
Abstract
Background:
Cohort studies with biobanks that use strict quality standards are essential requirements, not only for the development of new diagnostic and prognostic markers, but also for improving the understanding of pathophysiology of disease development, which have drawn an increasing amount of attention over the past decades. However, a bibliometric analysis of the global research on cohort biobanks is rare. The objective of this study was to evaluate the origin, current trend, and research hotspots of cohort biobanks.
Materials and Methods:
We searched the Web of Science Core Collection (WoSCC) with “biobank” and “cohort” as the topic words to retrieve English language articles published from 2009 to 2018. The CiteSpace 5.5.R2 was used to perform the cooperation network analysis, key words co-occurrence and burst detection analysis, and reference co-citation analysis.
Results:
The number of publications on cohort biobanks has increased over the past decade. Tai Hing Lam from the Department of Community Medicine, University of Hong Kong, was found to be the most productive researcher in this field. The percentage of publications in England (38.30%) was the highest all over the world. Risk, biobank, meta-analysis, cohort, disease, and so on were the most frequent keywords. Metabolic syndrome was the strongest burst keyword in this field, followed by Hong Kong, Guangzhou biobank cohort and personalized medicine. Moreover, of all the references for 932 articles included in the study, the article titled “UK biobank: an open access resource for identifying the causes of a wide range of complex diseases of middle and old age” published in PLoS Med by Sudlow et al., was the most frequently co-cited reference in this field. The largest cluster was labeled as Guangzhou biobank cohort study.
Conclusions:
This study provides an insight into cohort biobanks and the valuable information for biobankers to identify new perspectives on potential collaborators and cooperative countries/territories.
Introduction
Biobank has been defined as “a collection of biological material and the associated data and information stored in an organized system, for a population or a large subset of a population,” which refers to human population-based biobanks. 1 The population cohorts with donors' samples prospectively linked to continuously updated electronic health records, which is called a cohort biobank, are expected to facilitate advances in personalized medicine, including preventive medicine and safer, more effective prescription drugs. 2 So it is important to understand the global research bases, trends, and hotspots in this field.
Bibliometrics plays an important role in ranking the performance of a researcher, research groups, institutions, or journals within the international arena. It is a statistical and quantitative analysis designed to analyze the academic impact and characteristics of publications within a research field. 3 CiteSpace is a powerful and efficient bibliometrics visualization software that was developed by Dr. Chen Chaomei from Drexel University, which is useful for evaluating the current body of scientific knowledge, detecting trends in the literature, and identifying research frontiers of a research field, 4 not only for medicine and health, but also for environmental sciences,5,6 educational research,7,8 and engineering science.9,10 However, to date little has been published about this type of analysis about cohort biobanks.
In this study, the global trend and the research frontiers in this field will become clear as we visualize and explain our results. The purpose of this study was to observe the development of cohort biobanks using bibliometric tools.
Materials and Methods
Data source
The web-based Web of Science (WOS, previously known as Web of Knowledge), maintained by Thomson Reuters (New York, NY), was launched in 1997, is well known and widely used in academia.11,12 The database provides citation searches, giving access to multiple databases that reference cross-disciplinary research, and allowing for an in-depth exploration of specialized subfields. 13 All data in this study were obtained from the Web of Science Core Collection (WoSCC) on August 15, 2019. Bibliometric analysis based on published literature does not involve ethical issues.
Search strategy
In this study, the data retrieval strategy was as follows: (1) TOPIC: (biobank*) and TOPIC: (cohort). (2) Document types were articles. (3) Language was English. (4) The time span was set between 2009 and 2018. The chart of the literature search is given in Supplementary Figure S1. And the data of all eligible publications, including publication years, countries/territories, institutions, journal sources, research areas, cited references, and keywords, were downloaded for further analysis.
Analysis tool
CiteSpace is a Java application that combines information visualization methods, bibliometrics, and data mining algorithms in an interactive visualization tool. 4 It supports several types of bibliometric studies, including collaboration network analysis, co-word analysis, document co-citation, and so on,14–16 which were applied to this study. CiteSpace has been continuously developed to meet the needs for visual analytic tasks and is free to use. In this study, we used CiteSpace 5.5.R2 to perform the analysis.
Data analysis and statistics
First, the datasets for the analysis of cohort and biobank covering the time period from 2009 to 2018 were developed as a test platform for CiteSpace. The parameters were as follows: (1) Time period: 2009–2018. (2) The lengths of time were divided into 10 parts, each of which was 1 year. (3) Term source: title, abstract, author keywords, and keywords plus. (4) Node type: select the corresponding one each time. (5) Selection criteria: adjust the parameter settings each time to ensure that the results are well representative. (6) Pruning: minimum spanning tree and pruning sliced networks. (7) Visualization: cluster view-static and show merged network.
This study primarily includes the analyses of cooperation networks (including authors and countries/territories), keywords co-occurrence, and reference co-citations. We adjusted the parameter settings and selected the correct nodes each time. We combined cooperation network analysis, key words co-occurrence and burst analysis, and reference co-citation analysis to get a comprehensive understanding of the current state of cohort biobanks.
Results
General data
As the Supplementary Figure S2 shows, the initial search for cohorts and biobanks resulted in 936 original articles published between 2009 and 2018. After filtering out a small number of duplicate records, the dataset was reduced to 932 records. The quantity of published articles on cohorts and biobanks increased significantly over the studied period, especially after 2015 (Fig. 1).
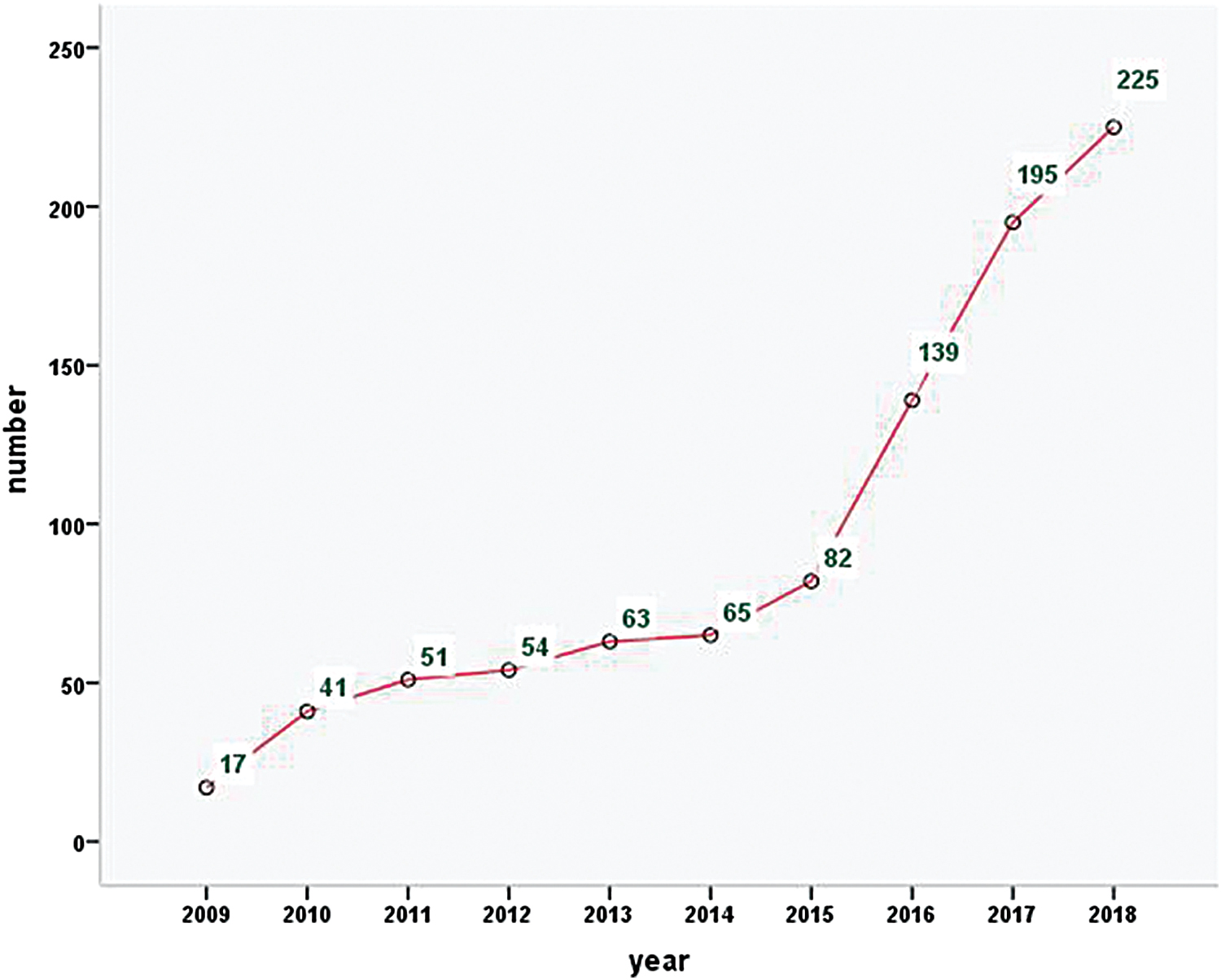
The number of cohort biobank publications indexed by WoSCC from 2009 to 2018. WoSCC, Web of Science Core Collection. Color images are available online.
Authors' and countries/territories' collaboration
Figure 2 provides the co-authorship network map generated by CiteSpace. There are 363 nodes and 1016 links in the network, which means the articles included in these statistics were published by 363 research authors and there were 1016 collaborations among them. The size of circles represents the amount of publications of the authors, and the shorter distance between two circles suggests more collaboration between individual authors. Regarding the authors who were active, Tai Hing Lam from the School of Public Health, University of Hong Kong ranked the first (72 publications), followed by Kar Keung Cheng from the Institute of Applied Health Research, University of Birmingham, United Kingdom (70 publications). The top 10 authors are given in Table 1, with data extracted from the network summary table.
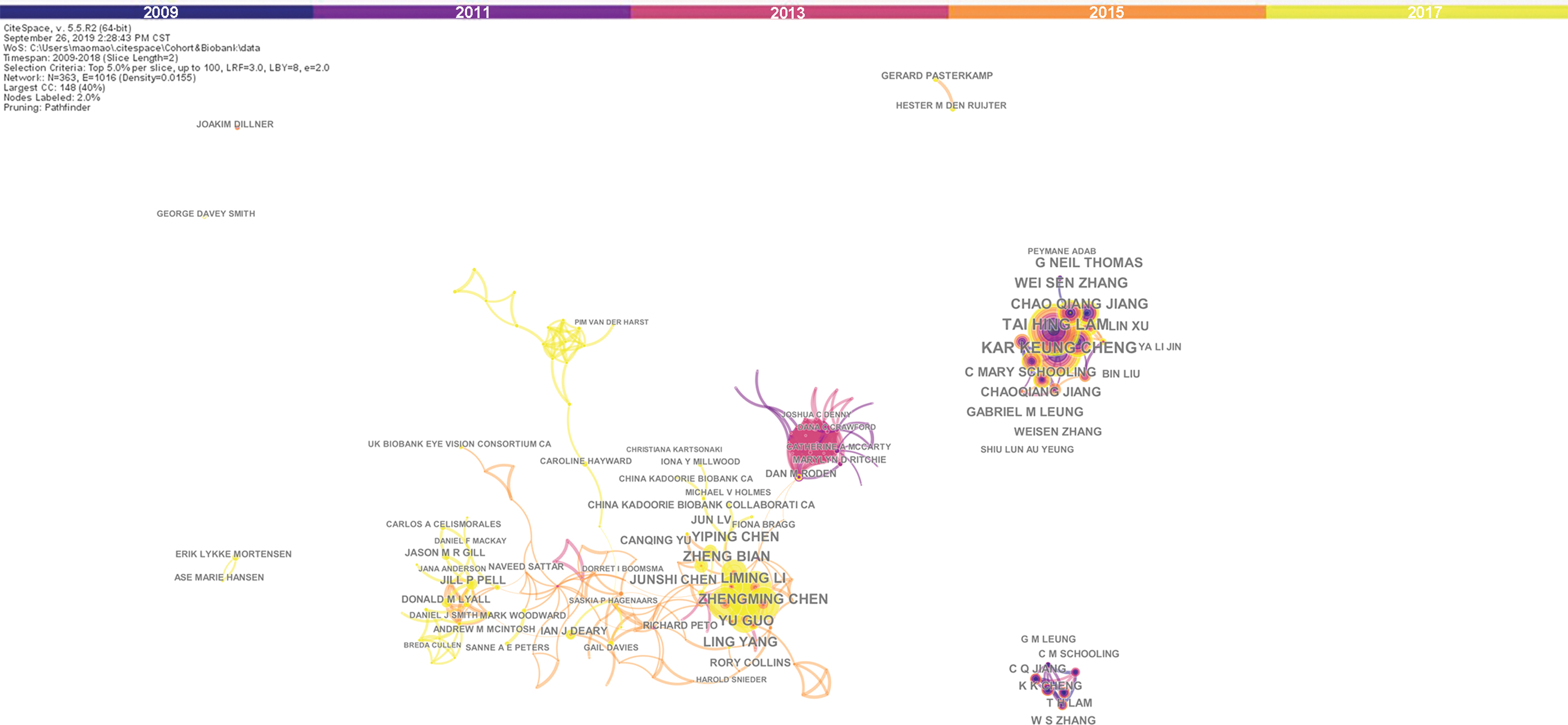
Co-authorship network map of cohort biobank from 2009 to 2018. The bigger the circle, the more original articles the author published. The font size of the name represents the number of articles published by the author. Different color rings indicate different years of publication and are consistent with the color bar at the top of the figure. The shorter and thicker the connection line, the closer relationship between authors. Color images are available online.
Top 10 Active Authors in Research of Cohort Biobank, 2009–2018
Figure 3 shows that there were 60 nodes, and 151 links among the countries/territories, which means that there was extensive cooperation between countries/territories. England (357) ranked first in the publication quantity, followed by the United States (289) and China (175). The top 10 most prolific countries/territories in this research field are given in Table 2.

Countries/territories' cooperative relations of cohort biobank from 2009 to 2018. The numbers at the top area of the figure is the time slice line, which represent years. The bigger the circle, the more original articles the country/territory published. The font size of the name represents the number of articles published by the country/territory. Different color rings indicate different years of publication and are consistent with the time slice at the top of the figure. The shorter and thicker the connection line, the closer the relationship. Color images are available online.
Top 10 Prolific Countries/Territories in Research of Cohort Biobank, 2009–2018
Keywords cluster analysis and burst detection
The keywords are generalizations of the topics in the literature. An analysis of keywords can be used to determine the hotspots in the field of cohort biobanks. CiteSpace can extract noun phrases (cluster labels) from the titles (T), keyword lists (K), or abstracts (A) of articles that cited the particular cluster. Cluster labels are numbered in the descending order of the cluster size, starting from the largest cluster #0, the second largest #1, and so on. The clustering keywords map resulted in 143 nodes and 290 links, and Figure 4 shows that these keywords were roughly attributed to six clusters, which were labeled by smoking cessation, Estonian genome center, case–control study, human tissue sample, Guangzhou biobank cohort study (GBCS), and later adulthood cognition. The top 10 hot keywords were risk, biobank, meta-analysis, cohort, disease, risk factor, association, mortality, population, and health (Table 3).

Clustering map of keywords on cohort biobank research from 2009 to 2018. Each cluster has its own closed loop. The sequence number of clusters and cluster labels were marked red in the central area. The size of the cross proportional corresponding to the co-occurrence frequency of the keywords, and the lines between the crosses represent the mutual relationship between the keywords. Color images are available online.
Top 10 High Frequency Keywords in Research of Cohort Biobank, 2009–2018
In addition, keywords burst detection can identify fast growing topics. In the keywords citation burst detection analysis, metabolic syndrome was the strongest burst keyword in this field during the entire time period from 2009 to 2018, followed by Hong Kong, Guangzhou biobank cohort, and personalized medicine. Therapy will be among the active research hotspots in this field in the future (Fig. 5).
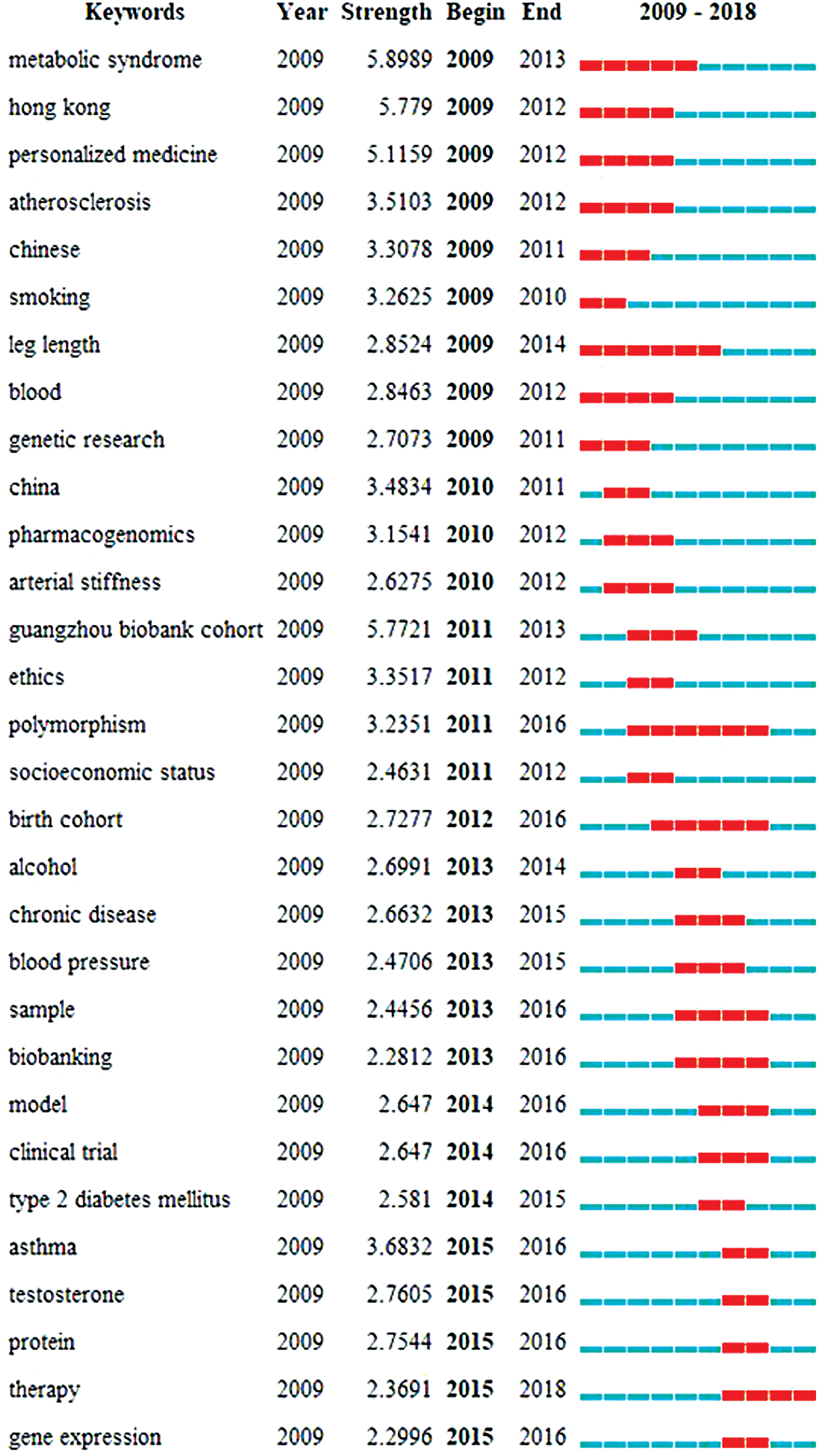
Keywords with the strongest citation bursts in published articles on cohort biobank from 2009 to 2018. The timeline is depicted as a blue line, and the time interval that a subject was found to have a burst is shown as a red segment, which indicated the beginning year, the ending year, and the duration of the burst. Color images are available online.
Co-citation references
After running the searches, we discovered that 932 original records containing 28,542 references were downloaded from the WOS, which would then be included in this part of the statistics. Figure 6 provides a timeline visualization of the reference co-citation network that is divided into six co-citation clusters. These clusters are labeled by index terms from their own citations. The nodes represent different cited references and the clusters represent a distinct specialty or a thematic concentration. Table 4 provides the top five co-citation references related to cohort and biobank over the 10-year period. The top ranked item by citation counts was published by Sudlow in cluster 4, with a citation count of 106.

Timeline of reference co-citation map related to cohort biobank research from 2009 to 2018. The numbers at the top area of the figure is the time slice line, which represent years. Major clusters are labeled on the right. Landmark articles are labeled with representative articles' authors and publication years. The larger the circle, the more frequently it is co-citation. The thicker the purple circle, the stronger the betweenness centrality. Color images are available online.
Top Five Co-citation References Related to Cohort Biobank, 2009–2018
Discussion
The term “biobank” first appeared in the scientific literature in 1996 and for the next 5 years was used mainly to describe human population-based biobanks. 1 Large cohorts with stored biological samples are crucial for understanding the determinants of complex diseases. 17 Now, biobanks and cohorts have become subjects of an increasingly important area of research. In this study, we utilized information visualization to analyze articles on biobanks and cohorts published from 2009 to 2018 to evaluate the origin, current trends, and hotspots of research in this field. We identified an increasing number of scientific research publications over a 10-year period. The number of publications in 2018 (n = 225) was nearly triple that in 2015 (n = 82).
In recent years, to explore and measure the roots (social or intellectual) of disciplines, social network analysis has been utilized by conducting co-occurrence analysis, including the collaboration networks of institutions/countries and authors. 18 Regarding the top 10 authors in Table 1, all the professors Lam, Cheng, Jiang, Zhang, and Thomas were the members of the GBCS, China19,20; and Guo, Li, Chen, Bian, and Yang were from China Kadoorie Biobank (CKB) Collaborative Group.21,22
The GBCS is a collaborative research project between the universities of Birmingham and Hong Kong, and the Guangzhou Number Twelve People's Hospital in China. The main long-term aim of the study was to examine the effects of genetic and environmental influences on health and chronic disease development. 23 The CKB, known previously as the Kadoorie Study of Chronic Disease in China (KSCDC), 24 is an open-ended study with very broad research aims. During the years 2004–2008, >510,000 adults were recruited from 10 geographically defined regions of China, with extensive data collection by questionnaire and physical measurements, and with long-term storage of blood samples for future study. 25 So we can see that China has benefited from its large sample population, attracted scientists from many countries, and established good cooperative relationships.
With regard to distribution by country/territory, our results showed that England, as an economically powerful region, was a key player in scientific research on cohorts and biobanks, which contributed about a third of the total literature between 2009 and 2018 (Table 2). In this case, the UK Biobank may play a very important role. As a prospective (forward-looking) study, UK Biobank is one of the national and international health resources with unparalleled research opportunities, open to all bona fide health researchers, and which has published a large number of articles. 26 China ranked third in publication quantity. On the one hand, China, as a rapidly rising developing country, has been gradually catching up with some developed countries in the input and output of scientific research. On the other hand, the Biobanking and Cohort Network (BCNet) was established by the International Agency for Research on Cancer (IARC) in 2013, and now has 34 low- and middle-income countries (LMIC) member organizations from across the world and 13 partner organizations. 27
From Figure 3, we see that there was very frequent and close cooperation among countries/territories in this field (151 lines). The technical challenges of connecting the cohort biobanks are increasingly being met by new information technology solutions. Harmonization tools, such as the R-based platform DataSHIELD, are used to synthesize data in the LifeCycle Project-EU Child Cohort Network. 28 We speculate that a global consensus will be reached on more international collaborative research based on multiple centers from different countries in this field.
Keywords can be regarded as the soul of an article. By analyzing keywords co-occurrence frequency, clustering and burst detection, some research hotspots can be discovered and used for monitoring the research frontier transitions of a certain knowledge domain. 29 Through the analysis of the high-frequency keywords in the literature of the past 10 years in this field, we can see from the top 10 keywords listed in Table 3 that all publications were closely related to the six themes of smoking cessation, Estonian genome center, case–control study, human tissue sample, GBCS, and later adulthood cognition (Fig. 4). So we can deduce from the high frequency keywords that most hotspots in this field were based on population research.
Citation burst is the detection of a burst event indicating dramatically increasing literature citation frequencies, which can last for multiple years as well as for a single year. A citation burst provides evidence that a particular publication is associated with a surge of citations. 30 In addition, the analysis of the keywords burst patterns reveals a latent hierarchical structure that often has a natural meaning. A stronger burst shows higher attention to this research topic and can better exemplify the research front in this period. 31
From Figure 5, we can see that the top-ranked key word by bursts was metabolic syndrome, with burst strength of 5.8989. Metabolic syndrome is a clustering of clinical findings made up of abdominal obesity, high glucose, high triglycerides, and low high-density lipoprotein cholesterol levels, and hypertension. 32 An authoritative study in 2004 showed that the metabolic syndrome is far more common among children and adolescents than previously reported, and that its prevalence increases directly with the degree of obesity. 33 In addition, according to the Developmental Origins of Health and Disease (DOHaD) hypothesis, 34 much of the literature included in the analyses are birth cohort studies focusing on metabolic diseases.
Leg length, a marker of early childhood deprivation, has been used in studies of the association of early life conditions with adult chronic disease risk, such as metabolic syndrome. 35 So leg length had the longest duration of burst (6 years), with a burst duration from 2009 to 2014. Similarly, polymorphism had a duration of burst up to 6 years, from 2011 to 2016. Most human traits are complex, and influenced by the combined effects of the environment and large numbers of small genetic changes. Genome-wide association studies (GWAS) have identified many genetic variants influencing many complex traits. The UK Biobank is a large prospective epidemiological study comprising ∼500,000 deeply phenotyped individuals from the United Kingdom. The cohort has been genotyped using an array that comprises 847,441 genetic polymorphisms, with a view to identifying new genetic variants in a uniformly genotyped and phenotyped cohort of unprecedented size, both in terms of the number of samples and number of traits. 36 The GWAS and gene polymorphisms and their relationship with a variety diseases are also the key concerns of many other cohort biobanks.37,38
Aside from the strength and duration of keyword bursts, we can also generalize that the active research hotspots in this field will be “therapy” from Figure 5. The red segment indicated the beginning year, and the ending year entry for the end point may extend beyond 2018. The ultimate purpose of a large-scale cohort biobank is to serve the accurate prevention, diagnosis, and treatment therapy of diseases.
The co-citation relationship exists when two documents appear together in the bibliography of the third document. A co-citation cluster refers to a network formed by co-citation publications and is used to investigate a knowledge base.39,40 From Figure 6, we can see a timeline view, and each cluster is arranged on a horizontal timeline. The six clusters were labeled as GBCS, polygenic risk score, Mendelian randomization study, biobank Japan project, UK biobank, and electronic health record, respectively, by LLR (log-likelihood rate), which emphasized the characteristics of research and usually gave the best results in terms of the uniqueness and coverage. 41 Nodes have purple rings around their outer rims that indicate the high betweenness centrality. The thickness of the purple ring indicates the degree of its betweenness centrality, which is a measure associated with the transformative potential of a scientific contribution. 15
Therefore, combined with Figure 6 (thick purple ring) and Table 4 (centrality: 0.79), we can infer that UK Biobank will greatly promote the research of multiple diseases in the world with large sample size and rich information (general information and specific sample information of the participants). We also can see that the earliest cited literature was published by Folstein et al. in 1975. The article titled “‘mini mental state’: a practical method for grading the cognitive state of patients for the clinical” introduced a simplified questionnaire for assessing cognition in the Journal of Psychological Research. 42
Based on co-citation networks, top-cited publications were further analyzed to investigate the study knowledge base for the cohort and biobank. Among the listed top five co-citation references in Table 4, the first and fifth are both about UK Biobank,43,44 which is considered to be a unique resource for studying human genetic variations linked to disease phenotypes, and played a fundamental and instructive role in the research of this field. So these two articles are naturally clustered to No. 4, which is labeled “UK Biobank” (Fig. 6 and Table 4). Cluster 4 also included the third most co-citation article published in the International Journal of Epidemiology by Chen et al., 45 which reported on detailed survey methods, and the main baseline characteristics of the participants and status of follow-up of the CKB. 45
The second most frequently co-citation article was published by Jiang et al., also in the International Journal of Epidemiology, 2006, which introduced the GBCS. 23 This was also consistent with the label of this cluster (No. 0). The fourth most frequently co-citation article was published by Purcell et al. in the American Journal of Human Genetics, 2007, which introduced a tool named PLINK that set for the WGAS and population-based linkage analyses, and described the five main domains of function: data management, summary statistics, population stratification, association analysis, and identity-by-descent estimation. 46 In summary, UK Biobank, CKB, and GBCS are the research bases of this field, and the development of analytical tools, such as PLINK, will further promote the progress of research in this field.
Our study is unique in several ways. First, to the best of our knowledge, this is the first bibliometric study in the field of cohort biobanks and establishes a baseline data for future analyses and comparisons. Second, our study gives a clear picture and a very close approximation of the quantity, quality, citation analysis, trends, and international activity of documents in this field in the past 10 years. Moreover, our findings provide an example of visualization analysis that is also available to explore research hotspots in other fields.
But our study has some limitations. For example, we only used one literature source, the Web of Science Databases, for its large collection and its comprehensive citation tracking. Not combining with literature from other major databases, such as Chinese and Korean Citation Databases limits the comprehensiveness of our results. Indeed, the primary source of data for CiteSpace is the Web of Science. Most importantly, the dataset should include cited references to maximize the potential of CiteSpace. In fact, because PubMed records do not include information on cited references, it is not possible to perform citation analysis, so we cannot choose the node types such as cited references, cited authors, or cited journals. CiteSpace can convert data in other databases, such as the SCOPUS, Chinese Social Sciences Citation Index (CSSCI), and China National Knowledge Infrastructure (CNKI) format to the WOS format. Therefore, it is hoped that there will be opportunities to analyze and compare different databases in this field in the future.
In conclusion, cooperation between researchers within countries/territories has led to the rapid development of cohort biobanks in the past 10 years. Professor Tai Hing Lam and England are the most prolific individual and country/territory, respectively. The hotspots in this field are mainly the exploration of disease treatment methods based on population research in the future. UK Biobank, CKB, and GBCS are the primary research bases of this field. With the help of information visualization, we were able to identify research hotspots and overall trends in this field. In addition, it will greatly enhance our understanding of cohorts and biobanks and provide gathered information for future researchers in this field. An important task of cohort biobanks is to gradually explore the origin of diseases and the possible genetic and/or environmental factors of the diseases, so as to find more effective therapies to treat them and promote global human health. Cooperation between biobanks will further promote the solution of these problems.
Footnotes
Authors' Contributions
D.W., S.W., C.H., C.Y., and M.W. contributed to study design and acquisition of research data. M.W. conducted the data analysis. S.W. and D.W. drafted the article. All authors contributed to improvements of the article for important intellectual content and approved the final version for publication.
Acknowledgments
The authors are indebted to the database of the Web of Science, which provided us unrestricted online access. The authors express their appreciation to Professor CM Chen, who invented CiteSpace, which is free to use.
Author Disclosure Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Funding Information
This work was supported by the National Natural Science Foundation of China (Grant No. 81703248) and Shanghai Municipal Health Bureau (Grant No. 20164Y0002). The funders had no role in the conduct of the study, the analysis or interpretation of data, and the preparation, review, or approval of the article.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.