
Abstract
Cloud resource scheduling is one of the most significant tasks in the field of big data, which is a combinatorial optimization problem in essence. Scheduling strategies based on meta-heuristic algorithms (MAs) are often chosen to deal with this topic. However, MAs are prone to falling into local optima leading to decreasing quality of the allocation scheme. Algorithms with good global search ability are needed to map available cloud resources to the requirements of the task. Honey Badger Algorithm (HBA) is a newly proposed algorithm with strong search ability. In order to further improve scheduling performance, an Improved Honey Badger Algorithm (IHBA), which combines two local search strategies and a new fitness function, is proposed in this article. IHBA is compared with 6 MAs in four scale load tasks. The comparative simulation results obtained reveal that the proposed algorithm performs better than other algorithms involved in the article. IHBA enhances the diversity of algorithm populations, expands the individual’s random search range, and prevents the algorithm from falling into local optima while effectively achieving resource load balancing.
Introduction
Over the last few decades, big data technology has drawn the interest of numerous scholars and industries. A large amount of data is generated in a short time and cannot be processed by a single computer, requiring a distributed architecture. With the rapid development of the Internet of Things and big data technology, the ever-expanding demand for computility by enterprises and individuals has prompted the establishment of advanced techniques to deal with it.1,2 One such innovation that can assist in the rapid configuration of interconnected data centers and save time is cloud computing.3,4 Cloud computing relies on its distributed processing to enable large amounts of data on the internet to be intercommunicated, controlled, and redistributed. It relies on the concept of computility sharing, which can deploy local projects to the cloud for other users to access. In cloud computing, the resource scheduler is designed to distribute resources to applications properly so that a scheduling algorithm can be used to maximize a variety of quality of service (QoS) factors, including expenses, the efficiency of resources, utilization of energy, etc. 5 Cloud resources are diverse and limited. If not arranged properly, the cloud processes large amounts of data, resulting in decreased performance and the issue of load imbalance. 6 Therefore, it has become an urgent challenge to develop an efficient scheduling algorithm under the assumption of satisfying the user’s QoS. Li et al. 7 proposed optimizing makespan and resource utilization algorithm for multi-DNN (deep neural networks) training. Linear Scaling Rule is used to regulate the learning rate during model training and a new GPU reuse scheme is introduced to adequately utilize the idle resources. The fault-tolerant mechanism of scheduling cannot be ignored while improving resource utilization. Three fault-tolerant scheduling mechanisms and a resource adjustment strategy are proposed in the scheduling algorithm for scientific workflows, which could enhance resource utilization even in the emergence of resource failure. 8 Traditional scheduling algorithms develop relational assignment tables of resources and tasks by linear combination, roulette method, or specific rules. Assignment tables have made the tasks allocated orderly among virtual machines achieving the scheduling of resources. Common algorithms include Round Robin (RR), 9 Weighted Round Robin, 10 Min-Min, and Min-Max. 11 Some scholars have made innovations based on traditional scheduling algorithms. Shafi et al. 12 proposed an enhanced CPU scheduling algorithm named Amended Dynamic Round Robin, which can reduce processing time without affecting the favorable characteristics of the traditional RR, resulting in higher efficiency. Lin et al. 13 proposed a main resource-balancing algorithm and a time-balancing algorithm. Tasks are sorted by time cost or relative load and then assigned to the specified virtual machines (VMs). Two parameters that influence the preprocess results are provided for users to control the algorithms. Sharma et al. 14 proposed a Median Average Round Robin algorithm. The median and average of the burst time of each phase are used to propose a dynamic time quantum for the system. Zhou et al. 15 presented the Min-Max algorithm to effectively integrate scattered tasks. The task set with a small task volume and large task amount is bundled into a task to apply for resources to the platform. It can slow down the server load situation.
Traditional resource scheduling algorithms have their own advantages in different situations. However, it is difficult to effectively divert the server load for large-scale tasks. The complexity of the algorithm calculation is high, and the additional computation generated will increase the burden of the platform. Meta-heuristic algorithms (MAs) are considered simple to operate and easy to implement and have been combined with advanced technologies such as blockchain to form a new paradigm in many actual optimization problems.16,17 The approximate solutions generated by using meta-heuristic to solve NP problems are near to the global optimal solution. Based on the superiority, MAs are commonly used for resource scheduling tasks. 18 Zhang et al. 19 proposed a load-balancing algorithm based on an improved cuckoo bird search. The algorithm introduces chaos mutation and reverse learning mechanisms to search for the optimal load allocation weights. Zhou et al. 20 added a growth stage in genetic algorithms. Local search algorithms and random multi-weight approaches are used as the growth path, providing benefits in growth and dimension reduction strategies. Manikandan et al. 21 added four mutation factors in the bee algorithm and introduced nonlinear weight parameters in the standard whale optimization algorithm, resulting in a significant reduction in completion time. Tang et al. 22 proposed an enhanced particle swarm optimization scheduling technique that uses a random matrix of integers to describe its location and possible task scheduling solutions, resulting in the total cost of cloud services optimization. Krishnadoss et al. 23 proposed an improved seagull optimization algorithm, which weighs the cost value and efficiency of the scheduling. Xiong et al. 24 investigated the cloud data center scheduling problem, combining Johnson’s approach with the genetic algorithm, designing a two-stage task scheduling, and optimizing the makespan of each virtual machine. Manikandan et al. 25 presented an optimal solution for scheduling and resource allocation utilizing the hybrid algorithm (BWFSO). Fuzzy c-means are used to cluster VMs, the fish swarm technique is used for job scheduling, and black widow optimization is used for resource allocation. Loheswaran et al. 26 proposed an improved Fruit Fly Optimization Algorithm for job scheduling process optimization. A basic approach is put forward to allocate the tasks to multiple computing resources. Chen et al. 27 presented an improved methodology called Improved Whale Optimization Algorithm (WOA) for Cloud task scheduling that aimed to enhance the WOA-based method’s optimal solution search capacity.
The above cloud resource scheduling method based on MAs has advantages in various indicators such as cost and time parameters. However, some MAs are prone to premature convergence. Issues of imbalanced local and global search strategies also exist, and the ideal resource allocation scheme is difficult to get. An algorithm with good global optimization capability is an urgent requirement for cloud resource scheduling tasks. The basic Honey Badger Algorithm (HBA) has been noted for its good optimization capabilities. It lacks strategies to escape from local solutions, which results in poor convergence performance and weak global balance capability. In this work, a multi-strategy fused Improved Honey Badger Algorithm (IHBA) for task scheduling optimization has been described. It enhances the global search capability and overall robustness. IHBA combines two local search strategies and proposes a new fitness function. It was compared with 6 MAs in four load scaling tasks. Simulation results show that IHBA outperforms classical intelligent optimization algorithms. Achieving resource load balancing on the cloud platform can be accomplished successfully. The major contributions of this article are summarized as follows.
Mutation factors are introduced to enhance the algorithm’s adaptability to different tasks, and an improved position update strategy is proposed to control the population search range. Two local search strategies and a new fitness function are proposed to accelerate the convergence speed of the task. IHBA is compared with 6 MAs such as ant colony optimization (ACO), genetic algorithm (GA), gray wolf optimization (GWO), HBA, particle swarm optimization (PSO), and slime mould algorithm (SMA) in four different scale load tasks. Experiments and boxplot analysis show that IHBA has superiority and practicality.
The rest of the article is structured as follows. An overview of the cloud resource scheduling model and the basic HBA is introduced in the Related Work section. The Multi-Strategy Fusion Honey Badger Algorithm section outlines IHBA using multi-strategies fusion. The cloud resource scheduling strategy is presented in the Proposed Cloud Resource Scheduling Strategy section. In the Simulation Experiments and Analysis section, the proposed algorithm and other same-type algorithms are compared in four different scale tasks. Finally, the Conclusion and Future Work section concludes the work and indicates several future research directions.
Related Work
Meeting computability requirements through a cloud platform for resource sharing is a critical task, with resource scheduling playing a crucial role in the control and application of big data. To address this task, various MAs have been applied to cloud resource scheduling, leading to good outcomes. A cloud resource scheduling model and the basic HBA are described in this section.
Cloud resource scheduling models
Cloud resource scheduling is fundamentally a combinatorial optimization problem. As task requirements increase, the server needs to allocate tasks more precisely to the specified pool of resources. To achieve this, all procedures can be executed on a single virtual platform (Fig. 1), with resources distributed among virtual machines. 28 Based on the task requirements, one or more virtual machines can be selected, and execution rights can be transferred to the chosen virtual machine. In resource scheduling, there are N virtual machines and M tasks. Multiple tasks can be executed concurrently by a virtual machine, subject to limitations on the number of concurrent tasks, memory size, and storage space. Each task can only be executed by one virtual machine, and there is no communication between virtual machines. The goal of resource scheduling is to construct a resource load distribution model that balances the load of all virtual machines as much as possible.
Tasks and VMs are encoded according to id(vmid = {1,2,3…N}) and id(taskid = {1,2,3…M}), encoded as a one-to-many relationship. The VM remaining memory space (RMS), the VM remaining available concurrency (RAC), and the VM remaining storage space (RSS) are considered, the objective function is shown in the equation below.
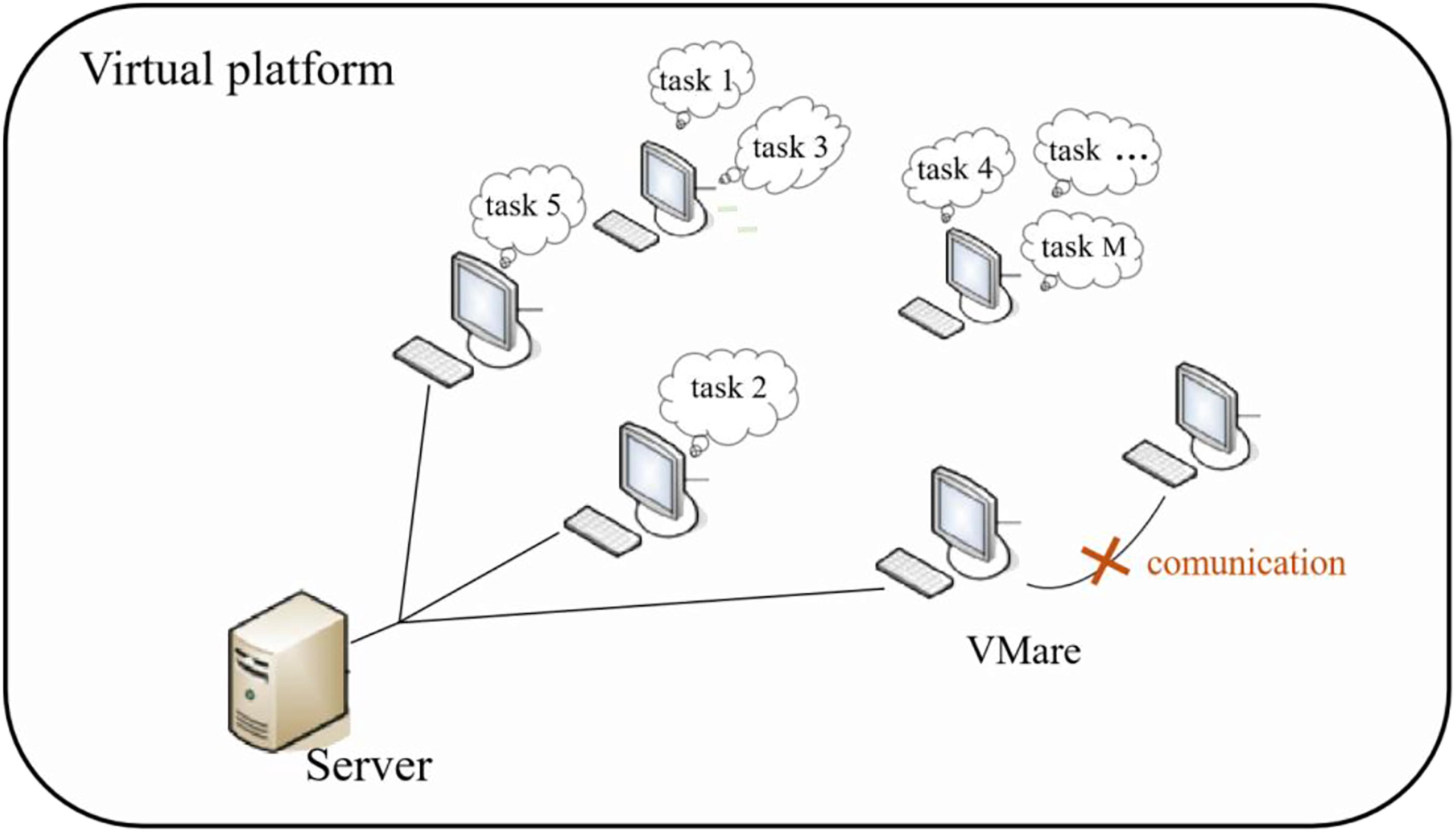
Relationship architecture.
Basic HBA
MAs have gained widespread attention in recent years due to the increased efficiency and performance.
29
A brand-new meta-heuristic optimization algorithm called the HBA simulates the foraging behavior of honey badgers. HBA comprises two stages the digging phase and the honey phase. During the digging stage, the population of honey badgers is guided by the smell of bees or wanders around the bees. During the honey phase, the population is directly attracted to the bees until honey badgers locate the honeycomb.
30
The population location update in the two modes is determined by Eq. (2) and Eq. (3), respectively.
Where
The HBA is a global optimization algorithm that strikes a balance between research and exploitation, enabling it to avoid local optima. Chen et al. 31 employed an HBA-based energy management strategy to enhance the performance of pressure-retarded osmosis and photovoltaic/thermal systems by maximizing multi-variable functions. Ashraf et al. 32 applied HBA to optimally determine the seven unknown parameters of the steady-state model for proton exchange membrane fuel cells. In summary, HBA is a straightforward and practical optimization algorithm with broad applications, offering researchers a novel solution for addressing optimization problems.
Multi-Strategy Fusion HBA
The basic HBA suffers from a lack of coordination between global search ability and local development ability. In the later stages of algorithm search, the population loses diversity and easily falls into local optima. In order to improve the performance of the algorithm, an improved algorithm called the multi-strategy fusion IHBA has been proposed. Composite mutation factors are added early in the algorithm search to strengthen the global random walkability of the population. In the population location update mechanism, the HBA’s capacity to optimize a system globally is retained, and the random search range of individuals is expanded by using a double-branching structure. The population of algorithms is more diverse and the fall into local optima is avoided.
The composite mutation factors
The complexity of the high-dimensional multi-peak task increases dramatically with the increase in data dimensionality, which poses a great challenge to the algorithm. In response to this phenomenon, composite mutation factors are introduced to strengthen the global random wandering ability of the population by exploiting the characteristics of randomness and nonlinearity. The expressions are given in Eq. (4).
Where
An improved swarm-based strategy
In the basic HBA, the algorithm converges quickly and premature convergence is likely to occur. Without compromising the theoretical foundation of the original HBA for optimization, this article divides the optimization phases into digging and honey. An improved double-branching population position update mechanism is proposed to enhance population diversity and balance the two phases. The specific population location update mechanism is given in Eq. (5) and Eq. (6).
It is clear that Eq. (5) is formed by compounding Eq. (2) and Eq. (4). It preserves the honey badger global optimization mechanism while expanding the search range and enhancing the randomness. When the population is evenly distributed in the search space, the distance
Proposed Cloud Resource Scheduling Strategy
IHBA proposed in this article is an MA outstanding in solving continuous type benchmark functions. A reasonable and efficient allocation scheme for the platform can be provided by IHBA’s excellent optimization ability. This section is designed to describe in detail how the virtual machines and tasks complete the assigned tasks.
Representation of the problem solution
Through random initialization, the relationship table between virtual machines and tasks is created. The original population of individuals is thereafter built. All virtual machines are queried at the beginning of the task assignment process to see if the tasks could be taken. Virtual machines that can carry the task will be added to the pending queue. If the queue is not empty, a pair of VMs and tasks are randomly selected and added to the relationship table to generate the initial individuals. Otherwise, all tasks will be reinitialized until all tasks have been assigned. For example, when there are five tasks and three VMs, the tasks are executed in task order, the sequence of VMs available to execute the task is found, and a VM number is randomly selected and added to the relationship table. The initialization procedure is depicted in Figure 2 and continues until all tasks are assigned to VMs.

The process of initialization.
An initial solution is generated following the relationship table’s creation. The created relationship table is a 1*M matrix with each element representing a task in a virtual machine in which there are N numbers, ranging from 1 to N. A targeted encoding is created in order to apply this optimization technique to discrete issues since the IHBA proposed is applicable to continuous jobs. The discrete initial solution will be generated by IHBA using the specified rules and the solution will be discretized using rounding. At the same time, a boundary constraint is applied to the point locations that are beyond the boundary.
In Figure 3, there are six tasks in the initial solution, with the first task in VM 1, the second task in VM 10, and the third task in VM 3. An intermediate solution is obtained using the IHBA optimization sequence, which is mapped to the generated solution after rounding and boundary constraints. Both the first and second tasks are transferred to VM 2 and VM 8, respectively.

Code rules.
The fitness function
In order to measure the load condition of each VM, IHBA needs to evaluate different individual states based on the fitness function. Individual load condition (ILC) intermediate variables are created in this part to evaluate the RMS size, remaining number of available concurrents, and RSS size of individual VMs.
where USM indicates the used space of the VM memory, NCU indicates the number of concurrency used by the VM, and USS indicates the used storage space of the virtual machine. The algorithmic load-balancing capability is evaluated in Eq. (1) at the overall level. It is evaluated using individual VMs in Eq. (7). The overall fitness function is generated by combining Eq. (1) and Eq. (7), the following equation illustrates this relationship.
Where
Algorithm implementation
A technique of optimization is designed that does not rely on the fitness function or variance factor in order to speed up the algorithm’s optimization-seeking process. The bottom bound of the solving capabilities of the algorithm can be improved by finding a solution of higher quality. This approach primarily optimizes the current matching sequence from two angles.
During task transfer (Fig. 4), the variable ILC is used to assess each VM’s load. The VM with the lowest load receives a job from the VM with the greatest load. In the VM with the lowest load, the newly introduced job causes the most change in ILC. To balance the load condition of both VMs, task 5 is transferred from VM1 to VM2. The target function fitness updates the variable ILC constantly until it reaches the current optimum value.

Task transfer.
During task replacement (Fig. 5), the variable ILC is used to assess each virtual machine’s load. To balance the ILC variable values of both VMs, the job with the lowest resource consumption from the VM with the greatest load and the task with the highest resource consumption from the VM with the lowest load are chosen for replacement. Similar to Figure 6, tasks 5 and 9 are switched. The variable ILC is updated constantly until the goal function

Task replacement.
Local more optimal solutions are generated in individual honey badgers after local optimization. The scope of the regional search is expanded with the assistance of an improved swarm-based strategy, it also reduces the probability of an invalid search. Local optimization does not rely on the population location updating mechanism and is not disturbed by IHBA’s stochastic properties.
The algorithm model for the IHBA for scheduling cloud resources is shown above, including the representation of the problem solution and the fitness function. The specific implementation and pseudo-code are shown in Table 1.
Pseudo-code of proposed IHBA
IHBA, Improved Honey Badger Algorithm.
Simulation Experiments and Analysis
To verify the effectiveness of IHBA in handling load-balancing tasks in the cloud resource scheduling model, this article completes simulation experiments in Windows 10 system using MATLAB2021(a) software.
Data source
The simulated data set four different specifications of data, two types of virtual machines, and tasks, which are used to determine the algorithm’s ability to recognize different machines and different tasks (see Table 2). Among them, the memory space and memory size of the virtual machines are fixed values, and the memory space and memory size of the tasks are random values within specified ranges.
Virtual machine and task parameter settings
Parameter settings
The population specification is set as 30, iterations number is set as 200. The same experiment is repeated 10 times to reduce algorithmic contingency. The evaluation metrics are mean (mean), variance (std), best solution (best) and worst solution (worst). Particle Swarm Optimization, 33 Genetic Algorithm, 34 and Ant Colony Optimization 35 are examples of traditional optimization algorithms that are included in the comparative algorithms. New meta-heuristic optimization algorithms include Gray Wolf Optimization, 36 Slime Mould Algorithm, 37 HBA, 30 and IHBA. The parameter settings are represented in Table 3.
Parameters settings for different algorithms
Simulation results
The results of different algorithms for finding the optimal performance are shown in Table 4. The mean and variance of the seven algorithms’ optimization for different scale tasks are in the same order of magnitude. The differences between algorithms are not significant. There are still slight differences between algorithms, although the tasks are accomplished well. In the scale 1 task, GWO and IHBA perform better in resource allocation tasks, with lower means of 6.9482E-02 and 6.9517E-02. It could be inferred that the load effect is better. The variances of ACO, IHBA, and GA are 3.0762E-03, 3.1283E-03, and 3.8231E-03, indicating that these algorithms are more stable. In the scale 2 task, SMA and IHBA have smaller means of 9.6100E-02 and 1.0230E-01, respectively, with good load-balancing effects. It could be seen that IHBA performs better in the extreme state. The performance of each algorithm in the scale 3 task is not significantly different from that in the scale 2 task.
Optimization results of different algorithms
The optimal values are highlighted in bold.
In the scale 4 task, the sharp increase in the data scale leads to an increase in the differences between different algorithms. The means (1.2092E-01 and 1.4362E-01) and variances (1.3101E-03 and 1.9502E-03) of IHBA and ACO are relatively small, and the optimization performance is more prominent. However, the optimization ability of classical algorithms such as GA and PSO is not as good as that of new algorithms, with larger means (1.6719E-01 and 3.9434E-01) and variances (1.6360E-03 and 9.6260E-03). The new algorithm draws on classical algorithms and builds on them to continuously optimize the search parameters and population location update mechanisms. The algorithm has a search advantage as it focuses more on the balance of algorithm exploration and exploitation capabilities.
Figures 6 and 7 show the fitting curves of different algorithms for scale 1 and scale 2 tasks. It can be observed that due to the nature of the problem being a discrete optimization task, the curves in the figures exhibit obvious “step-jump” characteristics.

Algorithm-fitted curves for scale 1 task.
In Figure 6, the strong exploration capability has been shown during the first 60 iterations of the search process. In Figure 7, the strong exploration capability has been shown during the first 80 iterations. The jumping of the curves is more pronounced and the amplitude is larger. At a later point in the search, the algorithm gradually shifts toward local optimization. The number and amplitude of the jumping decrease significantly, and the algorithm gradually converges. Compared with classical heuristic algorithms such as GA, PSO, and ACO, GWO and IHBA have an absolute competitive advantage in the early stages of the search.
Figure 8 shows the fitting curves of the algorithms in the scale 3 task. Compared with Figures 6 and 7, the variability of the different algorithms is more pronounced and there is a layered phenomenon. ACO, GWO, PSO, HBA, and SMA have better initial solutions, and there are better solutions during the optimization process. The optimization abilities of the five algorithms are similar. Better initial solutions can be generated by IHBA, improving the accuracy of the solution during the search process.

Algorithm-fitted curves for scale 2 task.
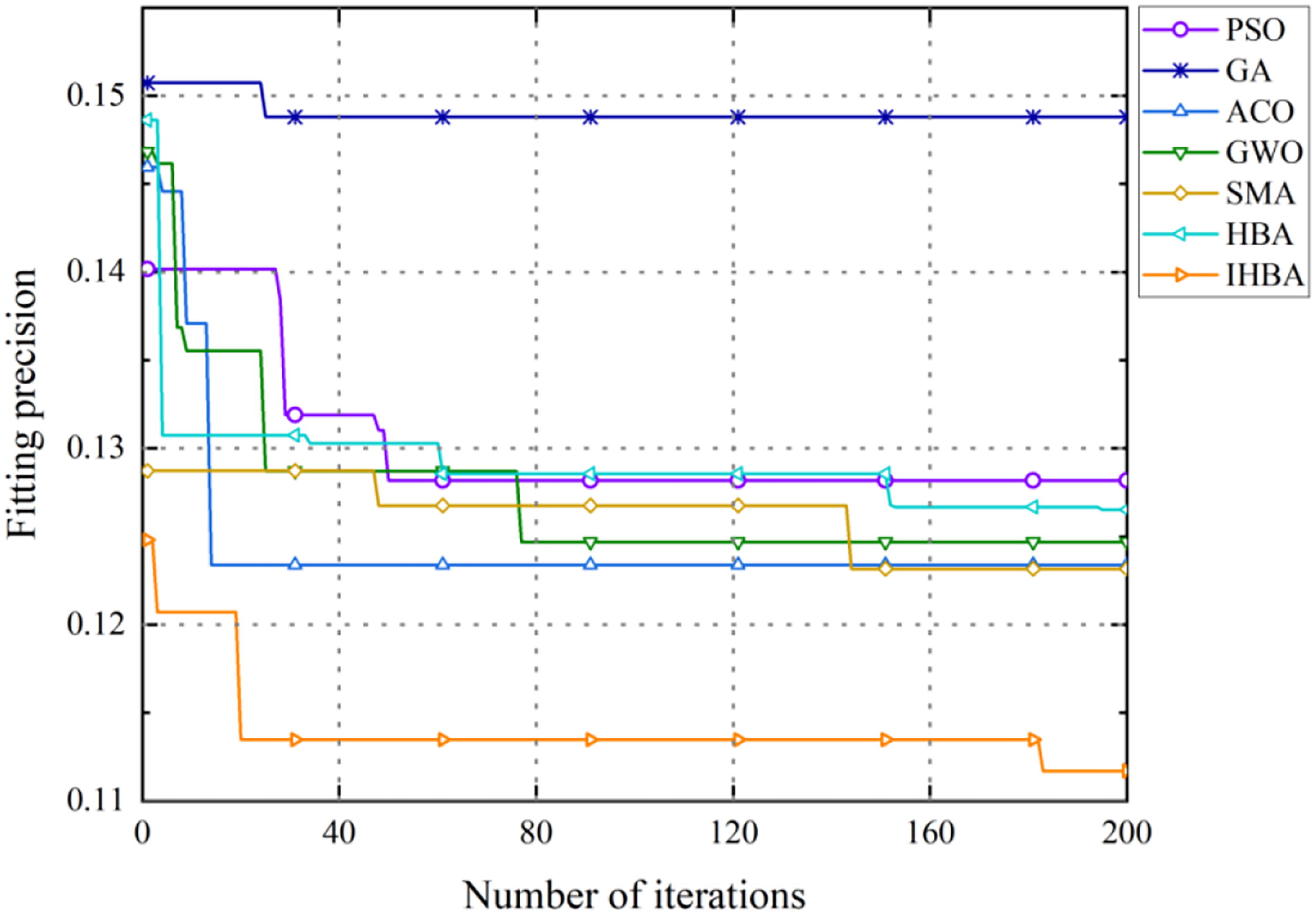
Algorithm-fitted curves for scale 3 task.
It can be inferred that Figure 9 also exhibits a layered phenomenon. Better solutions are not provided in GA and PSO throughout the entire search process. In the proposed scale, the two mentioned algorithms have weak optimization capabilities. Better initial solutions are provided by ACO, GWO, HBA, and SMA. The fitted curve for IHBA is similar to Figure 8, it can be seen from this that IHBA is better suited for resource allocation tasks involving large-scale load optimization.

Algorithm-fitted curves for scale 4 task.
Each algorithm was optimized 10 times in the experiment. The scales 2 and 4 are selected to make the boxplots for comparison. The mean is represented by the transverse line in the middle of the box, a smaller value corresponds to a better optimization ability. The degree of concentration of the data is represented by the height of the box, the smaller the height of the box indicates the more concentrated the data. Figure 10 shows the boxplot of the algorithms for the scale 2 task. It can be inferred that PSO and GA have a poor optimization ability. IHBA has an advantage in optimization capabilities. Its small box height represents less dispersion of the data and good data stability.
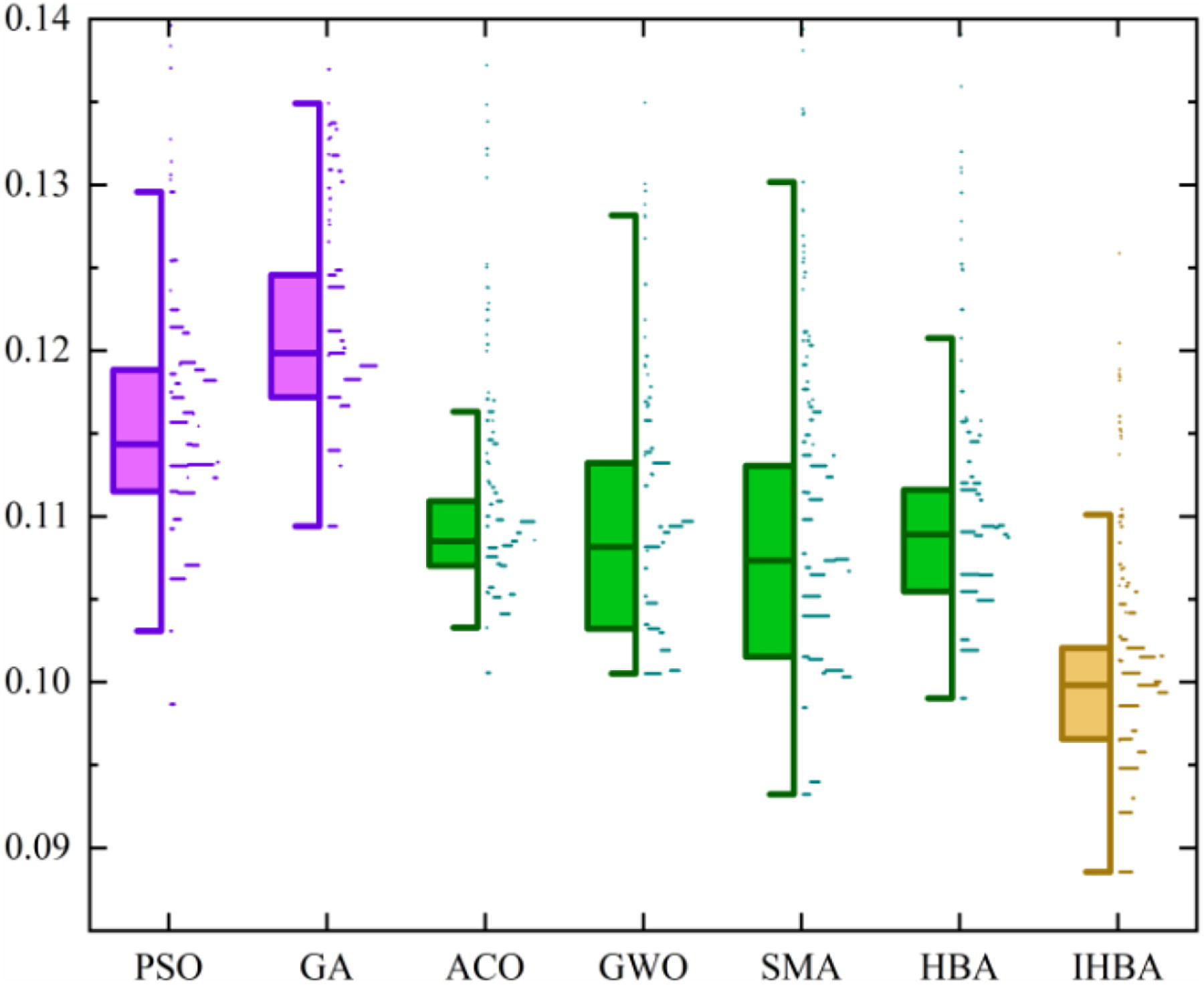
Boxplot of the algorithms processing the 100 tasks.
In Figure 11, as the task scale increases, the mean differences of each algorithm are even more significant. PSO still has a poor optimization ability and data stability. The solving abilities of ACO, GWO, SMA, and HBA are similar. The boxplot indicates that IHBA solutions have outstanding advantages in optimizing ability, especially in large-scale task. The results of the boxplots also validate the previous conclusions.
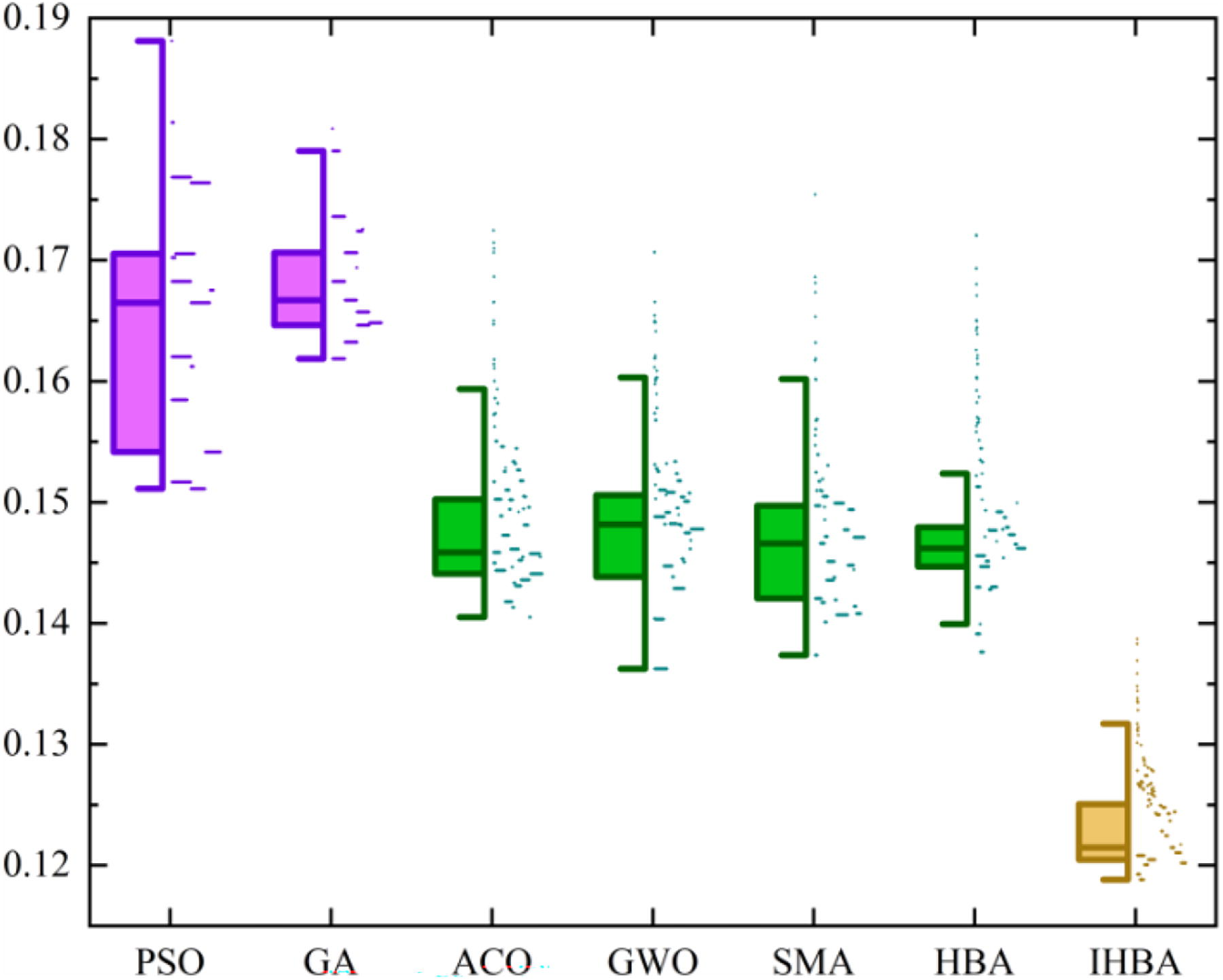
Boxplot of the algorithm processing the 500 tasks.
Conclusion and Future Work
Cloud resource scheduling is an important task in the era of big data. This article puts forward an IHBA, which targets the strengths and weaknesses of the basic HBA to achieve resource load balancing on the cloud platform. The population’s capability for global random walks in the solution space is increased by the inclusion of composite mutation factors in the early stages of algorithm search, accelerating the convergence rate of algorithms. A double-branching structure is adopted in the population position updating mechanism to enhance the algorithm’s exploration ability in the local solution space in the later stage. On the basis of considering individual load balancing and system load balancing, the cloud resource scheduling problem is described as a problem of combinatorial optimization, and a new fitness function is defined. Simulation experiments are conducted in four different cloud resource scheduling tasks. The results of the experiments demonstrate that IHBA performs better than traditional intelligent optimization algorithms including ACO, GA, GWO, HBA, PSO, and SMA. IHBA retains the global optimization ability of the HBA while expanding the individual’s random search range and enhancing the diversity of the algorithm population, thus preventing the algorithm from falling into local optima. IHBA can effectively achieve resource load balancing on the cloud platform.
With the development of the Internet of Things, the demand for real-time business decisions is increasing, and edge computing and streaming media analysis will become an important direction of big data processing. As a future work, the exploration capabilities of IHBA will be promoted. The application area of IHBA for practical optimization tasks could be extended by combining IHBA and other technologies, such as artificial intelligence and machine learning.
Footnotes
Author Disclosure Statement
The authors declare no conflicts of interest.
Funding Information
This work was supported in part by key projects of the Hubei Provincial Department of Education (D20161403).