
Abstract
The influence maximization (IM) problem is defined as identifying a group of influential nodes in a network such that these nodes can affect as many nodes as possible. Due to its great significance in viral marketing, disease control, social recommendation, and so on, considerable efforts have been devoted to the development of methods to solve the IM problem. In the literature, VoteRank and its improved algorithms have been proposed to select influential nodes based on voting approaches. However, in the voting process of these algorithms, a node cannot vote for itself. We argue that this voting schema runs counter to many real scenarios. To address this issue, we designed the VoteRank* algorithm, in which we first introduce the self-voting mechanism into the voting process. In addition, we also take into consideration the diversities of nodes. More explicitly, we measure the voting ability of nodes and the amount of a node voting for its neighbors based on the H-index of nodes. The effectiveness of the proposed algorithm is experimentally verified on 12 benchmark networks. The results demonstrate that VoteRank* is superior to the baseline methods in most cases.
Introduction
In the past two decades, the rapid development of information technology has brought huge convenience to individuals. More and more people have gradually participated in various social networks, such as Facebook, Twitter, and WeChat, on which a pool of information is exchanged every day.1,2 The boom of social networks has facilitated the research related to network analysis and mining. Among these primitive tasks of network analysis and mining, the influence maximization (IM)3,4 has aroused remarkable attention of researchers due to its immense potential in a plentiful of applications such as viral marketing, 5 disease analysis, 6 rumor control, 7 and social computing. 8 The IM problem is defined to select a group of influential nodes as seed nodes to disseminate information on a network and make the influence of these nodes as broadly as possible.9,10 Accordingly, the key issue to settle the IM problem is how to identify the influential nodes.11,12
To address the issue, a large number of algorithms have been proposed in the literature. Kempe et al. 11 proved that it is nondeterministic polynominal-hard to obtain the optimal set of seed nodes in IM problem and proposed a greedy algorithm to settle the problem. However, their greedy algorithm is extremely inefficient in large-scale networks. Afterward, Leskovec et al. 13 developed the Cost-Effective Lazy Forward selection (CELF) algorithm to reduce the computational cost of the greedy algorithm using a lazy forward strategy. By the same token, Goyal et al. 14 proposed the CELF++ algorithm based on the submodular property of objective function. In comparison with CELF, CELF++ further enhances the time efficiency since it reduces the unnecessary checking of candidates. Although these algorithms have the ability to acquire nodes with high propagation quality, they are very time-consuming owing to the requirement of Monte Carlo simulation.
However, heuristic algorithms were designed to solve the IM problem. Degree centrality considers the degree of a node when determining its importance. 15 Eigenvector centrality holds the view that a node is important if its neighbor is important. 16 H-index is often used to evaluate the influence and reputation of journals or scholars. Lü et al. 17 first extended H-index into networks to evaluate the influence of nodes. By mixing the degree and core number of a node as well as the diversity of its neighbors, Sheikhahmadi and Nematbakhsh 2 proposed the mixed core, degree and entropy (MCDE) algorithm to calculate the importance of the node. The cluster rank 18 measures the influentiality of a node according to its local clustering coefficient. The idea behind cluster rank is that the neighbors with high clustering coefficients can shorten the range of information dissemination.
Inspired by the cluster rank algorithm, Zareie et al. presented an Extended Cluster Coefficient Ranking Measure (ECRM), in which they further take into account the common hierarchy between a node and its neighbors. Wang et al. 19 proposed an improved K-shell 20 method, that is, IKS, by considering the information entropy of nodes. This method chooses influential nodes from not only the higher shell but also the lower shell since nodes in a lower shell sometimes may be more influential than nodes in a higher shell. 2 Zhang et al. 21 came up with a vote-based method, called VoteRank, to find the influential spreaders in a network. The VoteRank method selects the spreaders as per the voting scores of nodes attained from their neighbors. The WVoteRank approach 22 extended VoteRank by considering both node degree and edge weight in voting process.
WVoteRank can be applied for both unweighted and weighted networks. Moreover, Kumar and Panda
23
improved the WVoteRank approach by extending the scope of neighborhood from one-hop to two-hop. The EnRenew algorithm
24
leverages the information entropy of nodes when identifying influential spreaders and then outperforms VoteRank in terms of final affected scale. In our previous work,
25
we developed the
Among the above algorithms, VoteRank 21 and its variants22–25 addressed the IM problem efficiently and effectively to some extent. However, in these algorithms, the case of self-voting is not considered in voting process. In other words, when choosing influential nodes, a node cannot vote for itself in VoteRank and its variants. We argue that, when electing the influential nodes, self-voting is of significance due to the following two reasons: (1) in many real-world scenarios, one can certainly vote for oneself; (2) self-voting helps to the find influential nodes more accurately. In VoteRank, even the most influential node cannot vote for itself; only its neighbors can choose it as the influential node.
In this regard, we design an improved VoteRank algorithm, named VoteRank*, to finding influential nodes by exploiting the case of self-voting. Besides, we also take into account the diversities of nodes in VoteRank*. To be specific, we compute the voting ability of a node and the voting proportion of a node voting for others based on the H-index values of nodes. To verify the performance of VoteRank* algorithm, we conduct extensive experiments on 12 networks. Experimental results manifest that VoteRank* can enhance the spreading speed and ability compared with the state-of-the-art approaches.
The remaining of this article is organized as follows. We present the proposed method in The Proposed Method: VoteRank* section. In the Experiments section, we show and analyze the experimental results. Finally, the Conclusions section concludes this work.
The Proposed Method: VoteRank*
In this section, we describe our proposed VoteRank* algorithm. VoteRank* improves VoteRank
21
and its successors22–26
by mainly introducing the self-voting mechanism into the voting process when selecting influential nodes. In addition, VoteRank* also considers the difference of nodes in their voting ability and the different voting proportion between nodes. The VoteRank* algorithm is composed of the following steps:
Initialize the voting ability of each node; Compute the voting proportion that each node votes for itself and its neighbors; Calculate the voting score of a node obtained from itself and its neighbors; Choose the node that gets the highest voting score as an influential node; Suppress the voting ability of the selected influential node and its one-hop and two-hop neighbors; Repeat steps 3 to 5 until enough influential nodes are selected.
The detailed procedure of VoteRank* is shown in Algorithm 1. In what follows, the key components of the proposed algorithm are explained.
Initializing voting ability
To vote for the influential spreaders, we need to initialize a value for the voting ability of each node. In VoteRank, each node gets an initial voting ability as 1. However, this initialization is unreasonable. Since nodes in a network can be different from many aspects such as position, function, and role, their voting ability should also be diverse. To be specific, we initialize the voting ability of node v, in this article, according to the following equation:
where hv is the H-index value of node v and
Computing voting scores
In the voting process of VoteRank-like algorithms, a node can only vote for its neighbors. Even the most important node cannot vote for itself. Actually, on many real voting occasions, candidates can vote for themselves. Therefore, the voting mechanisms in those algorithms do not conform to common sense and are not conducive to the identification of influential spreaders. To overcome this drawback, the VoteRank* algorithm introduces a self-voting mechanism in the voting process for the first time. That is, in VoteRank*, a node can vote for itself as well as for its neighbors. Based on self-voting and H-index, we define the voting proportion that node u votes for neighbor v, denoted as

where
In the voting process, a node gets votes from itself and its neighbors. By aggregating those votes, we can compute the voting score of the node. Formally, given node v, its voting score is calculated as follows:
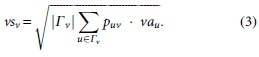
In Equation (3),
When all nodes obtained their voting scores, the node that has the largest score is regarded as the influential spreader identified in this iteration (line 10 in Algorithm 1).
Updating voting ability and voting scores
VoteRank* iteratively chooses the influential spreaders. After a spreader is selected, VoteRank* starts a new iteration to choose the next spreaders if the selected nodes are not enough (lines
If u is a one-hop neighbor of v, the updated
Afterward, VoteRank* updates the voting scores of unselected nodes to pick the next spreader. In fact, in this iteration, only a subset of nodes needs to update their voting scores. Given a node u, if the voting ability of itself and its neighbors is not discounted in this iteration, its voting score keeps the same. Consequently, in VoteRank*, we only need to recompute the voting scores of nodes within three hops of the spreader selected in the last iteration (lines
Complexity analysis
Now, we analyze the time complexity of Algorithm 1. Let N be the number of nodes and
Next, VoteRank* iteratively identifies the remaining
Differences between VoteRank and VoteRank*
In this subsection, we highlight the differences between VoteRank and VoteRank*, which are listed as follows:
When initializing the voting ability of nodes, VoteRank assigns the same value to each node, whereas VoteRank* uses the H-index value of each node.
In VoteRank*, the neighbor set of a node includes its one-hop neighbor and itself; however, the neighbor set of a node only contains its one-hop neighbor in VoteRank.
In the voting process, a node votes the same for each of its neighbors in VoteRank, and the voting score of a node is the sum of the votes it got from its neighbors. In VoteRank*, a node votes different amount of votes for its neighbors, and the voting score of a node is computed based on the weighted sum of the votes it got from its neighbors and the number of neighbors.
After selecting a spreader, VoteRank weakens the voting ability of the one-hop neighbors of the spreader, whereas VoteRank* weakens the voting ability of its one-hop and two-hop neighbors.
Experiments
Data sets
In this article, we evaluate the performance of VoteRank* via extensive experiments on 12 networks drawn from multiple fields. These 12 networks are as follows: (1) an email network among members of a university (Email), 27 (2) a collaboration network of researchers working on Network Science (NetSci), 28 (3) a friendship network extracted from hamsterster.com (Hamster), 29 (4) a social network extracted from Facebook (Facebook), 30 (5) the metabolic network of Caenorhabdities elegans (CE), 31 (6) the collaboration network between a group of jazz musicians (Jazz), 32 (7) a network of scientists studying Condense Matter Physics (Condmat), 33 (8) a structure network of the internet at the router level (Router), 34 (9) a trust network encrypted based on the Pretty Good Privacy algorithm on July 2001 (PGP), 35 (10) the protein-to-protein interaction network of budding yeast (Yeast), 36 (11) a network describing the U.S. air transportation system in 2010 (USAir), 37 and (12) a power grid network of the United States (Power). 38
Table 1 displays the topological characteristics of the 12 networks. In this article, we regard all networks as undirected ones.
The basic structural characteristics of the 12 networks
Here, N and M are the numbers of nodes and edges, respectively.
CE, Caenorhabdities elegans.
Performance metrics
Susceptible–Infected–Recovered model
So far, many researchers have adopted the Susceptible–Infected–Recovered (SIR) model 39 to investigate the effectiveness of IM algorithms. The SIR model is a famous epidemic spreading model, initially used to simulate the dynamic of disease spreading. 39 In the literature about IM problem, it has been adopted by researchers to evaluate the performance of IM algorithms.19,21,40,41
In the SIR model, each node has one of three states: Susceptible (S), Infected (I), and Recovered (R). At the initial time, the states of all seed nodes are I, whereas others belong to S. In each propagation iteration, each infected node spreads the disease to its susceptible neighbors with probability
Based on the SIR model, the infected scale
where N is the number of nodes, and
The final infected scale
where
Average shortest path length
In addition to the SIR model, the average shortest path length Ls between the seed nodes is also used to evaluate the performance of an IM algorithm. 21 Since the identified influential nodes are expected to widely distribute in a network, this measure can gauge the distribution of seed nodes. The computation of Ls is as follows:
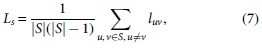
where S is set of seed nodes, and
Results and analysis
In this subsection, we analyze the performance of VoteRank* by comparing it with VoteRank, 21 Degree centrality, 15 K-shell, 20 H-index, 17 IKS, 19 ECRM, 41 MCDE, 2 EnRenew, 24 and VoteRank++. 25
To propagate information according to an IM algorithm, we need to select s seed nodes, that is, the initial influential spreaders. For convenience, we define the ratio of seed nodes
Figure 1 shows the values of infected scale
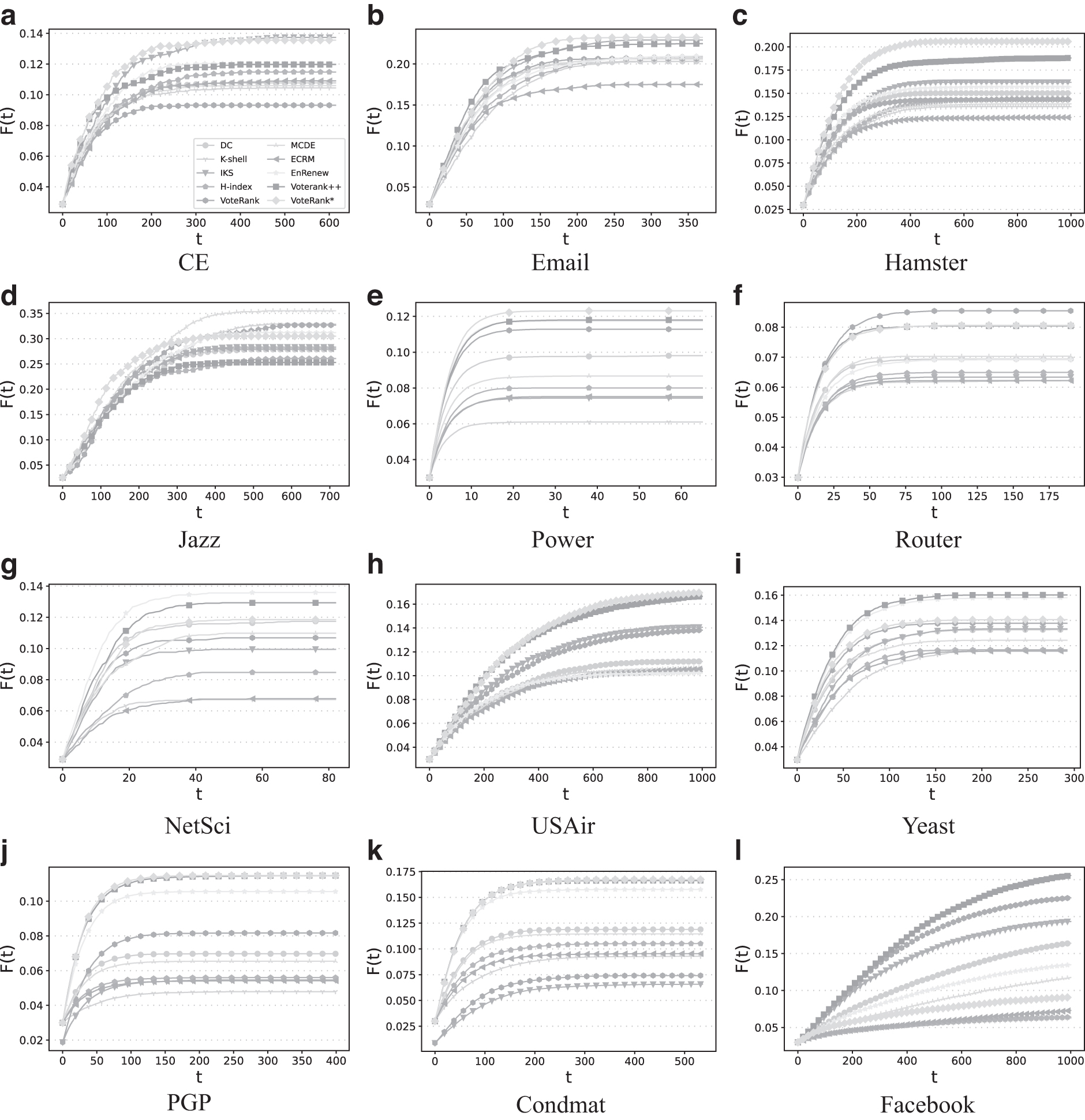
The infected scale
Meanwhile, from the point of view of propagation speed, to spread some message to the same number of nodes, we can spend less time using the seed nodes identified by VoteRank* than those picked out by compared methods on most networks. As a conclusion, the VoteRank* algorithm can find the influential nodes that have stronger information spreading ability in comparison with other methods. In addition, by comparing VoteRank* with VoteRank, EnRenew, and VoteRank++, all of them are VoteRank-like algorithms, we observe that VoteRank* outperforms others on 7 of the 12 networks. This result indicates that the self-voting mechanism proposed in this article can facilitate the identification of influential spreaders.
Next, we analyze the final infected scales of these algorithms with different ratio of seed nodes
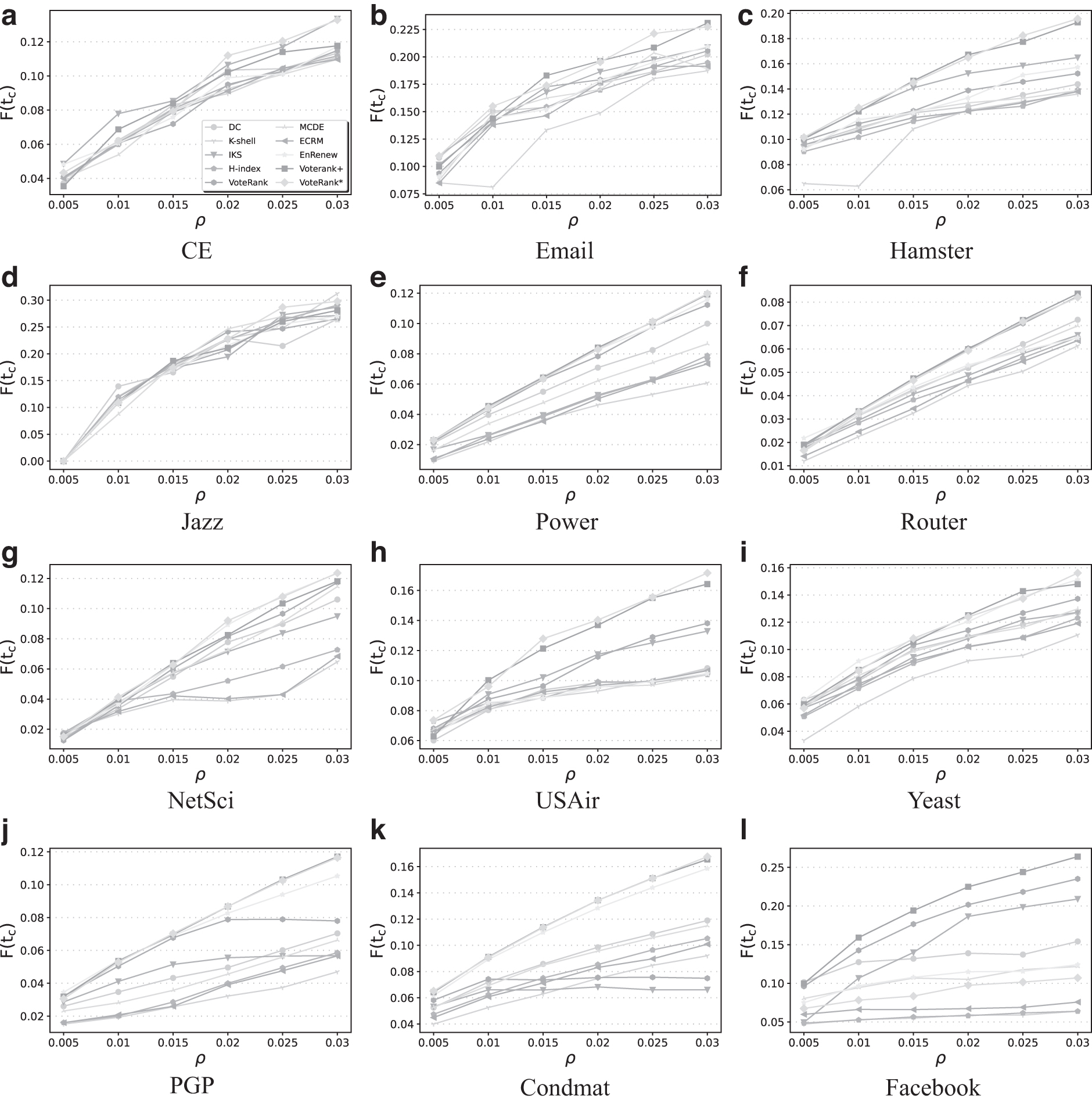
The final infection scale
Kitsak et al. 20 uncovered that the distances between spreaders play a vital role in maximizing the influences. The wider the distribution of seed nodes, the broader the spread of information. Therefore, we further employ the average shortest path length Ls of seed nodes to measure the distribution of them. The results in Figure 3 show that VoteRank* is superior to baselines since it always ranks at the top places. In other words, VoteRank* can select seed nodes more widely in the network, especially in large-scale networks such as Condmat and Facebook. In addition, we find that the corresponding lines of both VoteRank* and VoteRank++ are almost coincident. Besides self-voting, both methods consider the diversities of nodes and suppress the one-hop and two-hop neighbors. As a consequence, most of the influential nodes identified by them may be the same. Nevertheless, VoteRank* outperforms VoteRank and EnRenew in most of the cases. This further confirms that the VoteRank* algorithm can identify the nodes that are broadly distributed.

The average shortest path length Ls between spreaders selected by different methods on 12 networks.
Ablation study
In this subsection, we design an ablation experiment to further demonstrate the effectiveness of the proposed VoteRank*. The most important contribution of VoteRank* is introducing the self-voting mechanism into the voting process. Therefore, the ablation experiment is to analyze the influence of self-voting to the performance of VoteRank*. The results are shown in Figure 4. In this figure, VoteRank*_selfvoting denotes the version of VoteRank* without self-voting. As can be seen from Figure 4, compared with VoteRank*_selfvoting, VoteRank* can find the spreaders that have more infected scales on most networks. As a consequence, the self-voting mechanism plays a key role in the process of selecting spreaders.
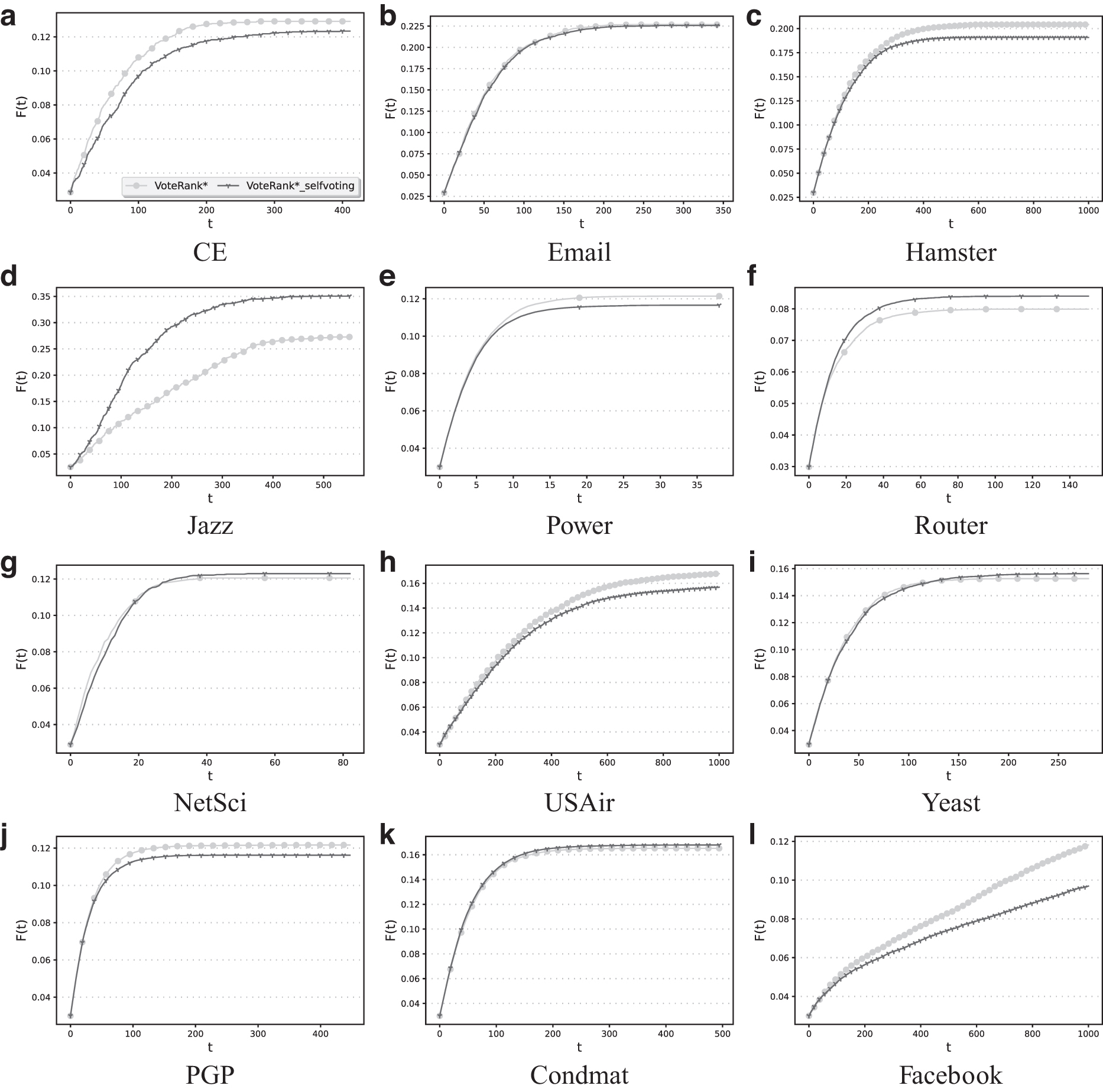
Ablation study of self-voting on 12 networks. VoteRank*_selfvoting is the version of VoteRank* without self-voting. The results are the average of 1000 independent runs with β = 1.5 and ρ = 0.03 under the SIR model.
Conclusions
In this article, we proposed the VoteRank* algorithm to address the IM problem. Inspired by VoteRank and its variants, VoteRank* also leverages a voting approach to choose the influential spreaders. However, in VoteRank and its variants, a node cannot vote for itself. This is a serious defect since, in many real scenarios, one candidate can certainly vote for himself/herself. In VoteRank*, we first introduce the self-voting mechanism to address this defect. Besides, we also consider the diversity of nodes in the voting process of VoteRank*. To verify the performance of the VoteRank* algorithm, we carried out experiments on 12 real networks. The experimental results indicate that the VoteRank* algorithm outperforms the state-of-the-art baselines in most cases.
Footnotes
Authors' Contributions
P.L.: Conceptualization (supporting), software (lead), formal analysis (supporting), writing—original draft (lead), writing—review and editing (equal). L.L.: Conceptualization (lead), formal analysis (lead), writing—review and editing (equal). Y.W.: Software (supporting), writing—original draft (supporting). S.F.: Conceptualization (supporting), formal analysis (supporting).
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This work was supported in part by the Science and Technology Program of Gansu Province (Nos. 21JR7RA458 and 21ZD8RA008) and the Supercomputing Center of Lanzhou University.