
Abstract
Introduction:
The establishment of a biobank requires specific expertise along with relatively expensive infrastructure and appropriate technology. This causes certain challenges in biobank implementation for research in low–middle-income countries. Biobank development with established specimens and data collection (legacy collection) was an approach used in the Faculty of Medicine, Public Health and Nursing, Universitas Gadjah Mada. This approach aimed to identify the resources available at present, while providing nontechnical information for further development of a centralized biobank.
Materials and Methods:
Retrospective modeling was done in 2015 by recruiting existing specimen collections and their associated data. The steps were as follows: (1) informing research stakeholders through discussion with experts and stakeholders; (2) identifying specimen collections to be used; (3) determining the system, infrastructure, and consumables needed; (4) determining inclusion criteria; (5) building an in-house database system; (6) organizing data and physical specimen collections; and (7) validating data and physical sample arrangement. All technical procedures were built into standard operating procedures.
Results:
The model included specimens from one −80°C freezer. The associated data included demographic, clinical diagnosis, and physical sample information. Samples came from six studies, collected between 2001 and 2014. A web-based database was built based on the MySQL programming system. Information on biospecimens from a total of 4196 subjects collected in 11,358 vials was entered into the database, following physical rearrangement of vials in the −80°C freezer with one-dimensional barcodes taped to vials, boxes, and racks. A validation test was done for data concordance between the database and physical arrangement in the −80°C freezer, showing no discrepancies.
Conclusion:
This report demonstrated current technical and nontechnical insights to further develop a centralized biobank for health research at an academic institution in Indonesia.
Introduction
The drive to find correlations between diseases and biological determinants has created an avenue for the development of disease biomarkers and innovative treatments to achieve minimum development goals 5. 1 Furthermore, in the era of development of personalized medicine, biobanks are developed as hubs to connect investigators with invaluable resources that are well examined, well characterized, and with appropriate subjects’ information. 2
Collection of biospecimens and their parallel data has long been done in academic research. 3 A famous example is the development of the HeLa cell line at Johns Hopkins Hospital in 1951, which also generated legal and ethical discussions. Academic-based biosample collections are typically characterized by responsibility solely assigned to the principal investigators’ specific interest. This type of collection is often hampered by limited support and inconsistent funding. 4 Over the last few decades, biobanks have emerged as a source of complex science, not only dealing with technical aspects of standardized collection of biosamples and their parallel data but also posing challenges in the field of social normative regulations and legislation. 5
The standard operating procedures (SOPs) of biobanks have relied on a set of guidelines developed based on empirical observations. Recent reports6,7 reviewed the technical aspects concerning sample collection, processing, storage, distribution, and sharing of specimens as well as related data collection and management issues in modern biobank practices. Added to this, ethical and legal concerns such as informed consent, patient privacy, and intellectual property have been included. Different features have been observed between biobanks in high-income countries compared with low- and middle-income countries (LMICs). 8
Many best practices are available online, supporting information sharing, including those of the National Cancer Institute (NCI), 9 the International Society for Biological and Environmental Biorepository (ISBER), 10 and the Canadian Tissue Repository Network (CTRN). 11 The International Agency for Research on Cancer (IARC) has recently issued Common Minimum Technical Standards and Protocols for Biobanks for Cancer Research, 12 which summarize years of collaboration with LMICs and managing their international networks. With regard to different standards used in different organizations, the trend for a unified quality system has stimulated the development of ISO/DIS 20387 on Biotechnology–Biobanking–General requirements for biobanking, 13 showing how a biobank organization is able to operate competently for the provision of biological resources (biological material and associated data) of appropriate quality.
Implementation of standards in the operation of biobanks requires time and effort to build a comprehensive system, especially in a resource-limited environment. 14 There are very few reports discussing the procedures for setting up a biobank. The Chinese biobank initiative was started in 1994 when the Chinese Academy of Medical Sciences made the initiative for establishing a biobank of immortalized cell lines of Chinese ethnic groups, and this initiative has driven the development of legislation, best practices, and state-funded biobanks. 15 On the other hand, a prospective thyroid biobank in Nice France was set up based on criteria that were already defined and added to the chain of biological sample collection. 16 Setting up a biobank may also be initiated by collaboration of more developed with less developed institutions based on similar interests, for example, the H3Africa (Human Heredity and Health in Africa) consortium championed by the African Society for Human Genetics (AfSHG) in partnership with the Wellcome Trust, United Kingdom, and the National Institutes of Health (NIH), United States, which are currently supporting the establishment of biobanking activities in Africa primarily in support of health-related genomic research. 17 The European, Middle Eastern, and African Society for Biobanking and Biopreservation (ESBB) working group and the Bridging Biobanking and Biomedical Research Across Europe and Africa (B3Africa) consortium 18 have emphasized the need for networking to support the development of biobanks.
The triple burden of LMICs means that in addition to having a lack of resources, these countries also suffer from both infectious and noninfectious diseases. LMICs account for 90% of the global health burden, while contributing minimally in the research to overcome challenges of this burden. Indonesia has the fourth largest population in the world. Economic growth and unique population characteristics in Indonesia have supported the growth of research, particularly in medical science. Data collections are mostly kept private, redundancy of collections is high, and low numbers of samples are commonly found in research publications, as in most biobanks in LMICs. 19 More importantly, the lack of inclusion of diverse populations in large-scale studies sometimes results in unnecessary extrapolation, thus posing further challenges in addressing global health concerns. Additionally, publication agendas have often affected the results.
In addressing the above-mentioned conditions, the biobank was initiated in the Faculty of Medicine, Public Health, and Nursing, Universitas Gadjah Mada Yogyakarta (FK-KMK UGM), Indonesia, and started in 2014. The purpose of the biobank was to establish a research infrastructure in (bio)medical science to provide good quality service within limited resources while considering nontechnical issues. The biobank development was based on legacy collections coming from several principal investigators (PIs) (specimens and data) and aimed to assess the capacity of current resources at the institution. This report is the first phase of a centralized biobank for health research development at our institution and provided lessons learned from technical and nontechnical perspectives, which became resources to further develop biobank services. This is the first study reported from Indonesia, which may form the basis for development of centralized biobanks for research in academic environments within LMIC settings.
Materials and Methods
The study was conducted in 2015 at the FK-KMK UGM. Ethical permission for the analysis of data collection was obtained from the Medical Ethics Committee at FK-KMK UGM.
The biobank development team consisted of five academic staff members (coordinator, members [system, database builder, SOP development]), who worked part-time and voluntarily, as well as one dedicated biobank laboratory analyst. The development process comprised a conception phase (240 hours over 6 months) and technical development phase (960 hours over 6 months); which was further broken down into several steps:
Discussion with experts and stakeholders
A series of workshops and discussions was conducted with FK-KMK UGM staff, including researchers, faculty management, and ethics committee members, to identify the need for a standardized specimen collection as well as the nontechnical aspects surrounding biobank activities. Participants were informed about biobank terminologies and common practices. The workshops were also aimed to identify needs, gaps, and possible solutions for the current situation, and the plan for this study was drafted.
Identification of specimen collection to be used
The team decided to use the already existing collection (legacy collection) stored in one −80°C freezer located at a centralized research facility, the Molecular Biology Laboratory, FK-KMK UGM. All collections included specimens from cancer-related studies.
Determining infrastructure and consumables needed
Based on the drafted plan, infrastructure and consumables were identified. The infrastructure needed was focused on organization of physical specimens and recording them in an electronic database.
Determining inclusion and exclusion criteria
The criteria for inclusion in the study were as follows: (1) availability of specimen collections in the −80°C freezer; (2) agreement of PI to be included in the study; and (3) availability of minimum database variables for each project recruited. The minimum variables included demographic information (name, sex, and age), clinical data (hospital medical record number and clinical diagnosis [for cancer patients]), pathological record number (for cancer), disease status, project identification (name of PI and name of project), specimen information (date of collection, specimen type, date of processing, and the intended analyte), and location of specimens in the freezer (rack, box, row, and column of the box). Furthermore, some of this information was used as a unique identifier and printed on the label that was taped to the specimen vials. Exclusion criteria were as follows: vials without identification, any vials that were empty or damaged, no associated data connecting with the vials in the −80°C freezer, and any vials dated before the year 2000.
Building the in-house database system
An in-house database system was built with attributes based on previously determined minimum variables. A template was developed in a spreadsheet file (using Microsoft Excel®), while enabling direct connection to the database that was developed with MySQL and the CodeIgniter framework.
Organize data and physical specimen collections
Following the agreement between the biobank team and PIs, data and specimen collections were retrieved and reorganized. First, the biobank laboratory technician identified the physical location of specimen vials in the −80°C freezer based on the original label and reorganized the specimen in uniform specimen boxes. The laboratory technician started the Excel datasheet with information from the original labels. The specimen list of original labels was further sent to each PI. In the process, PIs completed the Excel datasheet by providing the requested information, including demographic, clinical, and specimen information. The completed Excel datasheet was sent to the data manager, who uploaded it directly to the in-house database, which then automatically created a unique biobank number. Finally, the data manager sent the Excel spreadsheet back to the technician, containing unique biobank numbers using the original sample code as reference. The Excel spreadsheet was integrated into the BarTender label software (New Taipei City, Taiwan) to support a one-dimensional labeling system, so it could automatically generate barcodes for each vial. Additionally, for each specimen box and −80°C rack, labels were also created.
Validation of data and physical sample arrangement
A validation exercise was conducted to examine concordance between the physical specimen and the database, according to specific instructions written in the validation SOP as follows: (1) the laboratory analyst selected random samples from each sample box and recorded the barcodes and their physical location; (2) physical information was cross-checked with the Excel datasheet used by the laboratory analyst; (3) results were sent to the data manager; and (4) the data manager cross-checked the data with the MySQL-based database to check concordance.
If any discordance between the data and physical sample information was found, a correction was done accordingly.
Results
System and database development
The biobank model system is shown in Figure 1. The system includes three different interphases/functions: (1) laboratory analyst who entered the data related to physical characteristics and location of specimens using the Excel spreadsheet; (2) original PI (researcher) who provided demographic, clinical, and specimen information; and (3) data manager who managed and confirmed the data input into the system as well as developed a summary of information to be provided for PIs and other stakeholders when needed.
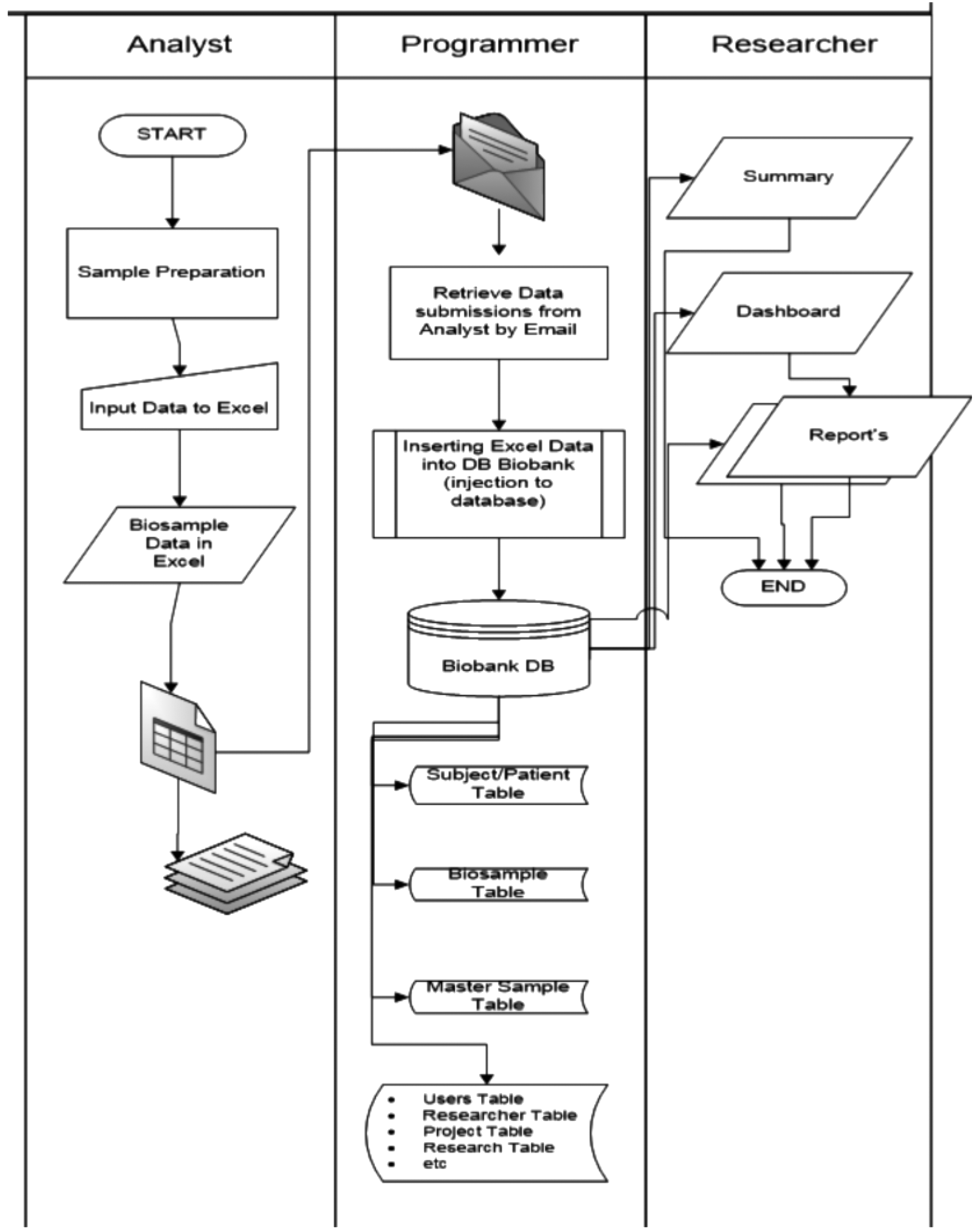
Flowchart of the in-house database consisted of three separate functions, laboratory analyst, data manager, and researcher/PI. The laboratory analyst collected data from PIs using an Excel datasheet, which was further uploaded into the MySQL-based system, basically containing demographic and clinical information of subjects as well as information of specimens. PIs could request a data summary in the graphic or table format. Each function has different data access levels. PI, principal investigator.
As a result of the defined flow, the following biobank infrastructure and consumables were the minimum items required for the retrospective model: (1) −80°C freezer (Thermo-Fisher Scientific); (2) locally purchased stainless steel racks; the freezer had four shelves: each was filled with three racks, each rack could be filled with 12 locally purchased laminated card boxes, and each of the specimen boxes could retain 81 1.5-mL vials; (3) plastic labels were specially purchased with the size of 2.5 × 2 cm2 that enabled taping on the surface of the 1.5-mL microtube with a V-shaped bottom; (4) printer for the one-dimensional label system was purchased; the printer was connected to a computer and could print preprogrammed barcodes based on the unique identifier assigned by the data manager; (5) computer for data management and programming for labeling; and (6) local server for data storage.
One-dimensional barcoding system
A one-dimensional barcode system was developed. The coding system included variables, as indicated in each digit and explained in Table 1, with an example presented in Figure 2. The unique number on the barcode represented the storage condition and position with 8 digits (upper codes), whereas the number below the barcode represented the type and code of specimens with 11 digits (lower codes). Barcodes of boxes and racks were represented as six and five first digits of upper codes, respectively, while vials had both upper and lower codes. A sticker with printed barcodes was taped onto vials, boxes, and racks in fixed positions to enable scanning, as shown in Figure 3.

One-dimensional barcode on the 1.5-mL vial. The barcode contained information related to storage condition (upper code) and specimen physical condition (lower code).

Biospecimen arrangement. Biospecimens in 1.5-mL vials with a V-shaped bottom were arranged in uniform card boxes. Twelve card boxes were arranged in one stainless steel rack. Each −80°C shelf contains three racks;
Dictionary to Numbers and Letters on the Upper and Lower Codes
Vials contain upper and lower codes; box contains six first digits of upper code; shelves contain five first digits of upper code.
MNC, mononuclear.
Inclusion of research projects and specimens
PIs of six different cancer studies agreed to participate in the study, with inclusion of specimens from 4196 subjects (76.2% cancer and 23.7% noncancer subjects) collected in 11,358 vials (summarized in Table 2). All specimens originated from clinical-based settings and were obtained from the Dr. Sardjito General Hospital, Yogyakarta (one of UGM-affiliated academic hospitals). Specimens consisted of tissue (1613 subjects), epithelial cells (786 subjects), mononuclear cells (259 subjects), whole blood in lysis buffer (1349 subjects), and buffy coat (726 subjects).
Summary of Samples Included in the Study
Validation
A concordance test between the database and physical specimen collection was done, which showed 100% concordance between the database and location of vials in the −80°C freezer. No data or vials were destroyed during this validation phase.
Discussion
The high burden of communicable and noncommunicable diseases in developing countries has not yet been fully answered with comprehensive research efforts. Despite many ethical and legal issues, lack of awareness, ineffective national and international collaborations, and major financial obstacles, the development and maintenance of research infrastructure, as well as biological diversity, continue to play important roles. 20 Considering the potential for significant contribution to research in disease treatment specifically and medical science generally, biobanks offer wide scientific value to diverse users (academic, commercial, and industry). 21 Many challenges have hampered the development of biobanks in LMICs,8,19 including Indonesia. Based on the needs for establishment of long-term storage systems and the present challenges of limited-resource settings, we propose the use of legacy biosamples (and their associated data) with the prospect to identify resources and challenges for establishment of biobanks in academic institutions. This was the first step to develop a biobank for health research in our institution. Described below are lessons learned, which needed to be addressed for establishment of the biobank for research at our academic setting.
Within this study, we included six available studies with the sample/data collection period of 2000–2014. Two studies had partial ethical permission and informed consent since the ethics committee in the institution was only active since 2005. One study did not include permission from the institution's medical ethics committee on data and sample collection for research intent. The reasoning for this particular study not obtaining specific ethical permission for research was that they used leftover tissue samples primarily used for histopathological diagnosis. Additionally, the informed consent form for tissue biopsy at our academic hospital included permission to utilize patients' material for learning objectives. It has been argued that the value of biomedical research benefits future patients and society as a whole, which justifies the use of archival tissues even in the absence of additional specific consent. 22
Common ethical understanding, locally, is that when information provided by the subjects may lead to identification of a person (i.e., biobanking, the use of specimen/data for research), a reconsenting process is needed. This is technically and financially inefficient in addition to the potential for breaching the subjects' privacy. Learning from this challenge, the use of uniform informed consent for long-term storage and use is needed. Several models were offered, including the use of broad informed consent, 23 which can protect subjects' privacy while providing the opportunity for yet unspecified research.
We were challenged by the absence of regulations regarding long-term specimen storage for research purposes in Indonesia. This dilemma requires an open discussion between the biobank community and policy makers. To fill in the legal gap, we are looking for the research management of the institution to develop clear regulations related to collection of specimens and their parallel data for long-term use.
Standardization of methods to collect and process specimens is necessary to ensure the quality of specimens because variables in specimen collection, storage, and analysis can potentially cause bias in study results. 24 However, the specimens used in this development phase were from past studies, therefore involving a variety of collecting and processing specimen methods. We also faced frequent power outages that require a more suitable infrastructure. In response, technical programs related to sample collection, transportation, processing, and storage are being established, including development of appropriate SOPs, information leaflets, and research on specimen quality.
It is important to establish a system that can accurately track specimens and manage patient information. Open-source databases are available either for clinical research or solely for biobank use. The most popular open-source databases are caTissue Suite from the US NCI and OpenSpecimen, which is an optimized version of Codebase. 25 These databases permit specimen processing, tracking, and annotating for quality assurance, as well as permitting a multiuser interface. While considering variables used in different known databases, we decided to develop an in-house system that was suitable to current needs and expertise, and which offers flexibility, and therefore is much less expensive. This decision allowed the system to be developed alongside the biobank. Additionally, existing biobank databases provide many possible variables, which at this stage are complicated. Based on the available resources at the institute, we developed a database using the MySQL system, an open-source relational database. MySQL was regarded as a reliable and easy-to-use system, suitable to the developer/programmer's expectations. We also used the CodeIgniter framework to manage the database because it is a lightweight, open-source web application framework that could perform faster than any other similar program. It had complete functions and could create an interface that was user-friendly.
The database was partitioned technically for different roles, for example, data manager, laboratory analyst, PI, or other researchers. Each function should have different levels of data access. The data manager should be able to access all information in the database; the laboratory analyst should only be able to access information regarding physical biosamples; and the PI should only be able to access individual information for their specific project without knowing the physical location of vials in biobank freezers.
The database could provide reports to PIs (Fig. 1) in the format of tables or graphs. For future use, a summary of data may be provided in a common portal (e.g., biobank website) to encourage scientists to collaborate with PIs who stored their collection in the biobank. This proposed approach came from results of a workshop on data sharing. PIs whose collections were stored in the biobank could be open for collaboration with other scientists while retaining their right to control access to the data/biosample collection. When scientists require more detailed data, they should collaborate with the PI whose collections are stored in the biobank. This approach emphasizes the capacity of the biobank not only to provide good quality sample storage but also encourages scientists to consider the long-term use of their collections and to collaborate with other scientists.
Coding of specimens was designed to be as simple as possible and provided needed information. The variables included in the database were the minimum variables that correlated with specimens (Fig. 2). Since legacy collections were used in the development, preanalytical data were varied. However, we expect to implement the Standard Preanalytical Code (SPREC) as a standard coding for the next biobank development phase with the objective of supporting effective and efficient interconnectivity and interoperability between biobanks.26,27 For prospective collection purposes, we further developed sample acquisition procedures allowing the documentation of specimen retrieval, interim storage, and preparation, enabling translation into the SPREC coding system. Additionally, regular checks for concordance of the database and physical data should be in place as part of the quality control of the system.
To conclude the effort, we were able to use legacy collections as the starting point to develop a centralized biobank for health research in a limited-resource setting. We realize that appropriate education for all research stakeholders plays a major role for biobank sustainability in the institute. We used existing infrastructure by adding small items with affordable cost. In the process, we gained valuable knowledge and confidence to move further in developing the prospective biobank, which will include not only technical aspects of data collection but also addresses ethical, legal, and social issues.
Footnotes
Acknowledgments
This study was funded by the Office of Vice Dean for Research, Postgraduate Study, and Collaboration FK-KMK UGM, Yogyakarta, Indonesia, for the financial year 2014–2015. The authors thank D. Purnomosari, D.K. Paramita, S.H. Hutajulu, and J. Fachiroh, the principal investigators, for permitting the use of their collections for this study.
Author Disclosure Statement
No conflicting financial interests exist.