
Abstract
Organizations have been investing in analytics relying on internal and external data to gain a competitive advantage. However, the legal and regulatory acts imposed nationally and internationally have become a challenge, especially for highly regulated sectors such as health or finance/banking. Data handlers such as Facebook and Amazon have already sustained considerable fines or are under investigation due to violations of data governance. The era of big data has further intensified the challenges of minimizing the risk of data loss by introducing the dimensions of Volume, Velocity, and Variety into confidentiality. Although Volume and Velocity have been extensively researched, Variety, “the ugly duckling” of big data, is often neglected and difficult to solve, thus increasing the risk of data exposure and data loss. In mitigating the risk of data exposure and data loss in this article, a framework is proposed to utilize algorithmic classification and workflow capabilities to provide a consistent approach toward data evaluations across the organizations. A rule-based system, implementing the corporate data classification policy, will minimize the risk of exposure by facilitating users to identify the approved guidelines and enforce them quickly. The framework includes an exception handling process with appropriate approval for extenuating circumstances. The system was implemented in a proof of concept working prototype to showcase the capabilities and provide a hands-on experience. The information system was evaluated and accredited by a diverse audience of academics and senior business executives in the fields of security and data management. The audience had an average experience of ∼25 years and amasses a total experience of almost three centuries (294 years). The results confirmed that the 3Vs are of concern and that Variety, with a majority of 90% of the commentators, is the most troubling. In addition to that, with an approximate average of 60%, it was confirmed that appropriate policies, procedure, and prerequisites for classification are in place while implementation tools are lagging.
Introduction
Organizations need to ensure that personal information is not shared, but protecting everything in big data ecosystems can be challenging since it is almost impossible. 1 In an approach to adequately protect data, it is imperative to know the data characteristics and understand the aspects/dimensions of big data. 2 Laney, often referred to as the father of big data, had introduced three dimensions that characterize it. 3 Volume is the first and refers to the amount of data created and stored in the digital universe. 4 The second is Velocity, which refers to the speed at which data changes in big data environments. Last but not least is Variety; this characteristic has to do with the nature of the data itself and the manifestations it can pertain to.
Volume and Velocity have had a significant research focus during recent years; however, Variety revealed a different trend. 5 Variety has proven challenging to overcome.6–8 There are no technological tools available to deal with the proliferation of data from many sources (e.g., internal and external, public and private), thus making Variety resilient to software solutions and heavily relying on human effort.9,10 The plethora of different formats, standards, and notations have also increased the risk of identifying personal information, thus augmenting the risk of disclosure. 2 The significant human dependency and the risk of data loss imposed by Variety, alongside the desire of organizations to fully utilize the data for competitive advantage, are critical challenges. In overcoming the limitations and securing the data toward safe processing, the corporate environment requires a structured approach in minimizing the risk with a standardized and automated proposal.
The data confidentiality challenge is driven by regulatory requirements. 11 As it is imperative to govern the activities of data custodians through legislative frameworks, information is increasingly being regulated in multiple sectors. 11 Examples include the Personally Identifiable Information privacy act 5 u.s.c. 552a 2020 edition, Public Sector Information Directive, General Data Protection Regulation (GDPR) law, and Payment Card Industry Security Standards along with anonymization standards such as European Medicines Agency Policy 0070 and the Health Insurance Portability and Accountability Act.12–17 These regulatory acts can have an immediate financial impact in the form of fines that can reach 4% of the annual global turnover. A recent example is Facebook, with a confirmed $5 billion fine and another €56 million potential fines depending on the outcome of 11 ongoing GDPR investigations.18,19
Due to the data loss prevention (DLP) risk, data confidentiality is a candidate for further automation, especially when all these rules and regulations impose a highly complicated legal and compliance framework to which organizations must comply. At the same time, reliance on data-driven analysis and visualization is increasing as confirmed by scholars and business community, leading to the addition of Value as one of the essential V's of big data.20,21 In an attempt to increase Value through big data, the utilization of data will intensify the use of data, which will increase the risk of confidential information being disseminated without proper controls. Once this risk is combined with the Variety effect of big data, it is evident why data confidentiality is considered the most important aspect of big data protection. 1
The increasing use of data along with the evolving regulatory frameworks presents an area of concern for organizations to effectively manage in avoiding associated risks. Toward this requirement, an opportunity for automation and standardization has been identified. Most organizations have embarked on a journey with their Information Security Office (ISO), Chief Data Office (CDO), and Information Technology departments in establishing the required policies and processes. Having this in place, organizations require a framework to automate the process and minimize human intervention, which could lead to errors or impartiality. The corporate cost of not sharing and utilizing the data, as per the big data era adoption has indicated, could limit the businesses' competitive advantage. 22 To that end, having identified the need and associated cost, the opportunity of automation was investigated.
The article proposes a framework toward maximizing big data's utility by mitigating the risk presented by preserving data confidentiality at a corporate level. The approach focuses on the requirements of a rapid turnaround of processing requests for data dissemination, information coverage, automation, standardization, flexibility, accountability, and traceability. In the following sections, the challenge posed will be presented, followed by the proposal, including the system proposal, the prototype, and the evaluation of the approach.
Background Research
In the context of big data, due to real-time processing and the massive quantum of data, new challenges pertaining to security risks and vulnerabilities have come into play. 23 To date, with respect to the issue of confidentiality, most studies have focused on the development of anonymization techniques. With much of the research in anonymization focused on static data, rather than unstructured data, which is a substantial portion of big data lakes. 24 Taking into consideration big data Variety, which introduces further data uncertainty, the problem is further exacerbated. Little work has been carried out in the proliferation of data, and research in academia and industry is limited.7,25 As big data analytics thrive, a part of the legal and governance framework (e.g., GDPR), ethical considerations in respect to the privacy and dignity of human beings are of major concern even in cases where consents for personal information usage are collected.26–28
In addition to these challenges highlighted by researchers, the legal and regulatory framework is constantly changing. The Open Data initiative, along with several other regulatory changes over the past 10 years, has been augmenting researchers' access to confidential information. Although everyone agrees that sensitive information should not be proliferated, the extent of the data protection is covered by different legal guidelines, which can be confusing and lead to unintentional exposure. 29 The exposure risk, along with the aforementioned elevated access, has created the necessity to design a framework that will enforce strong and transparent governance on access. 30
Anonymization is the irreversible process of altering the data in such a manner that it is impossible to identify the person to whom the data refer to, at least in principle. 26 There are three types of attributes in any data pertaining to privacy affecting confidentiality, as described in Table 1. Pseudonymization is a reversible anonymization where data are encrypted and with the use of pseudonyms the process can be reversed; Table 2 outlines the various anonymization levels. In attaining the destruction of the link between the data and the person it pertains to, the following two techniques are most commonly used: 31
User attributes' type definitions
Classification levels for anonymization
Complete deletion or alteration of the characteristics by which means the link becomes unidentifiable pointing to several subjects.
Increasing the number of similar subjects in which case the link is no longer unique.
Many studies argue that it is impossible to have 100% certainty that a set cannot be de-anonymized. 26 Since the process cannot be 100% safe, it is imperative to include in the framework detailed reference information to have traceability, which can be used in countering the four threats to confidentiality. 32
Reidentification or De-Anonymization, which refers to the capability of an attacker to identify the identity of an information subject, although the information shared are supposedly anonymized.
Reconstruction is the risk of reconstructing the data set from the partially distributed one, such as aggregated statistics.
Membership Disclosure is similar to reidentification with the difference that the subject is not identified but rather its membership to a group can be ascertained.
Cryptanalysis is mainly related to pseudonymization, where utilizing frequency analysis the attacker can correlate and decipher encrypted data.
The analysis of the literature indicates a growing concern for the requirements of confidentiality. These challenges stem from legal and compliance along with ethical requirements. It is apparent that big data era has intensified these challenges where Variety, being the least researched V, is attributing highly. In taming the risks researched agree there has to be a framework. Scholars have suggested and implemented several techniques to ensure big data privacy throughout the big data life cycle, which comprises different stages, that is, generation, collection, storage, processing, analytics, utilization, and destruction.33,34 In the initial stages of generation and collection, most scholars would target to limit the risk exposure by restricting access or restricting information. 11 The restriction of information, which is essentially nothing more than the abolishment or falsification of confidential and personal information, is usually suggested by many authors to be achieved with anonymization.33,35
In achieving anonymization or depersonalization of the data, many techniques are available, from deleting or hashing the data to the more sophisticated techniques of microaggregation (e.g., l-diversity, t-closeness, matrix anonymization, or k-anonymity).36–41 Business experts, along with scholars, have highlighted that the use of such quantitative techniques will point to the known controversy of the Statistical Disclosure Control where scientists propose approaches in reaching the balance between data disclosure and data loss.36,42–44 This delicate balance between the usability of the data and the preservation of the compliance frame is achieved with human intervention in deciding what and how the data will be anonymized or depersonalized, which is resource-intensive and prone to human errors and omissions.
The complexity of compliance requirements is critical, while at the same time, the need to derive Value through the use of data for analytics and visualization is also critical. In archiving both, an organization will have to have in place a framework to protect against data loss and at the same time preserve the usefulness of data. To do so, any movement of data for subsequent analysis (1) within the organization (e.g., from production to test/development environments) or (2) externally to it (e.g., sharing information with vendors or competitors) will have to be closely monitored and managed to ensure DLP. Data confidentiality in archiving DLP will have to be governed and implemented throughout the organization with a mechanism that will ensure coherence and ease of use. Currently, all research identified toward corporate guidelines for confidentiality focused on “the how.”
Algorithm implementation, rationalization, and optimization are being researched, focusing on minimizing the data loss, but “the what” should be safeguarded has not been referenced in the research. Research and most academic work focus on achieving anonymization with sophisticated techniques rather than identifying the element to be anonymized. Theoretical and practical implementations regarding data confidentiality and their enforcement are unsatisfactory. 45 Label systems mainly focus on enforcement of security and data access rather than identification and dissemination. 46 Classification levels associated with labeling are also available in academia. However, they focus mainly on the following four principles: labeling, binding, change management, and processing, which focus on access prevention rather than secure data proliferation. 47 The identification of data elements and the decision on what has to be done with/on them are imperative for any organization since they are the primary measures in countering the incompliance risk.
The Big Data–Confidentiality Preservation System
The article proposes a framework that will enable the organization to implement a comprehensive, standardized, and usable compliance approach toward data confidentiality and DLP. The primary objectives are as follows:
(a) to suggest automation of the process with a software-driven, algorithmic rule-based system; (b) to suggest alternatives in minimizing the data loss risk for an organization through standardization; (c) to investigate the feasibility of transforming the repetitive classification work before distributing any data internally or externally to the organization.
The intention is to transform the process from a human labor-intensive, nonstandardized, and error-prone effort to a corporate-wide, standardized, and automated process. Toward these objectives, the Big Data–Confidentiality Preservation System (BD-CPS) was developed to provide a consistent and robust corporate data confidentiality rule-based framework. Based on the business analysis and corporate best practices regarding resistance to change, management, and auditability, the framework considered the functional requirements/characteristics and business aims, as presented in Table 3. The system will store the definition of all the data elements of the corporate data dictionary in formulating a data confidentiality corporate taxonomy using an automated ingestion and identification process. 48
Big Data–Confidentiality Preservation System functional requirements, characteristics, and business aims
The corporate data elements will be abstracted with the use of entities to be able to implement the corporate strategy on a less granular level. For example, if we consider the mobile number for abstraction, we can refer to the superset as “party mobile.” In this way, the mobile telephone number element is generically represented in multiple data sets (e.g., customer mobile, vendor mobile, mobile used to login an application, one-time password delivery number). In some instances, the presence of multiple entities as a group might necessitate the need for a different approach to risk; thus, the concept of a combined entity to encapsulate multiplicity is also introduced. A set of dimensions/classification attributes is required for each entity to define the entity quantitatively. This is required since entities must participate in numerical calculations in implementing algorithmic preventive controls and safeguards. Appropriate attributes were sought and identified in adequately describing an entity in the corporate environment concerning confidentiality.
Having identified the entities and the classification attributes, it is imperative for transparency to have multiple entities review and confirm the ratings for each attribute of every entity. To that end, the system (illustrated in Fig. 1) will provide a workflow mechanism referred to as the Entities Classification Workflow so that the rating of the attributes is inputted and approved. Similar mechanisms for approvals will be employed in releasing a data set in the Data Release Workflow, where the system will algorithmically leverage the defined entity attributes. The calculated indexes will be utilized in visualizing and enforcing the organizational DLP strategy in real time.
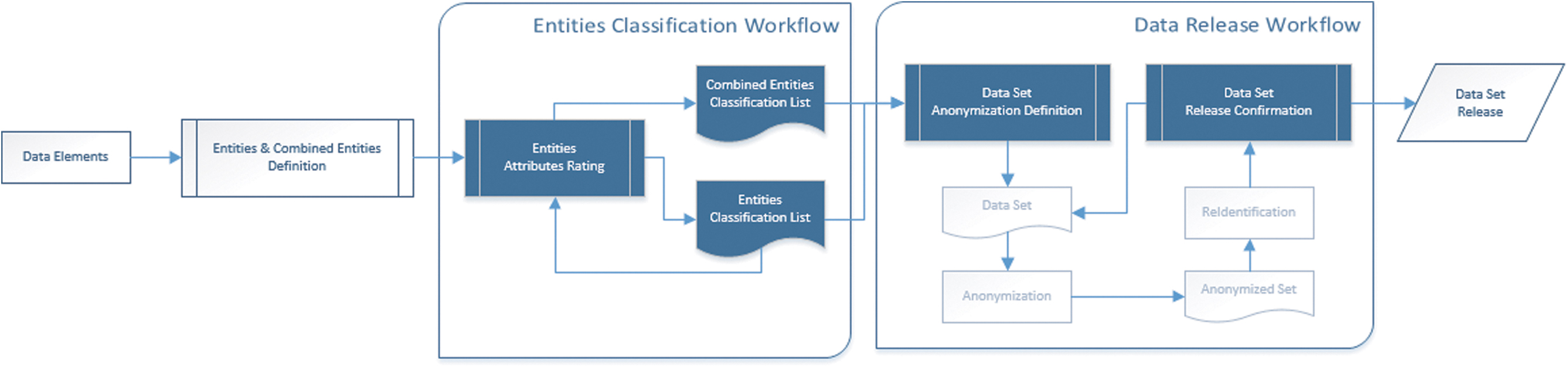
BD-CPS overview. BD-CPS, Big Data–Confidentiality Preservation System.
The proposed system provides a configurable environment where the different subject matter experts from business, risk, security, and other control disciplines, for example, audit, will be able to depict and review the corporate confidentiality rules. The data elements under management for the organization are mapped to entities, which in turn are classified based on the following three classification attributes:
Business Classification, which is provided by the data owner indicating the operational use of the data.
Regulatory Classification, which is the classification that is derived from industry, country or international regulatory requirements, acts, and laws.
Anonymization Risk, which will provide with classification relevant to anonymization and reidentification risks.
The proposed attributes are independent in nature since they are designed to identify different aspects of the data classification 360 view. The owner (business) perspective in addition to the corporate (regulatory and risk) perspective is segregated in depicting the different viewports by which the classification can be viewed upon. Invariably since they classify the same entity, there is correlation but only toward the describing entity and not among them.
Once the corporate classification policy is enriched with the classification and depicted, the system will employ algorithmic rules in identifying if the proposed anonymization or depersonalization action taken against each element or a combination of elements is adequate. There will be little ambiguity in this way, and the process will be secure and robust.
The BD-CPS spans multiple business areas, introducing complexity in understanding the terms used. To make it easy to follow and understand the terms used and their context in the subsequent paragraphs, a data dictionary along with some examples is provided in Table 4.
Terms dictionary
The BD-CPS is equipped with multiple features: (1) algorithms for decision-making, (2) workflows and automated orchestrations for collaboration and structured processing, (3) user guiding intricate user interface (UI) to educate and facilitate the users, (4) parameterization and configuration screens and features to provide the flexibility to the users, (5) user role and access management. The system is adhering to the latest Information Technology application development standards incorporating an n-tier architecture, which can be on-premises or cloud-enabled, along with the use of mobile technologies and distributed network access.
An information-loaded UI is available so that the user is presented with an adequate amount of information for decision-making, without requiring him/her to use other systems, but not overwhelming, leading to confusion and information overload. The BD-CPS can be delivered using mobile technologies. The system features a detailed auditing system to ensure the recording of invaluable information regarding forensics, traceability, and accountability.
The Entities Classification Workflow, where multiple levels of approvals can be accommodated, is centered on the concept of segregation of duty, commonly referred to as “duality.” 49 In implementing segregation of duty and preserving the integrity and accuracy of the data in the system, independent parties will have to review and inspect using the service world standard of the n-eyes principle. 50 In this system, the six-eyes principle instead of four-eyes is proposed due to its importance and criticality of the system. In addition, the workflow will enable the engagement of all related parties into a structured dialogue through the approval process. The roles suggested for duty segregation are as follows: (1) initiator/inputter, (2) first-level approver, and (3) second-level approver. In this way, three independent bodies can be mapped to corporate control functions such as compliance, risk, security, or audit. Any role can be assigned to any user, and in this way, the system can be parameterized in any manner the organization deems appropriate.
In each approval level of the workflow, there is a capability to further restrict the initial classifications to avoid multiple iterations. In addition, when it comes to assigning an element's anonymization or depersonalization action, the user can request an exception to the predefined calculated rule, which will again have to be ratified using the approval process.
A systemic algorithmic implementation is suggested to minimize the corporate policies' user perception and possible bias. The system will automate the process and provide the user with the required guidelines for better understanding and engagement along with corporate-wide alignment, and standardization of the BD-CPS is designed in (1) aggregating underlined entities ratings for combined entities and (2) autocalculating the baseline for elements' anonymization action as a corporate standard and as a run-time feature for each data set evaluation.
The first suggested algorithmic implementation of minimum levels for combined entities is proposed in facilitating the user when multiple interrelated attributes come into play. The system is automatically trying to provide suggestions concerning the possible classification level. In addition, the system will compel the user to select a “safe” level by aggregating the undelaying attribute classifications. In this way, the BD-CPS facilitates the organization in ensuring that the users have a clear metric to follow and minimizes the risk of misclassification. The combined entity's classification algorithms are presented in Table 5. They are calculated based on the maximum of all underlying entities for business and regulatory classification and with the advancement of one level for anonymization risk. For anonymization risk, the advancement of one level was implemented since the combination of multiple underlying elements will increase the exposure risk. 51
Combined entity minimum-level algorithms
A worked example of the calculation is presented in Table 6. In the example, a scale of 10–40 in increments of 10 is employed, and the combined entity is assumed to have three referenced entities. The calculated levels are proposed to the user and are limiting in their nature regarding minimal compliance. However, the user can always propose a more restrictive profile if deemed fit.
Combined entity algorithm example
The second proposed algorithmic implementation is related to the automatic suggestion of the minimum required level for anonymization. Similar to combined entities, when the anonymization actions have to be selected, the system will suggest a minimal-level restriction based on the configuration.
These functionalities and automation are essential for the BD-CPS since they will (1) enhance knowledge and awareness, (2) increase productivity, and (3) protect the organization. It is argued that the BD-CPS will cultivate a cultural change toward understanding and embracing the corporate policies through exposing users to the corporate policies on anonymization via the automated approach.. The users will be able to immediately get feedback on organizationally approved practices and guidelines with respect to the selected data element anonymization actions. This way, they will be empowered to make decisions without lengthy reviews. By having an independent nonhuman operated algorithmic rule enforcement engine, as exhibited in Figure 2, the organization has simply to define the rules, and enforcement will be non-bias, thus mitigating the risk of data loss.
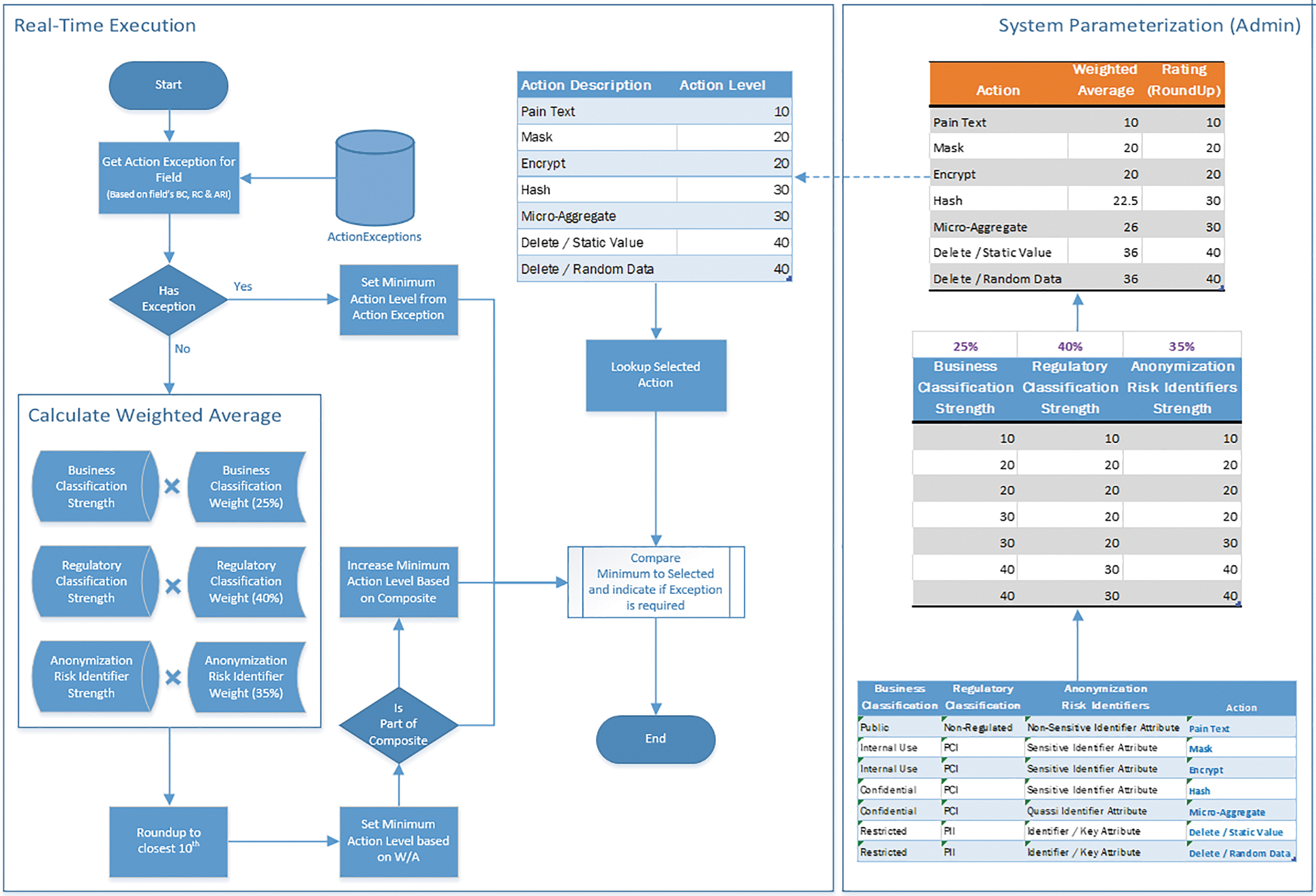
Action strength calculation.
The parameterization as shown in the System Parameterization figure section and enforcement as shown in the Real-Time Execution section are achieved in a two-step process using two independent calculations, which utilize the concept of an “action strength.” Each action is associated and classified with respect to the three classification attributes (showcased bottom-up in the right parallelogram in Fig. 2). Based on the underlying numeric equivalent, a weighted average is calculated. The weights for the weighted average calculation can be parameterized in the system. The calculated values, after being rounded up—so that we always minimize the risk of disclosure by applying a more restrictive action—will be used as a benchmark against the data scientist's proposed action.
In real time (showcased top-to-bottom in the left parallelogram in Fig. 2), the system will calculate each entity's “action strength” by performing a similar weighted average calculation based on the entity's classification attributes. The calculated action strength will be compared with the strength assigned to the selected action. An indicator provides the user with feedback in real time on compliance. In case of noncompliance, the list of compliant actions will be provided to the user to facilitate the process. Should the user decide to retain a noncompliant action, the exception process for the specific instantiation will have to be initiated, followed by all the required approvals based on the workflow.
In the system, we can identify that there are two parameterized scales: (1) the classifications scale and (2) the attributes' weights. The classification scale is independent for each classification attribute and for ease of use has a literal and an equivalent. In Table 7, a sample of the attributes scales is presented as utilized in the proof of concept (PoC). The scales can be adjusted per organization in respect to the levels (number of options) and respective scales (individual numeric values, e.g., scales 0–4 or 0–40). For simplicity, the PoC utilized a uniform scale among all attributes. The weights per attribute have been used to be able to consolidate all three independent attributes into a consolidated metric that will be used in all calculations for numeric comparison, the “action strength.” Similarly, the percentages to be utilized for the weighted average are set by the organization in reflecting the importance of each aspect to the business. For instance, in a highly regulated environment such as banking, regulatory classification would tend to be higher. The risk appetite of the organization or each classification attribute is in essence reflected by these percentages.
Attributes classification sample
PCI, Payment Card Industry; PII, Personally Identifiable Information.
Rule enforcement is achieved in real time alongside immediate visualization of any user interaction. These are critical for the success of the BD-CPS since it is of utmost importance for the user to have relevant and in-time feedback and guidance. The interface should at least cover a set of functionalities, including (1) immediate interactive calculations, without going to the backend server for recalculation; (2) capability to request or revoke exceptions; (3) capability to view at which approval level an exception is pending; (4) enquiring for prior rejections of exceptions for any element; and (5) easy and graphics-oriented journeys possibly using gamification.
In understanding the classification procedure and associated features, an illustrative example will be presented. The example will reference the values outlined in Table 7 and Figure 2. The corporate has identified that the low-risk elements can be disseminated as plain text. By low risk, they have identified that the business classification should be “Public,” the regulatory classification should be “Non-Regulated,” and the anonymization risk identifiers should be “Non-Sensitive Identifier Attribute.” The numeric equivalent for all classifications rating is 10. Thus, with the use of the weighted average 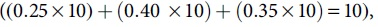 the action strength for “Plain Text” classification would be 10.
the action strength for “Plain Text” classification would be 10.
Table 8 shows the definition and the calculation of the action strength for a set of example business entities. Based on the aforementioned definition, the only entity that can be shared using “Plain Text” would be “Terminal Number,” which has the same action strength. All the other sampled entities will require a higher anonymization depersonalization action since their action strength is higher.
Sample business entities classification
The Data Set Release Workflow is composed of three stages. These stages are aligned to the segregation of duties principle and the stages data undergo before it can be released to the public. In order for the set to progress to the next stage, the aforementioned 6-eyes principle approval workflow is imposed.
Release Definition is the stage the Data Analysts/Scientist will define the anonymization or depersonalization action to be assigned against each field of the data set.
Release Anonymization is the stage where the anonymization or depersonalization actions are implemented. The implementation can be done with corporate proprietary systems or subcontracting to an external trusted entry. Since the data set is not yet anonymized or depersonalized, strict rules and contractual agreements should apply in case of external entities involvement. In this stage, the reidentification or de-anonymization strength is also calculated using specialized services. The respective percentage is inputted as a metric to proceed to the next level.
Public Release Confirmation is when the approvals are to be given, after anonymization and/or depersonalization so that the data set is distributed for its intended use.
An exception to this three-stage process is the case where an already approved data set is utilized. In this case, the existing release definition is used, but the subsequent two stages remain in place. The two primary reasons for not bypassing all the stages and directly distributing the data set are: (1) to avoid the distribution of data sets for different usage due to negligence or unlawful intent and (2) to re-anonymize and re-depersonalize with the current and possibly more advanced techniques and algorithms.
The administrative and configuration UIs/forms should be accessed using privileged accounts that will only have the capability of parametrizing the system. There will be no conflict of interest since the administrative users will have no access to the actual approval process or any application data-related information. These functionalities would cover for the parameterization of the weights between the classification attributes and the association of the anonymization/depersonalization actions to the classification attributes. The user management should utilize a different role and a new set of administrative user accounts to further segregate the roles and responsibilities. If required by the organization, four-eyes principle can be implemented for all administrative and parameterization functionalities in segregating the inputter and authorizer function. In this way, the two-step process will further minimize the risk of erroneous or unlawful alterations regarding access and global BD-CPS parameterizations.
The Prototype
The purpose of the experiment and PoC using a working prototype is to evaluate the value a data confidentiality framework would bring to an organization and its users. The organization utilizing the framework should be able to minimize the data loss risk and thus mitigate any regulatory fines and brand-related losses. In addition to that, the framework will provide better awareness and understanding by serving as a hands-on training instrument.
The fact that it is a PoC suggests that not all the functionality has been implemented, for example, user management module, mobile push notifications, or elaborate audit trails were not implemented, but that fundamental elements of the proposed information system have been implemented. Web applications facilitating n-tier architectures have become the standard for application development,52,53 but the adoption of mobile technology is also very high, and COVID-19 has intensified the adoption.54,55
Based on the current trends and the increasing mobile adoption, the system comprises two interrelated applications, using different technologies for enhanced responsiveness and mobility (as illustrated in Fig. 3). The Web Application targets users who use their PCs, and its UI is elaborate. The application provides capabilities in managing the configurations, data entry for classification, data request, and release process. Mobile Application is developed primarily for mobility so that approvals will not require a PC but rather a mobile device. In this way, the approvers can easily and quickly process any required requests.
Web and mobile application.
A use case has been utilized to understand better and provide a walkthrough of the proposed implementation. The selected use case is conducted in a highly regulated environment (e.g., banking sector) to highlight the risk reduction.
Before users can utilize the system, certain parameters and configurations will have to be put in place. The parameterization will be performed with the use of an administrative account, which will be in the custody of a control agency such as the ISO:
(a) After initial configuration of the system roles, which will be Data Analyst/Scientist (DA)—inputter, CDO—first approval level, and ISO—second approval level. The roles will be assigned to users operating the system with the associated privileges.
(b) Actions weighted average percentages, considering a highly regulated industry such as banking or health, for the PoC and its evaluation, it was suggested to use a mix of 25% for business, 40% for regulatory, and 35% for anonymization risk. The mix is suggested since the impact of any regulatory or anonymization risk in that order can have profound legal/compliance implications and penalties.
(c) Minimum levels association between the actions and the classification attributes. A visualization from the PoC is provided in Figure 4.
Based on Data Origination of the data ingestion journey, the fields and entities of a data set can be automatically identified. 48 The respective identified information can become an automated feed to the proposed system. In addition, information available at the corporate in Information Classification Policy can be imported into the system. Having the basic information available, configurations and fields/entities, the next configuration level will have to be performed. If available, the classifications can be imported from the institute's already defined Data Classification policy; otherwise, the evaluation and classification of the entities about the aforementioned Classification Attributes will commence manually in the system.

System parameterization.
Using the web interface, see flowchart in Figure 5, the DA will search for any entity and define the business, regulatory, and anonymization risk. Once the levels have been identified, an approval request will be sent to CDO on the mobile applications using push notifications. The CDO will be using the available deep-link to go directly to the required entity and view the request. If it is deemed necessary, the approver can edit the classification. Only increasing the level and thus making the data policy more restrictive. Once reviewed and confirmed, the approver (CDO) will record the approval. In case the approver is not in agreement, there is a rejection option whether the approver can also record the comments and rejection justification. The same approval process will be automatically triggered for the next level of approval, ISO. The system is fully parameterized in implementing the rule-based corporate-wide evaluation of data sets for internal or external dispatching.

Entities edit and approval process.
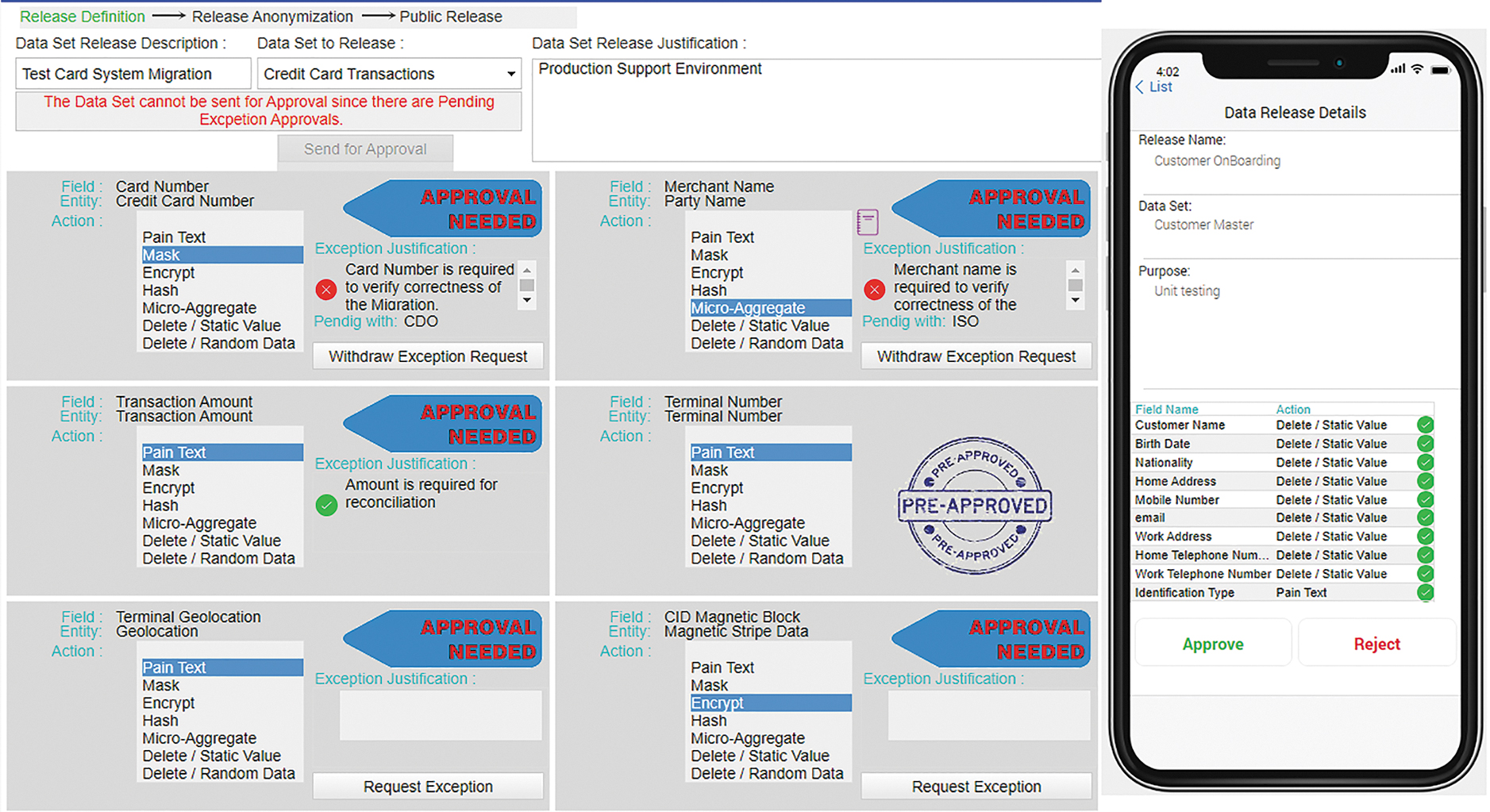
A credit card migration project is utilized to showcase the data dissemination process and prototyped UI, exhibited in Figure 6. In this use case (highlighted in blue parallelogram), the credit card transaction will have to be moved from the production environment to lower environments (development or test environments) to facilitate and verify the migration process's correctness. In authorizing the data sharing, the approval level is implemented in three stages, visualized on the form in the red parallelogram. For all the stages of approvals, the mobile application is used, while for editing, the web application is used.
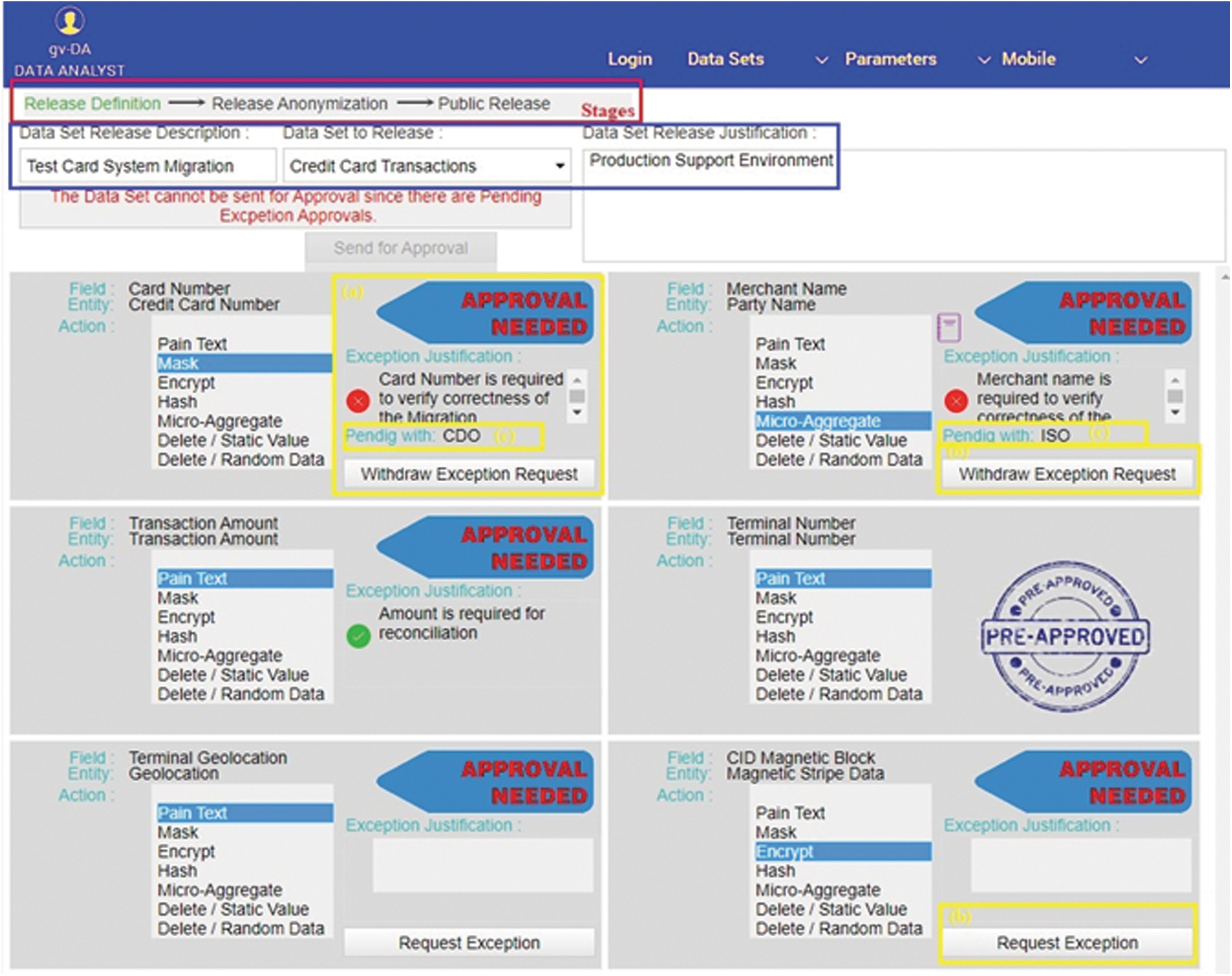
Data set elements' actions selection UI. UI, user interface.
The web application was selected since many calculations are to be implemented, and a substantial amount of information is exhibited. A mobile application interface would be complex and fragmented, leading to user confusion, omissions, or errors. The form, presented in Figure 6, is showcasing (highlighted in yellow parallelograms with labeling) the following capabilities (1) immediate interactive calculations, without going to the backend server for recalculation; (2) capability to request or withdraw an exception; (3) capability to view at which approval stage the exception is pending; (4) enquiring for prior exceptions approvals/rejections for the element.
The stage is available on the top of the screen, red parallelogram in Figure 6, so that the DA can move to the next level after implementing each level's requirements. In the first stage, the DA will have to define all the necessary actions to be taken per field. The system on the fly will inform the user of (1) required adjustment, (2) required exception, (3) recommendations, or (4) confirmation to proceed.
When all fields are associated with a preapproved action or the required approvals for an exception are in place, the DA will request the initiation of the approval to move to the next stage. The approval process is similar to the approval mentioned above process for the (Combined) Business Entities. However, the approvers cannot edit the proposed action levels in this case. The reason being that the approvers have already accepted any deviations to the corporate policy by approving the individual exceptions and now will have to approve the entire set. In case the DA is trying to distribute an already approved release of a data set for the same purpose, this step is obsolete, and the process will automatically move to the next level.
The second stage is related to the implementation of the suggested action. The set will be anonymized/depersonalized based on the actions set. This process is external to the system and can be undertaken using proprietary corporate mechanisms or using a contractually bound partner since the data set contains all the privileged information at this stage. After the anonymized/depersonalized process, the set will have to be submitted to an external engine, which can be one of the available public service providers, in evaluating the anonymized/depersonalized and calculate the reidentification factor/percentage of the set. The DA will have to input the respective factor as evidence and initiate the approval process so that the control function can validate and confirm that the required level of anonymized/depersonalized is achieved. The set has reached its final third stage, where the data set is ready to be distributed.
What was exhibited by know is that the system will provide the reusability of the configurations so that human intervention is limited. The entities will be parameterized once and reviewed at regular intervals but will not be required to be evaluated for each data set release. The users will get accustomed to the security concepts with the structured interactions, exceptions, and approvals, with the control functions, thus increasing their DLP awareness and education. In addition to that, the corporation can record all interactions and have full accountability and responsibility on any data release, along with an assurance that the system will preserve the minimal levels already defined in the system.
Evaluation
Methodology
In validating any proposal or suggested approach, there must be an evaluation process to measure the effect and possible impact. The proposal has to be gaged regarding innovation and value along with suggestions toward advancements and realignment. There can be a quantitative or qualitative measurement approach toward any such engagement. The difference between the approaches is in many respects, and an important one is the participants' number where the qualitative will study fewer people in more depth. For this reason, the qualitative approach was selected to be able to get from experts a rich response with in-depth retrospect and outlook on the proposed concepts designed.56–58
In ensuring a holistic review, experts from both academia and industry were invited. The diverse origin and different accumulated experiences from both academics and senior executives were important in understanding the proposal's value regarding theoretical validity and practical applicability. In addition to the different knowledge background and experience, the geolocation diversity and cultural background were considered by involving experts working in multiple countries, namely the United Kingdom, India, Kuwait, and Greece.
To have a constructive discussion, a PoC utilizing a working prototype was implemented, available at https://rb.gy/ekm5j1 Using the prototype, several videos were created in showcasing the concepts. A structured approach in delivering the concept was designed using a presentation. The delivered presentation exhibited an overview of the information presented in the Big Data–Confidentiality Preservation System section, along with video clips showcasing the process of utilizing the publicly available functional prototype (https://rb.gy/ekm5j1). Finally, the attendees were involved in a discussion driven by a set of questions (Table 10). The audience mix (Table 9) was decided to be diverse in covering from both academic and business perspectives. The expert commentators' number was initially driven by the 10 ± 2 rule and finalized based on the exhibited saturation of the responses during the progress of the interviews.59–61
Interviewees mix
Rating and open-ended questions
Ethical approval was sought and granted from Faculty of Science and Engineering Research Ethics and Integrity Committee of the University of Plymouth (Ref: 2862). The invites were delivered through emails along with the information form outlining the initiative's details and the consent form. The interviews were performed using teleconferencing facilities due to different geolocations and COVID-19. In evaluating the framework and system at the end of the 45-minute presentation, a set of rating and open-ended questions were discussed.
In acquiring insight on the occurrence and mitigation of particular challenges pertaining to big data and data confidentiality in particular, participants were asked a set of rating questions in addition to a series of open-ended questions (Table 10). The questionnaire was formulated in facilitating the discussion and acquiring insight from the experts. During the discussion, the focus of the insight was to explain the concepts, acquire feedback on the subject by the experts, and drive experts in providing further suggestions of enhancements. A 5-point scale similar to psychometric Likert and Five-Star quality rating grade was selected since it is easy and many people have prior experience with it. The five-levels gauge instead of three was used, although it has minimal statistical impact or value since we are interested in individual behavior.62–64
The results are presented in narratives as per the interviewees' responses. Direct quotations will be used to present the subject matter experts' views to comprehend not only the response content but also the tone and emphatic nature of the responses. The ranking provided by the commentators will be presented in heat maps to visually highlight the concentration of the responses. The actual color and intensity are used to reveal the progression/intensity. The selected visualization uses three colors: green denotes high concentration, blue is the middle ground with moderate concentration, and ivory is the unused ratings.
In implementing and evaluating the PoC, a desktop PC with Inter® Core™ i7–6700 CPU at 3.40 GHz and memory of 16 GB was utilized. The system and application software used would include Windows 10 (64-bit), MS Office (2013, 2016), and JustInMind prototyping platform.
Results
In putting the theory to the test, a total of 12 experts from several fields across academia and business were invited. By being senior executives and academics, the experts exhibit on average 25 years of experience in their fields while bringing a total experience of approximately three centuries to the case study. They were presented with the framework and asked to comment on a series of rating and open-ended questions as described in the Methodology section.
All commentators confirmed that managing data confidentiality is an existing day-to-day challenge. The intensity and awareness were exhibited with the use of strong words such as “obviously,” “definitely,” “indeed,” and “of course” when the commentators were describing the data confidentiality challenge as the “most important aspect of information management,” which is “pretty much impossible to guarantee.” Everyone had faced the issue, and different perspectives were given based on the commentator's role and experience. The academics were more on the receiving end, where the data shared were inconsistent or depleted due to the anonymization, thus often reducing their value. On the contrary, business originating commentators were on the sharing side where the concerns confirmed stemmed from the regulatory and security perspectives.
In acquiring further context, the commentators were asked pointed questions they had to provide a rating (Table 10). The responses are tabulated in the heat map presented in Figure 7. We can see the topic of the related question and the number of participants who gave the respective rating.

Rating heat map.
From the color coding and the rating distribution, it is evident that all commentators acknowledge the challenges posed by the big data basic 3V dimensions. Variety is confirmed to pose the highest challenge by exhibiting the highest ranking among the three, with the highest concentration on the slightest grade. The following three rankings are about data classification, strategy availability, and usage and seem to concentrate toward the middle of the scale. This is of vital importance toward the data confidentiality framework. In essence, these three dimensions are the prerequisites in identifying, defining, and classifying the data elements along with the proposed classification attributes, namely business, regulatory, and anonymization risk. Before going into the details of each metric, it is also important to mention that since the ratings are in the middle, there is obvious room for improvement.
That is the reason why commentators, while discussing these points, confirmed that the framework would also serve as a training and awareness tool. Having a good understanding of the business and regulatory classification will be the basis for the framework where the entities/data elements will be easily and quickly classified. Having such information readily available and documented will ensure consensus on all parties, and the process will be smooth. In addition to that, if there is a high-level strategy for anonymization and depersonalization, it would mean that the engaged parties have prior experience and understanding and are seasoned enough to take the next step in automating the process.
It was also confirmed that the data usage is well known, enhancing the classification by attributing to the anonymization risk. When the usage is known, it will be easier for each party to associate the risks and identify the required policy to mitigate them. Last but not least—if not most important—is the existence of tools and automation. Most of the participants have confirmed that existing tools are in their early stages and lack sophistication and automation. This fact is crucial in confirming the novelty of the proposed framework, suggesting a rule-based, automated, and algorithm-driven system.
The system, and to a certain extent the framework, to be adopted, will have to be easy to use and provide value to the users and the organization. In facilitating the user experience and the web application, a mobile application was introduced. The experts welcomed the introduction of the mobile application and confirmed that it would enhance responsiveness. Statements such as “will definitely help,” “it will enhance the responsiveness 100%,” and “I would give priority to the mobile app” indicated the enthusiasm and confidence of the experts toward the use of the proposed mobile application. It was also pointed out that the value of the mobile application will be increasing throughout the time when the data elements will be stable, and the distribution of the sets will mainly focus on approvals rather than the definition of the anonymization or depersonalization actions.
The three classification attributes of the data confidentiality framework were confirmed to be sufficient and well equipped to provide a holistic understanding and classification. The commentators stating, “I really like these suggestions because they are clear” or “100% sufficient,” confirmed that the use of these attributes would effectively and efficiently characterize the data elements in terms of confidentiality. Regarding the percentages allocated for each attribute toward the weighted average, the experts affirmed the research suggestion in which Regulatory is the highest, followed by Risk Anonymization and Business. Indicative of the consent is the wording used: “I would stick to the ones you have put together.”
Nevertheless, all the commentators pointed out that the respective percentages are organization- and sector-specific and applauded, “as long as it is an option I decide” the availability of a system capability to parameterize them through the administrative screens. In addition to that, they affirmed the concept of upward (ceiling function) roundup in increasing controls and reducing the risk of the assigned Action Strengths. For the anonymization or depersonalization actions, comments such as “I think is a good set,” “I have nothing to add,” or “I do not think we need to add anything more” were indicative of the experts' acknowledgement and confirmed as being a representative set, which would cover most, if not all, the Data Confidentiality requirements.
Toward the end of the discussion, the experts were asked their opinion on the presented automation, calculations, workflows, and the framework in general. Commentators identified the suggested framework as a viable and complete proposition, while at the same time confirming that all BD-CPS functional characteristics, as exhibited in Table 3, were showcased and would have a positive impact on corporate DLP challenges. “For sure, the work adds significant value to the business sector” and will prove to be helpful to the users in their day-to-day operations and preserve the interests of the organization toward the threat of data loss.
The framework proposed was accredited by all expert commentators, and it was confirmed that it could be a valuable addition to any organization's arsenal toward DLP. Throughout the process, it was exciting to observe a diverse set of experts converging in identifying similar challenges and confirming the framework's suitability for a diverse set of organizational applications toward data confidentiality.
It was suggested that the system could become a Software as a Service proposal where the organizations engaged can, should they choose to, share information among them. In this way, based on a sectoral classification, the system can provide templates and proposed values, percentages, classifications, actions, or levels for the participant by aggregating existing similar prior input from other participants.
Another future evolvement could include an automatic calculation where the system, considering the classification attributes, the anonymization factor, and the intended use of the data, will provide a risk factor. The factor will then be used to differentiate the approval workflows and define different roles and approval levels. The risk factor can be further augmented using the history of the approved and shared data sets where the concentration risk can be identified. In this calculation, the system will further aggregate the data that a destination already have and warn on possible exposures from the combination of seemingly unrelated distributions. For a tool to gain acceptance in the corporate world, it has to integrate and interact with existing office productivity tools; 65 toward that end, the system will have to provide hooks or add-ins for the most commonly used business applications.
Discussion
DLP has been identified as a matter of concern, based on the imposed risk, for all corporates. In mitigating the risk, organizations put in place endpoint controls. That could include solutions, which will scan documents, emails, and so on and highlight privileged information. Nevertheless, there are many limitations in identifying the attributes, and the substantial set of false positives hinders the process. 48 In many cases, corporate policies will enforce DLP procedures in external communications, for example, sending mails outside the organization, and block such communication. Such barriers present a different communication risk since due to false positives the communication will be falsely quarantined without the initiator's knowledge, and as such, important matters can be delayed. Most of these tools depend on personal judgments, and in many cases, individual classification, for example, document or email self-classification as confidential, which is not standardized nor corporate policy driven.
The risk of misclassification due to lack of understanding in respect to legal and/or business aspects, or even worse, intentional misclassification, is not centrally managed, and compliance is not monitored nor safeguarded. Another level of data distribution is related to actual data sets and information proliferated from the organization. These sets could be related to reports that are publicly available, data sets exchanged with other organizations, sets pertaining to data collected on cloud for customer behavior, or even sets that are moved within the organization from the production environment to lower environments such as development. For these data exchanges and movements, as confirmed also by the commentators, there is adequate process understanding and policies and procedures are in place, but there is limited, if any, set of tools to facilitate and manage the process. This limitation in essence will suggest that the work is done manually in a nonstandardized manner with little governance and minimal auditing.
In proliferating any kind of information, a common approach would be to proceed with a manual approval process. Based on the exhibited lack of tools, automation, and nonstandardization, there is reluctance from all control agencies within an organization in taking ownership and approval. Often, it can be identified that in the business environment, the request will mostly oscillate between ISO and CDO. Furthermore, in several cases, Risk, Compliance, Internal Audit, and Human Resources departments will be involved adding to the complexity of the evaluation. The communication will be fragmented in multiple emails and by no means can there be any reference to prior cases of already proliferated and anonymized sets.
In many cases, the final decision will have to be taken by the data owner, in which case being business could lack the understanding and technical depth to evaluate the request, especially when it comes to correlated or interrelated data sets. When it comes to big data and the manifestation of Variety, it could be very difficult to have a documented and risk-free approach unless it is corporate-wide, standardized, and process wise safeguarded by involving the appropriate skill set at the appropriate approval level.
Most organizations that embark on such a compliance and loss prevention journey will focus on prevention and training at the distributor level by imposing policies. This approach will introduce red tape and focus on prevention measures rather than automating and expediting the process. Inherent risks of impartiality, intentional misguidance, and misclassification will not be addressed. Ownership and accountability along with track records will not be recorder and safeguarded in any system, thus hindering the process's integrity and reusability.
Based on COVID-19 limitations in respect to direct human contact and group meetings, most organization will provide computer-assisted training toward data classification, identification, and the regulatory framework in an attempt to increase awareness. This educational material, although a very important and essential step, is generic and thus can only serve as the first step of the journey. Additional specialized training will have to be provided in respect to each user's needs, work responsibilities/job description, and skills. To that end, an event driven on the job training could be a plausible approach.
The framework presented is utilized in remediating some of the aforementioned risks and process inefficiencies. With the utilization of BD-CPS, auditability, and tractability is ensured. The right resources with appropriate skills are assigned to the approval levels in safeguarding that approvals are provided by the most suitable practitioner. Standardization and sustainability are another important dimensions in which BD-CPS is contributing. With the use of a centralized repository, conformity on the rules is achieved while reusability is facilitated. In this way, the organization will be much safer and reduce the risk exposures in comparison to the manual and unstructured approval process. Having digitized the journey and recorded all elements, be it attributes or approvals, the organization can achieve compliance. Taking the next step, it is of outmost importance to proceed in assisting the user within the process and streamline it.
To that extend, BD-CPS, as in detail presented, has introduced several automations. Main focus is to increase task-specific user awareness, provide with on the job training, and in general assist the users in making the right decision within a minimal time frame. The use of suggestion lists that are on the fly calculated based on the user selection and predefined policies guide the user in achieving operational efficiency both in terms of accuracy and timeliness of the decision. Workflows and approval levels along with four-eyes, or six-eyes, principle will safeguard the user from accidental mistakes while will also serve as a validation mechanism for possible intentional mistakes.
But the automations extend beyond only the end user/data distributor. The BD-CPS will use algorithmic facilities in assisting the control function representatives to formulate and preserve the corporate policies. Changes can be quickly and easily applied in respect to the weights utilized, thus tuning the system toward the corporate risk appetite and residual risk acceptance. Last but not least, prior approved sets and set elements/attributes can easily serve as examples and guidelines for future use. The fact that even not approved decision along with their justification is captured will serve as lessons learned for all users at all levels.
The BD-CPS is an approach toward a framework but just like any other suggestion can be affected by environmental limiting factors and could also be augmented or enhanced. Since compliance is a regulatory factor but not an income-producing initiative, there is probability that senior management sponsorship will be lagging, thus delaying implementation. As long as DLP is imposed, even in the form of restrictions, a profit-bearing project might be prioritized over such an initiative.
When there is reference to awareness and education, which are time-consuming processes, the timelines are extensive for such a project and cannot be considered as a quick win which once again could lead to reprioritization over other business critical projects. On the contrary, the introduction of new technologies and systems stemming from the artificial intelligence and machine learning can greatly enhance the BD-CPS by utilizing them to further guide or even predict the user/approver responses. The very fact that big data is involved could retrofit into the system. In such an enhancement, community modeling can be utilized.
Conclusions
While organizations strive to attain a competitive advantage through big data and analytics by utilizing data sets to their full extent, data loss is becoming a serious challenge. Organizations in many sectors, especially the highly regulated ones, are unable to utilize the data to their full potential over the fear of data compromise and breach of legislation and regulations. Governmental and international organizations impose standards on data sharing and disclosure, which can entail monetary fines if not adhered to. Based on this imposed regulatory governance, organizations face the challenge of data confidentiality. With the use of Business Classification, Regulatory Classification, and Anonymization Risk attributes, the BD-CPS seeks to classify all elements in the corporate data domain and automate the process of data safe distribution. The approach was proven effective and efficient by a group of expert commentators based on their evaluation of a working prototype that showcased the framework.
Future advancements of the systems can be obtained once the system and framework are adopted and implemented within an organization, preferably in a large one within a highly regulated industry. The adoption will provide insight into the system's realignments and methodology to gain easier adoption. Possible extensions and additional submodules might need to be introduced to serve needs that the adoption will uncover. The respective implementation along with evaluation will span in time since (1) planning and implementation along with corporate and legal processes have to be followed (project timelines will exceed 1 year), (2) the adoption process for any large organization will be slow, (3) the critical mass for evaluation will not be readily available since the usage will increase with time extending to multiple departments and functions.
Ethical Approval and Consent to Participate
Issued by the University of Plymouth Research Ethics Application Approval—Faculty Research Ethics and Integrity Committee reference number 2862, “Tackling Big Data Variety using Metadata—Corporate Data Confidentiality using a Rule Based system.” All participants have signed the required consent form after acquiring the information form as well as confirming their consent during the presentation and interview sessions.
Availability of Data and Materials
Interviews are not available since they are under confidentiality and personal information disclosure acts. The prototype is available in JustInMind site: https://rb.gy/ekm5j1
Footnotes
Authors' Contributions
G.V. was responsible for authoring, and N.C. along with S.A. was responsible for guidance and editing.
Author Disclosure Statement
No competing financial interests exist.
Funding Information
No funding was received for this article.