
Abstract
Biobanking at Duke University has existed for decades and has grown over time in silos and based on specialized needs, as is true with most biomedical research centers. These silos developed informatics systems to support their own individual requirements, with no regard for semantic or syntactic interoperability. Duke undertook an initiative to implement an enterprise-wide biobanking information system to serve its many diverse biobanking entities. A significant part of this initiative was the development of a common terminology for use in the commercial software platform. Common terminology provides the foundation for interoperability across biobanks for data and information sharing. We engaged experts in research, informatics, and biobanking through a consensus-driven process to agree on 361 terms and their definitions that encompass the lifecycle of a biospecimen. Existing standards, common terms, and data elements from published articles provided a foundation on which to build the biobanking terminology; a broader set of stakeholders then provided additional input and feedback in a secondary vetting process. The resulting standardized biobanking terminology is now available for sharing with the biobanking community to serve as a foundation for other institutions who are considering a similar initiative.
Introduction
C
In 1991, RAND Corporation 7 estimated there were 146 large tissue banks, repositories, core facilities, and longitudinal biobanks comprising over 120 million biological samples in the United States. In a 2013 survey of 456 U.S. biobanks, 78% (n = 356) were affiliated with an academic institution. 8 However, since biobanks are inconsistently defined in the research community, with variations in size, mission, or extent of associated data,1,9,10 one could argue that any collection of biological samples for research is a biobank, and therefore a large academic organization could house hundreds to thousands of biobanks. At the lead author's institution, 96% of the roughly 2500 active human subjects' research protocols included a biobanking component at the time of this analysis. If we estimate that the other 356 academic institutions surveyed by Henderson have only half the active human subjects research protocols (1250), we conservatively speculate that there could be at least 427,200 academic biobanks in the United States (356 × 96% × 1250). This proliferation of biobanks has led to a call for standardization as researchers have recognized that biobanking often represents an intersection between clinical care and research and the tracking chain of custody and preanalytical variables in a standardized searchable manner is essential for quality biobanking, and hence, good science. As previously asserted by Carolyn Compton of the National Cancer Institute (NCI), biospecimens are the “center of the personalized medicine universe,” and poor and/or unreproducible results can lead to the wrong answers with unprecedented speed. 11 Without quality specimens and well-documented annotation, one can neither differentiate between a null result and noise nor be confident of the veracity of test results, 12 wasting both the precious donations made by participants as well as financial resources.
In the last decade, interest in these issues has intensified and publications emphasizing the need to standardize biobanking practices and procedures have proliferated.13,14 ISBER and the NCI developed and published best practice documents that included guidelines regarding sample collection, processing and storage, quality, as well as legal and ethical issues related to consent and governance.15,16 In 2012, the College of American Pathologists (CAP) began the United States' first Biorepository Accreditation Program, aiming to “improve the quality and consistency of facilities that collect, process, store, and distribute biospecimens for research.” 17 However, the biobanking terminology (i.e., data elements and their definitions) is not specifically prescribed by these U.S. resources. In Europe, the Biobanking and Biomolecular Resources Research Infrastructure (BBMRI 18 ) developed a comprehensive source of information about existing biological sample resources and developed the informatics infrastructure to link existing biobanks. They defined 52 attributes to serve as the minimum data set for biobanks and studies using human biospecimen, called MIABIS 19 (Minimum Information About BIobank Data Sharing).
In the last several years, numerous companies began offering software to track and manage biospecimens. Before these platforms were available, biobanks relied on homegrown databases, spreadsheets, and paper logbooks that were perceived as more affordable and accessible than relational databases and commercial products. However, as requirements for chain of custody, inventory management, and sample documentation have become more formally defined, more robust tools have become the norm. Commercial software products that allow users to customize data fields are attractive to users, but sometimes result in idiosyncratic definitions, leading to difficulty with queries and reports. Cancer centers and academic medical centers are beginning to invest in enterprise software solutions to consolidate biobank databases; nonstandard, inconsistent data elements and definitions can lead to misunderstandings that confound research results. Thus, rigorous data standards are becoming expected and are being encouraged, if not required by government sponsors in solicitations. Although standardization of disease-specific data elements has progressed,20,21 at the time this project was undertaken, very little work had been done to standardize data elements for biobanking and biospecimen science.
The Biobanking Data Element Standardization Project took place in the context of a larger centralized biobanking effort that began in 2012, in which our institution sought to strengthen and harmonize its many diverse biobanking entities. Institutional funding was secured to purchase, configure, and implement an enterprise-wide biobanking information management system (BIMS). At the outset, a policy was established that required all users to use a common set of data elements with standard definitions and prespecified valid values for discrete data elements, regardless of which BIMS was purchased. This was important for several reasons shown in Table 1. To enforce this policy, user roles and privileges in the BIMS were designed such that only central administration could add new terms that had been fully vetted and approved. In this study, we describe the consensus-driven process and how multidiscipline stakeholder engagement ensured that the resulting terms met users' needs.
Materials and Methods
The methodology established by a data standards project from the National Institutes of Health (NIH) Roadmap Program was leveraged for the Biobanking Data Element Standardization Project. The NIH projects described by Nahm et al. 22 developed a methodology for identifying, defining, and standardizing therapeutic area data elements. The process involved creating an expert team to review clinical content and an informatics team to provide structure and develop data elements based on International Organization for Standardization (ISO) 11179 standards. 23 For this project, a data element is described as a standard term, its definition, and set of allowable values. These methods were adapted and a comprehensive project plan was designed over several months that defined the organizational and leadership structure, communication plan, data element approval process, and member responsibilities. The plan served as a reference document and helped team members maintain focus toward an achievable goal. In the first phase of the project, described in this article, the terms were identified and defined. The identification and defining of allowable values are to be addressed in a later phase as individual biobanks are implemented on the BIMS platform.
Organization and leadership
A terminology Oversight Committee led and managed the overall initiative (Fig. 1) and consisted of four individuals: the Director of the Duke Biobank served as the chair and the other three individuals were the BIMS product manager, a terminologist, and an experienced biobank manager. The Oversight Committee directed the vision and established and governed the Biobanking Data Element Standardization Project, was responsible for final decisions and deliverables, and championed the project with institutional leadership.

Diagram of project organization and leadership.
Five working groups (WGs) were established by the Oversight Committee by inviting qualified individuals to participate based on their biobanking, scientific, or informatics experience, planned future use of the BIMS, and ability to work as a member of a team. Each WG was appointed an informatics lead and a facilitator. Facilitators scheduled meetings, recorded meeting minutes, documented decisions, and handled communication with the other WGs and the Oversight Committee. The facilitators from each WG met regularly to review progress and resolve problems such as unclear or overlapping scope, duplicate terms, and conflicting definitions. They then reviewed all the terms approved by the WGs before sending them to the Oversight Committee. The informatics leads provided advice consistent with informatics conventions, such as proper data management techniques, data element structure, and existing authoritative sources.
Definition of scope
The Biospecimen Lifecycle (Fig. 2), as established by the Biospecimen Research Network of the NCI, 24 was used to define the general scope for the project. The Lifecyle is defined by all the activities and processes between consenting of a participant, through sample collection, processing, storage, tracking, analysis, and restocking. For practical purposes, the scope for each WG needed to be defined in such a way as to allow the effort of each WG to leverage, but not duplicate, the work of the others. The cumulative effort of the five WGs encompassed the Biospecimen Lifecyle; however, the processes focused on by each WG differed slightly from those defined in the Lifecycle (Table 2).

Lifecyle of the biospecimen as defined by the biospecimen research network of the National Cancer Institute (reprinted with permission).
Data element identification, process, and communication
The Oversight Committee provided the potential sources of data elements after consulting with in-house informaticists and other internal biobanking stakeholders, and after reviewing the literature and previous work done by standards organizations, including other authoritative sources such as the NCI's Cancer Data Repository and Registry (caDSR). 25 The existing data elements used in each legacy system were also carefully considered to ensure that all terms would be represented in the data elements and associated terminology. With an eye to improving biospecimen annotation, data elements regarding key preanalytical variables related to biospecimen quality and “fit for purpose” were identified in publications to improve biobanking practices, even if they were not currently in use in any participating biobanks.26,27 All authoritative sources are described in Table 3.
BIMS, biobanking information management system; BRISQ, Biospecimen Reporting for Improved Study Quality; caDSR, Cancer Data Standards Registry and Repository; CAP, College of American Pathologists; CBM, Common Biorepository Model; IRB, Institutional Review Board; MIABIS, Minimum Information About BIobank data Sharing; NCI, National Cancer Institute.
The Oversight Committee provided the WGs with an initial list of data elements to help clarify scope and promote discussion, and the activities of each WG were integrated to facilitate progress. Each WG compiled a draft of their internally approved candidate data elements for review by the informatics leads. Based upon the information provided by the WGs and the review by the informatics leads, the Oversight Committee harmonized terms, concepts, and definitions provided by the individual WGs. This was done to ensure consistency and resolve conflicts. Once the work of the WGs concluded, the terms were put into a domain model, which helped to identify gaps. All terms were then distributed to the institutional biobanking community and other affiliated researchers for a 30-day internal comment period. When the commercial BIMS was purchased, out-of-the-box terms in the commercial BIMS were identified, and engagement with each bank during detailed functional requirements specifications and data migration resulted in additional terms. The Oversight Committee managed the final terms and definitions and data types (Fig. 3).
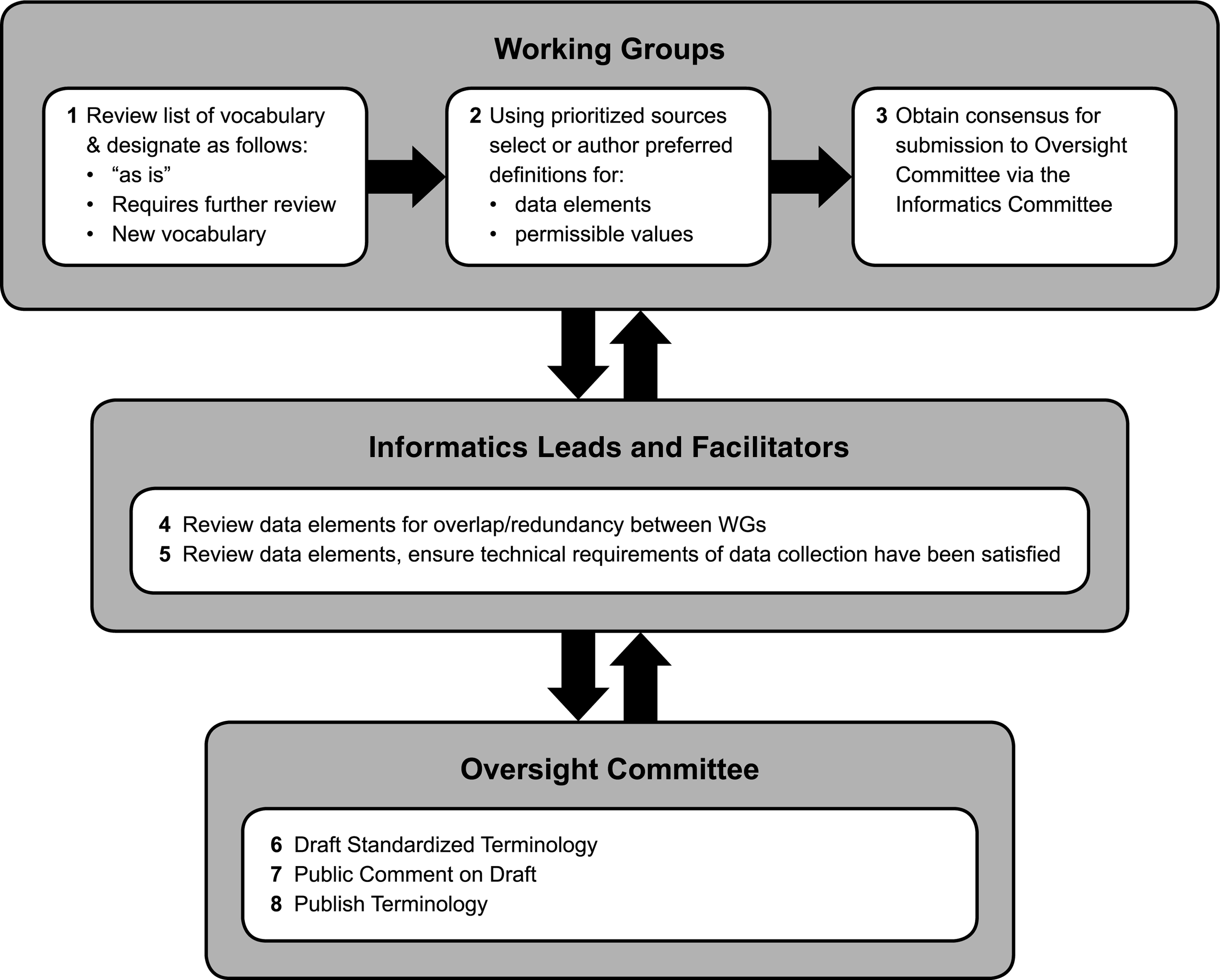
Data element development process.
Results
In total, 361 common data elements were established and approved by the Oversight Committee during the Biobanking Data Element Standardization Project (Supplementary Appendix 1; Supplementary Data are available online at www.liebertpub.com/bio). Each data element was assigned to a general category, a definition, and data type. Allowable values are to be defined in a later stage as the biobanks are implemented in the BIMS. The completed data elements are not represented in a data model, and therefore relationships are not specified between them. The data elements are grouped into seven general categories described in Table 4.
Discussion
Challenges
One goal of creating an enterprise-wide biobank is to leverage multiple biospecimen resources. In the context of many independent diverse biobanks, this necessitated the use of common data elements and terminology. The development of standard data elements and associated terminology demands training and commitment and is a meticulous and multistage process. Subject matter experts as well as informatics experts must be committed to ensuring their mutual understanding of each element so that an appropriate consensus can be reached. The scope can be difficult to define when topics overlap, impeding progress. These considerations, among others, presented both challenges and opportunities.
A common terminology reduces the time-consuming activity of mapping one term to another, which in turn reduces loss of information. Similar terms may not have the same meaning, leading to incorrect use of data and information. Indeed, conversations around the capacity and size of our institution's many biobanks clearly illustrated the challenge of using a nonstandard language. The seemingly simple question of “how many samples are in your bank?” could not easily be answered without further description of what was meant by “samples.” We found that at our institution, we had no less than five definitions of the word “sample.” At the completion of the terminology effort, these five definitions became five distinct data elements (Table 5). In addition, basic terms such as “sample” needed to be defined by one WG before another WG could develop and define terms within their purview.
Agreement on critical aspects such as format and structure is time-consuming and should be considered when planning. In fact, the entire process took almost twice as long as the 9 months that were predicted. Change is difficult; therefore, it is essential to engage stakeholders and obtain their input, buy-in, and support. A delicate balance was required to ensure essential stakeholders were included, while also keeping the groups small enough and adequately engaged to complete activities. Groups that were comfortable with structured data elements with specified valid values will likely have an easier time adapting to a new data element set. On the other hand, those whose terminology evolved over time without any thought to consistency may welcome structure and standardization, having experienced frustrations with inability to query, use, or combine data or samples across studies.
The scope for WG 5 included clinical data elements that could potentially affect the suitability of a sample to be selected for downstream analysis. There were strongly voiced differing opinions as to the scope, and therefore the activity was postponed until after nearly all data elements from the other WGs were complete. The diverse research areas of the WG members (e.g., cancer, Alzheimer's disease, and population studies) was a major factor in this discussion; collecting all of the relevant clinical data elements for these different diseases would have drastically affected the WGs' scope. In addition, there was considerable disagreement regarding to what extent the BIMS should manage clinical data; some felt that all clinical data should be stored in the BIMS and others felt the exact opposite. Furthermore, at our institution, the existing Enterprise Data Warehouse32,33 holds the complete clinical data that are linkable to samples, and duplicating those data did not make sense or add value to the initiative. In the end, the 56 clinical data elements that were identified and defined will likely not be managed in the BIMS, but tracked in other database systems.
Successes
Having a collaboratively established standardized data element set and associated terminology helped tremendously during the data migration process of incorporating each biobank into the BIMS, since the preexisting data elements were considered during the standardization process and the biobank members were also members of each WG.
During the project, several articles were published about important biobanking preanalytical variables. The Oversight Committee took them into consideration to identify gaps and help prioritize decisions, as previously described. For example, Robb et al. 26 identified 170 biobanking preanalytical variables with a priority score and an indication as to the scientific impact if not recorded. The Oversight Committee reviewed the article and identified many terms that were already on our list, terms to include, and many that we were not feasible to include due to logistics (e.g., third party clinical service providers) or the unavailability of information. Hence, the common data element initiative was informed by availability and accessibility of data in the real world.
Future work
Our resulting biobanking data elements are being integrated into the Ontology for Biobanking (OBIB 34 ) and the biobanking Informed Consent Ontology (ICO), which are both available on GitHub.35,36 Both OBIB and ICO are being developed by a cross-institutional, multidisciplinary collaboration. Ontologies contain formal naming and definition of the types, properties, and their interrelationships terms. Linking standardized data elements to rich ontological knowledge sources allows those querying or using the data to answer additional questions beyond those answerable from the data alone by reasoning over the relationships encoded in the ontology.
Conclusions
Biospecimens have become a highly valued resource and detailed annotation of these samples in a standardized manner is becoming increasingly important for academic organizations. It is clear that the development of the standardized biobanking data elements and associated terminology added value to the BIMS initiative at Duke. Development and use of common and standard data elements and associated terminology are also increasing elsewhere across healthcare and research domains as the need for quick and scalable information retrieval rises. Organizations must make the decision to adopt a common or standard terminology to facilitate the exchange of date or map to an ontology that is outside the information system. Both approaches have merit; similarly, they both take leadership, resources, significant time, and effort.
Footnotes
Acknowledgments
Special thanks to Blair Chesnut for creating the terminology management tool. Also, special thanks to the working group members: Diane L. Satterfield, David Layfield, Lawrence Whitley, Mike Leonard, Tom Burke, Dawn E. Bowles, Eric Lipp, Lori Hudson, Michelle Smerek, Gary Archer, Seth Fehrs, Jessie Tenenbaum, Carol Hill, Pankaj Agarwal, and Paul Debien. Research reported in this publication was supported by the National Center For Advancing Translational Sciences of the National Institutes of Health under Award Number UL1TR001117. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Author Disclosure Statement
No conflicting financial interests exist.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.