, area, and depth as SL1, SL2, and SL3, respectively. Roll-up operation R1, R2, and R3 are executed on data set S1, S2, and S3 correspondingly. It massively depend on aggregation function, so we kept the queries of roll-up as similar to dice only the level on dimension hierarchy gets updated. Comprehension of each operation has been described in following sections.
Data cube/data slice/data roll-up parameters and query
By Default [SELECT * ] will select least level of that dimension, that is, [time.day] OR [depth.1m] OR [area.OneSixtyfour].
Data storage
Concept of MOLAP requires to store multidimensional array and the values. In the proposed model, for big data, we adopted MOLAP where we must store elements through multidimensional arrays. According to the state-of-the-art technique discussed in the Data Storage Module section, we used indexing approach rather than multidimensional arrays to store dimensions and measures. Figure 11 and Table 7 depict that dimension-level storage of HaOLAP over indexing in OOHI requires double storage space. It proves that data storage cost of proposed model became half than baseline approach by applying the concept of dimension encoding method, serialization, and deserialization. Also, in OOHI model to improve data storage, we used binary format to store index as key and value as an element. HaOLAP stores metadata and dimension hierarchy with level-wise information used in dimension traversal for further processing.
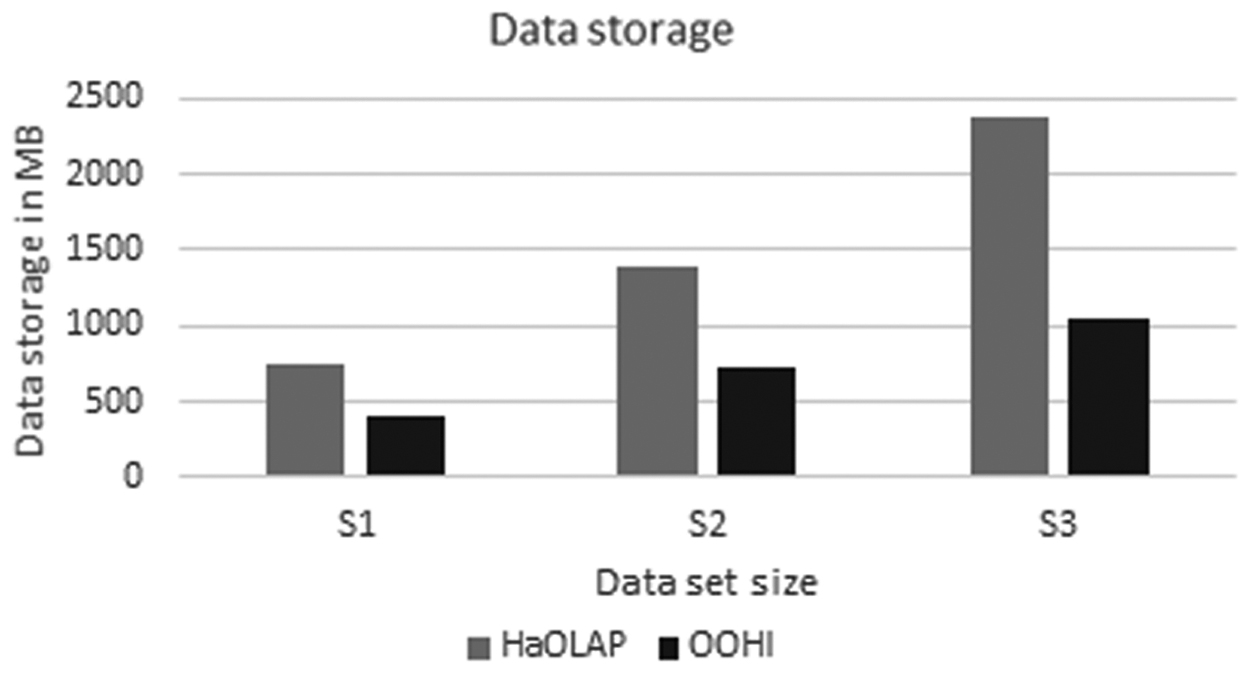
Data storage comparison. HaOLAP, Hadoop based OLAP.
Data subset size description
HaOLAP, Hadoop based OLAP; OOHI, OLAP on Hadoop by Indexing.
Dice operation
In dice operation, proposed model has been using segmentation equations and segment selection method as described in the System Architecture section. Also, the BSAP algorithm is applied to reduce the search space in selected chunks. Segmentation is the most effective solution to work with distributed environment and parallel processing, but the selection of segment/chunk size is critical as larger chunks will rise parallelism and smaller chunks will rise scheduling cost. As per Equation 3, chunk size has been decided with the consideration of given query conditions, average map reduce execution time, and file addressing time. We calculated chunk size as 82, 168, and 252 for queries C1, C2, and C3 respectively. OOHI worked onto targeted elements of the chunk and not to the whole chunk, whereas HAOLAP worked on the whole chunk. Brute force technique of HaOLAP resultant into more time consumption in dice operation, as shown in Figure 12a–d. Performance of the OOHI increases as per aforementioned figures, when the amount of elements and data increases. Also, Figure 12d shows the performance of OOHI is 2 × faster than HaOLAP with increase in volume. Table 8 depicts the result of HaOLAP and OOHI with the application of cube queries C1, C2, and C3 on data subset S1, S2, and S3, respectively. We summarized overall performance of dice operation of HaOLAP and OOHI in Figure 12d. Figure 12a–c shows the query comparison of C1, C2, and C3 having different dimensions, levels, and hierarchies comparison on data subset S1, S2, and S3. Query processing time reduction is proportional to performance. Performance analysis comparison of both the methods portray that OOHI performs ∼2.6 times better than HaOLAP. †
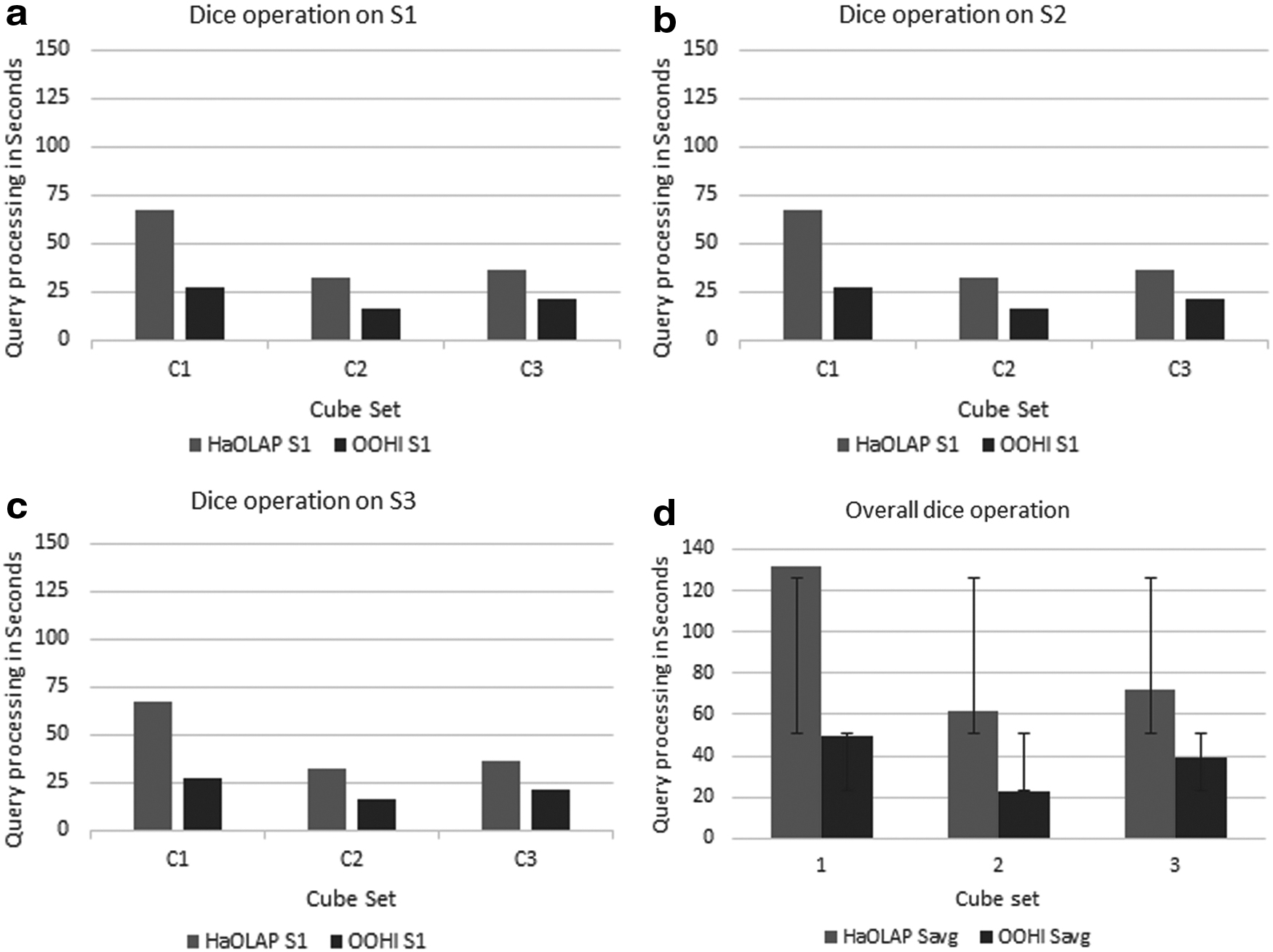
Dice performance
Slice operation
In the slice operation, OOHI performance is better than HaOLAP as shown in Figure 13d with resultant values shown in Table 9. Slice operation works with two dimensions, as per slice queries in aforementioned Table 6. All the dimensions are covered in all three queries and applied on data subset Si. Figure 13a shows the query on X direction and fetches the data as per block seek operation mentioned in the BSAP algorithm. Similarly, Figure 13b having query on Y direction and slice seek operation on BSAP is used to fetch elements from the selected chunk. Likewise, Figure 13c shows query on Z direction and corresponding operation is dice seek from the BSAP algorithm. Figure 13e shows the overall performance of slice operation with the increase in volume. It also compares the performance of OOHI and HaOLAP with big data involvement. HaOLAP lacks in chunk processing while reduction of search space and use of seek operations by BSAP and chunk selection criteria are the keys to have better performance. OOHI performs ∼1.36 times better than HaOLAP. †
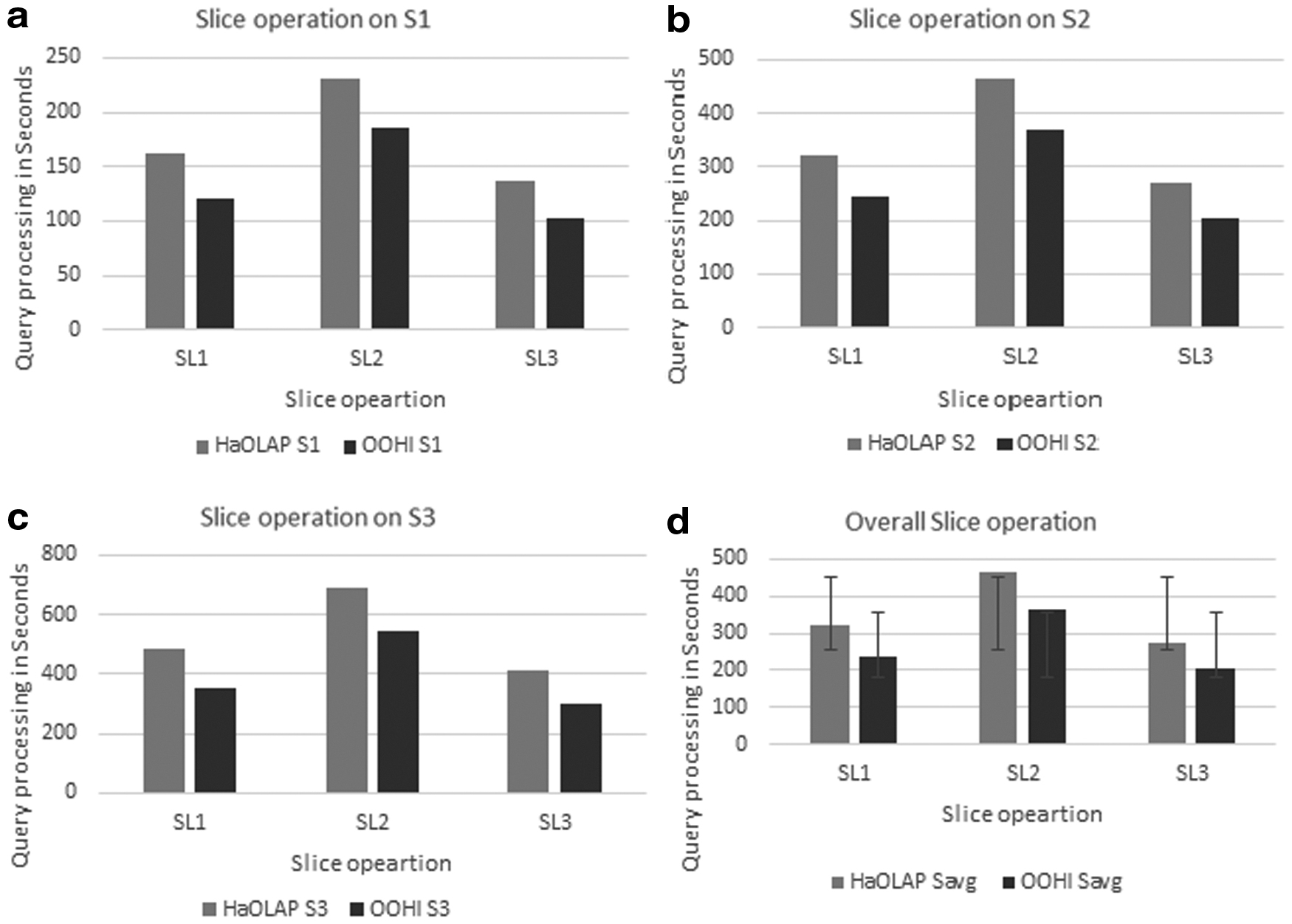
Slice performance
Roll-up operation
Roll-up operation queries represent the aggregation operation on dice queries. Time consumption of roll-up operation considering all the cases is presented in Figure 14d. The authors have displayed tendency of both methods in Figure 14a–c, with corresponding resultant values in Table 10. Roll-up operation basically involves aggregation on the resultant data that is obtained from the required level of dimension hierarchy. HaOLAP performs local operation on resultant data, whereas OOHI performs aggregation function as a result of reducer of BSAP module and that increase the query performance. Overall performance of roll-up operation is figured out in Figure 14d, which clearly shows that OOHI performs ∼2.8 times better than HaOLAP. †
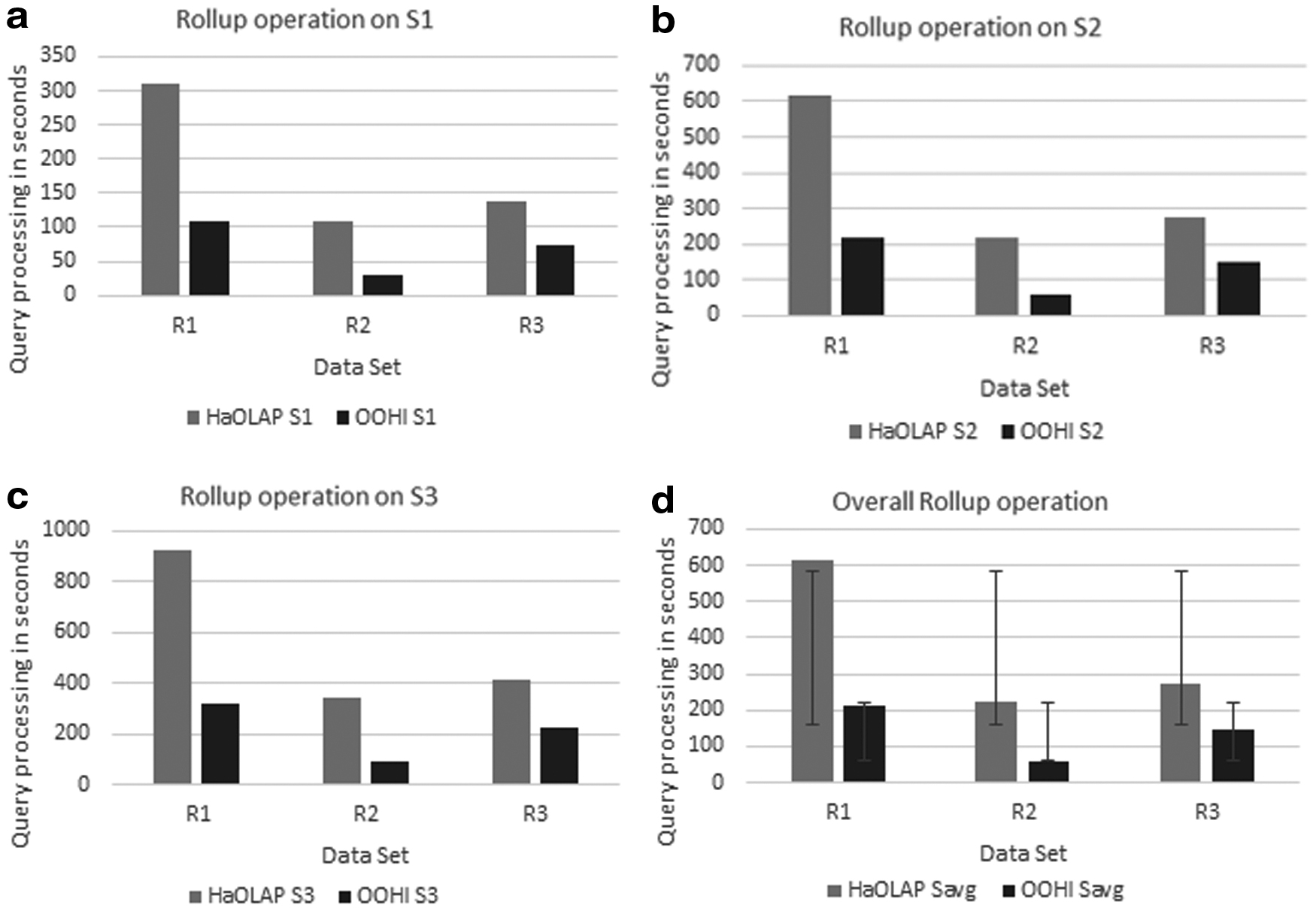
Roll-up performance
Overall performance of both the methods is displayed in Figure 15. Roll-up and dice query performances are 2 × faster in OOHI. Queries are designed in such a way that includes all the dimensions and different combinations of chunk size. Average query performance on each data subset is shown in Figure 15. Dimension encoding and chunking algorithm of HaOLAP are better than OLAP4cloud, HBaseLattice, and HadoopDB but lacking in brute force methods to get elements from the chunks. But, simplified dimension, indexing, chunking, and BSAP are the significant factors that affected OOHI in the slice performance.

Overall comparison. OOHI, OLAP on Hadoop by Indexing.
It is perceived from the results that our proposed model OOHI significantly outperformed the state-of-the-art baseline method HaOLAP and the improvement is statistical significant at p ≤ 0.05 by applying t-test. Here, p-value is obtained from t-test with paired two samples for means, as shown in Table 11. It also justifies and explains the efficient performance of our proposed model.
p-Value presentation
Conclusions
We have presented OOHI model to design, implement, and evaluate OLAP over multidimensional data. To achieve efficient storage utilization and reduced query response time, the authors have implemented (1) integer encoding method for dimensions of the cube in concept hierarchy, (2) serialization/deserialization to store and retrieval of measures, (3) segmentation and segment selection methods to choose appropriate chunk size, and (4) BSAP to reduce search space for queried search. All algorithms and techniques have been implemented through map reduce programming paradigm combined with Hadoop framework. Design of test case series helped us to compare results with baseline approach. Each method has been evaluated through nine test cases including every scenario. In test cases and experiment sections, we compared the performance of data storage, slice, dice, and roll-up on the proposed model and baseline model. We derived that data storage cost of OOHI is half of the HaOLAP. Also in slice (∼1.34 times), dice (∼2.6 times), and in roll-up (∼2.8 times), our proposed model has achieved better performance compared with HaOLAP. This study shows the MOLAP implementation on big data. Inclusion of semi-structured and unstructured data in OLAP would be the future scope of the proposed model. 31 In the future, more operations can be explored with the same model and existing results can be optimized. Furthermore, we can apply latest distributed platform to take advantage over map reduce framework to deal with volume of big data. 32
Footnotes
Biographies
J.A.P. is working as an Assistant Professor in the Computer Science and Engineering Department at the Institute of Technology, Nirma University. She has completed PhD in area of big data warehousing. Her field of interest and research is big data warehousing, theory of computation, big data analytics, and data mining. P.S. is currently working as Professor (IT) and Director (Research and Development) at Raksha Shakti University. She is having total of 20+ years of experience in teaching, admin, and research at PG level. Her area of interest is cyber security and machine learning.
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.