
Abstract
An accurate resource usage prediction in the big data streaming applications still remains as one of the complex processes. In the existing works, various resource scaling techniques are developed for forecasting the resource usage in the big data streaming systems. However, the baseline streaming mechanisms limit with the issues of inefficient resource scaling, inaccurate forecasting, high latency, and running time. Therefore, the proposed work motivates to develop a new framework, named as Gaussian adapted Markov model (GAMM)—overhauled fluctuation analysis (OFA), for an efficient big data streaming in the cloud systems. The purpose of this work is to efficiently manage the time-bounded big data streaming applications with reduced error rate. In this study, the gating strategy is also used to extract the set of features for obtaining nonlinear distribution of data and fat convergence solution, used to perform the fluctuation analysis. Moreover, the layered architecture is developed for simplifying the process of resource forecasting in the streaming applications. During experimentation, the results of the proposed stream model GAMM-OFA are validated and compared by using different measures.
Introduction
In ancient times, the data from smart phones, network management, product information, Internet of Things (IoT), and other data streams1,2 are highly used in an escalating variety of applications. Handling these types of big data streams in the time bounding environment is a highly complex and crucial task, because big data3–5 takes a long time to execute. Still, the conventional data management techniques are not more suitable for the real-time environments, due to their processing requirements, expense, and time. So, the cloud services 6 are increasingly used to properly handle the large amount of big data streams. Typically, the cloud7–9 is one of the popular and emerging platforms that allow the users to access their applications/services without delay and with reduced cost.
The Storm, Spark, Mahout, Hadoop, and etc. are the examples of tools used in the cloud streaming10,11 applications. Moreover, these engines allow the cloud users to continuously process the data with simple operations. However, satisfying the quality of service (QoS) 12 requirements of the big data applications still remains one of the challenging tasks, because the service providers are required to properly determine the amount of resources to fulfill the QoS, specifically the CPU and memory usage. In the existing works, different types of resource scaling methods 13 are developed for big data streaming applications. Some of the scaling approaches object to minimize the cost of resource usage prediction in data streaming. Finding efficient methods for real-time human resource adaptation becomes important. One of the most important methods for adjusting on-demand processing resources in cloud computing is elasticity.
In general, the resource scaling techniques14,15 are categorized into the proactive and reactive types, in which the reactive approaches are computationally very efficient. The management of elasticity in reactive approaches is dependent on both static bounds and if-condition-then rules. Users typically set an upper and lower limit for an intended performance parameter (such as CPU and memory usage, or response time) to activate and deactivate various resources, accordingly. There is a delay interval for the resource supply after the system hits an upper bound. There has been an application overload during that time. The lack of response when using these options is another issue. There are instances where it is easy to predict the (de)allocation of resources, but the resource configuration remains identical due to poor threshold-setting decisions.
To predict system behavior, a proactive method uses prediction algorithms to choose the appropriate adjusting actions. The application will be able to handle the rise when it actually occurs due to this capability. For accomplishing this model, the time-series-based prediction models are used, including machine learning, reinforcement learning, and pattern matching techniques. Reactive managers are those who rely on their judgments about flexibility only on thresholds; more specifically, resource reconfiguration occurs when either the lower or upper threshold is exceeded.
However, it has major problems
16
of increased latency in scaling, inability in handling multiple resources at the time, not suitable for the sensitive applications, and poor tolerance. The proactive techniques
17
overwhelm these problems by accurately forecasting the requirements of future applications. Yet, some of the baseline proactive models18–20
limit with the problems of inaccurate prediction results, autoscaling, delay in data arrival, and are clumsy. Therefore, the proposed work motivates to develop a new framework for an efficient big data streaming in the cloud systems. In this study, the resource usage patterns of multiples streams are accurately predicted by using the classifier. Moreover, it individually analyzes and captures the requirements of resources, which includes memory consumption, CPU utilization rate, and I/O status. The research objectives of this work are as follows:
To efficiently manage the time-bounded big data streaming applications in the cloud environment, a novel Gaussian adapted Markov model (GAMM)-integrated overhauled fluctuation analysis (OFA) framework is developed. To properly address the resource scaling problem in the big data streaming application system, accurate scaling decisions are made by using the combination of models GAMM-GS-OFA. To accurately forecast the resource usage with reduced error rate by using an advanced classification algorithm. To design and develop a layered architecture for simplifying the process of resource forecasting in the streaming applications.
The main contribution of this research work is to effectively perform data streaming by accurately predicting the resource usage. For this purpose, an advanced streaming framework is developed with the methodologies GAMM, GS, and OFA. In this system, the streaming data are taken as the input for processing, and then, the nonlinear features are obtained with the use of versatile feature unit integrated with the gating strategy (GS). After that, the data distribution is carried out by using the GAMM, which helps to enable reliable data streaming. During this process, the time stamp estimation and weight calculation processes are carried out to predict the resource usage.
For validating the performance and efficacy of the proposed data streaming framework, widely used measures were latency, CPU utilization rate, memory usage rate, log-likelihood, error rate, and time. Due to its network of centroids and self-learned gap, the suggested streaming model has high multidimensional scalability when compared with baselines, demonstrated by the estimated results. Real-time streaming workload assessments in big data streaming applications frequently show a sizable degree of workload variability over time. The fluctuation can be seen in the off-peak and peak times that frequently define the arrival of the workload. The resources used for streaming applications can be significantly impacted by the temporal patterns shown, and hence, resources must be adjusted up or down as necessary.
The GAMM-OFM model's capacity to make predictions over extended time periods is a significant benefit. When the process switches from one distinct state to another, the conditional independence in the GAMM-OFM model is ensured.
The other portions of this article are categorized into the following: The Related Works section investigates some of the baseline resource scheduling and load balancing models used in the big data streaming application systems. It also examines the pros and cons of each streaming model according to its resource usage prediction rate. Moreover, a clear explanation about the proposed model, GAMM-GS-OFA, is presented with its flow, architecture, and modeling equations in the Proposed Methodology section. The detailed experimentation and analysis are carried out for validating the results of the proposed big data streaming model in the Results and Discussion section. Finally, the overall article is concluded along with the future scope in the Results and Discussion section.
Related Works
This section investigates some of the baseline models relevant to resource scaling, allocation, and load balancing in the big data streaming application systems. Moreover, it examines the pros and cons of each resource scaling model based on its streaming and scaling operations.
Ali et al. 21 presented a comprehensive analysis to investigate the different types of issues in the big data analytics. Also, it analyzes the major effects of using a big data analytical model based on the horizontal and vertical platforms. Based on this study, it was identified that the major problems associated with the existing database models were mismatching, lack of numerical calculations, and missing iterative support. Zeng et al. 22 presented a taxonomy of service level agreement (SLA) management schemes used for the Big Data Analytical Applications (BDAA). The purpose of this work was to ensure the high QoS by efficiently managing the SLAs in the cloud systems. Moreover, a new conceptual framework was developed based on the multidimensional categorization mechanism for SLA management. Ullah et al. 1 objected to the development of an enhanced big data resource management framework for cloud systems.
In this study, it was stated that the big data resource management frameworks should satisfy the following parameters such as processing speed, fault tolerance, low latency, security, and scalability. Mortazavi et al. 23 implemented an advanced deadline-aware scheduling mechanism for improving the big data streaming process in the cloud system. This work utilized the data analytic query operators for the public cloud resource provisioning. Typically, minimizing the response time and increasing the energy efficiency were the major processes of the scheduling framework used in the cloud systems. However, it is one of the very complex tasks due to increased dimensionality of big data in the streaming applications.
Most of the cloud scheduling frameworks have been developed to increase the speed of processing, and to solve the size difficulties in the big data streaming applications. Furthermore, the suggested big data computing framework comprises the major phases of data model, query model, and scheduling model. In addition to that, the query partitioning algorithm was also implemented in this work to solve the partial critical path problem. Yet, this conceptual framework was very difficult to understand, and it follows some complex operations to perform the big data streaming.
Vergilio et al. 24 deployed a systematic approach, named as unified vendor-agnostic solution for big data streaming application system. The purpose of this work was to investigate the importance of virtualization in the cloud systems for enhancing the process of scheduling. The key components of the big data framework were as follows: data processing, loading, aggregation, visualization, and model specification. Moreover, minimizing the energy consumption was one of the most essential factors that must be properly addressed in the big data streaming applications. Liu et al. 25 presented a new wireless big data architecture for streaming applications. In this study, the machine learning models used for big data processing were categorized into different types according to their learning capability, which includes the following:
Instance-based learning
Online learning
Batch learning
Model-based learning
Moreover, the prediction and online refinement processes were performed in this framework by using various optimization-based classification models. It encompasses the methodologies of online convex, incremental stochastic gradient, progressive learning, and adaptive learning model. Based on this study, it is analyzed that the throughput maximization is one of the essential factors that need to be addressed in the big data streaming systems. Inoubli et al. 26 discussed about the different types of challenges associated with the big data streaming models. In this study, the four distinct types of streaming frameworks have been validated and examined for big data applications, which include the following:
Apache spark
Storm
Flink
Samza
All these frameworks are very popular for the big data streaming application systems, and also that allow real-time scaling operations with high efficiency. Moreover, the performance of these tools was assessed in terms of latency, machine learning compatibility, flexibility, clustering management, Application Programming Interface, parallelization, and data transport. From this study, it is analyzed that memory consumption, CPU utilization rate, and bandwidth of resource usage must be improved for an efficient data streaming. Table 1 presents a comparative analysis of the existing and proposed streaming techniques used for the big data streaming applications.
Characteristic analysis of baseline and proposed streaming models
Proposed Methodology
This section provides a clear explanation about the proposed resource scaling methodology used for big data streaming in the cloud systems. The original contribution of this work is to design a new resource prediction framework for the big data streaming applications. In this study, the resources are properly forecasted by analyzing the characteristics/features of each data stream. The working flow and architecture model of the proposed big data streaming application system are shown in Figures 1 and 2, respectively. The proposed streaming framework incorporates the methodologies of GAMM, GS, and OFA for predicting the resource. As shown in the layered architecture, the given streaming problem is decoupled into the layers, whereas each stream job is individually modeled by using the combination of GAMM-OFA method.
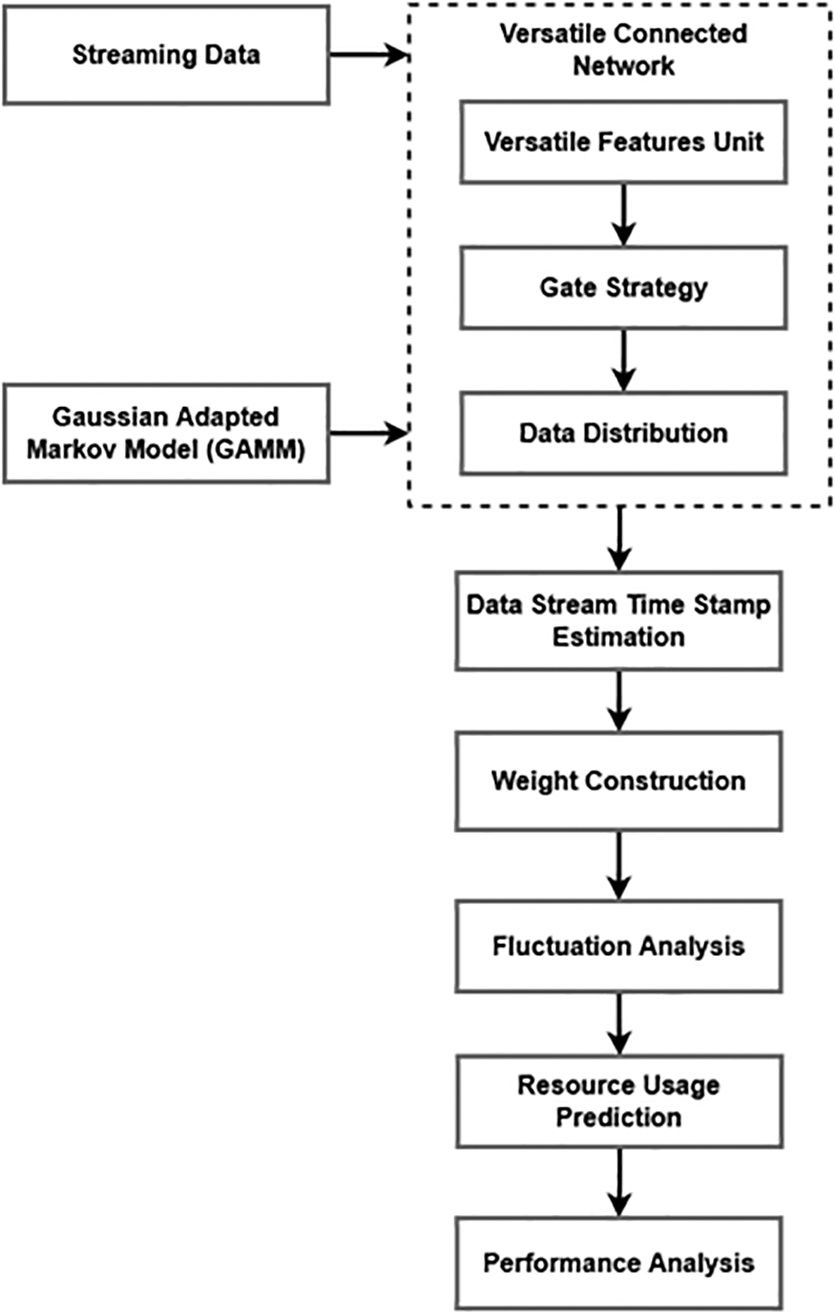
The proposed work flow of Gaussian adapted Markov model.
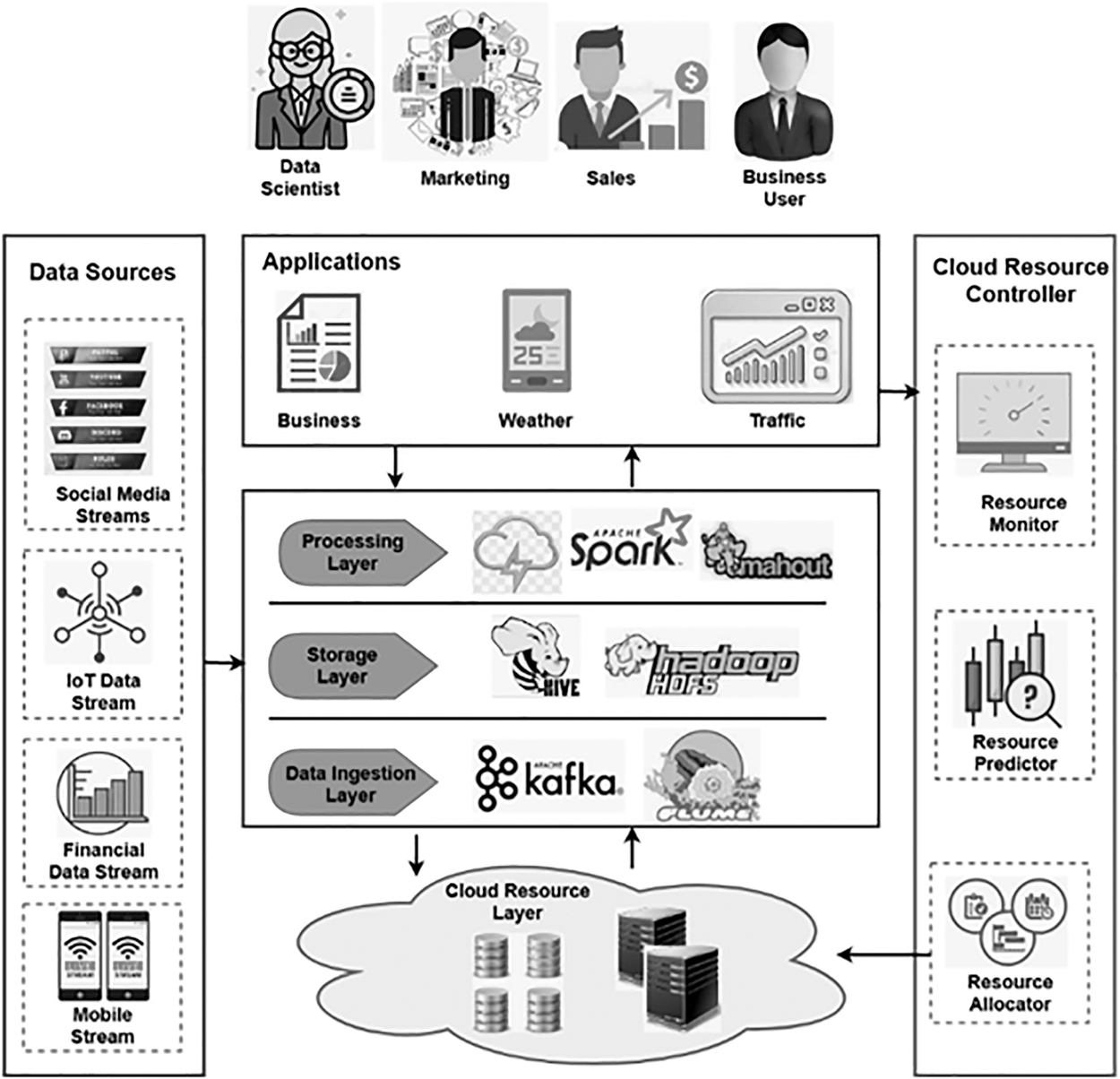
Architecture model.
Typically, resource provisioning is one of the most significant problems that need to be addressed in the big data streaming applications. Also, it is highly essential to accurately predict resource usage with a reduced error rate, and prediction of time span. Hence, this research work objects to implement a novel GAMM- based GS-OFA methodology for predicting the resource usage of big data streaming applications. The primary advantages of this work are computational efficiency, minimized error rate, accurate prediction rate, optimized time period, and less overhead. As shown in Figure 1, the streaming data are obtained as the input for processing, where data streaming is performed with proper resource usage prediction. After getting the data, the GS is used to extract the set of features for obtaining the nonlinear distribution of data, where the GAMM is integrated for enabling an effective data distribution.
For better data streaming, feature analysis and data distribution are performed in the proposed framework with the use of GAMM technique. To improve the performance of GAMM, the gradient descent function is estimated based on the parameters of learning rate and weight value. Consequently, the OFA is performed to predict the resource usage, which helps to predict the accurate resource consumption of streaming application. So, the GAMM is used for enabling reliable and efficient data streaming, and OFA is used for the prediction of resource usage. As shown in Figure 2, the different types of streaming data such as social media streams, IoT data streams, financial data streams, and mobile streams are processed in the cloud network with the use of distinct layers such as application, processing, storage, data integration, and cloud resource.
Moreover, the resources required for processing these data streams, the controlling units such as resource monitor, resource predictor, and resource allocator, are used. Overall, huge dimensional big data streams are effectively processed in the proposed framework with an optimal resource utilization rate by using the combination of GAMM-OFA methods.
Big data streaming
At first, the streaming data are initialized with the training samples and predicted class label as represented below:
Initialize streaming data,
where
In the versatile feature unit, the nonlinear distribution of data and fat convergence solution have been attained based on the set of features extracted by using the GS as shown below:
where
Consequently, the output of versatile feature unit is produced as follows:
where
Then, its corresponding forward propagation function is estimated by using the following model:
where
Here, the online gradient descent function is used to optimize the classifier parameter as indicated below:
where
Furthermore, the weight is constructed according to the updated GS as represented below:
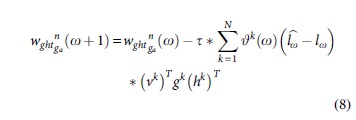
where vk represents the feature versatile unit for all N number of units.
• After that, the model performance vector is constructed with the previous time stamp
Consequently, the model performance of the current time stamp is computed by using the following model:
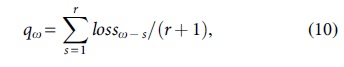
where r represents the model performance parameter.
Then, the fluctuation value vector is estimated according to the fluctuation level as shown below:
where
If the estimated fluctuation level is small and moderate, the selection function of classifier is determined by using the ensemble model as shown below: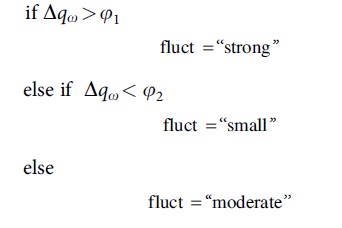
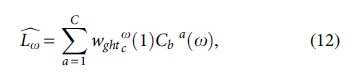
where
GAMM-based classification
For accurately predicting the resource usage, the GAMM-based probabilistic classification technique is implemented in this work. It is one of the advance classification approaches that help to forecast the resource usage in the big data streaming application systems. In other words, it is determined as the stochastic process accumulates the viable points in the parameter space. Moreover, the key benefits of GAMM are accurate prediction results, minimal classification error rate, and simple to understand. In this technique, every next state depends on the current state, where no variation in every state transition, since the states are determined as the time invariant model. Then, the number of states in the GAMM is considered M, which are most likely hidden. During practical implementation, the physical implication is generally assigned to every state or the set of states in the model, which is represented as follows:
Then, a fixed state sequence is represented as shown below:
where the state at a time t is represented as rT. Consequently, the observation symbols at each state are denoted as N, which is corresponding to the modeled output of the physical system. The individual symbols are represented as follows:
Then, the initial state of the system
where
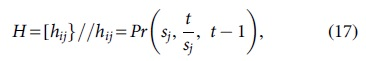
where
where Pj represents the observation at time t and the following conditions are considered:
Consequently, the threshold value is determined for the probability for taking decisions based on the GAMM stochastic process, and is illustrated below:
where Ht is the multivariate Gaussian distribution, and Ct denotes the covariance information of the given data. Then, the GAMM is initialized with the new solution as shown below:
where
where
where NT represents the weighting factor. Finally, the fitness-dependent update value of tH makes the model as invariant that is used to compute the linear transformations in the objective function.
Fluctuation analysis
In this study, the fluctuation analysis (FA) is performed to accurately predict the resource usage of the big data streaming applications, which highly improves the prediction accuracy of resource consumption. Moreover, it is used to determine the fluctuation of streaming data according to the model performance of the adjacent time stamp values. If the fluctuation streaming is strong, the current data distribution is adapted with the ensemble model of classifier; if it is moderate, the weight value of the classifier less than the threshold value is considered stationary. Otherwise, the fitting capabilities of the data are further improved. The motive of using this technique is to activate or halt the streaming services based on the fluctuation state.
In this algorithm, the trained model loss factor is taken as the input for processing, and the state of fluctuation is produced as the output. During initialization, the loss factor is set with the parameters of model performance vector, time stamp, and strong and small fluctuation detection parameters.

As shown in Algorithm 1, the steps involved in the OFA are illustrated. The OFA is mainly implemented in this study to predict the resource utilization for making a reliable and successful big data streaming. In this technique, the training loss function, model performance parameter, strong and small detection parameters are taken as the inputs for analysis. After initializing the parameters, the performance vector is updated with the time stamp value. According to the loss function, the model performance vector is calculated and updated with the fluctuation value. Then, certain conditions are validated to determine the strong, moderate, and small resource usage predictions.
After that, the versatile classifier weight value is computed for streaming big data in the cloud systems. During this process, the streaming data, learning parameter, model performance parameter, and fluctuation detection parameter are considered inputs for processing. After initializing these parameters, the network is initialized with m number of versatile classifiers as shown below:
Then, the storage weight matrix of the versatile classifier is estimated according to the former time stamp value. The instance block of the streaming data is received with its appropriate true labels. Consequently, the gate updation is performed and the adaptive depth unit is estimated. Moreover, the loss value of base classifier is determined by using the following model:
After that, the label and gate parameter of classifier are updated by using the following models:
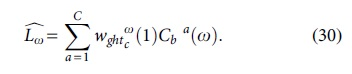
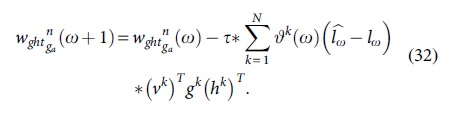
Finally, the normalized versatile classifier weight value is computed by using the following model:
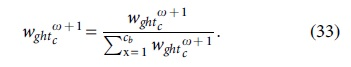
Based on this weight value, the resource usage is predicted with high accuracy and a reduced classification error rate. Furthermore, it enables an efficient and perfect big data streaming in the cloud systems with improved performance outcomes.
Here, the generator sigmoid function
Then, the derivative function of
If estimated value of
According to the values of
If
If
The proof for the properties of (i)–(vi) are given below:
For simple understanding, let us consider
Based on this, the function is substituted as
Let us consider
Let us consider
According to the definition of
Moreover, the limit properties of a generator function f, and the limit properties of the exponential function are considered here. This property immediately follows the definition of the generator function that depends on the sigmoid function
Results and Discussion
In this study, a detailed experimentation is conducted to validate the proposed models, GAMM-OFA, by using various parameters such as latency, memory consumption, likelihood function, prediction rate, purity, and standard deviation. A physical system with an 8-core i7-3770 CPU running at 3.40 GHz and 16 GB of RAM was used to set up the Spark cluster. With setups of 4 and 8 GB RAM and 2 VCPUs each, two VM instance types were taken into consideration. Each node had Hadoop 2.6, Spark 1.6, Scala 2.11, and JDK/JRE v1.8 installed. The other nodes were set up as slaves, with one node acting as the master. Each slave node has a 50 GB SSD disk, and the master node had a 195 GB SSD drive. Due to the lack of an independent storage system, Apache Spark was created to operate on the top of Hadoop.
It was configured to use Hadoop Distributed File System (HDFS) to supply storage for the streaming data. Apache Flume, a distributed system for gathering, aggregating, and transmitting the events produced, has been used to gather the streaming data. A certain quantity of data are downloaded at each interval and stored in HDFS so that the Spark engine may start processing it right away. The prediction model has been evaluated using two streaming application packages. At the master node, the constructed applications have been launched and monitored at various intervals. Each streaming application's workload arrival rates, the amount of streams, and a variety of system performance metrics have been obtained and stored for future examination. Moreover, the adaptability and applicability of the proposed big data streaming framework are verified by analyzing the resource usage in the cloud systems.
As shown in Figure 3, latency is computed for the existing data stream and proposed models, GAMM-OFA, with respect to varying time sequences in terms of minutes. In general, the latency is one of the most important parameters used to assess the performance of streaming applications. It is estimated based on the time delay of the data streams, in which increased latency could affect the performance of the entire big data streaming application. Hence, it must be properly minimized by accurately predicting the resource usage for data streaming. According to the estimated results, it is analyzed that the proposed model, GAMM-FD, provides reduced latency, when compared with the other techniques. Consequently, Figure 4 validates the CPU and memory usage rate of the proposed model GAMM-OFA, with respect to varying time in terms of minutes.
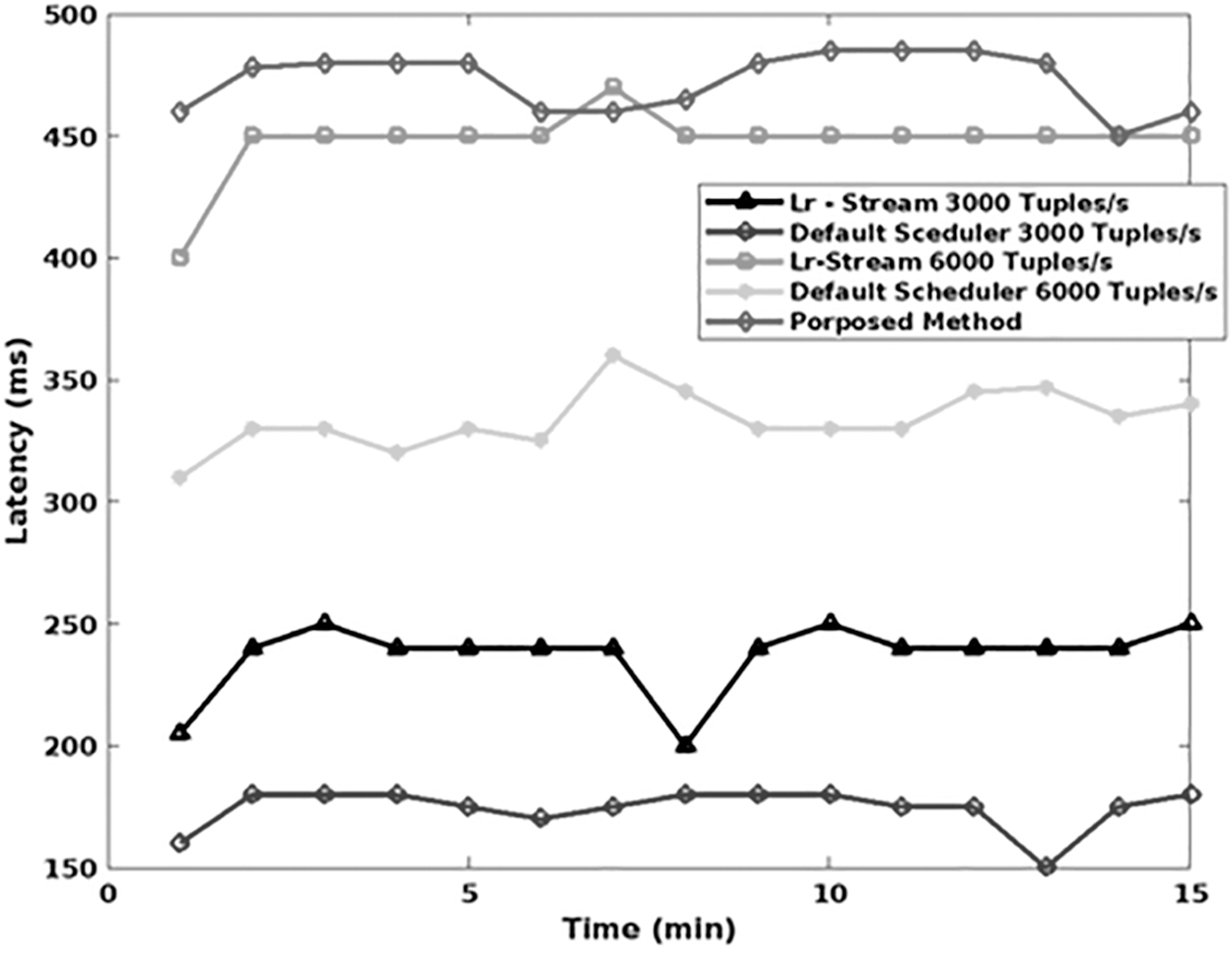
Latency versus time (minutes).
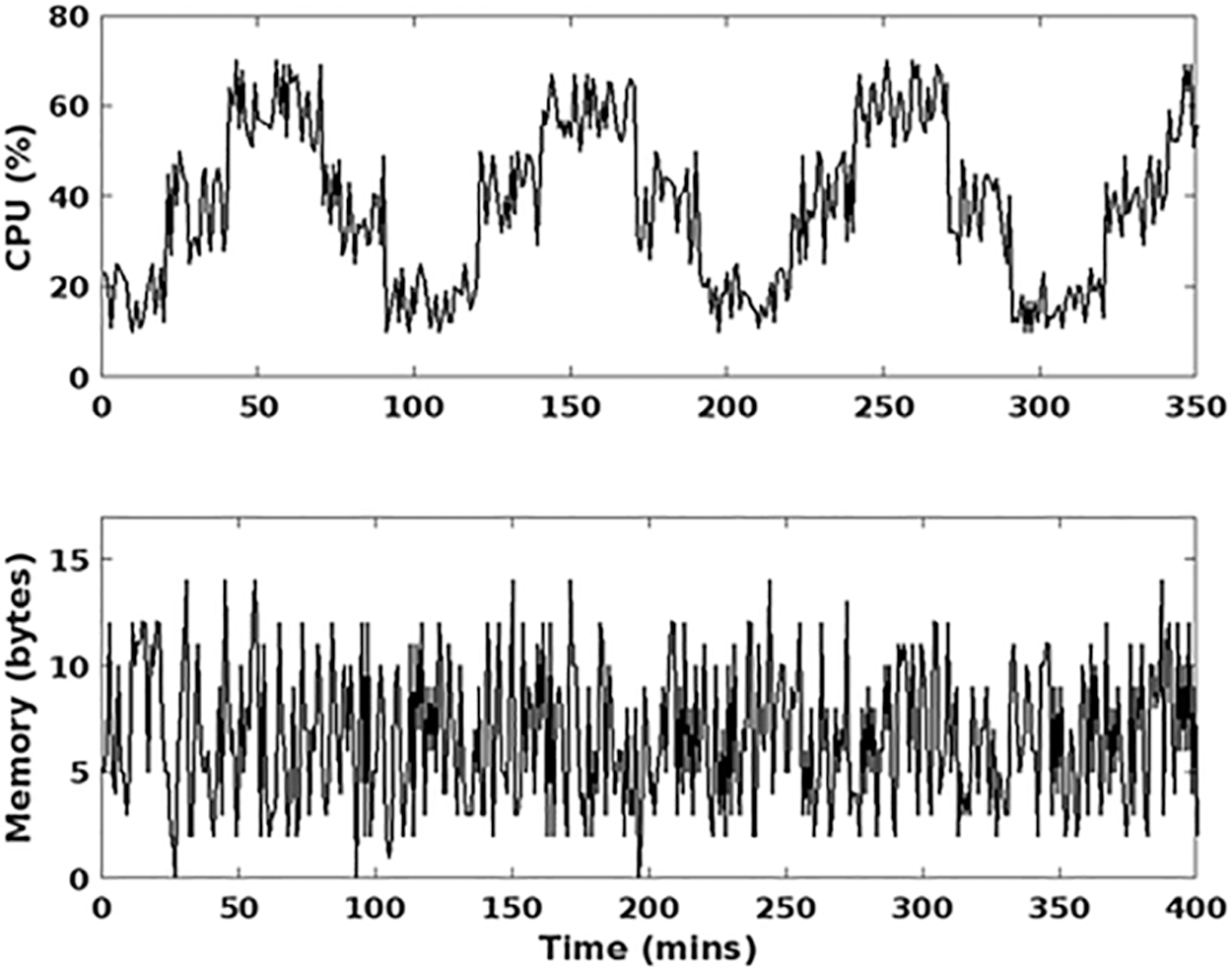
CPU and memory usage.
These parameters are mainly estimated to analyze the resource usage efficiency of the proposed big data streaming framework, in which, the CPU usage is determined in terms of (%), and the memory usage is determined in terms of bytes. Based on the curves, it is analyzed that the resource usage is properly maintained in the proposed streaming framework by forecasting the usage with the help of a classifier. Moreover, the log-likelihood function of the proposed GAMM is estimated as shown in Figure 5. According to the states of classifier, the model parameters of GAMM are updated and re-estimated for obtaining the results. In this study, the log-likelihood function is computed based on the training model of classifier.
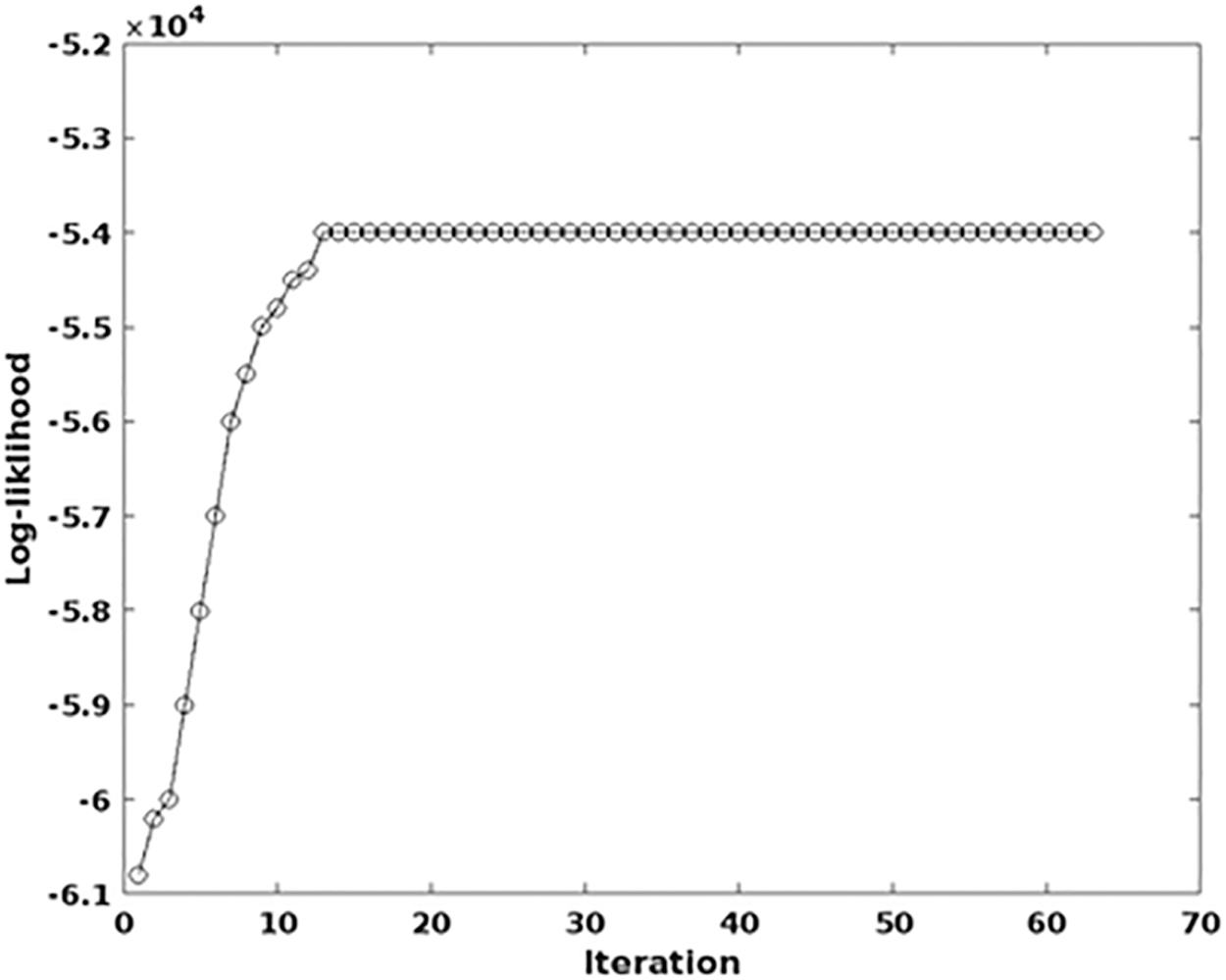
Log-likelihood analysis.
In Figure 4, the parameters such as memory utilization and CPU utilization rate are estimated with respect to changing time (m), where the y-axis indicates the CPU usage in terms of percentage and x-axis indicates the memory usage in terms of bytes, and the x-axis represents the time (minutes). As shown Figure 4, both parameters CPU and memory usage are estimated with changing time. Moreover, the obtained results indicate that the CPU usage rate is reduced to 20%, and the memory consumption is reduced to 10 bytes. Similarly, the log-likelihood value is estimated in Figure 5 with respect to a different number of iterations, where the log-likelihood is represented in y-axis, and the count of iterations is represented in x-axis. This parameter is mainly estimated to validate the training efficiency of the classifier.
Figure 6 validates the states of GAMM classifier with respect to varying time intervals, which includes the actual and predicted classes. From the analysis, it is evident that the proposed GAMM could accurately predict the state of classifier under varying time sequences. Due to the proper weight estimation and model parameter computation, the states of classifier are accurately predicted, which depicts the improved performance of the proposed big data streaming framework. Moreover, the error rate of the GAMM-OFA mechanism is shown in Figure 7, which includes the root mean squared error (RMSE) and mean absolute percentage error (MAPE). The parameters are computed as follows:
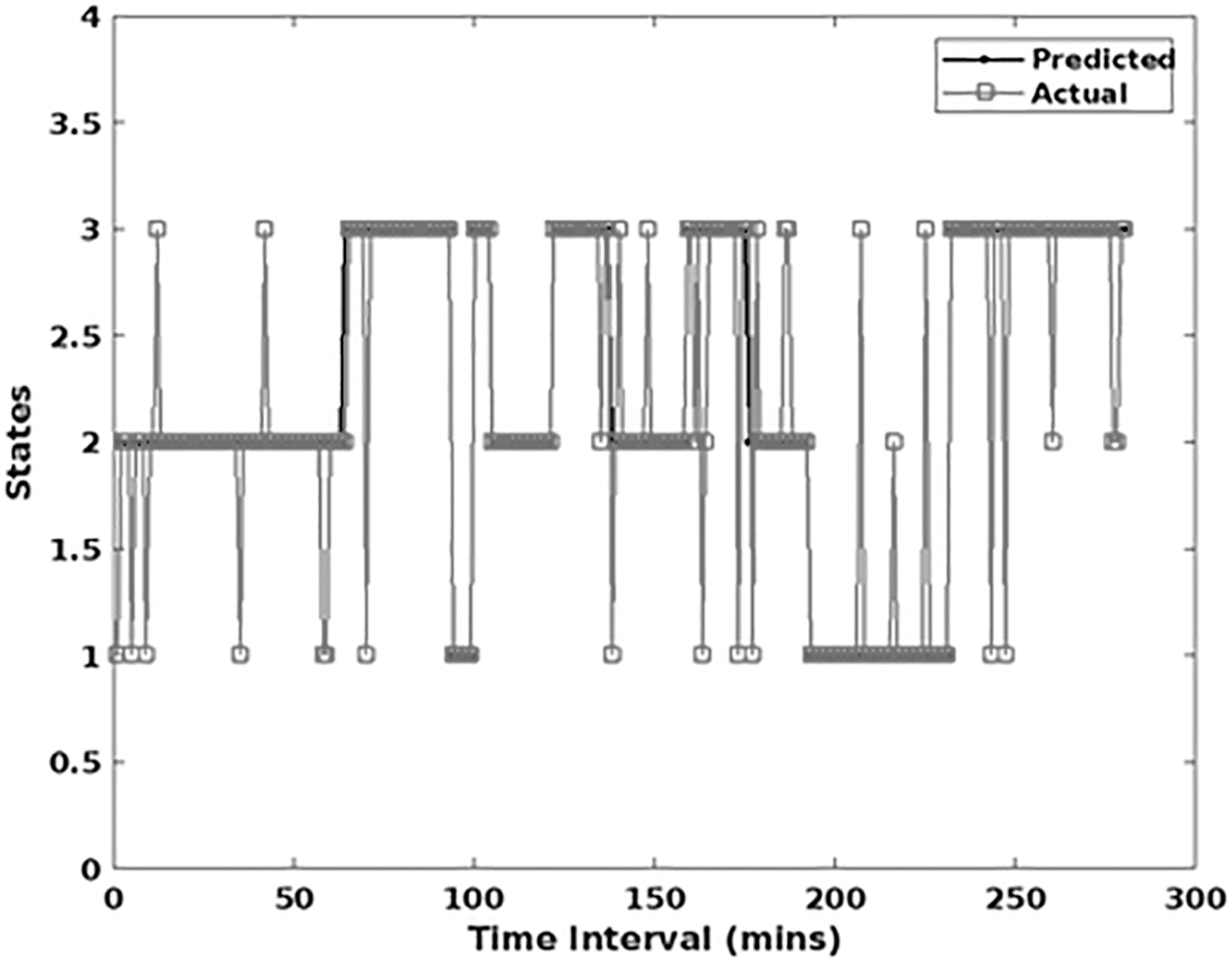
Actual and predicted states.
Error rate.
where N is the number of iterations,
where N indicates the number of nonmissing data points, ai is the actual observation, and
Figure 8 validates the running time (seconds) of the existing streaming 41 and proposed GAMM-OFA mechanisms by using various data sets such as DB2, RBF5, RBF10, and RBF20. The existing techniques considered in this work are CEDAS, HDD stream, GD stream, D-stream, and ESA stream. Here, the running time is mainly estimated for analyzing how data streaming is executed in the cloud systems with different data sets. Based on the estimated results, it is analyzed that the running time of the proposed model GAMM-OFA is efficiently reduced, when compared with the other data streaming techniques. Due to proper resource prediction based on the fluctuation analysis, the running time required for data streaming is efficiently minimized in the proposed framework. Consequently, purity (%) is also estimated for the existing and proposed streaming frameworks by using various data sets. Figure 9 depicts the purity analysis carried out and compares with the proposed system.
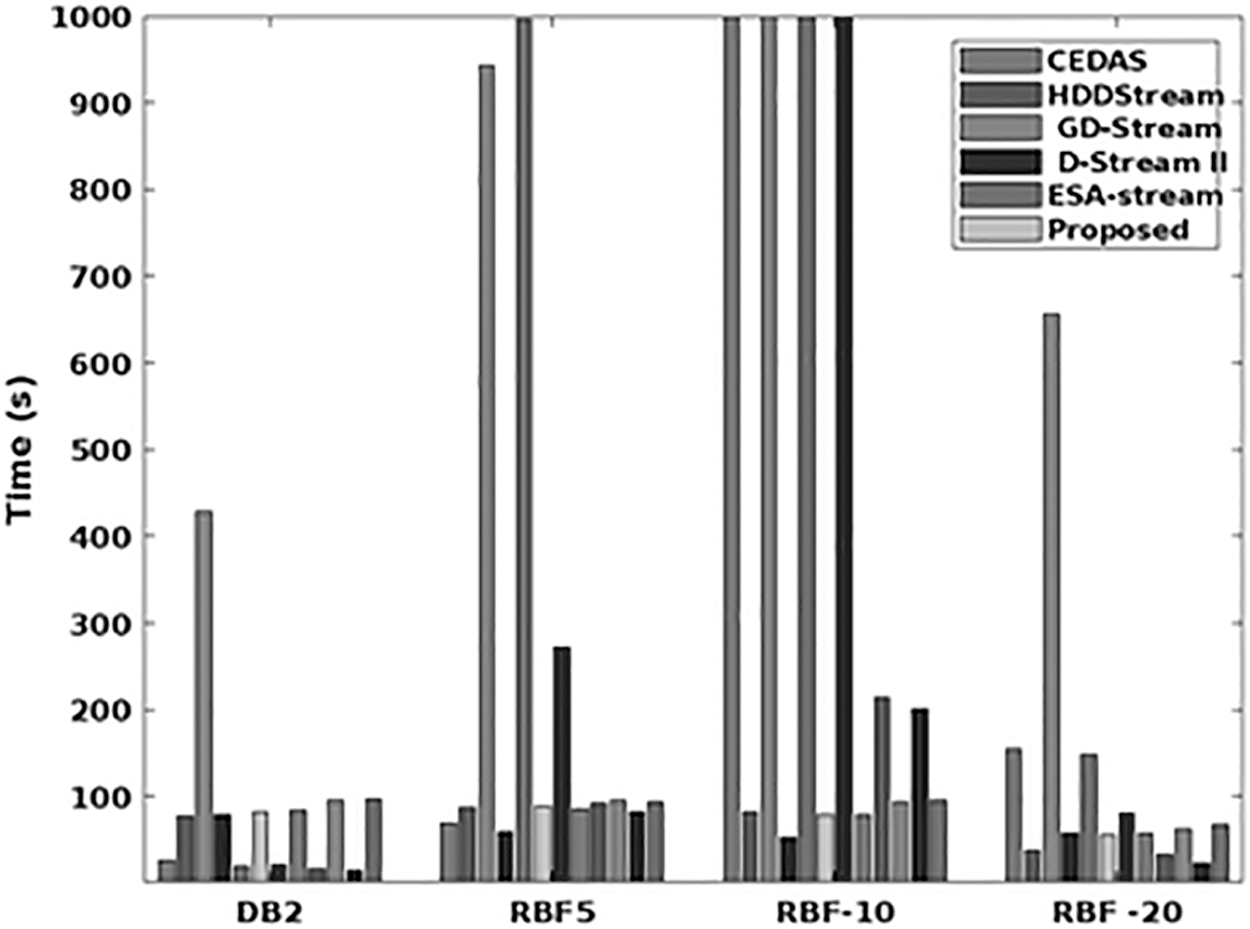
Time analysis.
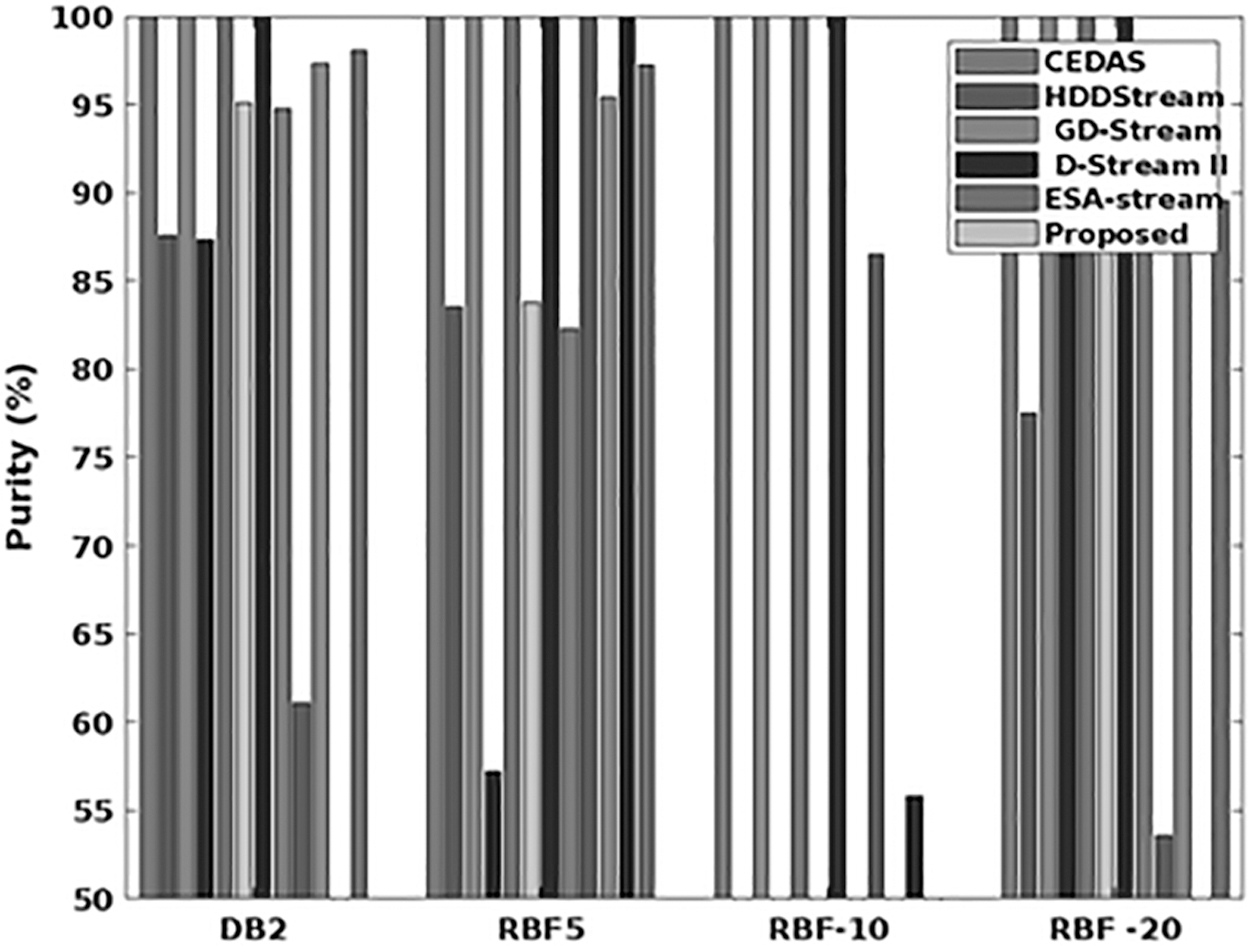
Purity analysis.
In other terms, purity is defined as the precision of classifier, which helps to determine the forecasting accuracy of classification. Table 2 depicts the time and purity analysis of existing and proposed streaming techniques for various data sets. According to the results, it is identified that purity is also highly improved in the proposed data streaming framework by using the FA.
Time and purity analysis
Figure 6 depicts the average throughput of the existing and proposed data streaming mechanisms in terms of tuples/second. Typically, the throughput is defined as the successful data transmission in the network through communication channel. The increased value of throughput indicates the improved transmission efficiency of the streaming techniques. From the results, it is evident that the average throughput of the proposed GAMM-OFA technique is highly improved, when compared with the other big data streaming models, because the proper fluctuation analysis with GAMM helps to accurately predict the resource usage in the versatile network. Hence, the average throughput of big data streaming is highly improved in the proposed framework. Figure 10 depicts average throughput analysis carried out with existing approaches and proposed system.
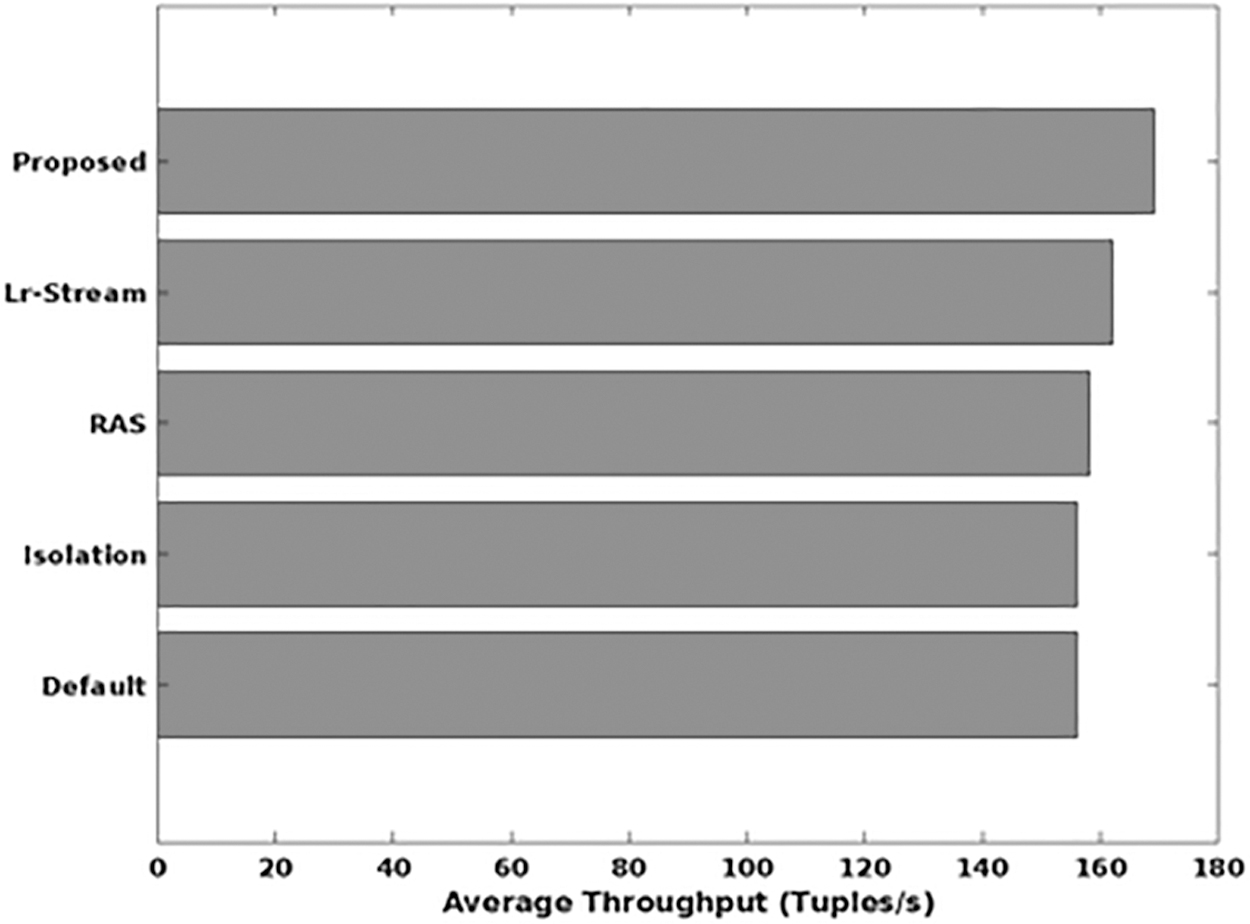
Average throughput.
Figure 11 validates the latency of various data streaming techniques with respect to different time sequences (minutes). Similarly, the average latency of the task scheduling techniques used in the existing big data streaming framework is compared with the proposed model, GAMM-OFA, as shown in Figure 12. The estimated results show that the overall latency of the proposed streaming model is highly reduced by properly balancing the loads in the cloud systems. Moreover, the GAMM accurately forecasts resource usage with the help of gating methodology and fluctuation analysis. Hence, the proposed big data streaming technique overwhelms the baseline techniques 42 with reduced average latency. Then, the standard deviation measures of the baseline and proposed streaming models are estimated and compared under different time instances (seconds).
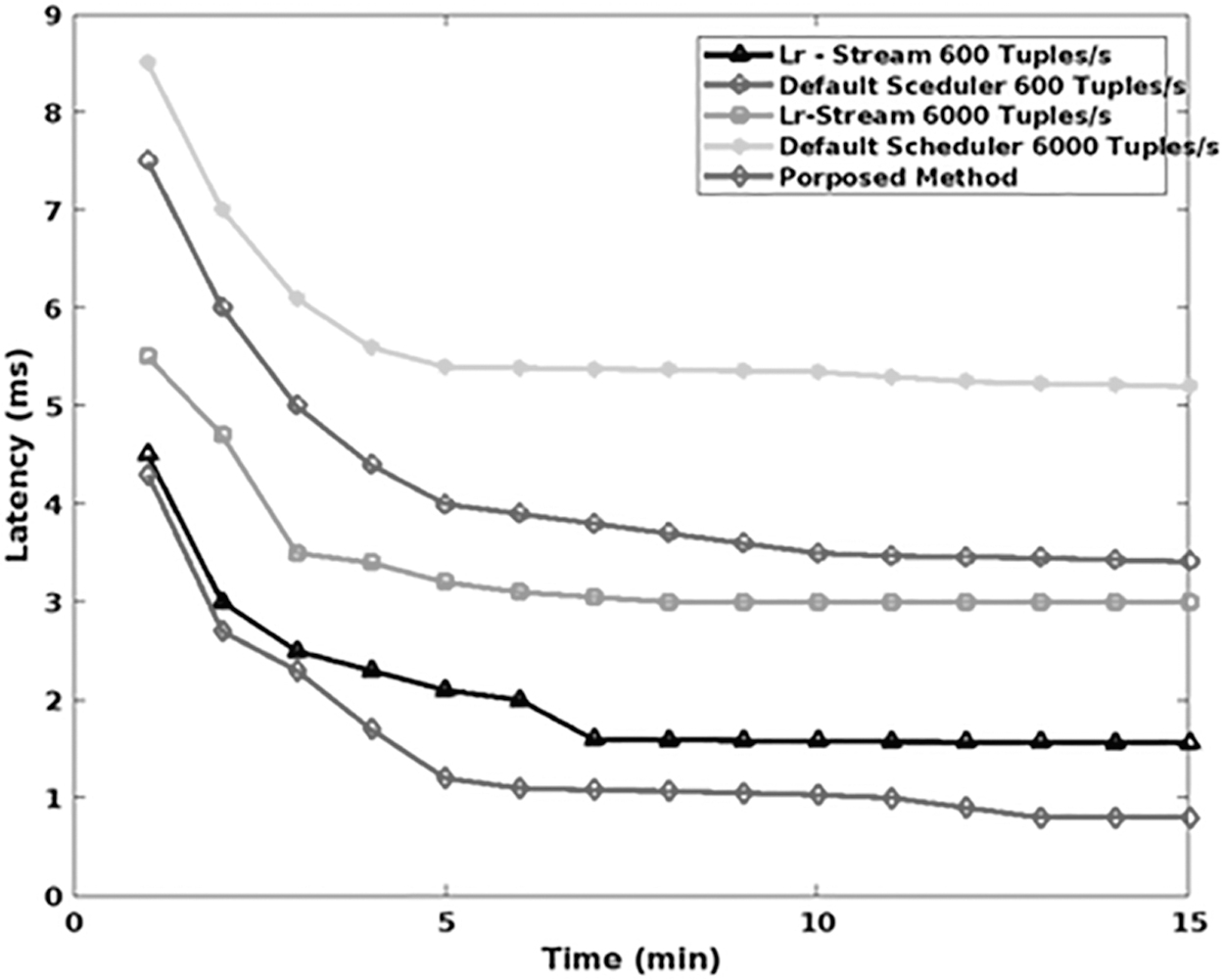
Latency of various data streaming techniques.
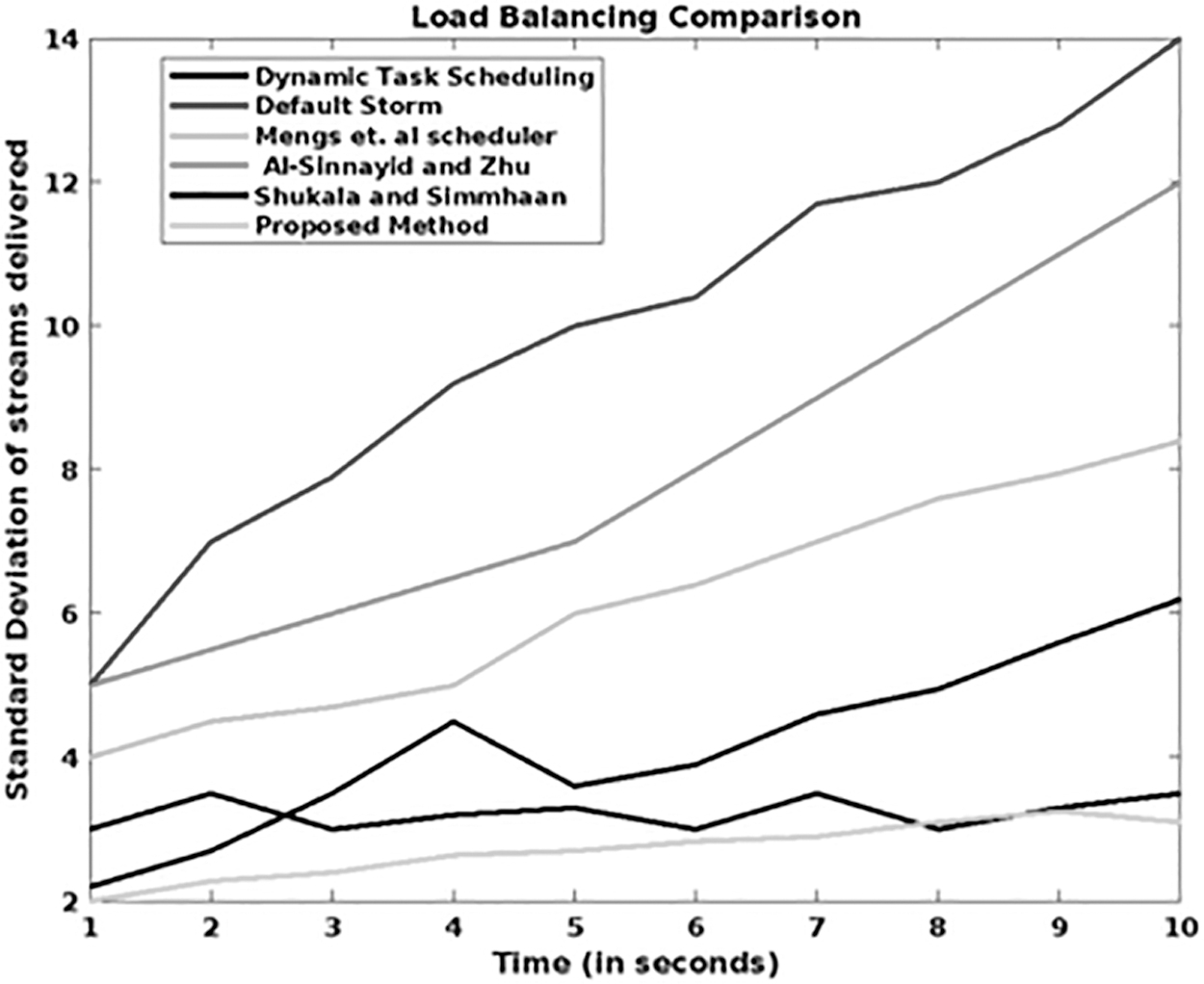
Standard deviation of streams.
In this study, the standard deviation is computed according to the number of streams delivered in the cloud systems. The reduced standard deviation ensures an effective load balancing in the streaming applications. From the observed results, it is stated that the GAMM-OFA technique could efficiently reduce the standard deviation, when compared with the baseline streaming models. Load balancing analysis is shown in Figure 13.
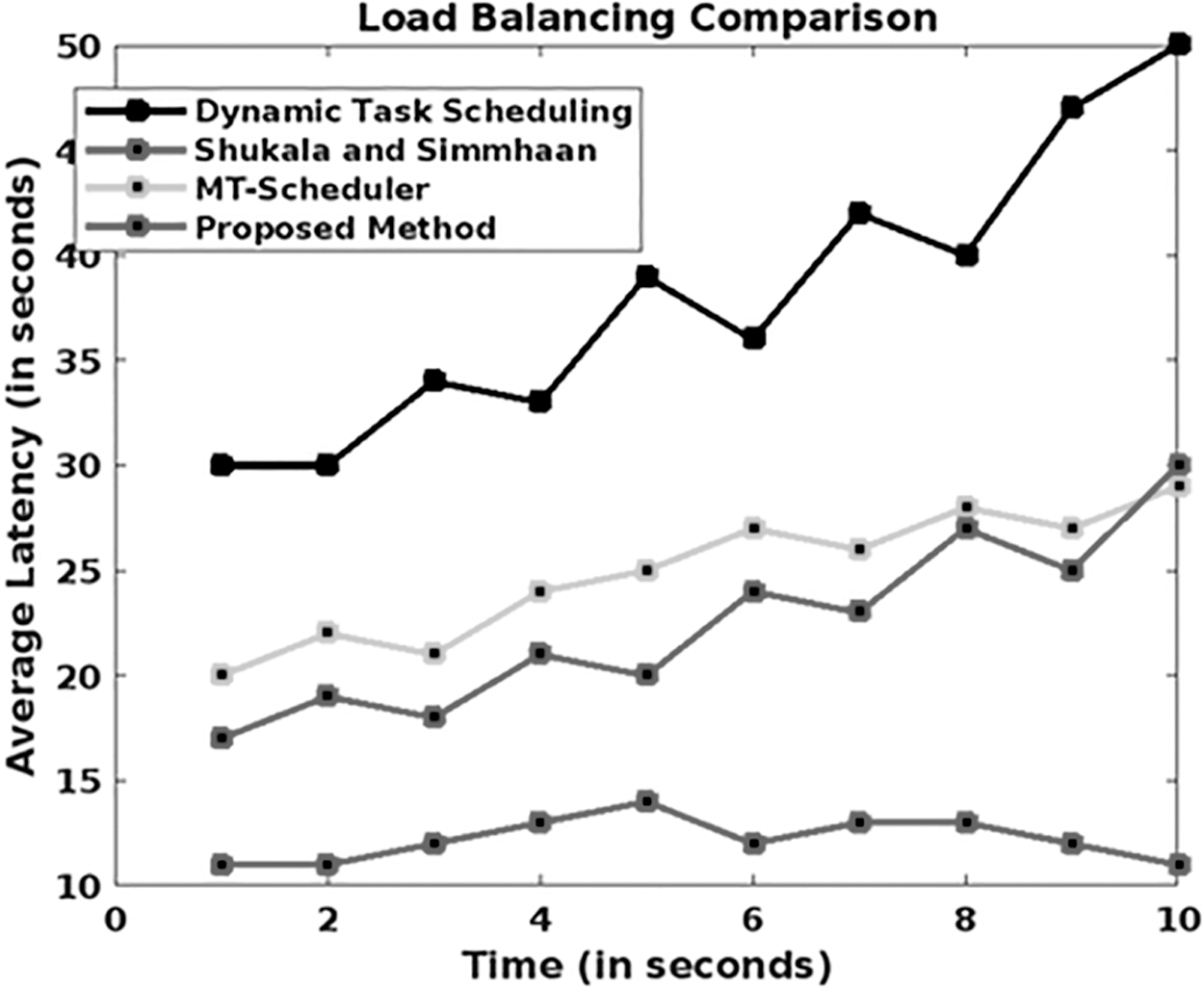
Load balancing analysis.
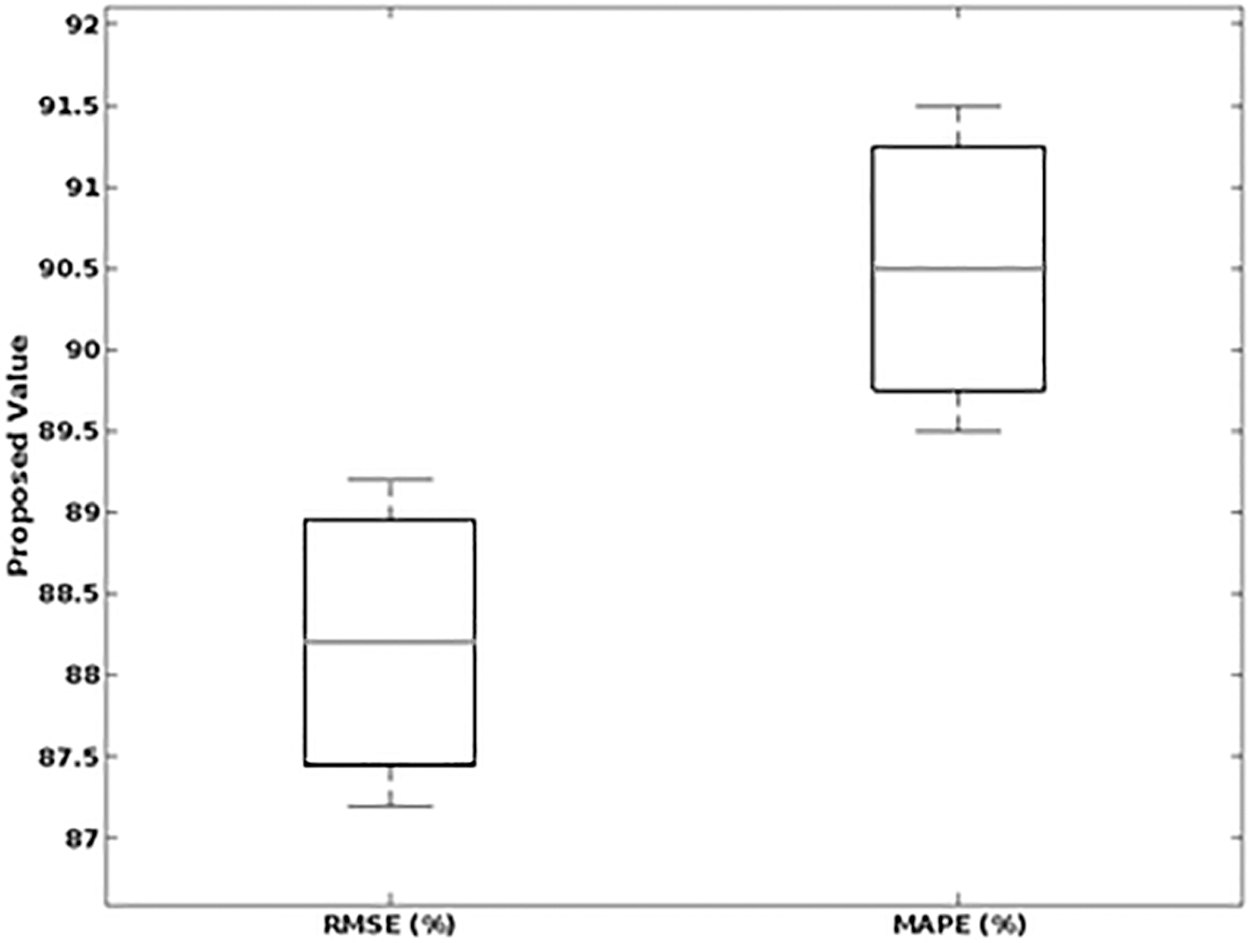
Table 3 validates the RMSE and MAPE values of the proposed big data streaming system with respect to the experimental time period and prediction time in terms of hours. The results indicate that the error rate is greatly reduced in the proposed framework by effectively streaming the data in the cloud network.
Prediction analysis
MAPE, mean absolute percentage error; RMSE, root mean squared error.
A training set and a prediction set were generated from the collected data sets. We trained the models on the training set and evaluated their accuracy by testing them with the prediction sets. After that, the upper layer used the GAMM-OFA results as input characteristics to decide how to scale the resources. In the prediction step, the system's current state is computed and used to forecast its future state. In this study, we attempt to produce a series of states that gave rise to the observation sequence. The degree to which the model works on new data sets that were not utilized when fitting the model tells us how accurate it is. In addition, two performance indices—the MAPE, a frequently used scale-independent measure, and the RSME, a scale-specific measure used to assess the prediction accuracy of the models, GAMM-OFA.
We used the OFM algorithm to figure out the states that had already been given the observations using the GAMM. After getting the model's parameters, we use a simulation strategy to create our own set of data. Because of its reliability in maintaining its predictive capabilities across time, the GDMM-OFM is effective at anticipating the resource consumption states of streaming applications. We can forecast the resource requirements of unbounded large data streaming applications by introducing explicit temporal structure into the framework. By using the created big data streaming applications operating in the Spark streaming environment, the proposed framework is validated and tested. Since the GAMM-OFM-based framework directly describes the duration of states, our empirical findings demonstrate that it performs significantly better than the standard models when used in unconstrained scenarios.
Conclusion
This article presents a new framework, named as GAMM-OFA Stream, for forecasting the resource usage of the big data streaming applications. In the existing works, different types of resource scaling techniques have been developed for big data streaming systems. Yet, most of the baseline models limit with the problems of inaccurate forecasting, high latency, reduced throughput, and increased error rate. Therefore, the proposed work motivates to develop a GAMM-based classification methodology to predict resource usage for big data streaming. In this study, the GS and OFA model are incorporated with the proposed streaming model for increasing the accuracy of scaling with reduced error predictions. Typically, resource provisioning is one of the most significant problems that need to be addressed in the big data streaming applications.
In GAMM, every next state depends on the current state, where no variation in every state transition, since the states are determined as the time invariant model. The OFA is used to determine the fluctuation of streaming data according to the model performance of the adjacent time stamp values. Furthermore, it enables an efficient and perfect big data streaming in the cloud systems with improved performance outcomes. In addition to that, an extensive experimentation is conducted in this work for validating the results of the proposed streaming model, GAMM-OFA, based on the parameters of latency, throughput, RMSE, MAPE, standard deviation, and running time. Then, the obtained values are compared with some of the recent baseline big data streaming models. Overall, the obtained results indicate that the proposed GAMM-OFA stream outperforms the baseline models with improved performance values due to proper resource usage prediction.
In the future, this work can be enhanced by implementing a new optimization + deep learning methodology for resource scaling in the big data streaming application systems.
Footnotes
Author Disclosure Statement
No competing financial interests exist.
Funding Information
No funding received to carry out this research.