
Abstract
The National Center Biobank Network (NCBN), consisting of six national centers (NCs) for advanced and specialized medical care, was launched in Japan in 2012 to collect biological specimens and health-related data. The common data formats of the six NCs, however, are not widely known outside the NCs. Therefore, we investigated whether the data elements collected by the NCBN could be made to conform to the international standards of the Clinical Data Interchange Standards Consortium (CDISC). We attempted to map the NCBN data elements (202 items) onto the Study Data Tabulation Model (SDTM), a set of CDISC standards on the submission format of electronic clinical data approved by the Food and Drug Administration. The results showed that all 202 items of the NCBN data could be mapped onto the SDTM and fulfilled 50%–70% of the required items of each domain specified in the SDTM. We concluded that, while the standardization of biobank data according to the CDISC standards is possible, there is a need to consider whether additional items must be included in the NCBN and to have experts familiar with the CDISC standards review the standardization needs.
Introduction
B
Biobanks are not often standardized—each bank may have differing objectives, methods of classifying and collecting biological specimens, subject population characteristics, methods of collecting health-related information, and data entry methods. Therefore, researchers using biobanks must interpret the biobanks' data on a case-by-case basis, which makes changing variables and data processing tasks burdensome when data from several biobanks are aggregated and used together.
Several biobanks are currently operating in Japan, one of which is the National Center Biobank Network (NCBN). The NCBN was launched in 2012 to improve the clinical infrastructure for next-generation medical care. It utilizes a network/federation organizational structure and its primary goal is to promote the use of bio-resources in industrial–academic–governmental collaborations through a wide range of joint research projects conducted at six national centers (NCs; see Fig. 1) spread across Japan. 5
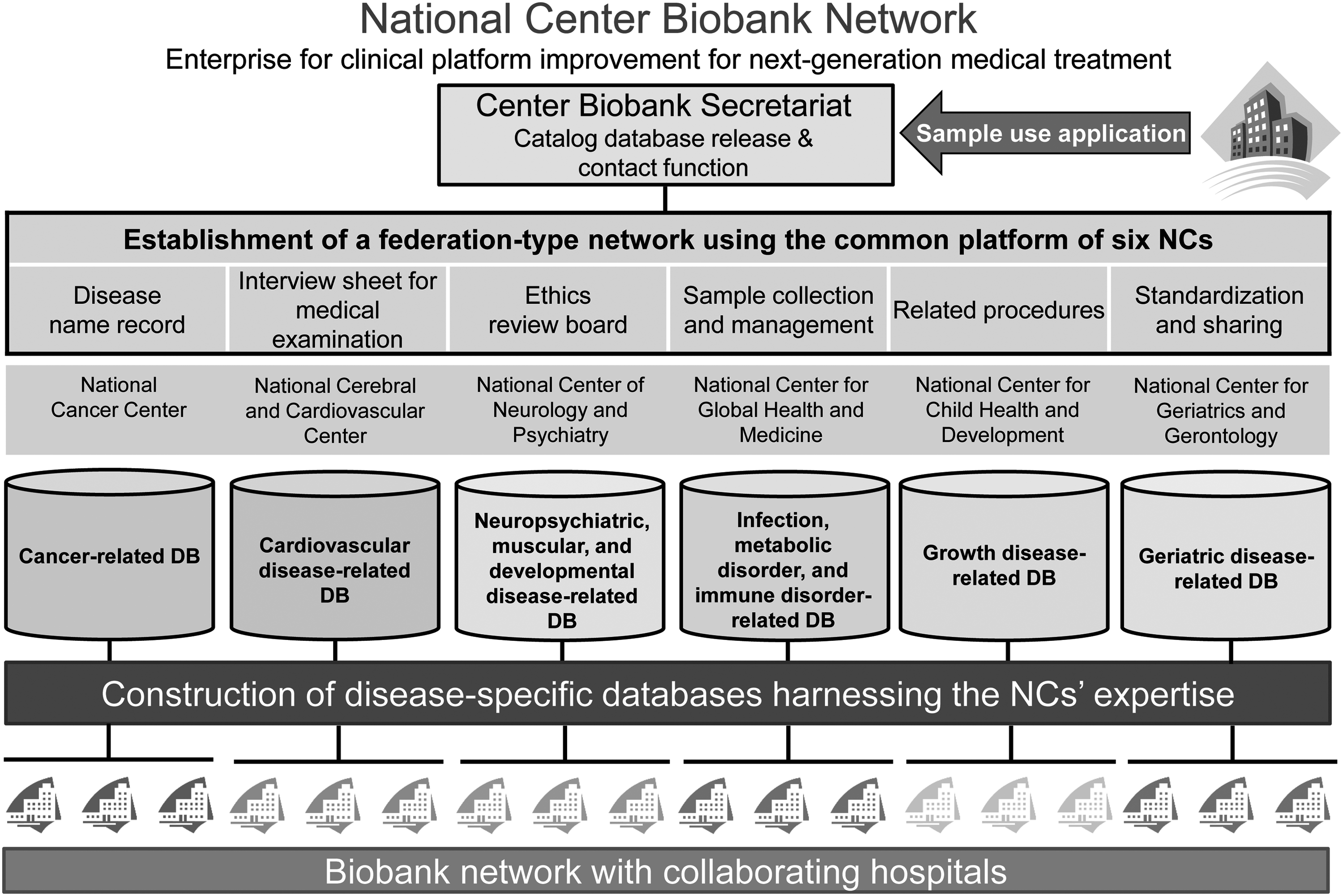
The outline of National Center Biobank Network (NCBN).
Biological specimens (e.g., blood, DNA, RNA, serum) and patient information collected and stored at each NC is aggregated and managed at a central biobank. Patient medical information is obtained from medical records and interview forms standardized across the six NCs and, along with information on biological specimens, is recorded in a data format created by the NCBN. However, the data format was specifically developed for the NCs and thus is not widely used or known outside them. Unique interpretations or noncompliance with data entry methods by individual NCs can thus cause problems when the data are accumulated in the central biobank.
Numerous notices on data entry methods have been sent out to the individual NCs, and the database system has been modified multiple times. Furthermore, although the NCBN project was launched in 2012, the database catalog was only posted on the NCBN homepage in 2013. As such, the NCBN database is not likely to be well known outside the NCs, which is further evidenced by how it has yet to be used by outside researchers.
In an attempt to standardize data formats, in 2004, the U.S. Food and Drug Administration (FDA) adopted the Clinical Data Interchange Standards Consortium (CDISC) standards and developed guidelines for submitting electronic data from clinical trials for use in the development and application of medical and pharmaceutical products.6,7 The CDISC is a nonprofit organization committed to establishing standards for clinical research data and metadata.
Since then, general use of the CDISC standards for submitting electronic data has expanded to the USA, Europe, South Korea, China, and numerous other countries throughout the world. The Japanese Pharmaceutical and Medical Devices Agency (PMDA) also announced that from 2016, clinical trial data received by the PMDA will have to comply with the CDISC's Study Data Tabulation Model (SDTM) and Analysis Dataset Model (ADaM) if being used to devise new medical and pharmaceutical products. 8 Data conforming to standard specifications can be more easily handled and processed in cross-sectional and international collaborations.
It is expected that standards will, in the future, become more widely used outside of the pharmaceutical industry, such as in research organizations, contract research organizations, and others, not only for clinical trials on medical and pharmaceutical products but also for clinical trials on other topics and epidemiological studies. The CDISC standards define the content of clinical trials, stipulate communication protocols, and provide standard formats for electronic application data. 9 To evaluate whether data collected in formats that do not comply with the CDISC standards can be transformed to meet these standards, we must first examine how the data conform to the SDTM. Ensuring that the data fit the SDTM is also essential for converting them to fit the ADaM, which is the CDISC's standard format for statistical analysis.
Toward this end, we mapped the data collected and managed by the NCBN onto the SDTM, and identified and explored the advantages and problems associated with this process.
Materials and Methods
Study design
This was a feasibility study to determine whether NCBN data could be made to conform to the CDISC standards. Toward this end, we investigated whether the NCBN data could be mapped onto the SDTM, one of the CDISC's standard specifications, and evaluated the advantages and problems associated with this process. This study used NCBN data accumulated by the central biobank as of August 2014.
NCBN data
To standardize the biological specimen and health-related information collected by the six NCs, the NCBN's information system review working group, the sample utilization review working group, and the sample handling system review working group created drafts for developing common interview forms and disease registries and defined methods for creating databases and collecting and managing specimens, respectively.
According to the items and data formats stipulated by these working groups, biological specimens are collected and stored at each NC, whereas health-related information is collected by each NC and aggregated at the central biobank. In the system, the data are recorded in a common NCBN data format (i.e., CSV files) and then uploaded via the Internet into the central biobank databases. As of August 2014, most of the data gathered and managed by the central biobank, including numerical data, text data, and date data, could be categorized into the following 202 items.
• Interview form information (117 items), including facility/patient characteristics, vital signs, medical history (patient/family), surgical history, transfusion history, allergies, substance use (tobacco/alcohol), and female reproductive information.
• Disease information (21 items), including International Statistical Classification of Diseases and Related Health Problems (ICD-10) codes or Medical Information (MEDIS) codes.
• Biological specimen information (64 items), including specimens and pathological samples.
SDTM
In this study, we referred to the SDTM Implementation Guide (IG) ver. 3.2 and SDTM IG Associated Persons ver. 1.0 during mapping. The SDTM is a data format that records individual patient clinical data in different domains. Each domain uses stipulated variables with defined conditions (required, expected, or permissible) and CDISC Controlled Terminology.
Procedure and methods for mapping NCBN data onto the SDTM
Figure 2 illustrates the procedure used for mapping the NCBN data onto the SDTM. First, a researcher classified the 202 items of the NCBN data (including 117 items on interview form information, 21 items on disease information, and 64 items on biological specimen information) in more detail according to the item content, and then determined the domain that each item applied to standard SDTM domains. The researcher also determined what specific variable that the item fell under among those defined for the selected domain. Next, another researcher reviewed the procedure to confirm whether the domains and variables adopted by the first researcher were consistent. If a given variable was not consistently classified by the two researchers, the first researcher would make a final decision by deciding whether to adopt the results of the reviewer.

Illustration of how the National Center Biobank Network data were mapped onto Study Data Tabulation Model data.
Evaluation items/methods
The level of mapping difficulty was classified as follows, and proportions of each level were calculated for each domain.
1. Easily classified
2. Problematic, but classifiable into one of the following categories:
a. Disparity between the NCBN and SDTM in the methods of categorizing the selections; b. Disparity in how date data are treated; c. Question items must be changed; d. Creation of supplementary materials required.
3. Classification not possible
The proportion of required items was calculated for each domain.
Results
Selected domains
Seven domains of health-related information were classified in this study [demographic data (DM), vital signs (VS), medical history (MH), associated persons (AP), substance use (SU), female reproductive system findings (RP), and laboratory test results (LB)]. The highest proportion of existing variables were in the VS domain (80.0%), while the proportions of variables in the DM and RP domains were 44.4%; the proportions in other domains such as allergies and substance use (alcohol and tobacco) were low (10%–40%).
Difficulty of mapping NCBN data onto the SDTM
All 202 NCBN variables could be applied to the SDTM variable [39 items (19.3%) were easily classified and 163 items (80.7%) were problematic but classifiable] (Table 1). Regarding the problematic but classifiable items, out of the variables of medical history, surgical history, transfusion history, and family history, the reasons for the problematic classifications were because of disparities in the methods of categorizing the selections and the treatment of date data from the SDTM. In addition, some question items and existing variables had to be changed and supplemental materials created. A complete breakdown of the “problematic but classifiable” items is presented in Table 2. Overall, 50%–70% of the required items in each domain were fulfilled. Common additional items such as STUDYID, USUBJID, and ARM needed to be included to achieve 100.0% fulfillment of the required items. The proportion of variables in the LB domain was low at 33% because additional test items such as LBTESTCD and LBTEST needed to be included. The proportion of items that were fulfilled in each domain is shown in Figure 3.

Proportions of required items that were fulfilled by the National Center Biobank Network data in each domain (%).
Please refer “Selected domains.”
STDM, Study Data Tabulation Model.
Discussion
In this study, we investigated whether the CDISC standardization is feasible for biobank data not collected and managed under a standard data format. Toward this end, we attempted to map the NCBN data onto the SDTM, which is one of the CDISC's standards, and the advantages and problems involved in this process were evaluated. All 202 NCBN data items could be mapped onto the SDTM, although some items were problematic. Furthermore, many of the required items were lacking in each domain; specifically, 30%–50% of the items required additional items to achieve fulfillment.
Since all the items of the NCBN data could be mapped onto SDTM variables in this study, it appears that the NCBN data can be made to conform to the CDISC standards. However, it would likely require a great deal of work to accurately conform these data to the SDTM. At present, the NCBN data are based on a standardized interview form and recording methods established by the network's working groups. Naturally, since conformance with the SDTM is not required, further changes would be needed to align the data with the variables used in each domain and with the CDISC Controlled Terminology. For instance, changes would have to be made with respect to the wording of the questions, how the answers are categorized, which codes are used, and how the date data are treated. Moreover, required items would need to be added to the NCBN data to make up for the current insufficiency.
When undertaking CDISC standardization, it would be indispensable to have a CDISC expert available to utilize their knowledge and skills. If standardization is not performed appropriately or under the supervision of a knowledgeable specialist, it is possible that the results would only be “SDTM-like.” In particular, it would be essential to have a specialist review whether the CDISC Controlled Terminology is followed and the domain variables selected are appropriate.
We believe that standardizing NCBN data to conform to the CDISC standards would be useful. First, the standards are all-inclusive when it comes to the evaluation items needed for clinical trials. The results of the present study showed that NCBN data currently lacks items required by the SDTM, which we believe would ensure high-quality clinical research data. Moreover, because the CDISC defines all of its items and terminology, researchers would not need to develop and define items when creating datasets, and the data would be easier to interpret than would original items, terminology, and classifications. Standardization to the SDTM would also reduce the likelihood of problems such as data input mistakes due to NCs' unique interpretations when data are integrated into the central biobank. Standardization would also reduce the time and effort that researchers must spend on data processing.
However, there are concerns regarding the extent to which organizations using the biobank data must understand the CDISC standards. While the CDISC is an international standard format for clinical trial data, it is mainly used in medical and pharmaceutical product applications. As such, it remains unclear as to how much it has (or will) spread among diverse fields of research.
In conclusion, it is possible to conform NCBN biobank data to the CDISC standards. However, to achieve this, it is necessary to reconsider not only the current entry formats of the data but also whether the domains and items are suitable for collecting patient information related to biological specimens. In addition, experts familiar with the CDISC standards should review the items, classifications, and terminology of the NCBN data.
Footnotes
Acknowledgments
The authors thank Mr. Yoshiteru Chiba for his technical skills and useful comments. This research was supported by a grant from the National Center for Global Health and Medicine. The funding source had no involvement in the study design; data collection, analysis, or interpretation; writing of this manuscript; or the decision to submit this manuscript for publication.
Authors qualify for authorship based on making one or more of the substantial contributions to the intellectual content: conception and design (IS, YK, YT), acquisition of data (IS, YT), analysis and interpretation of data (IS, YK, KI, IS, KK, HY), and drafting of the manuscript (IS, YK, KI, IS, KK, HY). Furthermore, all authors reviewed the manuscript and approved the final manuscript.
Author Disclosure Statement
No conflicting financial interests exist.