
Abstract
This article describes a hybrid method to threshold functional magnetic resonance imaging (FMRI) group statistical maps derived from voxel-wise second-level statistical analyses. The proposed “Equitable Thresholding and Clustering” (ETAC) approach seeks to reduce the dependence of clustering results on arbitrary parameter values by using multiple subtests, each equivalent to a standard FMRI clustering analysis, to make decisions about which groups of voxels are potentially significant. The union of these subtest results decides which voxels are accepted. The approach adjusts the cluster-thresholding parameter of each subtest in an equitable way, so that the individual false-positive rates (FPRs) are balanced across subtests to achieve a desired final FPR (e.g., 5%). ETAC utilizes resampling methods to estimate the FPR and thus does not rely on parametric assumptions about the spatial correlation of FMRI noise. The approach was validated with pseudotask timings in resting-state brain data. In addition, a task FMRI data collection was used to compare ETACs true positive detection power versus a standard cluster detection method, demonstrating that ETAC is able to detect true results and control false positives while reducing reliance on arbitrary analysis parameters.
Introduction
One of the challenges in analyzing a functional magnetic resonance imaging (FMRI) experiment is an appropriate correction for the large number of multiple comparisons, resulting from separate statistical tests at each spatial location (voxel). One strategy for multiple comparison correction is to leverage the observation that plausible results are likely to span multiple contiguous voxel locations, leading to the rejection of statistical findings that are spatially too small or too insignificant.
Leveraging contiguity is commonly carried out using dual thresholding of statistical parametric maps, performed in two successive steps. First, examine each voxel and reject any whose test statistic likelihood (p-value) is larger than some user-selected p-threshold (referred to herein as “S” or statistical threshold). Second, among the surviving voxels, accept only those that form neighborhoods with other surviving voxels in a cluster of some threshold size or larger (referred to as “C” or clustering threshold).
Both the “S” and “C” steps involve the selection of arbitrary parameters for voxel-wise significance and cluster threshold. The method presented here, called “Equitable Thresholding and Clustering” (ETAC), was developed to reduce the influence of the selection of these arbitrary analysis parameters. ETAC combines the results from using multiple sets of parameters to give experimental results that are not strongly dependent on arbitrary parameter choices. This combination is relevant to concerns about rigor and reproducibility, because it reduces the temptation for researchers to experiment with many different parameter combinations to find those that produce the desired results (even though they may not accurately portray the results that would be found with most parameter values). This effect has been referred to as “the garden of forking paths” problem (Gelman and Loken, 2013).
The complex interdependencies between the “S” and “C” parameters make this problem more complicated than it might appear at first. Typically, S is (somewhat arbitrarily) chosen by the researcher, and then C is estimated for S so that the final map of surviving voxels meets desired statistical stringency (e.g., p < 0.05). The appropriate C for a given S depends on the smoothness of the data, which depends on arbitrary choices about the size of spatial blurring during image preprocessing.
A common sense approach would be to base the choice of both parameters on the size of the region of interest, so that researchers interested in smaller brain areas would apply less smoothing and a more stringent S, so that a small cluster would be able to survive. However, no uniform values for S and C exist in the literature, and any choice within a reasonable range is accepted without further justification. Problems with this approach were brought to the attention of the FMRI community in 2016, with an article (Eklund et al., 2016) demonstrating that some methods for determining C from a given S showed a markedly higher than nominal false-positive rate (FPR), and this result was dependent on the voxel-wise thresholds (S) chosen (Cox et al., 2017a, b).
Finding threshold C from a given S does not have an exact closed-form solution, and there are multiple computational approaches available to find an appropriate C. While some formula-based approaches have been deployed, such as the method used in statistical parametric mapping (SPM) (Flandin & Friston, 2019; Friston et al., 1994), the accuracy of these formulae depends on the spatial smoothness of the noise in the underlying data (Cox and Taylor, 2017).
An alternative to using an asymptotic formula is a simulation approach, as commonly used in analysis of functional neuroimages (AFNI) (Cox, 1996). In this approach, data sets made up of computer-generated “noise” are used to determine the rate of cluster detection. The cluster-simulation approach avoids the pitfalls of the formula-based approach, at the cost of significant brute force computation.
The actual FPR performances of early iterations of the cluster-simulation approach were strongly dependent on S. Recently (Cox et al., 2017b), the AFNI parametric cluster-simulation approach was improved by modeling the noise spatial autocorrelation function (ACF) with a non-Gaussian shape—termed a “mixed model” ACF, as it combined Gaussian and monoexponential components—and able to improve the FPR performance markedly. However, the FPR performance was still dependent on the choice of S, and only for relatively stringent per voxel p-thresholds (≤0.002) did the modeling produce anything like the desired global FPR.
Further development of a separate nonparametric analysis, which omitted any explicit model for the ACF, was able to achieve robust FPR control for a wider range of S, extending to voxel-wise p ≤ 0.01 by combining a pure t-test resampling and cluster-simulation method. Unfortunately, the penalty for this latter approach to detection is that the resulting C thresholds can be very large for studies with relatively few subjects. In addition, the false positives are not uniformly distributed in the brain volume even for these kinds of approaches (Eklund et al., 2016), suggesting that biases still remain, in large part, due to regional differences in smoothness across the brain.
ETAC works by implementing a collection of related individual component tests—called subtests from here onward—across a range of parameter values, such as smoothing radius and voxel-wise p-threshold, for dual (voxel-wise S, then cluster-wise C) thresholding, and then merging the surviving clusters from the collection of subtests. Each subtest is a “standard” type of test carried out in FMRI group analyses, as exemplified in Eklund et al. (2016). The ETAC method maintains equity (or balance) among this collection of subtests and therefore across otherwise multiple arbitrarily chosen parameters, by constraining each individual subtest's cluster threshold to produce the same FPR as every other subtest. The final FPR is controlled by adjusting all subtests' equitably constrained cluster-threshold parameters simultaneously, to reach the desired target FPR in the simulations and final results.
ETAC's use of multiple subtests reduces the number of arbitrary choices the FMRI data analyst must make. Effectively, multiple p-thresholds and multiple levels of data blurring are all included, and the data analyst only needs to choose ranges of these parameters, rather than a specific p-threshold and a specific spatial blur—each combination comprises one subtest. As a result, ETAC has the potential to detect both small intense clusters (found using small p-value thresholds and small blurring) and large weak clusters (found using large p-value thresholds and perhaps more blurring) within a single execution. This choice of subtests is intended to balance cluster detection across spatial scale (cluster size) and cluster intensity.
As will be demonstrated, ETAC still gives reasonably accurate control of false positives and provides similar statistical power compared with the use of a fixed cluster-size threshold, which also controls global FPR properly. Thus, the benefits of equity do not appear to require a trade-off in FPR or power; the main trade-off seems to be in having greater computational demands (because of the necessity of multiple subtests), but as discussed later, even these are not extreme for typical FMRI studies.
In the next section, the concepts underlying the ETAC approach are outlined. In the Appendix, I provide a detailed summary of how ETAC is implemented in AFNI. To validate the performance of ETAC, I examined both the FPR and the power to detect real activations. To examine the rates of ETAC allowing false results to survive correction, I used simulations à la (Eklund et al., 2016), with resting-state FMRI as null data for task-based analyses. To examine the ability of ETAC to detect real results (i.e., investigating its utility), I analyzed a publicly available collection of task FMRI data sets and compared the findings to existing methods of multiple comparison correction, which also control global FPR.
Methods
Conceptual description of approach
Figure 1 shows a schema for judging all possible voxel clusters in a brain mask (i.e., globally). A point (S, C) in this configuration space represents a cluster of C neighboring voxels, each of which is individually more statistically significant than S [standing in for t, z, −log(p), or similar statistic]. The dual thresholding approach for finding significant clusters is also shown: first, a voxel threshold is chosen (a value along the abscissa, e.g., S*), which delimits part of the configuration space; one then names a desired global—within brain mask—FPR ϖ (cursive Greek “pi”) and determines an appropriate cluster-size C*, which further delimits the configuration space to the dark shaded region. Thus, C* depends on both S and ϖ.
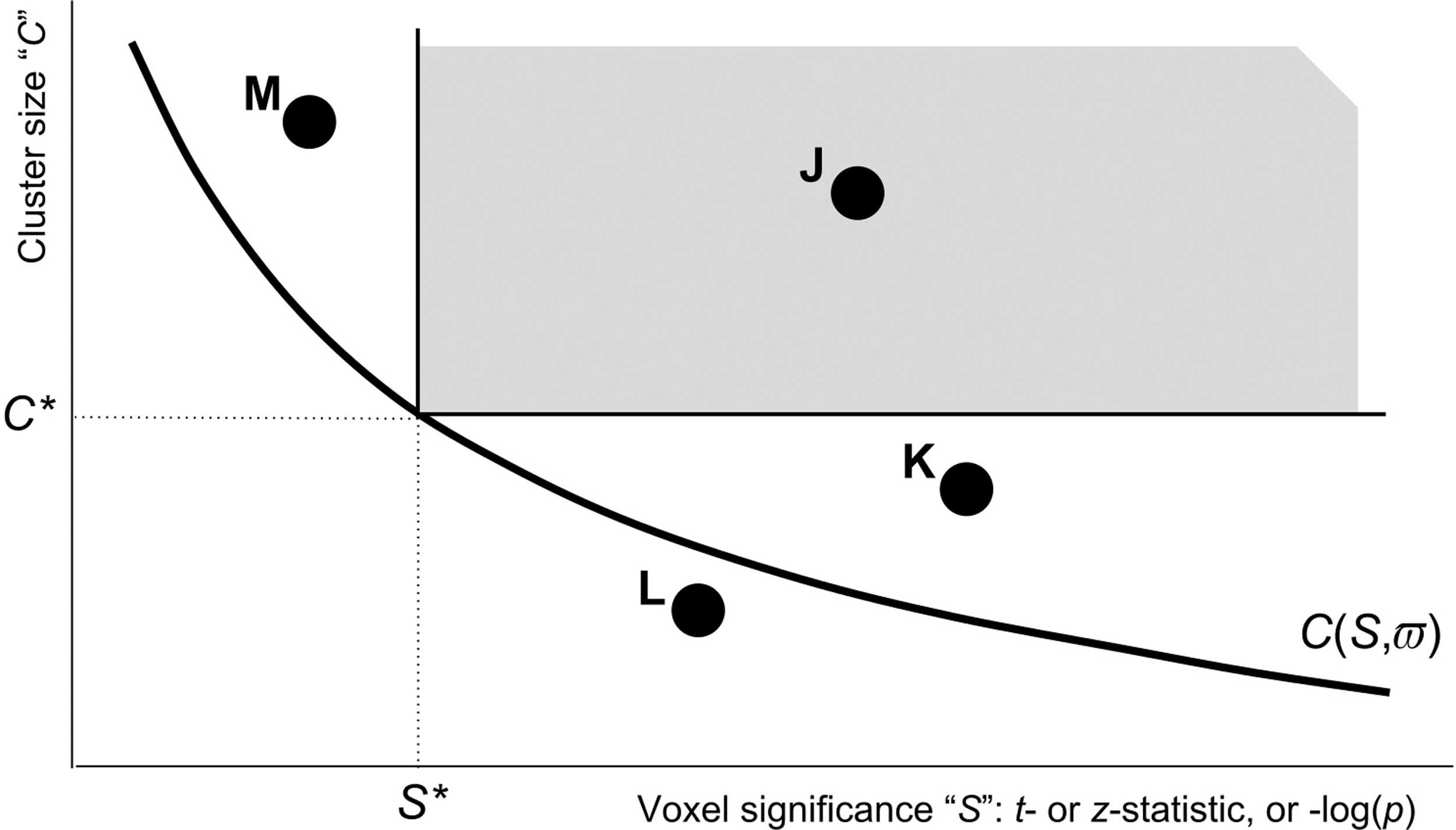
View of the dual thresholding trade-off. All voxels that meet a voxel-wise threshold and a cluster-size (contiguity) threshold are kept—the gray region indicates the combinations that pass a particular instance of this procedure: each voxel's statistic must pass a first significance threshold S*, and the number of contiguous voxels (in a single cluster) must be above a second threshold C*. The thick black curve C(S, ϖ) indicates the cluster-size threshold that gives a fixed global FPR ϖ (e.g., 5%) as a function of the per-voxel threshold S; ϖ is the probability that a noise-only cluster falls into the gray region. See the main text for discussion of named clusters J–M. FPR, false-positive rate.
For a given global FPR, the cluster-size threshold C* = C(S*, ϖ) is a decreasing function of per-voxel threshold statistical significance S*, as shown. There is a trade-off implicit in the dual thresholding approach; a more stringent per-voxel threshold (moving the shaded region rightward) allows for detection of smaller clusters (the shaded region extends further downward). The function C(S, ϖ) is determined by simulation in AFNI and by an asymptotic formula in SPM.
In Figure 1, the J cluster passes the thresholding test, by containing enough voxels for the given voxel-wise threshold. The K cluster is made up of voxels that easily pass the threshold test, but it does not have enough voxels to survive in the present scenario; however, if the per-voxel threshold test were more stringent (S* moved rightward), then the K cluster could pass the dual threshold test. For the right choice of per-voxel threshold, both clusters J and K would survive. The L cluster has voxels that pass the per-voxel threshold, but not enough of them and there is no per-voxel threshold that will permit L to survive at the desired FPR. Conversely, the M cluster has a lot of voxels above a slightly smaller per-voxel threshold. Again, one could make M survive by playing with the per-voxel significance threshold, as M lies above the C(S, ϖ) trade-off curve.
For a given nominal FPR ϖ, the choice of voxel-wise thresholding statistic S* is essentially the primary quantity for determining which clusters are accepted or rejected, because the cluster-size threshold C* is a function of S* parameterized by the ϖ value (e.g., 5%).
Figure 1 and the reasoning above lead to the obvious question. Since researchers are interested in obtaining clusters based on their dual properties of voxel-wise significance and size, how should they choose the single voxel-wise threshold that determines the result? Previous work (Cox et al., 2017b; Eklund et al., 2016) has demonstrated the bounds of a reasonable range of choices (at some larger p-thresholds the ability to control FPR decreases; in the present language, for some large p-values (small S-values), such as p ≥ 0.10, an appropriate C(S, ϖ) may not exist, or may be so large as to be useless).
Even within a reasonable range of p-values, the choice of threshold might affect the outcome dramatically. As illustrated in Figure 1, one could shift this voxel-wise threshold along the horizontal axis and obtain the following combinations of statistically significant clusters: only M; both J and M; only J; both J and K; or only K. When the results can depend strongly on the choice of an arbitrary parameter, any value of which might be considered reasonable within a large interval, the researcher is in a bad situation—as are the readers of any resulting scientific article.
Figure 1 also leads to the idea of finessing the trade-off between cluster-size and per-voxel thresholds; that is, simply accept every voxel configuration that lies above the solid black curve C(S, ϖ). From the viewpoint of the final FPR of the dual threshold method, any place along that curve is as acceptable as any other. The principle of equity asks, “Why discriminate?” However, a practicable algorithm must use a discrete set of p-thresholds combined with their corresponding cluster-size thresholds. Finally, the algorithm must be constrained by the need to achieve the desired global FPR in the final results.
Figure 2 illustrates the use of four different per-voxel thresholds within a single cluster test. In this example scenario, using the equitable thresholding method, clusters J, K, and M survive. When using the multiple voxel-wise thresholds (i.e., the proposed multi-S or multi-p case), it is important to note that one cannot use the original C(S, ϖ) trade-off curve (from the mono-S case) to calculate the cluster threshold for each subtest; this would lead to a final FPR that is larger than the desired ϖ, since more potential false-positive voxel configurations are allowed with the use of multiple S-thresholds than with a single S-threshold.
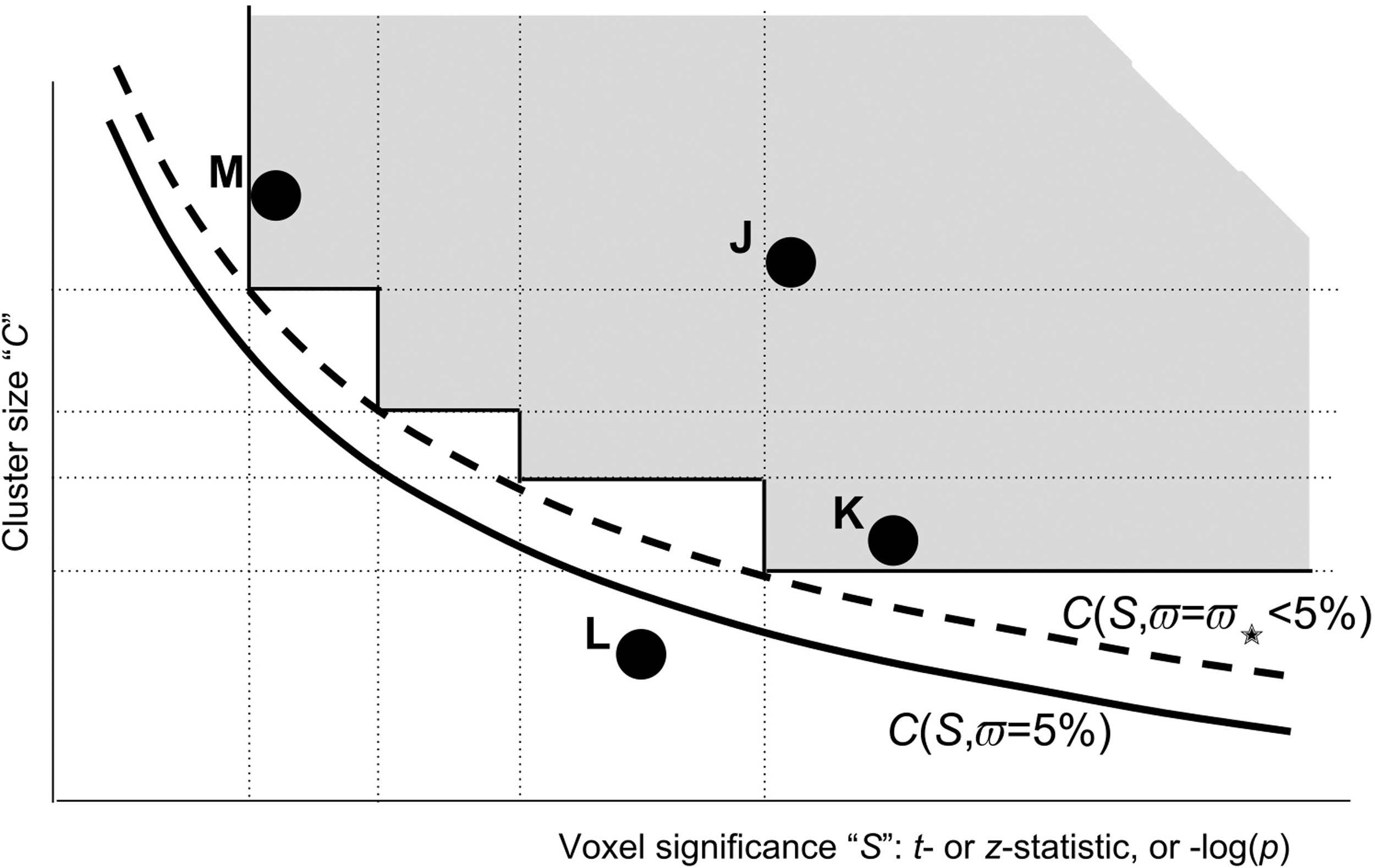
Thresholding as in Figure 1, but using four different per-voxel p-thresholds at once (vertical dotted lines), each using its own cluster-size threshold (horizontal dotted lines). The FPR for the gray region (the union of four mono-p-threshold rectangles), if constructed above the solid black curve C(S, ϖ), would be larger than the desired ϖ (FPR for the gray rectangle shown in Fig. 1), since this union region would include more possible voxel configurations. To compensate for that and maintain a nominal (5%) FPR, the cluster-size threshold curve from Figure 1 (solid curve) must be raised to a higher level by picking a curve C(S, ϖ✭) with ϖ✭ <5% (dashed). Which ϖ✭ should be chosen is determined by simulating this multi-p-thresholding process—just as the curve C(S, ϖ) for the original dual threshold method is determined (in AFNI) by simulating the mono-p-threshold procedure (cf. Fig. 6). AFNI, analysis of functional neuroimages.
It is thus necessary to find ϖ✭ < ϖG (subscript “G” for final goal) such that using the C(S, ϖ✭) for the individual subtests will achieve the desired ϖG in the final combined simulations. That ϖ✭ value then defines the multi-p-threshold clustering algorithm when applied to the original voxel-wise statistical tests. ETAC does not make the Bonferroni correction ϖ✭ = ϖG/4 among these four subtests. This correction would be very conservative and negatively impact the power of the method, as indicated by the strong overlap among the individual mono-p-threshold regions in Figure 2. The Appendix contains a detailed description of how ϖ✭ is adjusted (via simulation) to make the final FPR equal to ϖG in the Appendix.
A key advantage of this approach over the simpler mono-S-thresholding method is that it allows large clusters of low effect size (smaller S, larger p) to be detected along with small clusters of high effect size (larger S, smaller p) within a single analysis. In the more common mono-p-threshold approach, the user (or software) has to decide which type of cluster to favor. It would be difficult for a user to know a priori what single p-value would be appropriate or preferable for a study. This arbitrariness could all too easily lead to the user adjusting the per-voxel p-threshold to get more desirable results.
In addition, a user may be interested in both small and large clusters (e.g., responses in amygdala and posterior cingulate cortex) within a single experiment, an outcome that might be arbitrarily excluded by the constraint of being allowed only a single voxel-wise threshold. In the ETAC method, only a plausible range of p-thresholds need to be chosen, and these issues are effectively removed. In summary, where results initially depended on just a single parameter chosen from within a range of reasonable values, the ETAC method allows multiple parameter values to be chosen, tested, and have their results combined into a single result, while simultaneously balancing the importance of each subtest and maintaining control of the final FPR.
The idea of combining multiple dual threshold subtests for detection (in Fig. 2, each subtest is specified by its voxel-wise S- or p-threshold) can be directly abstracted and generalized to other parameter dependencies, such as the scale of the spatial smoothing applied to the data (parameterized by the full-width at half maximum, [FWHM], of a Gaussian shape). Similar to S, typically only a single blur size is chosen for a given FMRI study, but commonly implemented values within the literature range over 4–10 mm. No matter what the subtest is, its individual FPR will be controlled by a cluster-thresholding parameter. The ETAC approach is to require each subtest to have the same individual FPR ϖ✭ and to accept a voxel if it passes any of the individual subtests (set union); then, ϖ✭ is adjusted to achieve the goal of FPR = ϖG for the final set of accepted voxels. In this way, equity/balance across the parameter ranges of the subtests (in Fig. 2, defined by S threshold values) is maintained while the overall FPR is still achieved.
Using multiple cases of blurring to enable FMRI detections across spatial scales is certainly not new (Worsley, 2001). The ETAC framework maintains equity across blur scales in the same way as described above: the clustering thresholds at the different scales of blurring are balanced by making each subtest (i.e., combination of p-threshold and blurring FWHM) have the same individual FPR ϖ✭. The effect of this multiblur analysis is to remove the arbitrary choice of blurring scale from the data analyst. For this approach to work, the first-level (individual subject) analyses should be done without spatial blurring. Then, the blurring of the first-level results (individual subject betas; in AFNI, beta estimates percent signal change from voxel baseline) should be carried out by the ETAC software.
Computational approach
Building on the methods of Cox et al. (2017b), ETAC builds a large collection of noise-only t-statistic volumes using randomization/permutation of the original input data sets. These volumes are then thresholded, clusters are formed, and various scores for each cluster are computed. ETAC FPRs for this large collection of simulated volumes and clusters are computed (see Appendix for algorithmic details) and adjusted until the desired global FPR is met. Creating the collection of noise-only volumes by repeatedly t-testing thousands of randomized cases is the lengthiest part of the computation.
Cluster size is a very widely used score or figure of merit (FOM) for assessing significance in neuroimaging. The size of a cluster (voxel count) is the sum of the number 1 across all voxels within the cluster; that is, across N voxels, Σ 1. From this formulation, it is simple to generalize the cluster significance FOM to other sums across cluster voxels, sometimes referred to as “cluster mass” (Zhang et al., 2009); for example, incorporating the statistic associated with each i-th voxel as a weight, such as Σ zi
2, where zi
denotes the
Tests and Results
Tests 1: FPR control
The first test of the proposed ETAC approach uses a variation on the methodology in Eklund et al. (2016). From the FCON1000 collection of resting-state FMRI data sets (Biswal et al., 2010), the 198 data sets in the Beijing subcollection were processed with AFNI pipelines specified using afni_proc.py to produce the first-level (individual subject) activation maps. In this process, data sets were resampled to 2 mm3 voxels to conform with Eklund et al. (2016); this refinement is not needed for any other reason (the original voxel dimension is about 3 mm). The Beijing subcollection was chosen for this test to test ETAC in a similar setting as used in Eklund et al. (2016)—the article that launched this effort.
Five sets of pseudorandom timings were used to produce 198 × 5 = 990 maps of fit coefficients (betas), with no spatial blurring used at this analysis level. These 990 maps were each computed for three different pseudotask stimulus durations: 1, 10, and 30 s. The blood oxygenation-level-dependent (BOLD) hemodynamic response function (HRF) regressor models for all five pseudotask timings in each duration were nearly orthogonal—stimulus duration of 30 s had the most highly correlated HRF models, with mean correlation 0.09 and standard deviation 0.21—so that the five estimated response magnitudes (betas) in each subject were approximately uncorrelated. This use of multiple randomized timings slightly distinguishes the present testing methodology from that in Eklund et al. (2016).
At the second (group) level, two-sample t-tests were carried out, with 20 randomly chosen subjects (of the 198) assigned to each sample. For each subject, one of the five results from the variable task timings was selected randomly in each simulation. A total of 1000 realizations of this procedure were analyzed with ETAC, for each of the 3 stimulus durations. For each stimulus class (1, 10, 30 s), three results were calculated: the FPRs for one-sided (positive or negative) or two-sided t-thresholding; thus, there are 3 × 3 = 9 results for the two-sample t-tests for each goal FPR. A very similar set of simulations was run separately using one-sample t-tests with 40 subjects per simulation. In all cases, a panoply of nominal (goal) FPRs was run, with ϖG = 1%, 2%, …, 9%.
Within the ETAC procedure, three blur cases were used in defining the subtests: 4, 7, and 10 mm (FWHM). Ten voxel-wise p-thresholds were used, 0.010, 0.009, 0.008, …, 0.001 (the defaults); thus, 30 subtests were used in each of these simulations. The nearest neighbor (NN) cluster-defining level was left at the default 2 (i.e., neighbors of a voxel are those sharing either face or edge; cf. Appendix), and the default FOM with h = 2 (i.e., statistically weighted) was used.
The empirical FPRs from one-sample and two-sample t-test simulations are presented in Figure 3 for the ETAC method, along with the 95% (binomial) confidence intervals that would be expected from 1000 independent simulations if the algorithm exactly achieved the nominal FPR. For the two-sample t-tests (with 40 subjects in total), the results are tightly clustered, slightly below the nominal FPR and typically within the confidence interval. For the one-sample tests with 40 subjects, the results are more variable. This effect is due to the lack of independence among the resampled data set collections, as each collection of 40 is taken from the same 198 source data sets (Eklund et al., 2016; Supplementary Material). The same effect (broadened variability of achieved FPR) exists in the two-sample tests, but is much smaller.
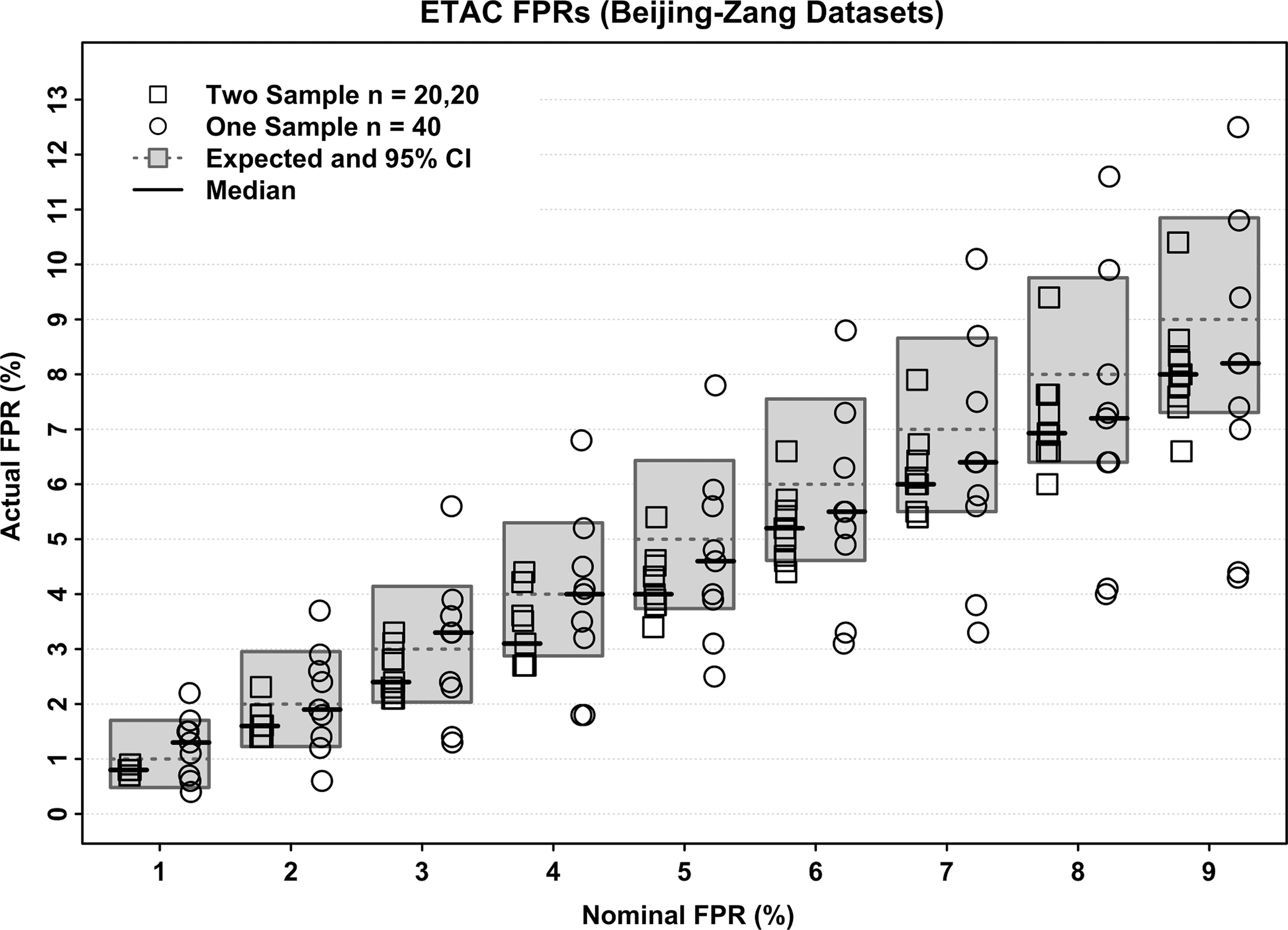
ETAC FPRs from simulations of two-sample t-tests (20 subjects/sample) and one-sample t-tests (40 subjects in the sample). The nominal (desired) FPR ϖG is shown along the horizontal axis, and is also shown as a dashed line within the gray boxes, representing the 95% confidence intervals for the FPR (from a binomial distribution, assuming the nominal FPR as the binomial parameter and assuming all 1000 replicates are independent). Thus, symbols that fall inside their gray box are within the 95% CI of what would be expected if the nominal FPR was the actual ETAC FPR. Medians for the nine values in each partition are shown with solid black lines. The two-sample ETAC results are fairly close to the nominal FPR and tightly clustered, but the one-sample results have a great deal more variability; see the main text for an explanation of this increased dispersion. CI, confidence interval; ETAC, equitable thresholding and clustering.
The two-sample FPR results appear to be slightly biased below their nominal goals. The reasons for this are unknown to the author.
Tests 2: FPR spatial variability
To examine the spatial distributions of false positives found by ETAC, 10,000 simulated two-sample cases were run using the resting-state FMRI null test methodology described earlier, using the beta maps from the 10-s duration pseudostimulus timings, with the same 3 blurring parameters and 10 p-thresholds. Figure 4 shows the spatial distribution of false positives for various sagittal slices, for ETAC, and for mono-p-thresholds applied to the individual blur cases (each of the latter was thresholded at p = 0.005). While, as shown above, the ETAC approach is successful at controlling the global FPR, the cluster results are not uniform across the brain; this result is similar to that previously observed in various cluster-thresholding methods (Eklund et al., 2016; cf. Supplementary Fig. 18 et seq.). My goal of producing a markedly more uniform distribution of false positives was not achieved.
Spatial distribution of false positives resulting from 10,000 null simulations. ETAC was run with ϖG = 5%, 10 p-thresholds (0.001, 0.002, … 0.010), 3 blurs (4, 7, 10 mm); ETAC results are mapped in the upper panel. The lower three panels show the spatial distributions for the single p = 0.005 threshold method for each blur case. Since the range of false-positive counts varies strongly with blur case, the color range for each panel is different and is set to the 95% point on the cumulative distribution of the nonzero FPR voxel counts in each case.
Tests 3: Reliability
To examine the ability of ETAC to find true positives, a collection of task data sets was downloaded from
Figure 5 shows the map of the differences in the detection rate between ETAC and mono-p-thresholding at p = 0.005 and p = 0.010 (Fig. 5 is not an activation map, but instead shows the places where the two methods differed in likelihood of finding results). Comparing ETAC to mono-p = 0.005 (upper panel), it is clear that ETAC results cover significantly more volume. Comparing ETAC to mono-p = 0.010 (lower panel), there are fewer differences and they are in both directions; ETAC finds some more results in places, and fewer in others.
Maps of the differences in the detection rate between ETAC and mono-p-thresholding at p = 0.005 (upper) and p = 0.010 (lower), calculated from running 1000 simulations with the UCLA phonemics study, pamenc-versus-control task t-test. Color range is set to 5%; for example, red means that ETAC detected a result at least 5% more often than the mono-p-threshold method, and dark blue indicated that the mono-p-threshold method detected a result at least 5% more often than the ETAC method. (Much more of the brain is truly active than shown here; in many places, the detection probabilities of the two methods were nearly identical.)
Figure 6 shows a graph of the cluster-size thresholds involved in computing Figure 5 (for ϖG = 5%), and is a real-life instantiation of the conceptual Figure 2. The lower curve (triangles) shows the cluster-size thresholds needed for mono-p-thresholding. The upper curve (circles) shows the cluster-size thresholds used with ETAC's 10 p-thresholds. The boxes-only plot shows the cluster-size thresholds resulting when ETAC is rerun specifying 91 p-thresholds from 0.001 to 0.010 (Δp = 0.0001). The 10 p-thresholds' cluster sizes faithfully follow the 91 p-thresholds' plot, and are raised above the mono-p-threshold cluster sizes. At p = 0.010, the ETAC cluster-size threshold is 1383 voxels, while the mono-p-threshold is 1053 voxels. This greater stringency at p = 0.010 is why Figure 5 shows places where ETAC is somewhat less likely to find clusters than mono-p = 0.010. The trade-off is that ETAC can find clusters where the mono-p-threshold method cannot.
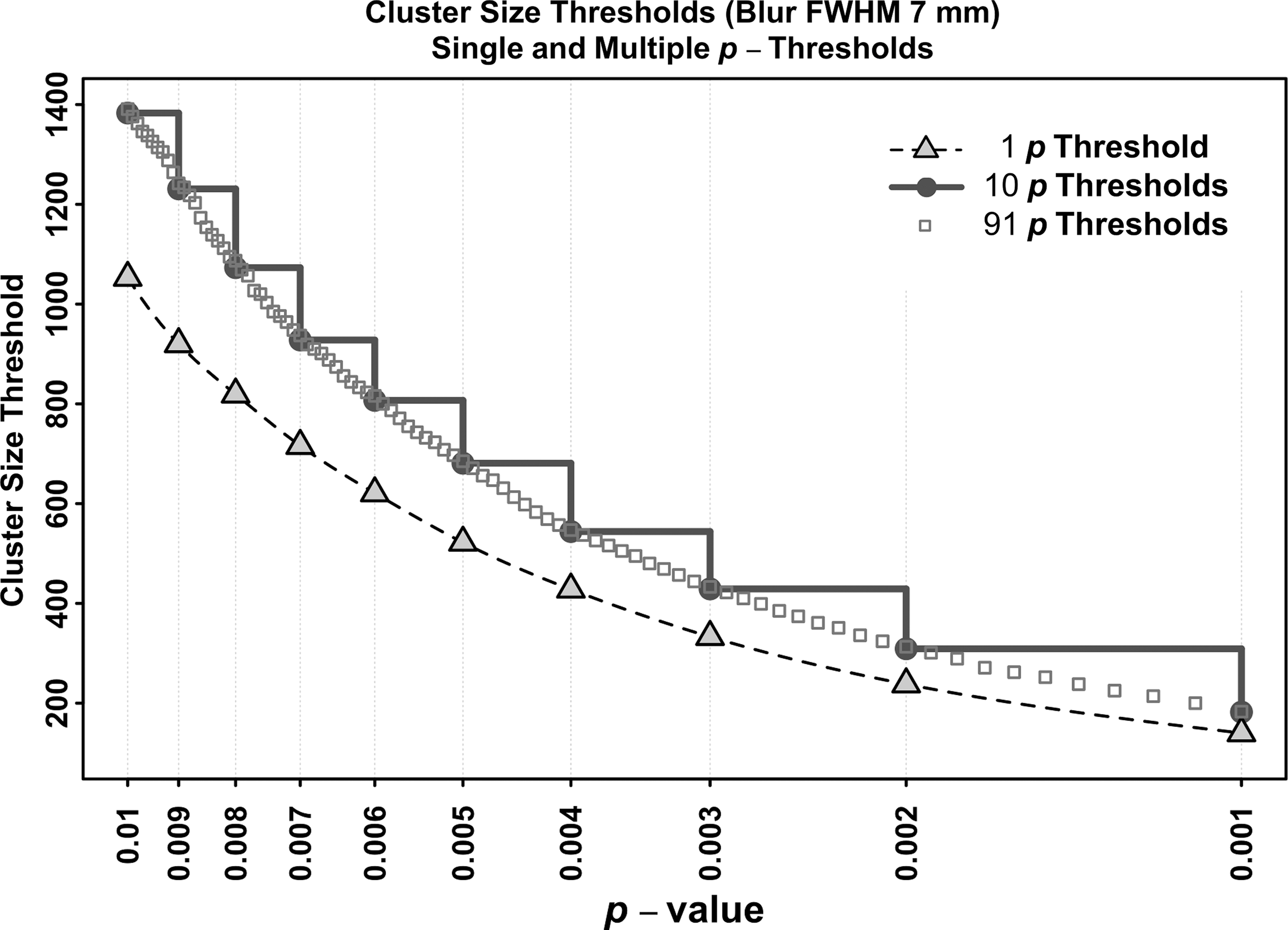
Cluster-size thresholds involved in computing Figure 5 (for ϖG = 5%). The lower curve (triangles) shows the cluster-size thresholds needed for mono-p-thresholding. The upper curve (circles) shows the cluster-size thresholds used with ETAC default 10 p-thresholds. The boxes-only plot shows the cluster-size thresholds resulting when ETAC uses 91 p-thresholds from 0.001 to 0.010 (Δp = 0.0001) (cf. Fig. 2.).
Discussion
The ETAC method has been shown to be effective at controlling the FPR for cluster-based detection in task FMRI. This performance is achieved while also reducing the influence of the arbitrary selection of parameters affecting the cluster results, the primary motivation for the method's inception. Importantly, ETAC does not lose much true detection power relative to simpler nonparametric cluster-thresholding methods, and can have more power depending on the study and on the simpler method chosen for comparison.
In the testing framework used in Eklund et al. (2016) and in Cox et al. (2017b), nonparametric clustering methods were shown to control FPR better than parametric methods that are based on a model for the spatial correlation function of the FMRI noise. These nonparametric methods, though, are more stringent than the parametric methods, having reduced power by comparison, and will lose some results that parametric methods will detect. In other words, the usual statistical trade-off is still present.
ETAC's use of multiple submethods can recover a little of the lost statistical power, as evidenced in Figure 5, but it is still more strict than the parametric clustering methods in widespread use since the cluster-size/FOM thresholds are usually larger than those the parametric models yield. A noteworthy advantage of ETAC is that it removes two arbitrary choices from the group analysis: the voxel-wise p-threshold, and the amount of spatial blurring to apply. For example, there are no strong a priori reasons to favor p = 0.001 over p = 0.01 (provided FPR is properly controlled), or 8 mm (FWHM) blurring over 4 mm blurring.
The computational burden of the full ETAC method is not especially onerous, since it is run on all of the data in a study to produce a group map. For instance, an ETAC run with 40 subjects at 2 mm3 resolution, with a single goal FPR ϖG, ran for 42 min on a 16 core Intel/Linux node, and needed 17 GB of memory to hold all the intermediate simulations and cluster tables. Most of this time and memory is needed for the repeated t-tests of the randomized/permuted input data sets. Expanding the ϖG list to the entire gamut of 1%, 2%, …, 9% increased the run time to 51 min.
While the computational cost of performing the ETAC analysis is not prohibitive, it could make it difficult to extend the ETAC method to more complex voxel-wise statistical mapping techniques, such as linear mixed-effect analyses (Chen et al., 2013). Such analysis methods are themselves computationally intensive, unlike simple voxel-wise t-tests or linear regression.
Thus, iterating and randomizing such tests thousands of times are at present impracticable.
Conclusion
I have described the ETAC methodology and shown comparisons of it with an existing standard cluster-threshold technique that also controls FPRs reasonably well. ETAC's primary benefit is to reduce the dependence of arbitrary parameter choices on final cluster results, as well as to allow for the discovery of a greater range of cluster types (large with relatively low voxel-wise significance or small with relatively high voxel-wise significance) in a single analysis and with essentially equal footing.
Footnotes
Acknowledgments
The research and writing of the article were supported by the NIMH Intramural Research Programs (ZICMH002888) of the NIH/DHHS/USA. This work would have been impossible without the outstanding computational resources of the NIH HPC Biowulf cluster. Data for the analyses included the FCON-1000 collection and OpenFMRI collection ds000030. Thanks go to Paul Taylor for the many suggestions that improved the article immeasurably. Thanks go to the referees for very useful critiques (p < 0.01). The ideas for equitable application of multiple subtests came to R.W.C. while hiking in Grand Canyon National Park; thanks go to the U.S. National Park Service for maintaining this inspirational public treasure.
Author Disclosure Statement
No competing financial interests exist.