
Abstract
Physics-based simulations are often used to model and understand complex physical systems in domains such as fluid dynamics. Such simulations, although used frequently, often suffer from inaccurate or incomplete representations either due to their high computational costs or due to lack of complete physical knowledge of the system. In such situations, it is useful to employ machine learning (ML) to fill the gap by learning a model of the complex physical process directly from simulation data. However, as data generation through simulations is costly, we need to develop models being cognizant of data paucity issues. In such scenarios, it is helpful if the rich physical knowledge of the application domain is incorporated in the architectural design of ML models. We can also use information from physics-based simulations to guide the learning process using aggregate supervision to favorably constrain the learning process. In this article, we propose PhyNet, a deep learning model using physics-guided structural priors and physics-guided aggregate supervision for modeling the drag forces acting on each particle in a computational fluid dynamics–discrete element method. We conduct extensive experiments in the context of drag force prediction and showcase the usefulness of including physics knowledge in our deep learning formulation. PhyNet has been compared with several state-of-the-art models and achieves a significant performance improvement of 7.09% on average. The source code has been made available * .
Introduction
Machine learning (ML) is ubiquitous in several disciplines today, and with its growing reach, learning models are continuously exposed to new challenges and paradigms. In many applications, ML models are treated as black boxes. In such contexts, the learning model is trained in a manner completely agnostic to the rich corpus of physical knowledge underlying the process being modeled. This domain-agnostic training might lead to many unintended consequences such as the model learning spurious relationships between input variables or models learning representations that are not easily verifiable as being consistent with the accepted physical understanding of the process being modeled. Moreover, in many scientific disciplines, generating training data might be extremely costly due to the nature of the data generation or collection process.
To be used across many scientific applications, it is important for ML models to leverage the rich physical knowledge in scientific disciplines to fill the void due to data paucity and be able to learn good process representations in the context of limited data. This makes the model less expensive to train as well as more interpretable due to the ability to verify whether the learned representation is consistent with existing domain knowledge.
In this article, we present PhyNet and attempt to bridge the gap between physics-based models and ML models by incorporating domain knowledge in the design and learning of ML models. Specifically, we present three ways for incorporating domain knowledge in neural networks: (1) physics-guided design of neural network architectures, (2) learning with auxiliary tasks involving physical intermediate variables, and (3) physics-guided aggregate supervision of neural network training. Our PhyNet model leverages prior physics theory to learn better representations of the drag forces affecting different particles in assemblies. Specifically, PhyNet has a physics-aware neural network architecture, designed to allow each layer in the network to learn one of the various physical properties that interact to produce the drag force on a particle. This physics-informed architecture design follows a sequential pattern wherein representations learned in earlier layers can be considered to correspond to physical phenomena, which have a direct effect on physical phenomena learned in the deeper layers. Such a sequential nature allows the system to learn physically consistent representations. In addition to the novel architecture design, we also introduce aggregate supervision, that is, we introduce physics-aware statistical constraints during model training to encourage the learning of more physically consistent representations of complex multimodal distributions such as pressure and velocity field values in the vicinity of each particle in the assembly.
Simulations in computational fluid dynamics (CFD) are expensive to perform, and hence, generating a large amount of data for training ML models is impractical. Hence, one of our primary goals in the article was to develop a physics-guided ML model that is able to perform effectively under data paucity. The physics-informed nature of the model also helps improve the explainability of the result and allows physics domain experts to verify the consistency model predictions with prior physics knowledge. We showcase this improved explainability of PhyNet through extensive experiments in the article. This article is an extension of our previous work accepted at SDM 20203 where we introduced the idea of PhyNet and presented some preliminary results showing its efficacy.
In this work, we build upon our previous work and introduce several improvements in the technical description of the problem statement and our proposed approach, conceptual modifications in PhyNet to improve its generalization performance, and extensive addition of experimental results to analyze the importance of various components of PhyNet aimed at incorporating physics in ML. Here is a summary of the main contributions of our article:
We extend the novel state-of-the-art PhyNet model and improve its representative capacity to model more granular pressure and velocity fields. This is described in the Proposed PhyNet Framework section and in the Data set Description section. We perform novel experiments to demonstrate the ability of PhyNet to interpolate (see results in the Physics-Guided Auxiliary Task Selection section, the Physics-Guided Learning Architecture section, the Performance with Limited Data section, and the Characterizing PhyNet Performance for Different (Re, ) Settings section) and to extrapolate to unseen particle assemblies (see results in the Effect of Neighborhood Size and Extrapolation to Unseen Assemblies section) and compare model performance of PhyNet to state-of-the-art baselines. We characterize the model performance of PhyNet with increase in granularity of sampled pressure and velocity fields and also the effect of change in particle neighborhood size on the model performance of PhyNet, as described in the Effect of Pressure and Velocity Sampling Methodology section and in the Effect of Neighborhood Size and Extrapolation to Unseen Assemblies section. We have developed a sampling procedure for pressure and velocity field sampling around the vicinity of a particle (see the Pressure and Velocity Field Sampling Methodology section). This procedure obeys the periodic boundary conditions that are an inherent property of the simulation domain. This updated sampling procedure allows sampling with increased granularity of the sampled fields used for PhyNet model training. We have also included a detailed description of the particle-resolved simulation (PRS) process in the Multiphase Fluid-Particle Systems section. Finally, we conduct extensive experimentation to uncover several useful properties of our model in settings with limited data and showcase that PhyNet is consistent with existing physics knowledge about factors influencing drag force over a particle, thus yielding greater model interpretability (see the Verifying Consistency with Domain Knowledge section).
The remainder of this article is organized as follows. The Related Work section describes related work at the intersection of physics and ML. The Multiphase Fluid-Particle Systems section provides the relevant background on the target application of multiphase fluid-particle systems. The Proposed PhyNet Framework section presents our problem formulation and our proposed PhyNet model. The Data set Description section describes details of the approach used for data generation (further details about the data generation process are provided in He et al., 1 He et al. 2 ). The Experimental Results section presents our experimental results while the Conclusion section presents concluding remarks.
Related Work
There have been multiple efforts to leverage domain knowledge in the context of increasing the performance of data-driven or statistical models, with the help of physically based priors in probabilistic frameworks,4–6 regularization terms in statistical models,7,8 constraints in optimization methods,9,10 and rules in expert systems.11,12 In a recent line of research, new types of deep learning models have been proposed (e.g., ODEnet 13 and RKnet 14 ) by treating sequential deep learning models such as residual networks and recurrent neural networks as discrete approximations of ordinary differential equations (ODEs).
In Karpatne et al., 15 the authors explored the idea of incorporating domain knowledge directly as a regularizer in neural networks to influence training and showed better generalization performance. Abu-Mostafa showed hints, that is, prior knowledge can be incorporated into learning-from-example paradigm. 12 In Ren et al. 16 and Stewart and Ermon, 17 domain knowledge was incorporated into a customized loss function for weak supervision that relies on no training labels. In a related line of work, physics-informed neural network18,19 provides a neat idea of how we can train a neural network that follows given partial differential equation constraints. The use of physics-based loss functions to capture monotonic constraints was explored in Karpatne et al. 20 and Muralidhar et al., 21 whereas Jia et al. 22 included physics-based loss terms to incorporate the principle of energy conservation.
In addition to manipulating loss function, there have been efforts to incorporate prior knowledge into model architecture design, for example, a low rank structure as structural prior was used to design the convolutional filters in the study of Ioannou. 23 In Anderson et al., 24 the authors proposed a neural network model where each neuron learns “laws” similar to physics laws applied to learn the behavior of complex many-body physical systems. In Kondor and Trivedi, 25 the authors proposed a theory that details how to design neural network architectures for data with nontrivial symmetries. The most direct way of using physics priors is explicitly incorporating knowledge as constraints. 26 However, in real-world settings where the physics of the problem is not available as closed-form equations, such as the problem discussed in this work, it is necessary to incorporate implicit physical rules 27 to enable learning representations consistent with physics laws, for example, feature invariance. 28 However, none of these efforts are directly applicable to encode the physical relationships we are interested in modeling in our target problem of drag force prediction, where the relationship between the input variables (neighborhood of particles around a target particle) and the output variable (drag force experienced by the particle) is not explicitly available in the form of a closed-form physical equation.
Multiphase Fluid-Particle Systems
Multiphase fluid-particle systems play a critical role in propulsion, energy, pharmaceutical, food processing, and environmental applications. Particles take the form of solid or liquid fuel droplets in combustion systems, biomass particles in fluidized bed reactors, catalytic agents or ore particles in chemical processing, pill processing in pharmaceuticals, sediment in river beds, and dust, toxins and pollutants in the atmosphere, to give a few examples. Methods for simulating dense fluid-particle mixtures range from extreme high-fidelity fine-grained simulations where only a few thousand particles 29 can be realistically simulated to coarse-grained methods where billions of particles are simulated in the system, 30 but with an accompanying loss in accuracy.
In high-fidelity PRS, each particle defined by its shape is resolved in the calculation as an independent entity. As a result, the flow and pressure fields resulting from the presence of the particle are directly available from the simulation. However, PRS is quite expensive, and only a few 100s or at most 1000s of particles can be resolved in a calculation utilizing grids of O(
One of the critical interaction forces in fluid-particulate systems that has a large bearing on the dynamics of the system is the drag force applied by the fluid on the particles and vice versa. 31 The drag force, which results from fluid forces acting on the surface of the particle, can be calculated from PRS with high accuracy. Since the velocity and pressure fields surrounding each particle are available in PRS, the resulting drag force on each particle in the suspension can be calculated directly without any approximations. However, this is not the case in coarse-grained models such as DEM and TFM, in which the drag force has to be approximated via models. This is because the particle is not resolved but represented by a point mass proxy in DEM and a continuous medium in TFM. As a consequence, the fluid pressure and velocity fields are only resolved on a scale that is much larger than the particle diameter.
For an isolated, single spherical particle placed in a flow, the drag force acting on the particle is a function of the approach velocity (U), the diameter of the particle (D), density
A typical application of the drag model in a DEM or TFM calculation would calculate the single particle drag based on local Reynolds number and then modify the value based on the local solid fraction to estimate the mean drag on a particle in suspension.32–34 Using the mean drag force based on the local Reynolds number and solid fraction is the current state-of-the-art. However, the mean drag is only a zeroth order approximation of the actual drag acting on a particle in suspension.
Given the variability of drag force on individual particles in suspension, this article explores techniques in physics-guided ML to advance the current state-of-the-art for drag force prediction in CFD-DEM by learning from a small amount of PRS data. The PRS are performed using the immersed boundary method (IBM)
35
implemented in a multiblock parallel framework of an in-house CFD software.36,37 In the IBM instead of having the volume grid conform to each resolved particle, the grid is nonconformal with the surfaces of the particles. Instead a volume Cartesian grid is used at a fine resolution ( of particle diameter) and the randomly distributed particles are immersed in the volume grid. The surface of each sphere is defined by 4168 triangular elements. The number of spherical particles in the domain range from 191 to 669 for solid fractions ranging from 0.1 to 0.35 (0.1, 0.2, 0.3, and 0.35), respectively. For each solid fraction, Re = 10, 50, 100, and 200 are calculated, which are in the intermediate regimen between Stokes flow and inertial flow. Three different random arrangements are simulated for each solid fraction and Reynolds number with each particle arrangement consisting of 7260 spherical particles.
of particle diameter) and the randomly distributed particles are immersed in the volume grid. The surface of each sphere is defined by 4168 triangular elements. The number of spherical particles in the domain range from 191 to 669 for solid fractions ranging from 0.1 to 0.35 (0.1, 0.2, 0.3, and 0.35), respectively. For each solid fraction, Re = 10, 50, 100, and 200 are calculated, which are in the intermediate regimen between Stokes flow and inertial flow. Three different random arrangements are simulated for each solid fraction and Reynolds number with each particle arrangement consisting of 7260 spherical particles.
The PRS calculations are conducted in a fully periodic cubic domain simulating an unbounded or infinite suspension with flow in the x direction. A representative particle suspension is shown in Figure 2. The incompressible constant property mass and momentum conservation (Navier–Stokes) equations are solved using a finite volume procedure. Since the volume grid and particle surface grid are completely independent of each other, a special procedure is developed for the flow to sense the presence of the particles, which is the essence of the IBM. Using the surface elements of the particle, the background grid cells are divided into fluid cells and solid cells, and the grid cells that make up the first layer of fluid cells outside the solid particle are designated as the fluid immersed boundary (IB) nodes. The IB nodes act as de facto boundary nodes for the fluid flow calculation such that the no-slip no-penetration fluid boundary condition is satisfied on the particle surface.
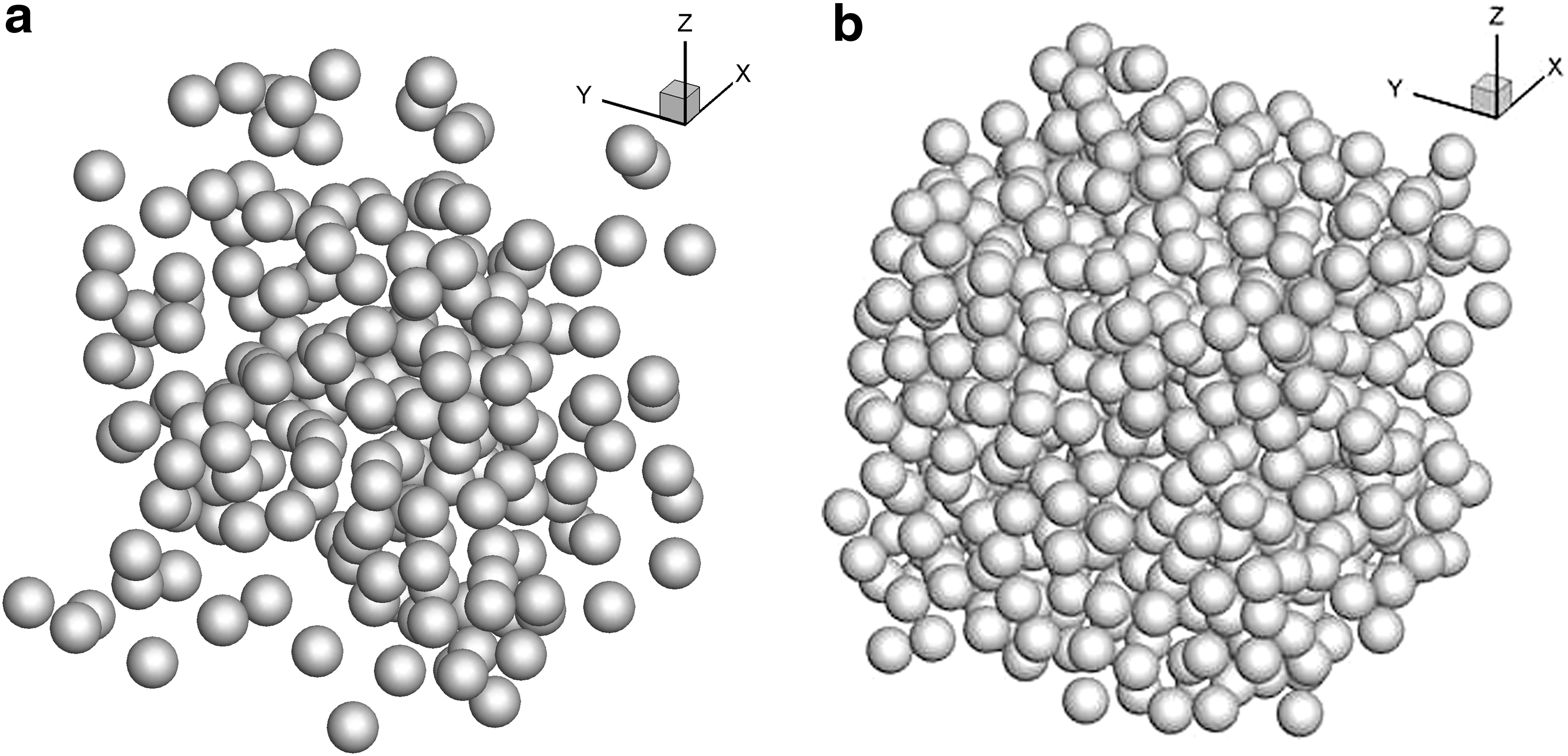
Immersed surfaces of spherical particle assemblies.
After obtaining the flow solution through the interstitial spaces between the spheres in the suspension, the drag force (force applied by fluid on particle in the flow direction) is calculated by direct integration over the particle surface. The forces on the particle surface are made up of viscous shear forces and pressure forces. These are calculated for each surface element and then integrating over all the elements to obtain the viscous and pressure contribution to total drag for each particle.
Collectively, 21,780 unique particle drag force data entries (7260 entries for each of 3 particle assemblies) are obtained from the calculations. For training the neural net, the Reynolds number (Re), solid fraction (
Proposed PhyNet Framework
Problem background
The overan learning pipeline of our proposed PhyNet model is outlined in Figure 1. Given a collection of N 3D particles suspended in a fluid moving along the X direction, we are interested in predicting the drag force experienced by the
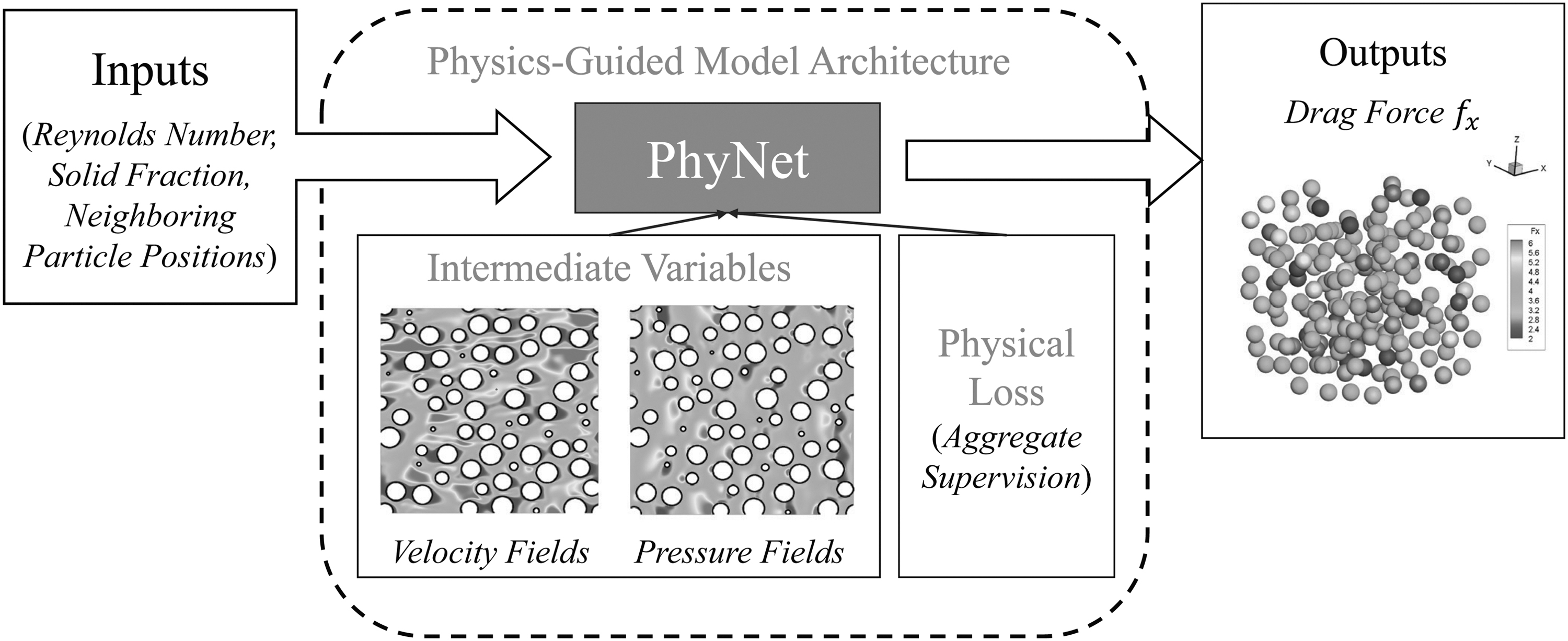
Our proposed PhyNet model.
A simple way to learn the mapping from
Physics-guided model architecture
To design the architecture of PhyNet, we derive inspiration from the known physical pathway from the input features
Using this physical knowledge, we design our PhyNet model so as to express physically meaningful intermediate variables such as the pressure field, velocity field, pressure component, and shear component in the neural pathway from
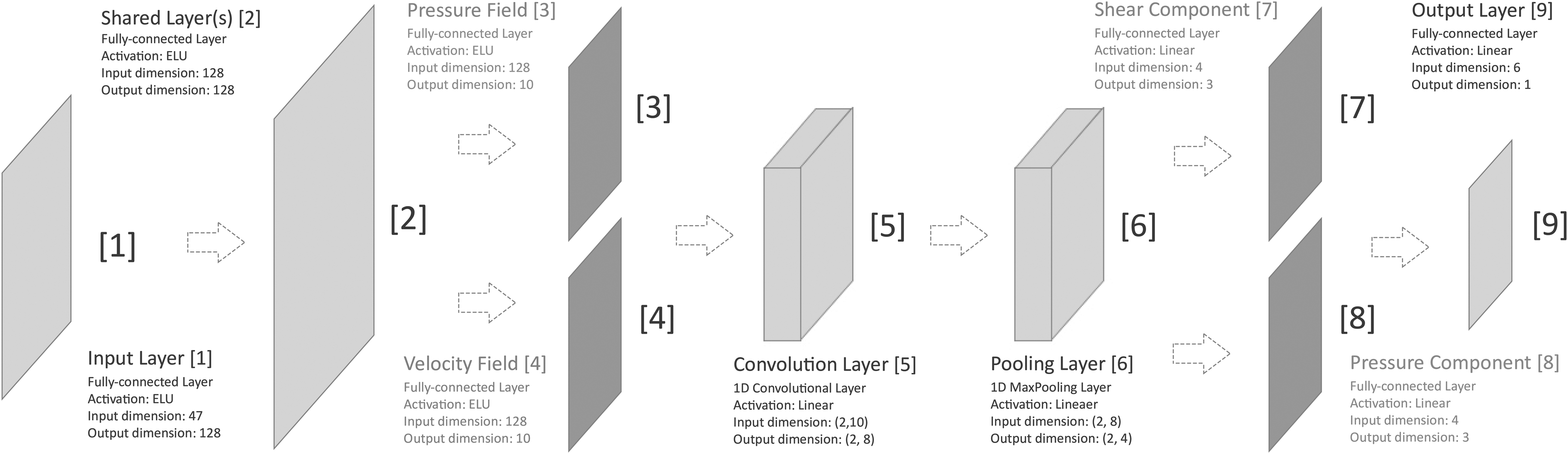
PhyNet architecture.
The outputs of pressure field and velocity field layers are combined and fed into a 1-dimensional convolutional layer that extracts the sequential information contained in the 10-dimensional
Learning with physical intermediates
It is worth mentioning that all the intermediate variables involved in our PhyNet model, namely the pressure field
where MSE represents the mean squared error,
The generalizability of this architecture is evident by extrapolating the concept of intermediaries to other physically meaningful variables or principles to enhance learning. For instance, the product of every CFD simulation is the 3D velocity and pressure fields, which are solely responsible for all derived quantities of practical interest. Thus, other physically relevant quantities derived from these fields such as velocity and pressure gradients can also be formulated as intermediaries. Additionally in more elaborate settings, principles of mass, momentum, and energy conservation can be included in the loss function to minimize errors in the intermediate variables.
Using physics-guided loss
Along with learning our PhyNet using the empirical loss observed on training samples,  and
and 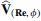 of the pressure and velocity fields around a particle, respectively, at a given combination of (Re,
of the pressure and velocity fields around a particle, respectively, at a given combination of (Re,

The function
Data set Description
The data set used has 7260 particles. Each particle has 47 input features (detailed in Table 1) including 3D coordinates for 15 nearest neighbors relative to the target particle's position, the Reynolds number (Re), and solid fraction (
The 47 input features of the data set
Pressure and velocity field sampling methodology
We now outline the procedure for sampling the pressure field (
The sampling field locations of a particle pi can be represented by
Experimental setup
All deep learning models used have 5 hidden layers, a hidden size of 128 and were trained for 500 epochs with a batch size of 100. Unless otherwise stated, 55% of the data set was used for training, whereas the remaining data were used for testing and evaluation. We applied standardization to all the input features and labels in the data preprocessing step.
Baselines
We compare the performance of PhyNet with several state-of-the-art regression baselines and a few close variants of PhyNet.
Linear Regression, Random Forest (RF) Regression, Gradient Boosting (GB) Regression 38 : We employed an ensemble of 100 estimators for RF and GB regression models and left all other parameters unchanged.
DNN: A standard feed-forward neural network model for predicting the scalar valued particle drag force Fi.
DNN-MT-Pres: A DNN model that predicts the pressure field around a particle (
DNN-MT-Vel: Similar to DNN-MT-Pres except in this case the auxiliary task models the velocity field around the particle (
We employ three metrics for model evaluation.
Mean squared error and mean relative error
We employ the MSE and mean relative error (MRE)
2
metrics to evaluate model performance. Although MSE can capture the absolute deviation of model prediction from the ground truth values, it can vary a lot for different scales of the label values, for example, for higher drag force values, MSE is prone to be higher, vice versa. Thus, the need for a metric that is invariant to the scale of the label values brings in the MRE as an important supplemental metric in addition to MSE.
where
Area under the relative error curve
The third metric we employ is the area under the relative error curve (AU-REC). The relative error curve represents the cumulative distribution of relative error between the predicted drag force values and the ground truth PRS drag force data. AU-REC calculates the area under this curve. The AU-REC metric ranges between [0,1], and higher AU-REC values indicate superior performance.
Experimental Results
We conducted multiple experiments to characterize and evaluate the model performance of PhyNet with physics-guided architecture and physics-guided aggregate supervision. Cognizant of the cost of generating drag force data, we aim to evaluate models in settings where there is a paucity of labeled training data. Our main goals are to generate effective predictions of drag force under data paucity and show consistency of the trained prediction model with known prior domain knowledge. We conduct several experiments to verify the consistency of the intermediate predictions with known physics phenomena, thereby ensuring explainability of the model predictions. Finally, we also tackle the challenging problem of extrapolation and characterize the ability of the proposed PhyNet model to extrapolate to unseen settings.
Physics-guided auxiliary task selection
When data about the target task is limited, we may employ exogenous inputs of processes that have an indirect influence over the target process to alleviate the effects of data paucity on model training. An effective way to achieve this is through multitask learning. Table 2 shows the results of several multitask and single task architectures that we tested in the context of the particle drag force prediction task. It is widely known and accepted in physics that the drag force on each particle in fluid-particle systems, such as the one being considered in this article, is influenced strongly by the pressure and velocity fields acting on the particles. 2 Hence, we wish to explicitly model the pressure and velocity fields around a particle, in addition to the main problem of predicting its drag force. To this end, we design two multitask models, DNN-MT-Pres and DNN-MT-Vel, as described in the Experimental Setup section. We notice that the two multitask models DNN-MT-Pres and DNN-MT-Vel show inferior performance to the DNN model; however, the PhyNet model, which is a combination of both the auxiliary tasks, is able to outperform the DNN and all other models, as shown in Table 2. This improvement in performance may be attributed to the carefully selected auxiliary task and model architecture to aid in learning the representation of the main task.
Overall PhyNet performance comparison
Boldface indicates best model in each column.
We compare the performance of PhyNet and its variant PhyNet-F
AU-REC, area under the relative error curve; DNN, deep neural network; GB, Gradient Boosting; MRE, mean relative error; MSE, mean squared error; RF, Random Forest.
Statistical significance comparison
To further verify the validity of model performance, we evaluate the statistical significance of PhyNet predictions relative to the other deep learning architectures mentioned in Table 2. We conducted a two-sided Mann–Whitney–Wilcoxon rank-sum test, 39 which is a nonparametric hypothesis test, in our case indicating whether the difference in performance of a pair of regression models is statistically significant. We notice from Table 3 that the PhyNet model yields statistically significant performance improvements over all the other deep learning architectures, further corroborating our earlier findings in Table 2.
Results of Mann–Whitney–Wilcoxon rank-sum test for statistical significance
Each p-value represents a result of the test performed to compare the statistical significance of PhyNet with every other model. We notice that based on the p-values obtained, we can comfortably conclude that the performance improvement obtained with PhyNet is statistically significant.
Physics-guided learning architecture
The Physics-Guided Auxiliary Task Selection section showcases the effectiveness of multitask learning and of physics-guided auxiliary task selection in the context of PhyNet models for learning improved representations of particle drag force.
We now delve deeper and inspect the effects of expanding the realm of auxiliary tasks. In addition to this, we also use our domain knowledge regarding the physics of entities affecting the drag force acting on each particle, to influence model architecture through physics-guided structural priors. As mentioned in the Proposed PhyNet Framework section, PhyNet has four carefully and deliberately chosen auxiliary tasks [pressure field prediction, velocity field prediction, predicting the pressure component(s) of drag, predicting the shear components of drag] aiding the main task of particle drag force prediction. In addition to this, the auxiliary tasks are arranged in a sequential manner to incorporate physical interdependencies among them leading up to the main task of particle drag force prediction. The effect of this carefully chosen physics-guided architecture and auxiliary tasks can be observed in Table 2. We now inspect the different facets of this physics-guided architecture of the PhyNet model.
We first characterize the performance of our PhyNet models with respect to the DNN and mean baseline. Figure 4 represents the cumulative distribution of relative error of the predicted drag forces and the PRS ground truth drag force data. We notice that both DNN and PhyNet outperform the mean baseline, which essentially predicts the mean value per (Re,
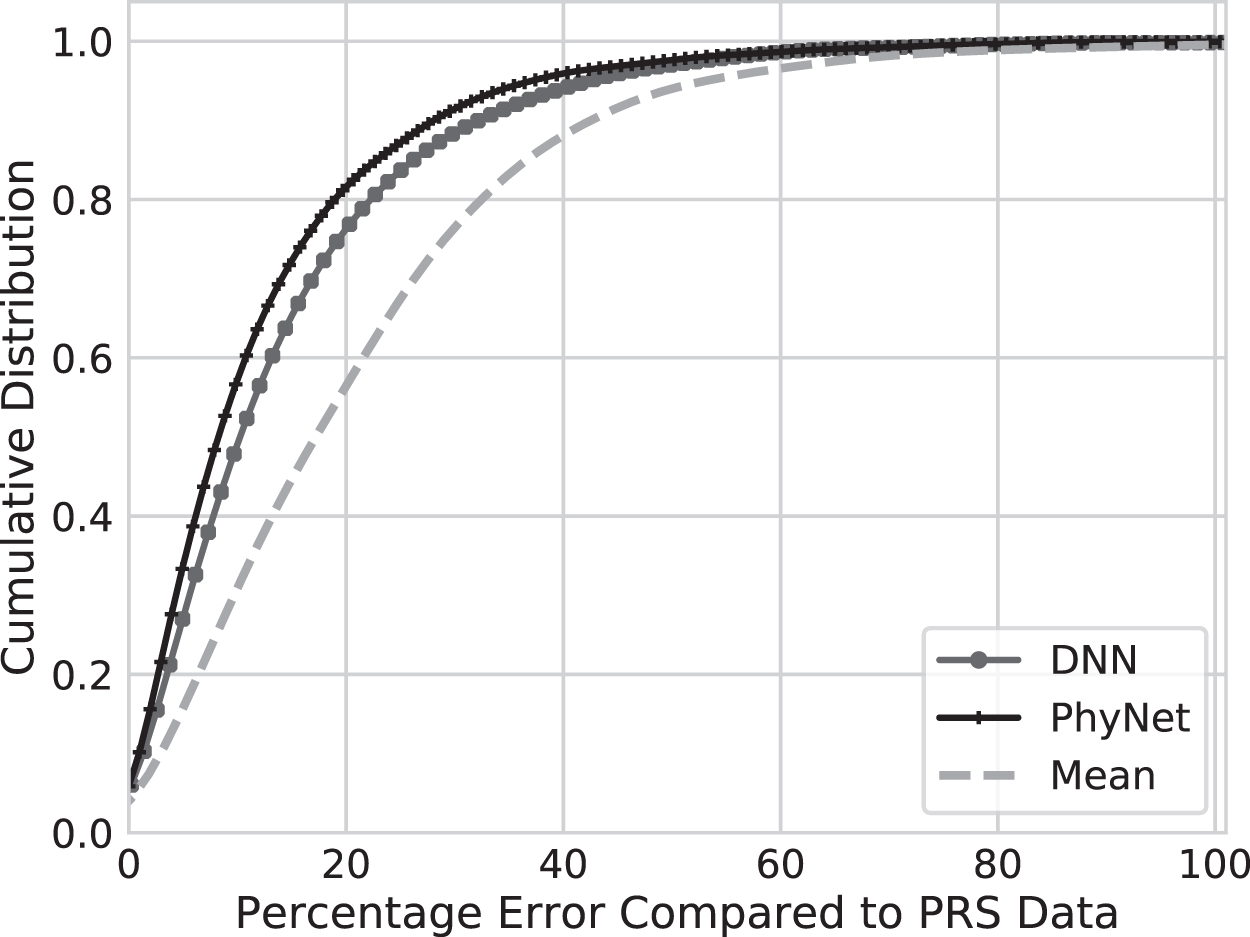
The cumulative distribution function of relative error for all (Re,
Performance with limited data
Bearing in mind the high data generation cost of the PRS, we wish to characterize an important facet of the PhyNet model, namely, its ability to learn effective representations when faced with a paucity of training data. Hence, we evaluate the performance of the PhyNet model as well as the other single task and multitask DNN models, on different experimental settings obtained by continually reducing the fraction of data available for training the models. In our experiments, the training fraction was reduced from 0.85 (i.e., 85% of the data used for training) to 0.35 (i.e., 35% of the data used for training).
Figure 5 showcases the model performance in settings with limited data. We observe that PhyNet model significantly outperforms all other models in most settings (sparse and dense). We note that even for the setting with highest data paucity, that is, training fraction 0.35, PhyNet outperforms all other models. The GB (and all the other regression models except DNN) fails to learn useful information as more data are provided for training. We also notice that the DNN model fails to outperform the PhyNet model for all settings, although the performance of the DNN and the PhyNet models is quite comparable for the setting with the highest volume of training data, that is, 0.85 training fraction.
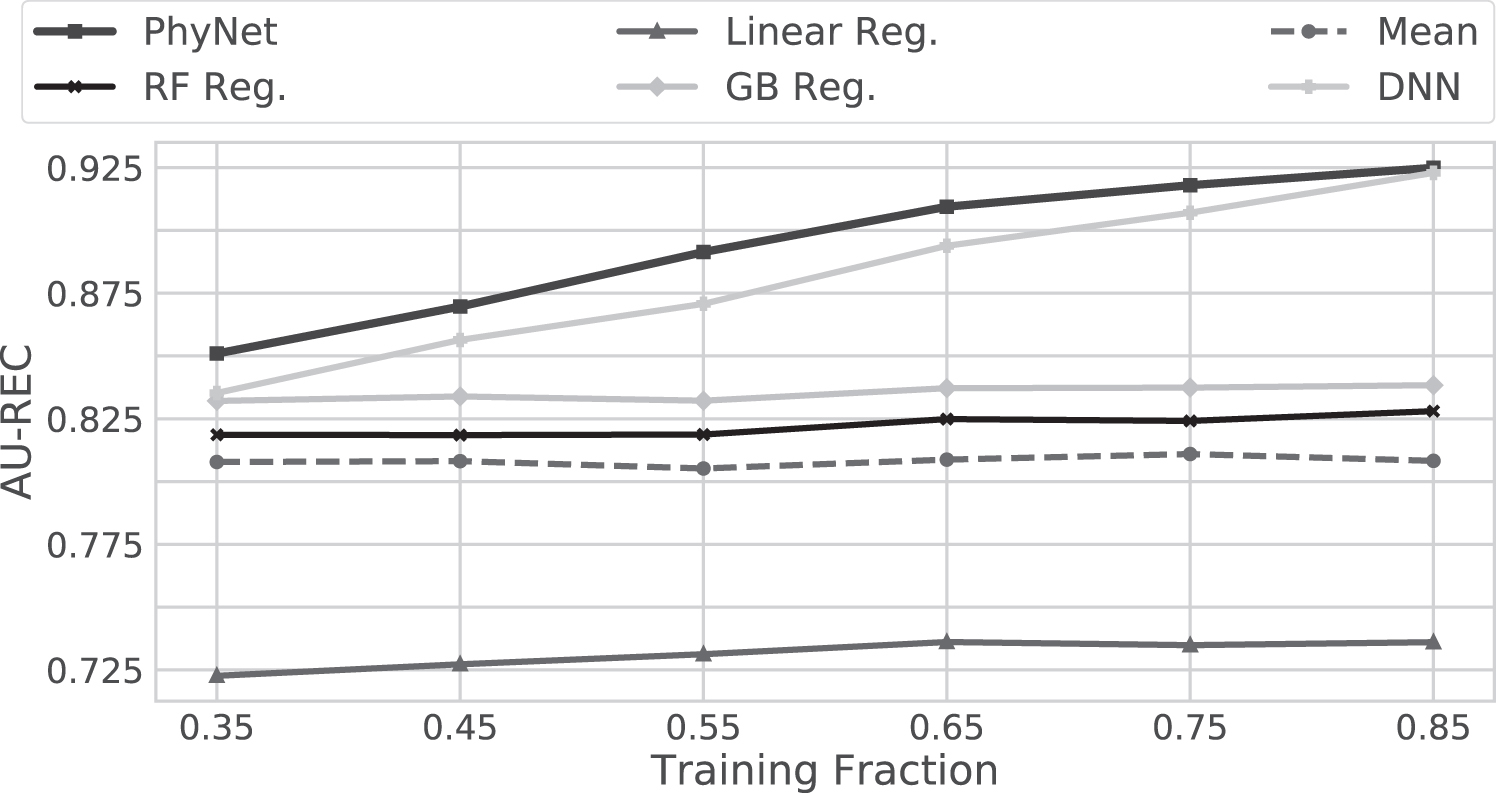
Model performance comparison for different levels of data paucity. We can observe that PhyNet outperforms all other models for all training fractions.
Characterizing PhyNet performance for different (Re,
) settings
In addition to quantitative evaluation, qualitative inspection is necessary for a deeper holistic understanding of model behavior. Hence, we showcase the particle drag force predictions by the PhyNet model for different (Re,
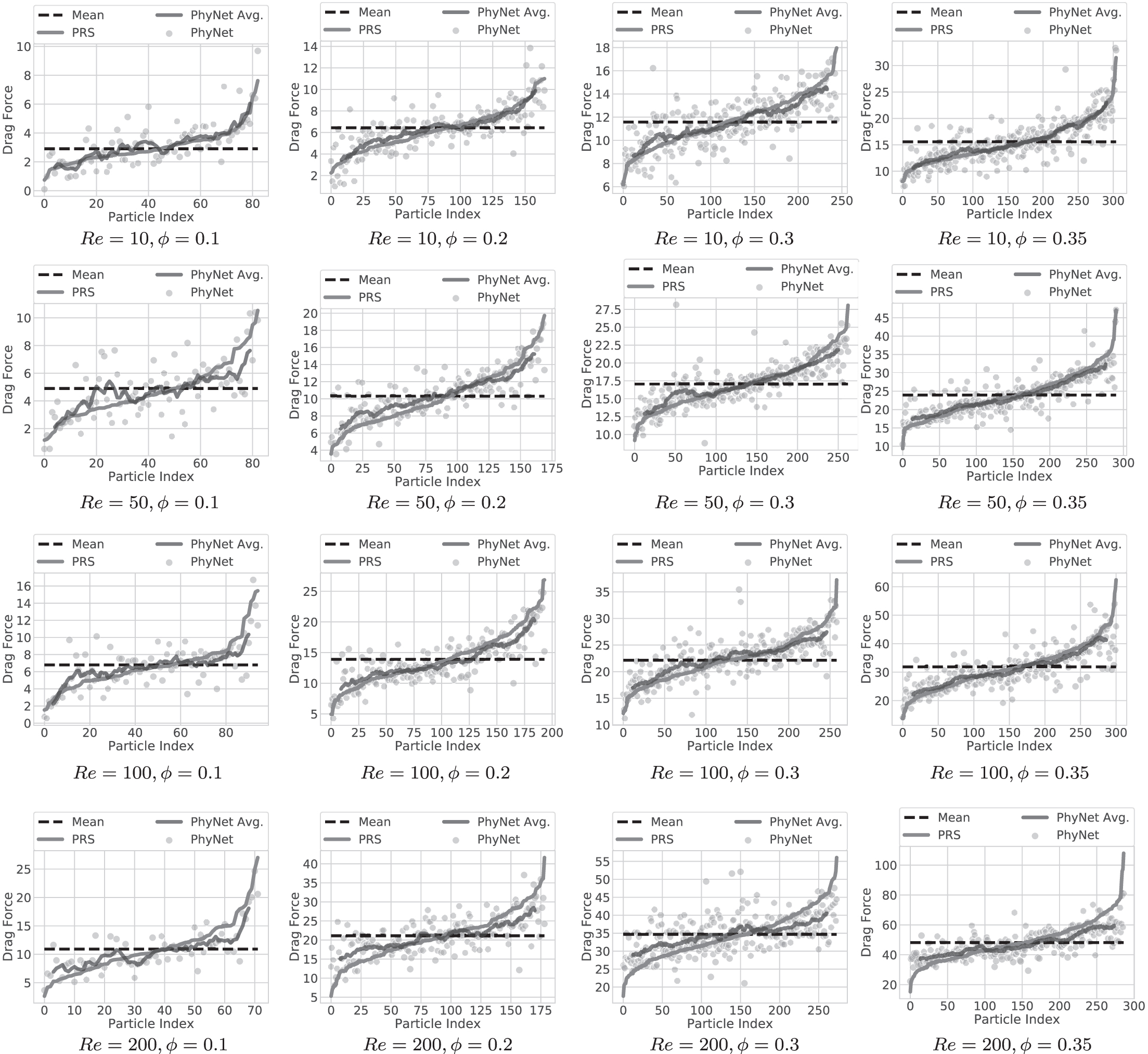
Each figure shows a comparison between avg. PhyNet predictions and ground truth drag force data, for different (Re,
Thus far, we characterized the performance of the PhyNet model in isolation for different (Re,
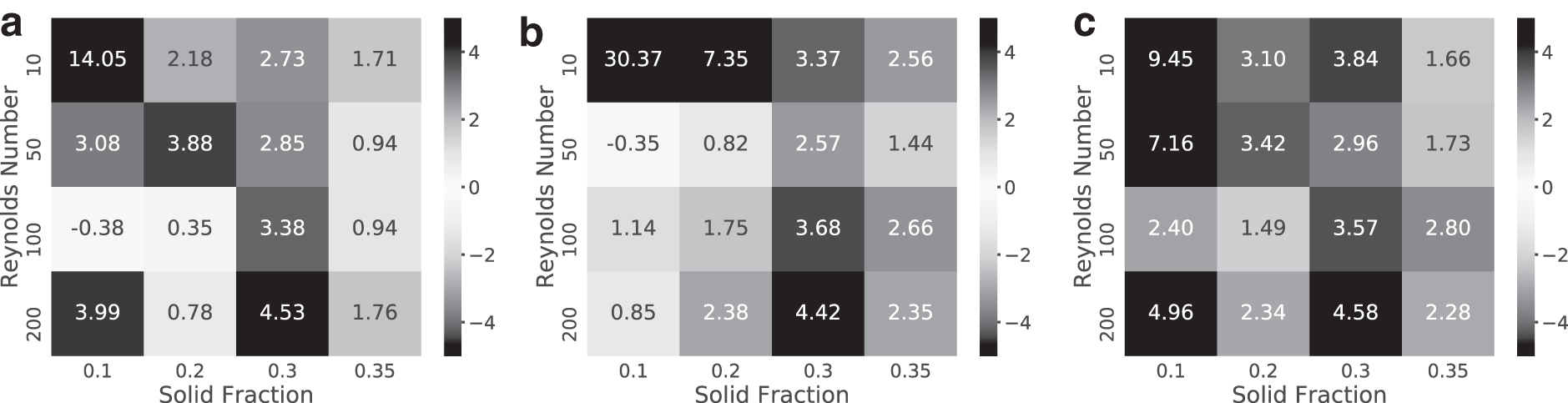
Each figure indicates the percentage improvement in the context of the AU-REC metric of the PhyNet model over the DNN
Verifying consistency with domain knowledge
A significant advantage of physics-guided multitask architecture design is the increased interpretability provided by the resulting architecture. Since each component of the PhyNet model has been designed and included based on sound domain theory, we may employ this theoretical understanding to verify through experimentation that the resulting behavior of each auxiliary component is indeed consistent with known theory. We first verify the performance of the pressure and shear drag component prediction task in the PhyNet model.
It is well accepted in theory that for high Reynolds numbers, the proportion of the shear components of drag (

Heat map with ratio of absolute value of pressure drag (
Auxiliary representation learning with physics-guided statistical constraints
Two of the auxiliary prediction tasks involve predicting the pressure and velocity field samples around each particle. We hypothesized that since the drag force of a particle is influenced by the pressure and velocity fields, modeling them explicitly should help the model learn an improved representation of the main task of particle drag force prediction. In Figure 9, we notice that ground-truth pressure field probability density functions (PDFs) exhibit a grouped structure. Interestingly, the pressure field PDFs can be divided into three distinct groups with all the pressure fields with
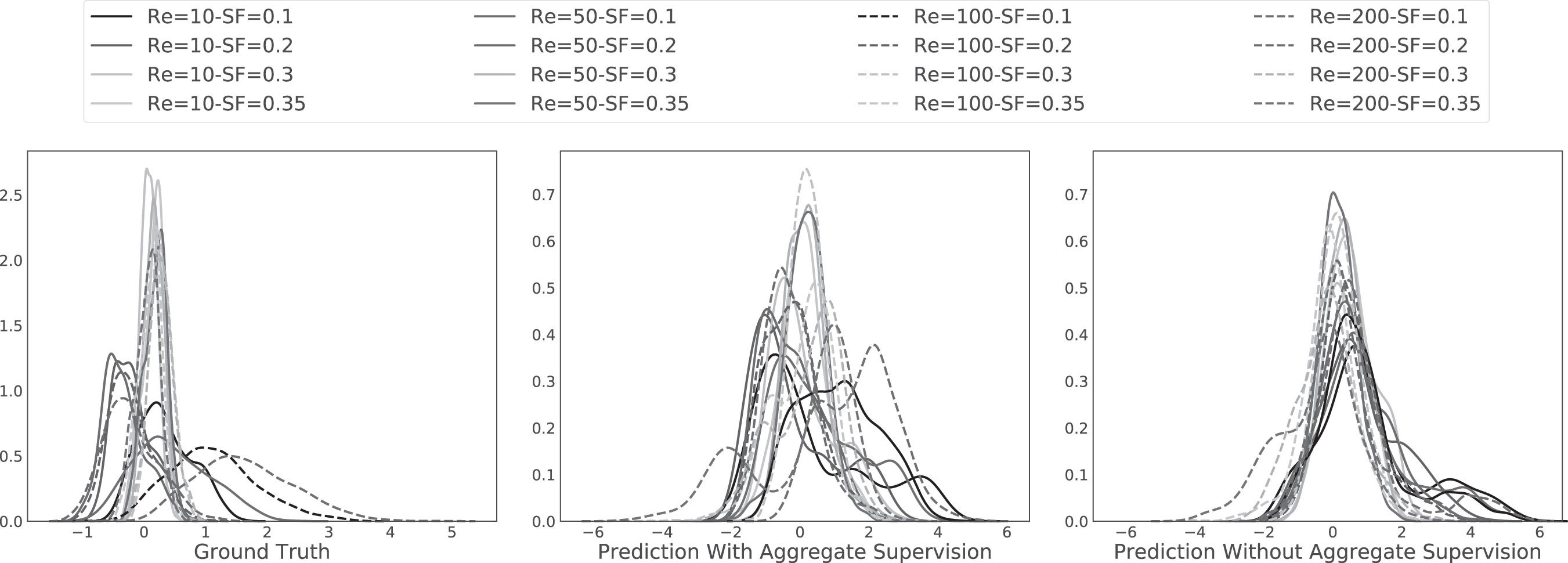
The figure depicts the densities of the ground truth (left) and predicted (center, right) pressure fields of the PhyNet model for each (Re,
It is nontrivial for models to automatically replicate such multimodal and grouped behavior, and hence, we introduce physics-guided statistical priors through aggregate supervision during model training of PhyNet. We notice that the learned distribution with aggregate supervision (Fig. 9, center) has a similar grouped structure to the ground truth PDF pressure field. We also obtained the predicted pressure field PDFs of a version of PhyNet trained without aggregate supervision, and the result is depicted in Figure 9 (right). We notice that the PDFs exhibit a kind of mode collapse behavior and do not display any similarities to ground truth pressure field PDFs. Similar aggregate supervision was also applied to the velocity field prediction task and we found that incorporating physics-guided aggregate supervision to ensure learning representations consistent with theory significantly improved model performance. The effect of aggregate supervision is empirically characterized in Table 4 where we compare PhyNet with and without aggregate supervision for different training fractions (0.35–0.85) as before. We notice that in all settings PhyNet with aggregate supervision performs better than the variant without aggregate supervision.
Effect of aggregate supervision on PhyNet for different levels of data paucity
Bold values indicate the best performing PhyNet variant (i.e. with or without aggregate supervision per training fraction).
We notice that PhyNet with aggregate supervision outperforms the variant without it in all cases.
Hyperparameter sensitivity
As outlined in the Proposed PhyNet Framework section, each of the four auxiliary tasks in the PhyNet model is governed by a hyperparameter during model training. In our experiments, we only tune the hyperparameters for the pressure field and velocity field prediction tasks leaving all other hyperparameters set to static values for all experiments. We employ a grid search procedure on the validation set to select the optimal hyperparameter values for the pressure and velocity field prediction auxiliary tasks in the PhyNet model. To characterize the effect of this hyperparameter selection procedure on the model evaluation, we evaluate the sensitivity of the model to different hyperparameter values.
We design the hyperparameter sensitivity experiment to inspect how model performance varies with different training fractions (i.e., different experimental settings). We conduct an experiment by reducing the training fraction from 0.85 to 0.35. Figure 10 shows the results of our experiment wherein the blue bars indicate the AU-REC values obtained when the PhyNet model was trained with a static (predefined) set of hyperparameters. ‡ The green bars indicate the setting where the optimal hyperparameters for pressure and velocity field prediction for the PhyNet model were obtained through grid search on the validation set. We notice that over all the training fractions, there is no significant difference between the two models and hence conclude that the PhyNet model is robust across different hyperparameter settings. Exact hyperparameter values are detailed in Table 5.
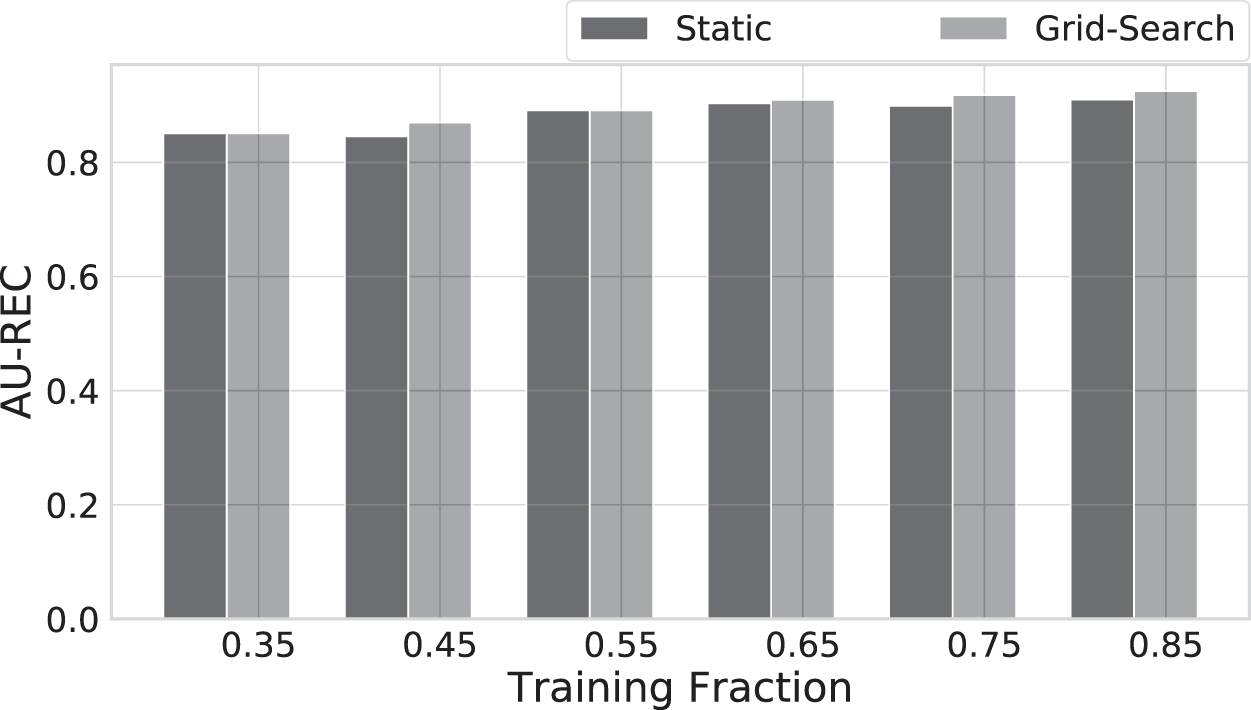
Hyperparameter sensitivity evaluation of the grid search hyperparameter selection procedure for the PhyNet model. We notice that PhyNet is robust to different settings of hyperparameters as we do not see significant changes in the AU-REC between the settings where hyperparameters for the PhyNet were selected through grid search on the validation set and the settings wherein the hyperparameter values were set to a constant value by hand before the experiment, that is, no parameter tuning.
Hyperparameter values of PhyNet for different levels of training fractions each obtained through grid search
It must be noted that only the hyperparameters for the pressure and velocity field prediction auxiliary tasks were tuned, and the rest of the values were kept constant for all experiments
Effect of pressure and velocity sampling methodology
In Table 6, we characterize the model performance with different sampling frequencies of the pressure and velocity fields around each particle. The sampling plane is the XY plane with the Z axis aligned with the particle center. We notice from the results in Table 6 that the model performance improves with increasing sampling frequency indicating that higher sampling frequencies capture the overall pressure and velocity fields in a more representative manner.
Effect of pressure and velocity sampling rates on drag force prediction
Model with the least error is shown in bold for each metric.
We can observe that the learned model representation improves with increase in sampling frequency, and the model with sampling frequency 100 yields the best performance. We notice that the most granular pressure and velocity field sampling procedure (100 samples) yields an improvement of 7.2% over the coarse-grained pressure and velocity sampling procedure (10 samples).
Effect of neighborhood size and extrapolation to unseen assemblies
Extrapolation is a challenging task for ML models and is the ultimate test of generalizability of a learned representation. We conducted experiments to evaluate the generalization capability of our PhyNet model by testing the model performance in the context of predicting drag forces of unseen particle assemblies. A particle assembly indicates a certain spatial arrangement of particles for a particular (Re,
We generated 3 separate particle assemblies [each with 16 combinations of the same range of (Re,
Extrapolation to two unseen particle assemblies using different-sized particle neighborhoods
Best model per neighborhood size and per metric are in bold.
The results depict that the PhyNet model outperforms the DNN model in the context of higher neighborhood sizes (10, 15 neighbors). PhyNet achieves an average of 2% improvement over the DNN model in terms of MRE, measured across all the extrapolation settings.
Conclusion
In this article, we introduce PhyNet, a physics-inspired deep learning model developed to incorporate fluid mechanical theory into the model architecture and to propose physics-informed auxiliary tasks selection to aid with training under data paucity. We conduct a rigorous analysis to test PhyNet performance in settings with limited training data and find that PhyNet significantly outperforms all state-of-the-art baselines for the task of particle drag force prediction, achieving an average performance improvement of 7.09% across all models. We verify that each physics-informed auxiliary task of PhyNet is consistent with existing physics theory, yielding greater model interpretability. We also introduce a sampling procedure consistent with the periodic boundary condition of the underlying simulation domain for obtaining a granular sample of the pressure and velocity fields around the particle surface and showcase that the PhyNet model was able to learn higher quality representations of the particle drag force with fine-grained pressure and velocity field samples.
We also show the effect of augmenting PhyNet with physics-guided aggregate supervision to constrain auxiliary tasks to be consistent with ground truth data. The effect of the size of particle neighborhood on modeling has also been detailed, and we notice that larger particle neighborhoods enable better modeling of the drag forces acting on the particle of interest. Finally, we also demonstrate the ability of PhyNet to extrapolate to unseen particle assemblies and wish to conduct additional experiments further characterizing extrapolation ability in yet other settings moving forward. In the future, we also plan to study the effect that upstream and downstream particles have on the pressure and velocity fields and drag force of a particle of interest.
In conclusion, the article gives a general framework for incorporating physics into ML through intermediaries when these intermediaries influence the quantity being modeled but are not available during model deployment. Such situations abound in computational science and engineering when highly resolved simulations are used to develop models to be deployed as “subgrid” models in low-resolution calculations. While the PhyNet framework has been demonstrated for finding particle drag in a suspension, the same framework can be deployed for other CFD-based model development efforts in a variety of engineering fields and in fields such as atmospheric and geological sciences.
Footnotes
Acknowledgments
This article is an extension of the article titled PhyNet: Physics Guided Neural Networks for Particle Drag Force Prediction in Assembly that appeared in the Proceedings of the 2020 SIAM International Conference on Data Mining (SDM20) and the arXiv preprint titled Physics-Guided Design and Learning of Neural Networks for Predicting Drag Force on Particle Suspensions in Moving Fluids.
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This work was supported by the National Science Foundation via grants DGE-1545362 and IIS-1633363.