
Abstract
Introduction:
Data augmentation improves the accuracy of deep learning models when training data are scarce by synthesizing additional samples. This work addresses the lack of validated augmentation methods specific for synthesizing anatomically realistic four-dimensional (4D) (three-dimensional [3D] + time) images for neuroimaging, such as functional magnetic resonance imaging (fMRI), by proposing a new augmentation method.
Methods:
The proposed method, Brain Library Enrichment through Nonlinear Deformation Synthesis (BLENDS), generates new nonlinear warp fields by combining intersubject coregistration maps, computed using symmetric normalization, through spatial blending. These new warp fields can be applied to existing 4D fMRI to create new augmented images. BLENDS was tested on two neuroimaging problems using de-identified data sets: (1) the prediction of antidepressant response from task-based fMRI (original data set n = 163), and (2) the prediction of Parkinson's disease (PD) symptom trajectory from baseline resting-state fMRI regional homogeneity (original data set n = 43).
Results:
BLENDS readily generates hundreds of new fMRI from existing images, with unique anatomical variations from the source images, that significantly improve prediction performance. For antidepressant response prediction, augmenting each original image once (2 × the original training data) significantly increased prediction R
2 from 0.055 to 0.098 (
Conclusions:
Augmentation of fMRI through nonlinear transformations with BLENDS significantly improved the performance of deep learning models on clinically relevant predictive tasks. This method will help neuroimaging researchers overcome data set size limitations and achieve more accurate predictive models.
Impact statement
Given deep learning success across life science, there is interest in their application to neuroimaging. Deep learning requires a large training dataset, hence data augmentation has been proposed to bolster model training, however, there is no validated augmentation for synthesizing anatomically realistic 4D images. To remedy, we propose BLENDS, which generates new fMRI by combining intersubject coregistrations into a warp field which is applied to existing 4D fMRI to create new images. Tests on predicting: (1) antidepressant response and (2) Parkinson's trajectory demonstrate significant performance improvements. The proposed general method helps researchers overcome limited data and achieve accurate predictive models.
Introduction
Data augmentation is an important tool for improving the performance of machine learning models, especially when limited data are available for training. Augmentation aims to simulate new data samples by introducing randomly generated variations to existing samples. Many neuroimaging applications of machine learning and deep learning are limited by small data set sizes (Cui and Gong, 2018; Varoquaux, 2018; Varoquaux et al, 2017), where even a data set of 100 samples can result in models with large uncertainty and bias. Data augmentation provides a mitigating solution. However, there are currently no augmentation methods to synthesize new, anatomically realistic functional magnetic resonance imaging (fMRI), complete with four-dimensional (4D) (three-dimensional [3D] + time) data.
Prior work in magnetic resonance imaging (MRI) augmentation has primarily focused on augmentation of 3D T1-weighted structural MRI (sMRI). Previously, algorithms were developed that applied independent components analysis (ICA) decomposition and then sampled random latent vectors to generate new T1-weighted images (Castro et al, 2015; Ulloa et al, 2015). While such an approach could be used to synthesize single 3D frames of fMRI data, the time-varying information would not be captured. This ICA approach is also specific to classification problems and unable to synthesize images conditioned on a continuous regression label.
Minimal work exists on methods for other brain MRI contrasts. Zhuang et al (2019) proposed the synthesis of 3D task fMRI brain activation maps using a generative adversarial network (GAN). While this augmentation strategy improved performance in classifying cognitive processes, training GANs to produce high-fidelity images requires large training data sets in the first place. Zhuang et al used data sets with >1800 images, whereas our work uses data sets with tens to hundreds of images. Furthermore, GANs to synthesize time series of 3D images have not been developed. Consequently, there is a clear need for a method to generate augmented 4D fMRI time series that is applicable to problems with small data sets.
The proposed method, Brain Library Enrichment through Nonlinear Deformation Synthesis (BLENDS), is the first that can be applied to 4D MRI data including fMRI to generate new image time series. It is computationally efficient, requiring only 2 min on most hardware to generate each new image. It is also easily scalable and can generate up to hundreds of augmented images per original image by introducing brain morphological variations derived from large public repositories of MRI. Minimal user parameterization is required, making BLENDS straightforward to apply. We show that BLENDS improves deep learning prediction accuracy in two cases, starting with as few as 43 original images: prediction of antidepressant treatment outcome from task-based fMRI and Parkinson's disease (PD) total symptom trajectory prediction from resting-state fMRI.
We compare this approach with our previously reported algorithm that augmented images by performing coregistrations with other, randomly selected images (Nguyen et al, 2020). Despite substantial improvement to the prediction of antidepressant outcomes, our previously reported method was limited by high computational cost and reliance on a two-step T1-based registration. This registration approach could introduce only anatomical variations represented in the data set at hand. The current algorithm proposed here overcomes these limitations and allows generation of out-of-sample augmentations plus demonstrates marked improvement in deep learning performance for two clinical problems while simultaneously reducing computation time by 15 × .
The contributions of this work are twofold. First, BLENDS enables researchers to build more accurate and generalizable machine and deep learning models with smaller data sets. While these modeling methods generally require hundreds or even thousands of samples (Varoquaux, 2018), BLENDS helps to bridge the gap between this requirement and the sample sizes feasibly acquired in most neuroimaging studies. Second, experimental results show that our method significantly improves model performance in two small data sets with distinct pathologies.
Materials and Methods
Augmentation
A given brain's morphology
where
In the proposed method, a set of hundreds of warp fields are produced by coregistering T1-weighted images to the MNI152 template. ANTs symmetric normalization is used to perform an initial rough affine registration, followed by a multiscale nonlinear registration (Avants et al, 2010). The resultant affine matrix for each image is decomposed into translation, rotation, shearing, and scaling components. The shearing and anisotropic scaling components are then composed with the nonlinear registration to obtain the warp field
Blended warp generation
Previous work showed that warping a given brain image to a different, randomly selected brain image through coregistration was effective for augmentation (Nguyen et al, 2020). However, this previous method could not introduce morphological variations beyond what exists in the data set. Also, performing these coregistrations on-the-fly required ∼30 min for each augmentation iteration, which quickly becomes computationally costly when 100-1000 or more augmented images are desired. BLENDS eliminates this most costly step by generating new warps directly from the set of precomputed warps.
Thus, an inordinate number of new warps can be rapidly created for the one-time fixed cost of creating the warp set. In many cases, a neuroimaging researcher may already have such a warp set on hand, which may be repurposed for BLENDS. To generate new warps from the set, fully learning the distribution of warp fields, particularly at the voxel level, is computationally costly and unnecessary. Instead, a new warp can be created by spatially blending combinations of existing warps. With the assumption that a weighted combination of real anatomical warps yields an anatomically realistic warp, this approach allows the combinatorial generation of far more warps than are present in the set (Fig. 1).

fMRI augmentation using BLENDS to combine four existing warp fields
For each augmentation operation, n real warps,
which computes, for each voxel
In the following applications, BLENDS was performed with the number of sampled real warps
Image preparation
The image to be augmented is the source image. To apply the newly generated warp
Since the warps can be applied agnostically to any 3D or 4D image, the same generated warp can be used to transform multiple contrasts from the same individual, such as fMRI, sMRI, and diffusion MRI. In the case of a 4D fMRI time series, the warp is applied to each volume in the time series, assuming that the volumes have been realigned with a tool such as FSL MCFLIRT to correct for intervolume motion (Jenkinson et al, 2002).
Applications
Here, we demonstrated BLENDS on two distinct neuroimaging data sets involving common brain disorders. Both use de-identified, publicly available data containing fMRI and sMRI. Brief details are provided here with full data set characteristics and MRI parameters available in Supplementary Tables S1–S4 in the Supplementary Data.
Major depressive disorder
The objective of the first application is to predict antidepressant response from brain activation measures of pretreatment fMRI. Imaging data for 163 participants with major depressive disorder (MDD) were obtained from the Establishing Moderators and Biosignatures of Antidepressant Response in Clinical care (EMBARC) study (Trivedi et al, 2016). Demographics are shown in Supplementary Table S1 in the Supplementary Data. Functional imaging during a reward processing task and structural imaging was performed at pretreatment baseline, before the participants underwent an 8-week course of the antidepressant sertraline (task paradigm and acquisition parameters are detailed in Supplementary Methods Section S1 and Supplementary Table S2 in the Supplementary Data). Depression severity was measured by trained clinical raters using the Hamilton Rating Scale for Depression 17-item score (HAMD) before and after treatment. Antidepressant response is defined as the difference in HAMD score.
The precomputed set of warps is generated by computing coregistrations between the MNI152 template and each of 127 structural (T1-weighted) images from EMBARC. This set of structural images composed of all participants not included in the main fMRI data set (i.e., from a separate treatment arm), as the latter was used for model training. BLENDS was applied to augment each fMRI 2 times (2 × ), 5 times (5 × ), and 10 times (10 × ). Augmented fMRI images were then preprocessed with a standard fMRI pipeline including head motion correction, spatial normalization, and nuisance regression (further details are provided in Supplementary Methods Sections S2 and S3 in the Supplementary Data).
Brain activation maps were computed using a generalized linear model. A custom 200-region brain atlas was created using the pyClusterROI tool, which performs spectral clustering normalized cuts on fMRI data (Craddock et al, 2012). Mean regional values were computed using this atlas and passed as input features into a neural network to predict post-treatment change in HAMD score. The augmentation was performed on the “raw” 4D fMRI time series rather than the 3D brain activation maps. This demonstrated the general applicability of BLENDS to 4D images and also its flexibility. In further applications, augmenting the original 4D images would allow the user the ability to re-process and extract other measurements (e.g., functional connectivity, regional homogeneity [ReHo], fractional amplitude of low frequency fluctuations) as needed for a targeted application.
Parkinson's disease
For the second application, the goal was to predict PD total symptom trajectory from baseline resting-state fMRI. In this case, disease severity 12 months after baseline needed to be predicted from the baseline ReHo measures extracted from resting-state fMRI. From the Parkinson's Progression Markers Initiative (PPMI) data set, 43 PD participants were selected who had functional and structural imaging data and who also had disease severity measured at 12 months after baseline. Severity was measured by clinical raters using the total score from the Movement Disorder Society's Unified Parkinson's Disease Rating Scale (MDS-UPDRS), which was assessed with participants in the medicated state. See Supplementary Table S3 for demographics and Supplementary Table S4 for acquisition parameters in the Supplementary Data.
The warp set contained 115 warps, computed from T1-weighted structural images from the Parkinson's Disease Biomarker Project (Gwinn et al, 2017; Ofori et al, 2016). This separate data set was used to ensure that no testing subjects would be included in the warp set. As with the MDD application, BLENDS was applied at 2 × , 5 × , and 10 × .
Augmented fMRI were preprocessed with the same fMRI pipeline (Supplementary Methods Sections S2 and S4 in the Supplementary Data). ReHo, which measures the similarity in activity of each brain voxel with its 26-voxel neighborhood, is computed using the C-PAC software (v1.0.3) (Craddock et al, 2013). ReHo reflects the synchronicity of a voxel with its immediate surrounding brain tissue, and abnormalities in ReHo have been observed in PD (Hu et al, 2019). The Schaefer 200-region atlas was used to compute the mean ReHo in each brain region. These values were used as inputs into the neural network described in the next section, along with clinical covariates including age, sex, race, ethnicity, disease duration, and baseline MDS-UPDRS. The clinical covariates were not altered during the creation of each augmented sample.
Neural networks
Deep feed-forward, fully connected neural networks were constructed for both applications. Hyperparameter optimization was conducted using Bayesian Optimization with Hyperband (BOHB), a fully automated hyperparameter search algorithm unbiased to user expertise or hand-tuning (Falkner et al, 2018). Full details of the hyperparameter optimization, model architectures, and hyperparameter ranges can be found in Supplementary Methods Section S5, Supplementary Figure S1, and Supplementary Table S5 in the Supplementary Data.
Model performance was validated using nested K-fold cross-validation with three outer and five inner folds. For each outer fold, testing data were held aside, and the remaining data were used to perform a random search over 100 hyperparameter configurations with fivefold inner cross-validation. The best performing model from the random search was retrained on all inner data and evaluated on the testing data. This retraining and evaluation was repeated 100 times per outer fold, with different random weight initializations, for significance testing. No augmented data were included in validation or testing, and data splits were grouped such that each augmented sample remained in the same fold as the original sample.
Neural networks were implemented in Tensorflow v1.12, and BOHB searches were performed with Ray Tune v1.2 with parallelization across 4 Nvidia Tesla P100 GPUs.
Results
Augmented images
Examples of augmented images generated with BLENDS are shown in Figure 2. A pair of structural and functional images from the same individual were augmented five times (same blended warp applied to both images) to introduce morphological variations throughout the brain. Comparing the augmented fMRI with the original image (Fig. 2, third row) highlights areas where variations have been introduced: for example, the lateral ventricle size and the convexity of the frontal lobe have been altered to varying degrees. Due to the process of blending multiple existing warps together, these resultant augmented images are distinct from those in the original sample. Figure 3 illustrates the examples of brain activation maps computed from original and augmented fMRI from the MDD data set, showing that the variability is carried into subsequent measurements derived from fMRI.
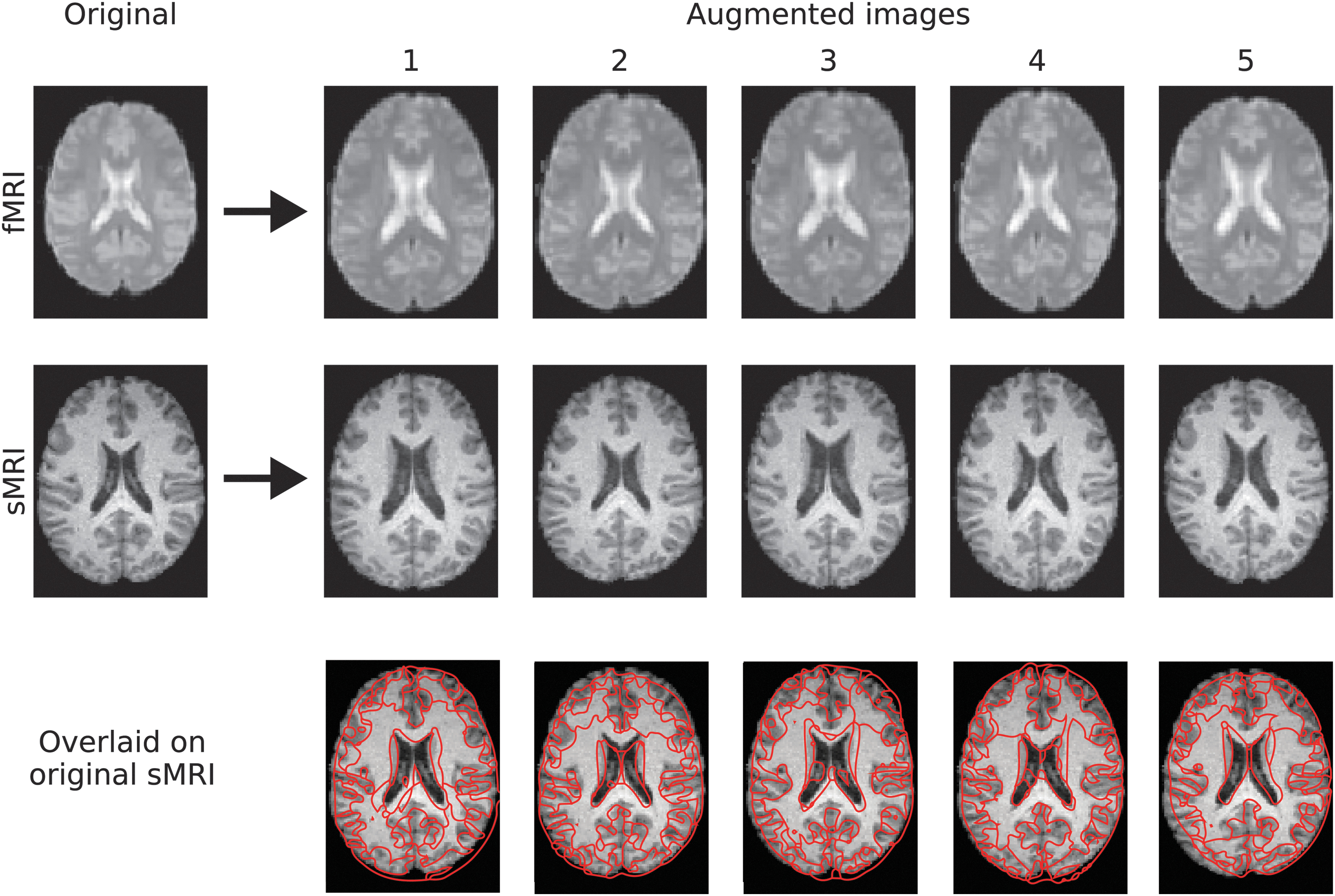
BLENDS applied to fMRI (first row) and structural T1-weighted MRI (sMRI, second row) from a Parkinson's Disease patient to synthesize five new samples. Morphological variations are introduced in global brain shape as well as in neuroanatomical structures such as the ventricles. In the third row, an edge map of each augmented sMRI is overlaid over the original sMRI to illustrate the morphological differences.
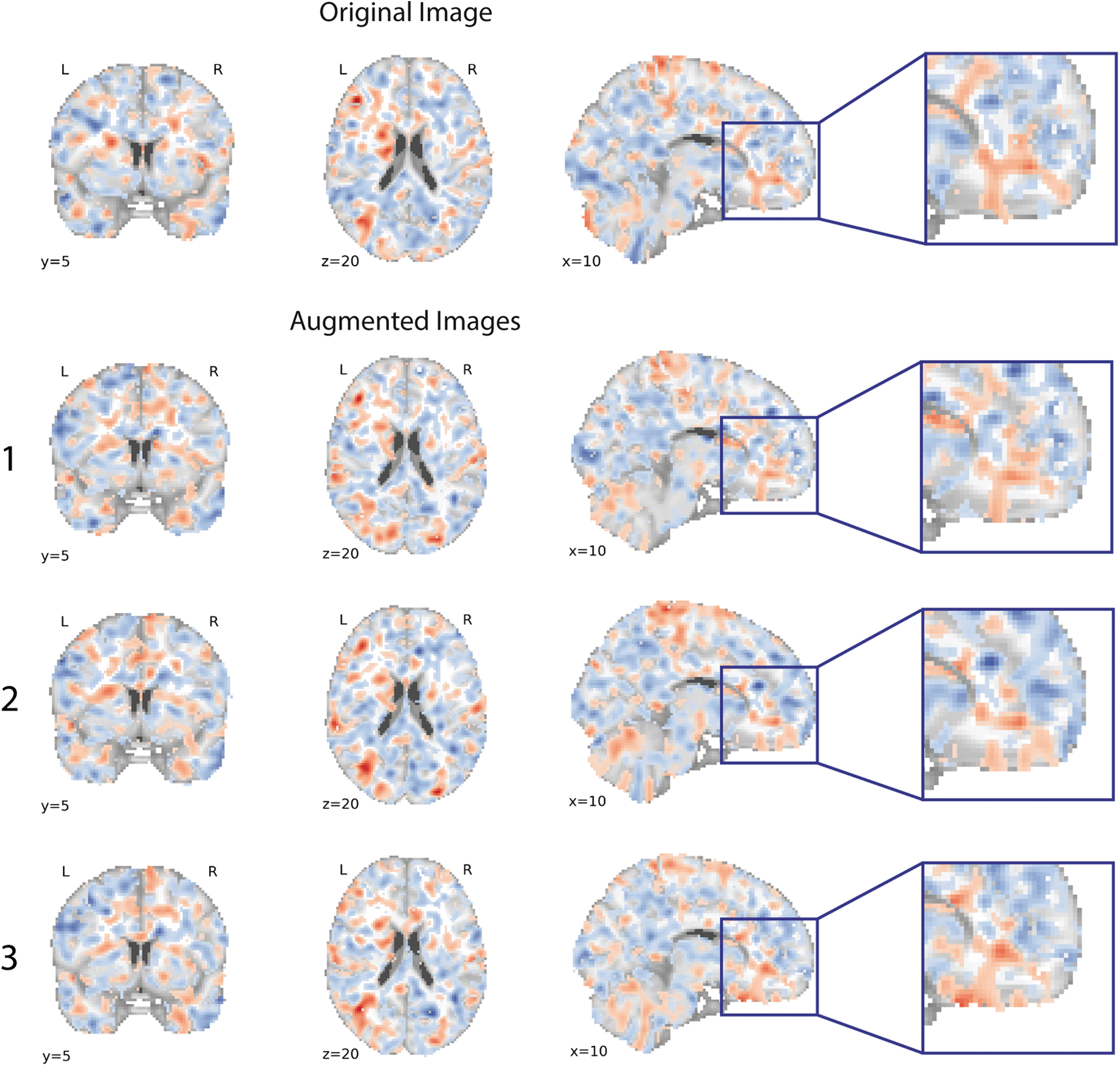
Brain activation maps computed from the original and three augmented fMRI of a participant from the major depressive disorder data set. Red indicates areas of higher activity during reward stimuli, and blue indicates areas of lower activity. Maps have been spatially normalized to the MNI152 template to control for global brain shape differences while highlighting local differences among the brain activation maps. An area of the prefrontal cortex has been magnified to show how augmentation has introduced variation in activation patterns. MNI152, Montreal Neurological Institute 152-brain.
The computation time for each source image includes a one-time registration to the MNI template (see the Image Preparation section), which takes 30 min on a conventional workstation CPU (Xeon E5-2680). Subsequently, each augmentation operation, including the generation of the blended warp and the transformation of the original image, required 2 min. Augmentation by 10 × thus requires about 50 total minutes of computation, whereas our previous coregistration-based method would require 300 min (30 per augmentation) (Nguyen et al, 2020). Thus, the proposed method provides a 6 × speedup in computation time.
Major depressive disorder
Performance in predicting antidepressant response from task-based brain activation measures substantially increased with augmentation (Fig. 4). At baseline before augmentation, R
2 (mean over all outer cross-validation folds) was 0.055. This indicates that the model was able to explain about 5.5% of the variance in the change in depression symptoms 8 weeks after antidepressant treatment from the pretreatment neuroimaging. Performance significantly increased (two-tailed T-test) with 2 × augmentation to 0.098 (
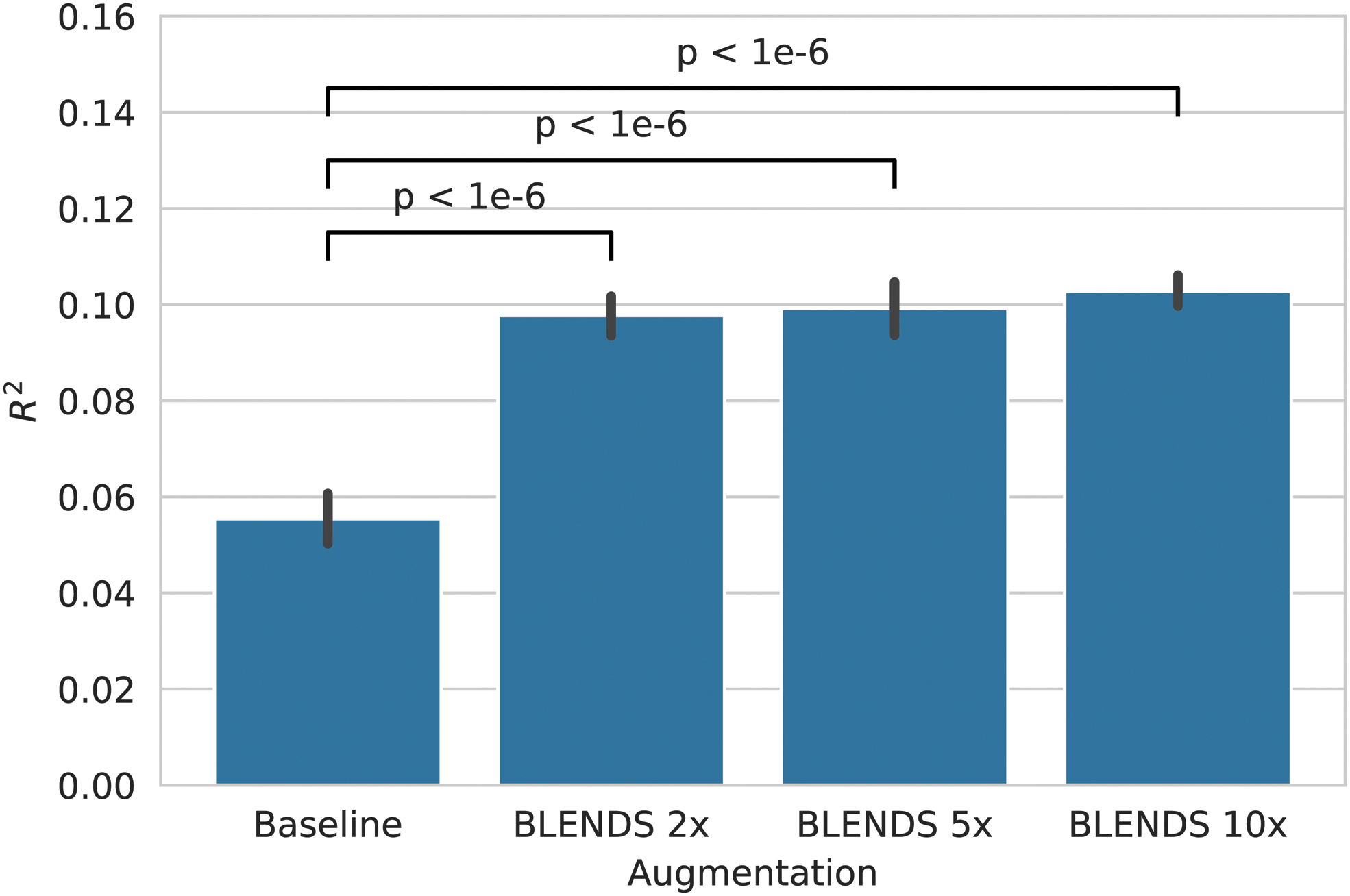
Performance (coefficient of determination, R 2) in predicting antidepressant outcomes from pretreatment task-based fMRI. Error bars indicate the 95% confidence interval, computed by retraining each model 100 times per cross-validation fold with different random weight initializations.
Parkinson's disease
BLENDS also markedly improved the accuracy of predicting PD total MDS-UPDRS severity at 12 months after the baseline imaging scan using ReHo measures (Fig. 5). Before augmentation, severe overfitting was observed with R
2 of 0.654 on training data but −0.044 on unseen test data. A significant increase to a test R
2 of 0.408 was seen with 5 × augmentation (
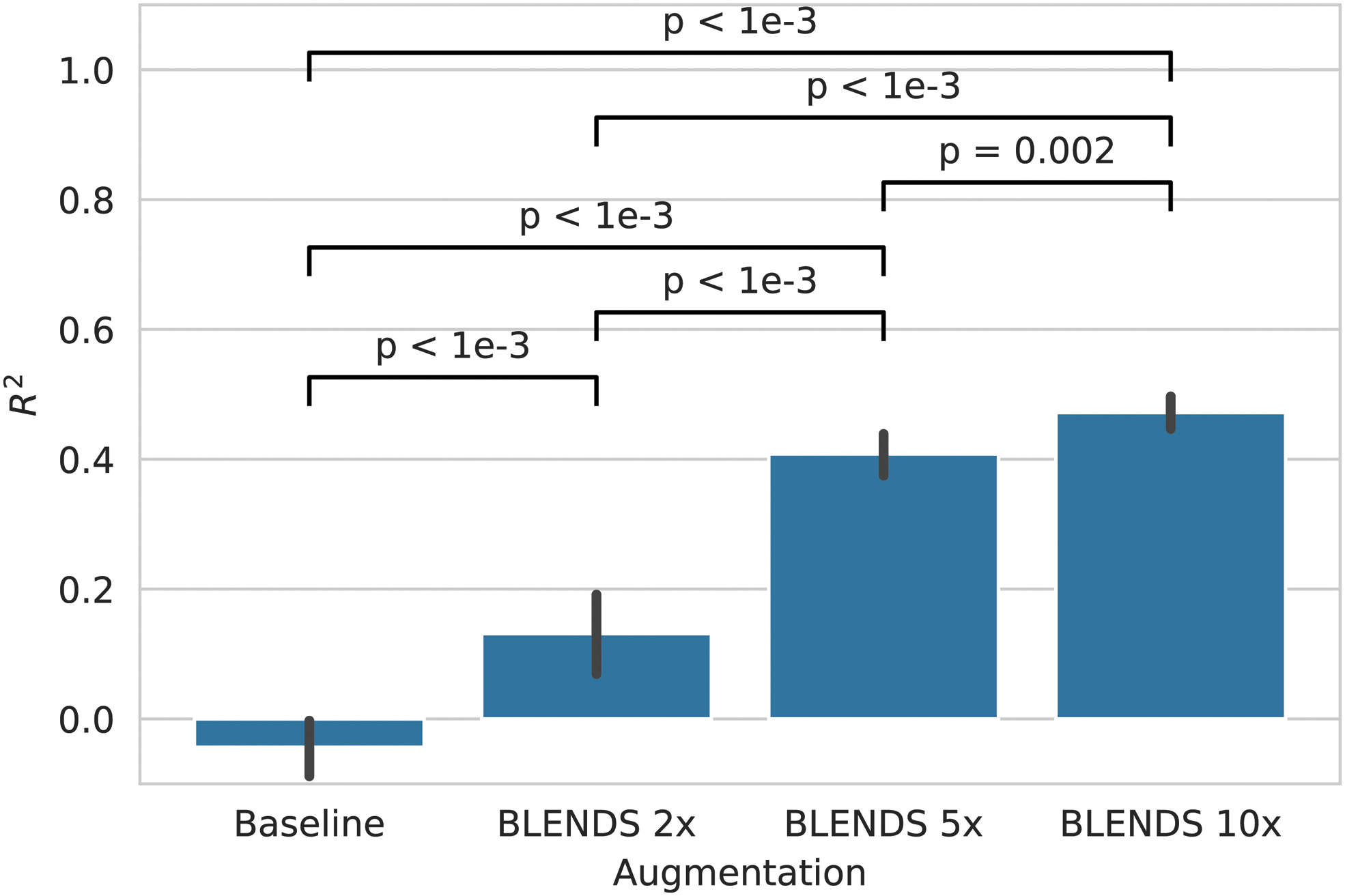
Performance (coefficient of determination, R 2) in predicting future Parkinson's Disease severity 1 year in the future from regional homogeneity derived from baseline resting-state fMRI. Error bars indicate the 95% confidence interval, computed by retraining each model 100 times per cross-validation fold with different random weight initializations.
To demonstrate that augmentation did not introduce spurious associations that did not original exist between the data and prediction target, a permutation test was performed. After permuting the MDS-UPDRS scores across samples to remove any existing associations in the data, R 2 remained negative regardless of augmentation (Supplementary Table S6 in the Supplementary Data). Thus, augmentation does not create false-positive associations when none exists in the data originally.
Discussion
Rationale for augmentation through warping
As observed in Figure 2, brain warping via BLENDS mainly creates variations in the spatial distribution of functional activity patterns. While the magnitude of the functional activity is not changed, its appearance changes when the image is warped and then resampled onto the rectilinear lattice of image voxels. Naturally, this assumes that the important information for the predictive task comes solely from the functional activity and is independent of brain anatomy. This is discussed further in the Limitations section.
Impact on predictor performance
For both clinical applications, the prediction of antidepressant response from task-based fMRI and the prediction of future PD severity from resting-state fMRI, BLENDS augmentation substantially improved neural network performance. In the antidepressant application, treatment outcome prediction performance improved by a relative 87% with 10 × augmentation compared with baseline. For the prognosis of individuals with PD, BLENDS also demonstrated a large and significant performance increase from baseline. Augmentation by 2 × was required to start achieving a non-zero R 2 of 0.131. Increasing to 10 × augmentation further improved performance by a relative 260%. Of note, the relationship between augmentation amount and performance is not linear. Consequently, for a new problem, it may not be known a priori what amount of augmentation is required to achieve a desired performance level. However, a straightforward search over augmentation amount can be employed to identify the optimal condition.
Comparison to other augmentation methods
Besides Nguyen et al (2020), there are few published fMRI augmentation methods for comparison. Zhuang et al (2019) recently reported an approach using a GAN to augment 3D brain activation maps derived from fMRI. They achieve up to a 4.6% accuracy increase (7.6% relative increase from baseline) in classifying cognitive states with a neural network. A main limitation of this approach is that it is constrained to 3D images; 4D GANs are computationally prohibitive to train on current hardware due to the sheer memory and compute required. This prevents usage on “raw” fMRI time series (3D + time) or other 4D data such as dynamic contrast-enhanced MRI or diffusion MRI (where the fourth dimension is direction). Similarly, Eslami et al (2019) proposed an extension to the Synthetic Minority Over-sampling Technique (SMOTE) using a similarity measure optimized for fMRI data.
However, this method is also limited to generating fMRI derivatives (e.g., functional connectivity matrices) instead of full 4D images. Augmentation of the full fMRI time series is essential if subsequent analysis requires deriving scalar measures, such as functional connectivity or causal connectivity, or multiple complementary measures such as ReHo and amplitude of low-frequency fluctuations (ALFF). Instead of directly synthesizing images, BLENDS generates new warps that can be applied to any image type, allowing more flexibility than a GAN-based approach.
An additional limitation to these existing methods is that they are restricted to classification tasks (i.e., with a discrete prediction target), which prevents application to the regression tasks investigated in this work. The GAN approach generates samples conditioned on the desired target label, and GANs conditioned on continuous labels do not yet exist. SMOTE is inherently limited to classification, and while an extension to regression exists (SMOTER), it depends on a linearity assumption to interpolate new target values (Torgo et al, 2013).
BLENDS for classification
To demonstrate the applicability to classification problems, BLENDS was also applied to the diagnosis of PD from resting-state functional connectivity (Supplementary Methods Section S6 in the Supplementary Data). On this problem, BLENDS achieved a similar increase to classification accuracy as SMOTE, up to 10% compared with the baseline without augmentation (Supplementary Fig. S2 in the Supplementary Data). This highlights how BLENDS can achieve competitive performance boosting augmentation results for both regression and classification applications. Additionally, BLENDS and SMOTE can be used in combination, which produced the best performance in this classification task.
Limitations
There are two limitations of BLENDS that warrant discussion. The first is that BLENDS requires a precomputed set of warps, which can entail some upfront computational cost. However, the combinatorial nature of sampling and blending warps means that a large range of morphological diversity can be generated from a relatively small warp set. For example, sampling four warps at a time from a set of 100 warps yields 4 million unique combinations, with further variations introduced through the random blending process. To mitigate this limitation, we will provide a large set of warps computed from more than 1000 healthy brains to the community for ready download, facilitating immediate testing and application of BLENDS. For applications where the cohort may have aberrant morphology compared to healthy brains (e.g., PD), we recommend that researchers compute their own warp set.
In many cases, researchers already have such a set of study-specific warps computed, as coregistration of brains to an atlas is a common step in many preprocessing pipelines. The second limitation is that BLENDS may not be applicable to situations where random warping may perturb biological information of interest in images, including cases where morphology is directly associated with the prediction target. However, this limitation is inherent to any data augmentation method that relies on random transformations. In the case of BLENDS, this could be partially mitigated by using stratified or separate sets for each class, as was performed with the PD diagnosis application.
Conclusions
These results establish clear evidence to augment neuroimaging data for deep learning when the data are limited. BLENDS demonstrated a substantial performance benefit when applied to two distinct neuroimaging problems encompassing psychiatric and neurological disease. Main advantages to the method include its (1) flexibility in synthesizing full 4D images, (2) computational speed, and (3) ability to produce out-of-sample variations through warp blending. These results support the use of BLENDS for task-based and resting-state fMRI, although future work could investigate applications to other MRI contrasts, including diffusion or dynamic contrast enhanced MRI, where the 4D data are costly and could benefit from augmentation. Consequently, BLENDS is anticipated to be of general interest to the neuroimaging community and especially to researchers looking to improve performance of deep learning on their existing data.
Footnotes
Acknowledgments
We thank Drs. Andrew Jamieson, Jeon Lee, and Jian Zhou for their feedback during the writing of this article.
Data used in the preparation of this article were obtained from the PPMI database. For up-to-date information on the study, PPMI—a public-private partnership—is funded by the Michael J. Fox Foundation for Parkinson's Research and funding partners, including Abbvie, Allergan, Amathus Therapeutics, Avid Radiopharmaceuticals, Biogen, BioLegend, Bristol-Myers Squibb, Celgene, Denali, GE Healthcare, Genentech, GlaxoSmithKline, Golub Capital, Handl Therapeutics, Insitro, Janssen Neuroscience, Lilly, Lundbeck, Merck, Meso Scale Discovery, Pfizer, Piramal, Prevail Therapeutics, Roche, Sanofi Genzyme, Servier, Takeda, Teva, UCB, Verily, and Voyager Therapeutics.
Additional data and biospecimens used in preparation of this article were obtained from the Parkinson's Disease Biomarkers Program (PDBP) Consortium, supported by the National Institute of Neurological Disorders and Stroke at the National Institutes of Health. Investigators are as follows: Roger Albin, Roy Alcalay, Alberto Ascherio, Thomas Beach, Sarah Berman, Bradley Boeve, F. DuBois Bowman, Shu Chen, Alice Chen-Plotkin, William Dauer, Ted Dawson, Paula Desplats, Richard Dewey, Ray Dorsey, Jori Fleisher, Kirk Frey, Douglas Galasko, James Galvin, Dwight German, Steven Gunzler, Lawrence Honig, Xuemei Huang, David Irwin, Kejal Kantarci, Anumantha Kanthasamy, Daniel Kaufer, James Leverenz, Carol Lippa, Irene Litvan, Oscar Lopez, Jian Ma, Lara Mangravite, Karen Marder, Laurie Orzelius, Vladislav Petyuk, Judith Potashkin, Liana Rosenthal, Rachel Saunders-Pullman, Clemens Scherzer, Michael Schwarzschild, Tanya Simuni, Andrew Singleton, David Standaert, Debby Tsuang, David Vaillancourt, David Walt, Andrew West, Cyrus Zabetian, Jing Zhang, and Wenquan Zou.
The PDBP Investigators have not participated in reviewing the data analysis or content of the article.
Authors' Contributions
K.P.N. and A.A.M. conceived the proposed methodology and contributed to experimental design and execution. V.R. contributed to the data processing. A.M., T.C., M.H.T., and R.B.D. contributed to the interpretation and discussion of the results. All authors participated in the writing of the article.
Author Disclosure Statement
Unrelated to this work, R.B.D. is a consultant for Supernus, Acorda and Amneal Pharmaceuticals. M.H.T. has served as an adviser or consultant for Abbott Laboratories, Abdi Ibrahim, Akzo (Organon Pharmaceuticals), Alkermes, AstraZeneca, Axon Advisors, Bristol-Myers Squibb, Cephalon, Cerecor, CME Institute of Physicians, Concert Pharmaceuticals, Eli Lilly, Evotec, Fabre Kramer Pharmaceuticals, Forest Pharmaceuticals, GlaxoSmithKline, Janssen Global Services, Janssen Pharmaceutica Products, Johnson & Johnson PRD, Libby, Lundbeck, Meade Johnson, MedAvante, Medtronic, Merck, Mitsubishi Tanabe Pharma Development America, Naurex, Neuronetics, Otsuka Pharmaceuticals, Pamlab, Parke-Davis Pharmaceuticals, Pfizer, PgxHealth, Phoenix Marketing Solutions, Rexahn Pharmaceuticals, Ridge Diagnostics, Roche Products, Sepracor, Shire Development, Sierra, SK Life and Science, Sunovion, Takeda, Tal Medical/Puretech Venture, Targacept, Transcept, VantagePoint, Vivus, and Wyeth-Ayerst Laboratories; he has received grants or research support from the Agency for Healthcare Research and Quality, Cyberonics, NARSAD, NIDA, and NIMH. All other authors have no conflicts to disclose.
Funding Information
A.A.M. was supported by the National Institutes of Health National Institute on Aging R01AG059288, the King Foundation, the Lyda Hill Foundation, and the UT Southwestern Lyda Hill Department of Bioinformatics. R.B.D. was supported by the Jean Walter Center for Research in Movement Disorders.
Supplementary Material
Supplementary Data
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.