
Abstract
Graph theory has recently received a lot of attention from the neuroscience community as a method to represent and characterize brain networks. Still, there is a lack of a gold standard for the methods that should be employed for the preprocessing of the data and the construction of the networks, as well as a lack of knowledge on how different methodologies can affect the metrics reported. The authors used graph theory analysis applied to resting-state functional magnetic resonance imaging to investigate the influence of different node-defining strategies and the effect of normalizing the functional acquisition on several commonly reported metrics used to characterize brain networks. The nodes of the network were defined using either the individual FreeSurfer segmentation of each subject or the FreeSurfer segmented Montreal National Institute (MNI) 152 template, using the Destrieux and subcortical atlas. The functional acquisition was either kept on the functional native space or normalized into MNI standard space. The comparisons were done at three levels: on the connections, on the edge properties, and on the network properties levels. The results reveal that different registration and brain parcellation strategies have a strong impact on all the levels of analysis, possibly favoring the use of individual segmentation strategies and conservative registration approaches. In conclusion, several technical aspects must be considered so that graph theoretical analysis of connectivity MRI data can provide a framework to understand brain pathologies.
Introduction
The brain remains, to this day, as one of the most enigmatic organs in the human body. The inherent difficulty to understand its wiring patterns and how they relate to different functions brought the necessity to explore new methods that can bring new light on this subject (Stam and Reijneveld, 2007). One such method that has received increasing attention in the last decade is graph theory and the study of complex networks. One of the core strengths of graph theory in brain network modeling lies in its ability to quantitatively characterize the topological organization of the brain (He and Evans, 2010). It can have a key role in the interpretation of the complex dynamics detected in the brain across different studies using different modalities and models. Starting in the 90s [see for a review Ref. (Sporns, 2012)], several key moments revolutionized the study of brain connectivity, namely the introduction of the functional magnetic resonance imaging (fMRI) technique (Ogawa et al., 1990), the first studies that demonstrated the potential of the analysis of brain connectivity patterns (Felleman and Van Essen, 1991; Sporns et al., 1991; Young, 1992), the association of memory mechanisms to different mental states and connectivity patterns (McIntosh et al., 1997, 1999), and the introduction of the concept of small-world networks (Watts and Strogatz, 1998). More recently, multiple studies have shown the potential of the application of graph theory to represent and characterize brain networks. While there are reports of the application of graph theory with different imaging techniques, such as electroencephalography, magnetoencephalography (Yu et al., 2008), and positron emission tomography (Huang et al., 2010), MRI is by far the most common (Bullmore and Sporns, 2009; Lang et al., 2012).
A graph is a mathematical abstraction that can be understood as a group of nodes, which represent the different elements of the network, linked by edges, representing some relationship between them (Gross and Yellen, 2006). Translating these components into a brain network is fairly simple in concept; each node can represent an anatomic unit of the brain (can theoretically range from individual cells to full anatomic structures) and the edges can represent different relationships between regions, like the statistical correlation of fMRI activations, the number/density of connecting fibers obtained through diffusion tractography, or structural properties such as cortical thickness correlations. Despite the many advantages of using graph theory as a model for brain connectivity, some key issues still ensue. Building a brain graph means making a lot of decisions and assumptions that can directly affect the outcome and the results arising from different processing strategies cannot be easily compared (Bullmore and Bassett, 2011). It has been demonstrated that different properties of the network behave differently with connection type (Liang et al., 2012), network size, edge density, and degree distribution (van Wijk et al., 2010), especially the small-world parameters, depending on the number of nodes and the average degree of the network (Wang et al., 2009).
Different node-defining strategies can vary greatly on the number of nodes used, ranging from very small networks with 19 nodes (Lord et al., 2011) to the most common number of 90 nodes from the Automated Anatomic Labeling atlas (Hosseini and Kesler, 2013; Richiardi et al., 2011; Tian et al., 2011), and building up to much bigger networks ranging from 998 nodes (Hagmann et al., 2007) and up to 10,000 (van den Heuvel et al., 2008). The choice of the nodes definition can also vary from the use of a presegmented atlas in a standard space (Achard et al., 2006; Sun et al., 2012), the use of segmentation tools to individually parcellate each subject's brain (Minati et al., 2012; Richiardi et al., 2011), brain activation clusters extracted from fMRI analysis (Sun et al., 2012; Vandenberghe et al., 2013), or simply to the use of all voxels in the image (van den Heuvel et al., 2008). Such diversity of possibilities demands a thorough knowledge on how these might affect the characteristics of the network in all its range of possibilities.
Another key difference between studies is the choice of fundamental preprocessing steps: some studies normalize the images to a standard space (Achard et al., 2006; Lord et al., 2011; Minati et al., 2012; Tian et al., 2011), while others do not (Sun et al., 2012; van den Heuvel et al., 2008); some apply spatial smoothing steps with differently sized kernels (Lord et al., 2011; Minati et al., 2012; Sun et al., 2012), while others do not (Achard et al., 2006; Tian et al., 2011); some apply signal regression to remove confound signals (Achard et al., 2006; Lord et al., 2011; Minati et al., 2012), while others do not (Richiardi et al., 2011; Tian et al., 2011; van den Heuvel et al., 2008); and finally, different frequency filtering strategies can also be found (Achard and Bullmore, 2007; Liang et al., 2012; Supekar et al., 2009).
There is an obvious need to have the functional images (originally on its native space) and the node-defining images (usually on a standard space) in a common space. While the most common approach to achieve this is to normalize the functional images to the standard space, the opposite is still a valid, rather unused, option. Although, as hypothesized in another study (van den Heuvel et al., 2008), the interpolation of the voxels that occurs during this step can introduce artificial correlations, the effect of the normalization step on the networks is still largely unexplored.
On the brain parcellation strategies, the most common approach is to simply coregister the functional images and a fixed template, resuming the segmentation to the normalization step. A more elaborate alternative is to employ tools to individually segment each subject, such as FreeSurfer (Fischl, 2012). This strategy takes more factors into consideration (such as surface matching and gyri and sulci identification) and is known to produce more accurate results (Destrieux et al., 2010). The impact of these different procedures on the resulting networks is still unknown.
All these different possibilities may be responsible for some of the differences found, in the metrics that characterize the networks, between different studies having a direct impact on the conclusions that can be drawn from its results. In this work, the authors will focus on the study of two critical issues: the effect of normalizing the fMRI images and the effect that different node-defining strategies (i.e., the use of individual parcellation methods versus the simple superposition of a fixed template) have on the resulting networks.
Materials and Methods
Ethics statement
The study was conducted in accordance with the principles expressed in the Declaration of Helsinki and was approved by the Ethics Committee of Hospital de Braga (Portugal).
Subjects and acquisitions
In the current study, the MRI acquisitions of 59 healthy volunteers were used, from which 4 were discarded due to excess of movement during the acquisition, so that all subjects displayed head motion less than 2 mm in translation or 1 degree in rotation. Thus, a total of 55 subjects from the SWITCHBOX project were used in this study (31 males and 24 females aged between 51 and 82 years old and with a mean age of 64.85±8.82 years). The goals and tests of the study were explained to all participants, who provided informed written signed consent.
Two different acquisitions from each subject were used: as structural acquisition, a T1 magnetization-prepared rapid gradient echo with repetition time (TR)=2730 msec, echo time (TE)=3.5 msec, field of view (FoV)=256×256 mm, flip angle=7°, in-plane resolution of 1×1 mm, and 1 mm slice thickness; as a resting-state functional acquisition, a T2* echo-planar imaging acquisition with 180 volumes, TR=2000 msec, TE=30 msec, FoV=224×224 mm, flip angle=90°, in-plane resolution of 3.5×3.5 mm, and 4.5 mm slice thickness. All acquisitions were performed on a clinically approved Siemens Magnetom Avanto 1.5 T (Siemens Medical Solutions, Elangen, Germany) scanner, in Hospital de Braga, using a 12-channel receive-only Siemens head coil. During the resting-state acquisition, all subjects were instructed to remain with their eyes closed and to not think of anything in particular.
Preprocessing strategies
All fMRI images were preprocessed using BrainCAT (Marques et al., 2013), and the Matlab (v.2009b,
While the usual procedure in functional studies is to normalize all images to a standard space (e.g., Montreal National Institute [MNI]) (Mazziotta et al., 2001), this step will, no matter how good the interpolation function is, alter the original data. To evaluate the effects of the normalization, two different strategies were tested: the normalization of all images to MNI standard space with 2 mm isotropic voxel size and the registration of all the support data (both the T1 structural data and the masks defining the nodes) to the native space of the functional acquisition of each subject. These strategies will allow testing if the normalization procedures can directly affect the network properties. Normalization and registration of all images was done using FSL FLIRT (Jenkinson and Smith, 2001) for each subject from the native functional image to the T1 anatomical image, using a rigid body transformation (6 degrees of freedom [dof]), and from the T1 image native space to the MNI standard space, using an affine transformation (12 dof). The concatenation and inversion of both transformation matrices allows for the registration from the functional native space to the MNI standard space and vice versa.
Graph construction
The construction of the graph encompasses two different stages, the definition of the nodes and the definition of the edges. On the node definition, two different strategies were compared, the use of a fixed template atlas, which was overlaid into each subject's acquisition, and the use of individually segmented images for each subject performed by applying the FreeSurfer v5.1 semiautomated workflow (Fischl, 2012). To eliminate the effect of comparing networks with different sizes (van Wijk et al., 2010) and different regions (Wang et al., 2009) derived from the use of different atlases, the MNI 152 brain template was segmented using the same FreeSurfer workflow, and thus creating the fixed template atlas. For both strategies, regions from two different segmentations were combined, 146 regions from the Destrieux cortical atlas (Destrieux et al., 2010) and 14 regions from the subcortical segmentation (Fischl et al., 2002), resulting in a total of 160 regions (Table 1 and Fig. 1). These two different node-defining strategies allowed us to test the effect of building networks with different parcellation strategies.
Axial view of the ROIs defined for one subject after preprocessing:
Regions of Interest Used from the Destrieux and Subcortical Atlas
Using these masks, the mean signal across the voxels of each region was extracted from each time point of the fMRI acquisition, allowing for the final extraction of the time series. To measure the similarity between the time series, establishing a measure of functional connectivity (edges) between the corresponding regions of interest (ROIs), the Pearson correlation coefficient was used. The Pearson coefficient of each possible combination of ROIs was calculated in Conn and used to build a correlation matrix for each subject. The Fisher's r-to-Z transformation was then used to transform the r-values of the correlations into Z-values.
Combining the two different preprocessing and node-defining strategies, four different networks were computed for each subject, with the functional images in the MNI standard space (MNI networks) using the fixed template atlas (ATL-MNI) and the individual FreeSurfer segmentation (FS-MNI), and the functional native space (NAT networks) using the fixed template atlas (ATL-NAT) and the individual FreeSurfer segmentation (FS-NAT).
The workflow and all the possible strategies are represented in Figure 2.
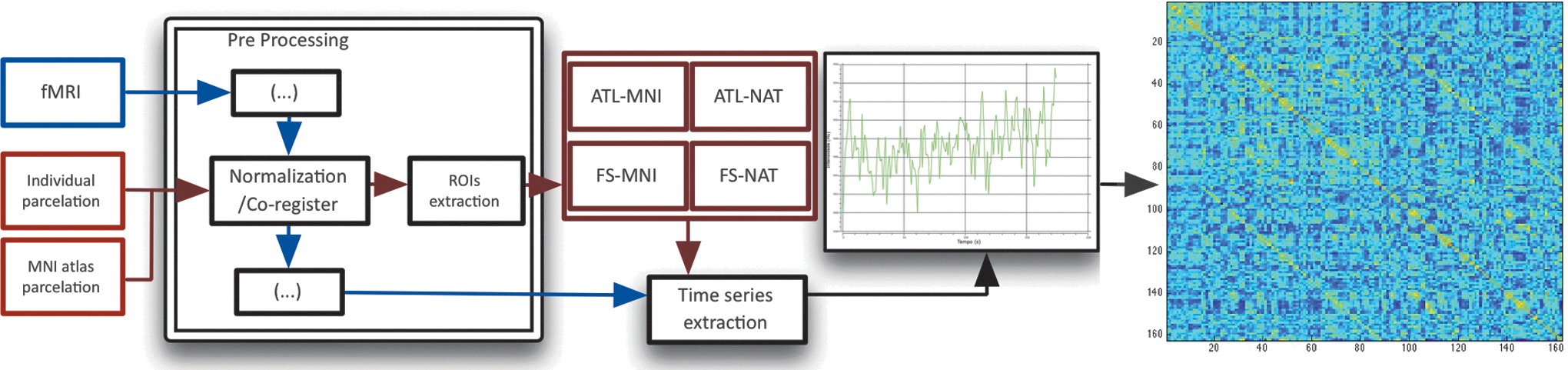
Complete image processing workflow: from the raw images to the correlation matrices. In blue, the workflow of functional images, and in red, the workflow of the node-defining atlases.
Network analysis and comparison
The comparison of the resulting networks was done at three levels: on the edges level, on the node level, and on the global network level. Regarding the networks' edges, differences in the Z-transformed correlation coefficients were tested for each pair of regions.
On the node level, two of the most commonly reported nodal metrics were used: betweenness centrality and local efficiency. The betweenness centrality, Ci
B, measures the fraction of the shortest paths that pass through the node i of the network (Freeman, 1978):
where σst(i) denotes the number of shortest paths between s and t that pass through i and σst denotes the total number of shortest paths between s and t. Measures of centrality evaluate the existence of nodes key to the communication of the network through which a significant number of communication paths go. Metrics of segregation indicate the existence of highly interconnected groups associated with functional specialization. Local efficiency (Eloc) is one of such metrics:
where Ni is the subgraph of the neighbors of node i, aij is the existence of a connection between i and j, and ki is the degree of the node i.
On the network level, three properties were tested: clustering coefficient, average path length, and assortativity coefficient. As a measure of network segregation, the mean clustering coefficient Cp reflects the tendency to form clusters of interconnected nodes (Rubinov and Sporns, 2010; Watts and Strogatz, 1998):
where N denotes the number of nodes in the network, Ci
denotes the clustering coefficient of the node i in graph G, d(i) denotes the degree (or number of edges connected to) of the node i, and e(Gi) denotes the number of edges in Gi
, the subgraph formed by all the node i neighbors. Functional integration measures reveal how easily each brain region communicates with the rest of the brain and combines specialized information. The average path length was used as a network-wise metric of integration, here calculated as the inverse of the network efficiency, Eglob
, to allow its calculation in disconnected graphs (Latora and Marchiori, 2001; Rubinov and Sporns, 2010):
where dij
denotes the distance, or the minimum number of connections, between the nodes i and j. Measures of network resilience quantify the network's ability to resist direct or random attacks. One possible measure is the assortativity coefficient r, which measures the correlation between a node degree and the degree of its neighbors, in other words, shows how likely it is for a node with a high degree to be connected to nodes with a similar degree (Newman, 2002, 2003):
M denotes the number of edges in the graph, ji and ki denote the degree of the nodes at both ends of the edge i.
Commonly, networks can be classified according to different architectures. One such architecture is the small-world topology. These networks are usually defined as having a higher Cp than those found on random networks (Cp/Cp rand >1) and a similar L (L/Lrand ≈1) (Rubinov and Sporns, 2010; Watts and Strogatz, 1998). This translates into the formation of highly connected subnetworks while keeping a high level of connectivity (Sporns et al., 2004). As so, Cp/Cp rand and L/Lrand were also called small-world parameters and were used to characterize the networks.
The nodal and network metrics for all networks and subjects were calculated along a range of densities, from 5% to 40% in steps of 2.5%. To reduce the complexity of the analysis, the nodal properties were condensed across the density range through the use of the integrated version of the measure, calculated as follows (Tian et al., 2011):
where X is the property of the node i, along 15 density levels, and Δd is the density interval (0.025).
Only positive correlation coefficients were considered and all networks were binarized before calculation of the metrics. All calculations were done using the Brain Connectivity Toolbox (Rubinov and Sporns, 2010) and Matlab.
Statistical analysis
To compare the different strategies, a 2×2 repeated measures ANOVA was done using Matlab, on the Z-transformed correlation coefficients, metrics CB, LocEf, Cp, L, r, and using the registration approach, parcellation strategy, and registration×parcellation interactions as within subject contrasts. The necessary assumptions for the analysis were previously verified and met. Differences were considered significant at p≤0.05 corrected for multiple comparisons using the family-wise error procedure.
Results
Network characterization
The average network matrices for each strategy, thresholded at a density of 7.5%, can be found in Figure 3. In these matrices, similar connection tendencies were observed for all the strategies. From the division in cortical and subcortical regions, it is possible to observe a tendency for stronger connections between regions of the same atlas; cortical regions revealed higher connectivity with other cortical regions than with subcortical regions and the same pattern was observed for subcortical regions. Moreover, regions tend to present stronger connections to regions within the same hemisphere than to regions of the contralateral hemisphere. A symmetry effect can also be observed, meaning that, regions showed strong tendencies to connect to the matching region on the contralateral hemisphere, as evidenced by the diagonal crossing both the second and third quadrant of the matrices (Fig. 3). From the distribution of Z-transformed correlation coefficients (Fig. 4a), it is possible to observe a roughly normal distribution with the majority of values located between 0 and 0.2, while in the distance distribution (Fig. 4b) it is noticeable that most values are located between 15 and 55 mm.
Correlation matrices for the four networks thresholded at 7.5% density averaged for all subjects: networks built using the presegmented atlas (ATL), the individual segmentation (FS), built on the standard MNI space, and on the functional native space (NAT). White lines divide the matrices in subcortical (SubCort) and cortical (Cort) regions as well as left and right. FS, FreeSurfer.
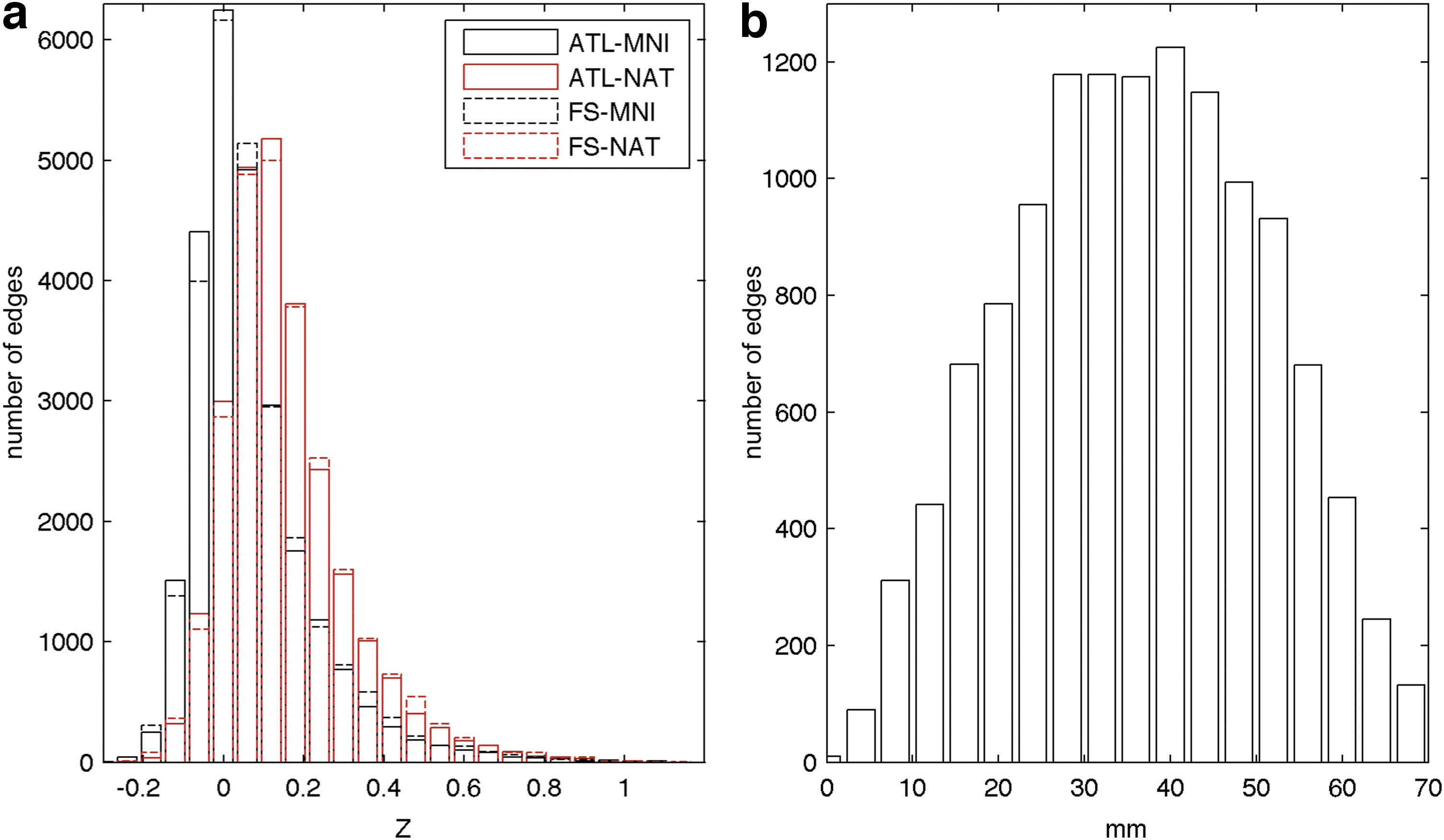
Networks distributions:
Regarding the small-world properties of the networks (Fig. 5), all presented high clustering values for the full range of densities, with 1.5<Cp/Cp rand <6, and a tendency for the values to become closer to those of random networks as the network density increased (Fig. 5a). The characterization of the average path length of each network revealed values close to those of random networks, with 1<L/Lrand <1.35, and once again a tendency to grow closer to those of random networks as the density increased (Fig. 5b). Concerning the assortativity of the networks, all values were found to be positive and 0.24<r<0.41 (Fig. 5c).
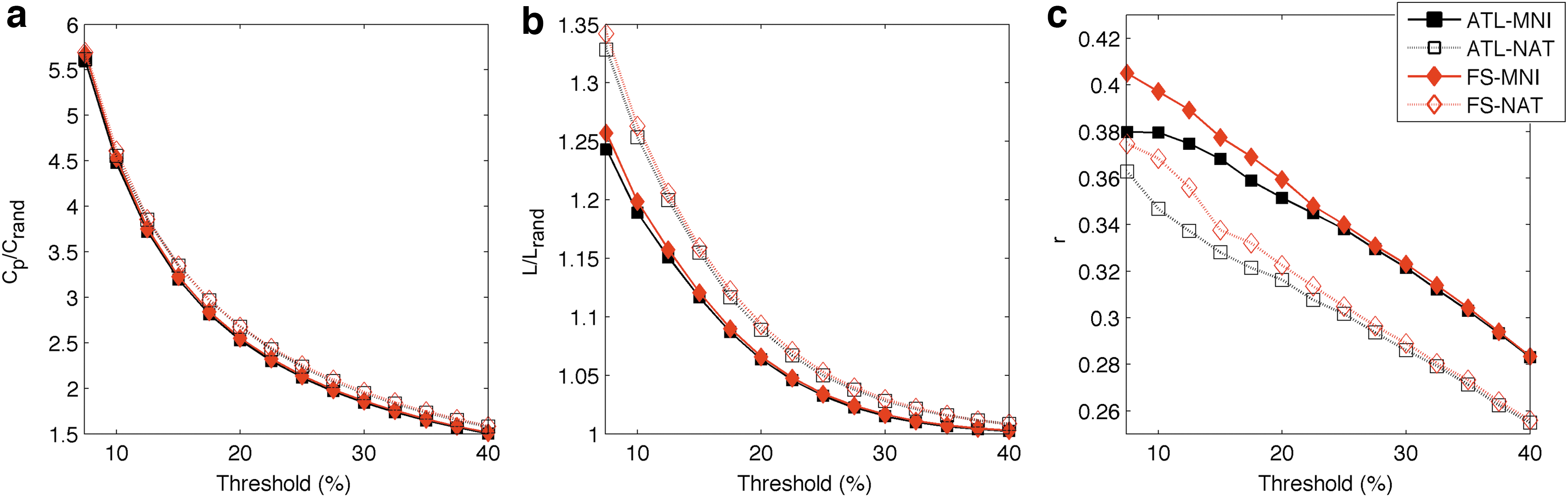
Global metrics network characterization.
Effect of registration and parcellation strategies
For the isolated effect of the registration and parcellation strategies, significant differences were found on the three levels of analysis.
In the edges comparison, differences were found in the registration test (Fig. 6a) in a total of 243 edges. All these edges, when computed in native space, presented higher values than the same edges computed in standard space. When considering the parcellation test (Fig. 6b), differences were found in a total of 112 edges, 26 of them having higher value on the ATL networks and 86 on the FS networks.
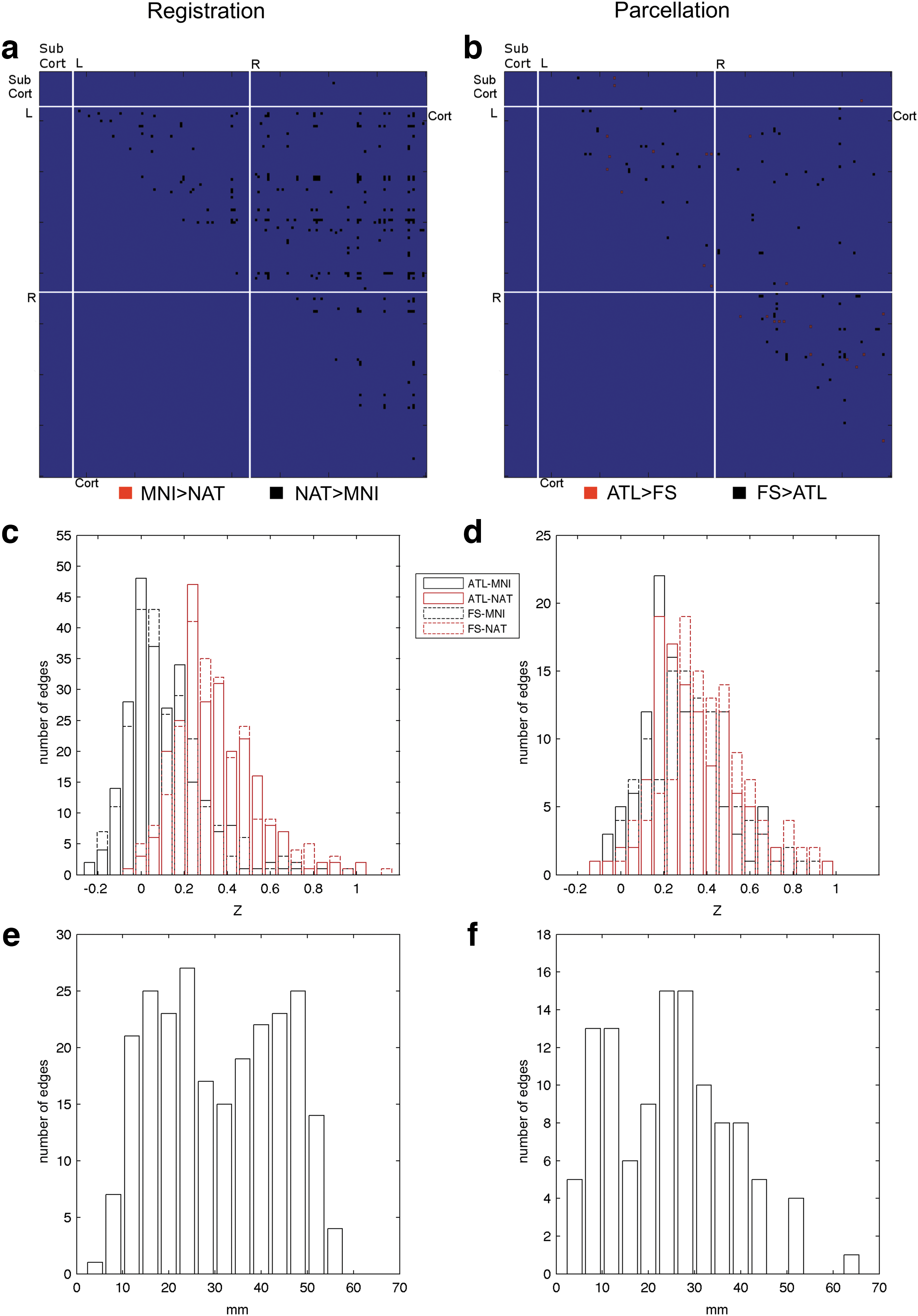
Edge level significant differences for the registration and parcellation comparisons for p<0.05 corrected for multiple comparisons with family-wise error procedure:
From the distribution of correlations of the edges with significant differences on the registration comparison (Fig. 6c), it was possible to observe that the NAT networks Z-transformed correlation values lie between 0.2 and 0.4, while on the MNI networks these were mainly located between −0.1 and 0.2. On the parcellation comparison (Fig. 6d), the values of Z-transformed correlation with significant differences from all networks were located mainly between 0.2 and 0.4. From the distance distribution of differences on the registration comparison (Fig. 6e), it was possible to observe a tendency for differences to be located on either long- or short-distance edges with a higher tendency for the short range. On the parcellation comparison, differences were mainly located over shorter connections (Fig. 6f).
On the nodal metrics, differences were found on both metrics for the registration test: one on CB, with MNI networks having a higher value, and five on the Eloc, with the NAT networks always having higher values. On the parcellation test, significant differences were found on the CB metric on three vertices with FS networks always having higher values and no differences were found on the Eloc (Table 2).
Significant Differences in the Nodal Metrics in Bold for the Registration and Parcellation Comparisons
p<0.05 corrected for multiple comparisons with the family-wise error procedure.
ATL, atlas; FS, FreeSurfer; MNI, Montreal National Institute; NAT, native.
On the global metrics level, several differences were found as follows: on the registration test, differences were found on the clustering metric for values of density between 15% and 40%, with the NAT networks always having higher values; on the average path length, differences were found on the full range of densities, with the NAT networks having higher values; and no differences were found on the assortativity metric (Table 3).
Isolated Effect of the Registration Strategies for the Graph Metrics Across All Threshold Values
Significant results in bold corrected for multiple comparisons with the family-wise error procedure.
For the parcellation test, differences were found for the clustering coefficient between densities of 22.5% and 40%, on the average path length for density values of 5%, 17.5%, and 20%, and on the assortativity metric, a density of 12.5%. In all instances, FS networks showed higher values than ATL networks (Table 4).
Isolated Effect of the Parcellation Strategies for the Graph Metrics Across All Threshold Values
Significant results in bold corrected for multiple comparisons with the family-wise error procedure.
Interactions between the node definition and registration strategies
No significant results were found for the registration×parcellation interaction.
Discussion
The results herein obtained are in accordance to the expected characteristics and architecture of brain networks, as demonstrated in several studies (Braun et al., 2012; Messé et al., 2012; Tian et al., 2011; van Wijk et al., 2010; Wang et al., 2009). All networks were shown to be assortative (r>0) and efficient (L/Lrand ≈1) in the full range of densities. All of them also showed a strong small-world-like tendency to constitute clusters (Cp /Cp rand >1) on the lower range of densities (5% to 20%).
The thresholded correlation matrices demonstrated a clear tendency for regions to connect to other regions within the same anatomical division (cortical/subcortical and left/right), evidencing not only a tendency for lateralization of function in the human brain (Tian et al., 2011) but also reflecting a tendency to have more efficient networks by having stronger connections over smaller anatomical distances (Tomasi and Volkow, 2012). The diagonals over the L/R quadrants reflect the natural correlation and sharing of functions between symmetric regions (Salvador et al., 2005; Toro et al., 2008).
For the isolated effect of the registration strategies, several significant differences were found in all three levels of the analysis. From the differences matrix and the corresponding correlation and distance distribution, it is possible to observe a strong tendency for the networks built in the functional native space to have higher values of correlation and for these differences to be mainly located on either shorter or longer range connections. These differences translate in the network metrics into a higher clustering coefficient and longer average path distance in the native space networks with a very large effect size (Cohen, 1988). Overall, this seems to point that networks built in this space favor the detection of stronger local paths of communication, not restrained to physically proximal or interhemispheric regions, in detriment of more evenly spread connections. On the nodal metrics, it could be expected that this would translate into a higher tendency for the native space networks to have vertices with a stronger centrality role. Instead, the authors found differences in only one vertex in BC, favoring the MNI space networks (although with a small effect size). In the local efficiency, the differences favor again the native space networks, with the existence of nodes with a more important role on facilitating the communication on their local networks, which should be associated with the higher clustering coefficient, but again, with a small effect size. The differences found can be the result of multiple factors: the resampling and interpolation of the functional data in the normalization step, the resampling of the parcellation images and loss of detail, or a mixture of both. As no interaction was found between the registration and parcellation strategies, the first option emerges as the most likely.
In the parcellation strategies comparison, several differences were also found. At the correlation level it is possible to observe differences in both directions, mostly with higher values in the individual segmentation networks. From the correlation distribution, it is possible to observe a small tendency for the individual segmentation networks to have higher values of correlation, and from the distance distribution, for the differences to be located mainly over shorter range edges and within hemispheres. The authors found higher values of Cp in the individual segmentation strategies, with large to very large effect sizes, L, with high effect sizes, CB, with small to very small effect sizes, and r with large effect sizes. These differences can be explained by the higher precision of the strategy in segmenting the different areas according to sulci and gyri (Destrieux et al., 2010), possibly establishing higher and more accurate correlations. This strategy seems to favor the detection of strong and short connections associated with the formation of local clusters (as seen in the increased Cp). The lack of the ability of the fixed template strategy networks to detect these strong correlations favors the survival on the threshold procedure of the weaker long-distance connections, establishing extra paths of communication between distant points in the network and reducing the average shortest path in these networks. Furthermore, on the nodal metrics comparison, three individual segmentation network vertices were found to have a higher value of BC. As the main hubs of communication in a network are usually associated with the necessity to establish bridges of communications between strong and independent clusters, these seem to be a logical finding, supported by the large effect size.
This study presents some limitations that should be noted. While the authors reveal the impact of the normalization step in several aspects of the network, it is, in this study, impossible to show which inner step of the normalization is the exact step responsible for these differences. Further exploration of the effect of resampling the functional data and the use of different interpolation functions are needed to characterize the exact effect of this step. It is also important to notice that several of the differences found in the network metrics were present on higher values of density. This can be explained by observing the distributions of correlations of differences, as most edges with significant differences have medium to low levels of correlation, and only once these survive the thresholding procedure their effect will be noticeable on the network. There is a tendency in neuroimaging studies to focus on lower density networks, possibly reducing the relevance of some of the present findings. Yet, there is no direct evidence of which density threshold is more appropriate, which could be critical for the overall interpretation of the present finding and of complex brain networks studies.
Overall, the authors have shown a strong impact of two different preprocessing steps on the resulting networks. It is, without prior knowledge of the expected network properties, impossible to determine which strategy better represents the underlying biological brain network, making it only possible to theoretically argue in favor of those strategies that have either less impact on the data or are more precise in defining the ROIs. While further exploration of the normalization step is needed, the present results favor the use of the more conservative approach, avoiding the use of resampling and interpolation functions on the data whenever possible. Similar to this, the use of a more precise segmentation method for defining the ROIs also seems to have a moderate impact on the networks obtained.
Footnotes
Acknowledgments
The authors are thankful to all the study participants.
Financial Disclosures: R.M. is supported by a fellowship of the project FCT-ANR/NEU-OSD/0258/2012 founded by FCT/MEC (
Author Disclosure Statement
No competing financial interests exist.