
Abstract
Legal and ethical demands for more transparent and strict data protection measures to enhance research participant privacy have grown with an increasing number of human biobanks providing biomaterial collections long term for unspecified future research questions. The design of a data protection scheme that minimizes the risk of donor reidentification and promotes biomaterial and data use in research is a big challenge to all kinds of human biobanks. Yet, there is a lack of publications which address this basic building block of a biobank. In this study, we present the data protection concept of our project driven, stand-alone biobank, focusing on meeting two biomaterial and data management areas simultaneously: operation of primary research projects involved in sample collection and long-term provision of biomaterial for future research purposes. The concept is based on national and international laws and ethical demands. Since the presented measures are transparent and basic, they should encourage biobanks in defining their own data protection concept and be easily transferable to different legal requirements.
Introduction
Biobanking,
However, the extent to which stand-alone biobanks are addressed by TMF is limited to biomaterial and data administration after samples and data have been provided by external suppliers. The issue of biobanks operating a multitude of clinically independent primary research projects themselves is not covered.
Existing publications concerning biobanks' data protection methods are rare and mainly limited to meta-biobanks or to multicenter clinical research networks, concentrating on more general organizational aspects combined with privacy protection and ethical issues.18,19 Certain aspects of data protection in clinical research networks, in particular technical methods concerning the separation of identity data from research data, were discussed by Müller and Thasler 20 and Leusmann et al. 21
Yet, in 2009, the large majority of 126 European biobanks from 23 countries, which participated in a survey, are stand-alone biobanks. 11 Internationally, most biobanks originate from “left-over” samples of primary research projects. 2 Therefore, it seems important to define rules that support the establishment of comprehensive privacy protection procedures of stand-alone biobanks.
The research Institute for Prevention and Occupational Medicine (IPA) is a facility of the German Social Accident Insurance (DGUV). Its project-driven biomaterial collections are physically stored in IPA's central biorepository, while biomaterial storage and data are managed by project staff, and technically supported by the IPA Biobank, as long as these projects are running. After research projects have been completed, the IPA Biobank is responsible for providing biomaterials and data centrally for open medical research projects in public interest. As it is a basic requirement of GDPR to collect, process, and use as little personal information as possible, the IPA Biobank needs to fulfil this requirement not only under the conditions of the lively internal exchange of biomaterial and data in primary research projects but also in subsequent long-term provision of biomaterial and data for unspecified secondary research questions. Therefore, IPA established a data protection concept according to TMFs generic solutions, which has been discussed and positively evaluated by the TMF data protection working group (“AG Datenschutz”). In this article, we introduce the peculiarity of our two-level concept and the transfer from one level to the other to support considerations of other biobanks in developing their data privacy measures for long-term provision of biomaterials and data.
Materials and Methods
IPA focuses on health protection at the workplace and in educational establishments. Occupational questions are answered in five centers of competence: Medicine, Toxicology, Allergology/Immunology, Molecular Medicine, and Epidemiology. Project-driven biomaterial collections amount to samples from more than 10,000 research participants to date, generated at a variety of sample-collection sites (e.g., hospitals, medical practitioners, and external companies). The aims of IPAs biobank in long-term provision of biomaterials are to ensure that:
-the ethical and legal regulations are applicable, observed, and complied with; -the personal rights of the donors are respected, in particular with regard to privacy protection; -biomaterial and data are processed and stored at a consistently high level of quality; -research projects that use biomaterials from IPA Biobank have a privacy policy and a positive rating from the responsible Ethics Committee; -transfer of biomaterial and data is performed on the basis of uniform and comprehensible principles.
Two-level data protection requirements at IPA Biobank
The most relevant requirements for IPA Biobank to enhance research participants' privacy are given in Table 1.
Most Relevant Requirements for Institute for Prevention and Occupational Medicine Biobank to Enhance Research Participants’ Privacy
AnaDB, analysis database; RDB, research database.
At IPA, coding of data is preferred over anonymization, since it allows research participants to withdraw consent and to ask for information about stored data. On the contrary, it enables the IPA Biobank to request for further data and to return health-relevant incidental findings.
The listed requirements relevant to ongoing primary research projects have already been put into practice for a long time. Moreover, data minimization principles have been assessed for relevance and adequacy through the Ethics Committee for each research project. In ongoing research projects, a central web-based biomaterial information management system (BIMS) supports project-internal management of randomly coded biomaterials linked to donor's ID and examination number. Data access is restricted to task-dependent views. Within BIMS, descriptive data, for example, age, gender, clinical, and questionnaire data, are limited to a small subset to allow the most common biomaterial queries by internal researchers.
Biomaterial and data provision for open secondary research purpose allow to be generalized and centralized across all data records of terminated primary research projects. Not least because data records stored in this context cannot be minimized to the purpose of a predefined future usage, IPA planned for both strengthening requirement 4 and additional privacy enhancing measures to preserve maximum value of data, while lowering the risk of reidentification (Table 1, requirements 5–7).
To list another aspect, authorized cross-over data-base queries or transfer of data to external researchers bear a nonzero risk for reidentification given by the combination of very large datasets or datasets containing genetic data. In these cases, k-anonymity tools need to be involved, which increase the probability that the information given in a record is not distinguishable from at least (k − 1) other record(s) in the same table or database. 22
Separated data-bases in long-term biomaterial provision (requirements 5–7)
Biomaterial information management system
Within BIMS, each biomaterial record is linked to its sample-container's LabID and also to an additional ID of its originating biomaterial sample (parent sample ID [PSID]). PSID serves to distinguish different sampling times of the same biomaterial.
Analysis database
Analysis data directly generated from biomaterial (e.g., laboratory values, pathological findings, and research results) are administered in the analysis database (AnaDB) linked to the LabID.
Image database
Image data of tissue sections are linked to the LabID, which can be hidden from sight when viewing the images within the database.
Research database
Within the research database (RDB) the following donor-specific records are administered:
Encrypted donor identifier (eDonID), resulting from a second coding of the first pseudonym; Each donor's personal data (e.g., lifestyle, diseases, occupation); The transformed parent sample ID (PSIDtrans) of each donated biomaterial; Each donor's biomaterial usage options (e.g., no consent in genetic research).
Data warehouse
Collective, aggregated information generated from RDB, AnaDB, and BIMS is stored in a data warehouse. Querying the data warehouse allows, for example, the creation of (chronological) reports or the conduction of feasibility studies.
Administration database
The administration database manages users, roles, and the link between the PSID and its unique transformation (PSIDtrans) to enable a linkage between BIMS and RDB. Moreover, it keeps a link between each donor identifier (eDonID) and eDonIDx, which is the result of a third coding. EDonIDx is assigned to data passed on to external researchers. The retention of this link allows the return of research results to the biobank.
Table 2 summarizes data distribution and organizationally separated database access to selected different databases involved in the long-term storage scenario.
Distribution of Information to the Most Relevant Databases at the Level of Long-Term Storage
Different shades of gray background color differentiate role- and task-specific database accesses.
BIMS, biomaterial information management system; PSID, parent sample ID; SOPs, standard operating procedures; SPREC-Code, sample PRE-analytical-code.
Role-/and task-based coarsened database views in long-term biomaterial provision (requirements 4 + 8)
All separated databases are connected to an IT-infrastructure and accessible from a central control server, which is used for all role-specific tasks at the various levels.
To lower the risk of a donor's potential reidentification in data base queries, different data views are offered, which consist of coarsened views of the raw data, for example, age (year) is coarsened on (5-year intervals) as demanded by requirement 8 (two-anonymity).
Transfer of data to long-term storage databases
Data transfer to the IT-infrastructure designated to long-term provision of biomaterial and data need to be carried out after a research project has been completed, and data have been finally proofed and cleaned by the primary research project's members.
Transfer of data to sample-related databases
Organizational biomaterial data (“sample data”) associated with the LabID are transferred to the BIMS installation serving long-term storage after both the assignment of random IDs (PSID) to all parent samples and the deletion of donors' pseudonyms. An allocation list between the PSID and a unique transformation (PSIDtrans) is generated.
Analysis data are transferred to the AnaDB after quality assurance within the AnaDBtemp (see frame “temporary databases” in Table 3). Since all sample-related databases do not keep donors' pseudonyms, no pseudonymization service needs to be integrated into these transfer processes, as shown in Figure 1.

Flowchart of the biomaterial data transfer to the level of long-term storage.
Aim and Function of Temporary Databases
Transfer of data to the RDB
Transferring donors' research data to the RDB, the pseudonymization service generates symmetrically encryptions of donor's IDs into coded donor identifiers according to the following procedure (Fig. 2):
The research project's database manager starts a transaction that includes a request to the pseudonymization service and transmission of the data to the central RDB, including unique transaction numbers for each donor's ID and examination. The pseudonymization service creates the PSID and the eDonIDs and sends them to the database manager of the central RDB, combined with the transaction numbers. After data standardization and—if possible and reasonable—data minimization within the temporary research database (RDBtmp) (Table 3), data are transferred to the RDB and deleted in the RDBtmp.
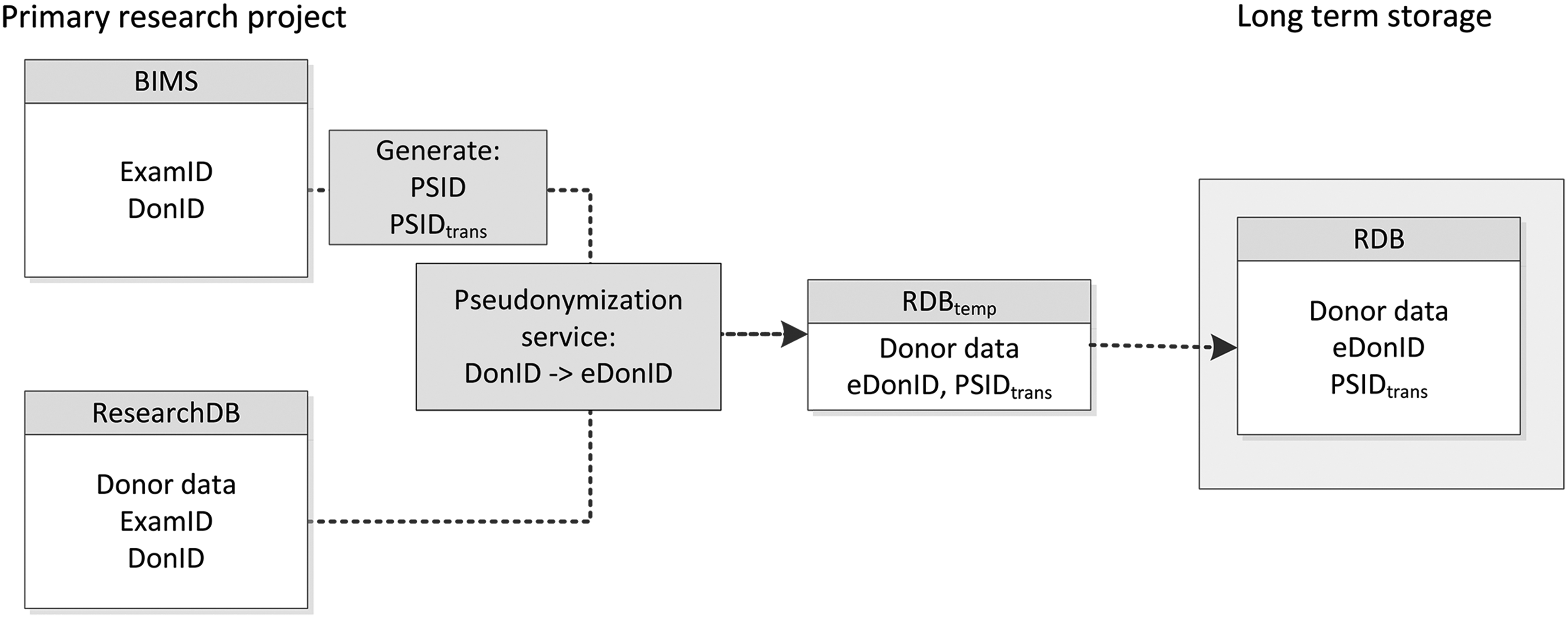
Flowchart of the phenotype data transfer to the level of long-term storage.
Results
We present main features of the data protection scheme of our project driven, stand-alone biobank. It comprises a set of techniques for minimizing risks of privacy breaches both in data base access and in data transfers. Our concept focuses on two levels: to protect informational privacy at level 1 (ongoing primary research projects), techniques such as coding as well as minimization of personal data are applied. At level 2 (sample hosting for secondary research), the protection of informational privacy is enhanced by several additional central measures, for example, double coding, data separation, multiple pseudonyms, and reducing the precision of attribute values in data base queries and in data transfers to secondary research purposes. An important part of the concept is formed by the standardized data transfer from level 1 to level 2. This includes a step in which data are selected, curated, and coarsened in temporary databases.
A summary of the incorporated main data protection measures for coded data is given in Figure 3.

Summary of IPAs main data protection measures for coded data. IPA, Institute for Prevention and Occupational Medicine.
Data protection measures in ongoing research projects have already been established at IPA, while measures of level 2 will be implemented in the near future.
Discussion
IPA's biobank belongs to the huge majority of biobanks providing human biomaterial of primary research projects for unspecified future use. 2 According to the GDPR and because research participants give an open consent, biobanks must base their actions on a transparent concept to prevent donor's reidentification by possible attacks and have to be able to account for the processing of personal data at any time. We introduced the main features of our data protection concept, to assist other biobanks in providing their biomaterial and data for secondary research questions, especially when transferring samples and data from a project driven sample collection into a long-term preservation biobank. Our solution is based on generic concepts by TMF, applicable laws, and ethical considerations. It considers the demand for individual and flexible data management in ongoing primary research projects, as well as the need for more strict and standardized management of data in long-term biomaterial provision for secondary research targets.
Measures are designed to be strong to keep reidentification risks low and build a basis for future data and biomaterial exchange with other biobanks. The usage of multiple separated databases increases the amount of required hardware and manpower, but largely enhances data protection—even if there is an illegal attack on one database, privacy is preserved at a high level.
As international biobank standards become adopted, biobanks now adhere to best practices of, for example, TMF 13 and the International Society for Biological and Environmental Repositories (ISBER). 24 Operational and database measures that provide high levels of protection for participant privacy and data within the biobank often exceed the levels of protection of their medical records. While examples of how to breach anonymity and achieve data linkage between research datasets have been pursued and published, this is in fact very difficult to achieve and is a very unlikely event to conceive of occurring in practice. Biobanks that only store a few biomarkers and potential outcomes for basic research are less likely to pose a significant privacy risk to participants than those that store extensive survey data, multiple patient factors, and genetic data; even more if their scope is on rare, hereditary, or stigmatizing diseases. The considerations in this concept can be helpful for all kinds of biobanks, but may be most applicable to biobanks storing comprehensive or critical data records.
Limitations of the two-leveled concept include not having samples and data of primary research projects being provided for secondary research purposes before the projects are completed, and data have been transferred to central databases for long-term storage.
Setup and maintenance of an appropriate infrastructure requires additional efforts in software development and configuration. We do not know of any complete software package, and, consequently, many biobanks develop their own programming. 25 Software solutions have to provide tools for data standardization, data validation, and data confidentiality, such as coarsening of many different data types. These tools add a lot of flexibility to the database infrastructure of the biobank, which allow matching new requirements, such as new data protection rules or new types of data. The research concerning efficient data protection measures is ongoing. The concept offers a lot of flexibility to react to future developments. This could be particularly interesting if, in the future, the deanonymization risk of genetic data increases, and in this context, even stricter measures may be required. 26
Experiences in implementing the central structures of our data protection concept can successively be incorporated into the ongoing primary research project and promote an increased use of technical and organizational standards at this level. As a consequence, the gap between the two administrative scenarios may gradually narrow.
Footnotes
Acknowledgments
We thank members and employees of the TMF work group “AG Datenschutz” for their support in establishing the presented standards of IPAs biobank.
Author Disclosure Statement
The authors do not declare any conflict of interest. As staff of the Institute for Prevention and Occupational Medicine (IPA), the authors are employed at the “Berufsgenossenschaft Rohstoffe und chemische Industrie” (BG RCI), a public body, which is a member of the biobank's main sponsor, the German Social Accident Insurance. IPA is an independent research institute of the Ruhr-Universität Bochum. The authors are independent from the German Social Accident Insurance in design, responsibility for data analysis and interpretation, and the right to publish. The views expressed in this article are those of the authors and not necessarily those of the sponsor.