
Abstract
Recent studies on brain networks have suggested that many brain diseases, such as Alzheimer's disease and mild cognitive impairment (MCI), are related to a large-scale brain network, rather than individual brain regions. However, it is challenging to find such a network from the whole brain network due to the complexity of brain networks. In this article, the authors propose a novel method to mine the discriminative subnetworks for classifying MCI patients from healthy controls (HC). Specifically, the authors first extract a set of frequent subnetworks from each of the two groups (i.e., MCI and HC), respectively. Then, measure the discriminative ability of those frequent subnetworks using the graph kernel-based classification method and select the most discriminative subnetworks for subsequent classification. The results on the functional connectivity networks of 12 MCI and 25 HC show that this method can obtain competitive results compared with state-of-the-art methods on MCI classification.
Introduction
Alzheimer's disease (AD), characterized by progressive impairment of cognitive and memory functions, is one of the most prevalent neurodegenerative brain diseases in elderly people. It was first described by a German psychiatrist and neuropathologist Alois Alzheimer in 1906 and was named after him (Berchtold and Cotman, 1998). AD is the most common form of dementia worldwide, and it is predicted that AD will affect 1 in 85 people by 2050 (Brookmeyer et al., 2007). The prodromal stage of AD is called mild cognitive impairment (MCI), which is an intermediate state of cognitive function between normal aging and dementia. Existing studies have shown that MCI subjects progress to clinical AD at an annual rate of ∼10–15% (Petersen et al., 2001). Some individuals with MCI remain stable or return normal over time, but more than half progress to dementia within 5 years (Gauthier et al., 2006). Thus, accurate diagnosis of AD, especially MCI, is very important for possible early treatment and delay of the progression of the disease.
In the past decades, researchers have proposed a lot of methods to extract imaging biomarkers (e.g., voxelwise and regional features) from magnetic resonance imaging (MRI) and other imaging modalities, for early diagnosis of AD and MCI, and significant progress has been achieved (Cuingnet et al., 2011; Huang et al., 2000; Mosconi et al., 2005; Zhang et al., 2011). At present, several modalities of biomarkers have been proved to be sensitive to AD and MCI, including (1) the brain atrophy measured in MRI (McEvoy et al., 2009); (2) pathological amyloid depositions measured through the cerebrospinal fluid (Mattsson et al., 2009; Shaw et al., 2009); and (3) metabolic alterations in the brain measured by fluorodeoxyglucose positron emission tomography (Morris et al., 2001). Moreover, multimodal methods are proposed to combine multiple modalities for improving the AD/MCI classification performance (Zhang et al., 2011), which achieves a classification accuracy of 93.2% for identifying AD from healthy controls (HC) and a classification accuracy of 76.4% for identifying MCI from HC.
Recently, besides individual brain regions, the patterns of structural or functional connectivity of the human brain have also received great attention in neuroimaging studies (Robinson et al., 2010; Sporns, 2012; Xie and He, 2011). Existing studies show that we can obtain a better understanding of the brain disease pathology through exploring structural and functional interactions among brain regions (Sporns, 2012; Wang et al., 2013; Xie and He, 2011). Several attempts have been made to map the structural connectivity of human brain. One study derived structural connection patterns from cross-correlations in cortical thickness or volume across individual brains (He et al., 2007). The structural connectivity has also been mapped based on the brain gray matter areas, which were obtained using diffusion tensor imaging (Iturria-Medina et al., 2007). The functional connectivity refers to the functional association among brain regions that are predefined by neurophysiological events (i.e., Hippocampus) (Kaiser, 2011; Wang et al., 2013). Different from structural network analysis, which helps to understand the fundamental architecture of connections between brain regions (Chen et al., 2008), functional network analysis directly elucidates how this architecture supports neurophysiological dynamics (Stephan et al., 2000).
Some recent studies have explored brain networks and reported different network patterns between patients and HC, which are supposed to convey pathologically relevant information of brain diseases (Busatto et al., 2003; Filippi and Agosta, 2011; Sperling et al., 2003; Xie and He, 2011). For instance, small-world characteristic, which is characterized by a high degree of clustering and short path lengths, has been found to be disrupted in the functional brain networks of AD/MCI (Bai et al., 2012; Sanz-Arigita et al., 2010; Stam et al., 2007). In addition, the functional connectivity between the hippocampus and other regions of the AD/MCI brain has been found to be decreased (Supekar et al., 2008; Wang et al., 2007), while the functional connectivity between the frontal lobe and other brain regions in early AD/MCI brain had been reported to be increased (Gould et al., 2006; Stern, 2006).
Network analysis provides a new way for exploring the association between brain functional deficits and the underlying structural disruption related to brain disorders. Recently, (anatomical/functional) connectivity networks have been constructed for analysis of AD and MCI with brain region as node and anatomical connection or functional association as link (Rubinov and Sporns, 2010), and lots of anatomical or functional connectivity networks-based methods have been proposed for prediction of AD and MCI (Jie et al., 2013a; Petrella et al., 2011; Wee et al., 2012b; Zhou et al., 2011). To the best of knowledge, existing (anatomical/functional) connectivity networks-based AD/MCI studies can be roughly divided into two categories, that is, (1) group comparison and (2) individual classification.
Most existing works on (anatomical/functional) connectivity networks-based AD/MCI studies belong to the first category, that is, group analysis. Graph theoretical analysis is often used to demonstrate the differences in the topology of brain networks between AD/MCI patients and HC and, thus, can better understand the relationship between brain connectivity and the disease processes (Rossini et al., 2006; Stam et al., 2007; Supekar et al., 2008; van Wijk et al., 2010) [for review, see the references (Liu et al., 2008; Tijms et al., 2013)]. Some graph properties (e.g., small-world, centrality and efficiency) are often adopted in group analysis methods (Sanz-Arigita et al., 2010). For example, the small-world characteristic has been used to analyze the brain network of AD patients (Supekar et al., 2008).
In the second category, machine learning methods have been applied to identify the patients with AD/MCI from HC at the individual level (Richiardi et al., 2012; Wee et al., 2011; Zhou et al., 2013). These methods usually first extract a series of features (e.g., local clustering coefficients) from the brain network and then use those extracted features to train a classifier (e.g., support vector machine) (Chen et al., 2011; Wang et al., 2006; Wee et al., 2011). More recently, in one of the previous works (Jie et al., 2013b), the graph kernel technique was used for structural feature selection, to obtain the most discriminative brain regions based on topological similarity between networks. It is noteworthy that in (Jie et al., 2013b), it is still needed to extract the features (i.e., local clustering coefficients) as done in the existing (anatomical/functional) connectivity networks-based classification methods (Wee et al., 2012a; Xie and He, 2011). On the other hand, existing studies have shown that many brain diseases, such as AD and MCI, are related with a larger scale brain network, not only on the single brain regions (Sanz-Arigita et al., 2010). However, it is challenging to find such a network from the whole connectivity network due to the complexity of brain networks. To the best of knowledge, few works have employed the subnetwork, especially discriminative subnetwork, for classification of brain diseases.
In this article, the authors present a new method based on connectivity measures for functional connectivity networks-based MCI classification. In this study, the hypothesis is that there exist different frequent and discriminative subnetwork patterns between the MCI group and HC group. The main idea of this method is to directly mine the discriminative subnetwork patterns from the functional connectivity network and then use them for subsequent classification between MCI patients and HC. Specifically, the authors first extract a set of frequent subnetworks from each of the two groups (i.e., MCI and HC), respectively. Then, measure the discriminative ability of those frequent subnetworks using the graph kernel-based classification method and select the most discriminative subnetworks for subsequent classification. The authors validate this proposed method on the functional connectivity networks of 12 MCI and 25 HC, and the experimental results show that this method outperforms the state-of-the-art functional connectivity networks-based method in the classification of MCI.
Contribution
The authors' contribution in this article is threefold: First, they propose a discriminative subnetwork mining (DSM) algorithm to discover the discriminative patterns underlying the whole brain network. Second, they apply this method for functional connectivity networks-based MCI classification. Last, the experimental results on MCI classification validate the efficacy of the proposed method.
Materials and Methodology
Materials
In the current study, the authors used the same dataset as in (Jie et al., 2013b). Table 1 gives the demographic and clinical information of the participants. All the recruited subjects were diagnosed by expert consensus panels. All the subjects were scanned using a 3T scanner with the following parameters: repetition time (TR)=2000 msec, echo time (TE)=32 msec, flip angle=77°, acquisition matrix=64×64, FOV=256×256 mm2, 34 slices, 150 volumes, and voxel size=4 mm. All participants were required to keep their eyes open and stare at a fixation cross in the middle of the screen during scanning, which lasted for 5 min.
Demographic and Clinical Information of the Participants
The p-value was obtained by two-sample two-tailed t-test.
HC, healthy controls; MCI, mild cognitive impairment.
Methodology
Overview of method
Figure 1 gives the flowchart of the proposed method, which includes four main steps: (1) preprocessing, where the functional connectivity networks are constructed from raw functional MRI (fMRI) image data; (2) frequent subnetwork mining, where two sets of frequent subnetworks are mined from the functional connectivity networks of MCI and HC groups, respectively; (3) DSM, where the most discriminative subnetworks are selected by evaluating the respective classification ability of the frequent subnetworks on training data; (4) classification, where the graph kernel-based classifier is used for final classification of MCI from HC based on the selected discriminative subnetworks.
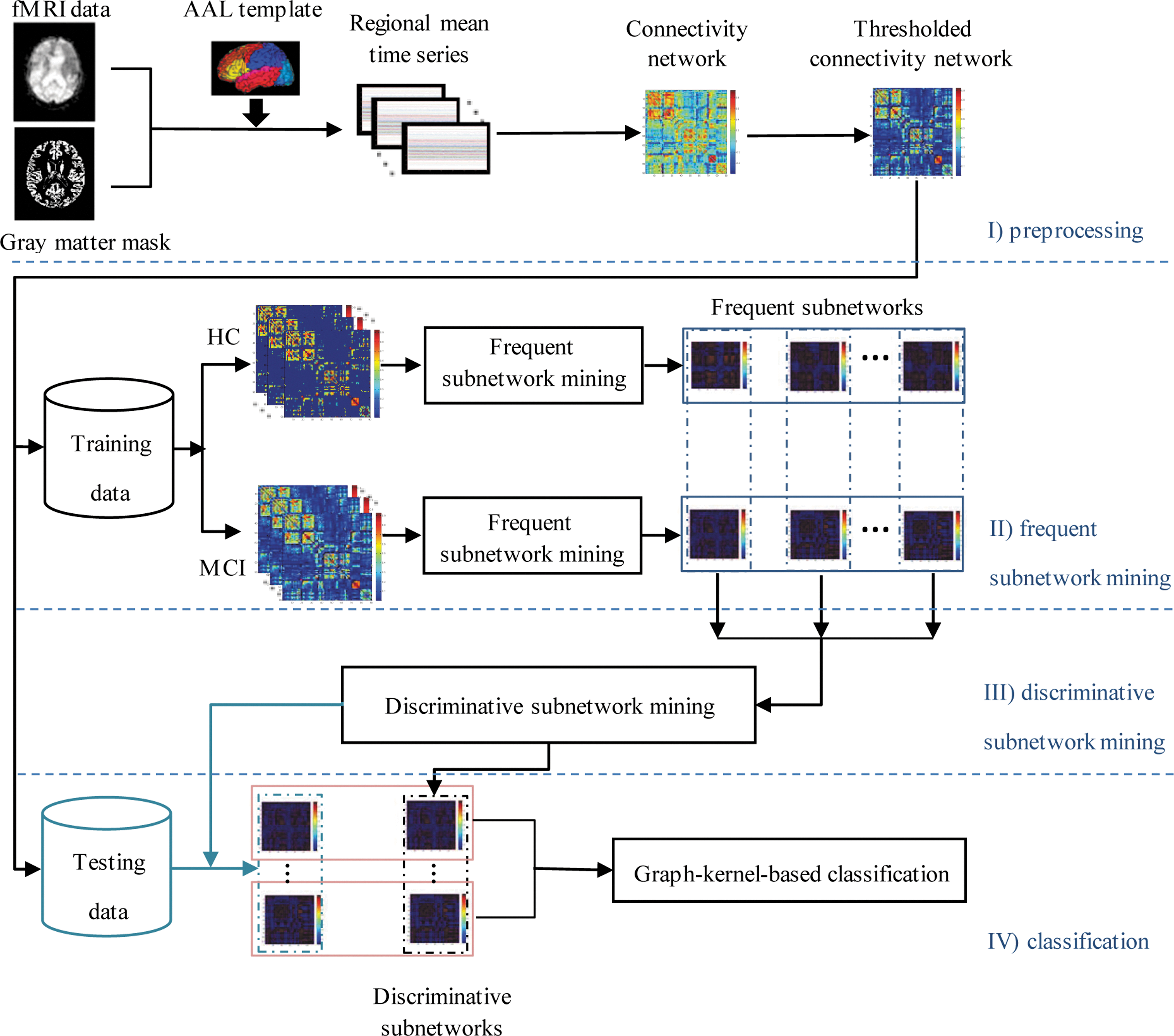
The framework of the proposed method. AAL, automated anatomical labeling; fMRI, functional magnetic resonance imaging; HC, healthy controls; MCI, mild cognitive impairment. Color images available online at
Preprocessing
The authors followed a similar procedure as in (Jie et al., 2013b). Specifically, the fMRI images were first preprocessed by applying the typical procedures of slice timing, motion correction, and spatial normalization using the Statistical Parametric Mapping software package (SPM8) (
where r is the Pearson correlation coefficient and z is approximately a normal distribution with standard deviation
Frequent subnetwork (subgraph) mining
In this section, the authors introduce the frequent subgraph mining algorithm to discover the most frequent subnetwork patterns for MCI and HC, respectively. In the data mining community, a number of methods have been proposed for frequent subgraph mining (Borgelt and Berthold, 2002; Huan et al., 2003; Yan and Han, 2002). For example, FSG (Kuramochi and Karypis, 2004) finds all frequent subgraph connected subgraphs by using the breadth-first search strategy to grow candidates, whereby pairs of identified frequent k subgraphs are joined to generate (k+1) subgraphs. Apriori-based graph mining (Inokuchi et al., 2000) uses an adjacency matrix to represent graphs, and a levelwise search to discover frequent subgraphs. For more methods on frequent subgraph mining, please refer to (Jiang et al., 2013) for a recent review. In this study, the authors adopt the well-known gSpan algorithm (Yan and Han, 2002) for mining the frequent subnetworks (subgraphs) from the functional connectivity networks because of its time efficiency (Krishna et al., 2011). Before giving the details of gSpan, there are some preliminaries used to derive the gSpan algorithm (Yan and Han, 2002) for frequent subgraph mining.
Definition 1 (Labeled Undirected Graph)
Let G=(V, E, L, l) be a labeled undirected graph, where V is a set of nodes and E⊆V×V is a set of edges. e={u,v} indicates an edge between the nodes u and v. L is a set of labels, and l is a mapping function that assigns labels to vertices in V and edges in E.
Definition 2 (Subgraph)
For two labeled undirected graphs, Gs =(Vs , Es , Ls , ls ) and G=(V, E, L, l), Gs is a subgraph of G if Vs ⊆V, Es ⊆E, Ls ⊆L, and ls =l.
Definition 3 (Graph Isomorphism)
A graph
Definition 4 (Subgraph Frequency Ratio)
Given a set of graphs,
Definition 5 (Frequent Subgraph)
Given a set of graphs,
Definition 6 (Frequent Subgraph Mining)
Given a set of labeled undirected graphs,
Definition 7 (Intersect-graph)
Given two graphs, G 1=(V 1, E 1) and G 2=(V 2, E 2), the intersect-graph G′=(V′, E′) (denoted as G 1∩G 2) is defined as E′=E 1∩E 2, all the nodes in edges set E′ form the nodes set V′.
Definition 8 (depth-first search [DFS] code)
Given a DFS tree T for a graph G, an edge sequence (ei
) can be constructed based on
DFS lexicographic order
In this subsection, the authors introduce how gSpan maps each graph into a unique minimum DFS code (Yan and Han, 2002). The authors use subscripts to label the nodes in terms of the DFS order. The node vi
is discovered befor node vj
if i<j. For the DFS tree, all the edges in the DFS tree are called forward-edge, and the edges that are not in the DFS tree are called backward-edge. A linear order,
Then, an edge can be simply represented by a five-tuple (i, j,l 1, l (i,j), l j). In this study, li and lj are the labels of vi and vj , respectively, and l(i,j) is the label of the edge (vi, vj ).
The DFS lexicographic order is a linear order defined as follows:
(i)
(ii)
Given a graph G, the minimum one of all the DFS lexicographic order is called Minimum DFS Code of G. It is also a canonical label of G. Figure 2 shows a DFS code tree, where all the minimum DFS codes of frequent subgraphs can be discovered through DFS of the code tree. It is noteworthy that the red nodes contain the same subgraph with different DFS codes, but g′ is not the minimum DFS code, so the whole branch of g′ can be pruned because it will not contain any minimum DFS code.
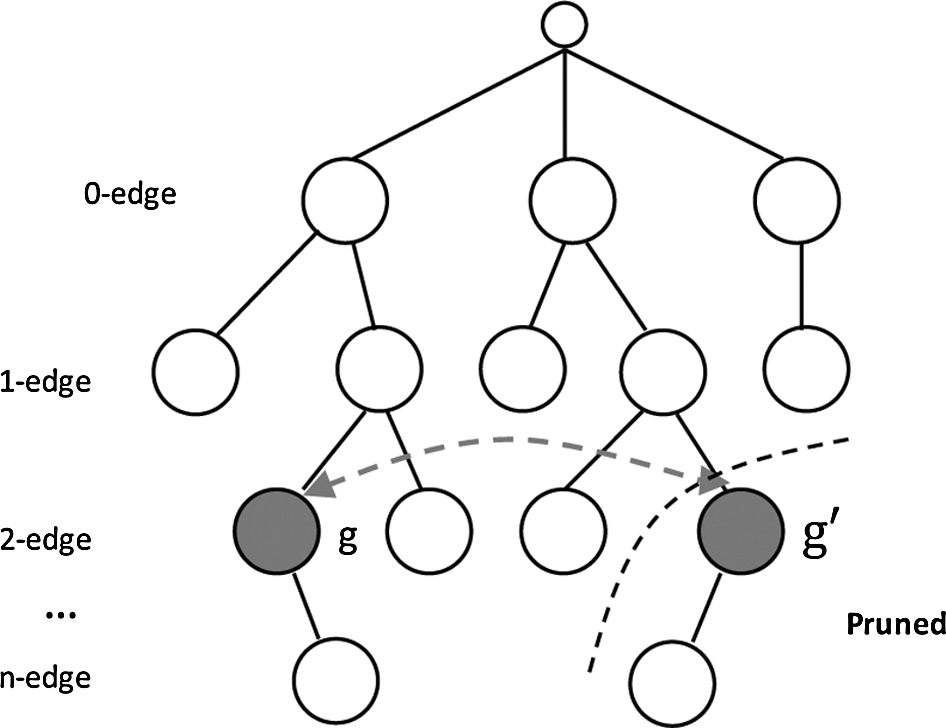
A search space: DFS code tree. DFS, depth-first search.
In summary, gSpan first constructs a new lexicographic order among graphs, and maps each graph into a unique minimum DFS code as its canonical label. Then, based on the lexicographic order, gSpan utilizes the DFS strategy to mine frequent connected subgraph patterns efficiently. In this study, the hierarchical search space of frequent subgraph is called a DFS code tree, and each node of the search tree represents a DFS code (i.e., subgraph). The k+1-th level subgraph is generated from the k-th level subgraph (i.e., parent) by adding one frequent edge. Finally, all subgraphs with nonminimal DFS code are pruned to avoid redundant candidate generations (Yan and Han, 2002).
In the Appendix 1, there is a toy example to illustrate the DFS lexicographic order used in frequent subgraph mining and also list the detailed gSpan algorithm (see algorithm 3).
Discriminative subnetwork mining
In the previous section, the authors have introduced the gSpan algorithm. It is worth noting that gSpan is only used for mining the frequent subgraph, which by itself does not have any discriminative power. Accordingly, in this study, the authors perform gSpan to extract two sets of frequent subgraphs (e.g., subnetworks) from the MCI group and HC group, respectively. However, some of the frequent subnetworks may still have less discriminative information for classification. To address that problem, it is further proposed to select the most discriminative subnetworks from those frequent subnetworks using a graph kernel-based classification method. In the following, the authors first introduce the graph kernel technique.
Graph kernel
Roughly speaking, kernel can be seen as a similarity measure between a pair of subjects, which maps the data from the original space into a higher dimensional feature space, where the data are more likely to be linear separable. Given two subjects x sand x′, the kernel can be defined as
where φ is a mapping function that maps data from input space to feature space. Besides the feature vector, kernel can also be applied on more complex data types, for example, graph, with the corresponding kernel called graph kernel (Vishwanathan et al., 2010). Graph kernel can be seen as a function that measures the topological similarity of pairs of graphs. In recent years, lots of methods have been proposed to construct graph kernel, which include walk-based (Gartner et al., 2003), path-based (Alvarez et al., 2011), subtree-based kernels (Shervashidze et al., 2011), and so on. Graph kernel has been widely used for image classification (Harchaoui and Bach, 2007) and protein function prediction (Borgwardt et al., 2005).
In this study, following the previous work (Jie et al., 2013b), the authors adopt the Weisfeiler-Lehman subtree kernel, which is based on the Weisfeiler-Lehman test of isomorphism (Shervashidze et al., 2011). Given two graphs, the basic process of the Weisfeiler-Lehman test is as follows: if those two graphs are unlabeled (i.e., vertices of the graph have not been assigned labels), first label each vertex with the number of edges that are connected to that vertex. Then, at each iteration step, the label of each vertex is updated based on its previous label and the labels of its neighbors. That is, compress the sorted set of updated node labels of each vertex into a new and shorter label. This process iterates until the node label sets are identical, or the number of iteration reaches its predefined maximum value.
Given two graphs G and H, let
where
and
In this study, ci (G, σ ij ) and ci (H, σ ij ) are the number of occurrences of the node label σ ij in G and H with the i-th iteration, respectively. It is noteworthy that the graph used in this study is the undirected graph.
The DSM algorithm
The authors first choose the same number of frequent subnetworks from each group and construct multiple pairs of subnetworks across two groups. It is noteworthy that each pair of frequent subnetworks represents two types of connectivity patterns from patient and normal controls. For each pair of frequent subnetworks, they utilized graph kernel proposed in (Shervashidze et al., 2011) to measure the similarity between the training data and the frequent subnetworks and classify the training data to the class with a high graph kernel value. Figure 3 gives a toy example of how to measure the similarity between brain networks. After that, the authors choose those pairs of frequent subnetworks with the best classification accuracy as the most discriminative subnetworks.
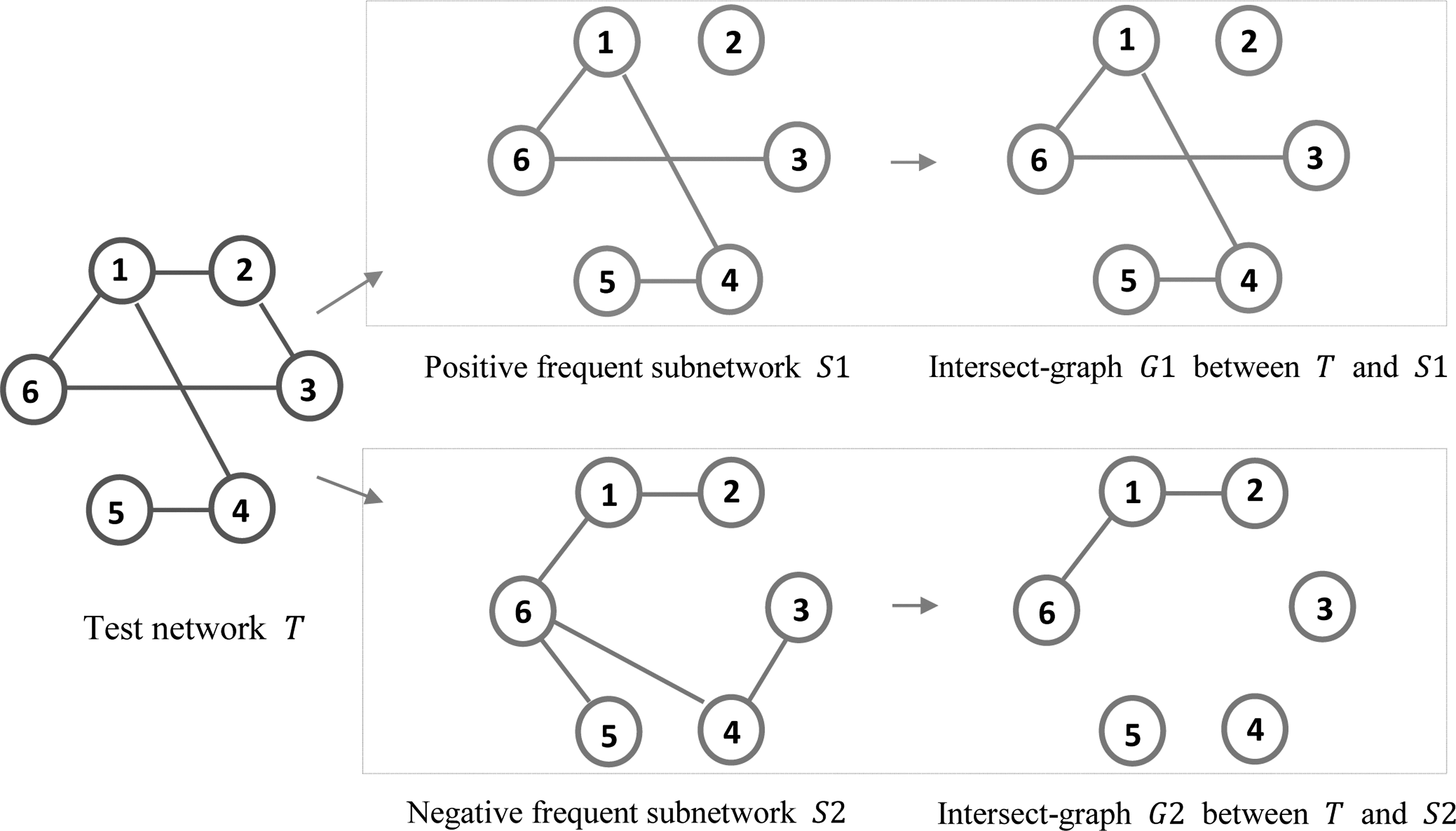
Illustration on similarity comparison between brain networks. In this study, the similarity between G1 and S1 is 12, while the similarity between G2 and S2 is 8. The similarity is measured by Weisfeiler-Lehman subtree kernel after 1st iteration.
Algorithm 1 summarizes the details of the proposed DSM algorithm. In this study,
Training subjects
Two sets of discriminative subnetworks DS 1 and DS 2
1:
2: Initialize a temporary list C=[];
3:
4:
5:
6: Compute the graph kernel using Eq. (3) on
7: Classify G to the class with larger graph kernel value;
8:
9: Compute the accuracy c on
10: Update list C=[C, c];
11:
12: Sort S 1, S 2 according to the C in a descending order;
13: Select the top k subnetworks of S 1 and S 2 as discriminative subnetworks;
Classification
For classification of testing subject, the authors also compute the graph kernel between each discriminative subnetwork and the intersect graph between the testing subject and that discriminative subnetwork, and then perform a graph kernel-based classification. Specifically, the authors obtain two sets of graph kernel values, one by measuring the topological similarity (through graph kernel) between the subnetworks from the MCI group and corresponding intersect graph of the testing subject, and the other by measuring the similarity between the subnetworks from the HC group and corresponding intersect graph of the testing subject. Then, the authors classify the testing subject to the class with the highest graph kernel value. Algorithm 2 gives the detailed procedure of the graph kernel-based classification. In this study, DS
1 and DS
2 represent two sets of discriminative subnetworks, which are obtained using the DSM algorithm, G represents a graph in test subject set
Discriminative subnetwork sets DS
1 and DS
2, testing subject set
Classification accuracy acc
1:
2:
3:
4: Compute the graph kernel on
5:
6: Classify G to the class which has larger graph kernel value;
7:
8: Compute the accuracy acc on
Validation
To evaluate the performance of this method, the leave-one-out cross-validation strategy was adopted in the experiment. Specifically, at each fold, one subject was left out for testing and the remaining subjects were used for training, and this process was repeated for each subject. The authors use the classification accuracy and the area under the ROC curve (AUC) as performance measures to quantify the results. Specifically, classification accuracy measures the effectiveness of predicting the true class label. The AUC measures the probability that when one positive and one negative sample are drawn at random, the decision function assigns a higher value to the positive than to the negative sample.
The functional connectivity networks were thresholded by using a predefined threshold T=0.3 to validate the classification performance of the proposed method. The authors used the gSpan algorithm to search for frequent subnetworks in thresholded functional connectivity networks of MCI and HC with corresponding supports s=9/11 and s=22/24, respectively. The number of iteration h in Weisfeiler-Lehman subtree kernel algorithm was set as 3.
Results
Comparison on classification performance
In this section, the authors evaluate the classification performance of the proposed method by measuring the classification accuracy. For comparison, they also give the results of other functional connectivity networks-based classification methods, including (Jie et al., 2013b, 2014; Wee et al., 2012a). Specifically, the core of (Jie et al., 2013b) is using a graph kernel-based approach to measure the topological similarity between functional connectivity networks, and the method in (Jie et al., 2014) integrates multiple properties of connectivity (i.e., local clustering coefficients, and global topological properties) for improving the classification performance. Also, in (Wee et al., 2012a), the authors utilize a multispectrum strategy to construct multiple functional connectivity networks for each subject, and then local clustering coefficients are extracted as features for MCI classification. Table 2 gives the classification performances of all compared methods. As can be seen from Table 2, the proposed method achieves a best classification accuracy of 97.30% with an increment of at least 5.4% from all other compared methods. Actually, only one MCI subject is misclassified by this method. Also, this method outperforms all other methods in the AUC performance measure.
The Classification Performances of Different Methods
The bold values are the best for comparison.
AUC, area under ROC curve.
The connectivity analysis
By mining the frequent and discriminative subnetworks of the functional connectivity networks for MCI and HC, this method may also help gain a better insight of the topological differences of the brain network between MCI and HC. Figure 4 shows the mined discriminative and frequent subnetworks from the MCI and HC groups. As can be seen from Figure 4, MCI and HC have very different connectivity patterns in the mined subnetworks. Specifically, compared with that of HC, there exist possible disruptions in the connectivity of MCI between certain regions that are consistent with existing findings reported in previous studies (Davatzikos et al., 2011; Grady et al., 2003; Han et al., 2011). For example, in HC, the mined frequent and discriminative subnetworks contain visual and auditory brain regions, with strong connections between these brain regions, while the connections in those brain regions are disrupted for MCI.
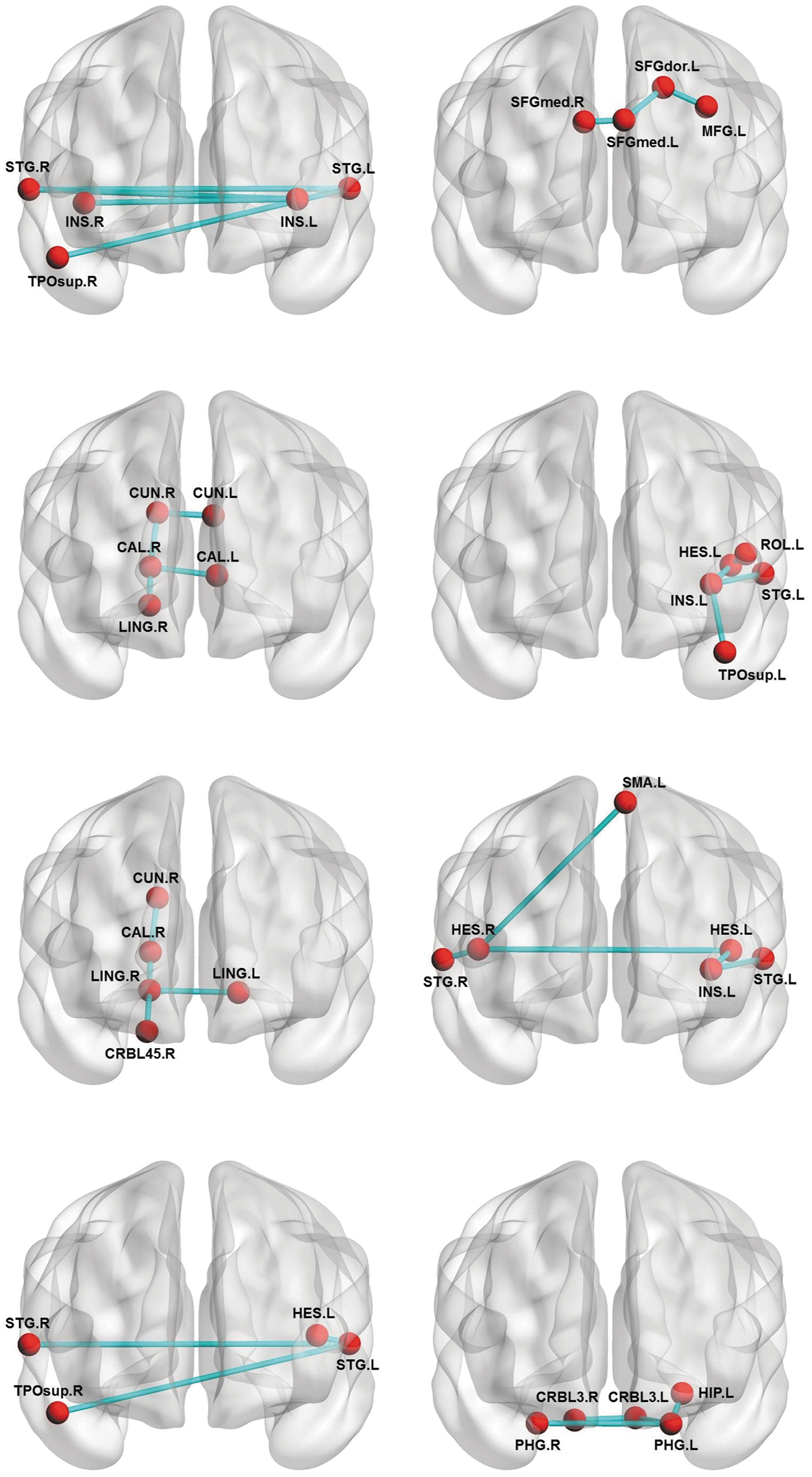
The discriminative subnetworks of healthy controls (the left column) and mild cognitive impairment (the right column). INS.L, left insula; INS.R, right insula; STG.L, left superior temporal gyri; STG.R, right superior temporal gyri; TPOsup.R, right superior temporal pole; TPOsup.L, left superior temporal pole; CUN.R, right cuneus; CUN.L, left cuneus; CAL.R, right calcarine sulcus; CAL.L, left calcarine sulcus; LING.R, right lingual gyrus; LING.L, left lingual gyrus; CRBL45.R, right lobule IV, V of cerebellar hemisphere; HES.R, right transverse temporal gyri; HES.L, left transverse temporal gyri; SFGmed.R, right superior frontal gyrus, medial part; SFGmed.L, left superior frontal gyrus, medial part; SFGdor.L, left superior frontal gyrus, dorsolateral; MFG.L, left middle frontal gyrus, lateral part; ROL.L, left rolandic operculum; SMA.L, left supplementary motor area; HIP.L, left hippocampus; PHG.L, left parahippocampal gyrus; PHG.R, right parahippocampal gyrus; CRBL3.L, left Lobule III of cerebellar hemisphere; CRBL.R, right Lobule III of cerebellar hemisphere. Figures were visualized using BrainNet Viewer (
Discriminative regions
In this section, the authors count the number of occurrences of ROIs from all the mined discriminative subnetworks, and then choose the top 14 ROIs with the highest occurrences as the discriminative regions. Table 3 lists these top ranked ROIs, which are visually plotted in Figure 5. As can be seen from Table 3 and Figure 5, the discriminative regions include insula, calcarine sulcus, lingual gyrus, transverse temporal gyri, superior temporal gyrus, which are mostly related to vision, auditory processes, function of language, social cognition, and information processes.
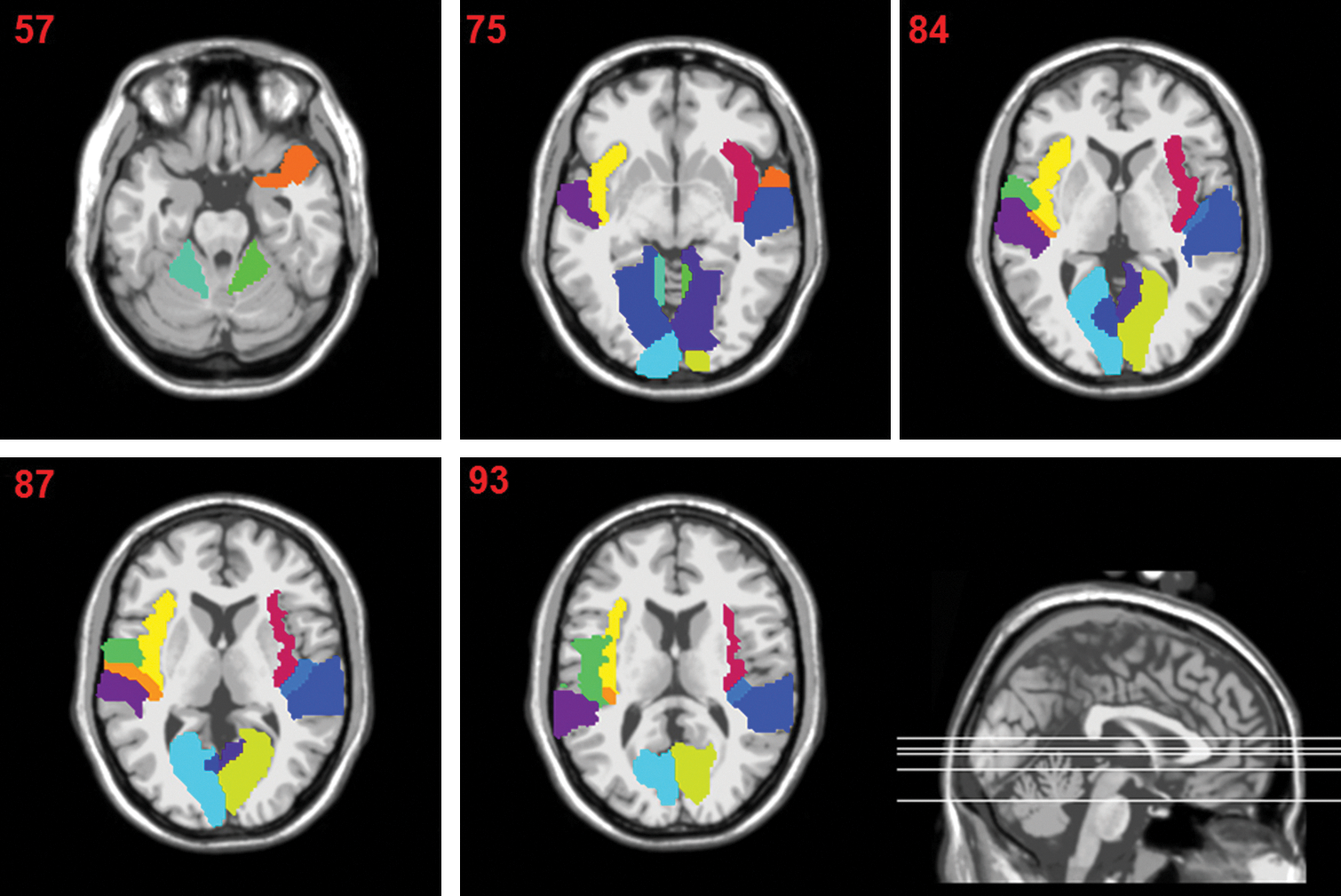
Visual plot of the top 14 discriminative regions in Table 3. Color images available online at
Top 14 Discriminative Regions
L and R denote Left and Right, respectively.
Discussion
This article investigated the diagnostic power of discriminative subnetworks, which were mined from functional connectivity networks, derived from resting-state fMRI, for the identification of individuals with MCI from HC. The proposed method employed the frequent subgraph mining and graph kernel-based classification for functional connectivity networks-based MCI classification. The classification performance in the experimental results validated the effectiveness of this proposed method. Moreover, the proposed method also gains an inherent insight for better understanding pathology of the disease. Specifically, the authors analyze the connectivity of the selected discriminative subnetworks and find that MCI patients have a disrupted connectivity between regions related to vision, auditory, language, social cognition, and information processes, which is consistent with other existing studies. For example, (Wang et al., 2013) investigated the topological structure of the functional connectome in MCI patients and found an abnormal structure, as shown by impaired functional connectivity between different brain regions. On the other hand, the regions with high occurrence in discriminative subnetworks as discriminative regions are selected, which include insula, calcarine sulcus, lingual gyrus, transverse temporal gyri, and superior temporal gyrus reported to be related with AD/MCI disease in literature (Davatzikos et al., 2011; Grady et al., 2003; Han et al., 2011; Liu et al., 2011).
Overall, these results show that the proposed method can effectively identify the MCI patients from HC, and provide empirical evidence for disrupted local network organization in MCI at both the regional and connectional levels. Besides MCI classification, the authors further validate the efficacy of the proposed method for gender classification, as detailed in Appendix 2.
The effect of threshold
In AD/MCI studies, threshold-based methods have been widely used for exploring the topological properties of functional connectivity networks (Sanz-Arigita et al., 2010; Supekar et al., 2008). In functional network analysis, it is noteworthy that there is no golden rule to determine the choice of threshold. Therefore, many studies investigate their methods over a range of thresholds (Supekar et al., 2008; Zanin et al., 2012). In this study, for further investigating the stability of the proposed method, extra experiments using different thresholds are performed. First, this method is performed using all the five thresholds (i.e., 0.2, 0.3, 0.38, 0.4, and 0.45) used in the previous study (Jie et al., 2013b), and this method achieves classification accuracies of 89.2%, 97.3%, 94.6%, 91.9%, and 91.9%, respectively. In contrast, the method in (Jie et al., 2013b) obtained an ensemble classification accuracy of 91.9% by combining all these thresholds together, while the classification accuracies corresponding to individual thresholds are only 86.5%, 83.8%, 75.7%, 75.7%, and 64.9%, respectively. Moreover, the authors investigate the stability of this method under more delicate interval partition of thresholds, ranging from 0.2 to 0.4 with an increment of 0.02, and the corresponding results are shown in Figure 6. As can be seen from Figure 6, the performance curve is relatively stable with respect to different thresholds, which again validates the efficiency of the proposed method.
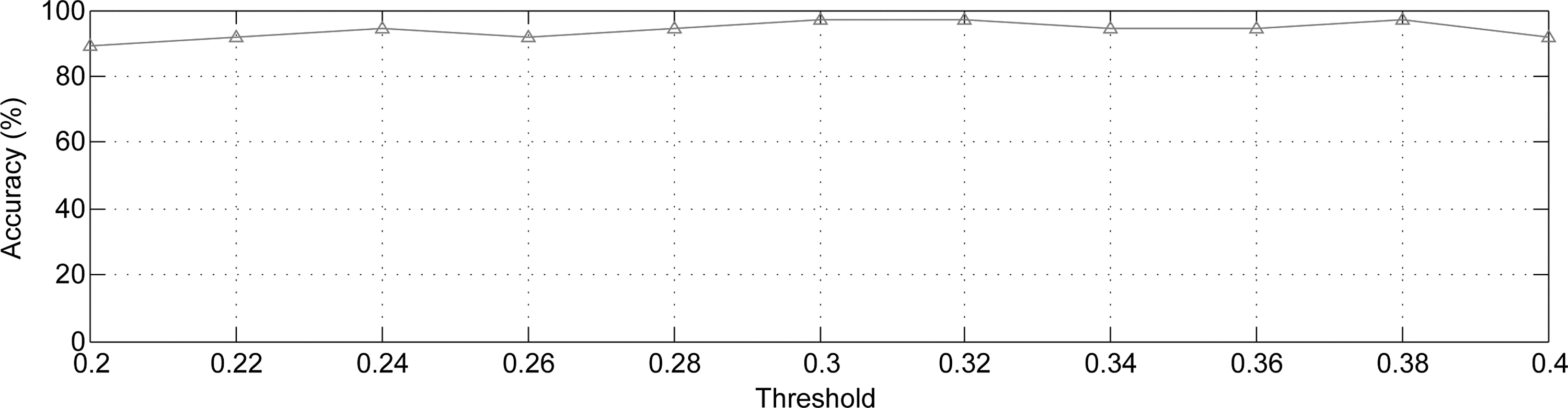
The classification performance curve with different thresholds.
The stability of the discriminative subnetworks
In this section, the authors computed the frequency of those mined discriminative subnetworks of the HC and MCI groups in Figure 4 in all 37 runs. The corresponding results (i.e., frequency) are (3/37, 37/37, 37/37, and 37/37) for HC (from top to bottom in Fig. 4) and (37/37, 2/37, 37/37, and 37/37) for MCI (from top to bottom in Fig. 4), respectively. This result suggests that most of the mined discriminative subnetworks of both the HC and MCI groups are stable. Especially, six discriminative subnetworks in Figure 4 (three for HC and three for MCI) have the frequency of 1, that is, appearing in all runs, showing a very high stability.
The choice of support parameter
In these experiments, the fixed values of support parameters for mining frequent subnetworks were used in each of the MCI and HC groups. Specifically, s=9/11 was used for the MCI group and s=22/24 was used for the HC group, respectively. In fact, other values for the support parameters were also used. However, because of the small sample size (and also the relatively large number of nodes (i.e., 116) in networks) of the training data (i.e., 11 for the MCI group and 24 for the HC group), smaller values of support (e.g., s=8/11 for the MCI group and 21/24 for the HC group) will lead to too many mined frequent subnetworks (usually over thousands), which are difficult for subsequent analysis. On the other hand, if larger values of support (e.g., s=10/11 for the MCI group and 23/24 for the HC group) are used, the mined frequent subnetworks will be too few (e.g., only 2 frequent subnetworks were mined for a certain run), which are insufficient for subsequent discrimination between MCI and HC. Actually, the authors computed the corresponding classification accuracy when using s=10/11 for the MCI group and 23/24 for the HC group, which is 81.08%. For this reason, in these experiments, the fixed values of s=9/11 for the MCI group and s=22/24 for the HC group were adopted, respectively.
Limitations
This study is limited by the following factors. First, during the network construction, the definition of nodes and edges is a critical step. Previous studies have demonstrated that network nodes can be defined using both anatomical and/or functional brain atlases and image voxels, but the constructed network exhibited significantly different topological properties (Hayasaka and Laurienti, 2010; He and Evans, 2010; Sanabria-Diaz et al., 2010; Wang et al., 2009). In the current study, following previous works (Jie et al., 2013a, 2013b, 2014), the authors adopted the widely used AAL template to parcellate the whole brain into 116 ROIs (including the cerebrum and cerebellar), and the correlation between ROIs is computed by the average time series of ROIs, which may cause intrinsic information being smoothed. One possible solution may be to use more delicate brain parcellation methods or using cortical landmarks (instead of average), for example, in (Zhu et al., 2013). However, this study does not analyze the impact of different brain parcellation atlases on the classification performance. Second, the performance of the proposed method may be affected by the unbalanced data. A classifier will normally try to adapt itself for better prediction of the class with majority. At present, the proposed method is not designed to handle this issue. Another limitation of the current study is the sample size of the material, which may reduce its generalization ability on MCI classification. In future, further evaluation of the proposed method on other brain diseases with larger size of subjects will be done, for example, ADHD (
Footnotes
Acknowledgment
The authors thank all the anonymous reviewers for their helpful comments, which improved the quality of the article. They thank Dr. Dinggang Shen for providing the MCI and the infant data sets used in the experiments. This work was supported by the Jiangsu Science Foundation for Distinguished Young Scholar under grant No. BK20130034, by the Specialized Research Fund for the Doctoral Program of Higher Education under grant No. 20123218110009, and also by the NUAA Fundamental Research Funds under grant No. NE2013105.
Author Disclosure Statement
No competing financial interests exist.