
Abstract
To deal with a large amount of redundant data in the indirect category database and inefficient redundancy elimination of the existing methods, we proposed an indirect category data transfer learning algorithm based on regularization discrimination. First of all, we denoised indirect category data, calculated the objective function of distance between the source domain and the target domain, and established the transfer relationship between indirect category data. Second, we adopted the regularization discriminant technique to divide the transfer network structure of indirect category data into five modules, analyzed the effects and advantages of different modules, and constructed the transfer network structure of indirect category data. Finally, the indirect category data transfer was realized by the design of the indirect category data transfer learning algorithm. The results show that the proposed algorithm can effectively eliminate redundancy of indirect category data, the amplitude of fluctuation of indirect category data is small, the transfer time and energy consumption of the algorithm are low, and the accuracy is as high as about 90%, which indicates that the proposed algorithm is far superior to the traditional method and has high application value.
Introduction
Transfer learning is a new machine-learning algorithm that imitates the human learning process and applies the existing knowledge to relevant fields to learn, thereby reducing the amount of data required and reducing the complexity of the algorithm. There is a lot of redundant data in the indirect category database, so it will be difficult to get valuable indirect category data from the database. 1
The concept of regularization is similar to the “penalty function method,” which optimizes data calculation results by penalizing undesired data, and finally obtains optimized values. 2 However, the regularization discriminant technique can manage the indirect category data, which is favorable for ensuring the location accuracy of the indirect category data and enabling users to obtain more valuable indirect category data. In many digital domains, it is essential to carry out regularization discrimination against the indirect category data.
Wang et al. 3 proposed a transfer learning algorithm based on regularization discrimination analysis, in which a modified embedding space was constructed by defining a distance function, the regularization method was used to filter samples in the mapping space, and the pseudo-marked data were used to classify the data samples for data sample transfer. The algorithm can effectively improve the generalization ability of the learning model, but there is a problem with the complicated calculation process. Lei et al. 4 proposed a regularized linear discriminant pedestrian re-recognition algorithm, which transformed the data in different dimensions, used the regularized linear discriminant analysis method to construct a projection matrix, showed the data high-dimensional to low-dimensional space distribution performance, and improved the algorithm recognition effect.
In Xu and Chen, 5 the data structure is represented by the graph regularization constraint, the feature discrimination is performed by using the label information of the dataset, the updating rules of data iteration are given, and the algorithm research is well completed. Shao and Sang 6 proposed a regularized maximum–minimum linear discriminant analysis method, and they introduced Shannon entropy based on Max-Min Linear Discriminant Analysis and the corresponding distance difference regularization term. In the optimization, the distance between the class centers can be accurately controlled, and the separation between classes can be approximately emphasized; experiments on the synthetic dataset and three public datasets have proved the effectiveness of the algorithm.
On the basis of existing algorithms, in this study, the algorithm of indirect category data transfer learning is studied based on regularization discrimination, to optimize the application performance of the indirect category database and provide a foundation for the development of the digital field. The results show that the proposed algorithm has better performance than traditional methods. The first part of this article introduces the introduction and related work, the second part introduces the algorithm of this article, the third part introduces the results and discussion, and finally, the conclusion is explained.
The contribution points of this study are as follows:
(1) An indirect category data transfer learning algorithm using regularization discrimination was proposed. (2) The indirect category data are denoised to lay the foundation for effectively improving the effect of data redundancy. (3) The network structure of data transfer is constructed, which is divided into different modules, and the operation functions of the modules are explained in detail. (4) A specific algorithm of data transfer learning is designed, and the algorithm is verified by several groups of experiments, which increases the reliability of the algorithm.
Related Work
Kang et al. 7 proposed a transfer learning algorithm for automatic demand model generation. Aiming at the inaccuracy and incompleteness of the software requirements description on the website, the case transfer learning method was used to construct a robust classifier, the domain feature knowledge was predicted based on the domain knowledge similar to the target domain, and the packet clustering algorithm and various clustering algorithms were used to select the transmission instance; however, this method takes a long time. Ntalampiras 8 proposed a transfer learning framework to reveal the potential similarity in the emotional perception process caused by sound events and songs. The results show the importance of transfer learning in a specific field. The method is generally good. But the operation energy consumption is high. Gan et al. 9 pointed out that transfer learning allows different distributions of source space and task space on different datasets, and transfer learning can involve more personalized learning models. This method was combined with transfer learning to propose a classification model. Experiments verify that the algorithm has a high accuracy rate. However, there is a large amount of labeling information in the data of this method, which makes the training of category data difficult. Lv et al. 10 proposed an adaptive incremental integrated classification algorithm for concept drift data flow, in which the data transfer model of adaptive concept drift was used to construct the data transfer model, the classification model was constructed by prioritizing the data concerned, and the data transfer was realized by analyzing the degree of data attention. However, the algorithm has the shortcoming of low stability. In Li and Dai, 11 a new ranking-based error reduction ensemble selection method is designed. This study combined the transfer learning mechanism based on knowledge leverage and the ensemble selection method based on rank reduction to complete the transfer learning task and find candidate classifiers, to maximize the classification performance of the extended subset; the overall performance is good, but the stability is insufficient.
To solve the problems just cited, an indirect category data transfer learning algorithm based on regularization discrimination was proposed to reduce the noise of the indirect category data, and the regularization discrimination was applied to the design of the indirect category data transfer learning algorithm, thereby reducing the amount of redundant data of indirect category data and guaranteeing the balance and stability of indirect category data. The amount of redundant data of the proposed algorithm is as low as 300 bits, the data fluctuation amplitude is low, the stability is good, and can reach 96.5%, the data transfer time is up to 0.6 ms, the data transfer accuracy is always 90%, and the average energy consumption of the algorithm is 15.8 J, which verifies the performance of the proposed algorithm.
Design of Indirect Category Data Transfer Learning Algorithm
Calculation of association rule matrix based on data denoising
In the process of establishing the indirect category data transfer relationship, the association matrix of category data should be calculated. Due to a large amount of noise data in the indirect category database, the calculation accuracy of the category data association matrix was affected, so the wavelet transform method was used to denoise data.12,13
If the mother wavelet of the wavelet transform of the database was
where
There was a certain relationship between data in the indirect category database. To establish the indirect category data transfer relationship,14,15 it was, thus, necessary to determine the data association rule and generate a sample set Q based on the existing data types, and
where
After the association rule between each subset in the sample set is determined, according to the similarity between the sets Z and Q, the association rule matrix of indirect category data could be obtained as follows in Equation (4):
where
Establishment of data transfer relationship
Although the category data association rule was determined, the establishment of the transfer relationship of indirect category data could reduce the redundant data amount of indirect category data. Then, this study preprocessed the indirect category data, ensured that the data were within the same value range, and regularized the data by using the regularization discriminant technique.16,17 Assuming that
where
After the indirect category data were preprocessed, the indirect category data in the source domain and the target domain could be matched to build the mapping relationship between the indirect category data.18,19 Due to the different spatial dimensions in the source domain and the target domain, the indirect category data in the two domains were coordinately transformed and the main features of the indirect category data in the domain were expressed by selecting the regularization discrimination method. 20
The regularization discrimination method was used to map the indirect category data in the source domain to the target domain, and then the distance between the source domain and the target domain in the main direction was calculated. The minimization of the target function is expressed as:
where
where T is the transpose symbol, and
Since
where
According to the steps just cited, indirect category data were preprocessed to keep the data ranges the same; the regularization discrimination was used to obtain new indirect category data21,22; and the transfer function between the indirect category data was completed by calculating the distance between the source domain and the target domain in the main direction.
Construction of data transfer network structure
Based on establishing the indirect category data transfer relationship, through an in-depth study of the data transfer network structure, the regularization discriminant technique could be used to express the rich indirect category data features in the indirect category data transfer learning. This study adopted the regularization discriminant technique to construct the indirect category data transfer network structure, which can reduce the amount of redundant data in the indirect category data.23,24 The indirect category data transfer network structure is shown in Figure 1.

Indirect category data transfer network structure.
The indirect category data transfer network structure is built based on the regularization discriminant technique. The indirect category data transfer network structure consisted of five modules, with a total of 25 layers of transfer networks. In Figure 1, C1, C2, and C3 are module 1, module 2, and module 3, respectively, which are structural modules composed of convolution-pooling-activation functions. C4 is a fully connected module; it is a three-layer indirect category data structure composed of fully connected blocks, pooling layers, and activation functions. C5 represents the prediction module, which consists of only one full connector. Module 1–3 was mainly used to extract the underlying features of indirect category data from the local area of indirect category data; the fully connected module was mainly intended to integrate the spatial location relationship of indirect category data between different features of the indirect category database and to obtain the global characteristics of the data in the indirect category database; and the prediction module predicted the possibility of data in each category based on the characteristics of indirect category data. 25 Configuration of the indirect category data transfer network structure uses the regularization discriminant technique. This is shown in Table 1.
Configuration of indirect category data transfer network structure
According to the indirect category data transfer network structure diagram, the indirect category data transfer network structure was divided into five modules by using the regularization discriminant technique, and the indirect category data transfer network structure was designed accordingly. At the same time, by using the configuration of the indirect category data transfer network structure, this study analyzed the functions and advantages of different modules and constructed the indirect category data transfer network structure. 26 Next, the design of indirect category data transfer learning algorithm was used to realize the transfer learning of indirect category data.
Proposed algorithm
In this study, the indirect category data transfer network structure was constructed, and the indirect category data transfer learning algorithm was designed, thereby ensuring the balance of indirect category data. The specific steps of indirect category data transfer learning algorithm are:
Input: the data after denoising indirect category data
Output: the result of data transfer learning
Step 1: According to the positive and negative categories of indirect category database Tl in the target domain, the data were divided into two different clusters, and the transfer centers
Step 2: The distance
Step 3: In the distance data between all sorted indirect category data and the transfer center, the source domain data corresponding to the previous p% of the target domain was extracted, and removed the remaining indirect category data:
where “
Step 4: The remaining indirect category data were divided into k shares.
Step 5: For the predicted data labels, find the corresponding data samples with the highest similarity to the label, and add them together to P. The data sample set obtained by searching is expressed as:
where v represents the selected data label.
Step 6: The distance from the indirect category data samples to the cluster center was calculated.
Step 7: The indirect category data with the shortest distance was selected and added to Tl. If the number of indirect category data samples was greater than P, the number of indirect category data added to the database was
Step 8: The indirect category data collection was updated. It is shown in Equation (15).
According to the earlier steps of the indirect category data transfer learning algorithm, the implementation process of the indirect category data transfer learning algorithm was designed. It is shown in Figure 2.
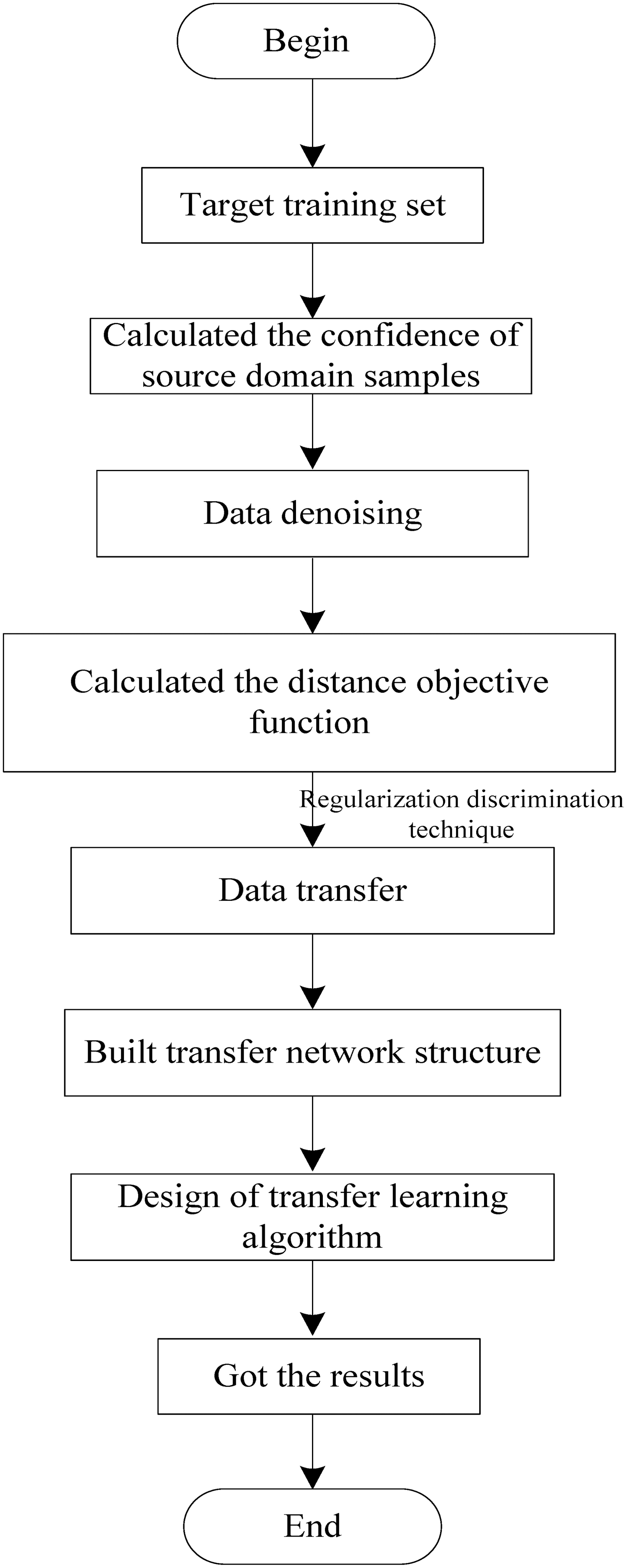
Implementation process of indirect category data transfer learning algorithm.
In summary, we first preprocessed indirect category data to ensure that the data have the same value range and we adopted the regularization discrimination to obtain new indirect category data. Through calculation of the distance target function between the source domain and the target domain in the main direction, the transfer relationship between indirect category data was completed. According to the indirect category data transfer network structure diagram, this study employed a regularization discriminant technique to divide the indirect category data transfer network structure into five modules and designed the corresponding configuration for the indirect category data transfer network structure. Subsequently, by using the configuration of the indirect category data transfer network structure, this study analyzed the functions and advantages of the different modules and constructed the indirect category data transfer network structure. Finally, through the design of the indirect category data transfer learning algorithm, the indirect category data transfer learning was implemented.
Experimental Analysis and Results
Experimental environment and dataset
To verify the performance of the proposed method, the experimental platform uses MATLAB 2014a. The hardware environment is 4 GB memory, Intel CoreTM i7-6700 CPU, and the computer with the main frequency of 3.4 GHz is tested. In this experiment, the cross entropy between the predicted value and the actual value of indirect category data was used as the target function, and the regularization discrimination method was adopted to optimize the target function. Subsequently, the indirect category data samples in the dataset were divided into an indirect category data block, and the regularization discrimination method was applied to process the experimental parameters. In addition, the experimental parameters were adjusted to one round of iteration, and the 60-round iteration was conducted to find the optimal transfer network parameters. Next, the bias sparseness of the experiment was initialized to 0, and the iterative learning efficiency was set to 0.05, 0.005, and 0.0005, respectively. Subsequently, the learning efficiency was updated every 20 iterations, and the experimental momentum value was set to 0.9.
In the process of training experimental data, the linear prediction values of indirect category data in different categories were selected as the experimental output values, and the type of prediction was judged according to the size of the experimental data prediction values. In this experiment, we selected NewsQA dataset, SQuAD dataset, and SimpleQuestions dataset, and we preprocessed the sample data to facilitate data analysis. NewsQA dataset: This dataset is mainly used for information mining and data classification. It is an international standard dataset that contains about 20,000 newsgroup documents, evenly divided into 20 newsgroup collections with different topics. SQuAD dataset: This is a set of reading datasets, a complex network analysis platform provided by Stanford University in the United States, and provides a variety of datasets, which are very useful for large-scale network analysis. SimpleQuestions dataset: It is a large-scale simple question and answer dataset based on a storage network. The dataset mainly provides question and answer information; the dataset includes 3047 questions and 29,258 sentences. The number of datasets selected in this experiment is 10 million, of which 7 million are used for data training, and the remaining 7 million are used for experimental testing.
Experimental steps
In this experiment, first, 50% of the data was selected as the source domain's sample data to train the classifier and obtain the indirect category data in the source domain required for the experiment; 50% of the extracted data were processed, and this increased the disturbance of indirect category data, so that the source domain and the target domain were different in the distribution of indirect category data. Second, the remaining 50% of indirect category data was used as the target domain, 10% of the indirect category data was extracted from the target domain as training samples, and the remaining indirect category data were used to detect the performance of the algorithm. Finally, 10% of the indirect category data in the target domain was used to train the classifier in the dataset without transfer ability, and the remaining 90% of the indirect category data was used for the experiment.
Evaluation criteria
The amount of redundant data
In the indirect category data transfer process, redundancy elimination was conducted over the dataset, and the redundant data volume was selected as the criterion to verify the performance of the proposed algorithm. This is shown in Equation (16):
where U is the amount of indirect category data, E is the variable of the dataset, and m is the learning duration.
Data fluctuation amplitude
To verify the stability of the proposed algorithm, the data fluctuation amplitude was selected as a criterion during the transfer process.
where q is the minimum value of the amplitude, n is the maximum value of the amplitude, and H is the number of learning times.
Stability of distance objective function
The objective function of calculating the distance between the source domain and the main direction of the target domain is the precondition of completing the data transfer. Therefore, the stability of the objective function has a great influence on the transfer results. According to Equations (7)–(9), the objective function can be calculated and the stability of the function can be compared.
Time consumption of data transfer
To verify the operating efficiency of the proposed algorithm, the time-consuming operation of different data volumes was selected as a criterion:
where O is data transfer efficiency.
Data transfer accuracy
The data transfer accuracy of the algorithm is compared, and the calculation Equation is shown in Equation (19).
where
Algorithm transfer energy consumption
Energy consumption is an important criterion to measure the performance of the algorithm. The proposed algorithm is compared with Xu and Chen, 5 Kang et al., 7 Ntalampiras, 8 and Gan et al. 9 to verify the algorithm performance.
Results and discussion
To ensure the application value of the proposed algorithm, this study selected the proposed algorithm, Xu and Chen, 5 Kang et al., 7 Ntalampiras, 8 and Gan et al., 9 and compared the amount of redundant data of indirect category data in the 10-minute learning time. The smaller the amount of redundant data, the better the application performance of the method. This is shown in Figure 3.

Comparison result of redundant data volume of indirect category data.
The algorithm propounded by Xu and Chen, 5 Kang et al., 7 Ntalampiras, 8 and Gan et al. 9 has a data redundancy of more than 500 bits at 10 minutes, especially the algorithm of Xu and Chen, 5 where the amount of redundant data reaches 700 bits. As for the proposed algorithm, the amount of redundant data reaches 300 bits at 10 minutes, and the reduction rate of redundant data is relatively stable, without any phenomenon that the amount of redundant data decreases due to the extended learning time. Besides, the proposed algorithm has established the indirect category data transfer relationship through the association matrix, so its redundancy reduction efficiency is much higher than that of existing methods, which indicates that the proposed algorithm has better due performance.
Based on the experimental conditions just mentioned, fluctuation amplitude data were extracted within 10 minutes, and five methods were used for comparison and recording. The closer the fluctuation amplitude is to the source data, the better the performance of the method is. The results are shown in Figure 4.
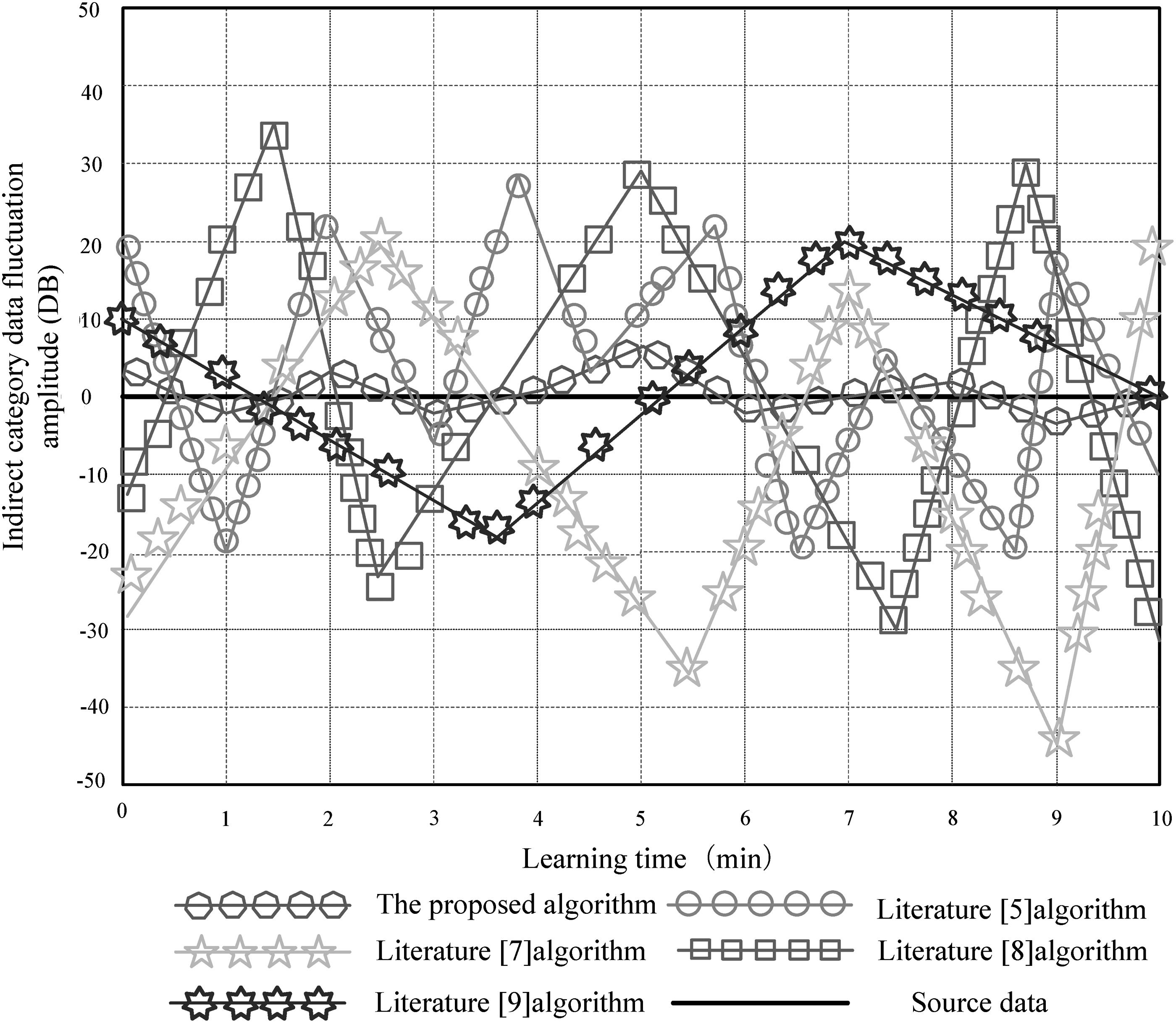
Comparison result of fluctuation amplitude of indirect category data.
According to Figure 4, the fluctuation amplitude of the proposed algorithm is relatively close to the source data, the fluctuation range is [−4, 6], and the fluctuation amplitude does not exceed 10 dB, which is much smaller than the existing methods. In contrast, the methods of Xu and Chen, 5 Kang et al., 7 and Ntalampiras 8 have high fluctuation amplitude. Kang et al. 7 can reach up to 40 dB, and there is a large deviation from the source data, and Gan et al. 9 reaches 30 dB. This is because this study first carried out data denoising, which laid a good foundation for subsequent data transfer.
The stability of the objective function of the distance between the source domain and the main direction of the target domain is compared. The results are shown in Table 2.
Stability of objective function/%
According to Table 2, the stability of the objective function of the proposed algorithm gradually increases with the increase of the number of iterations, and finally reaches 96.5% with high stability. The second is the algorithm in Ntalampiras. 8 The overall stability of the algorithm is relatively high and the distribution is relatively uniform, but the highest is not more than 90%, which is lower than the proposed algorithm. According to the algorithm propounded by Xu and Chen, 5 Kang et al., 7 and Gan et al., 9 objective function stability numerical value fluctuates, the change is large, the overall stability is not high, and the effect is not good. According to the analysis just mentioned, it can be seen that the algorithm performance in this article is better, which indicates that the structure of the data transfer network constructed in this article is stable and the algorithm completion effect is good.
In the case of different amounts of data, the time consumption of data transfer by different methods was compared. The shorter the transfer time, the higher the transfer efficiency of the method. The results are shown in Figure 5.

Time-consuming comparison results of different methods of data transfer.
According to Figure 5, in the existing methods, Xu and Chen 5 and Kang et al. 7 took up to 1.8 ms, Ntalampiras 8 took up to 1.5 ms, and Gan et al. 9 took a relatively low time, still reaching more than 1.3 ms. However, the proposed method takes up to 0.6 ms, indicating that the data transfer efficiency of the proposed algorithm is much higher than that of the existing method. In addition, the proposed algorithm grows with the amount of data, and the time consumption of the proposed algorithm increases steadily, thereby indicating that the increase in the amount of data has little effect on transfer efficiency. To sum up, the proposed algorithm shows good applicability. The comparison result of data transfer accuracy is shown in Figure 6.
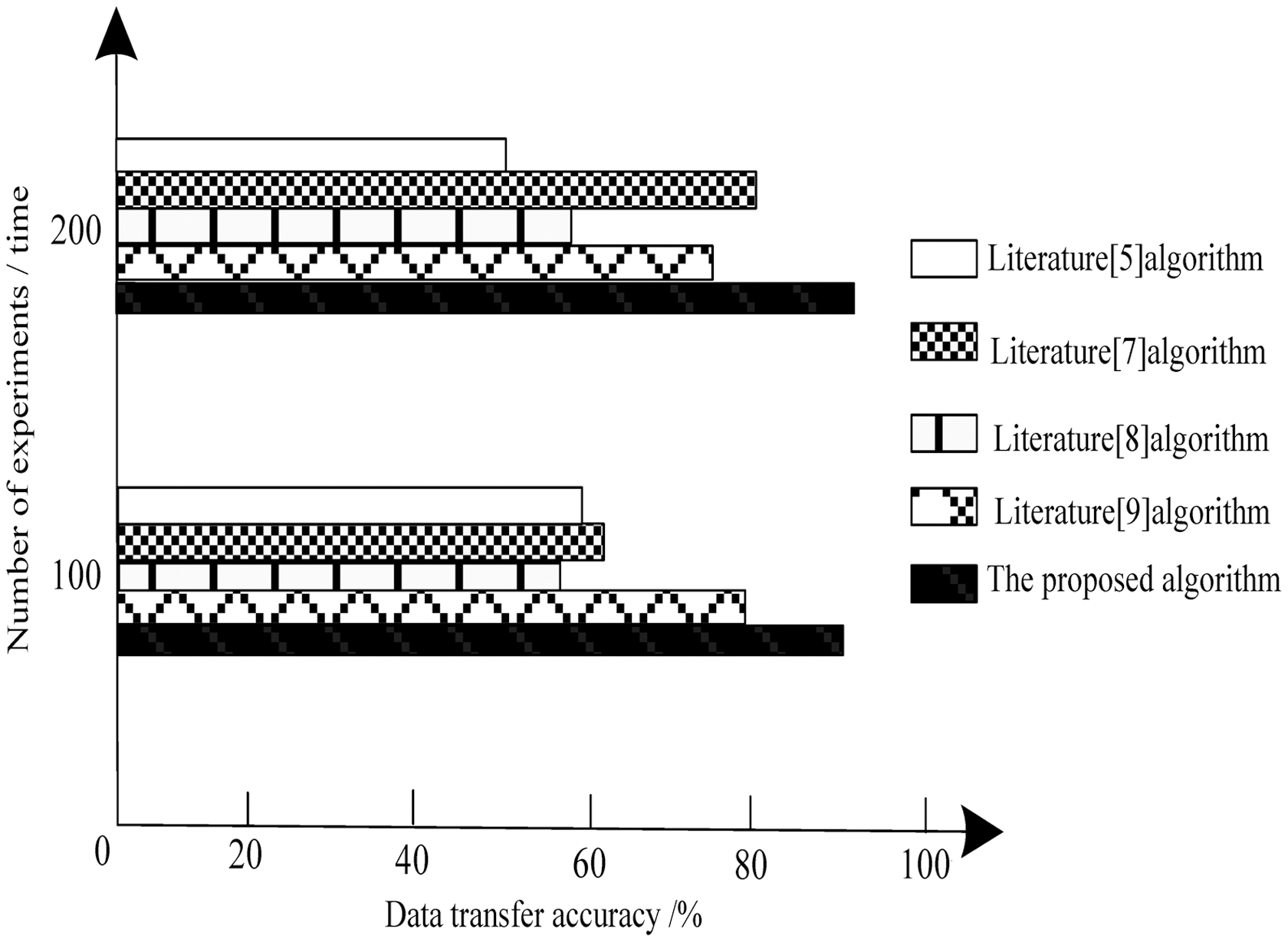
Data transfer accuracy.
According to Figure 6, the accuracy of the algorithm in Xu and Chen 5 and Ntalampiras 8 is not high in many experiments, less than 60%; the algorithm in Gan et al. 9 is relatively high, close to 80%; and the algorithm in Kang et al. 7 when the number of experiments is 100 times, the accuracy is low, the accuracy is higher when the number of experiments is 200 times, up to 80%. The data transfer accuracy of the proposed algorithm is always around 90%, which has significant advantages. This is because this study adopts the regularized discrimination method for data transfer, uses the regularized discrimination technology to construct the indirect category data transfer network structure, and obtains a better transfer effect. The comparison results of algorithm transfer energy consumption are shown in Table 3.
Algorithm transfer energy consumption
According to Table 3, with the increase of the number of iterations, the energy consumption of different algorithms shows an upward trend. The rising trend of the proposed algorithm in Kang et al. 7 and Gan et al. 9 is slow; however, the average energy consumption of the algorithms in Kang et al. 7 and Gan et al. 9 is higher, the energy consumption of the algorithms in Xu and Chen 5 and Ntalampiras 8 changes significantly, and the average energy consumption of Xu and Chen 5 is higher, which is 40.8 J. As a whole, the proposed algorithm presents a good state in terms of energy consumption and the stability of energy consumption numerical changes and has certain advantages. This is because the study first establishes the data transfer relationship, and then constructs the data transfer network structure, which increases the data and computing basis, and greatly improves the efficiency of the algorithm.
Conclusions
An indirect category data transfer learning algorithm based on regularization discrimination was proposed. First of all, indirect category data were preprocessed to keep the data ranges the same, and the transfer function between the indirect category data was completed by calculating the distance between the source domain and the target domain in the main direction. According to the indirect category data transfer network structure diagram, this study employed a regularization discriminant technique to divide the indirect category data transfer network structure into five modules. Second, by using the configuration of the indirect category data transfer network structure, this study analyzed the functions and advantages of the different modules and constructed the indirect category data transfer network structure. Finally, through the design of the indirect category data transfer learning algorithm, the indirect category data transfer learning was implemented. The results show that the data transfer learning algorithm based on regularization discrimination has a better data elimination redundancy effect, with stability, accuracy, energy consumption, and other aspects are better, which can be effectively applied in practice. To attain better research results, this study thus proposes an indirect category data transfer learning algorithm based on regularization discrimination. However, with the deepening of the research, it is found that although the proposed algorithm has verified the redundancy effect and stability of regularization discrimination on indirect category data, it is also characterized by relatively simple optimization attributes and high running cost. Therefore, it is necessary to further explore the problems of attribute weighting and cost control.
Footnotes
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This work was supported by the Humanities and Social Sciences Research Planning Fund Project in the Ministry of Education under grant no. 19YJAZH053, the Opening Fund of Big Data Application on Improving Government Governance Capabilities National Engineering Laboratory, the Opening Project of State Key Laboratory for Novel Software Technology under grant no. KFKT2020B18 and the Opening Project of State Key Laboratory of Digital Publishing Technology under grant no. cndplab-2020-M003, and Ministry of Education Science and Technology Development Center Industry-University Research Innovation Fund under grant no. 2018A01002.