
Abstract
The cross-lingual plagiarism detection (CLPD) is a challenging problem in natural language processing. Cross-lingual plagiarism is when a text is translated from any other language and used as it is without proper acknowledgment. Most of the existing methods provide good results for monolingual plagiarism detection, whereas the performances of existing methods for the CLPD are very limited. The reason for this is that it is difficult to represent the text from two different languages in a common semantic space. In this article, a novel Siamese architecture-based model is proposed to detect the cross-lingual plagiarism in English–Hindi language pairs. The proposed model combines the convolutional neural network (CNN) and bidirectional long short-term memory (Bi-LSTM) network to learn the semantic similarity among the cross-lingual sentences for the English–Hindi language pairs. In the proposed model, the CNN model learns the local context of words, whereas the Bi-LSTM model learns the global context of sentences in forward and backward directions. The performances of the proposed models are evaluated on the benchmark data set, that is, Microsoft paraphrase corpus, which is converted in the English–Hindi language pairs. The proposed model outperforms other models giving 67%, 72%, and 67% weighted average precision, recall, and F1-measure scores. The experimental results show the effectiveness of the proposed models over the baseline models because the proposed model is very efficient in representing the cross-lingual text very efficiently.
Introduction
The plagiarism means the unfair use of someone else's text/content without permission and proper acknowledgment. It is very unethical and a serious issue, mainly to maintain the academic integrity. The detection of plagiarism in monolingual languages is relatively easy and satisfactory results have been reported in the literature. However, when someone plagiarizes the content written in any other language and uses it after translation into another language, it is known as cross-lingual plagiarism detection (CLPD), and it is very difficult to detect such kind of plagiarism. CLPD is very challenging as the plagiarized content is in another language and there is no good way to represent the text in two languages in such a way that they are semantically close to each other. Recently, cross-lingual plagiarism has significantly increased due to easy access to the internet and advances in the translation systems.
The research in the detection of the cross-lingual plagiarism is very limited in the literature; however, it has emerged significantly in recent times since it is easy to copy the content from another language using translation software. 1 It is a very important yet challenging problem to improve ethical and honest practice in academics.
Plagiarism detection techniques broadly can be divided into the following two categories: (1) intrinsic plagiarism detection and (2) extrinsic plagiarism detection. When the plagiarism in the content is detected based on the author's writing style, it comes under the intrinsic plagiarism detection. Also, in extrinsic plagiarism detection, the documents are retrieved, from which the text might be plagiarized and then the similarity among these suspected documents and the targeted document is matched, and based on that, plagiarism is detected. Generally, the plagiarism detection task is considered paraphrase detection, and plagiarism is detected based on whether the given two sentences/documents have a significant amount of semantically similar content.
The paraphrase detection task is to determine the semantic similarity in the given sentence pairs and it detects them as paraphrase if they are semantically similar. Paraphrase detection is a critical and important task that is useful for many natural language processing (NLP) applications such as machine translation, summarization, plagiarism detection, and question answering.
In this article, the focus is on CLPD for English–Hindi language sentence pairs; the objective of the proposed model is to determine if the text written in one language is paraphrased with the text written in another language. The problem statement is described as to develop a model that can reliably determine an unannotated sentence pair as paraphrase or nonparaphrase, given a collection of K annotated sentence pairs in English and Hindi language He is going to the market to buy vegetables. वह सब्जी खरीदने के लिए बाजार जा रहा है
In this article, a deep learning-based approach is proposed that produces competitive results for CLPD systems. The proposed model can be divided into two components. The first component encodes the input sentences into a semantic feature vector using the Siamese architecture. The proposed Siamese network consists of an embedding layer, bidirectional long short-term memory (Bi-LSTM) network, and convolutional neural network (CNN). The Siamese network shares the weights with both of its subnetworks. In this model, first, the input texts are represented using word embeddings. Furthermore, the output is fed into the CNN and Bi-LSTM networks in sequence to encode the whole sentence, where the CNN includes the local context information and the Bi-LSTM network includes the global context information of the sentence.
In the second component of the proposed model, the feature vector is formed by computing the element-wise subtraction from the encoded sentence representation of the sentence pairs of different languages, which is further used to train the neural network to learn the semantic similarity in the given sentence pairs.
The main contributions of this article are as follows.
A Siamese network-based model is proposed for the detection of cross-lingual plagiarism in English–Hindi language pairs.
A detailed empirical study is presented showing different deep neural network-based models for the CLPD task.
The hyperparameter tuning of the proposed model is also presented in the article that shows the robustness of the proposed model.
The article is organized as follows. In the Related Work section, the related work concerning paraphrase detection is detailed in general and further specific to the cross-lingual paraphrase detection. In the Materials and Methods section, the details of the proposed model are described; furthermore, different variants of the proposed models are described in the Variants of the Proposed Approach section. In the Experimental Setting section, the experimental setting is described and Results and Discussion section are presented in detail. Finally, the Conclusion and Future Work section concludes the article along with outlining the future research directions.
Related Work
There is a significant amount of research in the literature for the monolingual paraphrase detection mostly for the English and Chinese languages. Most of these existing approaches are based on handcrafted features and were evaluated on the Microsoft Research Paraphrase (MSRP) data set. Existing machine learning algorithms such as support vector machine, neural network, and logistic regression were trained on handcrafted features such as n-gram overlapping,2,3 WordNet similarity, syntactic features, 4 common words in a given pair of sentences, Wikipedia-based similarity measures, 5 and part-of-speech (POS) tag-based similarity metrices. 6 However, in recent times, the deep learning-based approaches are achieving state-of-the-art results for plagiarism detection due to better representation of the text.7,8
It is evident in the literature that there is very limited research in the literature for CLPD especially for English–Hindi language pairs. Mostly, the existing methods are based on linguistics features (such as syntactic relations among words) for CLPD. The performances of such models are limited due to very poor textual representation of words of different languages in a common representation space. A traditional approach for CLPD is that one language text is initially translated into another language, and then, the monolingual plagiarism detection technique is applied. These models did not perform well due to error in the machine translation.
Danilova 9 proposed CLPD models based on various features such as machine translation, dictionary-based, syntax-based, and comparable corpora-based models. Potthast et al. 10 proposed a detailed analysis of various CLPD methods based on character n-grams, explicit semantic analysis, and alignment-based similarity features based on statistical machine translation. Kumar and Das 11 presented the CLPD approach for English–Hindi language pairs for news articles. Kothwal and Varma 12 proposed three approaches for the detection of text reuse of English language documents in the Hindi language, based on stemming and keyphrase-based approach. Gupta and Singhal 13 also presented an approach for text reuse of English documents in the Hindi documents. They first transformed the Hindi documents in English documents using WordNet, transliteration, and bilingual dictionary. Furthermore, authors used the probabilistic model, Okapi BM25, for identifying the similarity among the given sentence pairs.
Franco-Salvador et al. 14 presented a graph-based approach for CLPD using a multilingual semantic network that compared the text of different languages. Haneef et al. 15 presented an approach to develop a parallel corpus for the detection of cross-lingual for Urdu–English language pairs. Barrón-Cedeño et al. 16 also presented three architectures for plagiarism detection across different languages based on similarity estimation-based models such as cross-language alignment, cross-language character n-grams, and translations. El Mostafa and Benabbou 17 presented a detailed comparative study of monolingual plagiarism detection, and concluded that most of the existing research focused on the word level information and used word2vec-based representation; the main limitation of such models is the incorporation of semantic knowledge in the models. Majority of the existing work in the literature used conventional machine translation-based methods for detecting cross-language plagiarism.
In recent times, deep learning-based CLPD is gaining more momentum due to better representation learning techniques with the help of Word2Vec and Glove methods. In line with this, Vulić and Moens 18 proposed a deep learning-based approach in which authors used skipgram with negative sampling technique to learn word representation from the aligned comparable documents. Ferrero et al. 19 also presented a new CLPD technique for the English–French language pairs using word embedding-based text similarity and syntax similarity measures. They show that their hybrid approach outperforms other methods based on cosine similarity on syntactically weighted representation. Ehsan et al. 20 presented a two-step CLPD approach for English–Spanish language sentences based on dynamic text alignment using machine translation.
Shuang et al. 21 showed that the deep learning-based models rely on unique word vector representation, however, such methods do not consider the context; the authors addressed this problem by incorporating information of polysemy for better understanding of the problem, and they proposed a convolution–deconvolution-based word embedding model that incorporates the context-specific and task-specific information. Bakhteev et al. 22 proposed CLPD based on the deep learning technique and machine translation for the English–Russian language pairs. They first translated the Russian documents into the English language using machine translation, and then they detect plagiarism in the source documents using deep learning-based techniques. Ratna et al. 23 proposed CLPD for the English and Bahasa Indonesia languages using linear vector quantization classifier in a latent semantic analysis model.
Zubarev and Sochenkov 24 presented a data set for CLPD for the Russian–English language pairs, and compared different models such as the first approach was based on semantic similarity of text using word embeddings, another approach was based on the machine translation-based features, and another model was based on the pretrained language representation such as the bidirectional encoder representation transformer.
Franco-Salvador et al. 25 proposed a new hybrid approach for the English–Spanish and English–German language pairs using knowledge graphs and continuous space representation. Most of the existing works for CLPD rely on massive bilingual corpora, which are quite resource intensive. Chang et al. 26 address this issue and present a new CLPD method based on word embeddings that require a small set of translation pairs and which further computes the semantic distances among texts using word mover's technique. Alzahrani and Aljuaid 27 presented novel techniques for plagiarism detection in cross-lingual settings using deep neural networks with various combinations of features, such as topic similarity, bag-of-words, frequent n-grams, and named entity-based features. Moreover, they used BabelNet and WordNet semantic networks for computing the semantic distance among the texts of different languages.
Siamese architecture has shown success in various NLP applications mainly in measuring text similarity in the given sentence pairs. 28 Jonas and Thyagarajan 28 recently proposed a Manhattan LSTM deep learning architecture to learn the semantic similarity between any given sentence pairs for the English language. They initially encode the given sentence pairs using LSTM networks with shared weights; furthermore, they compute the Manhattan distance in both the encoded representations, used to train the neural network. Zhoulin and Jian 29 proposed a hybrid plagiarism detection model by combining the Siamese LSTM network and MatchPyramid model showing competitive results on the Quora duplicate question data set. A quite similar Siamese LSTM model is proposed by Benajiba et al. 30 to predict the similarity score of a given question to the question corpora.
Pontes et al. 31 proposed a hybrid approach that combines the CNN and LSTM networks in Siamese architecture for sentence similarity task. Neculoiu et al. 32 presented an approach for learning similarity in text based on variable-length character sequences; their model is a character-level Siamese bidirectional LSTM architecture. Agarwal 1 presented a survey of various techniques for CLPD for the English–Hindi language pairs.
It is evident from the literature that the existing work in CLPD is very limited especially for the English–Hindi language pairs. Most of the existing work using Siamese architecture is reported only for the English language. In this article, the focus is on developing efficient CLPD in the English–Hindi languages based on Siamese architecture.
Materials and Methods
The central idea of the proposed model is that the network learns the similarity between any given two sentences, if the semantic similarity among the given sentences is high, the predicted output will determine the sentence pairs as paraphrase. The Siamese network has two identical network models; each has one sentence as input, and they share the weights during training. In the proposed approach, the Siamese network is used to learn semantic similarity, and the Siamese network consists of the CNN and Bi-LSTM networks. This model is named as SiaCNN-BiLSTM. The Siamese network initially represents the input sentence in the semantic embedding, and then, the CNN model is applied to learn the local region information in the given text; furthermore, the Bi-LSTM is applied to learn long distance information among the words.
Furthermore, element-wise subtraction is computed of the final representations of the English and Hindi language sentences, which is further fed into the fully connected neural network to learn the similarity between two given sentences. The overview of the proposed model is shown in Figure 1.
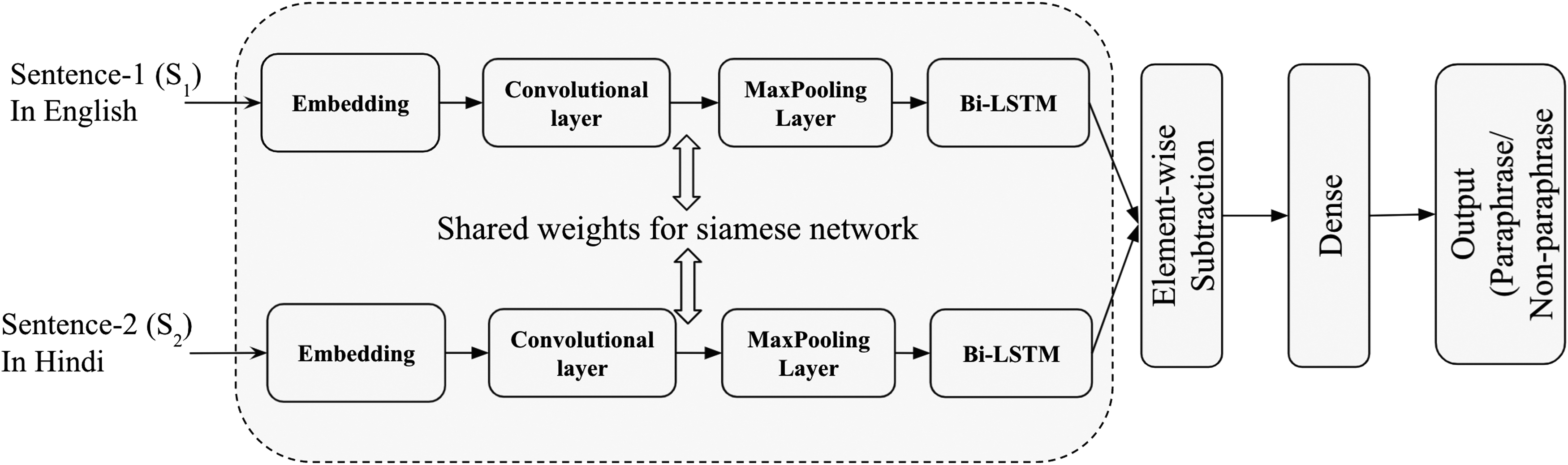
The proposed SiaCNN-BiLSTM architecture for cross-lingual plagiarism detection model. SiaCNN-BiLSTM, Siamese convolutional neural network-bidirectional long short-term memory.
The proposed model consists mainly of the following two components: (1) Siamese network and (2) fully connected network.
The inputs to the models are the English and Hindi language sentence pairs, words in each of these sentences are required to be converted into a feature vector. We represent these sentences using the embeddings of each of the words. More specifically, the input to the Siamese network model is one sentence from different languages (English and Hindi) for each subnetwork, transformed into an embedding matrix:
Here,
The LSTM is a variant of recurrent neural network, which overcomes the gradient vanishing problem. An LSTM unit consists of three main gates, namely input gate (
Here, the
The Bi-LSTM network is trained in two directions, that is, one is from left to right direction (forward states), and the other is from the right to left direction (backward states); furthermore, the output of both these states is concatenated to create a feature vector. With these two directions, the network learns the patterns from the past time stamp to future time stamp, and in the reverse direction, the network also learns the patterns of future time stamp information with the past information.
The final semantic representations are obtained for the sentence pairs using the Siamese network. Furthermore, the element-wise subtraction is computed of the final distributional representation of each of the sentences to produce a feature vector. This feature vector is representative of the similarity of the given sentence pairs which is further used to train the fully connected neural network. The overall end-to-end network is able to determine whether the given sentence pairs are paraphrase or not.
Variants of the Proposed Approach
To evaluate the robustness of the proposed model, different variants of the proposed model are also experimented and evaluated. The main component of the proposed model is the Siamese network, which is a combination of the CNN and Bi-LSTM networks. In this article, three different variants of the proposed model are developed by changing the Siamese network, namely SiaLSTM, SiaCNN, and SiaBiLSTM, which are based on LSTM, CNN, and Bi-LSTM network architectures, respectively. The details of these models are described in detail in the following subsections.
SiaLSTM model
The SiaLSTM CLPD model consists of a Siamese LSTM network with shared weights, as shown in Figure 2. In this model, initially, words in the given sentences are represented using distributional word embeddings. Furthermore, the LSTM network is trained on the given input word sequences. The weights of the LSTM network for each sentence are shared during training the model. Furthermore, the last hidden sequence of the LSTM unit is taken as the final representation of the input sentence. Finally, the feature vector is constructed by taking the element-wise subtraction of the final encoded representation of the input sentences from the Siamese network. The obtained feature vector is further used to train the fully connected neural network.
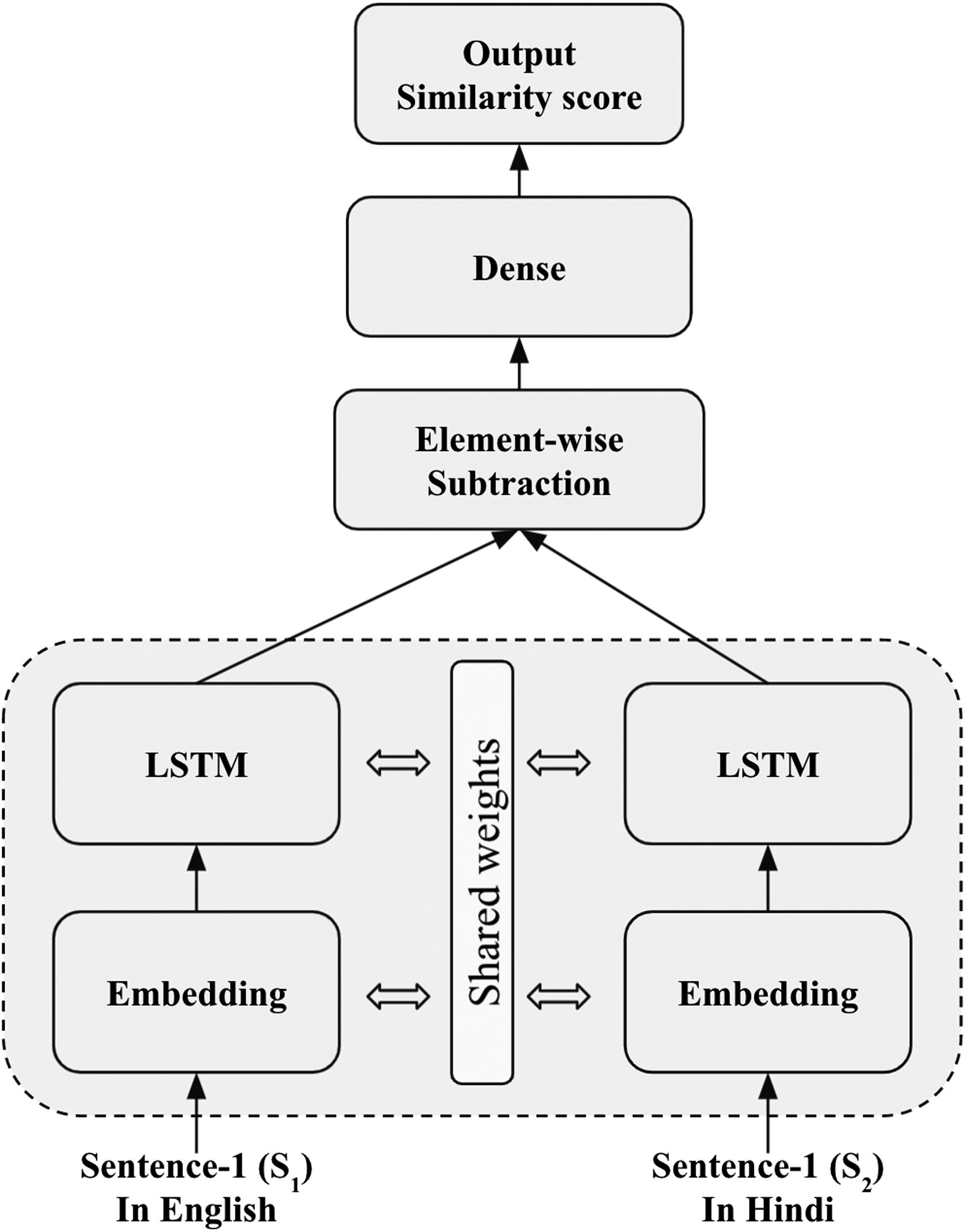
The SiaLSTM network architecture for cross-lingual plagiarism detection. SiaLSTM, Siamese long short-term memory.
SiaBiLSTM model
The Siamese learning-based CLPD model for the English–Hindi language pairs, namely the SiaBiLSTM model, is based on the Bi-LSTM network, as shown in Figure 3. This model is very similar to the SiaLSTM model discussed in the previous subsection; the only difference is that in this model, the Bi-LSTM network is used instead of LSTM network. In Bi-LSTM, the network is trained in two directions, that is, forward direction (the past context to the future context information is learned) and backward direction (the future context information to the past context is learned). The information learned in forward and backward directions is concatenated to form the final representation of each of the sentences. Finally, the element-wise subtraction of the final representation of both the sentences is computed to obtain the feature vector, which is further used to train the overall network architecture.
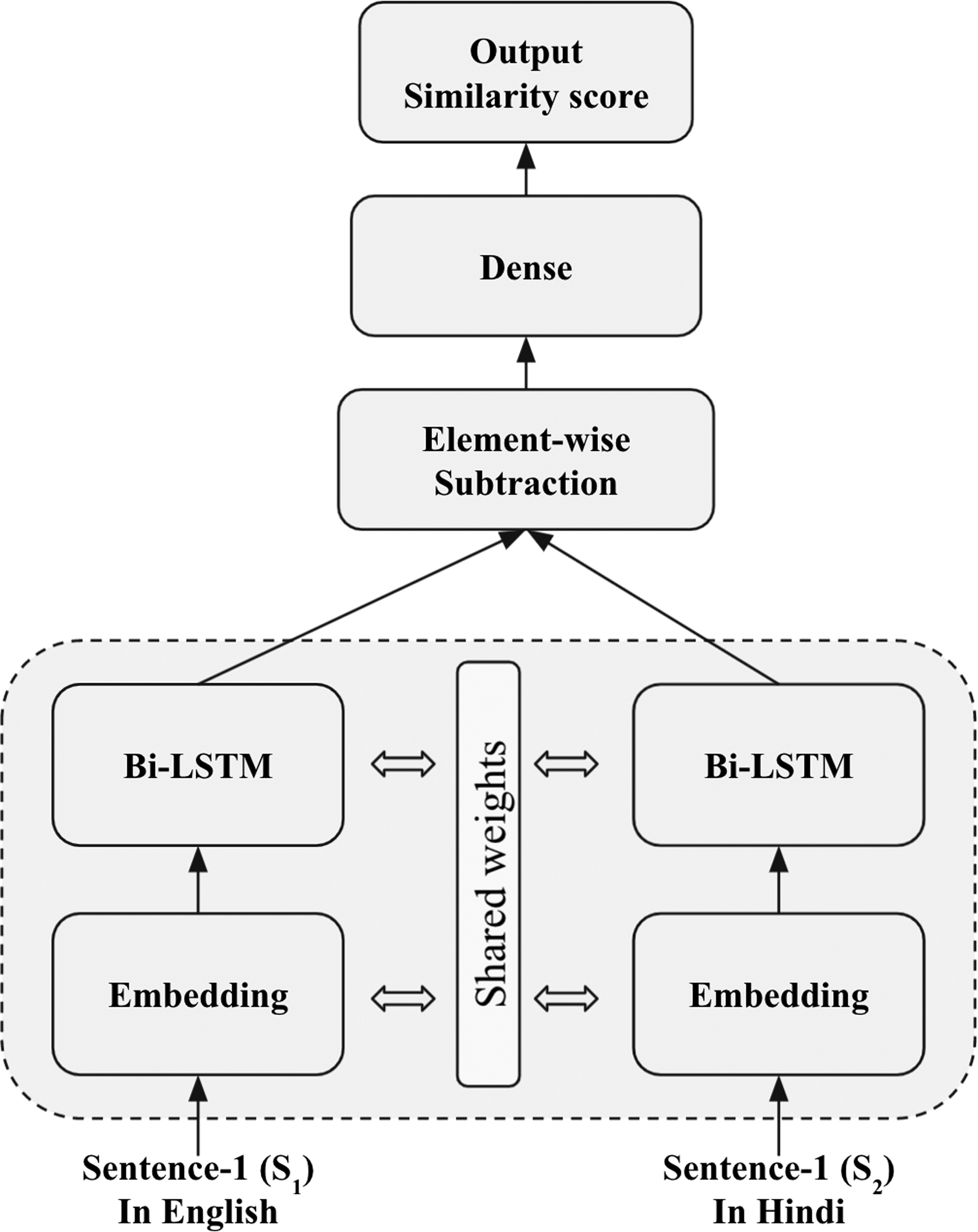
The SiaBiLSTM network architecture for cross-lingual plagiarism detection. SiaBiLSTM, Siamese bidirectional long short-term memory.
SiaCNN model
The SiaCNN CLPD model is composed of the CNN in Siamese learning settings, as shown in Figure 4. The Siamese network is constructed using CNN, in which the weights are shared. In this model, initially, the input sentences are represented using embeddings. The CNN layer is applied with different filter lengths and sizes. Next, two CNN layers are stacked to extract high-level features. Furthermore, the global-max-pooling layer is applied to keep the high activation information (important information). Finally, the feature vector is constructed by computing the element-wise subtraction of the final representation of both the sentences.
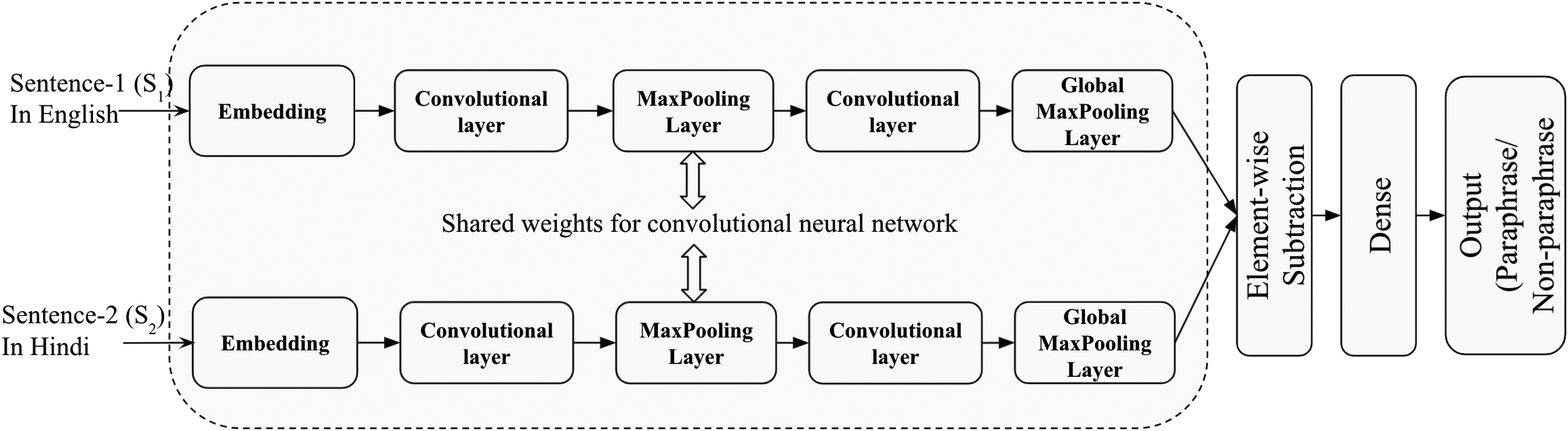
The proposed SiaCNN architecture for cross-lingual plagiarism detection.
Experimental Setting
The performance of the proposed models was evaluated using the benchmark data set, MSRP, for paraphrase detection in the English language. This data set is also used for evaluation of the CLPD models. To evaluate the CLPD using this data set, first it is transformed in such way to make it suitable for plagiarism detection in cross-lingual settings for the English–Hindi language pairs. For this, one pair of the MSRP data set is translated into the Hindi language using the Google translator, while keeping the other pair as it is. All the sentence pairs in this data set are converted in such a way that each sentence is translated into the Hindi and English language.
More specifically, initially, the original data set has 4076 training sentence pairs, in which first, the first sentence of the pair is taken and converted into the Hindi language and is prepared for the training purpose; likewise, afterward, the second sentence of the pair is translated into the Hindi language using Google translator to prepare the training sentence pairs. In this way, the training data set has double instances compared with the original MSRP data set. The statistics of the data set is given in Table 1, and it contains 8152 sentence pairs for the training the model, and 1725 pairs for testing. The length of sentences in this data set varies from 7 to 35 words, having 21 average numbers of words in the sentence.
The statistics of the Microsoft Research Paraphrase data set
To evaluate the performance of the proposed models, the precision, recall, and F1-measure scores are used as performance measures to compare the performance of various models. Precision (p) is computed as given in Equation (7).
Here, the
Furthermore, the F1-score (F1) is computed as the harmonic mean of precision, and recall is computed as in Equation (9).
The weighted average scores are used and reported in the article to measure the performance of the proposed models since the data set is not balanced.
Hyperparameter tuning
The performance of the deep learning-based models depends on the optimal set of hyperparameters, which are determined using grid-search parameter optimization technique. The reported results are obtained with optimal parameters using the grid-search method for all models. The best combination of the hyperparameters for the proposed model (SiaCNN-BiLSTM) is presented in Table 2. The performance of the proposed models is also shown on different values of the hyperparameters, to show robustness of the proposed model, as shown in Figures 5–7. The performance of the proposed model does not vary much with varying the different hyperparameters, thus showing the robustness of the proposed mode.
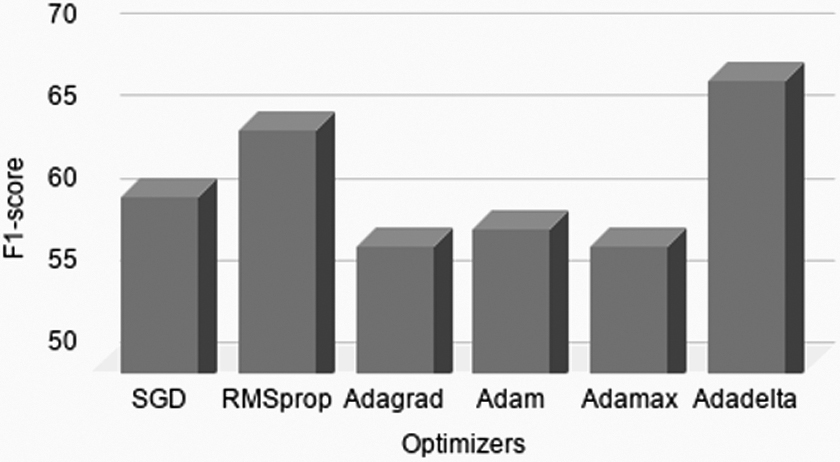
Variation of F1-score with different optimizers in the proposed model.
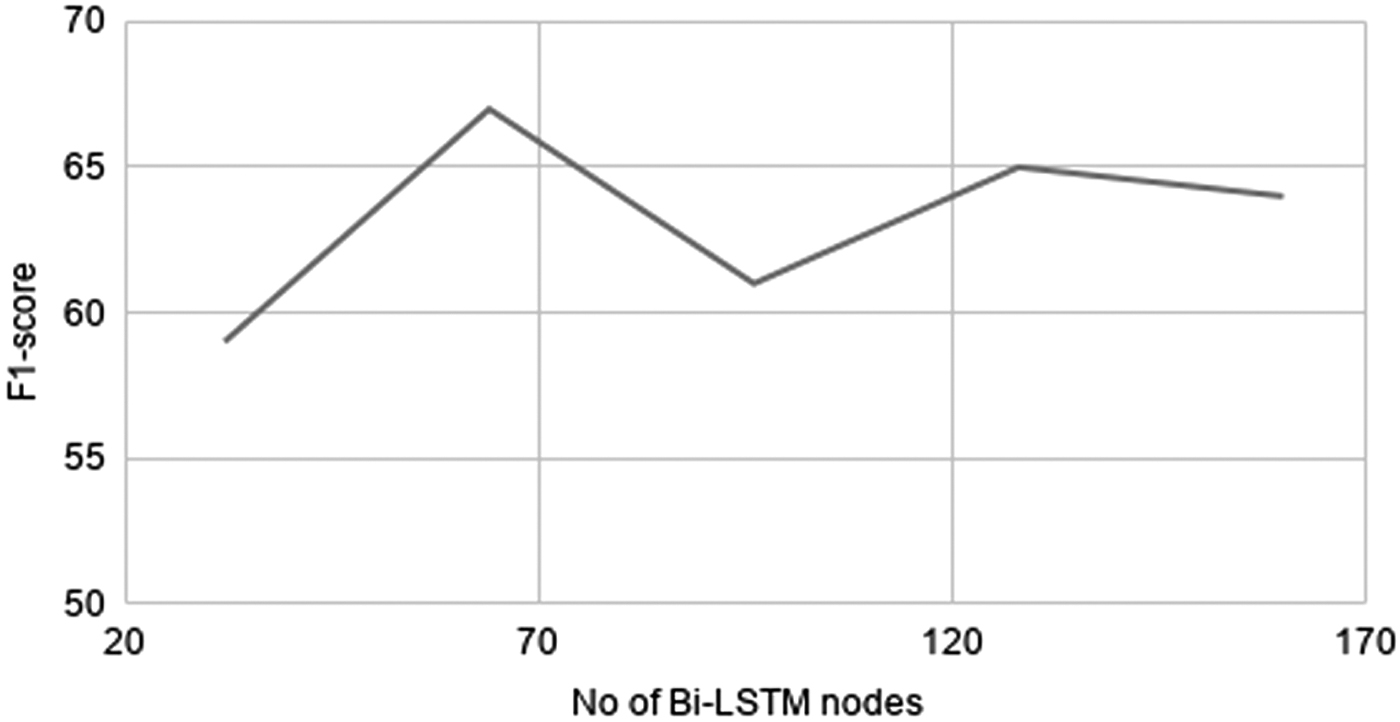
Variation of F1-score with number of Bi-LSTM nodes in the proposed model. Bi-LSTM, bidirectional long short-term memory.

Variation of F1-score with number of filters in the proposed model.
Hyperparameters for the proposed model Siamese convolutional neural network bidirectional long short-term memory network
Bi-LSTM, bidirectional long short-term memory.
Results and Discussion
The results of different models are shown in Table 3 with respect to the weighted average precision, recall, and F1-score. To compare the proposed deep learning models, different deep learning-based models are developed such as CNN and LSTM, Bi-LSTM, and hybrid networks (combination of CNN and Bi-LSTM). The proposed deep learning-based models with different traditional classifiers such as support vector machines, naive Bayes, and decision tree are not compared because there is no way to construct the feature vectors in different languages using features such as statistical counts of occurrences of words, common number of words, and common specific POS tags to develop traditional machine learning models. All the proposed deep neural network architectures are trained in two different settings, that is, with Siamese architecture and without Siamese architecture. All the deep learning-based models without Siamese architecture-based learning are taken as baseline models for CLPD.
Results of various models for cross-lingual plagiarism detection on Microsoft Research Paraphrase data set
CNN, convolutional neural network; LSTM, long short-term memory; SiaBiLSTM, Siamese bidirectional long short-term memory; SiaCNN, Siamese convolutional neural network; SiaLSTM, Siamese long short-term memory.
It can be observed from the results shown in Table 3 that the LSTM performs better than CNN since LSTM gives an F1-score of 62% compared with 60% given by CNN. The LSTM network learns the sequence of words in the sentences, whereas CNN learns the local patterns, and thus, LSTM is providing a better performance for this task. Furthermore, the hybrid model CNN-Bi-LSTM network gives an F1-score of 64%, which is better than all other methods such as CNN, LSTM, and Bi-LSTM. The hybrid model provides better results compared with the individual networks since it incorporates more information.
Moreover, experimental results show that the Siamese architecture gives better results for all the deep learning models compared with models in which learning is performed without Siamese architecture. It is due to the reason that Siamese model shares the weights of parallel sentences of the network that helps in learning the similarity of sentences in a better way.
The SiaLSTM model produces an F1-score of 63%, which is better than SiaCNN and LSTM models. Moreover, SiaBiLSTM further produces better performance of 64% F1-score. Experimental results show that Bi-LSTM shows better results compared with CNN and LSTM models. Furthermore, the best performance if given by the proposed model, SiaCNN-BiLSTM, is an F1-score of 67% for CLPD for the English–Hindi language pairs. The proposed model outperforms other models since it combines two models having complementary nature, in that, the CNN model includes local region information, whereas the Bi-LSTM model learns the information among long distance texts. Moreover, the Siamese-based architecture helps in learning the semantic similarity among the texts of different languages. Figure 8 shows the comparison of the different deep neural network models for CLPD.
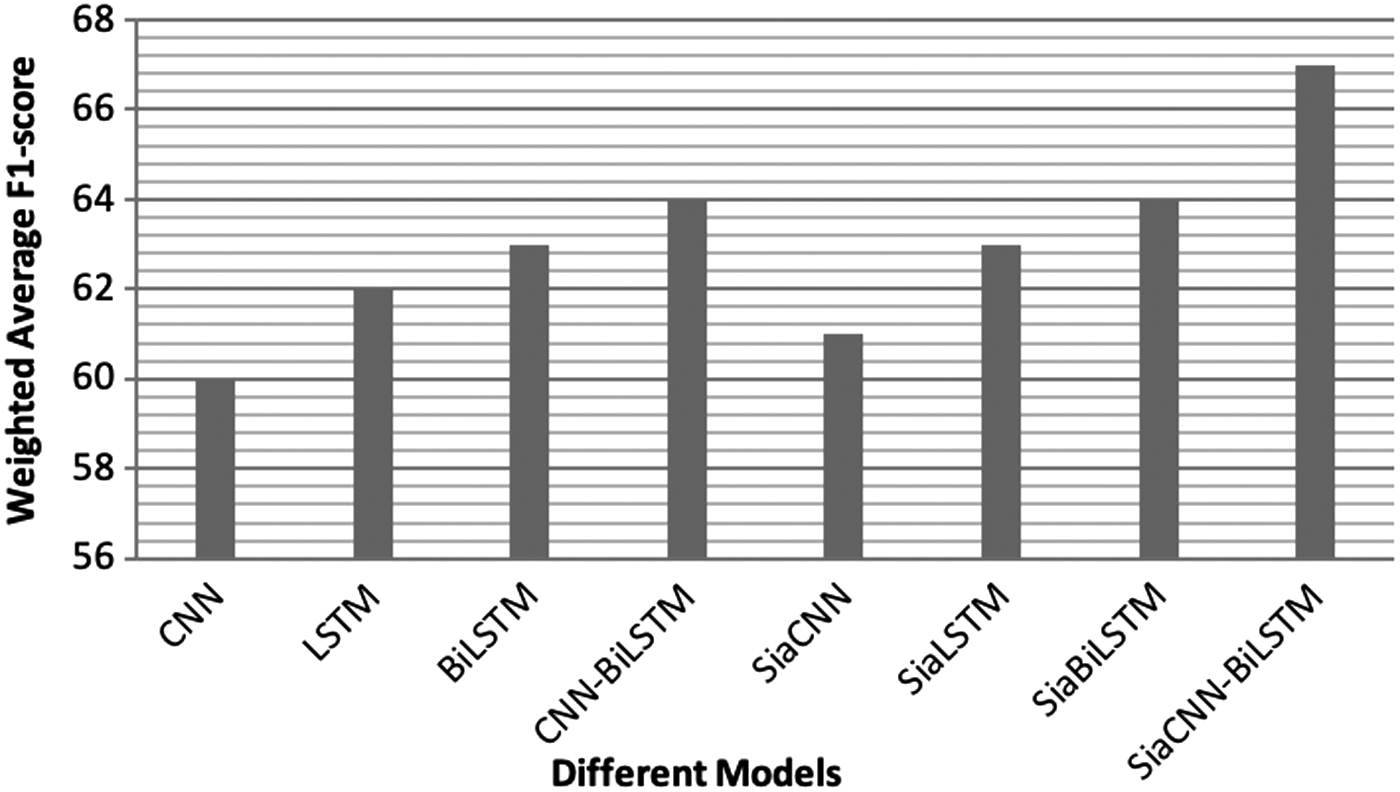
Performance comparison of the different models for cross-lingual plagiarism detection.
Conclusion and Future Work
CLPD is a challenging problem since there is no efficient method available in the literature for the representation of text from two different languages in a common semantic space. In this article, the focus is to efficiently detect whether the given sentence pairs from two languages convey the same meaning or not. The proposed model achieves better results over the existing methods since the proposed model depends on similar semantic representations of text even in different language sentences. The proposed deep learning model is a combination of CNN and Bi-LSTM techniques that learns if the given two sentences of English–Hindi languages are similar. The proposed model is trained using Siamese architecture, which proved to be successful compared with baseline methods.
Experimental results show the effectiveness of Siamese architecture for English–Hindi plagiarism detection. Furthermore, the proposed hybrid model outperforms other baseline methods on the Microsoft paraphrase corpus. The proposed model gives 67%, 72%, and 67% weighted average precision, recall, and F1-measure scores for determining the semantic similarity among the English–Hindi language pair texts. The limitation of the proposed model is that the overall performance is still quite low and that it needs further improvement; the main reason is that the training data set is quite small for the deep neural network-based models. This study provides important pointers to explore Siamese-based models for plagiarism detection in the English–Hindi language pairs.
Future research directions can be to develop parallel corpora to carry out the research for CLPD. In the future, more sophisticated network architectures will be explored that can learn more fine-grained details of the text. Moreover, the proposed models will be experimented with different language pairs.
Footnotes
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This work is funded by the National Project Implementation Unit (NPIU), Technical Education Quality Improvement Programme, TEQIP-III RTU (ATU) with the sanction letter no. TEQIP-III/RTU (ATU)/CRS/2019-20/18.