
Abstract
Multiexposure image fusion (MEF) is an effective approach to generate high dynamic range images from multilevel exposures taken from ordinary cameras. In this article, a novel MEF algorithm is proposed to gain maximum visual details as well as vivid colors from the captured scene. This algorithm first decomposes the input images with multiple exposures into the base and detail layer. The weights for the base and detail layers are computed by using exposedness function and then both the layers are combined to generate the final fused image. The proposed multiexposure technique requires fewer computational operations, preserves edges, and also reduces spatial artifacts. The proposed technique has been evaluated quantitatively using image quality assessment model based on structure similarity index measure for MEF. By the extensive experimental results, it has been illustrated that in addition to significantly outperforming other state-of-the-art techniques, the proposed technique is much faster and can achieve better image quality.
Introduction
Recent advancement in technology has undergone enormous evolution in almost all the fields of life and to stay relevant with this evolution, every field needs to keep pace. This aspect has resulted in an increased interest in computer vision and image processing, both of which have gained popularity throughout the past few years.1–3 In today's technological world, a large variety of devices have been invented that are capable of capturing digital images, which can be effectively used in various technological fields and industries.4,5 The main objective of all these devices is to capture the image of a scene as much similar as possible when viewed via human natural visual system.
In general, the dynamic range of a natural scene is often large as compared to the dynamic range of commercially available imaging products. Therefore, in digital image processing, it is a challenging task to render a natural scene, which has a high dynamic range (HDR) to an imaging display which typically has a low dynamic range (LDR). In general, for a natural scene, the dynamic range can be characterized as the ratio of radiance among the brightest to the darkest point in the scene.
In the real-world scenes, the illuminance values are of several orders of magnitude that cannot be spanned by LDR. For instance, the radiance of the natural scenes spans the range 1:500,000, which cannot be spanned by the cameras available now-a-days, even though they have sensors with pixel depth within the range of 8 to 14 bits that represents digital values from 256 to 16,384. 6
To overcome this limitation, HDR imaging techniques are used. In these techniques, a series of images of the same scene are captured at different exposure levels and the HDR image is then reconstructed by inverting the camera response function (CRF). In these techniques, estimating the CRF is the main problem.
Different constraints, for example, exposure time and some particular parameters are required for breaking the exponential and self-similar ambiguities.7,8 In HDR imaging, multiple images are captured of the same scene, with all of them having distinct exposure levels. These images are then fused to give the resultant LDR image. The HDR imaging technique can be considered as an image enhancement technique that can be divided into two subcategories, tone mapping-based image enhancement techniques 9 and fusion-based image enhancement techniques. 10 Basically, in a tone mapping-based method, numerous LDR images are taken of the same scene but at distinct exposure levels. These images are then converted to intermediate HDR images by using CRF and finally converted into LDR images using tone mapping operator. 11
An effective alternative to resolve the problems of tone mapping-based technique is provided by the multiexposure image fusion (MEF) technique, which circumvents the gap between HDR imaging and LDR displays. In MEF, various images are taken of the same scene under distinct exposure levels as its input sequence. These images are then integrated together to produce a resultant fused image, which is sharper, perceptually appealing, and has more details, compared to any of the individual input image.12,13 Multiexposure fusion aims at merging various images having distinct exposure levels into a single composite image having high quality so that the full dynamic range contains details and texture of LDR images. 14
The main contribution of the proposed framework can be summarized as follows:
An innovative technique for MEF to extract comprehensive information from the input source images and also remove the blurring and halo artifacts. A novel technique with a fast and accurate bilateral filter used for preserving edge information and estimation of weight maps uses the exposedness function required for fusion. By the extensive experimental results, it has been illustrated that the proposed technique generates fused images that are better both qualitatively and quantitatively. The complexity analysis and comparison of execution time proved that it provides substantial perceptual gains, while maintaining an achievable computational complexity. The proposed technique reduces the computational cost and ensures minimum manual interaction when compared with the state-of-the-art methods.
The organization of the rest of the article is as follows: In Related Work section, existing MEF techniques are explored. Proposed MEF technique is discussed in Proposed Methodology section. Performance Evaluation section compares performance evaluation of proposed MEF technique with existing MEF techniques, both qualitatively and quantitatively. Conclusion section concludes the article.
Related Work
Over the past few years, various research studies have been carried out on MEF due to which it has attained great importance as a developing research area.15–22 Some of these recent researches have been taken as a reference for the development of the proposed framework.
MEF was introduced in 1980s.
15
Most of MEF techniques are pixelwise that are generally formulated as:
where, n denotes the number of input images with different exposure levels of the same source sequence. In the nth exposure image,
Mertens et al. 16 computed weight maps in terms of saturation, contrast, and well exposedness measure. This being appropriate for the preservation of global contrast, still fails to preserve fine details in case of overexposed or underexposed areas. Therefore, various techniques were proposed for edge preservation and weight refinement. The MEF technique proposed by Raman and Chaudhuri 17 used the bilateral filter for preservation of edge information, and then weights were calculated to guide the fusion process. For accurate estimation of the weight map, recursive filtering-based techniques18–21 were proposed. Li et al. 20 used Laplacian filtering for construction of weighting maps followed by guided filtering 21 for weight refinement.
In some cases, gradient information of input images is used to estimate the impact on the resultant reconstructed image. Similarly, different techniques22–24 were proposed in which gradient field from the structure of the input images was extracted which was subsequently modified iteratively to calculate the final fusion weights. Production of halo artifacts was the common drawback of these techniques.
Most algorithms for MEF could be categorized as: single-scale algorithms 25 and multiscale algorithms.26,27,32 In single-scale exposure fusion, the minute details are preserved well for the HDR scenes, however, it causes the fused images to appear flat. Contrary to this, in multiscale exposure fusion, the images obtained are of better quality compared to the ones obtained from single-scale exposure fusion. Multiscale exposure fusion does not preserve the details in brightest and darkest areas besides producing halo artifacts. To overcome these problems, other techniques were introduced, which are known as the edge preserving smoothing techniques that are appropriate for the design of exposure fusion algorithm.28–30 On one hand, such techniques can preserve the edges, and on the other hand, they are not able to reduce halo artifacts which arise in the fused image.
Other techniques14,31,33 proposed in literature for image fusion are MEF pyramid decomposition. In these techniques, down sampling or blurring operation is used to decompose the source images into successive subimages. Fusion rules are then applied on these successive subimages to synthesize the final fused image. In such techniques, proper selection of the decomposition levels in the darkest or the brightest regions is required to retain the fine details as well as the global contrast. One major drawback of such techniques is that the details of the fused image are preserved regardless of the increased computational complexity. The algorithm proposed by Yang et al. 34 takes multiexposed images as its input to obtain a virtual image by using an intensity mapping function and subsequently use the existing pyramid-based technique. This algorithm provides a better way to preserve brightness, however, it can possibly produce halo artifacts.
Later, it was found that compared to the pyramids, wavelets can produce better results, therefore, discrete wavelet transform (DWT) 35 was used to achieve image fusion. Being shift invariant, DWT can produce artifacts in the resultant fused image. To reduce such artifacts, shift invariant DWT-based exposure fusion technique was developed. 36 Another drawback in the DWT-based exposure fusion techniques was that, compared to the images in the source sequence, the details of the fused image were not fine enough. This problem was solved by use of non-subsampled multiscale analysis technique. 37 Selection of proper decomposition level and production of halo artifacts are the main drawbacks of this technique. These methods were time consuming. A few existing techniques for image fusion19,38,39 add an optimization framework to the MEF technique.
In these techniques, an estimate of the weight maps can be obtained by solving an energy function. A proper balance is found between the color consistency and the local contrast when combining the details of the scene 36 where a framework for the generalized random walk is proposed. A fusion scheme based on a probabilistic model approach is used 39 that can preserve the maximum visible contrast, as well as the gradient consistency in the resulting fused image. Li et al. 19 proposed a method in which a quadratic optimization problem is solved so as to get the minute details present in the input images, which is then augmented in an intermediate reconstructed image to make it sharp. Patch-based exposure fusion techniques40–43 were also proposed in the literature. These techniques give better quality of fused image, but they were consuming more time.
From the previous research carried out on image fusion, it can be concluded that most of the techniques used for MEF basically aim at finding the weight map. In these techniques, an innovative weighting factor is designed by considering various quality measures; contrast, color saturation, and luminance of a pixel to build a blending function for the input images to obtain a better fused image. Therefore, existing MEF techniques preserve edges at the expense of computational complexity and produces halo artifacts. Furthermore, most of the existing MEF techniques are validated with a confined dataset without extensive database verifications that include sufficient image content discrepancies.
In this work, an improved MEF technique is proposed, which results in output having most of visual details, vivid colors, and also preserves edges. Beside fusion performance, computing efficiency is very important in real applications. The goal of proposed technique is to synthesize a high-quality image with less computation time. By applying the proposed technique on various image datasets, it is concluded that, compared to existing technique, the proposed approach is memory efficient, less complex, and very fast that makes it suitable to be used in embedded systems and other real-world applications.
Proposed Methodology
This section covers the detailed discussion of the proposed MEF technique along with the mathematical modeling involved at each step. The new MEF framework is comparatively efficient to fuse multiple images. The gist of the proposed technique is the decomposition of sequence of input images into two scales defined as the base layer and the detail layer, followed by the calculation of weight map. The proposed framework is depicted in Figure 1.
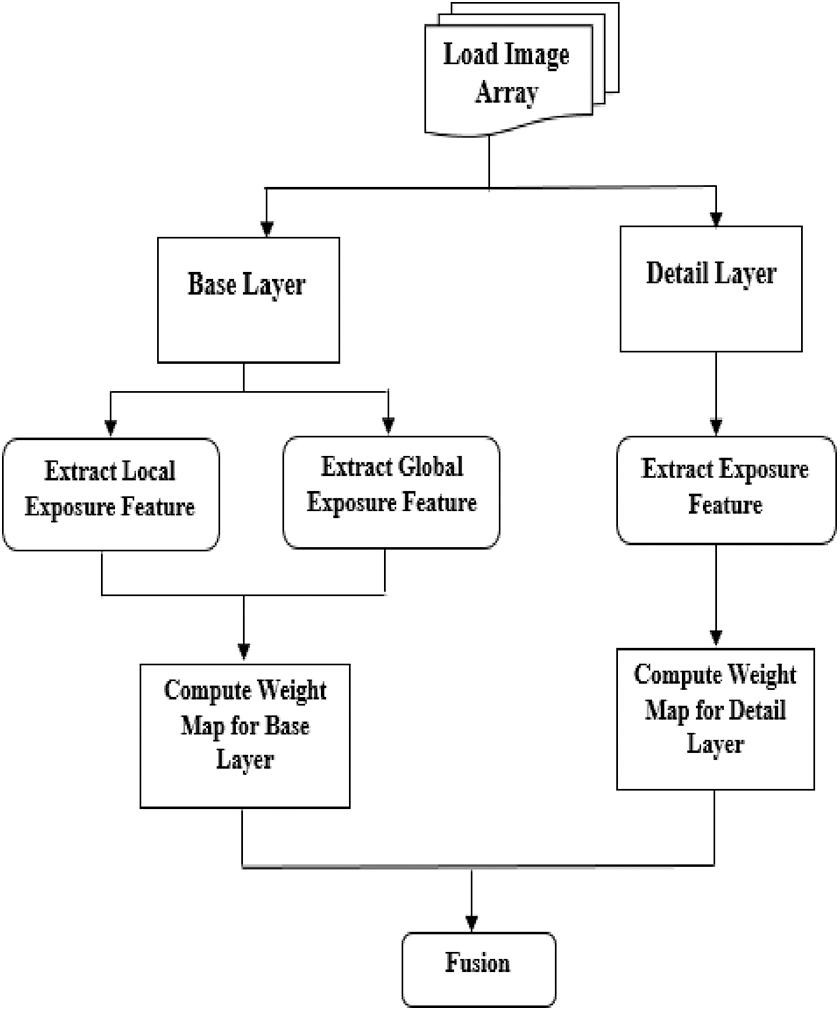
Block diagram of Proposed Technique.
Two-scale decomposition
In the proposed technique, two-scale image decomposition has been exploited to separate each source sequence into two layers, on which fusion steps are then applied. This decomposition step focuses on separating each image of the input sequence into a smooth layer known as the base layer that accounts for the large-scale intensity variations and a detail layer for the small-scale intensity variations.
Let the input images of a source sequence with multiple exposure be denoted as
Base layer
To obtain the base layer, an averaging filter can be applied to the luminance component. However, in case of a large noise floor, more pixels are needed to be averaged to suppress the noise. In such scenario, these averaging filters tend to over-smooth sharp image features such as edges and corners. Gaussian and box filters typically work well in applications where the amount of smoothing required is small. However, this over-smoothing issue can be alleviated by using the edge preserving smoothing filter where the image features are used to control the quantum of smoothing. Bilateral filter is one such edge-preserving smoothing technique that can effectively blur the image but retains the sharpness of edges. Unlike conventional filters, it defines the closeness of two pixels based on geometric as well as the radiometric distance. In the recent years, the bilateral filter has gained attention in the perspective of image denoising.
In the proposed technique, we use an extension of the bilateral filter for edge preserving and smoothening of images.
44
Conventionally, O(S) operations per pixel are required by a bilateral filter, where S denotes spatial filter support size. In proposed work, a fast and accurate bilateral filter has been used. In the proposed method, the bilateral filter proposed by Chaudhury and Dabhade
44
with O(1) operation per pixel is used. Therefore, in the proposed work, the fast bilateral filter is used to obtain the base layer represented by bn, as follows:
Detail layer
In the proposed technique, two-scale decomposition takes place. The large-scale intensity variations are included in the base layer, whereas the small-scale information is included in the detail layer. After obtaining the base layer from Equation (2), the detail layer is easily formed from original input image sequences and base layer.
where,
Estimation of the weight map
In MEF, exposedness feature gain significant importance to get more detailed and comprehensive final resultant image. The weights used in the proposed technique are estimated efficiently by utilizing a generalized exposedness function f, defined as follows:
where,
The base layer obtained from Equation (2) mainly expresses the large-scale structural details of image luminance. To construct the fusion weights for this layer, the exposure quality of the local as well as luminance is considered. For the assessment of global exposure quality, the mean value of luminance of the entire image is used for estimating the exposedness feature. Thus, the global exposedness weight
where
However, base layer itself can be used as an exposure feature, to achieve structural consistency among the base layer and its weight map. For each pixel location, the value of local mean of luminance can be utilized as the exposure feature for the assessment of the local exposure quality of the base layer. Correspondingly,
where
Thus, for the nth source sequence of input images,
For the detail layer, at each pixel position the exposedness feature
Once the weight maps are constructed for all the input images, their normalization is done so that for each pixel position a unit sum is obtained. Finally, a summation of the weighted averages of both the base and detail layers of the input images gives the resultant fused image, which is given as:
where,
Performance Evaluation
For performance evaluation of the proposed technique, we have tested it on various images of static natural scenes, each having a different exposure level and compared its results with the different existing techniques for MEF. In this work, we selected 17 natural source image sequences of high quality to span a diverse image content, consisting of man-made architectures, natural sceneries, and outdoor and indoor views. All the source sequences are enlisted in Table 1. These different techniques are implemented on MATLAB R2015 on a computer with Intel Core I3, 1.61 GHz CPU, and 8 GB RAM, running Microsoft window 10 operating system.
Information of input image Sequences
HDR, high-dynamic range.
As described previously, for a fair comparison, the parameter values used in the fusion process are taken to be same for all the images. It is demonstrated that for all test sequences, perceptually appealing results are produced by the proposed technique, both qualitatively as well as quantitively.
Figure 2 compares existing MEF algorithm with proposed method by applying them on the “Madison Capitol” sequence. In the fused image produced by Gu et al., 22 it can be seen that the color in the uniform areas of the image appears dreary. The resultant image produced by Li et al. 19 gives sharper contrast and looks artificial. The image represented by Li et al. 20 is unable to recover precise details about painting as well as pattern on the walls and the image produced by Raman and Chaudhuri 17 has suffered from lack of brightness and detail loss. Therefore, it can be seen that, compared to the previous techniques, the proposed technique has not only produced a more sharp image, but has preserved the patterns on the wall as well.

Images are shown for subjective analysis of the scene.
In Figure 3, we compared the results obtained by applying Mertens et al., 16 Gu et al., 22 Li and Kang, 18 and Raman and Chaudhuri 17 and the proposed technique on the “Tower” sequence. Compared with Mertens et al., 16 the proposed technique generates a fused image with various perceptual gains such as better preservation of top structure of the tower as well as the brightest cloud area, as shown in the red box. Furthermore, the sky and meadow regions give a more natural color appearance that is consistent with the source sequence. In the uniform areas of the fused image obtained by Gu et al., 22 as represented in Figure 3b, the color appears dreary, such as at the top of the tower, greenery, and the sky. Figure 3c represents the result obtained by Li and Kang. 18

Results of the proposed technique compared with other MEF techniques on “Tower” sequence.
Li and Kang's 18 is basically a detail-enhancement form of Mertens et al., 16 but detail enhancement might not inevitably result in perceptual gains, particularly when the limit of camera acquisition is neglected. Therefore, the resultant image obtained after fusion from Li and Kang 18 technique does not look natural around the edges such as marked in the box. Figure 3d compares the results obtained by Raman and Chaudhuri. 17 As it can be seen that image has suffered from lack of brightness and detail loss as it gives less information about color and texture. On the contrary, Figure 3e is obtained by the proposed technique. The image looks sharper and brighter, as it can be seen in the red boxes. Also, greenery and the structure of the tower are more clear.
Hence, from the subjective analysis, it can be concluded that the proposed technique produced a fused image that looks brighter, perceptually appealing, and more informative.
For the objective performance evaluation, quality assessment model, 13 which is proposed recently, is utilized. This model is using a metric based on structural similarity index measure for MEF. This quality indicator is used to measure the local structure preservation at the fine scales and also captures luminance consistency at coarser scales.
The results obtained in the proposed work of Ma et al. 13 show that, compared to the existing measures for the assessment of MEF quality, this quality measure outperforms in terms of correlation with subjective judgments. This quality measure is used to compare the performance of the proposed technique with already prevailing 12 different MEF techniques, which include Raman and Chaudhuri, 17 Li and Kang, 18 Li et al., 19 Li et al., 20 Gu et al., 22 Zhang and Cham, 23 Liu and Wang, 24 Song et al., 39 Ma and Wang, 40 Ancuti et al., 25 Xu et al., 45 and Zhang et al. 46 Table 2 enlists the results of this comparison for a dataset of 17 multiexposure image sequences. The range of the quality score is from 0 to 1, with the higher value indicating better quality.
Performance comparison of proposed multiexposure image fusion technique with existing multiexposure image fusion technique using image quality assessment model 13
From the comparison shown in Table 2, it is clear that for all the 17 image sequences, proposed technique mostly gives better performance in terms of the quality measure proposed by Ma et al. 13 Therefore, it can be concluded that the proposed method and Zang and Cham 23 and Ma and Wang 40 have the best performance.
Since the MEF techniques are mainly implemented in digital cameras, along with fusion quality, the fusion speed is an equivalently significant factor. For this purpose, we made a comparison among the proposed method and the existing best MEF algorithms, for which the source codes are available, on the basis of their fusion speed. In the proposed work, computational time is reduced by using a fast bilateral filter 44 having constant computation complexity to obtain base layer.
Moreover, we reduced computations by using two-scale decomposition technique instead of multiscale decomposition technique. Table 3 and Figure 4 include the comparison of the average computational time of the proposed technique over 17 MEF image sequences with the 7 existing methods, which include Yang et al., 34 Ma and Wang, 40 Li and Kang, 18 Liu and Wang, 24 Li et al., 32 Zhang et al., 46 and Li et al. 20 From comparison, it can be concluded that the proposed technique is computationally efficient.
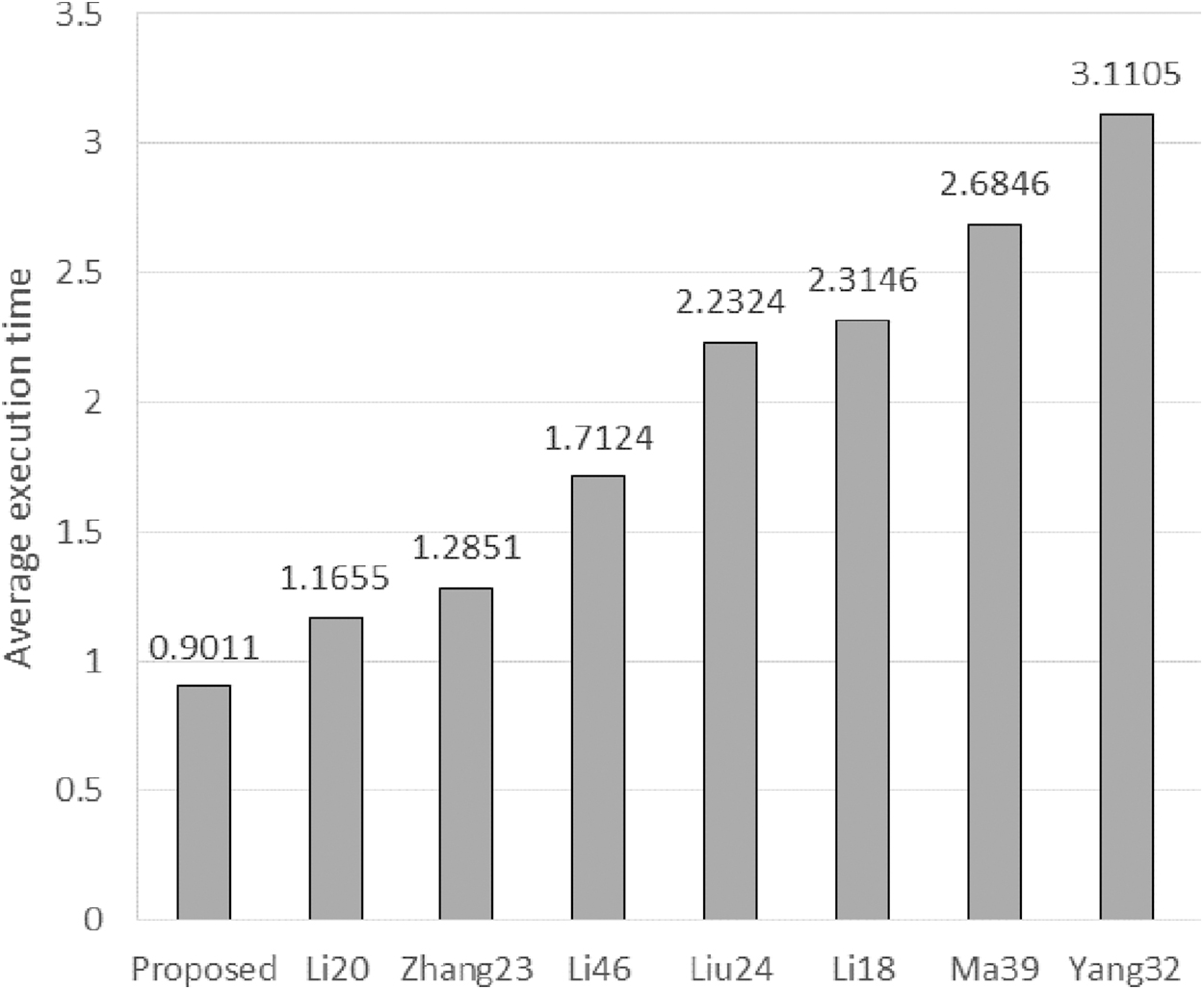
Bar graph of average execution time comparison of eight fusion methods.
Comparison of execution time of different multiexposure image fusion algorithms
Conclusion
In this article, an efficient technique for MEF is proposed. In particular, it decomposes the input images into two scales, and also for preservation of edges, we used fast algorithm and then computed the blending weights efficiently by using exposedness function. The proposed technique is also less time consuming for digital electronics. By experimental results, we compared the proposed technique against other existing MEF techniques. It shows that the proposed technique significantly outperforms in terms of objective as well as subjective evaluation. Moreover, proposed technique is computationally efficient and applicable for real-world applications.
Footnotes
Authors' Contributions
N.Z.: writing—original draft (lead) and editing (equal). A.M.S.: conceptualization (Support) and review and editing (equal). A.A.: methodology (Support) and review. W.I.: methodology (lead) and writing—review and editing (equal). M.I.: conceptualization (supporting), writing—original draft (supporting), and writing—review and editing (equal). I.T.: formal analysis (lead) and review. W.M.: software (lead) and writing—review and editing (equal).
Author Disclosure Statement
No competing financial interests exist.
Funding Information
No funding was received for this article.