
Abstract
Performance measurement is an essential task once a statistical model is created. The area under the receiving operating characteristics curve (AUC) is the most popular measure for evaluating the quality of a binary classifier. In this case, the AUC is equal to the concordance probability, a frequently used measure to evaluate the discriminatory power of the model. Contrary to AUC, the concordance probability can also be extended to the situation with a continuous response variable. Due to the staggering size of data sets nowadays, determining this discriminatory measure requires a tremendous amount of costly computations and is hence immensely time consuming, certainly in case of a continuous response variable. Therefore, we propose two estimation methods that calculate the concordance probability in a fast and accurate way and that can be applied to both the discrete and continuous setting. Extensive simulation studies show the excellent performance and fast computing times of both estimators. Finally, experiments on two real-life data sets confirm the conclusions of the artificial simulations.
Introduction
Since the beginning of this century, technological advances dramatically changed the size of data sets as well as the speed with which these data have to be processed, analyzed, and evaluated. Modern data may have a huge number of observations and/or a very large number of dimensions. Recently, data are growing at an explosive rate and these massive data sets are collected at high speed from different sources, for example, results of sensors in an industrial process or in health care, spatial data from mobile devices, etc.
These data are often used to get insights into a certain process, which are typically obtained by predicting one response variable by using all the other explanatory variables. Many statistical models can be used for this prediction task that will turn data into knowledge and hence, it is of utmost importance to compare the performance of these various models. In this article, it will be shown how to efficiently compute the concordance probability, a popular measure of the predictive ability of both classification and regression problems. We will focus on the presence of a huge number of observations, to which the computing time of this measure is particularly sensitive.
For evaluating the quality of a binary classifier, the focus typically lies on the discriminatory ability of the model. For more information on the different aspects of the predictive ability, such as the difference between the discriminatory ability and the calibration, we refer to Steyerberg et al. 1 The most widely used performance measure to check the discriminatory ability of a binary classifier is the area under the receiver operating characteristic (ROC) curve (AUC); see, for example, the work of Liu et al., Razavian et al., and De Cnudde et al.2–4 Note that the construction of the ROC curve was suggested in the electronic signal detection theory. 5
It is known that the AUC in case of a binary response variable equals exactly the concordance probability, also called the C-index.
6
The concordance probability corresponds to the probability that a randomly selected subject with outcome
A pair of observations with their predictions that satisfies the above condition is called a concordant pair. Hence, the concordance probability can also be defined as the probability that a randomly selected comparable pair of observations with their predictions is a concordant pair. The concordance probability, defined in Equation (1), normally ranges between 0.5 and 1, and the closer it is to 1, the better its discriminatory ability.
If its value drops below 0.5, the predictions are consistently inconsistent. For a sample of size n, the concordance probability typically is estimated as the ratio of the number of concordant pairs nc over the number of comparable pairs nt:
where the value
For observation i, yi and
According to Yan and Greene, 8 it depends on the context whether one wants to ignore ties. An estimator should, therefore, be able to handle both situations. Since ties only influence the actual definition of the comparable and concordant pairs, the choice of whether to include ties does not influence the expression of any definition or estimator presented here.
See Yan and Greene 8 for a more detailed treatment of the subject of ties on the concordance probability. However, the approximations that we will discuss in this article are still applicable when one wants to include ties in the predictions, something that is often done in the classical AUC estimator.
As can be seen in Equation (2), calculating this C-index can be very time consuming for large data sets. Therefore, research was conducted to find approximations that reduce the time complexity for calculating such a discriminatory measure in a discrete setting. For example, Bouckaert 10 provides a method for incrementally updating exact AUC curves and for calculating approximate AUC curves.
A number of researchers have attempted to approximate the AUC by smooth functions,11–13 or more specifically polynomials. 14 The most popular algorithm is introduced by Fawcett, 15 where the ROC curve is determined efficiently such that the AUC can be calculated as the area under the ROC curve. This area is obtained by approximating the integral by the trapezium rule.
In this article, two additional approximations will be presented, which do not rely on the link between the concordance probability and the area under the ROC curve.
k-means approximation: rather than working with the predictions of all observations of the data set, the predictions of the observations of each outcome class are reduced to the predictions of the centroids of k clusters. Afterward, Equation (2) is applied to predictions of the latter centroids only. Due to its favorable scaling to large data sets, the k-means clustering algorithm will be used.
Marginal approximation: For each observation of a given outcome class, its prediction is compared with all predictions of the other outcome class, meaning that there is no correlation between the pairs of both outcome classes that are considered during the estimation process. Hence, by approximating the distribution of predictions of both outcome classes separately by discrete bins and by computing the concordance probability using these bins rather than each separate observation in Equation (2), the concordance probability can be computed more efficiently.
When the response variable Y is continuous, the discriminatory ability of the model can also be of interest, especially when the ranking of the observations is of higher importance than obtaining well-calibrated predictions. Typical examples are the modeling of the claim size distribution of a non-life insurance product, or the modeling of a lifetime distribution in a churn analysis. Note that the concordance probability is particularly popular within the field of survival analysis, and many estimation methods have been proposed to compute the concordance probability in the presence of right censoring.16,17 As such, the basic Definition (1) is typically adapted as:
where
where
As a result, the aforementioned research is not suitable for this setting in case of a large data set. To our knowledge, the present article is the first one that focuses on approximating the concordance probability in a fast and efficient manner in the continuous setting. The aforementioned k-means and marginal approximation will be adapted to the continuous setting.
Summarized, we present in this article two computationally efficient approximations of the concordance probability for big data, in both a discrete and continuous setting, the k-means and marginal approximation. The remainder of this article is structured as follows. The k-Means and Marginal Approximation section presents a detailed explanation of the two proposed approximations. The good performance of both estimators of the concordance probability is verified in an extensive simulation study in the Simulations section. Finally, we illustrate the practical applications of this work on two real-life examples in the Real-Life Examples section. The main findings and suggestions for further research are summarized in the Conclusion section.
k-Means and Marginal Approximation
In this section, two approximations of the concordance probability are presented. One approximation makes use of the k-means clustering algorithm and will therefore be called the k-means approximation. The other one takes advantage of the structure of the estimation process of the concordance probability and will be denoted the marginal approximation. The first subsection focuses on the discrete setting, meaning that the response variable is binary. The second subsection considers the continuous setting, where the response variable is continuous.
Discrete setting
In this subsection, we consider the situation of a binary response variable Y. The k-means approximation can be obtained by separately applying a clustering algorithm to the predictions of each group in the definition of the concordance probability. The number of clusters k will then determine the level of approximation, hence a more precise estimate will be obtained as k increases. When the clustering algorithm is applied, only the cluster centroids will be considered for estimating the concordance probability.
In other words, all cluster centroids of each group will be compared with one another. The importance of each cluster by cluster comparison is weighted by the probability that a randomly selected pair of observations belongs to the respective clusters, or:
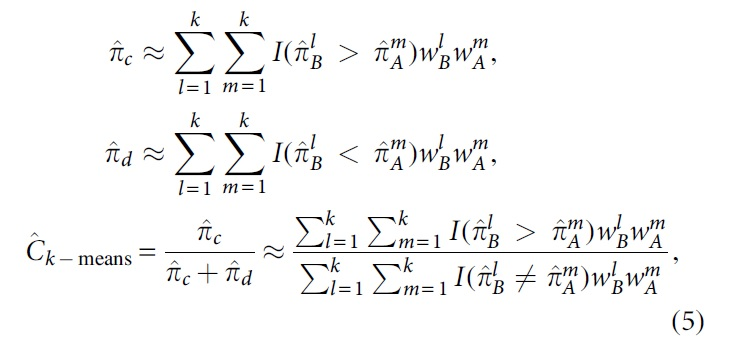
where subscript B (respectively A) refers to the group of observations of which the predictions are supposed to be higher (respectively lower) than the ones of subscript A (respectively B). The denominator of the estimator is needed to eliminate the effect of ties on the predictions. Moreover,
The marginal approximation is obtained by taking advantage of a structure that can be found in the estimation process of the concordance probability. For each observation of a given group, its prediction is compared with all predictions of the other group. As such, no correlation is present between the pairs
where
Hence, when a grid with the same q boundary values

Scatter plot showing the different pairs that are considered in the estimation of the concordance probability. In dashed blue lines the grid lines are shown, hereby delineating the different regions of the grid.
In the next step, three different regions in the two dimensional space can be determined: regions that only contain concordant pairs, regions that contain only discordant pairs, and regions that also contain ties (induced by the grid structure). As such, the latter region is considered to be a region of incomparable pairs only. For the ease of presentation, we assume that the q boundaries are the same for both groups, but this is not an absolute necessity.
Remember that it is assumed that all observations of group A have a lower observed outcome value than all the observations of group B, and that the values of group A (respectively B) are plotted on the X (respectively Y)-axis. Therefore, all concordant pairs are located in the upper left part of the support of
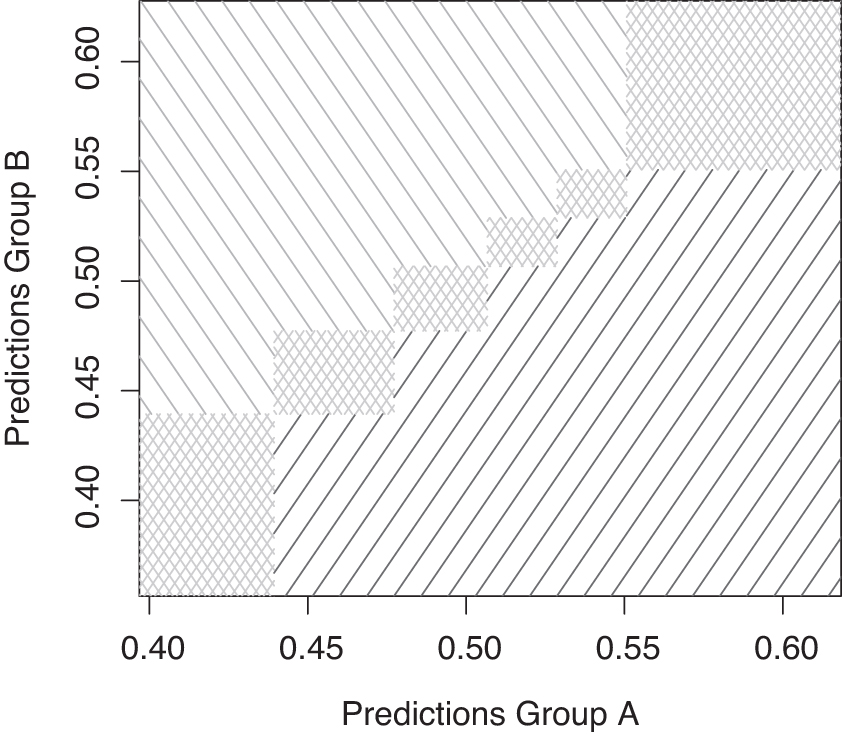
The different regions of the grid, shown in Figure 1, in which the concordant pairs (downward dashed region, in green), the discordant pairs (upward dashed region, in red), and incomparable pairs (upward and downward dashed region, in gray) are highlighted.
Since only both marginal distributions
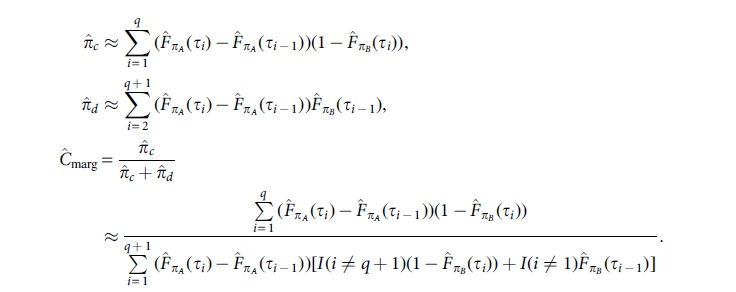
Note that this methodology only yields an approximation of the estimated concordance probability of Equation (2), and that the accuracy improves as q increases. Although
Continuous setting
Here, we consider the situation of a continuous response variable Y. Since the data structure and the design of the concordance probability is entirely different for the continuous setting as compared with the discrete setting, the approximations that were proposed in the Discrete Setting section (subsection of k-Means and Marginal Approximation section) will not necessarily work for this new setting. One of the key points underpinning these approximations is the existence of two independent groups. In case of a continuous response variable, two of such groups cannot be defined and therefore the previous approximations need to be adapted to the continuous setting.
Based on Equation (4), the large data set can only be reduced to a smaller set of clusters, when these clusters of observations are jointly constructed based on their observed outcomes and predictions. All these clusters are uniquely characterized by their observed outcome, prediction and weight, the latter being determined by the number of observations that pertain to the cluster at hand. As a result, Equation (4) can be computed while using only these representations of the clusters,
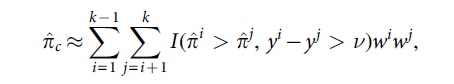
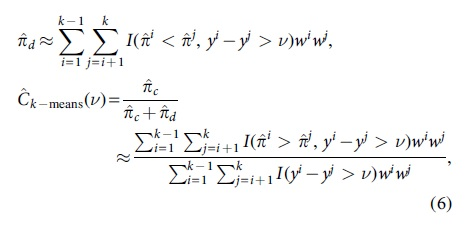
where yl and
wl is the weight of the l-th cluster that is estimated by computing the percentage of observations belonging to cluster l, such that by definition
The marginal approximation can be adapted to the continuous setting as well. In this case, a grid will be placed on the
The set of boundary values for dimension
An important difference with the marginal approximation in the discrete setting is that the distance in the Y dimension between two regions needs to be larger than
Therefore, regions of which the distance in the Y dimension between their lower boundary and the upper boundary of the selected region is smaller than
Ties in the predictions need to be eliminated as well, such that regions that have exactly the same boundary values for the
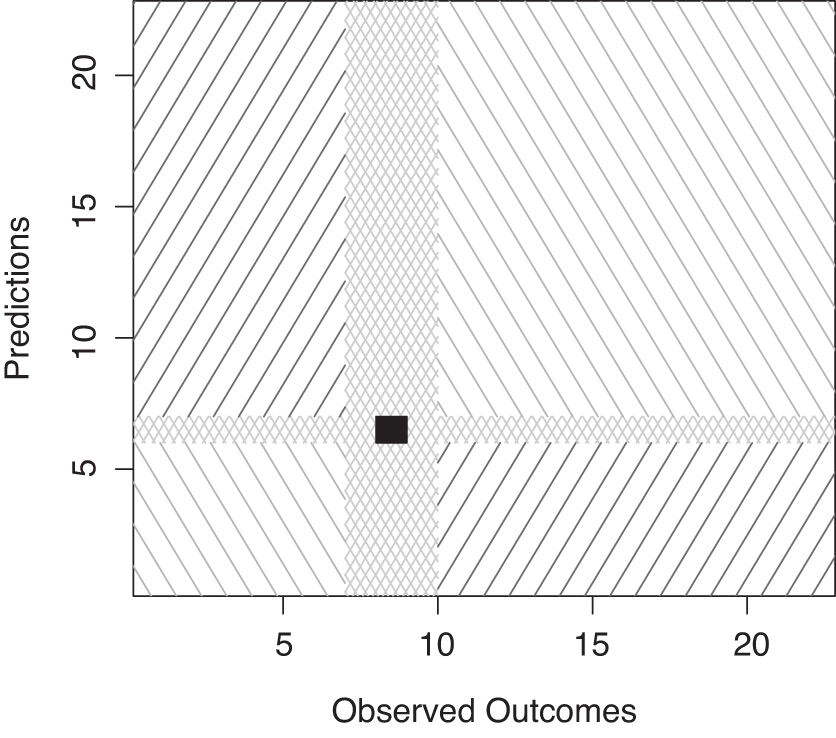
A grid is laid on top of the
This partitioning greatly simplifies the estimation of the contribution of the selected region, since for each of the two or four main regions, all members of the selected region contribute to either
In Figure 3, the downward dashed regions (in green) correspond to the region of the concordant pairs, contributing to
During the estimation of
One might as well choose any of the other three remaining directions, that is, on the left-hand side, below or above the selected region, as long as the same direction is used for all selected regions. Therefore, by selecting the main regions that are located on the right-hand side of the selected region only, the marginal approximation of the concordance probability can be computed as:

where
Simulations
We now investigate the performance of the proposed k-means approximation and the marginal approximation for the concordance probability in an extensive simulation study. The Discrete Setting section (subsection of the Simulations section) investigates the approximations for the discrete setting with a binary response variable, whereas the Continuous Setting section (subsection of Simulations section) focuses on the continuous setting with a continuous response variable.
Discrete setting
Data generation setup
To examine the performance of the proposed estimators when the response variable is binary, a simulation study was set up on a response variable following a beta-binomial distribution with parameter n equal to 1. The beta-binomial distribution, denoted
Note that when
In this simulation setting, a parameter p is sampled from the beta distribution (and used for true prediction), whereas a sample of the corresponding beta-binomial distribution yields the observed value. These pairs of predicted and observed values for p are then used to calculate the proposed approximations for the concordance probability.
First, the population value of C is computed. For this, a large sample (i.e., with sample size 100,000,000) is selected from a beta distribution. Based on its mean and concentration, we considered 63 possible beta distributions (resulting in 63 population values) (see Table 1 for combinations). Next, these samples are used as true rate values to sample outcomes from the binomial distribution with
The population values of C when p is sampled from different beta distributions with mean μ and concentration κ
Moreover, they can be classified into two groups: the ones that have a sampled outcome equal to 0 and the ones that have a sampled outcome equal to 1. The population value is then computed by comparing the sampled rates of the 0 group with the ones of the 1 group. This population value is for each of the considered situations presented in Table 1.
A first thing to notice is that a concentration
Moreover, the larger the concentration, the smaller the population value of the concordance probability. This can be explained by the fact that the difference between the values of the probabilities, that is, the predictions, is small in case of a high concentration. Finally, the more extreme the probability (close to 0 or close to 1), the higher the concordance probability.
It is important to investigate whether the size of the population value has an effect on the algorithms. Therefore, we consider
Evaluation setup
For each of the above discussed simulation settings, 1000 samples are generated on which the k-means approximation and the marginal approximation are applied to calculate the concordance probability. As a benchmark method, we added the standard trapezium approximation of Fawcett, 15 which determines the ROC curve efficiently and then calculates the AUC as the area under the ROC curve, by approximating this integral by the trapezium rule.
This simulation study also tests the effect of using 10, 20, 100, 500, or 1000 boundary values or clusters, while working with a data set with 500,000 or 5,000,000 observations. In case of the marginal approximation, the boundary values are evenly spaced percentiles of the empirical distribution of the predictions of both groups, as advised in the Discrete Setting section (subsection of k-Means and Marginal Approximation).
Focusing on the simulation setting with
This table considers the discrete simulation setting with
It shows not only the mean and median bias and run time, but also the interquartile range and standard deviation over the estimates and over the run time. This is shown in function of the number of boundary values or clusters, for the k-means approximation, the marginal approximation, and the one based on the trapezium rule. Two data set sizes are considered, namely 500,000 and 5,000,000.
Discussion of results
From Table 2, some general conclusions that are also valid in the other simulation settings can be drawn about the bias. First of all, the bias of all approximations is low, even almost negligible. Overall, the bias of the k-means approximation and the trapezium approximation is smaller than the bias of the marginal approximation. The latter results in a bias that is not affected by the sample size of the data, whereas the bias of the k-means approximation depends on the sample size.
As expected, the bias decreases when the number of clusters or boundaries increases. In general, we see that the bias based on the mean and the bias based on the median are close to each other. Hence, we can conclude that there were no extreme estimates.
Table 2 also reveals some general conclusions about the run time. Primarily, the marginal approximation results in the smallest run times, opposite to the k-means approximation with the largest run times. Hence, the run time of the trapezium approximation is always smaller than the one of the k-means approximation, but larger than the run time of the marginal approximation. As expected, the run time generally increases as the number of clusters or boundary values increases. The run time also increases as the sample size increases.
More specifically, we see that when the sample size increases from n = 500,000 to n = 5,000,000, the run time gets ∼10 times larger for the marginal approximation and the trapezium approximation. However, for the k-means approximation, the increment factor of the run time is shorter than 10 and becomes even shorter when the number of clusters increases.
The estimates vary little as can be seen from Table 2. From the simulations, we learn that the variability of the estimated concordance probability is higher for the k-means approximation than for the marginal approximation, at least for a low number of clusters or boundary values. This can be explained by the random starting values for the clusters in the k-means clustering algorithm, combined with the low number of clusters. For >20 clusters or boundary values, the standard deviation and the interquartile range are the same for the two approximations.
Further, the standard deviation and interquartile range do not change in function of the number of boundary values for the marginal approximation, whereas we do see a reduction of variability when the number of clusters increases for the k-means approximation. Overall, the variation of the estimates decreases for each of the three algorithms when the sample size increases. For the marginal approximation, we can conclude that, in general, the run time variability increases when the sample size increases. This conclusion cannot be made for the k-means approximation.
Until here, only general conclusions of each specific simulation setting on its own are considered. To check whether there is an effect of the size of the population value on the algorithms, Table 2, Appendix Tables B.2 and B.3 are compared. From these tables, we can see that the bigger the concentration (and hence the smaller the population value of the concordance probability), the smaller the bias of all approximations in most of the cases.
Moreover, the true population value of the concordance probability has no effect on their run time and its variability for all algorithms. The true population value of the concordance probability has also no effect on the variability of their estimates. Another question was whether the extremity of the probability affects the algorithms. To answer this question, we compare the Table 2, Appendix Tables B.1 and B.4.
The extremer the probability, the bigger the bias and the smaller run times of the marginal approximation. These conclusions cannot be drawn for the k-means approximation and the approximation based on the trapezium rule. For all algorithms, the extremity of the probability has no effect on the variability of the estimates and their run times.
As a conclusion, this simulation study favors the marginal approximation over the approximations based on the k-means algorithm or the trapezium rule. The marginal approximation with 500 clusters or more delivers namely estimates that are very weakly biased. Moreover, this approximation is computed faster when dealing with the really large data sets, hence better passing the sample size complexity test than the k-means approximation or the one based on the trapezium rule.
Continuous setting
In this subsection, the goal is to investigate the performance of the k-means approximation and the marginal approximation, when the response variable is continuous.
Data generation setup
We suppose that the observations and predictions both follow a standard normal distribution. In this simulation, the correlation between the observations and predictions varies between the following values
A first step in this simulation is to determine the correct values for
The 20% and 40% percentiles of these absolute differences represent the values for
Since the ranges of
The next step for the simulation is to determine the population values of
The mean value of the aforementioned obtained means
The population values of the concordance probability for several combinations of ν and ρ
Evaluation setup
Similar to the discrete setting, 1000 samples are generated for each of the above described simulation settings. On these samples, the marginal approximation and the k-means approximation are applied to calculate the concordance probability. To the best of our knowledge, we have proposed the first approximations to compute the concordance probability in the continuous setting and hence no benchmark methods are available.
The k-means approximation tests the effect of 10, 20, 100, 500, or 1000 clusters, whereas the marginal approximation focuses on 10, 20, or 100 boundary values. The latter only considers small numbers of boundary values due to the lengthy run times, as will be clear from the simulation results. Moreover, the boundary values are evenly spaced percentiles of the empirical distribution of the observed values, as advised in the Continuous Setting section (subsection of k-Means and Marginal Approximation).
Focusing on the simulation setting with
This table considers the continuous simulation setting with ρ = 0.25 and ν = 0.3583
It shows not only the mean and median bias and run time, but also the interquartile range and standard deviation over the estimates and over the run time. This is shown in function of the number of boundary values for the marginal approximation, or the number of clusters for the k-means approximation. Two data set sizes are considered, namely 500,000 and 5,000,000.
Discussion of results
From Table 4, some general conclusions that are also valid in the other continuous simulation settings can be made about the bias. The bias is low for all approximations, and there is a decrease in the bias when the number of clusters or boundaries increases. Moreover, similar to the discrete setting, the bias of the k-means approximation is smaller than the one of the marginal approximations when using the same number of clusters or boundaries. The sample size of the data has clearly no effect on the bias of the marginal approximation, as well as on the k-means approximation with 100 clusters or more.
Finally, when the number of clusters is larger than 10, we see that the bias based on the mean and the bias based on the median are almost similar. Hence, we can conclude that no extreme estimates were encountered in these cases. The same holds for all considered numbers of boundaries for the marginal approximation. A note of caution is due here, since some aforementioned conclusions are not valid in case there is no correlation between the observations and the predictions (Appendix C).
First, the bias of the marginal approximation seems independent of the number of boundaries. Second, the bias of the k-means approximation is only smaller than the one of the marginal approximation in case of <100 clusters or boundary values. Once it is higher than 100, the bias of both approximations is equal.
Table 4 also reveals some general conclusions about the run time. In contrast to the discrete setting, the run time of the marginal approximation is higher than the one of the k-means approximation. More specifically, the k-means method is approximately two times faster to compute than the marginal method for 10 clusters or boundary values, whereas for 100 clusters or boundary values, it is 30 to 50 times faster.
Next, we see that the run time generally increases as the number of clusters or boundary values increases. Note that sometimes, this is not the case when we compare the simulation results for 10 and 20 clusters. Further, the run time increases as the sample size increases for both approximations. Finally, there are no extreme run times, since the mean and median run times are nearly identical.
The estimates vary little, as can be seen in Table 4. From the simulations, we learn that the variability of the estimated concordance probability is higher for the k-means approximation than for the marginal approximation when the same number of clusters and boundary values is considered. The k-means approximation with >100 clusters has approximately the same values for the standard deviation and interquartile range of the estimates, as the marginal approximation with 10, 20, or 100 boundary values.
This was expected due to the random starting values for the clusters in the k-means clustering algorithm. The latter also explains why we see a reduction of the variability when the number of clusters increases for the k-means approximation. However, for the marginal approximation the standard deviation and interquartile range of the estimates hardly change in function of the number of boundary values. Overall, the variation of the estimates decreases when the sample size increases.
Thus far, the focus was on the variability of the estimates. In Table 4, the variability of the run times is also studied. When the number of observations equals 500,000, the variability of the run time is mostly higher for the k-means approximation than for the marginal approximation. Moreover, it increases when the number of clusters or boundary values increases.
For 5,000,000 observations, we still see an increase of variability when the number of clusters or boundary values increases, apart from the interquartile range for the cases with 10 or 20 clusters. Moreover, the variability of the run time is in this case typically smaller for the k-means approximation than for the marginal approximation. Going from 500,000 to 5,000,000 observations leads to an increase in the variability of the run time for the marginal approximation.
For the k-means approximation, the same holds for the standard deviation (interquartile range) in case of 100 (20) clusters or less. However, a larger number of clusters results in a decrease of variability in the run time when going from 500,000 observations to 5,000,000 observations.
Finally, we also consider the effect of
Next, the variability of the run times and the estimates does not change in function of
To conclude, this simulation study clearly favors the k-means approximation over the marginal one. The k-means approximation delivers namely estimates that are very weakly biased, even if the number of clusters is poorly tuned. Also, the k-means approximation is computed much faster when dealing with really large data sets, hence better passing the sample size complexity test than the marginal approximation. As a general recommendation, one should choose 100 clusters when using the k-means approximation, as the fitting time is still very small, and as this results in a low variability over the estimated concordance probability.
Real-Life Examples
In this section, two real-life data sets from Kaggle* are used to compare the exact concordance probability with the approximations discussed in this article. The first example focuses on the discrete setting, whereas the second one deals with a continuous response variable. Both examples are executed on a computer with specifications Intel Core i7-8650U CPU @ 1.90 GHz 2.11 GHz processor.
Predict click through rate for a website
We consider data about the click through rate for a website related to job searches. 18 This data set consists of 10 variables and 1,200,890 observations, where each observation corresponds to a user's view of a job listing. One of the variables is called apply, which indicates whether or not the user has applied for this job listing after checking the job description. The related notebook “Let's Start” on Kaggle cleans the data first, that is, duplicates and observations with missing values are removed.
Next, the data set is split into a training and test set (respectively containing 871,290 and 81,704 observations) and finally three popular predictive models are applied: XGBoost (xgb), random forest (rf), and a Light Gradient Boosted Machine (lgbm). The main interest of this article is on the calculation of the concordance probability of the model once the predictions are available. Normally, this measure is only determined for the test set, but since we also focus on large data sets, we consider the predictions of the entire cleaned data set as well.
To determine the bias of the concordance probability estimates, we first need to determine its exact value. Therefore, the data set is first split into a 0-group and a 1-group, based on the value of the variable apply. In this case, the 1-group is the smallest, which is why a for loop is used for the elements in this group. In each iteration, we count the number of predictions in the 0-group that are smaller than the prediction of the considered element of the 1-group. Summing up all these counts, divided by the number of considered pairs, results in the exact concordance probability. The latter can be found in Table 5 and shows that, based on the concordance probability, the third model, based on an lgbm, performs best on the test set. Moreover, it requires an excessive amount of time to calculate the concordance probability on the complete cleaned data set.
The first three columns show the exact concordance probabilities obtained for the three different models of the click through rate example, for the test set (test) or the complete cleaned data set (all)
In the last three columns, the computing times are shown.
lgbm, Light Gradient Boosted Machine; rf, random forest; xgb, XGBoost.
Table 6 shows for the three predictive models the bias of the different approximations for the concordance probability discussed in this article. First of all, the bias of all approximations is extremely low, even almost negligible. More specifically, the smallest bias is in this example obtained by approximations based not only on the trapezium rule, but also on the k-means algorithm with 1000 clusters. However, the approximations based on the k-means algorithm do have the largest run time.
In the left part of this table, we can see the bias of the concordance probability estimates for the click through rate example, based on the k-means approximation, the marginal approximation, and the one based on the trapezium rule
The right part shows the corresponding run times of these approximations.
The smallest run times are obtained by the marginal approximation. Moreover, comparing Tables 5 and 6 show that all approximations for the complete cleaned data set have a much smaller run time than the one of the exact calculation. Finally, general conclusions from the simulation study in the previous section are confirmed in this example; for example, the bias decreases when the number of boundaries increases, the run time increases when the number of clusters, and/or observations increase and so on.
New York City taxi fare prediction
We consider data about the taxi fares in New York. 19 This data set consists of a train and test set of, respectively, 55,423,856 and 9914 observations, representing taxi rides in New York City, and 7 variables each. One of the variables is called fare_amount, which is a continuous variable indicating the fare amount (inclusive of tolls) for a taxi ride in New York City. The other six variables represent the pickup and drop off locations, the pickup time and the number of passengers.
The related notebook “NYC Taxi Fare—Data Exploration” written by van Breemen 20 uses 2,000,000 rows of the training data to construct a linear regression model to predict the variable fare_amount. The first step is cleaning the data, for example, removing missing data, removing noisy data points with underwater locations, and so on. This results in a data set consisting of 1,918,905 lines, of which 75% will be used to train the model and 25% to test the model.
In the next step, some data exploration reveals that the important features will be the year and hour of the pickup time, the driven distance, and the number of passengers. The latter variables are therefore used in the linear regression model to predict the fare amount for a taxi ride in New York City. Once again, the interest of this article is not on how this model is constructed, but on the calculation of the concordance probability of the model once the predictions are available.
Normally, this measure is only determined for the test set that consists here of 479,727 observations. Since we focus on large data sets, we also consider the 1,918,905 predictions of the entire cleaned data set. Note that the correlation between the predictions and the observations is 89.52% for the test set and 89.24% for the complete cleaned data set.
The goal is to predict the C-index for different values of
However, in case of 1,918,905 observations, this would result in 1,841,097,240,060 pairs and corresponding differences. A closer look to the data reveals that out of these almost 2 million observations, only 2569 unique values for the fare amount for a taxi ride in NYC are denoted. These unique values are represented in
However, do note that there are still
This table shows the exact concordance probabilities together with the computing times for different values for ν
The upper part focuses on the test set (test) and the lower part on the complete cleaned data set (all).
To determine the bias of the concordance probability estimates, we first need to determine its exact value. Note that we cannot take advantage anymore of the small number of unique values in the observations, since their predictions can differ. Therefore, a for loop is used for all the observations. In each iteration, we select the rows with an observation strictly larger than the considered observation added up with
The number of selected rows is for each iteration stored in
Table 8 shows the bias and run time of the marginal approximation and the k-means approximation in this example. First of all, the bias of all approximations is low, especially for the marginal approximation when
The bias of the concordance probability estimates for the taxi fare example, based on the k-means approximation and the marginal approximation
This is done for the test set (test) and the complete data set (all), for different values of ν.
Moreover, the marginal algorithm is not always able to determine an approximation when
Since the absolute difference between
Conclusion
The current existing algorithms to compute the concordance probability are only adapted to a discrete response variable in case of large data sets. Therefore, we proposed two computationally efficient algorithms to estimate the concordance probability in both the discrete and continuous settings: the k-means algorithm and the marginal algorithm. In the discrete setting, the marginal approximation is the fastest method and moreover, it achieves the same bias as the standard approximation based on the trapezium rule.
However, in case of a continuous response variable, the k-means algorithm is the most precise and results in the smallest run time. These conclusions are based on an extensive simulation study, which also focuses on the variability of the estimates and the run times of the algorithms. The good performance is also illustrated in two real data applications. Further lines of research can consist of adapting these methods to different types of concordance probabilities.
In survival analysis, for example, it can happen that some observations are right censored. To have a comparable pair of two survival times with their predictions, one needs to be sure that the observation with the smallest observed survival time is not censored.16,17 For the k-means approximation, this can be obtained by adding in the indicator functions of Equation (6) the condition that yj is not censored.
The implementations of the discussed approximations of the concordance probability are written in R and are available on github as an R-package † .
Footnotes
Authors' Contributions
All authors contributed to methodology and validation. R.V.O. and J.P. were responsible for conceptualization, formal analysis, investigation, software, and writing (original draft). B.B. and T.V. were responsible for funding acquisition, supervision, and writing (review and editing).
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This work was supported by the Allianz Research Chair Prescriptive business analytics in insurance at KU Leuven and the International Funds KU Leuven under Grant C16/15/068.