
Abstract
Sediment transport modeling is an important problem to minimize sedimentation in open channels that could lead to unexpected operation expenses. From an engineering perspective, the development of accurate models based on effective variables involved for flow velocity computation could provide a reliable solution in channel design. Furthermore, validity of sediment transport models is linked to the range of data used for the model development. Existing design models were established on the limited data ranges. Thus, the present study aimed to utilize all experimental data available in the literature, including recently published datasets that covered an extensive range of hydraulic properties. Extreme learning machine (ELM) algorithm and generalized regularized extreme learning machine (GRELM) were implemented for the modeling, and then, particle swarm optimization (PSO) and gradient-based optimizer (GBO) were utilized for the hybridization of ELM and GRELM. GRELM-PSO and GRELM-GBO findings were compared to the standalone ELM, GRELM, and existing regression models to determine their accurate computations. The analysis of the models demonstrated the robustness of the models that incorporate channel parameter. The poor results of some existing regression models seem to be linked to the disregarding of the channel parameter. Statistical analysis of the model outcomes illustrated the outperformance of GRELM-GBO in contrast to the ELM, GRELM, GRELM-PSO, and regression models, although GRELM-GBO performed slightly better when compared to the GRELM-PSO counterpart. It was found that the mean accuracy of GRELM-GBO was 18.5% better when compared to the best regression model. The promising findings of the current study not only may encourage the use of recommended algorithms for channel design in practice but also may further the application of novel ELM-based methods in alternative environmental problems.
Introduction
Sediment transport analysis is required in urban infrastructure hydraulic design. To design drainage and sewer pipes, sedimentation problems should be addressed. Thus, channels are planned to reduce sediment deposition based on various effective parameters. Self-cleansing is a term used in channel design to encompass two basic sediment motion and nondeposition requirements. 1 The nondeposition theory includes three criteria of nondeposition with clean bed, incipient deposition, and nondeposition with deposited bed. The nondeposition with a clean bed criterion is determined by adjusting a velocity or shear stress to satisfy a clean bed channel.2,3 The incipient deposition is the moment when suspended particles start to deposit. The phenomenon could be set at some area of the channel bed, free of a deposited layer. For the nondeposition with deposited bed concept applicable for large-channel design, an acceptable deposited bed depth is used to decrease the cost of channel construction..4,5
Nondeposition sediment transport equations were recommended in recent decades to satisfy nondeposition requirements by adjusting limiting velocity or sediment concentration. Pedroli 6 reported that the sediment size had a significant impact on sediment transport rate. Suspended sediment transport under nondeposition condition was studied by Macke, 7 Arora, 8 Nalluri, and Spaliviero. 9 Detailed experimental studies were conducted on bed load sediment transport and indicated that the design velocity increased with an increase in the pipe size Ab Ghani. 10 May et al, 11 De Sutter et al, 12 and Butler et al 13 analyzed the efficiency of previously suggested equations for the sewer design. Vongvisessomjai et al 14 tested the Camp method in sewer design and demonstrated its significant overestimation for flow velocity computation.
Safari et al 3 performed tests in a trapezoidal channel and utilizing own experimental data together with data comprising different sources, recommended a model in which a channel shape factor was embedded based on flow resistance consideration. Montes et al 15 carried out experiments in a large pipe and evaluated their developed model in contrast to the existing counterparts. Safari 16 performed experiments in rectangular, V-bottom, U-shape, trapezoidal, and circular channels for determination of nondeposition mode of sediment transport. Utilizing Safari 16 data, Safari and Aksoy 17 suggested a self-cleansing design model using a simple shape factor applicable for variety of channel shapes. Selected classical regression models are given in Table 1.
Empirical regression equations for nondeposition with clean bed mode of sediment transport

Variety of machine learning techniques were used in open channel sediment transport models. For example, Ab Ghani and Azamathulla 18 tested gene expression programming and uncertainty analysis in sediment transport models. Azamathulla et al 19 implemented adaptive neuro fuzzy inference system (ANFIS) in sediment transport modeling and demonstrated its superiority when compared to the typical regression methods.
Recently, various machine learning techniques, for example, support vector machine (SVM) and extreme learning machine (ELM), SVM-Wavelet, SVM-firefly algorithm, decision tree-artificial neural network (DT-ANN), neuro-fuzzy-based group method of data handling, combination of evolutionary algorithm and ANN, evolutionary polynomial regression, generalized structure group method of data handling, and invasive weed optimization-based ANFIS were attempted to improve sediment transport model performance by Roushangar and Ghasempour, 20 Ebtehaj et al, 21 Ebtehaj et al, 22 Ebtehaj et al, 23 Najafzadeh and Bonakdari, 24 Ebtehaj and Bonakdari, 25 Roushangar and Ghasempour, 26 Najafzadeh et al, 27 Safari et al, 28 and Safari et al, 29 respectively. The above-mentioned studies utilized limited number of data, which can be considered as their main deficiency. As can be seen in the studies mentioned above, hybrid algorithms show superior performance in modeling compared to standalone algorithms.
Recently, ELM technique became popular in modeling studies for variety of environmental problems.30–33 ELM is easy to use and various analytical solutions could be integrated in its algorithm.34–40 Deo and Şahin 41 investigated the drought index using ELM and ANN. They illustrated the outperformance of ELM in contrast to the ANN by means of model precision and speed. They indicated that ELM is much more faster than the ANN. Online sequential extreme learning machine (OS-ELM) was utilized by Yadav et al 34 for flood forecasting. They showed that OS-ELM was superior to genetic programming, ANN and SVM. As an alternative ELM method, Shamshirband et al 42 implemented kernel extreme learning machine for global solar radiation modeling. They indicated that KELM performed better than support vector regression.
Roushangar and Shahnazi 43 implemented wavelet-KELM for estimation of sediment transport with three different scenarios. Inaba et al 44 introduced generalized regularized extreme learning machine (GRELM), which is a method that makes robust to outlier. They stated that the computing time of the method is less 45 in contrast to the ELM. One of the main advantages of the GRELM method is that, there is no need to determine the optimal number of neurons. This method reduces the number of neurons to the optimum for initial conditions if the number of neurons is large enough. 44
This study has three main research contributions. First, this study promotes the sediment transport modeling through implementation of six algorithms of ELM and GRELM coupled with particle swarm optimization (PSO) and gradient-based optimizer (GBO) for the first time in open channel hydraulics. The weight and bias values of the ELM and GRELM methods are hybridized with the novel GBO algorithm and compared with the traditional PSO algorithm performance.
Second, the validity of a design model is related to the range of data used for the model development. While majority of the studies utilized narrow data range, in this study, for the sake of enhancing the validity of the models, wide data ranges collected from different channel cross-sectional shapes were utilized. This is the first implementation of such a large number of experimental data for developing machine learning-based sediment transport models. Furthermore, a data preprocessing analysis to identify the most representative data split samples. Third, effective variables involved in sediment transport hydraulics were incorporated into the model's structure where a channel shape factor is considered in the machine learning-based sediment transport modeling.
Methodology
Experimental data
Experimental laboratory data reported by Mayerle, 46 May, 47 Ab Ghani, 10 Vongvisessomjai et al, 14 Safari, 16 and Montes et al 15 are used in this study. Mayerle 46 carried out tests in two cross-sectional shapes as circular and rectangular. The circular PVC channel had a 20.5 m length and 152 mm diameter. One channel of rectangular had 12.2 m length and 311 mm width and, the other one had 12.6 m length and 462 mm width. Six different granular material sizes with range of 0.5–8.74 mm were utilized in the tests. May 47 performed tests in a circular pipe with 21.3 m length and 450 mm diameter. Granular material with 0.73 mm size was utilized in the tests.
Ab Ghani 10 performed tests in three channels having circular cross-section shape with diameters of 154, 305, and 405 mm, where 154 and 305 mm diameter pipes had 20.5 m length and 405 mm diameter channel had 21.3 m length. In experiments for channel of 405 mm diameter, granular material size of 0.72 mm and, for 154 and 305 mm diameter pipes, six granular material sizes ranging from 0.46 to 8.3 mm were used. Vongvisessomjai et al 14 performed tests in two channels having diameters of 150 mm and 100 mm, and 16 m length. Three different granular materials having sizes 0.2–0.43 mm were used in the experiments. Further information about these experimental data can be found in Safari et al.1,28
Novel experimental data of Safari 16 and Montes et al 15 are used in this study, simultaneously, for the first time in the relevant literature. Safari 16 conducted experiments in five cross-sectional shapes: circular, rectangular, trapezoidal, V-bottom, and U-shape channels with length of 12 m. These cross-sectional shapes had approximately width of 300 mm. Four granular materials having median sizes of 0.15–1.52 mm were used. Montes et al 15 conducted tests in a pipe with 595 mm diameter and 10.5 m length. Granular materials with sizes ranging of 0.35–2.60 mm were used in the experiments. List of data sources are given in Table 2.
The datasets used in this study
D is circular channel diameter.
Extreme learning machine
Having single-layer feedforward neural network (SLFN), ELM was suggested by Huang et al. 48 ELM is a learning algorithm that creates input weights at random and analyzes the SLFN output weights. 49 The advantages of ELM include better performance, learning speed, applicability, and competence for several types of activation and kernel functions.50–52 It could be shown that ELM includes integrated radial basis function (RBF) and hidden nodes through:
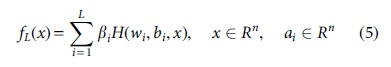
in which βi is the weight of the ith hidden and output nodes, wi and bi indicate the hidden nodes learning variables (weights and bias) and L is the hidden nodes number.
in which g(x) denotes the activation function type, for instance, sigmoid, radial basis, hardline, and so on. Here, g(x) refers to the radial basis activation function that could be written as follows:
in which wi and bi denote the center and impact factor of ith RBF node. Eq. (7) can be expressed as below:
in which
where T denotes the training target matrix and H is ELM's hidden layer output matrix. The adjustment of the output values to the target values (T) was achieved by editing the output weights as
Output weights (β) were calculated with HT that is a Moore–Penrose generalized inverse matrix of ELM's hidden layer output. In the present study, hidden layer number of neurons was adjusted as 30 through a trial and error procedure and, as an activation function, RBF was used in the ELM model framework. The architecture of the ELM is depicted in Figure 1.
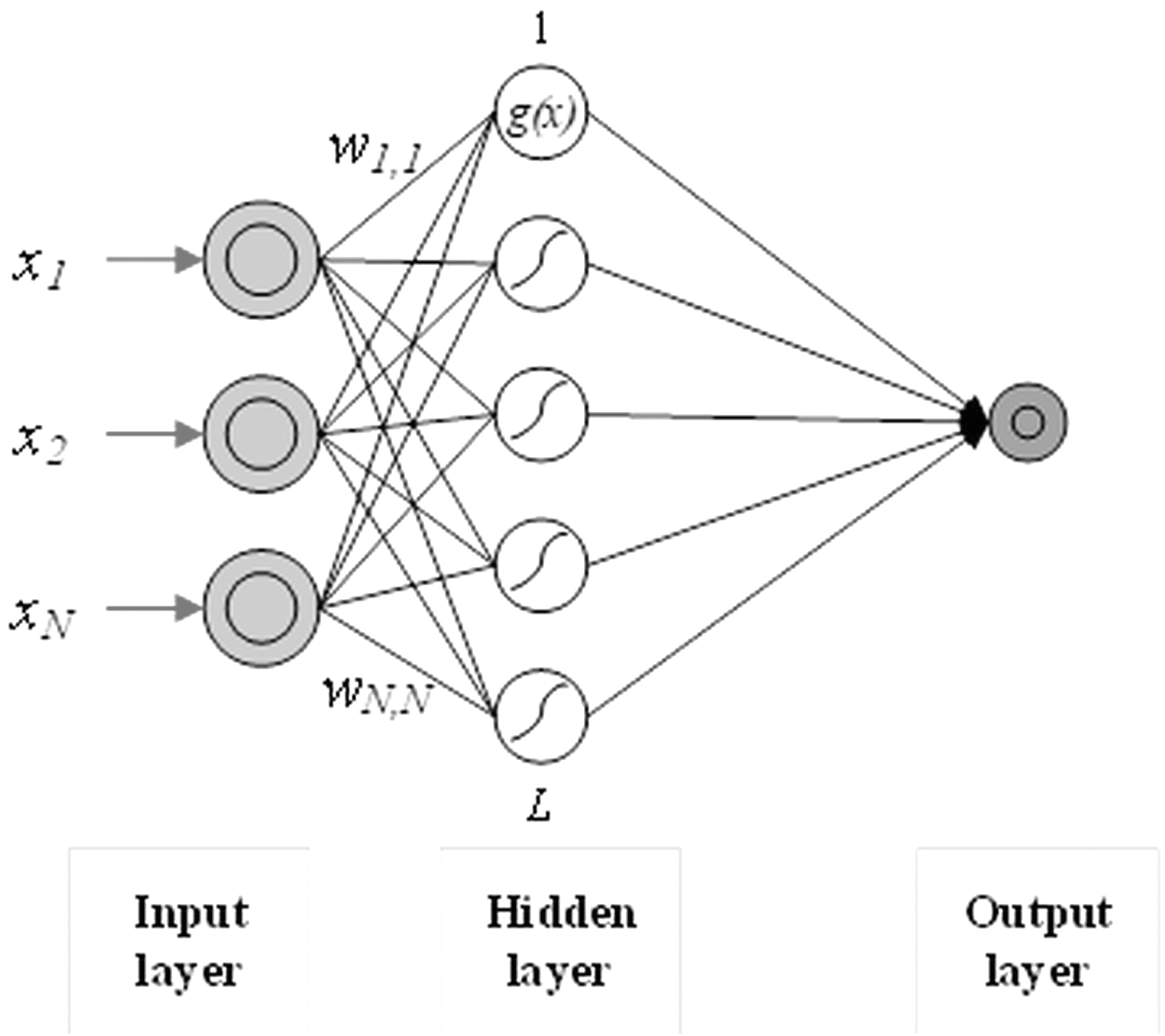
The general ELM structure. ELM, extreme learning machine.
Generalized regularized extreme learning machine
Alternative generation of ELMs were developed that are more compatible with various data types by editing classic ELM weights,53,54 loss,55,56 and activation functions.37,49,57 Deng et al
53
introduced the weighted regularized ELM through including a positive quantity in the
in which ϵ denotes the error vector, C regularization variable,  is the connection of M hidden layer neurons and
is the connection of M hidden layer neurons and
To analyze the output weights, Martínez-Martínez et al
58
emphasized various penalties for least squares regression. Variety types of penalties such as Lasso, ridge regression, and elastic nets59–61
were studied in the regularization. The three regularization methods were generally defined as

in which λ denotes the regularization variable, the
Wang et al 62 were the first authors who investigated generalized ELM (GELM). 63 Output weights are fixed in the classical ELM and unrelated to the sample inputs. When compared to ELM, GELM applies p-order reduced polynomial functions for all input features as output weights. More willingly than using R-ELM, to each T value, they searched for jointly sparse solutions. The motivation was to determine a solution with common nonzero support that would reveal a compact network (Fig. 2). The GRELM method is implemented in R-ELM for multiclass classification problems. GRELM uses alternating direction method of multipliers 64 for solving the Eq. (14):

The general GRELM structure. GRELM, generalized regularized extreme learning machine.
in which
Particle swarm optimization
PSO algorithm is a swarm intelligence method. Eberhart and Kennedy
66
developed this approach for optimizing difficult engineering problems by utilizing members of a population known as particles, which they named the particle algorithm. In each generation, the particle positions are updated by applying a set of velocity vectors to the current values. While the optimization process is in progress, each particle regulates its location in relationship to its own experience and that of the optimal experience. During each generation, the position and velocity of each particle is determined by Eqs. (15) and (16):
where k represents particle of the movement,
Therefore,
Gradient-based optimizer
Metaheuristic algorithms are inspired by nature or basic principles. GBO, which is one of the metaheuristics, was developed using Newton's approaches by Ahmadianfar et al.
67
First, GBO method is started by selecting initialize parameters, which includes number of iterations and the population size depending on the problem complexity. In GBO, the vector of N vectors in D-dimensional space can be described. Each member of the population indicates vector (Xm) in GBO. To initialize, N vectors with D dimensionally are created as follows:
where LB and UB are lower boundary and upper boundary in problem definition, respectively. rand is the random vector within range [0, 1].
Second, the GBO algorithm searches feasible space using gradient search rule approach. The GSR regulates vector movement to improve search within the feasible domain and reach better placements. The GSR method is suggested with the goal of increasing the exploration tendency and accelerating the convergence of the GBO. It is based on the notion of the GB method. This rule, however, is derived from Newton's gradient-based technique. The GSR is expressed as follows:
where rand and randn represents random value and the value with a normal distribution, which includes vector of N element. ɛ is a small number within the range of [0, 0.1]. xworst and xbest are the positions during the optimization process, R1 is the weighting factor and um + 1 is the new vector generated by updating xm. The GD is expressed as follows:
where R2 parameter is a random value that enables each vector to have a unique step size. For each iteration, new solutions are obtained using GSR, GD, and xm. Finally, the GBO uses local escaping operator to tackle complicated issues. This operator can dramatically alter the position of solution. 68
Hybridization process
In this study, ELM and GRELM standalone models was applied to determine best model for sediment transport. Then, ELM and GRELM hybridized with PSO and GBO. Therefore, four hybrid algorithms, ELM-PSO, ELM-GBO, GRELM-PSO, and GRELM-GBO were utilized for prediction of particle Froude number in open channel. Node parameters of the ELM and GRELM, biases and weights were optimized using root mean square error (RMSE) as fitness function. Table 3 indicates PSO and GBO parameters. Figure 3 displays flowchart of PSO and GBO. The hybrid models results were examined in terms of performances and finally the best model is introduced as the superior model for particle Froude number computation.
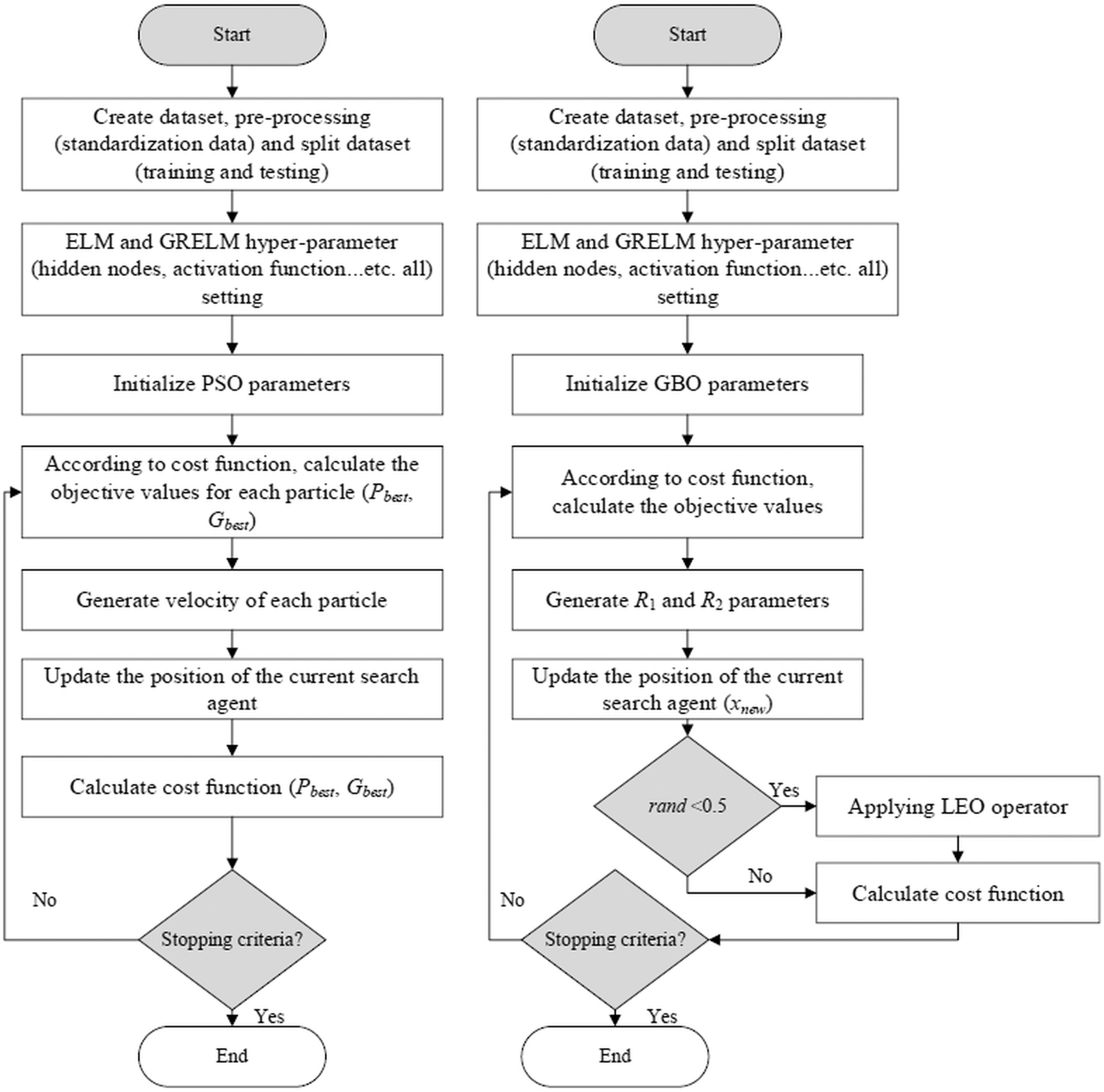
The flowchart of PSO and GBO. GBO, gradient-based optimizer; PSO, particle swarm optimization.
The initial parameters of particle swarm optimization and gradient-based optimizer evolutionary algorithms
GBO, gradient-based optimizer; PSO, particle swarm optimization.
Performance criteria
The analysis of model performance is important in investigating the credibility of the models. Thus, RMSE, root mean square difference (RMSD), mean absolute error (MAE), mean absolute relative error (MARE), BIAS, and coefficient of determination (R 2 ) were used in this study to determine the goodness-of-fit index. The model performs well with R2 close to the unity, and RMSE, MAE, and MARE close to zero. The RMSE, MAE, MARE, BIAS, and R2 could be computed, using the below equations, respectively:

where, yj is the observed value, ŷj is the predicted value, subscript of m indicates the mean value, and n is the data number.
Results
Data preparation
Effective self-cleaning models use flow, fluid, and sediment characteristics.
1
Within the structure of self-cleansing sediment transport models, sediment volumetric concentration (Cv) or particle Froude number 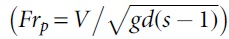 is used as dependent parameter as functions of other effective parameters. Relaying on the relevant literature, flow velocity (V), gravity acceleration (g), hydraulic radius (R), fluid-specific mass (ρ), fluid kinematic viscosity (υ), sediment volumetric concentration (Cv), median size of sediment (d), channel friction factor (λ), and sediment relative specific mass (s) could be considered as effective sediment transport variables for the modeling. Furthermore, P/B as a cross-section shape factor can be used to express the channel shape properties for generalization of the developed model.
17
Taking into account of aforementioned variables, as s group of dimensionless parameters, following expression is written.
is used as dependent parameter as functions of other effective parameters. Relaying on the relevant literature, flow velocity (V), gravity acceleration (g), hydraulic radius (R), fluid-specific mass (ρ), fluid kinematic viscosity (υ), sediment volumetric concentration (Cv), median size of sediment (d), channel friction factor (λ), and sediment relative specific mass (s) could be considered as effective sediment transport variables for the modeling. Furthermore, P/B as a cross-section shape factor can be used to express the channel shape properties for generalization of the developed model.
17
Taking into account of aforementioned variables, as s group of dimensionless parameters, following expression is written.
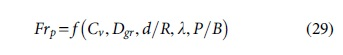
where Dgr is the dimensionless grain size parameter as
Statistical characteristics of the utilized data are listed in Table 4. In the current study, data split rates of 70% and 30% were applied to the whole data for training and testing stages, respectively. Based on the results reported by Ebtehaj et al, 69 who conducted uncertainty analysis, it was indicated that the split between training and testing data would not make a significant difference in model performance; however, the best data split rate was reported as 70% and 30% during the training and testing stages, respectively.
Statistical properties of the entire data
SD, standard deviation.
Determination of the best data distribution
The distribution of training and testing data affects the machine learning modeling results. Inappropriate training and testing data discriminations may cause to overfitting or underfitting problems. In the present study, laboratory data taken from six different sources were compiled. The utilized data sets included the widest data range in the literature. An accurate sediment transport model should fit the best-fit line to avoid underestimation or overestimation problems. Otherwise, a lower learning status would prevent a safe infrastructure planning. Similarly, overestimation problem would lead to a noneconomic model. Considering these problems, the dataset was determined to include 10 random distributions based on 70% for training and 30% for testing distributions. The statistics of the data distributions are presented in Figure 4.

Boxplots for different data splits at training and test stages.
In previous studies conducted with a smaller data range, it was reported that Cv was the most effective parameter. On the contrary, outliers affect the performance of the machine learning methods. As seen in Figure 4, the outlier count was quite higher for the Cv input. This is because of the quite wide data range. It was suggested to remove the outliers and data noise to improve the machine learning performance. However, it is impossible for the experimental data used in this study.
The utilized data were divided into 10 different sections as training and testing splits. The boxplots presented in Figure 4 consist of five sections; minimum and first (q1), median and third (q3) quartiles, and maximum. Points other than those specified exhibit outliers (O). In the present study, maximum whisker length (w) was selected as 1.5. Outlier initial value was calculated using Eq. (31):
where m indicates the model number and q is quartile of data. Positive skewness could be observed in Table 3 and Figure 4. Standardization of the data was conducted between [−1 1] applying the below relationship.
Utilizing the randomly selected 10 different data distributes, ELM and GRELM models were developed. The results are given in Table 5 for 10 different data split scenarios. The performances of two models developed in this study, namely ELM and GRELM, were compared based on various statistical error measurement criteria, including R2, RMSE, MAE, BIAS, and MARE, as shown in Table 5 for the training and testing phases, separately. Results indicated that GRELM was superior to ELM in all models. Training performance results are important in machine learning techniques where a model could have overfitting or underfitting problems. These problems are solved during the training and testing stages. ELM could also lead to overfitting problems, especially for higher number of neurons. To tackle this problem, the most suitable hidden neurons number is determined by choosing the model where the training and testing performances were almost the same.
Performance of extreme learning machine and generalized regularized extreme learning machine models for different data distributions
ELM, extreme learning machine; GRELM, generalized regularized extreme learning machine; MAE, mean absolute error, MARE, mean absolute relative error; RMSE, root mean square error.
After all, training and testing data ranges are closely related to overfitting or underfitting issues. Especially, in S4 and S6, the training data range is smaller than the testing counterpart for many parameters (Fig. 4). Therefore, S4 and S6 are models with the highest overfitting problem. Training performance was better than test performance in all different scenarios for GRELM. However, for GRELM and ELM, test performances showed better results than training in some scenarios. Considering the data distributions in S8 and S9 in Figure 4, test data ranges are smaller than training data ranges. For all scenarios, the BIAS criterion gave better results in training stage in contrast to the testing outcomes.
As a result of all these indicators, S7 was chosen as the superior model and accordingly, it is selected to compare with classical regression equations. For ELM and GRELM models the rate of change of the RMSE values are found as 20.83% and 25.89%, respectively.
Figure 5 demonstrates the scatter of machine learning methods at the training stage. Outlier initial values for models 1–10 for the training data were O1 = 12.54, O2 = 12.06, O3 = 12.42, O4 = 11.79, O5 = 11.89, O6 = 11.94, O7 = 12.32, O8 = 12.43, O9 = 12.18, and O10 = 12.43, respectively (Fig. 4). Model outliers could be observed especially at the beginning of the scatter. GRELM's outlier performance was better than that of ELM. ELM and GRELM exhibited almost the same trends.

Scatter plots for models at training phase.
To provide a practical tool for, the following equations (Eqs 27–28) can be used to determine the Frp using the best GRELM-GBO model, where InV is the input variable vector, InW is the input weight, OW is the output weight, and BHN is the bias of hidden neurons as given in Table 6.
The weights and bias values for generalized regularized extreme learning machine gradient-based optimizer model
Comparison of hybridized ELM and GRELM with classical benchmarks
Statistical comparison of ELM, ELM-PSO, ELM-GBO, GRELM, GRELM-PSO, and GRELM-GBO as machine learning algorithms and conventional regression equations of Ab Ghani, 10 Vongvisessomjai et al, 14 Montes et al 15 and Safari, and Aksoy 17 is listed in Table 7 by means of R2, RMSE, MAE, BIAS, and MARE. Results show that ELM, ELM-PSO, ELM-GBO, GRELM, GRELM-PSO, and GRELM-GBO outperform all empirical regression equations although, Safari and Aksoy 17 is superior to the other classical regression equations. GRELM-GBO provided best results with lowest error and higher correlation. Since GRELM-GBO had positive BIAS values, it produced slight overestimation. GRELM-GBO improved the best regression equation by a factor of 18.5%. Figure 6 illustrates the scatter plots for ELM, ELM-PSO, ELM-GBO, GRELM, GRELM-PSO, GRELM-GBO, and conventional regression equations. As seen in Figure 6, all machine learning models and conventional regression equations were distributed for outlier values.
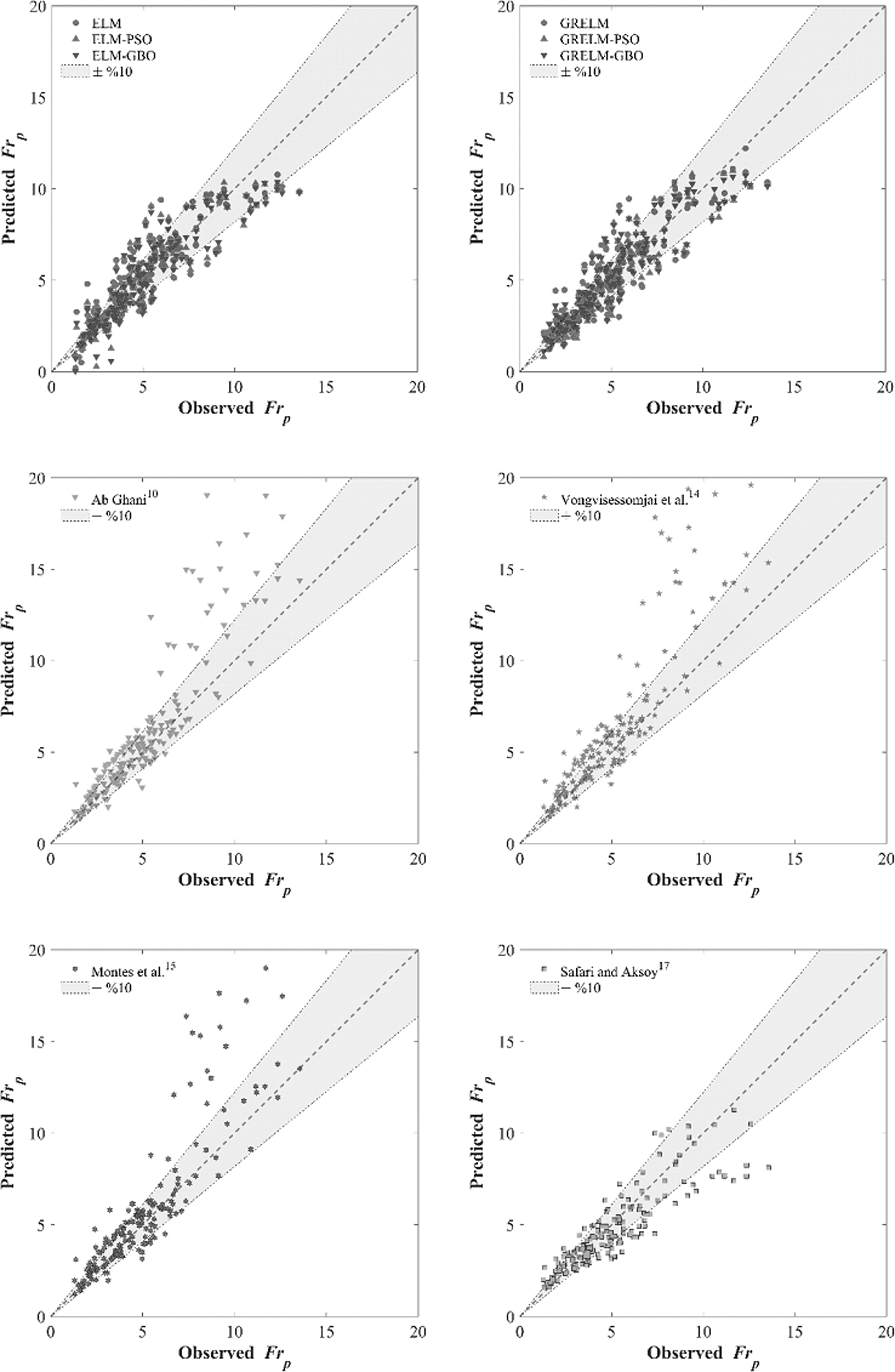
Scatter plots for machine learning and empirical regression equations at testing stage.
Comparison of models for best distribution (S7)
For machine learning models of ELM and GRELM at testing sages for 10 different splits, the initial outliers were O1 = 11.45, O2 = 12.63, O3 = 11.78, O4 = 13.22, O5 = 13.01, O6 = 12.89, O7 = 12.03, O8 = 11.73, O9 = 12.37, and O10 = 11.75 (Fig. 6). When the performances of machine learning algorithms are evaluated, it can be found that GRELM outlier performance is found superior to ELM.
Overestimating and underestimating model performances are common problems in machine learning modeling. For the case of overestimation, the results of the model will be larger than their actual values. This design tool will create economic problems in the planning of engineering structures where channels need higher velocity and accordingly, steeper bed slope. However, underestimation is also the case where the model results are lower than the real value. This problem will cause problems such as early sedimentation and maintenance expenditures. To address these concerns, it is needed to construct a model with minimum underestimation or overestimation. Although Safari and Aksoy 17 model generated slight underestimation, Ab Ghani, 10 Vongvisessomjai et al, 14 and Montes et al 15 models gave a significant overestimation.
Discussion
Determination of the flow velocity required for sewer design is vital in infrastructure engineering. As a design standard, different self-cleansing approaches of nondeposition, incipient deposition, and incipient motion can be implemented. This study concentrates on the nondeposition with clean bed design method. Existing machine learning-based models were established for different cross-section shapes where channel geometrical characteristics were not utilized as a model effective parameter. Overestimation and underestimation of a design model cause for additional expenditures. For example, as described in the previous section, the conventional regression equations underestimate or overestimate particle Froude number in testing phase. Designing a channel that underestimates the expected Froude particle number induces early overflow and sediment deposition, the reverse application of an overestimated model causes a greater velocity and, therefore, a steeper bed slope is needed in channel construction. This study suggests GRELM-GBO, as a novel machine learning method to overcome all these problems.
Classical nonlinear regression approach was widely used to develop models considering the effective parameters involved in nondeposition mode of sediment transport. Several studies have shown a deficit in accurate estimation for certain cross-sectional forms in classical regression methods.3,17 Toward this, the current study applied ELM, ELM-PSO, ELM-GBO, GRELM, GRELM-PSO, and GRELM-GBO as robust machine learning methods. Although there are many studies in the implementation of ELM, the novel generation of ELM as GRELM algorithm was rarely used in the literature for the environmental problems. Thanks to the ELM compact algorithm, it can be integrated very quickly and easily. To this end, in this study, the GRELM-PSO and GRELM-GBO methods, which are superior to hybridized ELMs, were used to model the nondeposition mode of sediment transport applicable for channel design. Figure 7 illustrates an improvement in machine learning modeling when compared to the best conventional regression equation 17 for all models in testing phase. Percentage improvement (Pi) was calculated using
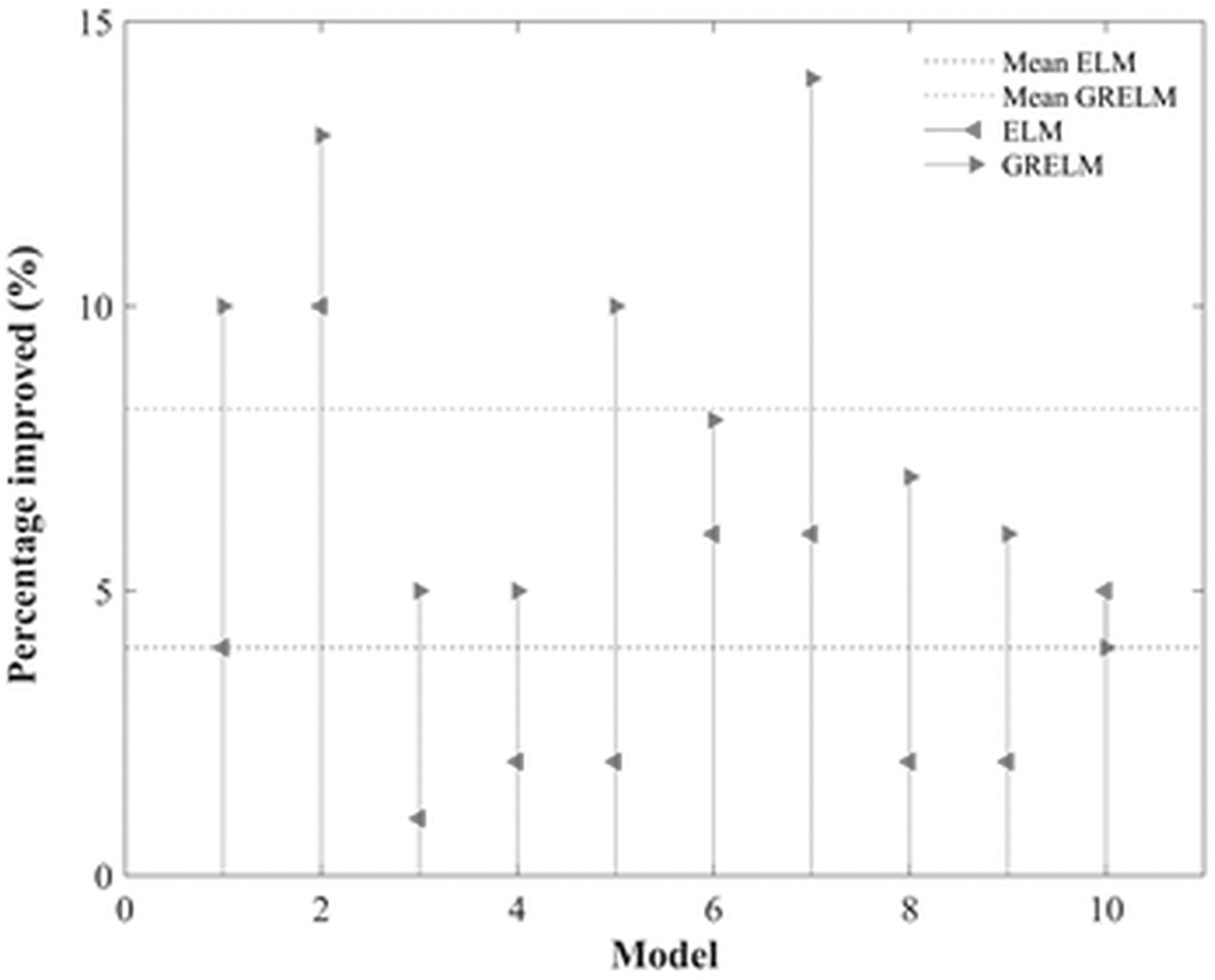
Comparison of the best empirical regression equation (Safari and Aksoy 17 ) with ELM and GRELM machine learning models.
where RMSEs is RMSE value of the best conventional regression equation 17 and RMSEm is RMSE value of machine learning algorithms. GRELM outperformed ELM based on the percentage improvement. The improvement ranking considering machine learning algorithms did not change for all models. The improvement in GRELM has an average of 15% and GRELM-GBO 18.5% better when compared to the traditional regression equation in all data splits. The data range is very important in sediment transport modeling studies. Especially the data range size is of importance in solving the problem of overestimation and underestimation.
In present study, variety of cross-sectional data were used and a wide velocity range was modeled. In addition, this study provides detailed information for examining the data distribution effect on the machine learning modeling results. Figure 8 shows the Taylor diagram of ELM, ELM-PSO, ELM-GBO, GRELM, GRELM-PSO, GRELM-GBO, and classical regression equations for superior model. According to the Taylor diagram, it was seen that the best model was GRELM-GBO.

Taylor diagram for comparison of models.
Experimental data of the present study were performed under laboratory conditions, which can be considered as the main deficiency of the study. Furthermore, experimental studies have been performed using noncohesive sediment, but for the real cases, the cohesive sediment may be appeared in the field studies. It would be useful to collect field data to develop more reliable design models in the future studies. In addition, detailed studies are needed to examine the data distribution strategy presented in this study. It is recommended that machine learning algorithms powered by hybrid algorithms can be tested in future studies applying alternative ELM-based algorithms.
Conclusions
Existing machine learning-based self-cleansing models were established on limited number of data neglecting a channel shape factor for nondeposition mode of sediment transport. Applying novel GRELM algorithm robust self-cleansing model is developed and their outperformances were demonstrated in contrast to the conventional ELM and empirical regression equations. Through the modeling, all experimental data reported for the nondeposition mode of sediment transport are utilized. Wide ranges of sediment volumetric concentration, sediment size, channel size, and cross-section shapes are considered in this study, which bring a significant credibility for the developed models. Empirical equations have significant overestimation or underestimation, which cause early overflow and early sedimentation, respectively, when they are applied for channel design in practice. Machine learning-based models of ELM, ELM-PSO, ELM-GBO, GRELM, GRELM-PSO, and GRELM-GBO are found superior to the empirical regression equations.
Although GRELM-PSO and GRELM-GBO give better results than conventional models, GRELM-GBO slightly outperforms GRELM-PSO in accurate calculation of flow velocity. Results obtained in this study are promising and can be implemented as reliable method for sewer and drainage design in practice, where the models are established on large number of data covering various types of channel cross-section, and more importantly, incorporating a channel parameter in the model based on robust machine learning algorithms. Collecting filed data for the development of a more reliable model applying novel generation of ELM-based hybrid algorithms are recommended as future research directions.
Footnotes
Authors' Contributions
E.G.: conceptualization (equal), formal analysis (equal), methodology (equal), software, validation (equal), and writing—original draft (lead). M.J.S.S.: conceptualization (equal), formal analysis (equal), data curation, methodology (equal), validation (equal), writing—original draft (supporting), writing—review and editing, and supervision.
Author Disclosure Statement
No competing financial interests exist.
Funding Information
No funding was received for this article.