
Abstract
Recommender system (RS) plays an important role in Big Data research. Its main idea is to handle huge amounts of data to accurately recommend items to users. The recommendation method is the core research content of the whole RS. However, the existing recommendation methods still have the following two shortcomings: (1) Most recommendation methods use only one kind of information about the user's interaction with items (such as Browse or Purchase), which makes it difficult to model complete user preference. (2) Most mainstream recommendation methods only consider the final consistency of recommendation (e.g., user preferences) but ignore the process consistency (e.g., user behavior), which leads to the biased final result. In this article, we propose a recommendation method based on the Entity Interaction Knowledge Graph (EIKG), which draws on the idea of collaborative filtering and innovatively uses the similarity of user behaviors to recommend items. The method first extracts fact triples containing interaction relations from relevant data sets to generate the EIKG; then embeds the entities and relations in the EIKG; finally, uses link prediction techniques to recommend items for users. The proposed method is compared with other recommendation methods on two publicly available data sets, Scholat and Lizhi, and the experimental result shows that it exceeds the state of the art in most metrics, verifying the effectiveness of the proposed method.
Introduction
Nowadays, recommender system (RS) is becoming a popular Big Data-related research field. It uses various information about users and items to calculate the matching score between users and items to perform items (music, 1 movies, 2 books, 3 news, 4 etc.) recommendation for users. 5 Traditional recommendation methods include the content-based method and the user- or item-based collaborative filtering (CF) method. 6 The content-based method analyzes the user's historical data to find other items similar to the user's favorite items and recommend them to the user. CF analyzes the similarity between users or items to find similar users and recommend items liked by those users or recommend items liked by the same group of users. These traditional recommendation methods usually use Pearson's correlation coefficients, constrained Pearson's correlation coefficients, cosine similarity, or adjusted cosine similarity to calculate the similarity between users or items. 7
With the enhancement of market demand for a smart recommendation, traditional recommendation methods are becoming more difficult to meet the recommendation requirement of novel scenarios, such as short videos recommendation and literature recommendation. In these scenarios, the user is also the creator of the content, which is not taken into account by traditional recommendation methods. 8 Besides, some websites record a large amount of user behavior data, such as Browse, Like, Post, and Rate, but existing data sets often contain only one of them, for example, MovieLens 9 and Last.Fm, 10 both merely contain information on users' ratings of related items.
Due to the lack of these behavioral data, most of the recommendation methods published in recent years combine information about the users and the items themselves to perform recommendation. However, the process of extracting and processing auxiliary information generates cumulative errors, which in turn reduces the performance of the recommendation and makes the result unconvincing.
The emergence of the knowledge graph (KG) has made it possible to represent various kinds of knowledge in a unified way. 11 Inspired by the powerful ability to express KG, some researchers attempt to combine traditional recommendation methods with KG and gain satisfactory results. 12 Due to the deficiencies of the relevant data sets, most of the current KG-based recommendation methods extract some auxiliary information about the items and convert them into the corresponding graph representation, using knowledge graph embedding (KGE) methods to embed the entities and edges in the graph. The errors accumulated in this process are delivered into the next layer of the algorithm and ultimately reduce the quality of the recommendation. This degradation is essential because the existing methods use the KG as a structured representation of item information to enhance the effectiveness of specially designed recommendation algorithms, which ultimately make recommendations.
The similarity of user behavior has also been taken into consideration in some recommendation scenarios.8,13–15 But again, due to the deficiencies of the data sets, these methods are hard to completely model user behavior or only for a limited number of behaviors that are not generic. Therefore, it is difficult for these methods to outperform the existing user preference-based recommendation methods.
Unlike the previous methods, this article will model user behaviors using the KG, and the construction of the KG will be quite different from the construction process commonly used. In general, the KG records various factual relations among entities, such as (“China,” “capital,” “Beijing”), (“South China University of Technology,” “located in,” “Guangzhou”), and other triples of the form
The construction of the KG in this article, however, is more inclined to the various interactions between entities, such as (“user1,” “Browse,” “item1”) and (“user2,” “Create,” “item1”). We refer to this type of KG as the Entity Interaction Knowledge Graph (EIKG). Using the EIKG to cluster users with similar behaviors and their corresponding items, we obtain the matching scores of users and items, and finally, make recommendations based on the scores. In this article, we call it generic user behavior (GUB) recommendation method. Experiments on two public data sets, Scholat and Lizhi,
†
validate the effectiveness and superiority of the proposed method. The main contributions of this article are as follows:
Unlike previous methods treating different kinds of interactions separately, our proposed method converts them into a unified expression by incorporating them into a KG where the users and items are regarded as entities and the interactions between entities are regarded as relations. We call this kind of KG EIKG. GUB is an item recommendation method based on the EIKG. It transforms entities and relations in the EIKG into vectors and uses the link prediction method in knowledge graph complementation (KGC) task to perform item recommendation for users. As far as we know, this is the first method that uses the KG as the main recommendation method rather than additional information. Experiments on two publicly available data sets achieve the state of the art in most metrics validating the effectiveness of GUB and the superiority of congenitally leveraging multiple interaction relations.
The article is organized into the following sections: The Related Work section introduces the related work on RS; the GUB Recommendation Method section elaborates on the overall architecture and recommendation process of GUB; the Experiment Results section performs experiments to evaluate and analyze GUB; the Conclusion section summarizes the work of this article.
Related Work
With the increase in user needs in recent years, RS receives more and more attention from researchers, who have proposed a large number of innovative methods that combine the latest models and greatly improve the effectiveness of recommendation.
It is currently a popular research field to combine RS with deep learning. 16 Most of the deep learning-based approaches are proposed in early use multilayer perceptron (MLP) for item recommendation. Neural Network Matrix Factorization (NNMF) 17 and Neural Collaborative Filtering (NCF) 18 are typical examples of them. NNMF makes improvements on Probabilistic Matrix Factorization (PMF) 19 and its related derivative models. Unlike PMF, which directly sums the element-wise product of latent vectors of users and items, NNMF inputs the result of an element-wise product together with the original hidden vector into a feed-forward neural network and trains it.
NCF combines Generalized Matrix Factorization (GMF) and MLP to propose Neural Matrix Factorization (NeuMF). The principle of GMF is similar to that of NNMF. It applies element-wise product operation on latent vectors of users and items, splices the result with the output of MLP, and inputs it into a single-layer neural network with nonlinear activation units for prediction. Time decay-based deep neural network (DNN) 20 considers time-related factors, uses matrix factorization to denoise the data set before feeding it into the MLP layer, and uses the Time Decay function to increase the weight of recent ratings.
In recent years, researchers pay more and more attention to auto-encoder and convolutional neural network (CNN). The former can complete the incomplete content in the original data, and the latter combines methods originally applied to computer vision and natural language processing 21 with RS. Collaborative Denoising Auto-Encoder (CDAE) 22 treats the interactions between users and items as a residual of the user's complete preferences, which recovers the original content and uses the existing user preference information to predict the items users may prefer. Based on variational autoencoder (VAE), Multi-VAE 23 adopts multinomial likelihood to generate the model and uses Bayesian inference for parameter estimation and achieves better results than CDAE.
For performance enhancement, recommender variational autoencoder (RecVAE) 24 introduces a new encoder structure, a new composite prior distribution of latent coding, a new method for setting hyperparameter β, and a new training method into the multi-VAE. Neural Graph Collaborative Filtering (NGCF) 25 uses a CNN-based graph convolutional network (GCN) for the item recommendation; NGCF adds an embedding propagation layer to GCN to allow interaction between user and item embeddings for collaborative signals. LightGCN 26 makes improvements to NGCF. The author of NGCF studies the recommendation process and removes unnecessary complex design, reducing the computation cost and achieving better results. However, the aforementioned methods use only a single kind of user-item interaction, making it difficult to model user preferences comprehensively, which will have an impact on the final recommendation results.
Combining RS and KG is the latest research trend. 12 Since Google first published the KG, 27 it has been applied in many research fields such as question-and-answer 28 and graph analytics. 29 Collaborative Knowledge Base Embedding 30 is an early approach to combine KG for the recommendation, where the author transforms the structured information of items in a data set into a KG and uses TransR 31 to embed the entities and relations in it, combining other embedding information for joint training and recommendation. Collaborative filtering with knowledge graph 32 applies a similar idea to our article for a personalized item recommendation, where the author unifies the user's Purchase and Rate behavior and items' information into the KG and embeds them.
Items are recommended according to the ascending order of the distance between the user entity and the item entity under the purchase relation. A Courses Resource Recommendation Algorithm Fusing Knowledge Graph and Collaborative Filtering Technology 33 combines CF with KG for personalized course recommendation. The author uses the KG for the representation of semantic information of courses, which is used to calculate the similarity between courses and combines the results with CF recommendation methods to recommend courses to students. In summary, most of the current KG-based recommendation methods only use KG as a source of structured information for the proposed recommendation method, and few studies use KG itself as a recommendation method.
The similarity of user behaviors can also be used as a recommendation basis. Akcayol et al. 13 first cluster users with Pearson's correlation coefficient, collect various behaviors (such as Click, Rate, and Like) made by users on items, use a fixed formula to calculate users' interest in items, and finally use roulette wheel selection to decide the recommended items. Behavior2Vec 14 distinguishes behaviors such as Click and Purchase and refers to the idea of Word2Vec 34 to embed the combination of user behavior and the interacted item.
They use cosine distance to predict the items that users are likely to click on or purchase, respectively. ReBKC 15 is an RS with unified behavioral and knowledge feature embedding, which mines user preferences from KG and historical user behaviors to perform recommendation with higher accuracy. Deep Interaction-Attribute-Generation (DIAG) 8 uses MLP and graph attention network (GAT) to combine users' Browse and Create behaviors and features of items to predict the next item the user is likely to browse. Through the above research, we can discover that there are various kinds of recommendation methods using user behavior similarity, which indicates that the research in this area is still at a relatively early stage and no unified consensus has been reached. Therefore, it is still a very worthy research problem of behavior-similarity-based recommendation.
GUB Recommendation Method
Overview
As shown in Figure 1, GUB mainly contains three steps. The first step is entity and interaction extraction. The key to this step is to find out the entities and their corresponding interactions from the data set and generate the corresponding fact triples, to construct EIKG. The second step is to perform a graph embedding operation on the EIKG. The quality of embedding in this step directly influences the recommendation result. The third step is to perform link prediction and recommend items to the users with the embedding result.
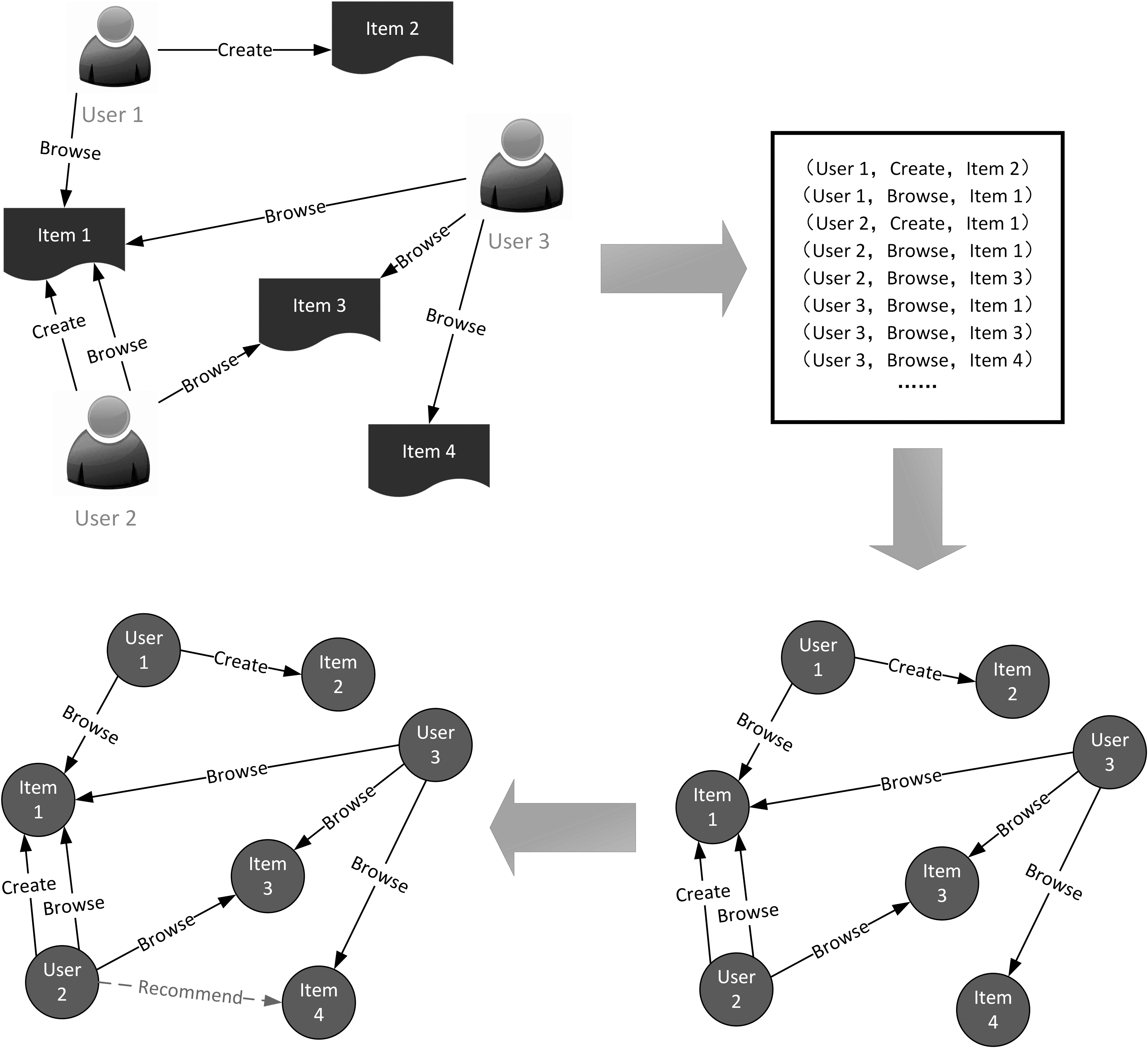
The overall of generic user behavior.
Entity and interaction relation extraction
In general, the KG only contains various factual relations among entities, such as the aforementioned (“China,” “capital,” “Beijing”) and (“South China University of Technology,” “located in,” “Guangzhou”). These relations are persistent factual relations, which were facts in the past and are still facts in the present. The interaction relation, however, is a temporary factual relation that holds only for the duration of the action and will no longer be considered a fact after the completion of the action. Therefore, with the characteristic of interaction relation, “Browse” in (“user1,” “Browse,” “item1”) can be considered as an interaction relation since the activity of “user1 browses item1” creates this temporary fact triple. After the Browse behavior is finished, the event of “user1 browses item1” is no longer considered a fact. In contrast, the content of the fact triple (“China,” “capital,” “Beijing”) is artificially defined. It is not that “China” actively designated “Beijing” as the “capital,” so “capital” is not an interactive relation.
In an RS, it is usually the user who actively performs various actions on the items, hence the extracted fact triple will have the user as the head entity and the items as the tail entity. This relation is a one-way relation, which can be simplified to a bipartite graph, as shown in Figure 2.

Convert EIKG to a bipartite graph. EIKG, Entity Interaction Knowledge Graph.
Embedding the EIKG
In the previous section, we extracted entities and their interaction relation. In this section, we will embed entities and their relations in these fact triples based on existing KGE methods. The specific process is shown in Algorithm 1.

This algorithm refers to the KGE method proposed by Bordes et al.
35
It is worth noting that the algorithm used in this article is quite different from the usual KGE method. The proposed algorithm first accepts set S, which contains fact triples
In the initialization step, we initialize the embedding vectors in U, I, and R using the uniform initialization method proposed by Glorot and Bengio
36
and normalize the embedding vectors in R. At the beginning of each loop, we normalize the embedding vectors in U and sample b samples from S according to the idea of minibatch. For each fact triple

where
The goal of training is to decrease the distance between
Item recommendation based on link prediction
After completing EIKG embedding, the next step is to predict the items that the user may be interested in. This article regards this process as a KGC task, that is, predicting missing interaction in the fact triple. As shown in Figure 3, the behaviors of users 2 and 3 are more similar among the three users. Therefore, the embedding vectors of these two users will become closer after KGE, and the items they interact with should also be approached accordingly. Since the purpose of item recommendation is to recommend items that the user has not seen but may be interested in, the link prediction technology in the KG can be used to predict the items that user 2 expects to browse.

EIKG embedding.
As shown in Figure 4, assuming that there are entity embedding vectors for user 2 and items 1 to 4 and a Browse relation vector between them. The vector of the ideal recommendation is the vector of user 2 + the vector of Browse. It is known that user 2 has already browsed items 1 and 3; therefore, these two item entities will not be considered in the link prediction process. Since the entity embedding vector of item 4 is closer to the vector of ideal recommendation than that of item 2, the possibility of the existence of a Browse relation between user 2 and item 4 is higher. So, item 4 will have a higher rank than item 2 in the final recommendation list.

Recommendation based on link prediction.
Experiment Results
In this section, we first introduce the environment and the data set required for the experiment and the evaluation method of the experiment. Then, we analyze the influence of the two main hyperparameters on model training and recommendation accuracy through experiments and set the hyperparameters according to the analysis results. Subsequently, we design comparative experiments to verify the accuracy and effectiveness of GUB in item recommendation. Finally, we verify that multiple interaction relations can indeed improve the model performance through the experiments.
Experimental environment and methods
The environment of the experiment is CentOS 7, the CPU is a dual-channel Intel Xeon Gold 5218, the memory size is 256 GB, and the GPU is NVIDIA Tesla T4.
The experiments we have performed using two public data sets from Scholat and Lizhi. They both contain the two most common interactions, Browse and Create. The specific statistical information is shown in Table 1.
Statistical information of the two data sets
The first data set is collected from Scholat, which contains Scholat users who have browsed at least two documents and their corresponding document entities. The data set has 1991 users and 5008 documents. It contains 17,736 user-document interactions, including 13,960 times of browse and 3776 times of creation. The 1232 nonuser-created documents are mainly created by the administrators of Scholat.
The other data set is collected from Lizhi. It contains user entities that have browsed (listened to) at least 10 audios and their corresponding audio entities. The total number of users in this data set is 3716, and the total number of audios is 9205. The data set contains 863,868 user–audio interactions, including 858,124 times of browse and 5744 times creation. The 3461 pieces of nonuser-created audio are mainly created by Lizhi official or some special users.
Nadam, 37 which is equivalent to the combination of Adam 38 and Nesterov's Accelerated Gradient, 39 is used as the optimization method of the model. Compared with the original method, Adam, this method converges faster and better. The training process adopts the minibatch training method, where each batch input 2048 samples with 256 times of negative sampling. To obtain a stable score, this article conducted five experiments on each data set and averaged the results.
To evaluate the effectiveness of GUB, this article takes the last item browsed by each user as the test set, and the remaining data are fed into the model for training. In the prediction, we randomly select 100 items that have never been browsed by any users as negative examples and then use the trained model on the test set and rank the prediction result. To evaluate the result, hit ratio (HR) and normalized fixed cumulative gain (NDCG) are used to evaluate the model. Their formula definition is as follows:
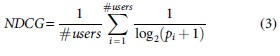
where
Finally, we score the top k of the prediction list and use
Model hyperparameter optimization
This experiment validates the only two hyperparameters derived from TransE, which are used by GUB. Figure 5a demonstrates the experiment results on EIKG embedding dimension, with the margin

Experiments of the model hyperparameters, using
Figure 5b represents the EIKG margin γ experiment with the embedding dimension set to the optimal value. With the figure, we can easily obtain the best parameter settings through the experiments. In the Scholat, the best results are obtained when
Results of model comparison
This section will illustrate the effectiveness of GUB by comparing it with seven baseline models. First, we will introduce the seven benchmark models.
Probabilistic Matrix Factorization
PMF is a probabilistic linear model with Gaussian observation noise. 19 The model uses two matrices to represent the latent feature vectors of users and items. By taking the dot product of these two vectors and using it as input to the formula, the model finds out the probability distribution of user ratings for items.
Multilayer perceptron
This method uses a multilayer neural network (NN) combined with a cross-entropy loss function for model training and prediction. 18 The specific process is to splice the user vector and the item vector in the user–item matrix into the neural network to predict the user's preference for the item.
Generalized Matrix Factorization
This is a matrix factorization method with activation layers. 18 In this method, the user vectors and item vectors in the user–item matrix are multiplied by the corresponding matrix, respectively, and the user latent vectors and item latent vectors with equal dimensions are obtained. Then, it calculates the Hadamard product of these two hidden vectors and inputs the result into a single-layer NN with an activation layer for the prediction result.
Neural Matrix Factorization
This method concatenates the hidden layer outputs of MLP and GMF, inputs it into a single-layer NN, and uses the sigmoid function to obtain user preference predictions for items. 18
Recommender VAE
RecVAE uses an improved DNN-based polynomial-likelihood VAE for CF. 24 It performs better than the previous VAE by applying regularization techniques.
LightGCN
This method is based on GCN for CF. 26 LightGCN simplifies the traditional GCN. It only normalizes and sums the nearest neighbor embeddings in the lower layer and deletes operations such as self-connection, feature transformation, and nonlinear activation. Finally, it sums the embeddings of each layer to get the final representation.
Deep Interaction-Attribute-Generation
DIAG uses two interaction relations between users and items. 8 Compared with the traditional CF method that only uses one single interaction relation, the additional interaction relation allows DIAG to get higher performance. DIAG uses a graph attention method to embed users and items and concatenates them with MLP-based embeddings to obtain the final prediction results.
Detailed comparisons are shown in Tables 2 and 3. The performance improvement is calculated as
Experimental results of Scholat
DIAG, Deep Interaction-Attribute-Generation; GMF, Generalized Matrix Factorization; GUB, generic user behavior; GCN, graph convolutional network; MLP, multilayer perceptron; NeuMF, Neural Matrix Factorization; PMF, Probabilistic Matrix Factorization; RecVAE, recommender variational autoencoder.
Experimental results of Lizhi
The values of k in
It can be seen that the matrix factorization method used by PMF lags behind the other methods on most metrics in both data sets. The performance of MLP and GMF are improved on Scholat after adding extra interaction, but their performance on Lizhi is decreased. As a method that combines MLP and GMF, NeuMF improves most of the metrics on both data sets compared with its components, but its improved version cannot fully utilize the information. The performance of RecVAE and its variants on the Lizhi is not much different.
However, the improved version of RecVAE has a great improvement on the Scholat, and its performance is second only to GUB. The performance of LightGCN is similar to that of RecVAE. Although the performance improvement of its advanced version is not as high as that of RecVAE, results also show that both LightGCN and RecVAE can effectively utilize additional interaction relations. DIAG, as a method that considers additional interactions from the very beginning, integrates the two interactions through an NN and a GAT. DIAG outperforms most models on most metrics, regardless of the advanced versions of existing models.
Compared with the best available methods, GUB has significant improvement in almost all metrics. On the
The experiment results above indicate that GUB exceeds the state of the art in most metrics, verifying the effectiveness of the GUB.
Validation of interaction relation
This section will demonstrate that GUBs utilization of multiple entity interaction relations indeed significantly improves model performance. As shown in Figure 6, the experiments were conducted independently using the Browse and Create relations in Scholat and Lizhi. The abscissa is the value of k in

Experiments of interaction relations.
Also, it can be noticed that in Scholat, the improvement effect of using the interaction relation between two entities is more significant, whereas the improvement in the Lizhi is very small. Compared with the Scholat, the proportion of user-created items in the Lizhi is 62.40%, which is relatively lower than that of 75.40% in the Scholat, resulting in the lower performance improvement of GUB on Lizhi. At the same time, the number of views of Lizhi is 858,124 times, which is 149.39 times the number of creations, whereas that of Scholat is only 3.7 times, resulting in that the scores of Lizhi are largely determined by the Browse relations in the entity interaction relations.
In this experiment, the DIAG that uses two relations simultaneously is added to the comparison. It can be discovered that in Scholat, the scores of DIAG are similar to GUB that only uses Browse relations, which indicates that GUB can make better use of multiple interaction relations and achieve better performance. The result also shows that GUB is more suitable for data sets containing similar proportions of interaction relations. For example, the ratio of the number of views to the number of creations in the Scholat is close, and the improvement of GUB on this data set is more significant.
Conclusions
GUB refers to the idea of CF and uses the similarity between user behavior and recommend items. We define the user's active actions to items as the interaction relation and then divide the entire recommendation process into three steps based on the task requirements. The first step is to extract fact triples containing users, items, and their interaction relations from the data set. The second step is to use the KGE method to embed the fact triples into a specified dimension. The last step is to predict items that users may be interested in with the link prediction method based on the similarity of user behaviors.
The experimental results on two data sets show that using HR as the evaluation indicator, the proposed method has an improvement of a maximum of 6.6% and 2.4%, and 5.7% and 0.6% on average compared with other methods. When using NDCG as the evaluation indicator, the proposed method achieves the highest 3.6% and 2.5%, and the average of 3.5% and 2.0% improvement. The experimental results validate the effectiveness of GUB in item recommendation.
Limited by the current research, there are still many deficiencies and areas worth improving. Here will be the research direction in the future:
In this article, we only use the entity interaction relations in the KG for the recommendation, but the entity itself also contains information. It is worth studying to know how to combine the information to obtain a higher precision user behavior model and improve performance.
Due to the limitation of the data set, the experiments can only validate the performance of GUB under two kinds of interaction relations. Performance under more types of interaction relations remains to be verified.
Footnotes
Authors' Contributions
Z.H.: Conceptualization (lead), writing—original draft (lead). W.L.: Methodology (lead), writing—original draft (supporting), writing—review and editing (equal). X.Y.: Validation (equal), writing—review and editing (equal). H.X.: Writing—original draft (supporting), writing—review and editing (equal). H.Z.: Formal analysis (equal), writing—review and editing. H.H.: Validation (equal). X.W.: Writing—review and editing.
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This work is supported by Guangdong Marine Economic Development Special Fund Project (GDNRC[2022]17), the National Natural Science Foundation of China (62072187), Guangdong Major Project of Basic and Applied Basic Research (2019B030302002), the Major Key Project of PCL (PCL2021A09), Guangzhou Development Zone Science and Technology (2021GH10, 2020GH10), and the Fundamental Research Funds for the Central Universities (BLX202140).