
Abstract
Biomedical data bear the potential to facilitate personalized diagnosis and precision treatment. In the era of Big Data, high-quality annotation of human specimens has become the primary mission of biobankers, especially for tumor biobanks with large amounts of “omics” and clinical data. However, the lack of agreed-upon standardization and the gap among heterogeneous databases make information application and communication a major challenge. International efforts are underway to develop national projects on informatics management. The aim of this review is to provide references in specimen annotation to regulate and take full advantage of biological and biomedical information. First, critical data categories that are vital for specimen applications, including sample attributes, clinical data, preanalytical variations, and analytical records, are systematically listed for subsequent data mining. Second, current standards and guidelines related to biospecimen information are reviewed, and proper standards for tumor biobanks are recommended. In particular, commonly-used approaches and functionalities of data management are summarized and discussed. This review highlights the importance of informatics management of tumor specimens, defines critical data types, recommends data standards, and presents the methodologies of data harmonization for biobankers to reach high quality annotation of biospecimens.
Introduction
Biobanks are repositories of biological samples and relevant data engaged in the advancement of precision medicine and biomedical research. 1 With the emergence of Big Data, massive phenotypic and “omics” data derived from biological samples have led to more in-depth biomedical research, leading to a better understanding of human disease and transformation of scientific discoveries into individually tailored bedside applications.2–4 Biospecimen information combined with correlated clinical and analytical data are vital determinants for sample value in scientific research. 5 A consensus has been reached that the more accurate and extensive the annotation of human specimens, the more valuable and productive the scientific studies will become. 6
However, the current situation of bioinformatics management of biobanks demands improvements. Data from multiple databases, including pathological systems, electronic medical records, radio-and chemotherapy systems, laboratory results, image reports, molecular sequencing, and research-generated data, are stored separately and are difficult to be integrated and well-communicated.7,8 Moreover, these databases are often in different formats, from unstructured free-text, semistructured forms to structured text fields, and some health care institutes still rely on paper records and manual recording of data, which is time consuming and may possibly generate inaccurate data recording.9,10 Preanalytical variations, which occur during the whole life span of samples and are critical in creating high-quality samples, are difficult to track by current informatics infrastructures. 11
Guidelines such as the Best Practices from the International Society for Biological and Environmental Repositories (ISBER) dictated: common objectives of bioinformatics management are to be compatible of both clinical and biospecimen data, and capable of establishing biospecimen networks that can exchange information. 12 However, it didn't provide detailed procedures such as what information to collect, extract, transform and integrate, and how this can be supported by specific IT systems. 13 Consequently, individual biobank collects inconsistent data, resulting in communication barriers, which severely hinders the application of clinical samples. The information inconsistence has become one of the most challenging issue biobankers face to solve.
International efforts have been made to achieve consistent data and provide standardized programmatic access to multiple databases.14,15 Based on this approach, this review aimed at highlighting bioinformatics management with an emphasis on specimen annotation. We summarized key data categories of specimen annotation for subsequent data mining, discussed current data standards and guidelines, and recommended methodology of bioinformative management built on reported experiences. We believe we are the first to publish such solutions for biospecimen annotation and data harmonization in a review article.
Critical Information Categories
To define information categories (types of information) is the first step for specimen annotation. The published guidelines Biospecimen Reporting for Improved Study Quality (BRISQ) mainly focus on preanalytical factors influencing research results, while Minimum Information About BIobank data Sharing (MIABIS) does not contain data elements relevant to medical areas or data on individual subjects and samples.16,17 Individual biobanks include information categories and their subcategories that meet the needs of most hypotheses in clinical research, but the content is far from enough to fully annotate the specimen.18,19 According to previous reports and biobank practices,19–22 a detailed list of data categories highly related to sample application is summarized in Table 1 and the explanations are as below.
Main Data Categories for Biospecimen Annotation
HE, hematoxylin-eosin; ICD-10, The International Statistical Classification of Diseases and Related Health Problems 10th Revision.
Attribute information
The function of attribute information is for the identification and tracking of biospecimens. 20 It demonstrates sample types, disease profiles, sample ID, date of collection, number of aliquots, sample volume, tumor sites, storage sites, location (spot-freezer-layer-rack-slot), and more. 12 In addition, the specimens derived from the refining of original specimens also generate a series of information, such as concentration and purity of nucleic acids, and array and locations of tissue chips, which must be recorded and saved under the original catalogs for further management and application.21,23
Clinical data
As stated in the National Cancer Institute (NCI) Best Practices, “information linked to biospecimens may include demographic data, lifestyle factors, environmental and occupational exposures, cancer history, structured pathology data, additional diagnostic studies, information on initial staging procedure, treatment data, and any other data relevant to tracking a research participant”. 20
Based on published guidelines and individual experiences,8,19,22,24–30 seven main clinical datasets were included, namely, the treatment history demonstrating past and current medications, radiotherapy, and surgery; diagnostic descriptions revealing gross, pathological, and clinical diagnoses during treatment; pathological investigations stating cancer types, grades, and stages; inspection records indicating image and hematologic examination results; epidemiologic data illustrating familial history of cancer and exposure and risk factors; demographical data elucidating basic population information; and follow-up data showing relapse and survival details (Table 1).
Preanalytical variations
Preanalytical variations are defined as any variation taking place between the time of specimen collection or ischemia (for organs) to that of sample analysis. They are essential for evidence-based practices and are necessary to provide effective and efficient interconnectivity and interoperability between biobanks for credentialing research. 31 As ISBER's Best Practices pointed out, any information about the specimen being compromised in any way should be recorded and available to the user. 12 The standard preanalytical options have been published by the ISBER Biospecimen Science Working Group for application to biospecimens quality control. They included seven Standard PRE-analytical Code (SPREC) variables for liquid and solid tissue samples, respectively.32,33 In addition, the BRISQ also mentioned critical preanalytical elements involving human specimens. 16
According to these standards or guidelines, important variations in the life cycle of tumor samples are summarized in Table 1.
Quality assurance results
In-house tests carried out by biorepositories to assess and control biospecimen quality are essential for qualified research. 34 Any results produced by evaluating the biomolecular analytes of the samples are quality assurance results.32,35 These data reveal the actual quality status of the samples, thus allowing researchers to differentiate between the pros and cons when retrieving samples and further improve the quality of biomedical studies. 36
Analytical records
With the development of high-throughput methods for “omics” studies, a large number of physical samples have been analyzed and transformed into digital information. These abundant experimental records, combined with a clinicopathological database, can reveal potential biomarkers and clinical phenotypes directly, which significantly expand our understanding of carcinogenesis and guide personalized medicine.37–39 In addition, by taking advantage of a stored analytical database, unnecessary tests and ineffective treatments can be avoided, thereby becoming cost effective to both the patients and health care practitioners. 40
Recommendations for Data Standardization
To minimize data heterogeneity, standards and guidelines have been established with instructions on how to create more consistent and standardized information to optimally annotate biospecimens. The SPREC is a seven-element code corresponding to the most critical preanalytical variables of fluid and solid biospecimens. 33 It lists the data fields and their abbreviations or codes. SPREC is a good precedent for data standards, but it only covers preanalytical variations and is not sufficient for entire data standardization. The BRISQ guidelines include general information for consistent documentation of classes of biospecimens and factors that could influence research results. The list was prioritized into three titers according to their relative importance. The third tier contains “additional items to report,” which includes information unlikely to influence research results. 16 However, its data elements, such as ischemic time, disease status, and clinical characteristics of patients, are crucial in answering scientific questions. MIABIS is a dataset consisting of 52 attributes of minimum information facilitating the sharing of samples and data among biobanks on a global scale, with limitations that it does not include data on medical, quality, and ethical levels. 17 In addition, several data elements of MIABIS that describe biobanks and biobankers like contact phone and email are not essential for specimen usage and can be omitted or marked as “additional items.”
A minimum data set and associated standard available in BRISQ, SPREC, and MIABIS have been included and published by World Health Organization/The International Agency for Research on Cancer. 41 However, the data set only integrated and listed the data elements presented by the above standard and guidelines. A data standard for sourcing fit-for-purpose biological samples in an integrated virtual network of biobanks has been published based on the above guidelines. 42 The data categories covering comprehensive information are appropriate for annotation of sample networks and large scale biobanks.
According to the data categories summarized in Table 1, combining the standardized formats of data items presented in the above standards and guidelines, we recommend standardized formats of data elements suitable and critical for tumor specimens and cancer research in this section. As shown in Table 2, existing guidelines or standards mainly focus on sample attributes and their associated preanalytical variations, with little reference to data related to clinical, prognostic, and analytical outcomes, which are vital resources for scientific research. The standardization of these data still needs further exploration and efforts. While BRISQ provides a referential standardized form for most of the data elements, SPREC provides only a limited number of preanalytical variables, and MIABIS focuses more on sample attribute information. It is suggested that BRISQ is more comprehensive in terms of data standardization.
Recommended Standardized Format of Critical Data Elements According to Standard PREAnalytical Code, Biospecimen Reporting for Improved Study Quality, and Minimum Information About BIobank Data Sharing
BRISQ, Biospecimen Reporting for Improved Study Quality; EDTA, ethylene diamine tetraacetic acid; MIABIS, Minimum Information About BIobank data Sharing; SPREC, Standard PRE-analytical Code.
Principal Technological Approaches and Functionalities
For methods of bioinformatics management, considerable efforts have been made by international organizations and individual biobanks. In 2003, the National Cancer Institute Center for Bioinformatics (NCICB) established the NCICB core infrastructure for biomedical informatics (caCORE), a robust infrastructure for data management and integration that supports advanced biomedical applications. 43 Successively in 2004, the NCI launched cancer the Biomedical Informatics Grid (caBIG) to develop a federation of interoperable research information systems.44–46 The caBIG platform was later changed to the NCI Genomic Data Commons, which aims to harmonize both the genomic and clinical data across programs and projects. 47 Evolved from caBIG, the caTissue was launched to capture and represent highly granular, hierarchically structured data for biospecimen processing, quality assurance, tracking, and annotation. 48 Individual biobanks have also attempted to develop biospecimen data management systems (BDMSs) to merge clinical data with biospecimen information for research purposes.19,26 These above projects and practices have exemplified the implementation of data harmonization, programmatic access, and data integration.
In this section, essential approaches and functionalities of information management on attribute- and external data are discussed and summarized. The architecture of relative informatics management module is shown in Figure 1.
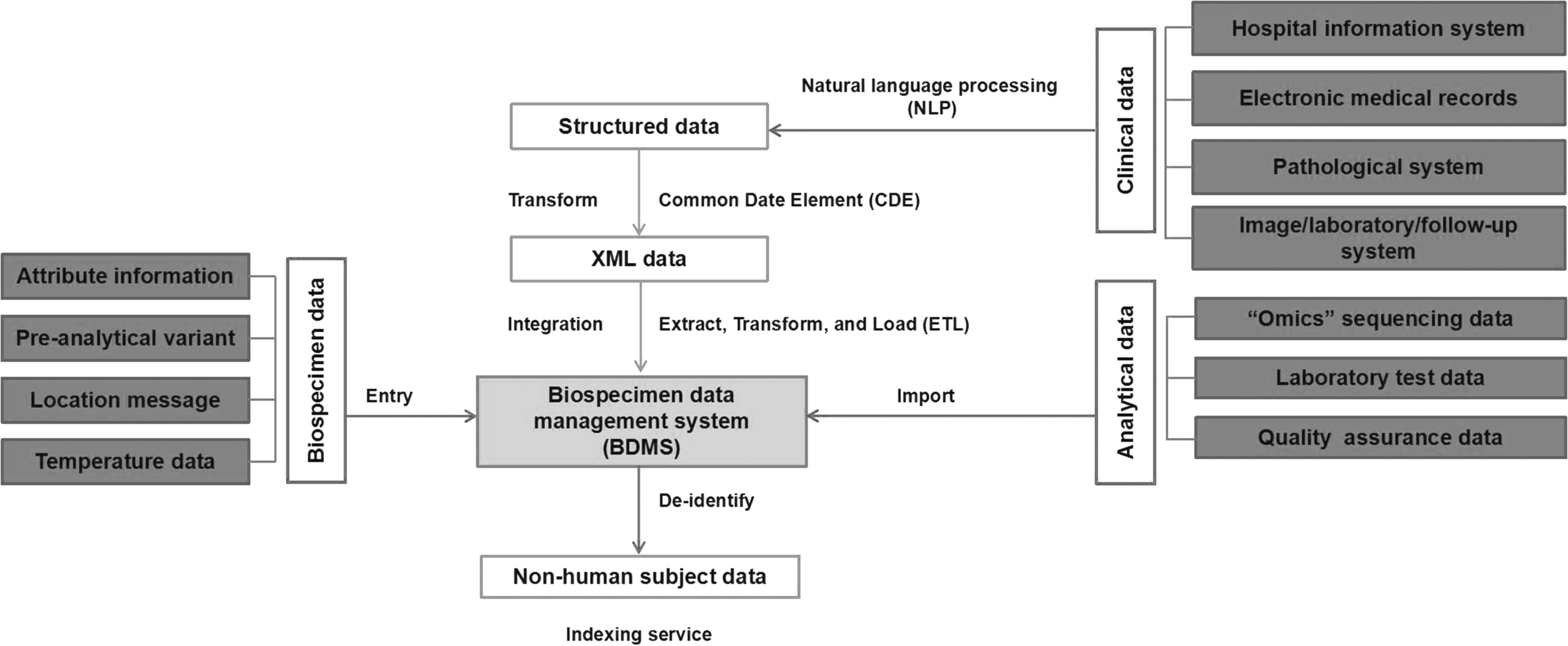
Technological architecture of data management. Clinical data were converted from free text to structured data by NLP. The structured data were then standardized by tool CDE to XML data. An ETL system was then applied to ETL the uniform data to BDMSs. At the same time, external analytical data were imported to BDMSs and integrated with existing biospecimen related data. Finally, all the messages were deidentified to nonhuman subject data according to data protection rule. BDMS, biospecimen data management system; CDE, common date element; ETL, extract, transform, and load; NLP, natural language processing; XML, extensible markup language.
Structuring and standardization of data
To deal with mass data stored in nonstandard forms, a growing number of published works have applied Natural Language Processing (NLP) to convert the free text into standard structured text fields.19,48 NLP is any computer-based algorithm that handles, augments, and transforms natural language to extract target information so that it can be represented for computation.14,29,49,50
Creating an NLP system involves exploiting three common related NLP resources: extraction tools, ontologies, and corpora. 49 Typical clinical NLP pipelines include the following tasks: (1) section identification, (2) medical named entity recognition, and (3) negation and assertion classification. Ontologies provide a knowledge base to reference how various concepts are related to one another, for example, a medical dictionary. Corpora are collections of clinical text that can be used to test an NLP system. As exemplified in the NCI programs, the construction of the cancer text information extraction system and the clinical annotation engine was to meet NLP and clinical data annotation needs in caTissue Core. 48 Although the sensitivity of personal health information limits the availability of this text, the development of deidentified data sets has solved the challenges. Detailed methods of NLP in oncology have been introduced in previous reviews.14,46,51
To promote data communication and sharing across different databases, NCI and many other institutes have supported a broad initiative to standardize vocabularies and ontologies to create the common date elements (CDEs) applied to cancer research data capture and reporting.43,52–54 CDEs are combinations of precisely defined questions (variables) paired with a specified set of responses to the question that is common to multiple datasets or used across different studies. 55 Although there are no formal international specifications governing the construction or use of CDEs, the NCI's attempt on data vocabularies and ontologies can serve as a reference for data standardization and harmonization.
Definition and integration of data sources
The definition of data sources was accomplished by converting the hierarchy to valid extensible markup language (XML) as defined by the XML schema definition. XML makes the connection using registered data types in an implementation and platform agnostic manner possible. 44 An XML element generally includes a connection string, the type of Structured Query Language (SQL) engine, and a transact SQL statement, as well as a structural metadata scheme of a data table.19,46 The biospecimen annotation is exported into an XML document, including the patient identification number. Afterward the biospecimen annotation is linked to related clinical information using a tool. The tool combines the clinical data with the corresponding biospecimen annotation by matching the patient identification number, that is, the patient's medical record number (MRN).56,57
As multiple databases are connected to the BDMSs, to put these databases on a grid, an extract, transform, and load (ETL) system was exerted for creating topic-specific subsets of source databases.56,58–60 The system uses a series of toolkits to extract data from multiple heterogeneous databases (that are not optimized for analytics), transform the data into designed formats, and flexibly load the derived information into a whole data warehouse. 56 The exact steps in that process might differ from one ETL tool to the next, but the end result is the same, namely, integrated data for analysis.
Biospecimen and analytical data entry
Once the recruited patients are determined, their basic clinical information (such as patient demographics and diagnoses) stored in the Hospital Information System or the electronic health record is linked and saved within the BDMSs by the patient's MRN.19,61 Empty fields are preset for subsequent entering of sample attribute data. At the time of specimen collection, attributive messages of the samples are entered and saved with the previous patient information. 62 In most circumstances, the software also needs to be capable of tracking processing details and preanalytical events, for example, centrifugation conditions, freeze–thaw cycles, storage temperature, especially time recording for time-sensitive properties for evidence-based practices. 51 In terms of analytical data, because it is mostly derived from a variety of data formats, one of the good practices is to accept their format and bulk import the data using a set of mapping tables that map columns in their data (patient ID, time point, analytical result) to BDMS data elements.60,62,63
Specimen identification and positioning
Unique ID and relevant barcode linking to the sample are generated by corresponding toolsets according to specified templates. 19 The barcode is set as an electronic tag that identifies the sample electronically. IDs are usually presented as numbers, while barcodes are preferentially stored as strings and numbers for pattern matching and searched by an electronic scan. A storage management module which is devoted to assign storage location (site-freezer-layer-rack-slot) and to keep track of a given specimen should also be maintained to meet the inventory management functionality.1,12,62,64
Data security
To make data communication safe, there has been growing recognition for the need of data security and access control. 65
The European Union (EU) published the GDPR (general data protection regulation), which is a law about data privacy and security for the protection of personal data. 66 Data protection can be assured by additional tools to encrypt key data, deidentify sensitive information, and support role authorization.44,67 To protect the private messages from the donors, it is mandatory to develop a deidentification process by removing the 18 identifiers required by health insurance portability and accountability act (HIPAA), to limit exposure of patient identifiers to research staff.25,46,68,69 After deidentification, randomly generated Universally Unique Identifiers linked to the original identifiers were created and stored, to support the reidentification that is permissible under HIPAA. 46 In addition, security logging with defined privilege levels, such as administrators, visitors, and common users, must be set to insure access control. Data backups should also be routinely developed in case of database corruptions.12,63
Register and retrieval service
To support the function of registration and application, a web-based end-user friendly interface composed of role-based perspectives is needed so that users (such as researcher, preliminary user, administrator, and honest broker) can register and apply to relevant user needs.46,70
In particular, indexing services used to retrieve the integrated information must be established to choose appropriate samples between different end points. 57 A pick list preset for critical factors, such as sample type, collection date, pathological type, and medication condition, are created and designed flexibly with the Standard Boolean constructs, including AND, OR, and NOT, used to combine all of the above constraints in the user interface.46,56 The query results are returned as a single row preferably, presenting the necessary nonhuman structured data, including clinical key elements, biosample information, and biological data. 62 A function to export these data according to their content type into comma-separated value files supported by popular statistical software such as SPSS, EXCEL, STATA, or R must be included. 19
Inventory tracking and temperature monitoring
The inventory module should have the capability of repository management. This includes assigning new virtual locations to the sample after collection, automated location tracking, and location editing when the sample location is changed or deleted. 62 In the event that a container fails, the inventory management system must be able to meet mass movements and changes of specimen location. 12 Ideally, the system should also have the ability to display the spatial utilization rate of each storage container so that biobankers can see the space used intuitively.
Since the change of storage temperature is an important factor in determining specimen quality, it is preferable to keep records of the temperature data of both the carriers and rooms for subsequent sample quality assessment. 71 This can be realized by binding to an interface of an external temperature monitoring system or by building a temperature monitoring function independently within the BDMSs, according to previous experience.
Operation log and documentation
An operation log describing any changes made to the system in any way must be recorded and saved as an important part of the BDMSs. This includes, but not be limited to, the details of the changes made, by whom these were made, and recordings of the date and time of the change. 12 Ideally, any documents of the repository, including operating instructions, standard operating procedures, (digitally scanned) informed consent, and financial revenue, may also be archived electronically and stored within the BDMSs for administrative convenience.
To provide a better reference for specimen annotation, the recommended priority of data management approaches is summarized in Table 3 depending on the size, the type, and the objective of the biobanks. Biobanks can refer to the corresponding approaches in data management according to their own situations.
The Priority of Technical Methods Recommended in Data Management
Importance degree: emergence > very important > important; priority degree: mandatory > ideal > best.
ETL, extract, transform, and load; NLP, natural language processing; XML, extensible markup language.
Conclusions and Future Perspectives
With the development of digital technology and the advent of Big Data, physical biobanks that store sample entities may gradually give way to electronic biorepositories that store electronic data in the future, as the U.K. biobank has done. 72 In view of this, the challenge of data management of biological samples has been increasingly emerging. This review highlights the importance of specimen annotation and provides recommendations for daily specimen informatics management for biobanks. We summarized the important information categories for the annotation of tumor specimens and recommended a standardized format of data to maintain data consistency, including main technical approaches and functionalities of biospecimen data management for biobanks. Based on these data management principles, each BDMS can be designed to best support the processes of a particular biorepository with its own unique workflows and dataset types.
We should acknowledge a few potential drawbacks of this review. First, due to the limitation of current standards of specimen information, the recommended standardized format of data presentation was incomplete and needs further efforts in data standardization. Moreover, in consideration of the professional level of biobankers, the approaches of data management were not described in detail with specific tools and procedures. A wealth of professional literature and guideline is available for reference. And professional system design engineers can direct to relevant reference for further details.
In the future, biobanks are expected to achieve significant breakthroughs in precision medicine if they continue focusing on the strengthening of the depth and breadth of data mining for facilitating open sharing. To achieve this goal, one of the first steps would be to construct a dynamic boutique clinical database with longitudinal clinical data based on prospective design, that is, to collect matched tumor tissues, paracancer tissues, metastatic foci, lymph nodes, peripheral blood, and relative messages from patients at different stages before, during, and after treatment. Researchers can utilize the data produced in different stages for the evaluation and analysis of drug efficacy and treatment effects longitudinally. The second step would be to prompt global data standardization and open sharing, thus making horizontal data analysis based on a large sample size from different regions and ethnic groups become possible. Based on large sample databases, many complex medical problems and global health issues may be solved comprehensively.
Taken together, a globally open shared bio-database built on the depth and breadth would usher a promising future for biobanking, defined by comprehensive metadata and extensive collaboration in medical research.
Footnotes
Authors' Contributions
P.-F.Z. drafted the article. W.-H.J. reviewed the article before submission. All authors read and approved the final article.
Acknowledgments
The authors thank Ye-zhu Hu, Shao-dan Zhang, and Ting Zhou for their unique experience and insights in information management. The authors are also grateful to the colleagues in the biospecimen and biobank industry for their efforts in the standardization of sample annotation.
Author Disclosure Statement
No conflicting financial interests exist.
Funding Information
This work was supported by the National Key Research and Development Program (grant no. 2016YFC1302704) and the Science and Technology Planning Project of Guangdong Province, China (grant no. 2019B030316031).