
Abstract
Biobanks are the biological back end of data-driven medicine, but lack standards and generic solutions for interoperability and information harmonization. The move toward a global information infrastructure for biobanking demands semantic interoperability through harmonized services and common ontologies. To tackle this issue, the Minimum Information About BIobank data Sharing (MIABIS) was developed in 2012 by the Biobanking and BioMolecular Resources Research Infrastructure of Sweden (BBMRI.se). The wide acceptance of the first version of MIABIS encouraged evolving it to a more structured and descriptive standard. In 2013 a working group was formed under the largest infrastructure for health in Europe, Biobanking and BioMolecular Resources Research Infrastructure (BBMRI-ERIC), with the remit to continue the development of MIABIS (version 2.0) through a multicountry governance process. MIABIS 2.0 Core has been developed with 22 attributes describing Biobanks, Sample Collections, and Studies according to a modular structure that makes it easier to adhere to and to extend the standard. This integration standard will make a great contribution to the discovery and exploitation of biobank resources and lead to a wider and more efficient use of valuable bioresources, thereby speeding up the research on human diseases. Many within the European Union have accepted MIABIS 2.0 Core as the “de facto” biobank information standard.
Introduction
S
MIABIS was ontologized (OMIABIS) by Brochhausen et al., 3 becoming the first ever biobank ontology representing the administrative entities in biobanking and their relations.
MIABIS 2.0 is a collection of components with associated attributes representing relevant concepts from biobanking and biomedical research and can be used to integrate the most relevant building blocks of the biomedical research ecosystem (Fig. 1). This article describes MIABIS 2.0 Core, an update of MIABIS jointly prepared by a working group composed of representatives of BBMRI-ERIC 4 member countries. In this new version, certain attributes have been newly defined and structured and the component Sample Collection/Study has been separated into two distinct components that, together with the Biobank component, form the Core module of MIABIS. Guidelines on how to implement this standard in informatics systems and examples of use cases are also provided.

Minimum Information About BIobank data Sharing (MIABIS) is a recommendation about what information should be stored in biobank and research information systems to be able to easily exchange information and data. The aim is to facilitate the reuse of bioresources and associated data by harmonizing the information in the most relevant components of the biomedical research ecosystem. LIMS, Laboratory Information Management System; ELN, Electronic Lab Notebook.
Materials and Methods
Governance
An international MIABIS Working Group was established under the umbrella of BBMRI-ERIC with representatives from national BBMRI nodes, with the aim to continue the development of MIABIS.
MIABIS is maintained through an extensive procedure where new components and attributes can be proposed and voted on by each country. We have been following the MoSCoW 5 prioritization to reach consensus on the MIABIS 2.0 components and attributes.
Each participating member country was asked to provide one or more contacts to participate in several MIABIS review sessions, most of which were done through teleconference and web meetings. During and in between the meetings, each of the MIABIS data elements was reviewed by all and changes were proposed and subsequently accepted or rejected. We adhered to a consensus model for decision-making with the following characteristics:
(1) Participatory and Collaborative: All group members were included and encouraged to participate and collaborate on the basis of their availability, expert knowledge, and their countries' special needs or area of interest. (2) Agreement Seeking: Seeking widespread or full agreement where possible. We have committed ourselves to the goal of generating as much agreement as possible, but “agree to disagree” on items and on a case-by-case basis discussed if attributes would be excluded from MIABIS for the short term or that inclusion and agreement were essential. (3) Process Oriented: We have carefully considered the process of making decisions, not just the result but also with a view to maintaining MIABIS in the future in a similar way. All contributions were welcome. The facilitator and the structure of the discussions specifically discouraged power leverage, adversarial positioning, and other group manipulation tactics.
Changes from MIABIS 1.0
MIABIS was implemented in several use cases as biobank registers and catalogs and also as part of data models for biobank and research management systems. These experiences provided inputs to the MIABIS team regarding limitations and improvements to facilitate its easy adoption. The main suggestions were related to the large number of attributes, the need of a more structured design, and the incorporation of components that could cover other relevant actors in the biomedical research process.
The major update of MIABIS 2.0 from the previous MIABIS proposal 2 has been the introduction of a more modular and generic architecture. The “Biobank” component has been retained, while the “Sample Collection/Study” component was separated into two components: “Sample Collection” and “Study.” These three components make up the MIABIS 2.0 Core. The data element list consists of a total of 22 attributes divided over these core components, presented in Tables 1–3 respectively. To ease adoption, none of the 22 attributes is mandatory or required because MIABIS is only a guideline highly recommended to be used when applicable.
MIABIS, Minimum Information About BIobank data Sharing.
Attribute can be aggregated from data stored on the sample and subject levels in local management systems of the biobanks.
Attribute can be aggregated from data stored on the sample and subject levels in local management systems of the biobanks.
The main steps for creating MIABIS 2.0 included the following:
(1) The terms Biobank, Sample Collection, and Study have been defined. (2) The concept of “Sample Collection/Study” was separated into two distinct components: “Sample Collection” and “Study” as one study can be conducted using samples from more than one sample collection. A “Sample Collection” is not necessarily associated with a specific “Study.” (3) MIABIS 2.0 has been structured in a more effective way. The definition of lists and structured data facilitates its implementation in informatics systems. For instance, the Contact Information is a structured data element that can be reused by several components in MIABIS. (4) The attribute Biobank Type was removed from the component “Biobank” because this concept is not consistently used by the biobank community (5) The attribute Hosted Studies was removed from the component “Biobank” because it reflects a relationship, not a real value. (6) The attributes Average Age, Current Sampled Individuals, Current Total Individuals were removed from the “Sample Collection” and “Study” components because they represent calculated values that can be derived from other components or data elements such as participant and sample. (7) The attributes comorbidity and medical records were removed from the “Sample Collection” and “Study” components because they are only associated to specific sample collections or studies. (8) Type of collection was renamed to Collection Type in the “Sample Collection” component and Study Design in the “Study” component. (9) We have made a modular structure of MIABIS, allowing additional components to be added, making MIABIS flexible and applicable for a variety of use cases and domains of biobanking and research studies. The proposed additional components currently being drafted in MIABIS 2.0 are “Biological Experiment,” “Participant,” “Rare Disease,” “Sample,” and “Quality.” (10) All definitions and value sets for the attributes have been reviewed and fine-tuned.
Results
MIABIS 2.0 Core: components and attributes
Before defining the minimum attributes of MIABIS 2.0 Core, it is important to clarify and define its three main components: “Biobank,” “Sample Collection,” and “Study.” Unanimous and unequivocal definitions for these terms are hard to find in literature, as described by Fransson et al. 6 Thus, we introduce the following general definitions aiming to facilitate the representation of MIABIS 2.0 Core as part of informatics data models:
Definition 1: Biobank represents an organization or an organizational unit that stores samples and data related to the samples.
Remarks: In MIABIS 2.0 Core, biobanks do not contain samples directly, but they are hosts of sample collections. On the level of biobanks, only attributes related to the organizational aspect of the biobanks are represented.
Definition 2: Sample Collection represents a set of samples with at least one common characteristic.
Definition 3: Study represents a set of samples brought together in the context of a research study.
Remarks: A study can combine samples from several sample collections and from several biobanks. One sample can participate in multiple studies.
Tables 1–6 provide the attribute list for each MIABIS 2.0 Core component.
ORCID 7 website: http://orcid.org/
The attributes Contact Information and Disease are classified as structured data as part of the modular approach of MIABIS. These attributes are reused by several components, for example, Contact Information is relevant to all three of the core components. The structures of Contact Information and Disease are presented in Tables 4–6. Contact Information consists of general “Contact Information,” for example, a biobank and “Research Information” to describe, for example, a Principal Investigator (PI).
Guidelines for implementing MIABIS 2.0 Core in biobank and research informatics systems
To be MIABIS compliant means (1) MIABIS concepts and attributes are part of the data model of biobank and research informatics systems or (2) data from biobank and research are mapped to MIABIS for sharing purposes.
Each component of MIABIS 2.0 Core can be modeled as a class in a logical model or as an entity in an Entity Relationship Diagram (ERD). The semantic of MIABIS 2.0 Core allows for the implementation of use cases for managing and sharing biobank and research data at the aggregated and metadata levels.
MIABIS 2.0 has two main parts: MIABIS 2.0 Core that represents a high level of information of biobank and biomedical research and additional components that describe particular subdomains derived from concepts that drive everyday biomedical research processes. This way, data from every component of the biomedical research ecosystem can be represented in a standardized manner. It will help create interfaces and tools to facilitate interoperability and reusability of data and knowledge. Currently, five additional components dealing with the concepts of “Biological Experiment,” “Participant,” “Rare Diseases,” “Sample,” and “Quality” have been proposed within the MIABIS Working Group. They are not presented in this article as they have not gone through the whole governance procedure and are still under the status of “proposed.” All updates and proposals can be found on MIABIS Wiki page (https://github.com/MIABIS/miabis/wiki).
Formal representation of MIABIS
Figure 2 provides a logical representation of MIABIS 2.0 Core for a use case that could be a biobank catalog, part of a Laboratory Information Management System (LIMS) or a research management system, such as an Electronic Lab Notebook (ELN). It captures the semantics proposed for the core components.
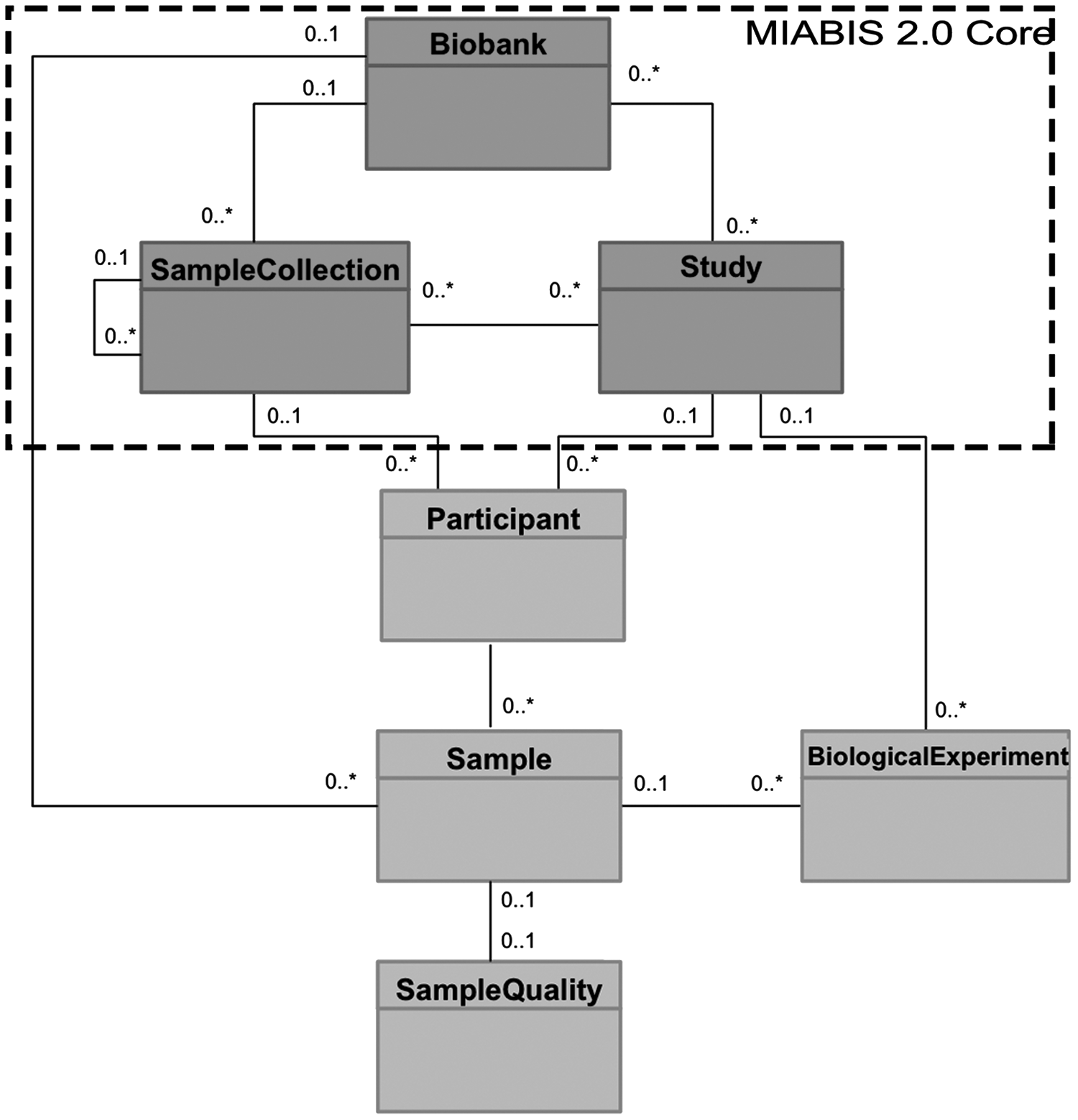
Logical data model of a use case that implements the MIABIS 2.0 Core and some additional components (Participant, Biological Experiment, Sample, and Sample Quality). Multiplicities in the diagram represent cardinality among the different classes for the specific use case.
When expressing the example logical model (Fig. 2) in an ERD, it introduces auxiliary entities as contact information, researcher information, references to ontologies, diseases, and so on. The attributes expressed as lists (Material Type, Data Categories, etc.) can be included as separated entities or in a unified table for all the lists. Examples of the use of MIABIS 2.0 Core in ERDs are as follows: the BBMRI-NL 8 catalog, which can be downloaded as open source MOLGENIS software, 9 the data model for BBMRI-LPC 10 and for the Biobank Catalog for the BCNet network from the WHO organization. 11 Examples are also provided in the MIABIS wiki:
https://github.com/MIABIS/miabis/wiki/Database-implementation
Data sharing
MIABIS can be used to share data in a federated network of biobanks or in a virtual environment (e.g., cloud computing, business intelligence, service-oriented architecture). In a federated environment, as a first step, data from the biobanks should be mapped to the MIABIS data elements. This can be done manually or through a program or script, but it is essentially a manual job that can be substantially simplified if the biobank management systems already are MIABIS compliant. The mapping process needs to be done every time the data model is changed in the biobank database. Once the biobank data are mapped to MIABIS, an interface should be in place as a communication channel between the biobank and external services. In a federated solution, a uniform user interface can be used to distribute queries among the biobanks. A virtual environment applies data abstraction and data transformation techniques to deal with the different semantics in the biobanks. In this case, the mapping should produce linked data to a data layer that semantically connects the data with the data elements in MIABIS. This approach has been demonstrated as a proof of concept in the RD-Connect project 12 and in the BioMedBridges project. 13
MIABIS 2.0 Core XML Schema
A machine-readable version of MIABIS 2.0 Core allows for the implementation of several data sharing use cases such as the following:
(1) A federation of catalogs where searches can be expanded to include data from another catalog. (2) Annotation of data sets in a data repository with the provenance of the samples. (3) Exchanging data about samples between a catalog and a track and trace system for sample requests, shipments, and so on.
An XML Schema Definition for MIABIS 2.0 Core to facilitate these use cases has been designed. The schema's guiding principles are as follows:
(1) It must be possible to use each component individually. (2) Duplication of data should be avoided. (3) The resulting schema should be suitable for streaming access. (4) The XML file should be human-readable.
All relationships between components have been marked as optional to allow an implementation to cherry pick only the items desired, and we have used recognizable names for the fields.
To test the schema, a reference implementation has been created that generates Java classes that can be used to read and write a schema file. The XML schema can be found on the MIABIS Wiki (https://github.com/MIABIS/miabis-xml).
The case of the BBMRI-ERIC Directory
MIABIS 2.0 Core is implemented in the BBMRI-ERIC Directory (http://bbmri-eric.eu/bbmri-eric-directory), which integrates biobank catalogs from the member countries. To interface with the Directory, sample collections should be modeled using partitioning of a parent set, 14 which is either a biobank or another collection, where each collection is a partition. For the top-level collections, the parent set is the biobank, while each collection can be further partitioned into subcollections. This implies (1) each sample of a parent set belongs to exactly one (sub) collection; (2) there are no empty collections. Use of partitioning to create (sub) collections allows for aggregation of the collection to obtain insight in the overall composition of the parent collections, and ultimately, the content of the whole biobank. If a biobank is not using the concept “Sample Collection,” one virtual sample collection for the biobank should contain all the samples. For clinical biobanks that lack standardized structuring, the software developers are advised to introduce sample collections that aggregate samples by, for instance, the material type.
Showcases of MIABIS
Since 2012, several projects and biobanks have adopted the MIABIS standard in different use cases. Below is a short summary of these projects.
Confederation of Cancer Biobanks
The Confederation of Cancer Biobank from National Cancer Research Institute (NCRI) created the Biobank Data Standard for collection, storing, and sharing data describing human biological material. The standard includes components and attributes from MIABIS (http://ccb.ncri.org.uk).
BBMRI-ERIC Directory
The first version of the BBMRI-ERIC Directory (http://bbmri-eric.eu/bbmri-eric-directory) provides an aggregated view of the BBMRI-ERIC biobank infrastructure. Currently, MIABIS 2.0 is implemented on a common catalog platform that integrates biobank and research applications from most of the European countries that are members/observers of BBMRI-ERIC.
BBMRI.se Sample Collection Register
The Swedish BBMRI node created a MIABIS-compliant national catalog (http://bbmriregister.se) in 2012 with descriptive data about studies and sample collections using human biological samples in Sweden. The aim of the register is to raise awareness about sample accessibility for potential scientific collaborations.
BBMRI.fi's KITE availability tool
This is an open web-based database that contains information on available Finnish sample collections using MIABIS attributes. KITE also allows users to browse and search standardized lists of variables available in each sample collection. KITE also includes information on Finnish biobanks in MIABIS 2.0 format (https://kite.fimm.fi).
BBMRI-NL national catalog
The Dutch BBMRI node has published a national catalog since 2012 (https://catalogue.bbmri.nl/), which has been updated to MIABIS 2.0 using BBMRI-NL Rainbow Project 11. Currently, work is progressing to support fully automated updates of the data without human interaction from several large Dutch biobanks.
BiobankCloud
The BiobankCloud is an EU FP7-funded project aiming to create a cloud-computing platform as a service (PaaS) for storage and analysis of genomic data. MIABIS 2.0 is being used as part of the data model for representing metadata related to the biobank, collections, research study, and also metadata representing omics data (www.biobankcloud.com/).
RD-Connect Databases
Biobanks and clinical bioinformatics hub for rare diseases, or RD-Connect, is an EU FP7-funded project with the aim to provide an integrated platform connecting databases, registries, biobanks, and clinical bioinformatics for rare disease research. The project has 27 full partners, also outside the European Union such as in the United States (NIH) and Australia and 26 associated. RD-Connect also collaborates with a wide range of other people and organizations worldwide (http://rd-connect.eu/).
EUDAT
The MIABIS component study is used in B2SHARE, a user-friendly, reliable, and trustworthy way for researchers, scientific communities, and citizen scientists to store and share small-scale research data from diverse contexts (www.eudat.eu/).
BioMedBridges
Within the EC FP7-funded cluster project for Life Sciences, BioMedBridges, and a joint effort of the 10 biomedical sciences research infrastructures on the ESFRI roadmap. “Biobank” and “Sample Collection” components are used in the data model of the BioSample service (www.biomedbridges.eu/).
International Agency for Research on Cancer
In the global biobank network for International Agency for Research on Cancer (IARC), BBMRI.se is developing an international biobank catalog at the sample level for BCNet. The data model is fully based on MIABIS 2.0 (http://ibb.iarc.fr/).
Discussion
MIABIS 2.0 Core is now simplified so that the components have smaller attribute lists. We foresee that the Core will not be subject to much additional change. Modularization will support different kinds of use and will make it easier to add future extensions. As the MIABIS 2.0 Core attributes are often already represented in the databases of commercial and in-house management systems (e.g., LIMS, ELN, registries, and catalogs), little effort is needed to adopt the standard for data sharing.
MIABIS 2.0 will cover most of the relevant concepts in biobanking and biomedical research represented in MIABIS 2.0 Core and other additional components. Future plans, beyond the additional components already in progress, include adding components to represent personal data protection and clinical data.
As MIABIS is a conceptual information model, it does not define mandatory attributes. However, when implementing MIABIS in an informatics system, mandatory attributes are relevant according to the system requirements. When using MIABIS for biobank interoperability, the question of mandatory attributes gains more relevance.
Making informatics systems MIABIS compliant does not necessarily mean that the data model should follow MIABIS strictly. The informatics systems can keep their own idiosyncratic semantics and map their data to MIABIS for sharing purposes. Nevertheless, one of the aims of MIABIS is to shift the biobank and biomedical research community toward the use of the controlled vocabulary represented in this standard.
Another relevant issue is quality assessment for biobanks, sample collections, samples, and data. Sharing of bioresources requires consistent and standardized tools to evaluate the quality of the bioresource. This has a significant impact on the research process and will be addressed by the MIABIS component “Quality,” which is currently in preparation and will be associated with other components.
While a consensus procedure for proposing and accepting new components and attributes is in place, there is still some work to be done on the governance of MIABIS. It is envisaged that the maintenance and further development of MIABIS to include more countries will be aided by a content management platform that allows any interested countries, experts, and other interested parties to be informed, join, and contribute to the “under construction” components. Workgroup coordinators will post and display most current components, and country representatives will actively seek deliberation with their stakeholders. The voting process will be more formal but, by definition, transparent for all.
The biomedical research community is moving toward a more open-data and open-science environment. However, there is still a lack of dependable informatics platforms for researchers to share data in an easy and secure way. Even when several efforts are being made to facilitate sharing of biomedical data,15–17 better information and dissemination of results in that direction are needed. At the moment, several informatics infrastructures providing services for storage, analysis, and integration of scientific data8,18,19 are already implementing MIABIS 2.0 Core to facilitate biobank and research data sharing in trustable and secure environments.
We have developed a standard that can be used by biobanks, biomedical researchers, and software developers around the world, as the information recommended in MIABIS 2.0 Core is often a natural part of the data models for the biobank and research management systems. To further promote the use of MIABIS and exemplify how it can be used once implemented, specifying scientific use cases will be beneficial.
The MIABIS 2.0 Core is the stable part of MIABIS 2.0, the de facto standard for sharing data in the BBMRI-ERIC community, and has also been adopted by other biobank networks. MIABIS 2.0 will shortly be finalized, including additional components that represent the most relevant building blocks of the biomedical research.
Footnotes
Acknowledgments
We thank our fellow members in the MIABIS Working Group: Martin Fransson, Roman Siddiqui, Heimo Müller, Klaus Kuhn, Linda Zaharenko, Helmut Spengler, Araceli Diezfraile, Joakim Geeraert, Ondřej Vojtíšek, Anita Nieminen, Kristjan Metsalu, Murat Sariyar, Michael Hummel, and Cathleen Ploetzand. We also thank the European Commission for financially supporting the BBMRI preparatory phase (grant agreement 212111), the Swedish Research Council for granting the BBMRI.se project (grant agreement 829–2009-6285), BBMRI-NL, a research infrastructure financed by the Netherlands Organization for Scientific Research (NWO project 184.021.007), the Center for Translational Molecular Medicine, Translational IT project (CTMM-TraIT), and the Academy of Finland for financially supporting the BBMRI.fi network (grant no. 273527).
Author Disclosure Statement
No conflicting financial interests exist.