
Abstract
At present times, financial decisions are mainly based on the classifier technique, which is utilized to allocate a collection of observations into fixed groups. A diverse set of data classifier approaches were presented for forecasting the financial crisis of an institution using the past data. An essential process toward the design of a precise financial crisis prediction (FCP) approach comprises the choice of proper variables (features) that are related to the issues at hand. This is termed as a feature selection (FS) issue that assists to improvise the classifier results. Besides, computational intelligence techniques can be used as a classification model to determine the financial crisis of an organization. In this view, this article introduces a new FS using elephant herd optimization (EHO) with modified water wave optimization (MWWO) algorithm-based deep belief network (DBN) for FCP. The EHO algorithm is applied as a feature selector, and MWWO-DBN is utilized for the classification process. The application of the MWWO algorithm helps to tune the parameters of the DBN model, and the choice of optimal feature subset from the EHO algorithm leads to enhanced classification performance. The experimental results of the proposed model are tested against three benchmark data sets, namely AnalcatData, German Credit, and Australian Credit. The obtained simulation results indicated the superior performance of the proposed model by attaining maximum classification performance.
Introduction
Financial crisis prediction (FCP) is important to any financial organization, which helps to minimize the future loss by estimation probable threats and evades novel credit offers if default risk is superior to an existing acceptance level. These methods are known as a credit default classifier model that denotes a client as “non-default” if he recompenses loan, or the client is denoted as “default.” Accuracy of the FCP performs an essential task for regulating the financial organization's production and success. For example, a minor positive modification in the accuracy level of a possible customer through defaulting credit would reduce the great upcoming losses of a firm. 1 FCP could be measured as a data classifier issue that mentioned a client as “non-default” if he recompenses the loan, or the customer is mentioned as “default.” 2
The classifier is defined as a supervised learning role in machine learning (ML) that decides a relationship among the features and classifier-labeled data. 3 Many investigations have been carried out on classifying FCP, happening from the year of the 1960s. In the former times, conventional techniques applied arithmetic roles to guess the financial crisis that distinguishes the monetary institute among powerful and feebler ones. In the 1990s, the attention has shifted to artificial intelligence (AI)-related techniques, such as neural network (NN) and support vector machine (SVM). In recent times, AI techniques are implemented for refining conventional classifier techniques, although the existence of several characteristics in the high-dimensional monetary data is the reason for several problems, namely low interoperability, high computational complexity, and overfitting. The dimensionality curse represents the sample count to determine an arbitrary function with a provided level of accuracy grows exponentially with respect to the number of input variables. The easier method for solving this problem is minimizing the existing features count using feature selection (FS) technologies.
FS method aims for identifying suitable features subset and has essential inferences for problems, namely (i) noise reduction through eliminating noisy features, (ii) cost consumption and computational time needed for developing a proper technique, (iii) reorganization resulting technique, and (iv) enabling easier access settings and updating techniques. The selected subset of features is convenient to signify classifier functions that influence many dimensions of classifiers such as learning duration, the accuracy of the classifier method, and cost cohesive with feature. 4 The FS technique is utilized in different applications, such as pattern recognition, ML, and data mining, to minimize the dimensionality of feature space and to increase the forecast accuracy of a classifier technique. 5 Based on the estimation norms, FS methods are spitted into the filter-, embedded-, and wrapper-based methods. 6 The wrapper technique employs a learning method as a calculation part for assessing the benefits of the chosen feature subset. However, the wrapper technique has few limits such as maximum calculation difficulty, determining the user-specified parameter of the learner, and inherent learner restrictions. Embedded techniques are calculation less difficult than wrapper technique; however, the selected subset of feature is incapable of the learning technique. 7 Due to such limitations, the filter technique is utilized in several models.
The filter technique calculates the subset of features by predefined metrics instead of the learning technique and selected features. The method of FS is measured as an optimization issue, 8 with a considered efficiency for each feature subset, which referred predicted classifier efficiency of the resulting technique. The issue is to achieve the subset of feature space for finding the best or nearly best method-based performance measure. Many techniques have been offered for determining the suboptimal results with lesser time consumption. Stochastic techniques such as simulated annealing, scatter search, ant colony optimization (ACO), and genetic algorithms are commonly applied for FCP to attain maximum precision rate.
This article introduces a new optimal FS using elephant herd optimization (EHO) with modified water wave optimization (MWWO) algorithm-based deep belief network (DBN) for FCP. The proposed model involves preprocessing, EHO algorithm-based FS, and MWWO-DBN-based classification. Once the EHO algorithm chooses the appropriate set of features from the preprocessed data, the MWWO-DBN model is applied to identify the proper set of class labels. The application of the MWWO algorithm helps to tune the parameters of the DBN model, and the choice of optimal feature subset from the EHO algorithm leads to enhanced classification performance.
Related Works
Recently, many research experiments have been performed for addressing FCP issues by exploiting the records of a banking institute. There are two kinds of FCP, namely structural and statistical methods. The structural method represents the dynamic of interest rates and organization norms to originate the usual possibility. In contrast, the statistical method absorbs the connection from facts rather than displaying it. The conventional statistical techniques are shown in the studies of Beaver, 9 Altman et al., 10 and Ohlson. 11 Ohlson employed logistic regression (LR) in the FCP domain. NN, logit analysis, and discriminant analysis (DA) are the common statistical devices for the FCP model, 12 where Altman Z-score is generally used in DA. 13 Currently, an artificial NN is a familiar tool in the predictive process. Van Gestel et al. 14 utilized least square SVM-based Bayesian kernel for modeling a classification model to corporations bankruptcy, and it detected that there is no clear variance among DA, LR, and SVM based on properly classified examples. Hu and Ansell 15 focused on American trade market credit prediction that used four techniques with SVM. The outcomes exposed that the classification has various classifier capabilities on kappa value and accuracy. Lee and Teng 16 planned a Mahalanobis–Taguchi system (MTS) technique that is carried out on multivariate deduction and performs FCP for Taiwan businesses. They equated the MTS outcomes with LR and NN for identifying effective FCP method.
Sun and Li 17 suggested an SVM ensemble technique for FCP, which is related to a specific SVM classification model. The result of the study exhibited that the SVM ensemble technique results in the specific SVM classification model. Lin et al. 18 applied SVM with traditional techniques and conveyed that the rankings of the method differ by means of accuracy and precision to Taiwan stock replace the corporation's information. Research of FCP in 107 Chinese corporations is performed with the help of data mining methods. 19 The stimulation outcomes addressed that NN is determined to be efficient than DT and SVM. In recent days, the metaheuristic technique was effectively utilized to resolve classifier issues.
For enhancing the efficiency of a data classification method, an FS model was established for identifying suitable feature subset. In the study by Etemadi et al., 20 genetic programming is utilized to the bankruptcy forecast method of Iran cooperation in the Tehran Stock Exchange. The comprehensive research on filter- and wrapper-dependent FS techniques is performed to acquire effectual FCP. At this point, two bankruptcy forecast and credit scoring data sets are used. The statistical outcomes described that GA and LR execute well compared with other techniques. In the study by Li and Zeng, 21 they planned a GA-based FS technique, which is appropriate for apps that involve maximum accuracy and less cost. The fuzzy entropy-based FS technique is suggested in the study by Shie and Chen 22 for handling the classifier issues. This fuzzy-based technique takes subsets of features for attaining maximum classifier accuracy. The fruit fly optimization techniques are associated with General Regression NN for developing an FCP technique. 23 The attained outcomes are related to General Regression NN and Multiple Regression NN. The projected technique is discovered to be effectual in means of convergence and classifiers capability.
A novel improved boosting known as FS-Boosting is given in the study by Wang et al. 24 with the FS technique. Using FS in boosting, the proposed technique performs better and achieves maximum accuracy and also assortment. Another concept of FS is found in the study by Lin et al., 25 which combines expert's familiarity and wrapper technique. At first, the financial norms are separated into seven sets and then the wrapper technique is employed to choose a subset of features. The investigational outcomes exhibited that the planned technique performed well than the conventional FS technique, which depends on classifier accuracy.
A new FCP model is presented in the study by Uthayakumar et al. 3 using ACO-based ant-miner technique. The performance of the model is assessed against both qualitative and quantitative data sets. Another FCP model utilizing the ACO algorithm has been presented. 26 The presented ACO algorithm involves the ACO algorithm for both FS and classification. In the study by Uthayakumar et al. 27 , a novel cluster-based classifier model for FCP has been presented, which involves improved K-means-based clustering and a fitness-scaling chaotic genetic ant colony algorithm (FSCGACA)-based classifier model. Initially, the improved K-means clustering technique discards the misclustered data. Afterward, a rule-based approach is chosen to make the design fit into the provided data set. Finally, the FSCGACA is applied to seek optimum variables of the rule-based model. Sankhwar et al. 28 introduced an effective FCP model using improved grey wolf optimization (IGWO) and fuzzy neural classifier. An IGWO algorithm is based on the integration of the grey wolf optimization (GWO) algorithm and the tumbling effect.
However, many FCP techniques have been recommended and determined in the literature; it is believed that there is a further scope to improve for even optimal forecast process. In review, the associated researches described in which the effectiveness of classifiers in FCP differs on the basis of performance measures and dissimilar data sets.
The Proposed Model
Figure 1 shows the working procedure involved in the presented model. As depicted in the figure, the input data are preprocessed in two stages, namely format conversion and data transformation. Next, the preprocessed data undergo FS using the EHO algorithm. Then, the feature reduced data are given as input to the optimal DBN-based classifier to classify the data into appropriate class labels. Besides, the performance of the DBN model is further improved by the use of the MWWO algorithm.
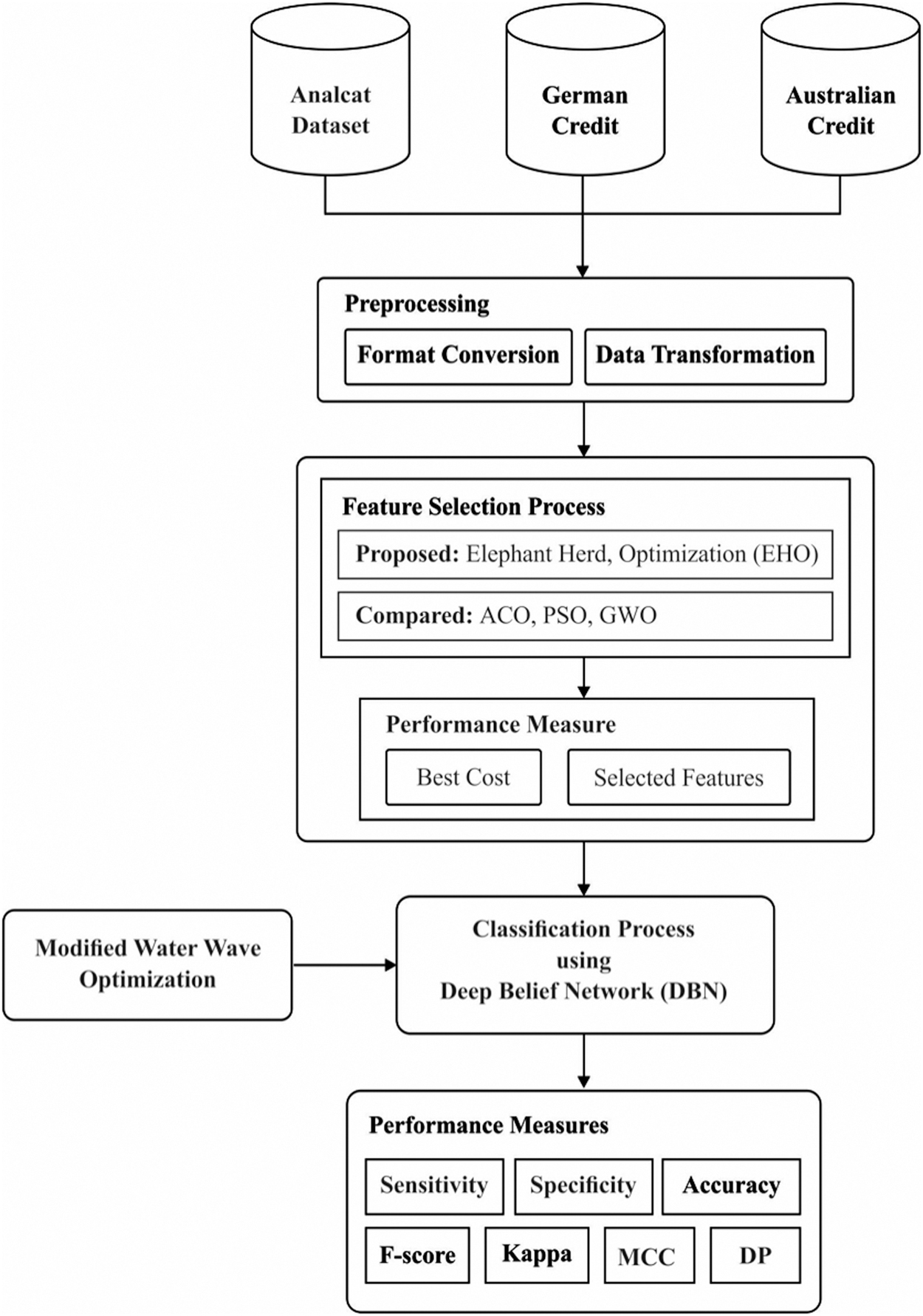
Overall process of proposed framework.
EHO-based FS process
Once the input financial data have been preprocessed, the next step lies in the selection of relevant features from the preprocessed data using the EHO algorithm.
EHO algorithm
A fundamental EHO algorithm is explained by utilizing the following principles
29
:
Elephants belong to various clans and live jointly lead by a fitting elephant. All clans have a count of elephants. During the use of modeling, it is considered that all clans include an equivalent unmodified count of elephants. The places of the elephants in a clan are efficiently depended on their connection for the fitting elephant. The mature male elephants (MEs) leave their family sets and live separately. It is considered that in all generations, a suitable count of MEs go away from their clans. Hence, EHO methods undergo the updating procedure utilizing a splitting operator. Usually, the matriarchs in all clans are the eldest female elephant (FE). During this function of modeling and resolving the optimized issues, the fitting elephant is regarded as the matriarch separate in the clan.
While these studies are focused on enhancing the EHO updating procedure, in the following subsection, it gives additional information about the EHO updating operator.
Clan updating operator
Consider that an elephant clan is indicated as cu. The subsequent positions of some elephants v in the clan are updated utilizing Equation (1), as given in the following:

where Pnew,cu,v is the updated position, Pcu,v is the prior position of elephant v in clan cu. Pbest, cu indicates the matriarch of clan cu and is the fittest elephant separately available in the clan. A scale factor
It must be noticeable that Pci, v ≟ Pbest, cu, implying that the matriarch (fittest elephant) in the clan could not be updated by Equation (1). For avoiding these conditions, it is updated by the matriarch utilizing the following equation:
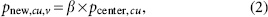
where the control of Pcenter, cu on Pnew, cu is normalized by

where
Separating operator
In the elephant clan, MEs go away from their family set and live separately upon getting puberty. During the procedure of partition, it is modeled into a dividing operator while solving optimized issues. To additionally enhance the explore capability of the EHO technique, it is assumed that the separate elephants with the bad fitness executed the splitting operator to all generations, as depicted in Equation (4).
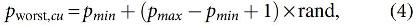
where
Operation of the EHO algorithm
In EHO, similar to the other metaheuristic techniques, a type of elitism approach is utilized with an aspiration of keeping the optimal elephant being from an individual ruined by the clan updating as well as dividing operators. Initially, the optimal elephant individuals are saved, and the worse ones are returned by the saved optimal elephant individuals at the end of the explore method. The elitism makes sure that the afterward elephant population is not forever worst than the previous one. Figure 2 shows the flowchart of the EHO method.
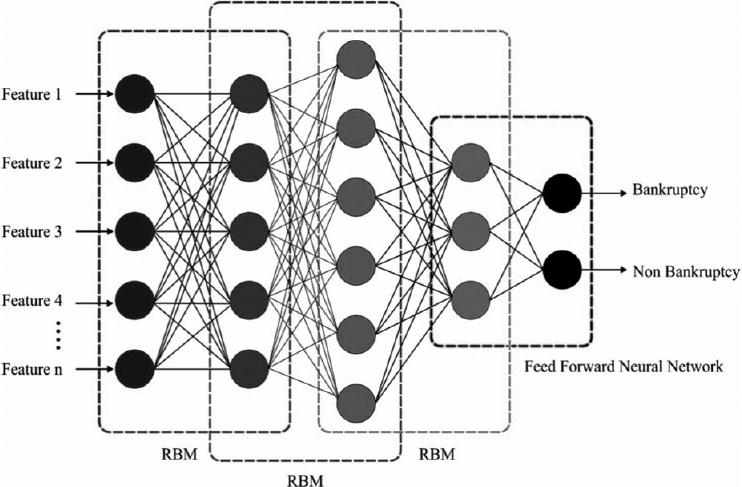
Structure of DBN. DBN, deep belief network.
EHO as a feature selector
In this study, EHO is utilized as an FS method for selecting a better subset of features out of every feature. An EHO explores the element space covetously and is frequently capable of determining the optimal feature subset for optimizing the provided input data. It can be utilized for enhancing the classifier outcome. Naturally, the elephant is also regarded as a social animal and the herd includes various clans of FEs and their calves. In the control of leader elephant or matriarch, the progress of all clans is determined. Some of the assumptions made are listed below 30 :
The population of elephants is separated into clans; all clans contain a set of elephants.
A set amount of ME goes away from their clan and lives separately.
All clans move in the leadership of a matriarch.
The set of matriarch influences the optimal result in the herd of elephants as the poor result is decoded from the position of the MEs. The updating process of the EHO algorithm has been depicted below. During the elephant position update stage, the position of all elephants in various clans is defined, but the matriarch and ME hold the optimal and worst results correspondingly. To all clans Ci elephants, all clans have “P” elephants. The position of ith elephant
Movement update of the fittest elephant of each clan
An elephant that goes distant from the set is utilized for modeling the searching process. All clans have a certain number of elephants, and it noticed that the worst evaluation of the goal work has been stimulated to the novel position.
Separating worst elephants in the clan
The worse elephant or ME is split from their family sets. In the clan separation operation, the bit is altered arbitrarily as multiplication is executed with the arbitrary number. When the possibility of arbitrariness is provided, the bit count needs to be modified in estimation. During the provided condition of EHO, all clan source is connected with a bit vector, as the vector is based on the entire count of features. Each feature is after estimated, and the feature that has the value of “1” is included in the subset of optimal features. This optimal feature set is fed into the classification method for enhancing the precision and performance rate of the presented method.
MWWO-based DBN model for classification process
The DBN is defined as a generative method that is composed of the input layer and the output layer, which is isolated by massive layers of hidden stochastic units. The multilayer NN could be trained effectively with restricted Boltzmann machines (RBMs) and feature activations of a single layer as training data for the next iteration. Figure 2 implies the instance of a DBN structure. 31 In general, DBN is composed of two types of diverse layers, namely the visible layer and hidden layer. Initially, visible layers are composed of input nodes and output nodes, and hidden layers are embedded with hidden nodes. A greedy layer-wise unsupervised learning method for DBNs is presented, which depends on sequence training using RBMs. An RBM contains two various layers of units with weighted connections. Moreover, it is composed of one layer of transparent nodes neurons and one layer of hidden units. The nodes present in all layers are not connected units in the alternate layer. The links from nodes are bidirectional and equal. RBM is applied as generative methods with various data types such as labeled or unlabeled images windows of mel-cepstral coefficients, which signify the audio, and so forth. The significant application is that learning objectives are constrained with deep belief nets.
Suppose vi and hj depict the states of visible node i as well as hidden node j, correspondingly. In the case of binary state nodes, where, vi and
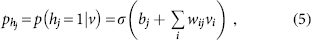
where

The training process of RBM is defined in the following. Initially, a training instance is provided to visible nodes and accomplished with
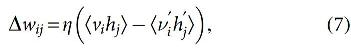
where
Water wave optimization algorithm
The water wave optimization (WWO) has been developed from shallow water wave methods to resolve the optimization problems.
32
Without any loss in generalization, a maximization issue exists in the objective function f. The resulting space U is meant to be the same as the seabed area, and fitness of a point
Propagation
Refraction
Breaking
For all generations, a wave should be transmitted accurately. The propagation operator deployed a new wave u′ by altering the dimension d of original wave x as provided in the following.
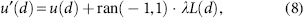
where ran ( -1,1) defines an arbitrary function, and
The propagation is determined with the help of fitness of offspring wave u′. If
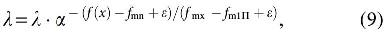
where
Refraction
In this approach, the refraction on waves is computed with limited heights to 0 and applies a simple model for determining the position after the completion of the refraction process:
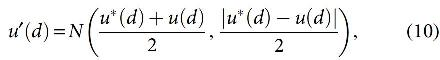
where u* showcases the best result, and

Breaking
When the wave moves to a position where the water depth is minimum when compared with the existing value, wave crest velocities exceed wave celerity. At last, a crest is highly effective and the wave is divided into pieces as a single wave. In the WWO algorithm, the major operation in a wave u is that it finds the best result and computes local exploring with u* to simulate the wave breaking. Also, k dimensions are arbitrarily chosen, where the dimension d generates a single wave u′ as provided in the following

where
MWWO algorithm
The existing works define that the optimal management between exploration and exploitation is extremely required for attaining the global and local exploring method in which searching procedure is restricted in the limited space. WWO model contains the demerits for smart technologies. Initially, when the local exploitation ability is said to be adequate, then global exploration is highly vulnerable. Then, WWO suffers from premature convergence; where the searching operation is trapped in local best to multimodal objective function, which leaves the diversity. To overcome these issues, applicable


where
Performance Validation
This section discusses the experimental results offered by the proposed model against three benchmark data sets.33–35 The AnalcatData data set comprises a set of 50 instances with 5 attributes and 2 classes. Next, the German Credit data set included a set of 1000 instances with 24 attributes and 2 classes. Similarly, the Australian Credit data set consists of a set of 690 instances with 14 attributes and 2 classes. For experimentation, 10-fold cross-validation process is applied.
Analysis of FS results
Table 1 lists the chosen features by the EHO-FS algorithm on the applied three data sets. The table values represent a set of four features that were chosen in the AnalcatData data set: working capital/total assets (WC/TA), retained earnings/TA, sales/TA, and book value of equity/book value of total liabilities. Besides, 12 features are selected from German Credit data set and 8 features from the Australian Credit data set.
Selected features of elephant herd optimization–feature selection algorithm on applied data set
Table 2 and Figures 3–5 provide a detailed comparative analysis of the EHO-FS with existing FS models under a varying number of runs in terms of the best cost. The best cost refers to the fitness value, which is obtained from the fitness function of the applied algorithm. The value of the best cost should be lower to yield better performance. The table values denote that the particle swarm optimization (PSO)-FS algorithm has resulted to be an ineffective performance by attaining maximum cost over the compared methods. Simultaneously, the GWO-FS algorithm has shown slightly better FS results over the PSO-FS algorithm. Although the ACO-FS algorithm has achieved near-optimal FS results, the EHO-FS algorithm is found to be an effective FS method over the compared methods.

Best cost analysis on AnalcatData data set.

Best cost analysis on German Credit data set.
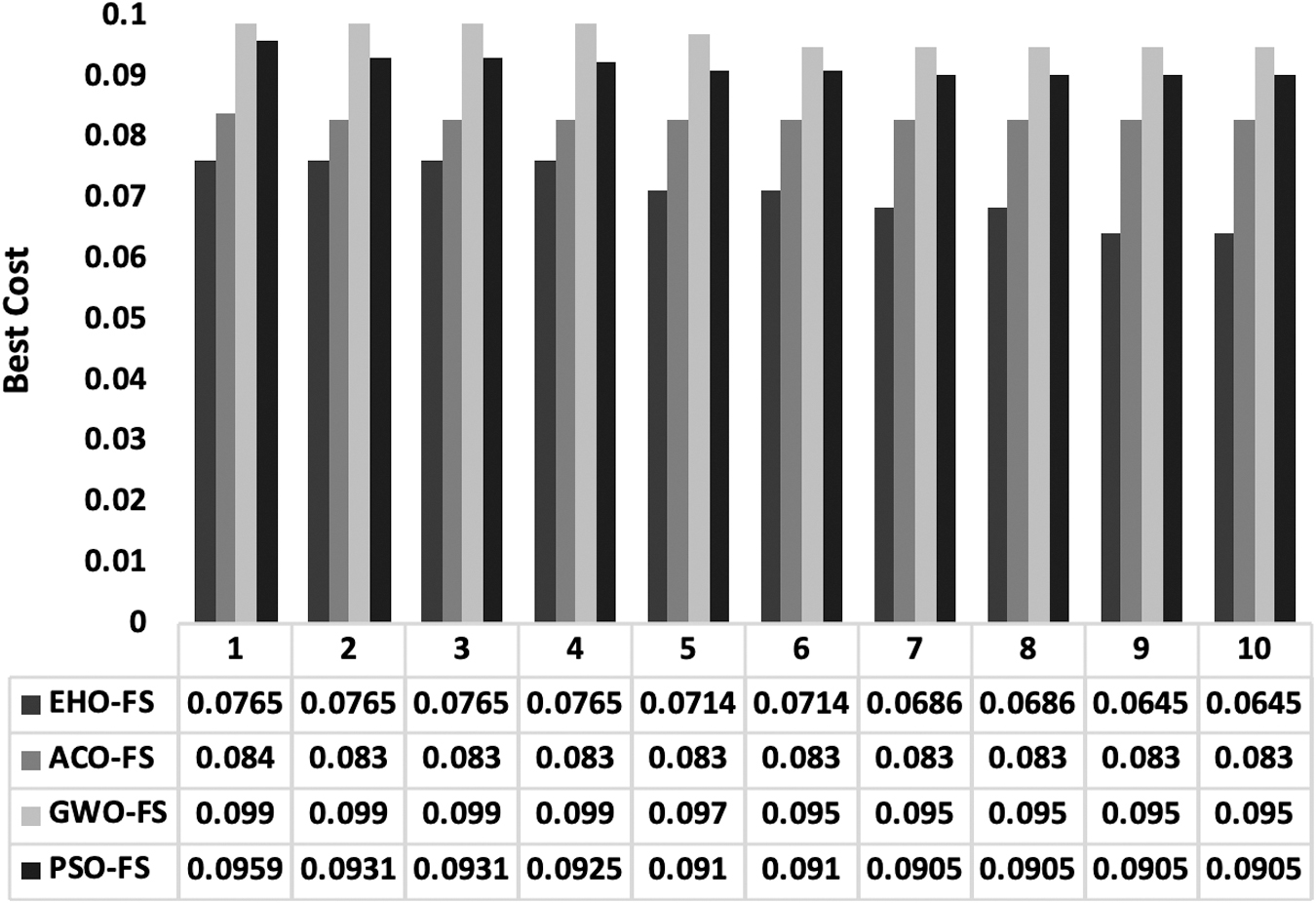
Best cost analysis on Australian Credit data set.
Results analysis of feature selection methods on applied data set
ACO, ant colony optimization; EHO, elephant herd optimization; FS, feature selection; GWO, grey wolf optimization; PSO, particle swarm optimization.
Analysis of classifier results
An analysis of the classification performance takes place in terms of different measures. The values of these measures should be closer to 100 for better performance. Table 3 provides the analysis of the classifier results by the MWWO-DBN model with existing methods on the AnalcatData data set. Figure 6 investigates the analysis of the classifier outcomes by the MWWO-DBN model in terms of different performance measures. The figure indicates that the AdaBoost model has exhibited worse classifier outcomes with a sensitivity of 65%, a specificity of 67%, and an accuracy of 65.83%. Also, the SVM model has shown slightly higher classifier results with the sensitivity of 76%, the specificity of 79%, and the accuracy of 77.43%. Besides, the multilayer perceptron (MLP) model has achieved even better classifier results with the sensitivity of 78%, the specificity of 80%, and the accuracy of 79.87%.
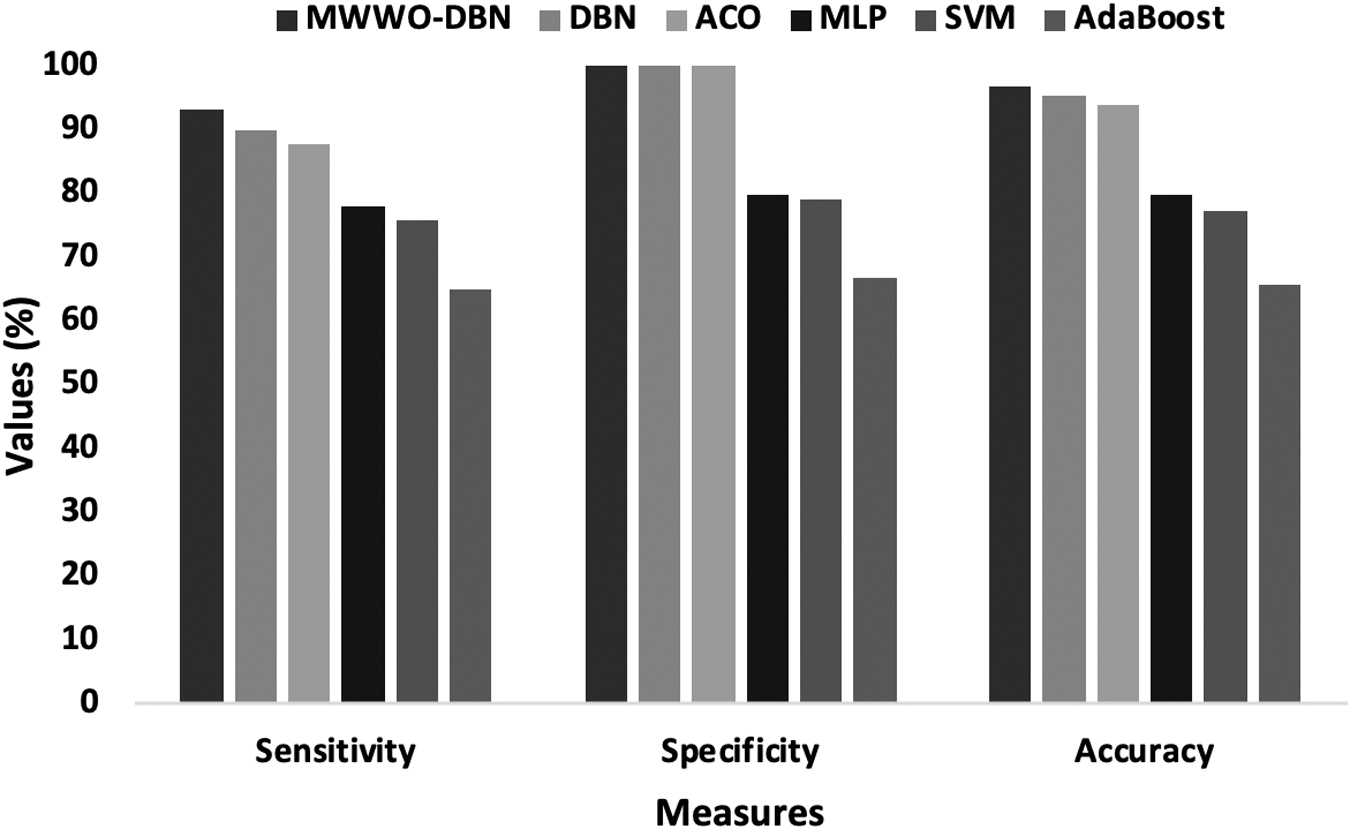
Comparative analysis of MWWO-DBN on AnalcatData data set. MWWO, modified water wave optimization.
Result analysis of proposed modified water wave optimization–deep belief network on AnalcatData data set
DBN, deep belief network; MLP, multilayer perceptron; MCC, Mathew correlation coefficient; MWWO, modified water wave optimization; SVM, support vector machine.
Moreover, the ACO algorithm has resulted in a moderate classifier outcome with the sensitivity of 88%, the specificity of 100%, and the accuracy of 64%. Followed by, the competitive classifier outcome with the sensitivity of 90.13%, the specificity of 100%, and the accuracy of 95.37% has been obtained by the DBN model, the MWWO-DBN method has demonstrated all the previous methods with the maximum sensitivity of 93.40%, the specificity of 100%, and the accuracy of 96.87%.
Figure 7 examines the analysis of the classifier results by the MWWO-DBN method with respect to diverse performance metrics. From the figure, it is evident that the AdaBoost approach has shown poor classifier outcome with the F-score of 65.82%, Mathew correlation coefficient (MCC) of 64.31%, and kappa of 64.24%. Followed by, the SVM approach has exhibited better classifier results with the F-score of 75.41%, MCC of 75.12%, and kappa of 75.02%. Followed by, the MLP technique has attained moderate classifier results with the F-score of 79.45%, MCC of 77.33%, and kappa of 77.21%. Furthermore, the ACO approach has showcased a gradual classifier outcome with the F-score of 93.61%, MCC of 88%, and kappa of 88%. Besides, a competing classifier result with the F-score of 94.56%, MCC of 90.23%, and kappa of 90.45% was accomplished by the DBN method, the MWWO-DBN technology has performed quite well than the existing frameworks with the highest F-score of 95.31%, MCC of 92.40%, and kappa of 92.98%.

Comparative analysis of MWWO-DBN on AnalcatData data set in terms of different measures.
Table 4 offers the analysis of the classifier outcomes by the MWWO-DBN approach with previous models on the German credit data set. Figure 8 examines the analysis of the classifier results by the MWWO-DBN model by means of various performance measures. From the figure, the result has implied the poor performance of the AdaBoost technique with the sensitivity of 70.45%, the specificity of 62.74%, and the accuracy of 66.54%. Besides, the SVM method has depicted moderate classifier results with the sensitivity of 71.38%, the specificity of 64.83%, and the accuracy of 69.42%.
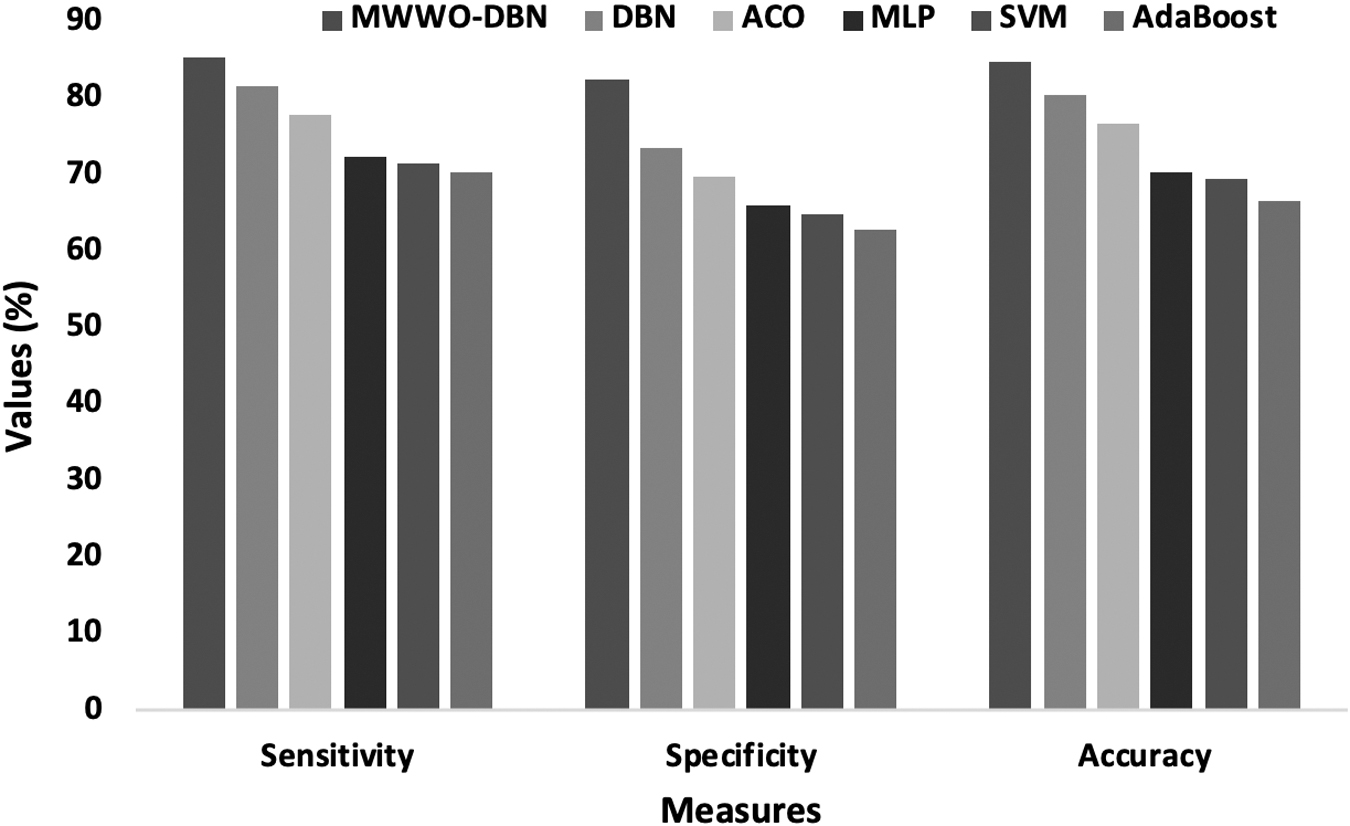
Comparative analysis of MWWO-DBN on German Credit data set.
Result analysis of proposed modified water wave optimization–deep belief network on German Credit data set
However, the MLP approach has accomplished considerable classifier results with the sensitivity of 72.44%, the specificity of 65.93%, and the accuracy of 70.31%. Furthermore, the ACO model has attained a manageable classifier result with the sensitivity of 77.93%, the specificity of 69.87%, and the accuracy of 76.60%. Besides, the comparative classifier result with the sensitivity of 81.46%, the specificity of 73.50%, and the accuracy of 80.46% was achieved by the DBN framework, the MWWO-DBN technique has performed in a superior manner when compared with the existing higher sensitivity of 85.38%, the specificity of 82.46%, and the accuracy of 84.74%.
Figure 9 demonstrates the analysis of the classifier outcomes by the MWWO-DBN method with respect to diverse performance metrics. From the figure, it is pointed out that the AdaBoost technique has showcased inferior classifier outcome with the F-score of 69.42%, MCC of 39.51%, and kappa of 26.98%. In addition, the SVM approach has showcased better classifier results with the F-score of 71.46%, MCC of 30.56%, and kappa of 28.40%. On the other side, the MLP scheme has accomplished moderate classifier results with the F-score of 73.40%, MCC of 32.49%, and kappa of 30.54%. Additionally, the ACO method has concluded with considerable classifier results with the F-score of 84.74%, MCC of 38%, and kappa of 36.13%. Besides, the symmetric classifier outcome with the F-score of 87.33%, MCC of 43.57%, and kappa of 42.93% was attained by the DBN model; the MWWO-DBN model has performed an outstanding process than the former approaches methodologies with the higher F-score of 89.92%, MCC of 51.09%, and kappa of 50.70%.
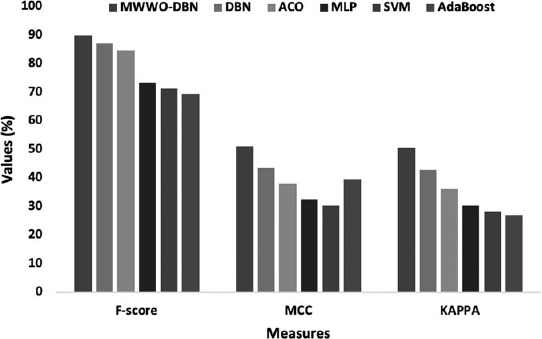
Comparative analysis of MWWO-DBN on German Credit data set in terms of diverse measures.
Table 5 offers the analysis of the classifier outcomes by the MWWO-DBN method with former models on the Australian Credit data set. Figure 10 examines the analysis of the classifier results by the MWWO-DBN model in terms of several performance measures. From the figure, it is portrayed that the AdaBoost approach has implied inferior classifier outcome with the sensitivity of 70.44%, the specificity of 68.47%, and the accuracy of 68.90%.
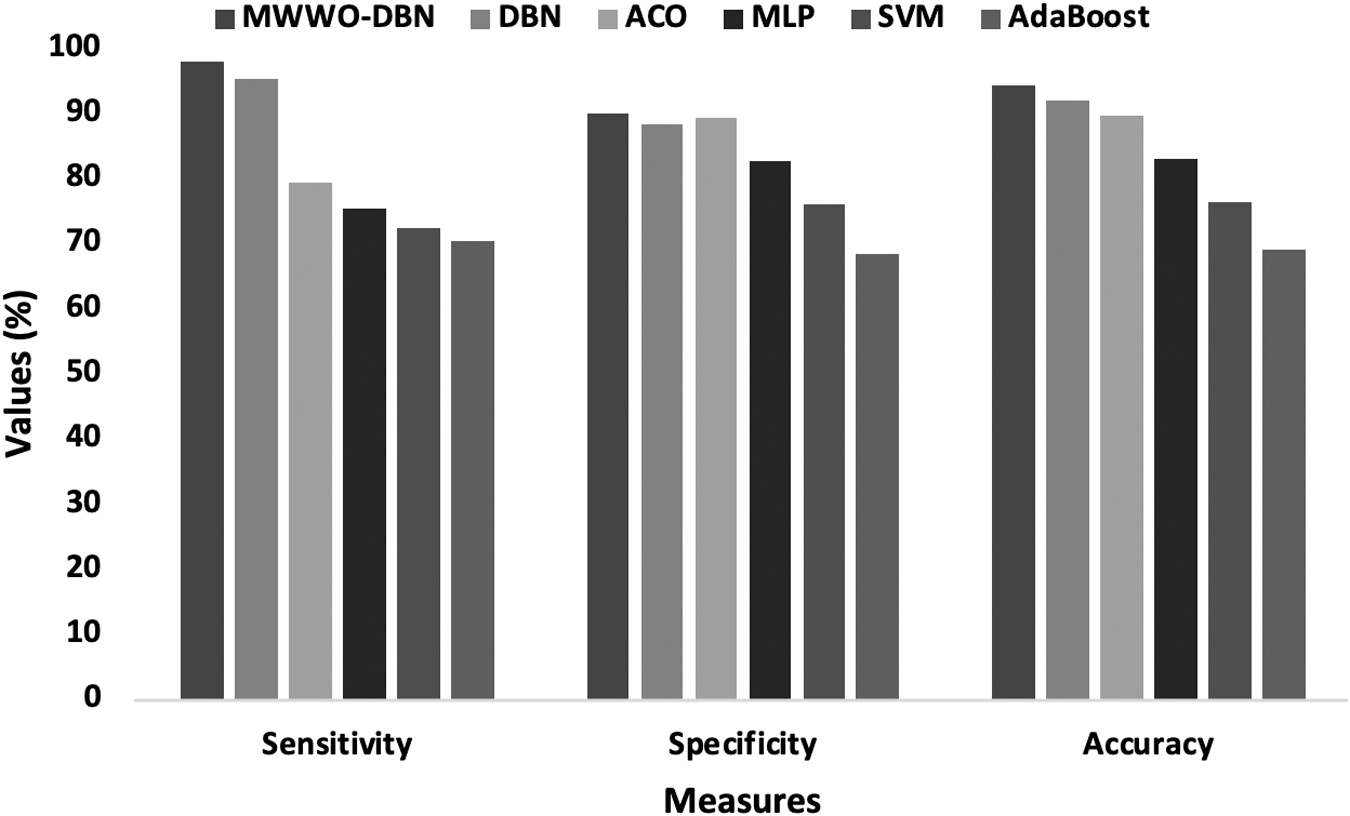
Comparative analysis of MWWO-DBN on Australian Credit data set.
Result analysis of proposed modified water wave optimization–deep belief network on Australian Credit data set
Moreover, the SVM technology has showcased better classifier results with the sensitivity of 72.48%, the specificity of 76%, and the accuracy of 76.28%. Followed by, the MLP model has accomplished far better classifier outcomes with the sensitivity of 75.33%, the specificity of 82.47%, and the accuracy of 83.04%. Furthermore, the ACO technique has ended up a gradual classifier result with the sensitivity of 79.41%, the specificity of 89.42%, and the accuracy of 89.49%. However, the competing classifier results with the sensitivity of 95.30%, the specificity of 88.41%, and the accuracy of 92.03% has been achieved by the DBN model, the MWWO-DBN method has exhibited quite well than existing approaches with the higher sensitivity of 98.03%, the specificity of 90.09%, and the accuracy of 94.20%.
Figure 11 examines the analysis of the classifier outcomes by the MWWO-DBN method by means of numerous performance metrics. The figure implies that the AdaBoost model has represented poor classifier outcome with the F-score of 67.41%, MCC of 60.66%, and kappa of 67.86%.
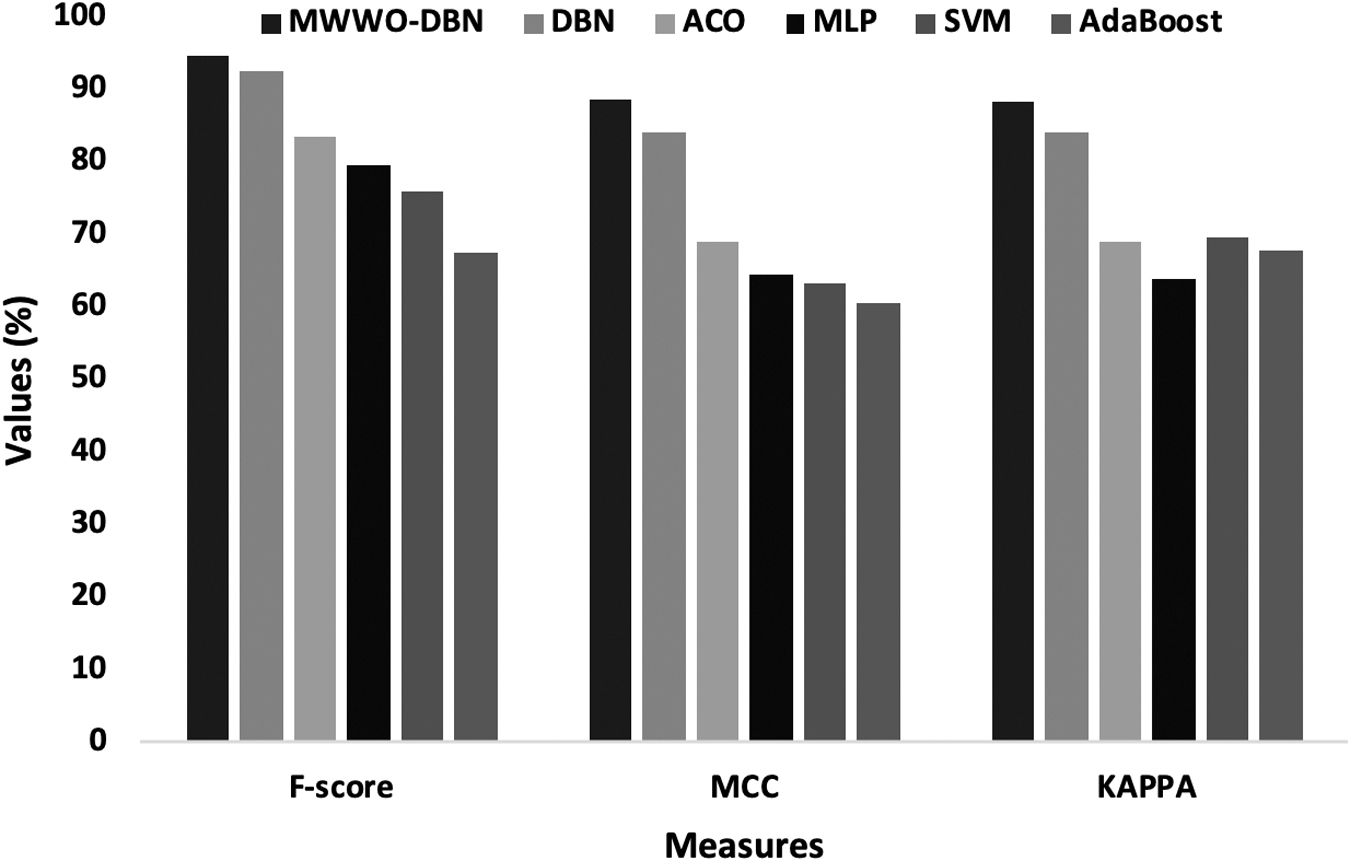
Comparative analysis of MWWO-DBN on Australian Credit Data set-II.
Additionally, the SVM technique has demonstrated better classifier results with the F-score of 75.84%, MCC of 63.13%, and kappa of 69.48%. Followed by, the MLP model has accomplished moderate classifier outcomes with the F-score of 79.52%, MCC of 64.59%, and kappa of 63.87%. Also, the ACO method has ended with a slightly better classifier outcome with the F-score of 83.46%, MCC of 69%, and kappa of 68.93%. Besides, the competitive classifier result with the F-score of 92.62%, MCC of 84.13%, and kappa of 84.06% has been accomplished by the DBN approach, the MWWO-DBN model has shown superior performance than existing frameworks with the higher F-score of 94.59%, MCC of 88.62%, and kappa of 88.36%.
Conclusions
This article has developed an optimal FS using EHO with MWWO algorithm-based DBN for FCP. At the initial stage, the input data are preprocessed in two stages, namely format conversion and data transformation. After that, the preprocessed data undergo FS using the EHO algorithm. Followed by, the optimal DBN-based classifier is utilized to classify the data into appropriate class labels. Besides, the performance of the DBN model is further improved by the use of the MWWO algorithm. The performance of the presented FCP model is tested against the benchmark data set, and the experimental results indicated the superior performance of the proposed model by attaining maximum classification performance. The experimental results stated the effective performance of the proposed model by attaining a maximum accuracy of 96.87%, 84.74%, and 94.20% on the applied AnalcatData, German Credit, and Australian Credit data sets. In the future, the performance of the presented model can be further improved by the use of feature reduction and clustering techniques.
Footnotes
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This research received no specific grant from any funding agencies.