
Abstract
Predicting propagation cascades is crucial for understanding information propagation in social networks. Existing methods always focus on structure or order of infected users in a single cascade sequence, ignoring the global dependencies of cascades and users, which is insufficient to characterize their dynamic interaction preferences. Moreover, existing methods are poor at addressing the problem of model robustness. To address these issues, we propose a predication model named DropMessage Hypergraph Attention Networks, which constructs a hypergraph based on the cascade sequence. Specifically, to dynamically obtain user preferences, we divide the diffusion hypergraph into multiple subgraphs according to the time stamps, develop hypergraph attention networks to explicitly learn complete interactions, and adopt a gated fusion strategy to connect them for user cascade prediction. In addition, a new drop immediately method DropMessage is added to increase the robustness of the model. Experimental results on three real-world datasets indicate that proposed model significantly outperforms the most advanced information propagation prediction model in both MAP@k and Hits@K metrics, and the experiment also proves that the model achieves more significant prediction performance than the existing model under data perturbation.
Introduction
Information propagation is a fundamental and ubiquitous event in our daily lives, 1 such as viral marketing, 2 online advertising, 3 fake news controlling, 4 campaign strategy, 5 and epidemic prevention.6,7 Therefore, the information propagation prediction techniques, which aims at identifying potential users of information dissemination, are urgently needed to solve the problems of current online social media application scenarios.8,9 The information diffusion prediction can be described as: given a sequence of information cascades, the diffusion model aims at estimating the likelihood of spreading information among other potential users and predict the ranking of these users, as shown in Figure 1. However, due to the complexity and large-scale nature of the data, predicting information propagation in social networks is a challenging task.10,11
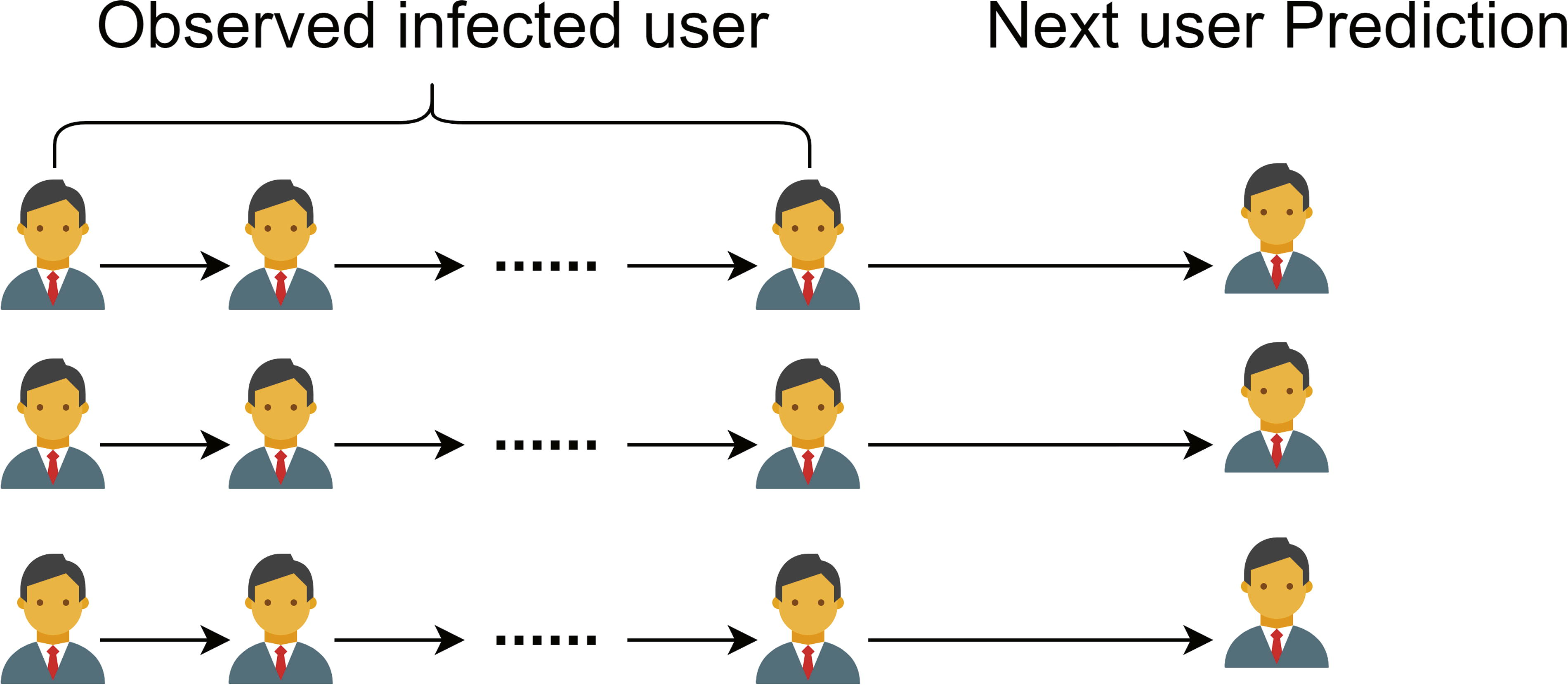
Information propagation prediction.
The problem of diffusion prediction has attracted extensive research attention. Previous studies always concentrate on sequence or structure of cascades itself, ignoring social structures that are not visible in cascades but have a significant impact on users’ behavior,12–15 leaving them unable to exploit inactive users. Recurrent neural networks (RNNs) are used to extract sequential features of diffusion events, while convolutional neural networks (CNNs) have been used to mine meaningful features from the diffusion network. 16 Furthermore, graph neural networks (GNNs) have also been widely used for information diffusion prediction, as they can capture the structural information of the diffusion network. 17 Xue et al. 18 compared the performance of the SIR model, logistic regression, and deep neural networks on predicting the spread of COVID-19 topic on Twitter. They found that deep neural networks outperformed the traditional methods in terms of prediction accuracy. Similarly, Li et al. 19 compared the effect of various deep learning-based methods, including RNNs, CNNs, and GNNs, on predicting the popularity of tweets on Twitter. They found that GNNs outperformed the other models in terms of both prediction robustness and accuracy. Qiu et al. 20 proposed a GNN framework to capture users’ potential feature of user social networks for predicting diffusion. Yang et al. 21 proposed reinforced recurrent networks with structural context (FOREST) that combines graph convolutional network (GCN) and gated recurrent unit (GRU) to jointly extract the cascading contents and social network feature representations. Recently, Yuan et al. proposed dynamic heterogeneous graph convolutional network (DyHGCN), 22 which developed heterogeneous graphs to collectively learn user interactions and social relation. Wang et al. 23 developed an dynamic diffusion variational autoencoder (DyDiff-VAE) to predict the diffusion likelihood by federating information from cascade sequence and forwarding user content.
Although the above methods are able to exploit both cascading sequences and user–social relationships to some extent, they still suffer from some limitations. First, the existing methods ignore the global dependencies of cascades and users, which is insufficient to characterize their dynamic interaction preferences, limiting the performance of prediction. Furthermore, the existing method model is poor in solving the problem of model robustness. Once the model is disturbed, its performance will significantly decrease.
To address above issues, we propose a novel information propagation predication model named DropMessage Hypergraph Attention Network (DMHANT) for information propagation prediction. Specifically, we not only takes advantage of the friendship relationship by using GNN, but also construct a hypergraph based on the cascade sequence. To obtain user preferences dynamically, we divide the diffusion hypergraph into multiple subgraphs according to the time stamps, develop hypergraph attention networks to explicitly learn complete interactions, and adopt a gated fusion strategy to connect the subgraphs embedding. Furthermore, due to the prominence of self-attention mechanisms in dealing with sequential tasks,24–26 we choose two Multi-Head Self-Attention modules to efficiently capture the friendship and subgraphs feature interactions within cascades. Finally, we can obtain the predictive representation through a postfusion strategy. In addition, a new drop immediately method DropMessage is added to increases the robustness of the model.
The main contributions of our work can be summarized as follows:
To take full advantages of global dependencies of users and cascades, we construct a hypergraph based on the cascade sequence and analyze the hypergraph to deeply learn the dynamic correlation between users and cascades. While learning the cascade sequence, we introduce the social relationship graph and design a hypergraph attention network to help the model dynamically learn the importance of different parts of the hypergraph and social relationship graph data and adjust the weights accordingly to improve the model’s performance and generalization ability. To enhance the robustness of the model, we add a new drop immediately method DropMessage which directly performs dropping operations on message matrix.
Related Work
Recently, many technologies have been proposed to tackle information propagation prediction, including independent cascade (IC)-based, embedding-based, and deep-learning-based approaches.
Independent Cascade-based approach
Lots of cascade propagation models are based on the assumptions from the IC approaches, and some extensions have been proposed by incorporating more information, such as continuous timestamps, 27 user profiles, 28 and the influence of nodes. Chen et al. 29 proposed a modification of the IC model called the weighted IC model, which takes into account the strength of the connections between nodes in the network. Several techniques have explored the integration of additional information in cascade modeling. Wang et al. 30 introduced an emotion-based IC model to capture dynamics of information spread in online social media, specifically focusing on the context of emotion contagion.
However, pairwise independence oversimplifies the intricate nature of diffusion process, leading to the problem of poor performance when applied to real datasets.
Embedding-based approach
Embedding-based approaches can fully utilize representation learning techniques. Xu et al. 31 analyzed the main factors influencing users’ retweeting behavior on Twitter and trained classification models using publisher features, posting content features, and retweeter features and found that the social network characteristics of publishers and retweeters were most important in influencing retweeting behavior. Li et al. 32 proposed an engagement ranking model based on adoption probability, which estimates the adoption probability of each user for different topic tags and gives actual participants a higher dynamic weights in learning to predict which users will be activated to generate propagation behavior early on. Wang et al. 33 introduced a model named Diffusion-Network Representation Learning (DNRL) which learns user representations simultaneously from social network and diffusion sequence.
Nevertheless, embedding-based approaches did not consider the modeling of sequential information in cascades.
Deep learning-based approach
With successful applications in various areas of deep learning, many deep learning-based methods have shown remarkable potential in modeling information diffusion. Wang et al. 34 proposed an attentional recurrent neural network to improve propagation prediction accuracy by incorporating social network structure information into propagation sequence modeling. Zhou et al. 35 introduced a hierarchical cascade framework that combines multiscale modeling and user representation learning.
Recently, some graph networks have been proposed to effectively capture the dependencies in cascading sequences of information diffusion. Qiu et al. 20 used graph attention neural networks in propagation behavior prediction and proposed the DeepInf framework, which takes the user’s egocentric network as input and fuses propagation features into convolutional GNNs and attention networks. Recently, Feng et al. 36 introduced a hypergraph neural network that utilizes a Chebyshev expansion of the simple graph Laplacian. Bai et al. 37 then introduced attention mechanism to hypergraph. Xie et al. 38 introduced an independent asymmetrical embedding model that aims to embed each individual into a single latent influence space and multiple latent susceptibility spaces. Wang et al. 39 propose a cascade-enhanced (CE)-GCN, effectively exploiting collaborative patterns over cascades to improve the prediction of future propagation.
These approaches typically ignore the global dependencies of users and cascades, which is insufficient to characterize their dynamic interaction preferences, thus limiting the performance of prediction. Moreover, the existing method model is poor in solving the problem of model robustness.
Preliminaries
Construction of social graph
As users’ propagation behavior is consistently influenced by personal interests, previous behavior and the external environment, we will construct the friendship graph and diffusion hypergraphs firstly which are essential components for predicting diffusion.
Social graph can be represented as
Construction of diffusion hypergraphs
To enhance the global dependencies of users and to facilitate taking the time factor into account, we construct the cascade sequence as a hypergraph, as shown in Figure 2. The cascades sequence is represented as
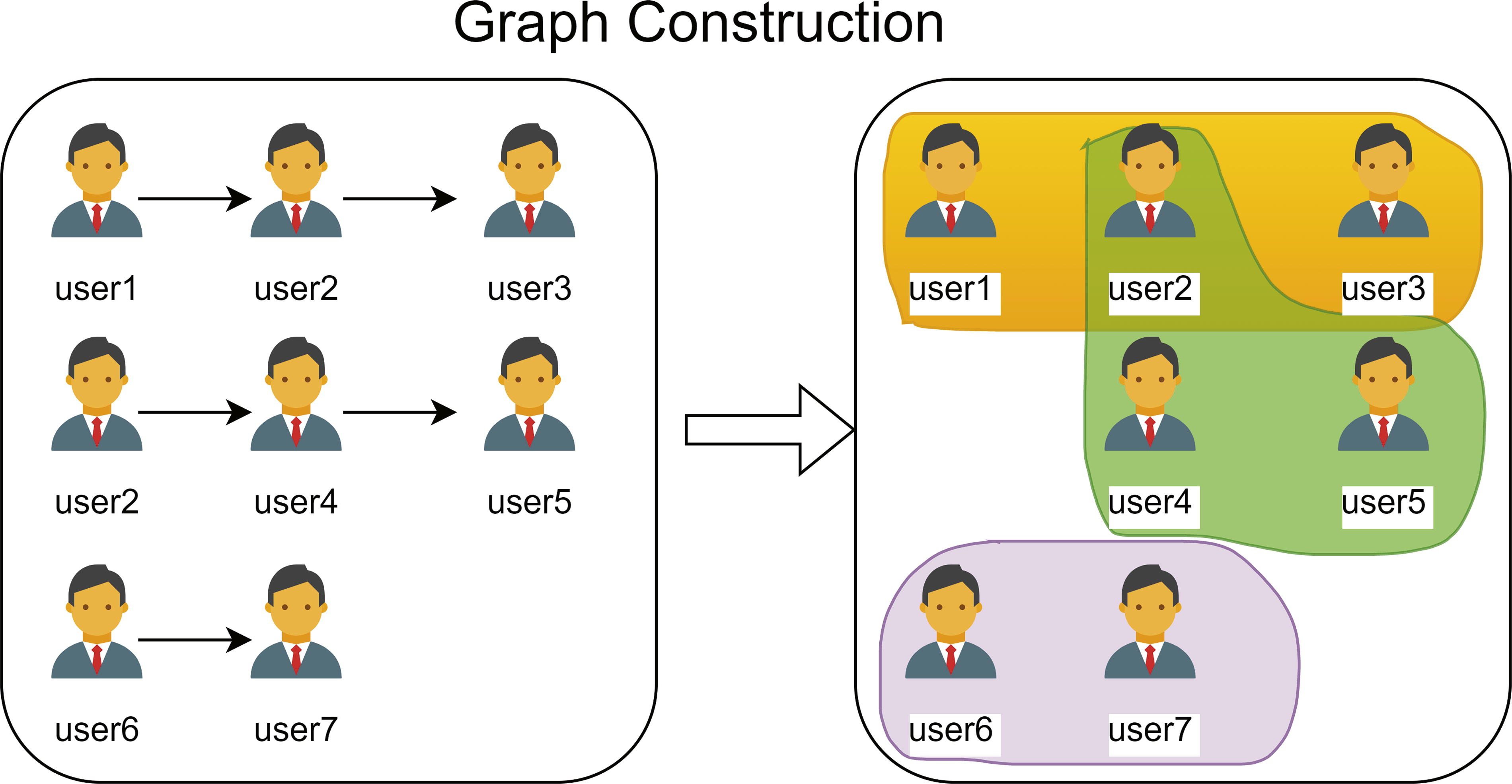
Hypergraph construction process.
The node–hyperedge relationship of each subgraph is independent, which means that the hyperedges that appeared in the previous hypergraph will not appear in other hypergraphs. If ui participates in em during tth timestamp, the connection between node ui and em will only exist in hypergraph
Problem formulation
Based on the above introductions, we can describe the prediction task as: given a friendship graph
The Proposed Model
In this section, we will introduce DMHANT in detail. The overall architecture of our model contains four major components, as shown in Figure 3: (1) GCN module that learns users’ social relationship. (2) Sequential Hypergraph Attention Network (HANT) module which obtains interaction-based user and cascade embeddings. (3) Multi-Head Self-Attention module that captures the context interaction within the cascade. (4) Interaction Prediction module that calculates infection probability of candidates. In the following subsections, we will provide an elaborate introduction to each component of our framework.
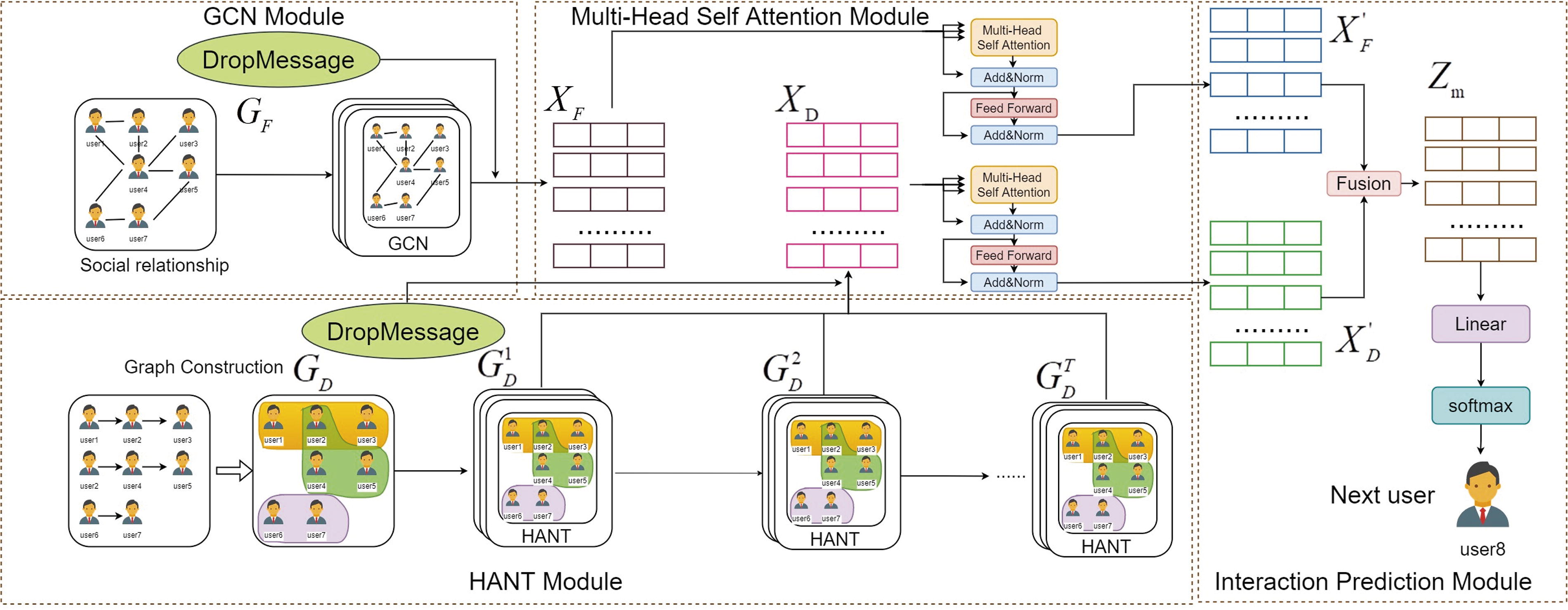
Four modules of DMHANT: (1) users’ social relation is learned by GCN Module; (2) user dynamic interaction is learned by sequential HANT Module; (3) contextual interaction information within a cascade is learned by Multi-Head Self-Attention Module; (4) the final results are obtained by Interaction Prediction module. DMHANT, DropMessage Hypergraph Attention Network; GCN, graph convolutional network; HANT, Hypergraph Attention Network.
GCN module
The social relationship networks can express users’ static dependency. By introducing users’ social networks, it can facilitate the extraction of effective information among users and also alleviate the cold start problem to some extent. We can further obtain user preferences by learning their neighborhood features even if no user participated in a cascade sequence.
Considering the relative stability of the user’s social relationship, we use a GCN to learn user’s social network structure. Given a social relationship graph
Where the initial user embeddings
HANT module
As users’ friendships graph may not accurately capture their global dependencies, we additionally construct sequential hypergraphs based on diffusion cascades in our framework and adopt sequential attention networks to effectively learn the dynamic timing characteristics and user interactions at the cascade level. The process of HANT is shown in Figure 4. All modules contain two aggregations.
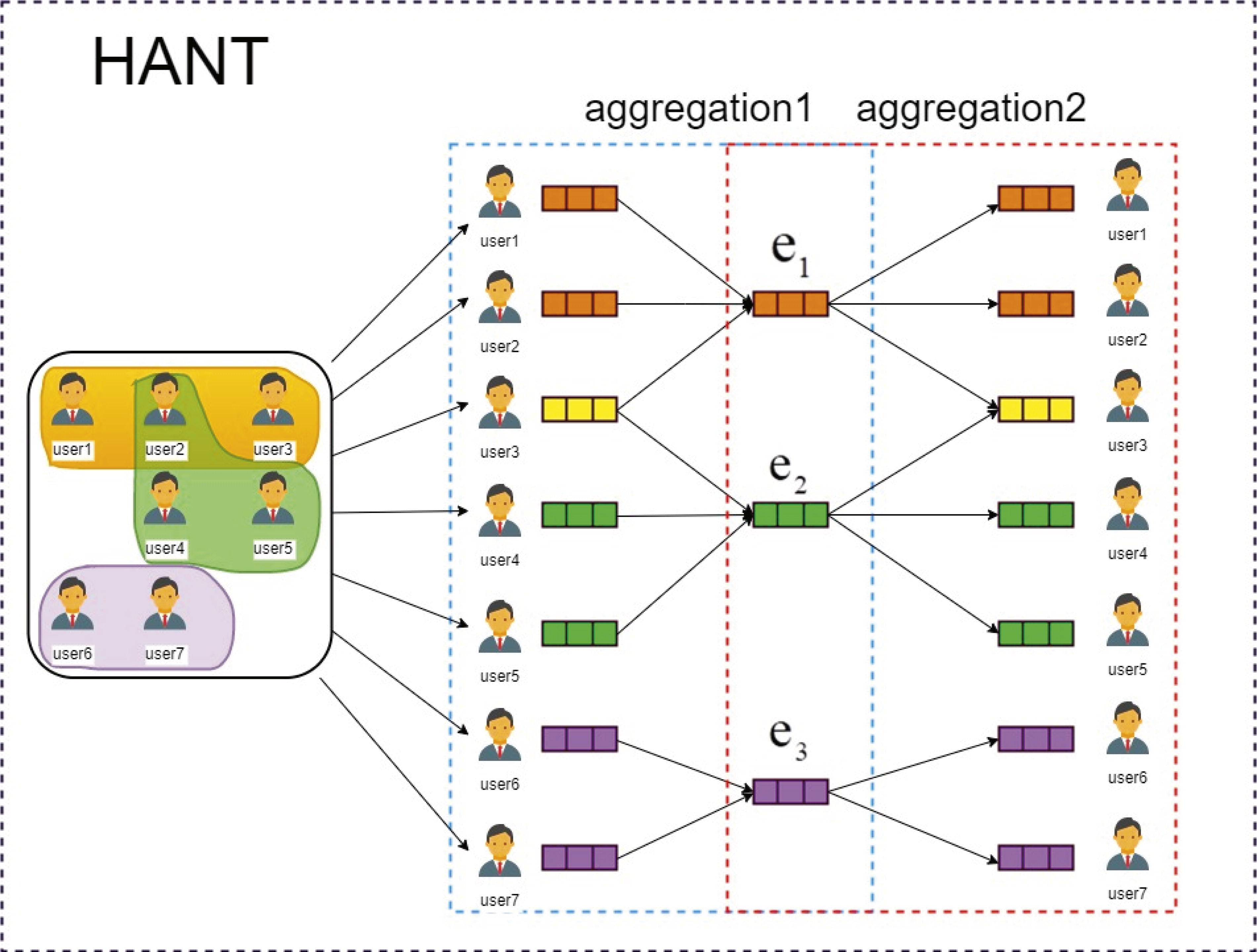
Feature learning process for hypergraphs: (1) Nodes-to-hyperedge aggregation; (2) hyperedges-to-node aggregation; (3) Sequential HGATs with Fusion.
Nodes-to-hyperedge aggregation
The first aggregation is nodes-to-hyperedge aggregation, which aims to learn the representation of hyperedge. Given a hypergraph
Where σ denotes an activation function
However, the traditional method of calculating attention coefficients requires prior knowledge of each vector feature. Here we cannot know the feature representation of the hyperedges in advance. Meanwhile, subhypergraph only contains the user cascade interaction information for the current time interval, which aims to learn the short-term preferences of users but will inevitably result in· information loss. Therefore, since the root node can partially reflect the content of the cascade, we compute the attention scores of other nodes by using the root features replacing the hyperedges for each hypergraph, that is:
Where
Hyperedges-to-node aggregation
On the basis of obtaining representations of hyperedges, we choose to train another aggregator to integrate all hyperedges
Where σ represents an activation function. After passing the L-layer HANT, we finally get the dynamic embedded post features of users
Sequential HGATs with fusion
According to the previous definition of subhypergraphs, each hypergraph only includes information at short intervals, so learning a single hypergraph cannot accurately describe the dynamic changes in user preferences. Therefore, we develop a fusion strategy to connect them in a chronological order. The propagation of negative news can be viewed as a Markov process,40–43
meaning that the state of the next moment up to the current state is related to the state of the previous moment, independent of the state of the previous moment. Therefore, when calculating the features of each subgraph, we weight the initial representation of each user and the output of the tth time interval using the attention mechanism as the input to the next interval, formally:
Where σ represents the activation function
DropMessage
GNNs are effective tools for graph representation learning but currently have some limitations such as nonrobustness. Here we adopt a novel random dropping strategy called DropMessage, which performs dropping operations directly on the message matrix, allowing for selective removal of a certain fraction of messages during GNN computations.
Message Matrix
A basic idea of existing GNN models is to adopt the message-passing framework, where each node receive messages from its neighbors and simultaneously transmit messages to its neighbors. When applying message-passing GNNs on the graph, we gather all the propagated messages into a message matrix
Where
DropMessage Method
Traditional Dropout method drops the elements
DropMessage strategy performs random masking directly on the message matrix
Where
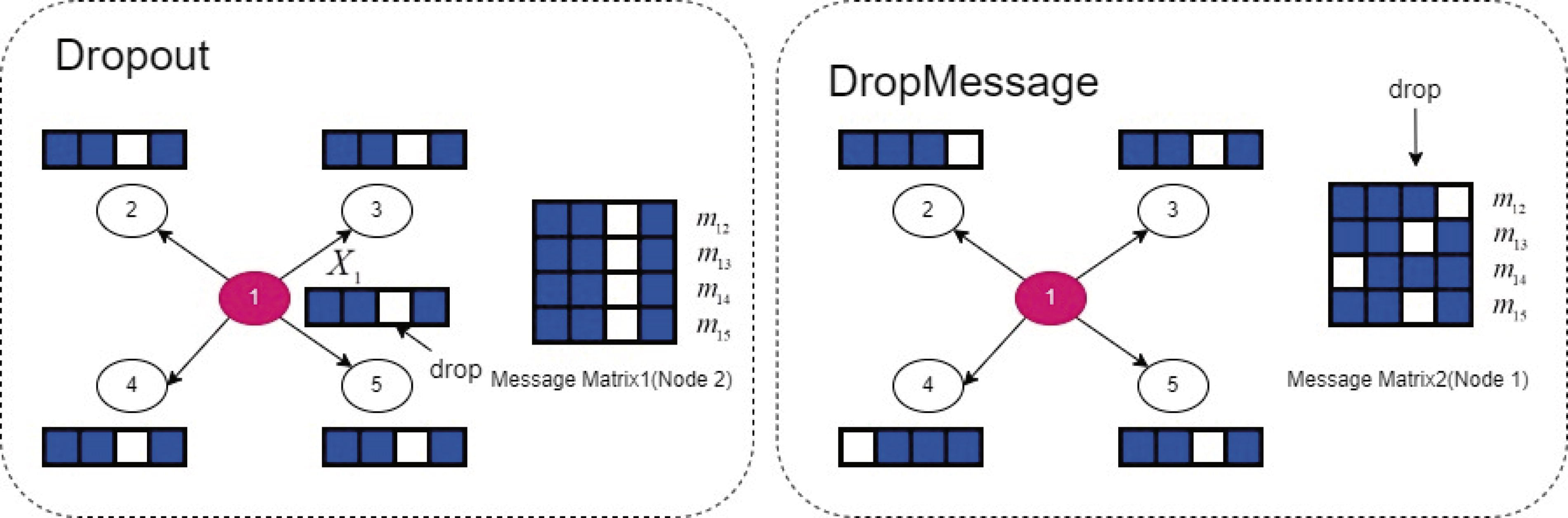
The difference between DropMessage and Dropout: Dropout drops the elements in the feature matrix, while DropMessage strategy directly performs random dropping on the message matrix.
Multi-Head Self-Attention module
Graph representation-based learning alone cannot capture contextual interaction information within a cascade, we adopt two Multi-Head Self-Attention modules to efficiently extract the static and dynamic feature interactions within cascades. For static learning, which is introduced in GCN module, given the obtained user embedding
Where
Where
Where σ is RuLU activation function,
Here we get social relationship representation
Interaction Prediction Module
Fusion
In order to simultaneously integrate the vector representations learned from social relationship representation
Where
Prediction
As we get final representation
Where
Where θ represents all learnable parameters in the model. If the user ui participates in cascade cm at step j,
The whole process of DMHANT is shown in Algorithm 1.
Experiments
Datasets
To investigate the generalization of DMHANT, we collect datasets from various social platforms, specifically Douban and from Q&A websites such as Android and Christianity. The specific details regarding the sampled data are provided in Table 1.
Dataset
Douban: 44 The dataset obtained is from a social website consists of information where users share their book or movie reading statuses and follow the statuses of other users. The friendship relation in this dataset is established based on the co-occurrence relation among users. This implies that users who frequently share similar interests or engage in similar activities are considered to have a friendship relation.
Android: 45 A dataset collected from a Stack Exchanges, a community websites. The friendship relation is constructed by users’ interaction on various channels, such as questioning, answering.
Christianity: 45 The dataset collected from community Q&A websites contains the user friendship network as well as cascading interactions that are related to the Christian theme.
Baselines
We will compare DMHANT with several information propagation prediction models:
DeepDiffuse
46
uses RNN and attention mechanism to predict when the next infection will occur and who will be infected. NDM
47
, neural diffusion model employs self-attention mechanism and CNNs to learn cascades effectively, incorporates relaxed independence assumptions to alleviate long-term dependency. FOREST
21
models GNNs and RNN-based method to obtain users’ social relationships and learn cascades context. Inf-VAE
45
, influence variational autoencoder introduces a variational autoencoder framework that jointly embed social homophily through temporal influence and GNNs. DyHGCN
22
constructs heterogeneous graphs which encompass both diffusion relations and social relationship of users, jointly encoding diffusion cascades and social networks through GCN. CE-GCN
39
effectively leverages collaborative patterns within cascades to improve the performance of prediction of next user. H-Diffu
48
encodes social graph and information diffusion cascades into two latent hyperbolic spaces, each with its own trainable curvature. Additionally, it introduces a co-attention mechanism to effectively capture the processes of diffusion cascades using positional embeddings.
Evaluation settings
Based on the problem formulation above, we can regard our prediction task as a retrieval problem. Therefore, in line with previous studies, 47 we employ Mean Average Precision on top k(MAP@k) and Hits score on top K (Hits@k) as evaluation metrics. These metrics consider both the occurrence and ranking position of ground-truth users in the predicted list. In our experiments, we evaluate MAP@K and Hits@K with K values of 10, 50, and 100, respectively.
Implementation details
Our experiments are done on an Intel(R) Core(TM) i5-7400 CPU @ 2* 3.00 GHz, 8.0GB RAM, Windows 7 and a single card GPU connected to a server NVIDIA RTX3090. The software is implemented in Python 3.7.10, while using the Deep Graph Library, the PyTorch framework on the backend, and Adam as the model optimizer.
For each dataset, we randomly select 80% of the cascades sequences for training, 10% for validation, and the remaining 10% are reserved for testing.
We set the maximum length of cascade to 200. For our model DMHANT, the batch size is set to 64, the dimension of embedding is 64, and the learning rate is 0.001. In order to maintain high computational efficiency, the number of multi-headed attention heads K is set to 8. The number of subhypergraphs is also set to 8. To fully train the parameters of the model, training batch is set to 100 and Batch size is 64, with each Batch including cascades sequence and friendship graph.
Performance of model
We compare DMHANT with several baselines on three datasets and the experimental results are shown in Tables 2 and 3. Based on these, we can make the following analysis.
Experimental results comparison on 3 dataset (%) (Hits@k scores for K = 10, 50, 100)
The bolded data indicates the most effective outcomes.
Experimental results comparison on 3 dataset (%) (MAP@k scores for K = 10, 50, 100)
The bolded data indicates the most effective outcomes.
We can find that DMHANT significantly and outperforms consistently all baseline methods on three real datasets. Compared to the second best model H-Diffu, DMHANT construct a hypergraph based on the cascade sequence to dynamically learn its global features and uses DropMessage Replacing traditional dropout method, thus reaching up to 2.14% improvement in Hits@100 score and 1.23% in MAP@100 score than DyHGCN. The improvement in these metrics demonstrates the effectiveness of DMHANT.
The methods that utilize user social relations (FOREST, DyHGCN, CE-GCN, H-Diffu, and DMHANT) generally perform better than cascades-based approaches (DeepDiffuse and NDM). since they use traditional neural networks, but not GNNs that can mine graph structures. In terms of feature mining, they only exploit the propagation cascade feature and failed to incorporate the relationship graph between users, which proves the validity of social relationship.
DMHANT, CE-GCN, and H-Diffu consider users’ global interactions and ultimately achieve excellent results, which confirms our theory that users’ interaction preferences can be learned both from their historical behavior and social relationship.
Overall, the Android dataset is worse than the other two datasets and the model improvement is relatively small. The reason may be that the learning of users’ intimate relationships in Douban and Christianity can effectively describe their behavior, in which case the introduction of construction of hypergraphs may not help much.
Robustness of our model
To verify the robustness of DMHANT, we also conduct experiments through handling perturbed graphs. Specifically, we randomly add a certain ratio of edges (0%, 10%, 20%, 30%) into the both relationship graph and hypergraph. In particular, to demonstrate the robustness of DropMessage strategic, we develop a set of comparison experiments that adopt traditional dropout method. The results are displayed in Figure 6. It can be seen that the Hit@100 of all methods decrease as the side ratio increases, but our model DMHANT consistently outperforms other methods in noisy situations. As for the comparison experiments that adopt traditional dropout method, the results indicate that the DropMessage strengthen the robustness of GNN models. This means that even if our dataset is perturbed, our model still gives a high accuracy rate. Besides, the reason for the poor performance of all models on Android may be due to the relative sparsity of the dataset.
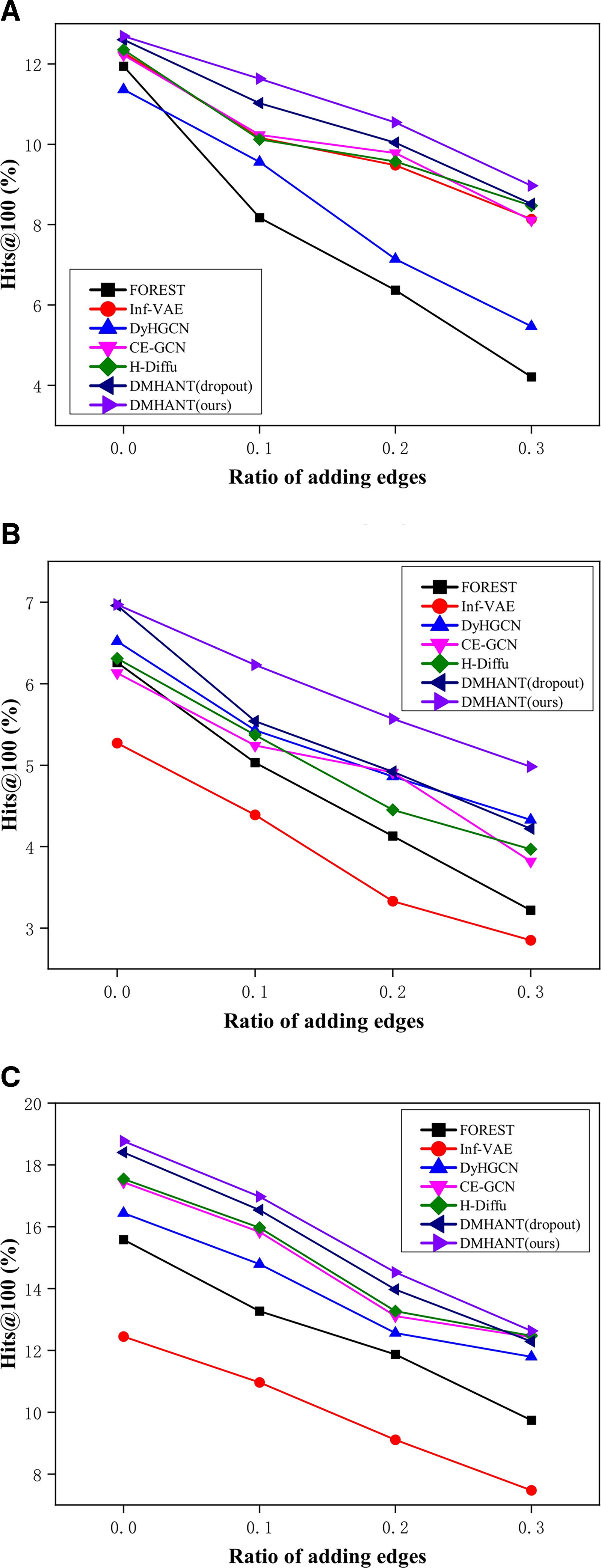
Robustness study of our DMHANT.
Ablation study
We conduct ablation studies and compare with different variants of DMHANT on three datasets to evaluate the contribution of each part:
As shown in Tables 4 and 5, DMHANT achieves the best performance compared to any of its variants. Specifically, from the results, first, there is little difference in the experimental performance between the two, whether the GCN module or the HANT module is removed, indicating the validity of two types of global dependencies. Second, experimental performance of direct weighted average strategy is significantly inferior to that of using the fusion strategy on three datasets, which is due to the fact that the Fusion strategy uses an attention mechanism that fully considers the weight of both. Third, the single GCN module and the single HANT module outperform the average weighting of both, indicating that the two modules should be fused with a certain weighting to ensure the benefits of the model, while illustrating the importance of the attention mechanism introduced by the Fusion strategy.
Ablation study of DMHANT (%) (Hits@k scores for K = 10, 50, 100)
The bolded data indicates the most effective outcomes.
Ablation study of DMHANT (%) (MAP@k scores for K = 10, 50, 100)
The bolded data indicates the most effective outcomes.
Parameters sensitivity
To investigate the effect of some parameters, we show some Hits@100 results in Figure 7.
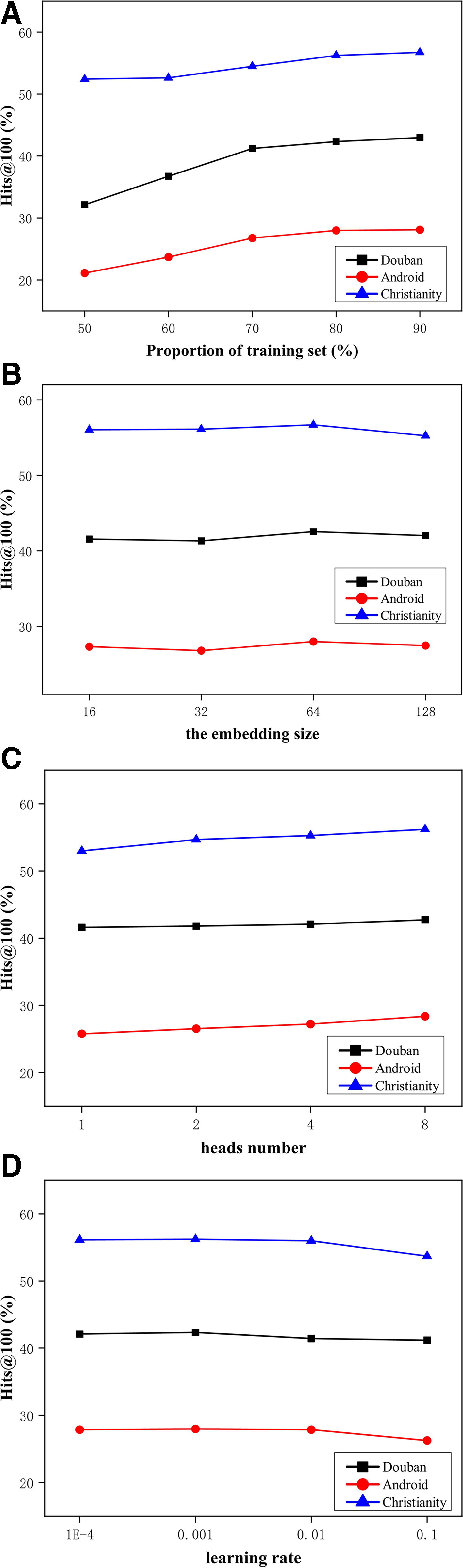
Parameters Sensitivity study of our DMHANT.
Figure 7a illustrates the impact of the proportion of the training set. As the training ratio increases, the effectiveness of the model improves. This improvement may also be attributed to the reduction in the size of the test set, which results in less data available for testing and consequently increases the Hits@100 metric. It is worth noting that the model effect does not change much when the ratio changes from 70 to 90, which also indicates robustness of the model.
Figure 7b plots the effect of the number of dimensions. Overall, the effect improves as dimensions increases because higher dimensions can better represent the influence of interrelationships. In addition, the highest scores for all three evaluated datasets are obtained when the size is 64. Therefore, we can empirically set the default number of dimensions to 64.
In Figure 7c, we plot the influence of number of heads in Multi-Head Self-Attention module. We observed that the model performance improves as the number of heads increases, which also indicates that the multi-head attention mechanism acts as an integration to improve the overfitting problem of the model.
In Figure 7d, we verify the relationships between model performance and learning rate, we observe that the model presents a small peaks of performance when the learning rate is around 0.001 and 0.01. Therefore, the selection of a suitable learning rate has an significant impact on the model.
Conclusion
This article investigates the GNN-based information propagation prediction. Aiming at how to collect more global dependencies and dynamic interaction preferences feature from observed network as well as how to solve poor robustness, we presented a novel information propagation prediction model named DMHANT, which jointly learns users’ social relationships and diffusion cascade representation. Through GCN module, HANT module, Muti-Head Self-Attention module, and Interaction Prediction Module, our model fully captures dynamic interactions. In addition, a new drop immediately method DropMessage is added to increases the robustness of our model. Experiments on three real-world datasets demonstrate the effectiveness and robustness of proposed model.
For future works, we will consider incorporating the content of the propagated information and the user’s preference for information content to further explore the features in it and improve the model performance.
Footnotes
Acknowledgments
The authors thank the editors and the anonymous reviewers for their efforts.
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This research project was supported by Major Science and Technology Projects in Henan Province under 221100210100.