
Abstract
Functional magnetic resonance imaging (fMRI) has proved to be useful for analyzing the effects of illness and pharmacological agents on brain activation. Many fMRI studies now incorporate effective connectivity analyses on data to assess the networks recruited during task performance. The assessment of the sample size that is necessary for carrying out such calculations would be useful if these techniques are to be confidently applied. Here, we present a method of estimating the sample size that is required for a study to have sufficient power. Our approach uses Bayesian Model Selection to find a best fitting model and then uses a bootstrapping technique to provide an estimate of the parameter variance. As illustrative examples, we apply this technique to two different tasks and show that for our data, ∼20 volunteers per group is sufficient. Due to variability between task, volunteers, scanner, and acquisition parameters, this would need to be evaluated on individual datasets. This approach will be a useful guide for Dynamic Causal Modeling studies.
Introduction
I
Effective connectivity studies using DCM may contribute valuable information regarding the neurobiological mechanisms of psychiatric illnesses (Rowe et al., 2010; Sonty et al., 2007) and psychoactive drug action (Stephan et al., 2007). Before embarking on such studies, it is important to estimate the number of volunteers required for a study to observe the effect of interest. Horwitz (2003) argues that it may be difficult to make inferences from effective connectivity analyses due to variability, arising from volunteers using different strategies for completing tasks and researchers having different hypotheses and specifying different models. Therefore, studies investigating the variability of effective connectivity results are needed. A DCM study using EEG data was carried out by Garrido et al. (2007), who found that Bayesian Model Selection (BMS) chose the same model consistently; however, the variability in the individual parameters was not investigated. A study by Rowe et al. (2010) found DCM and BMS to be reliable and reproducible for the study of Parkinson's disease. Our previous work has shown that nonparametric permutation tests provide more power for testing for between-group differences compared with the parametric equivalent (Goulden et al., 2010).
There are two possible approaches to performing a DCM study comparing two groups (Stephan et al., 2010). The first approach is to use BMS (Penny et al., 2004, 2010; Stephan et al., 2009a) to find a separate best-fitting model for each group, focusing more on the model structure and how it differs between groups. A second approach is to use BMS in both groups together to find a single best-fitting model and then compare parameter values. This article presents a method for estimating the sample size (SS) for a study when the intention is to compare parameter values.
SS estimation has been previously carried out for fMRI studies. A study conducted by Desmond and Glover (Desmond and Glover, 2002) found that for typical activation tasks, 12 volunteers are required to achieve 80% power at a single voxel level of p<0.05 uncorrected. The number of volunteers required when correcting for multiple comparisons doubled to 24.
As illustrative examples, we perform SS estimation for DCM analyses of data from two cognitive tasks, an implicit face emotion processing task previously used by our group to investigate drug effects and the differences between psychiatric groups (Anderson et al., 2007, 2010; Del-Ben et al., 2005) and an n-back task (Honey et al., 2002; Owen et al., 2005; Schlosser et al., 2006).
We employ a bootstrapping procedure that estimates the population variance. Bootstrapping has been previously used in the context of fMRI for activation detection (Darki and Oghabian, 2009) and to assess the stability of resting-state clusters (Bellec et al., 2010).
The implicit face emotion processing task has been used to identify the brain regions associated with face and emotion processing. The brain areas found to be important for face emotion processing include the fusiform gyrus (FG), amygdale, and lateral orbitofrontal cortex (LOFC) (Phan et al., 2002). Tractography studies have also demonstrated white matter tracts between these regions (Cavada et al., 2000; Ghashghaei and Barbas, 2002; Iidaka et al., 2001), making them good candidate regions for an effective connectivity analysis.
The N-back task is generally used to identify the brain regions associated with the working memory. The dorsolateral prefrontal cortex (DPC) is critically involved in this task (Callicott et al., 1999), together with superior frontal areas, including the supplementary motor area (SMA) (Cohen et al., 1997) and the posterior parietal cortex (PPC) (Callicott et al., 1999). Tractography studies have shown white matter tracts between the parietal cortex and SMA (Petrides and Pandya, 1984), parietal cortex and frontal cortex (Petrides and Pandya, 1984), and SMA and frontal cortex (Bates and Goldman-Rakic, 1993; McGuire et al., 1991).
In this study, we initially applied BMS to a number of DCMs and then applied a bootstrapping analysis to the DCM parameters from the selected model in order to estimate the population standard deviation of the parameters of DCM.
Materials and Methods
Volunteers
Twenty-four right-handed volunteers (12 men) aged 18–23 were recruited by local advertisements. This SS has previously been shown to be adequate (Desmond and Glover, 2002) for achieving 80% power at the single voxel level for typical corrected fMRI activations. The local ethics committee approved the study, and each volunteer provided written informed consent before participating. Volunteers had no personal or family history of psychiatric illness and no contraindications to MR scanning.
Implicit face emotion processing task
A series of faces were presented to the volunteers, with an equal number of male and female faces. Emotional faces were presented for 3 sec with a 1 sec gap. There were three blocks of five face stimuli presented (neutral [N], anger [A], and fear [F]) and a rest (R) block where a fixation cross was displayed. Each block was 20 sec long and was shown in NANRNFNRNANRNFNRNANRNFNR order. The total duration of the task was, therefore, 8 min. At each presentation of a face, the volunteers responded with a button press to indicate whether they perceived the face on the screen to be that of a man or a woman; they were not told of any change in the emotion of the faces and were not asked to attend to the faces' emotion.
n-back task
Each block of this task consisted of a series of 13 letters. Each letter was presented for 1.5 sec with a 0.5 sec interval. At the beginning of each block, an instruction screen stated when the subject was to press a button within that block. There were three task blocks: 0-back (Press on appearance of the letter X), 1-back (Press when the letter presented is the same as the previous one), and 2-back (Press when the letter presented is the same as the one before last). There was also a rest block (R) where a fixation cross was presented for the same length of time as the active blocks. Each block was 26 sec long with 9 sec for the instruction screen for each active block with the rest block lasting for 35 sec. The blocks were presented in 01R02R02R01R02R01R order. The total length of the task was 10 min.
Functional magnetic resonance imaging
Images were acquired using a single-shot echo-planar pulse sequence on a 1.5T Phillips Intera scanner (Eindhoven, Netherlands) housed in the Wellcome Trust Clinical Research Facility, University of Manchester, United Kingdom. Each three-dimensional volume comprised 29 contiguous axial slices (repetition time [TR]/echo time [TE]=2100/40 ms, 3.5 mm by 3.5 mm in-plane resolution, slice thickness 4.5 mm with a 0.5 mm gap). A high-resolution T1-weighted structural image was also collected for each volunteer to assist with registration to standard stereotactic space. For the implicit face recognition task, 227 volumes were acquired, while for the n-back task, 285 volumes were acquired. No volumes were discarded before analysis, as the Philips scanner automatically excluded T1 magnetization equilibrium volumes.
Image analysis
All preprocessing was carried out in SPM5 (
The task regressors included in the general linear model comprised all task-active blocks. For the implicit face recognition task, this included blocks of neutral faces, fearful faces, and angry faces. For the n-back task, this included blocks of 0-, 1-, and 2-back, and the time taken to read the instructions at the start of each block. The second task regressor modeled the condition we were interested in for testing modulations for fearful faces and 2-back, respectively. Motion parameters were included as covariates of no interest in the first-level analysis. A random-effects one-sample t-test was carried out for each task in order to identify the activations that were significant across the entire group of volunteers. Data were extracted, and adjusted for effects of interest, from regions of interest defined using the fearful face and 2-back contrasts, respectively.
Dynamic causal modeling
DCM8 analysis was performed using SPM8. For each individual, local maxima were found within 14 mm of the most significant group activation in the prehypothesized areas for each task, using a threshold of p<0.05 uncorrected. Data were then extracted from a 6 mm radius sphere region of interest. The DCM models were specified for brain regions from the right hemisphere only using the toolbox in SPM8. Random effects (BMS) (Stephan et al., 2009a) was used to determine the best intrinsic connectivity model for each task. This approach computes an expected probability and an exceedance probability, the probability that a model is a better fit than any other model in the model space. The intrinsic connectivity models tested for the implicit face emotion processing task and n-back task are shown in Figures 1a and 2a. These models were tested to reveal whether there are feed-forward or reciprocal connections between regions and whether the input region is connected to the most anterior region in the model (OFC and DPC for implicit face recognition and n-back tasks, respectively). In order to assess whether the results were related to model structure, in particular the origin of the input, the n-back task models were tested with the input going into the PPC dotted in Figure 2a and then separately with the input into the DPC. We display the eight intrinsic models tested for simplicity; these models were tested with input into the PPC (labeled models 1–8) and input into the DPC (labeled models 9–16). For the implicit face recognition task, the fully connected intrinsic model, Figure 3a, was the best fit (exceedance probability 0.2822, Figure 1b, where the top plot shows the expected probability, and the bottom plot indicates the exceedance probability). For the n-back task, the fully connected intrinsic model with input entering the DPC, Figure 3b was the best fit (exceedance probability 0.5220, Figure 2b). Models with modulations by fearful faces and 2-back were then tested, using the optimum intrinsic connectivity models for the implicit face emotion processing task and n-back task, respectively. These models are shown in Figure 3c. First, we tested for the possibility that a single feed-forward connection was modulated by an emotion, then all possible pairs of feed-forward connections, and finally, all feed-forward connections. Feed-back connections were then tested in the same way. Finally, we tested reciprocal connection modulations (feed-forward and feed-back), first between one pair of brain regions, then between two pairs of brain regions followed by every connection being modulated.


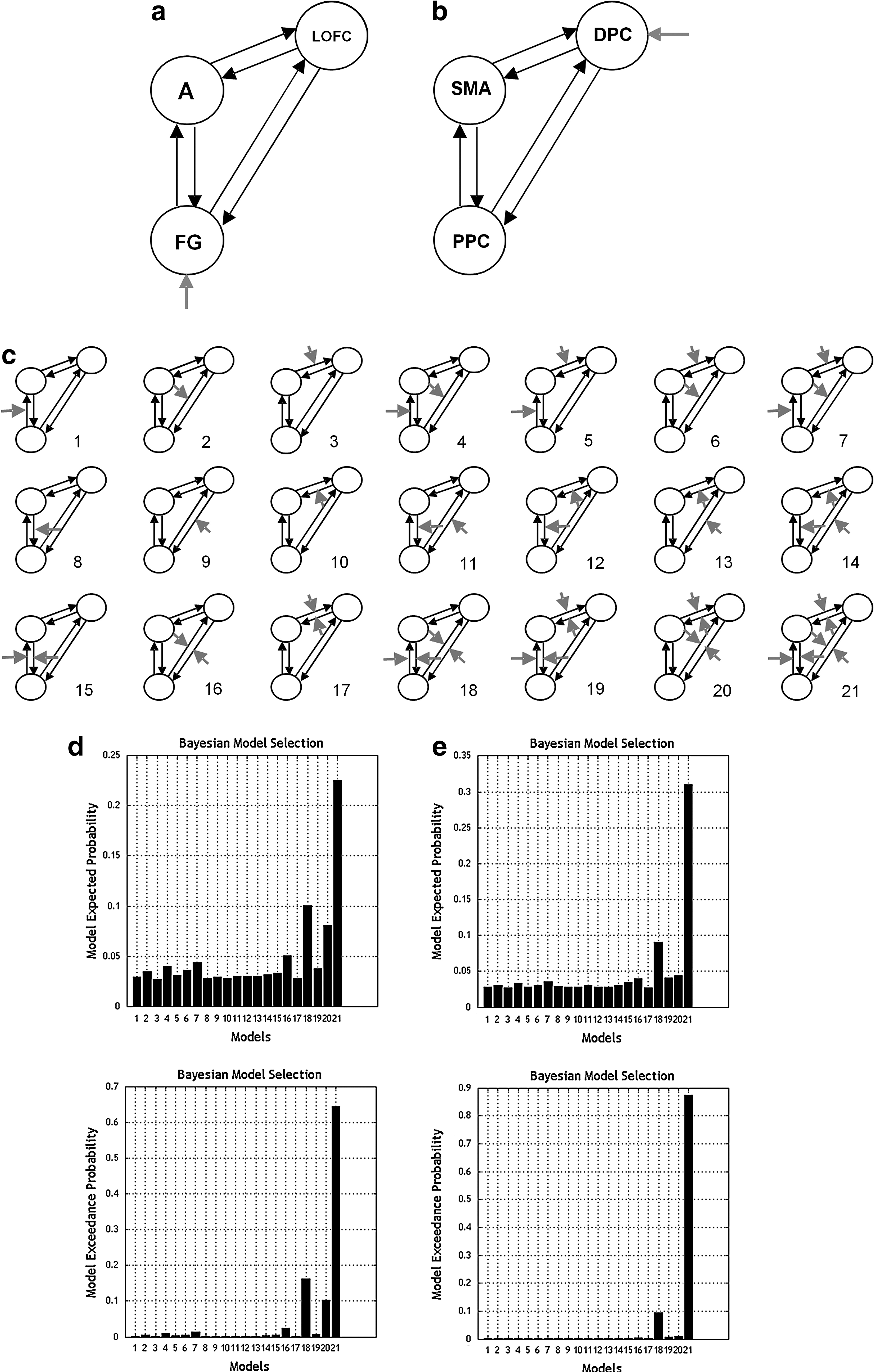
Models for the implicit face emotion processing and n-back tasks.
Bootstrapping inference
Bootstrapping involves sampling with replacement from the original data to construct the distribution of results under the null hypothesis (Good, 2005). We are interested in a two-sample t-test, so random groups are generated, which are of equal size to the groups in our data (i.e., 17 and 22 for n-back and face processing respectively—the size of each group is explained in the results section). The mean was calculated for each of the random groups we generated. This distribution was then used to obtain an estimate of the population standard deviation (s) for each DCM parameter (i.e., calculating the standard deviation of the generated distribution). The bootstrapped distribution of each parameter was also tested for normality using the Kolmogorov–Smirnov test.
The SS necessary to observe a significant difference between the means of two groups of size d may be estimated, using Equation 1 (Dell et al., 2002). This equation is specific to a two-sample t-test and provides the SS per group for achieving 80% power at a significance level of 0.05. A typical difference between means was obtained from two previous effective connectivity studies: phonological processing in children with and without reading difficulties (Cao et al., 2008) and in healthy controls and patients with primary progressive aphasia (Sonty et al., 2007). The models specified had three and six regions, respectively. A typical significant difference between the means of groups was 0.03. In this study, 0.05 was also used as a less stringent test for a larger group difference.
The following section provides the derivation of Equation 1 (Dell et al., 2002), from Snedecor and Cochran (Snedecor and Cochran, 1989). This equation is used to estimate the necessary SS per group. It is important to bear in mind that the SS found using this equation needs to be doubled.
Equation 1: The relationship between effect size (d), standard deviation (s) of the bootstrap distribution, and SS
In order to use Equation 1, the experimenter needs to supply the value of d (the size of the difference of interest), the desired probability, P′, of obtaining a significant result if the true difference is d, and the significance level of the test, α. Assume that the standard deviation, s, is known, and s
Group1
=s
Group2
=s. The power of a two-tailed test of H0: μ=μ0 (null hypothesis of equal means) against HA: μ=μA (alternative hypothesis of nonequal means) is the probability that the normal deviate Z lies in one of the regions, that is,
where Z α denotes the two-tailed significance level. In this case, H0 =μ0=0 and HA=μA=δ, assumed >0.
The test criterion for the independent samples t-test is
Since we want 80% power for the two-tailed test at a 5% significance level, we use Z0.05=1.96. We also need the value for the normal deviate that is exceeded by 80% of the distribution, which is Z=−0.842. Therefore,
The bootstrapping procedure was used to generate 5000 resamples. The entire bootstrapping procedure (i.e., generating 5000 bootstrap resamples) was repeated 1000 times, generating 1000 bootstrap distributions and thereby generating a distribution of SS estimates in order to calculate confidence intervals. The mean of this SS distribution as well as the 95% confidence intervals was calculated, by taking the values for the top and bottom 2.5% of the distribution.
We also assessed the size of the difference between means that could be declared as significant with these data by using Equation 1.
Results
Demographical and behavioral measures
Volunteers were 12 men, mean age 20.25 years (standard deviation [SD] 1.66) and 12 women, mean age 20.08 years (SD 1.56). The mean IQ score for men was 92.92 (SD 8.23), and the mean IQ score for women was 92.67 (SD 6.46). One male volunteer was found to have an IQ of 69 based on the Quick test (>2.5 standard deviations below the mean) and was excluded from subsequent analysis.
Implicit face emotion processing task
Behavioral data
The mean accuracy in the task was 86.6% correct gender identification, and the mean reaction time for classifying the gender of the face was 1254 ms (SD 427.2 ms).
fMRI group activation
Statistically significant voxel level activations were found in the three regions of interest on the right in the fear versus rest contrast at the group level: FG (MNI coords=39, −56, −15; T=8.19, p(FWE)<0.001), amygdala (MNI=25, −7, −20; T=6.68, p(FWE)=0.012), and LOFC (MNI=56, 25, 0; T=5.18, p(FWE)=0.229, p(FWE=0.005 small volume corrected using the WFU PickAtlas mask of the inferior frontal gyrus which contained 611 voxels).
DCM and bootstrapping
Significant amygdala activity was not detected, using a significance level of p<0.05 uncorrected, in 6 volunteers; therefore, the DCM and bootstrap analysis was carried out on data obtained from the remaining 17 volunteers. The best-fitting model found using BMS was model 21 from Figure 3c, and the BMS results are shown in Figure 3d. The exceedance probability for this model was far larger than that for any of the other models (0.6651), making this model the best-fitting model from the model space tested. All the parameter values from the 17 subjects are normally distributed, as shown by the results of a 1-sample Kolmogorov–Smirnov test depicted in Table 1. The SS estimates per group, which need to be doubled for a two-sample t-test, including confidence intervals, are detailed in Table 2, along with the means and standard deviations of the bootstrapping distributions. Examples of the bootstrapping distribution with 5000 resamples are shown in Figure 4 for intrinsic connections emanating from the input regions and not emanating from the input regions, along with the distributions of SS estimates. The SS estimates in Table 2 show that 20 volunteers per group would allow the detection of a significant difference between groups of 0.03, and 8 volunteers would allow the detection of a significant difference between groups of 0.05 in 9 out of the 12 parameters. Correcting for the number of subjects who did not show any amygdala activation makes these numbers 27 for d=0.03 and 11 for d=0.05. The confidence intervals in the SS estimates are small, indicating that these are robust results for these data.

An example of the bootstrap distribution from the face emotion recognition task obtained with 5000 resamples for an intrinsic connection from FG to OFC
All parameters fit a normal distribution.
Amyg, Amygdala; FG, fusiform gyrus; DPC, dorsolateral prefrontal cortex; KS, Kolmogorov-Smirnov; LOFC, lateral orbitofrontal cortex; PPC, posterior parietal cortex; SMA, supplementary motor area.
We also include estimates of the difference between means that could be detected as significant.
CI, confidence intervals; SD, standard deviation; SS, sample size.
The SS values of FG→Amyg and FG→OFC connections and modulations are generally larger than those for the rest of the parameters. By excluding these connections and modulations, the average SS value reduced from 22.7 (25.3) to 10.4 (5.4) for d=0.03 and from 8.8 (9.1) to 4.4 (2.0) for d=0.05.
For the majority of parameters, the difference between means is between 0.01 and 0.03, the typical sizes of differences reported as significant in previous studies. For the intrinsic connection and modulation of the connection from FG to OFC, we are able to detect a larger effect size as significant due to its higher variance (0.0687 and 0.0546, respectively).
The n-back task
Behavioral results
The mean task accuracy was 98% correct responses, and the mean reaction time to targets was 841 ms (SD 172.7 ms). Two volunteers were excluded from the analysis due to poor task performance: One volunteer had a response accuracy that was more than 2.5 standard deviations below the mean, while the other did not respond during any of the 2-back blocks. Therefore, data from 21 volunteers were analyzed for this task.
fMRI activations
Significant maxima were detected in all the hypothesised areas on the right for the 2-back vs. rest contrast at the group level: PPC (MNI=35, −56, 45; T=12.75, p(FWE)<0.001), SMA (MNI=4, 14, 50; T=7.15, p(FWE)<0.001), and DPC (MNI=53, 14, 30; T=7.47, p(FWE)<0.001). A peak level Family Wise Error (FWE) correction was applied.
DCM and bootstrapping
The best-fitting model found by BMS was also model 21 from Figure 3c, with input entering into the DPC. The results are shown in Figure 3e. The exceedance probability for this model was far larger than that for any of the other models (0.8554), making this model the best fitting from the model space tested. The SS estimates and confidence intervals are detailed in Table 2. The SS estimates in Table 2 show that 27 volunteers per group at an effect size of 0.03 and 10 volunteers at an effect size of 0.05 would be sufficient to detect group differences in 8 out of the 12 connectivity parameters. The confidence intervals in the SS estimates are small, indicating that these results are robust for these data.
The SS values of DPC→SMA and DPC→PPC connections and modulations are much larger than those for the rest of the parameters. By excluding these connections and modulations, the average is reduced from 22.4 (13.8) to 14.4 (6.0) for d=0.03 and from 8.7 (5.0) to 5.8 (2.2) for d=0.05.
For the majority of parameters, the difference between means is between 0.02 and 0.03, typical sizes of differences reported as significant in previous studies. For the intrinsic connection and modulation emanating from the DPC, we are able to detect larger differences between means, the largest being 0.0469 for the intrinsic connection from DPC to SMA due to its higher variance.
Discussion
A method has been presented for calculating SS estimates for DCM parameters after using BMS to select the best-fitting model. The four connectivity parameters that show large SS estimates compared with the estimates for the other parameters are those emanating from the driving input region. This is possibly due to the higher prior variance on driving inputs than on other parameters, causing a much wider bootstrap distribution. We would, therefore, suggest structuring models so that the connections/modulations of interest are not emanating from the input region. This effect is demonstrated in Figure 4 and Table 2.
The SS estimates reported are similar to those estimated for detecting group activation in fMRI studies; typically, 12 volunteers to provide 80% power (Desmond and Glover, 2002). A study of an event related task by Murphy and Garavan (Murphy and Garavan, 2004) found that with 20 volunteers, the centre of mass of the activated areas falls within 25 mm of each other. A further study by Thirion et al. (2007) has shown that at least 20 volunteers per group are required for an fMRI study, preferably 27. However, the exact numbers required depend on the task being analyzed and the effect size of interest.
Previous work using the DCM which studies face perception has demonstrated that viewing emotional faces increases the effective connectivity between the FG and amygdala (Fairhall and Ishai, 2007; Ishai, 2008). This connection is also modulated in our study as a result of viewing fearful faces. The same study also demonstrated that viewing famous, attractive faces increases the connectivity between the FG and the orbitofrontal cortex. This is not something that we tested for during the present study.
Since the DCM is a Bayesian modeling method, the choice of previous probabilities is very important, as this will influence the parameter estimation. The DCM uses uniform previous probabilities for estimating parameter values; however, work has shown that using previous probabilities based on results from Diffusion Tensor Imaging data improves the model fit (Stephan et al., 2009b). It may seem strange that the BMS chose the most complex model; however, model selection now uses the free energy as opposed to the original Akaike's Information Criterion (AIC) (Akaike, 1983) and Bayesian Information Criterion (BIC). The free energy account, for interdependencies or covariances among parameters; so, there is no longer a bias toward the simplest model. In this study, we chose to perform our BMS analysis in two steps. This allowed us to more easily identify the best-fitting intrinsic model and also to test for modulations of this model.
Concerns have been raised over the validity of the model selection procedure. Lohmann et al. (2011) raise issues concerning model fit and model validity. This work showed that it is possible for randomly generated models to have a better fit to the data than the best-fitting plausible model. The authors also show that the best-fitting model found using BMS does not necessarily have a good fit to the data. Since we have specified a set of what we consider to be plausible models, we may state that we have found the best-fitting model from among the ones we have tested. The issue that the authors raise is the lack of a systematic way of constructing the model space, and, hence, different researchers will construct different model spaces. The ideal solution would be a method of generating all plausible models to test so that any two independent researchers would test the same models. The issue with model fit to the data should be avoided if data are carefully extracted using a high enough significance threshold that the time series are not noisy, and this is the main reason we do not include certain individuals who do not show significant responses around the chosen foci.
A response to these criticisms has been provided by Friston et al. (2011). As stated in the previous paragraph, the issue with combinatorial explosion of models only arises when one is interested in finding the best-fitting model. This is typically not the goal of BMS with DCM, which is to rather identify the best-fitting model among a set of well-motivated competing hypotheses. They also highlight the fact that a family-level analysis would have been a more appropriate way of testing some hypotheses, that is, the most likely model having no input to V1. This should have been demonstrated with a family-level analysis of models with input to V1 versus models with no input to V1. With regard to comments on noise levels in brain regions, this should make no difference, as it should still be possible to identify the model with the largest model evidence.
The criterion used for model selection is important and may influence any inference made. In order to investigate whether BMS favors more complex models, we redid the model selection using Akaike & Bayesian Information Criterion (AIC/BIC). For the implicit face recognition task, there was a bias toward a much simpler model, model 2; however, there was not such a strong bias for any particular model for the n-back task with complex models preferred as consistently as simple ones. The winning model in the case of the n-back was model 18. We also redid the SS estimates using the models preferred by AIC/BIC and compared them with the SS estimates from the models selected using BMS. The SS estimates increased for the majority of the connections for both tasks, suggesting a lot more variance in the models selected using AIC/BIC.
We chose to exclude volunteers who did not display activation of the amygdala in the implicit face emotion processing task. The reason for this was to prevent noise from entering into the model, as this would have affected the model estimation. However, this does bias the sample studied and would possibly skew the distribution of results. Optimizing the imaging sequence for detecting amygdala activation is important for these types of tasks. The possibilities include thinner slices with a longer TR (Robinson et al., 2004), but this may compromise the reliability of DCM. The gender identification accuracy is low, which could be due to some of the pictures either not being clear enough or too ambiguous with regard to gender; in the task, there were 6 pictures for which none of the subjects provided a correct gender classification. The gender identification accuracy had no bearing on whether amygdala activation was observed or not.
The number of subjects used in this study is a limitation to performing SS estimates, particularly for the implicit face emotion processing task. Previous studies [e.g., (Thirion et al., 2007)] have recruited far larger samples; however, these studies have aimed at producing SS estimates that are generalizable to all future studies. The aim of this work is slightly different, as the results of these calculations are only generalizable to the task and scanner for which the results have been calculated. This is more of a post hoc test of SS and effect size. This method would be useful to perform on pilot data for estimating SS for a larger study. The new version of DCM, DCM10, is now being used for estimating parameter values. One of the main differences between DCM8 and DCM10 is that DCM10 employs a simpler model inversion to allow for nonlinear and stochastic DCMs. This means that the parameter estimates will be different for DCM8 and DCM10 estimation; however, it will still be possible to use the current SS estimation procedure for DCM10 estimated models to guide future studies.
This work has focused on two-sided two-sample t-tests between groups. It is important to point out that these types of SS calculations can be performed for different statistical tests, including paired tests, correlations, and one-sample tests. A summary of the equations for each is presented in Dell et al. (2002).
Our previous work has demonstrated that nonparametric tests provide more power than parametric tests when comparing group differences (Goulden et al., 2010). This could also help with increasing the power of a study. Given the importance of BMS for DCM, estimating the SS required for consistent model selection results would be an important extension to this work.
Footnotes
Acknowledgments
The authors acknowledge the Magnetic Resonance Imaging Facility, University of Manchester, UK, for sponsoring the scanning costs and would like to thank the staff at the Wellcome Trust Clinical Research Facility, Manchester, UK, for their assistance in conducting the study.
Author Disclosure Statement
No competing financial interests exist.