
Abstract
Relationship between the p27Kip1 (here after referred to as p27) V109G polymorphism and cancer risk has been extensively studied; however, results from different studies were not fully consistent. Therefore, we carried out a meta-analysis to comprehensively assess the correlation between the p27V109G polymorphism and the cancer risk. Articles on the relationship of the p27V109G polymorphism with cancer risk were searched from Medline, Pub Med, and Web of science databases. A total of eight eligible studies with 3591 cases and 3799 controls were included in this meta-analysis. Overall, it seemed that the G allele was not associated with the elevated cancer risk (pooled odds ratio [OR]=0.98, 95% confidence interval [CI]: 0.88–1.09, p=0.68, fixed effects). Analyses in different populations revealed that no statistically significant associations between the G allele and cancer risk were demonstrated in Caucasians or Asians. When analyzed in different types of cancer that, from two studies, the G allele was found to be associated with a decreased risk of prostate cancer in a dominant genetic model (pooled OR=0.60, 95% CI=0.36–0.98, p=0.04, fixed effects), but did not alter the breast cancer risk from four studies. In conclusion, this meta-analysis indicated that the p27V109G polymorphism did not correlate with the overall cancer risk in the general population.
Introduction
Aberrant cell cycle control is one of the hallmarks of cancer.
1
The eukaryotic cell cycle progression is driven by cyclin-dependent kinases (CDKs) and negatively regulated by CDK inhibitors (CDKIs).
2,3
In tumor cells, it seen frequently that abnormal function of CDKIs can cause the deregulation of proliferative activity.
4
The p27, a CDKI belonging to the ciprofloxacin/kinase inhibitor protein family, inhibits the CDK2-cyclin E complex and regulates the cell cycle checkpoint at the G1-to-S transition, and it is a putative tumor suppressor.
5,6
While mutations of p27 are frequently found in cancer,
7,8
whether polymorphisms of this protein are associated with cancer risk is also not well understood and remains an interesting question in the field. According to the dbSNP database (
Methods
Identification and eligibility of relevant studies
We searched for relevant studies published in English before October 2011, by using the electronic databases of Medline, Pub Med, and Web of science with the following terms: p27, p27 or CDKN1B, V109G or Val109Gly, cancer, tumor, polymorphism, and risk. References of the retrieved articles were also screened for original studies. We included all the case–control studies that investigated the association between the p27V109G polymorphism and cancer risk with genotyping data. Abstracts, unpublished reports, and articles written in non-English language were not considered. Additionally, when the same case–control case series were used for multiple times in different studies, we only selected the study that included the largest number of individuals.
Data extraction
We extracted the following information from each article: author, year of publication, country of origin, cancer type, ethnicity, genotyping information, genotype method, and source of control groups (population-based, hospital-based, or mixed controls). For studies, including subjects of different ethnicities, data were extracted separately and categorized as Asians, Caucasians, and others.
Statistical analysis
We performed a meta-analysis to estimate the risk (odds ratio [OR]) and 95% confidence interval [95% CI]) of cancer associated with the p27V109G polymorphisms. In addition to the comparison among all subjects, we also performed stratification analyses by ethnicity, cancer type, and source of controls. We investigated the interstudy heterogeneity by using the Cochran's Q-test, 23 and the heterogeneity was considered significant if p<0.05. 24 When p<0.05 of Q-test for heterogeneity, we used a random effects model (DerSimonian Laird), conversely a fixed effects model (Mantel-Haenszel). Inverted funnel plots and the Egger's test were used to examine the influence of publication bias (linear regression analysis). 25 –27 We checked deviation from the Hardy–Weinberg equilibrium (HWE) among controls for each of p27V109G polymorphism by a χ 2 -test, with one degree of freedom. All the p-values were two sided, and all analyses were done in Statistical Analysis System software Stata11.0 and Review Manager 5.0.
Results
Protein structure
Protein, a peptide connection of a long chain of amino acids, can produce specific biological function only in the shape of folding into a specific structure. Therefore, to understand the function of protein, understanding the structure of protein is significantly important. The classic biological means of protein structure determination cannot keep up with the speed of DNA and Gene sequencing prediction and cannot meet the demand of structure prediction on a proteome scale. Therefore, researchers want to shorten the above gap by computer prediction methods. Those prediction methods can help to understand the mechanism of protein folding, and to shorten the design process. As above points, accurate prediction of a protein structure starting from the sequence has become the urgent requirement of people.
The classic means of protein prediction are homology modeling, threading, and ab initio. The core idea of threading is looking for the protein that has the same structure fold type with the targeted sequence, but without significant homologous relation. Threading can make full using of the template library of structure information and sequence–structure comparing calculation to get the most likely alignment. Therefore, threading can get a more accurate prediction than other methods. In this article, we found that the p27V109G polymorphism resulted in an amino acid change from valine (V) to glycine (G) (Fig. 1) by Threading software.
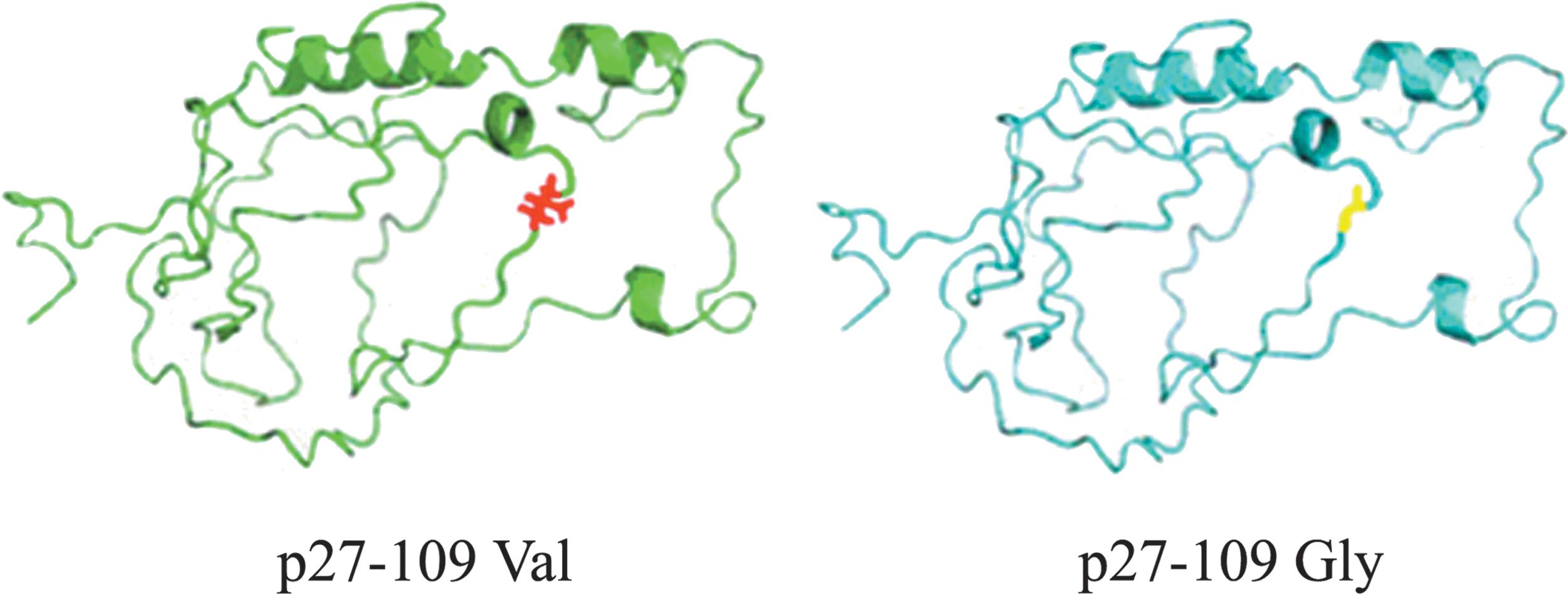
The crystal structures of the wild type and the mutant type with p27V109G. Threading, a popular protein structure-modeling technology, is used to build modeled structures for p27-109 Val (left) and p27-109 Gly (right). The superposition between the native structure of 109 Val (red) and 109 Gly (green) predicted by Threading. Color images available online at
Meta-analyses database
A flowchart of relevant study identification was shown in Figure 2. Briefly, 263 articles were obtained in the primary search. After initial screening, we identified a total of 34 relevant publications. Among these, 11 publications appeared to meet the inclusion criteria and were subjected to a detailed full-text review. 12 –22 We further excluded three publications because they did not provide detailed genotype data of cases and controls. 18,20,22 Therefore, our final data pooling consisted of eight publications (Table 1). 12 –17,19,21 Three of the eight case–control studies were conducted in Caucasians, and the remaining five studies were conducted in Asians. Overall, there were four breast cancer studies, two prostate cancer studies, one pancreatic cancer study, and one oral squamous cell cancer study. Cancers were confirmed histologically or pathologically in all the studies. Of the eight studies, four were population-based, three were hospital-based, and one was with mixed controls. Different genotyping methods were used in these studies, including polymerase chain reaction–restriction fragment length polymorphism in five studies, the 5′-nuclease TaqMan assay in two studies, and Pyrosequencing in one study (Table 1). Information about genotyping methods was missing in one publication. 19 A summary of genotype data was listed in Table 2. Overall, the distribution of genotypes in the controls was consistent with HWE, except for one breast cancer study by Naidu et al. 15

Flow chart for the study selection.
PCR-RFLP, polymerase chain reaction–restriction fragment length polymorphism.
CI, confidence interval; OR, odds ratio; HWE, Hardy–Weinberg equilibrium; N/A, not available.
Quantitative synthesis
The eight studies 12 –17,19,21 included a total of 3591 cases and 3799 controls. When all eligible studies were pooled into the meta-analysis, there was no statistical evidence of an association between the p27V109G polymorphism and the increased cancer risk (homozygote genetic model, GG vs. TT: OR=0.93, 95% CI=0.72–1.20, p=0.59; dominant genetic model, TG+GG vs. TT: OR=0.98, 95% CI=0.88–1.09, p=0.68; recessive genetic model, GG vs. TG+TT: OR=1.19, 95% CI=0.92–1.53, p=0.18) (Fig. 3 and Table 3). Considering that in one study, the genotype frequencies in controls significantly deviated from HWE, 15 whereas in another study, the numbers of each individual genotype were not sufficiently provided 19 ; we did a reanalysis with these two studies excluded, and association between the p27V109G polymorphism and the cancer risk was again not found (homozygote genetic model: OR=1.11, 95% CI=0.85–1.45, p=0.43; dominant genetic model: OR=0.94, 95% CI=0.83–1.06, p=0.29; recessive genetic model: OR=0.97, 95% CI=0.32–2.97, p=0.96, random effect model) (Fig. 4).
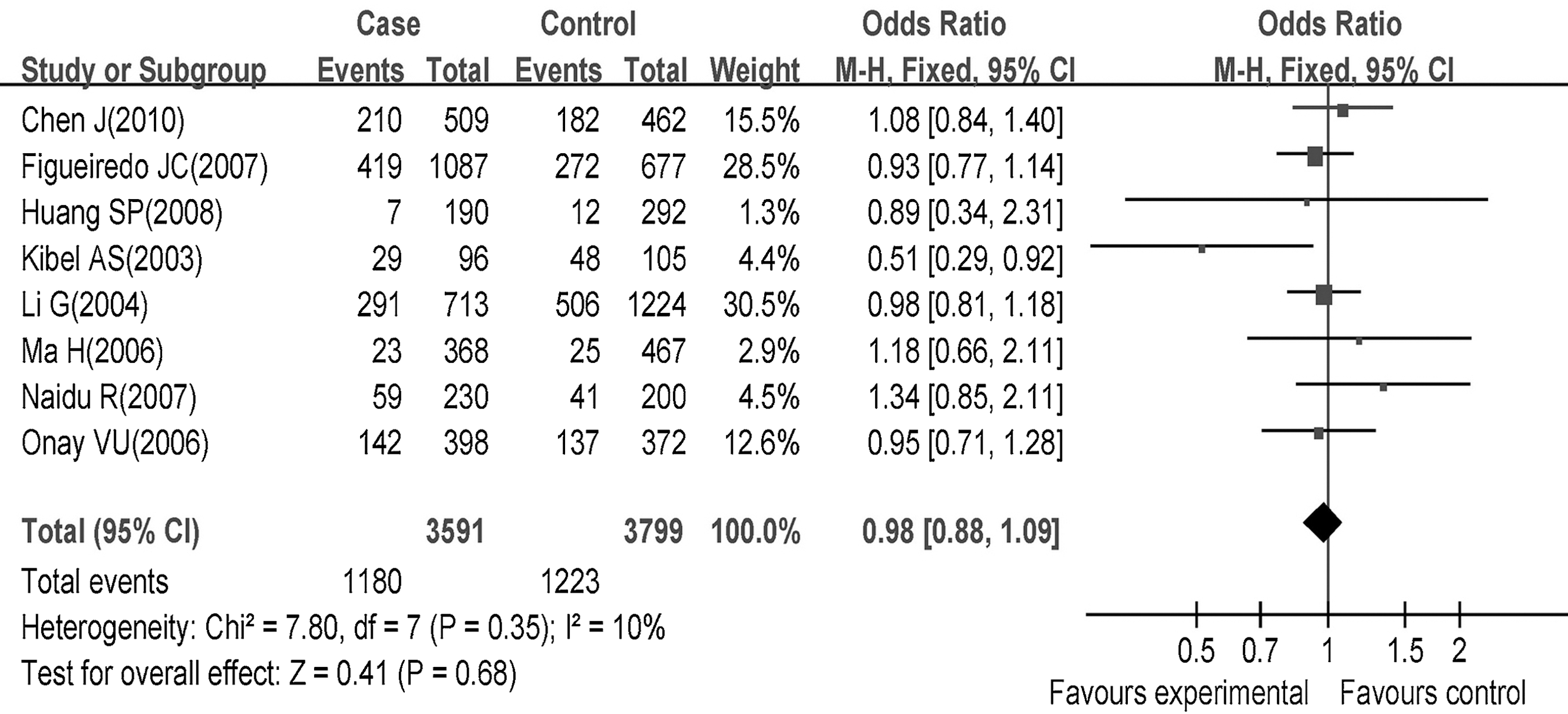
Association of the p27V109G polymorphism with overall cancer risks.

Association of the p27V109G polymorphism with overall cancer risks in a reanalysis (excluded two cases, see text for detail).
In the stratified analysis by a cancer type as shown in Table 3, we found that the p27V109G polymorphism had not significantly increased the risk of breast cancer (homozygote genetic model: OR=1.17, 95% CI=0.81–1.68, p=0.40; dominant genetic model: OR=0.99, 95% CI=0.85–1.15, p=0.90; recessive genetic model: OR=1.19; 95% CI=0.83–1.70; p=0.35). Interestingly, the G allele was found to be associated with a decreased risk of prostate cancer in a dominant genetic model (OR=0.60, 95% CI=0.36–0.98, p=0.04), but not in other genetic models (homozygote genetic model: OR=0.43; 95% CI=0.14–1.32, p=0.14; recessive genetic model: OR=0.52, 95% CI=0.17–1.59, p=0.25) (Fig. 5).
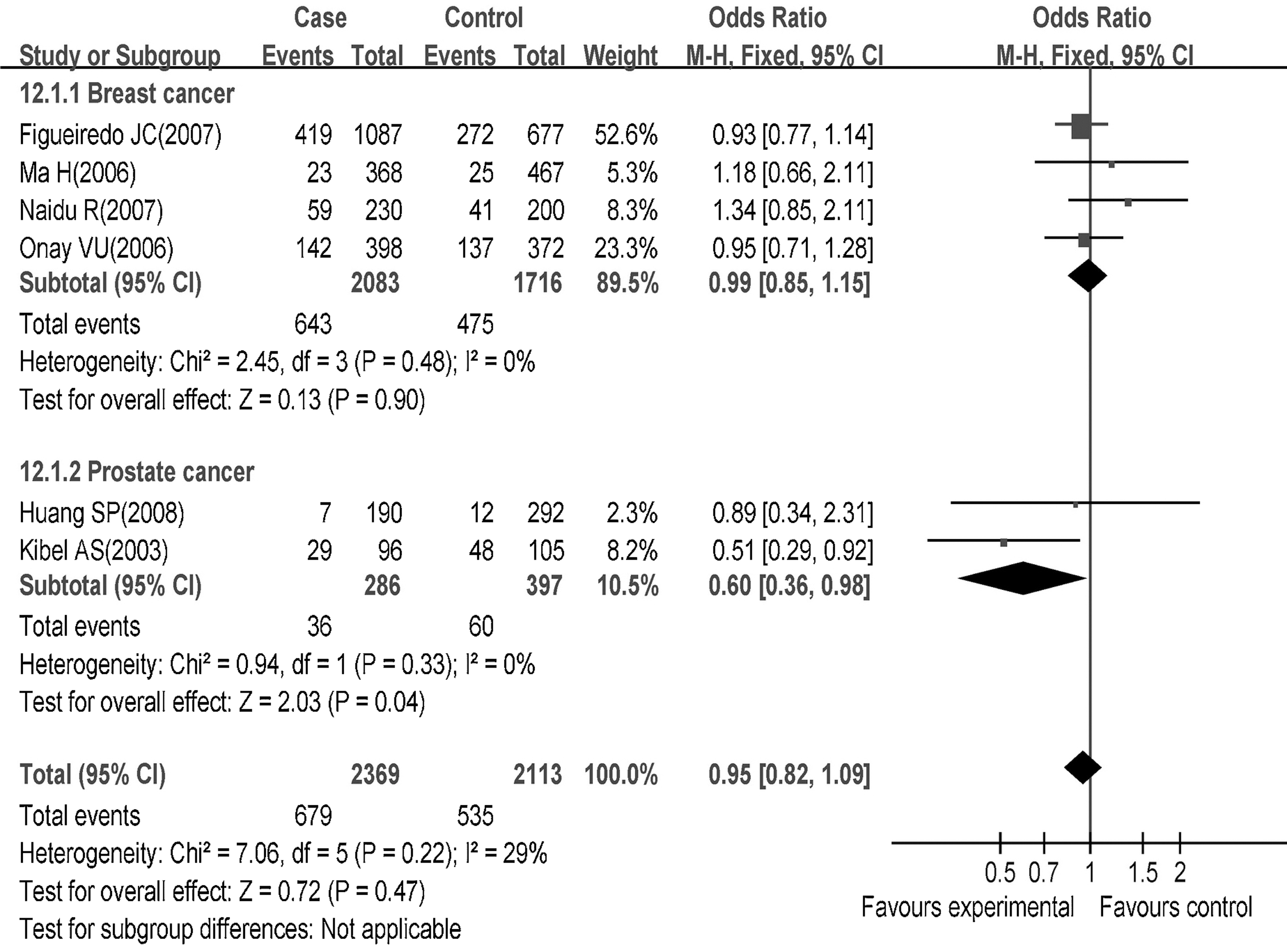
Association of the p27V109G polymorphism with breast cancer and prostate cancer risks.
In terms of subgroup analysis by ethnicity, the p27V109G polymorphism was not found to be associated with the cancer risk in either Caucasians (homozygote genetic model: OR=1.13, 95% CI=0.79–1.63, p=0.50; dominant genetic model: OR=0.97, 95% CI=0.84–1.12, p=0.67; recessive genetic model: OR=1.19, 95% CI=0.83–1.70, p=0.34) or Asians (homozygote genetic model: OR=1.28, 95% CI=0.89–1.83, p=0.19; dominant genetic model: OR=0.99, 95% CI=0.85–1.14, p=0.87; recessive genetic model: OR=1.19, 95% CI=0.83–1.70, p=0.35) (Fig. 6 and Table 3)
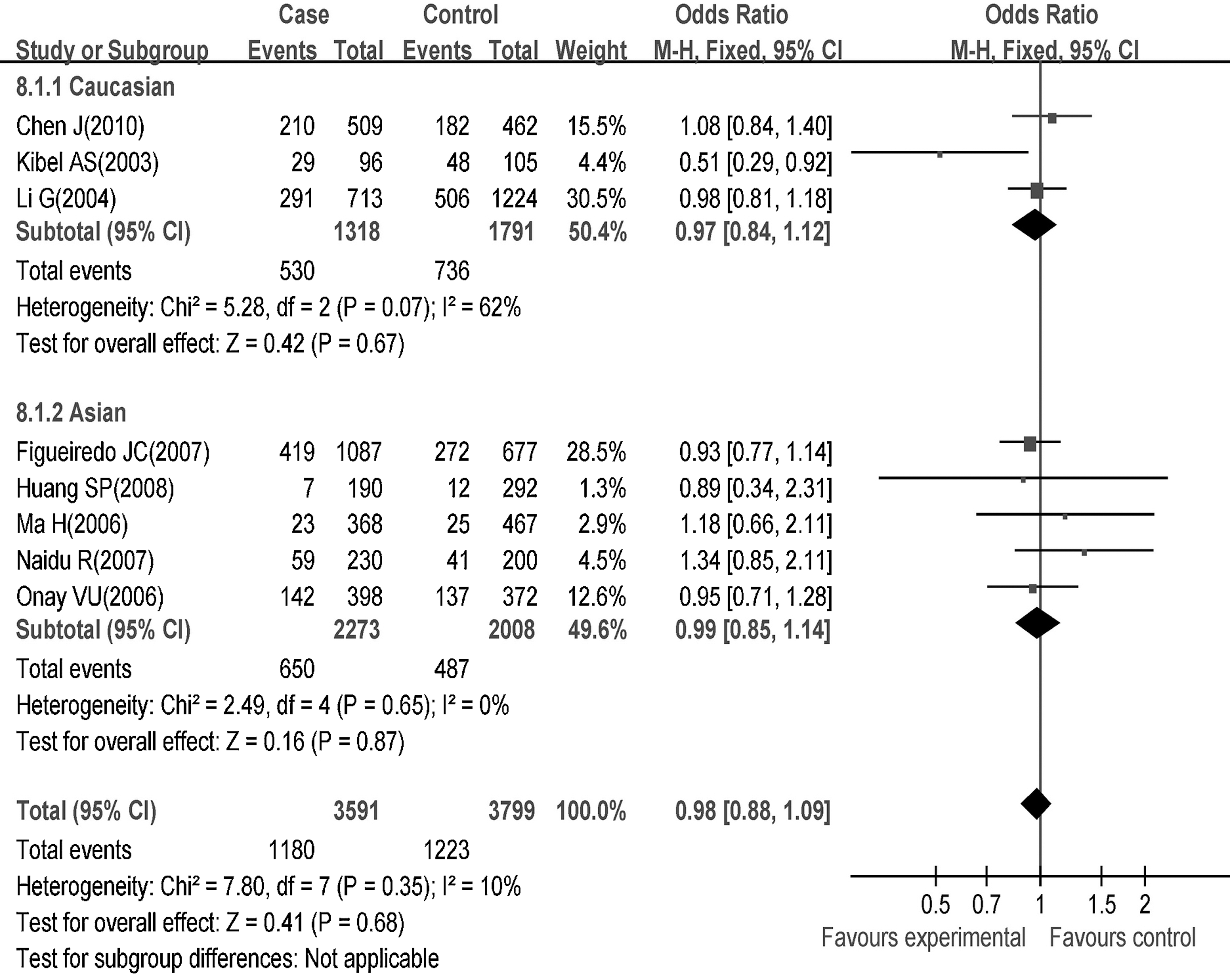
Association of the p27V109G polymorphism with cancer risks in Caucasians and Asians.
For the studies with population-based controls, it was indicated that there was no association between the p27V109G polymorphism and the cancer risk (homozygote genetic model: OR=1.17, 95% CI=0.81–1.68, p=0.40; dominant genetic model: OR=1.00, 95% CI=0.88–1.15, p=0.95; recessive genetic model: OR=1.19, 95% CI=0.83–1.70, p=0.35). This was also true for those studies with hospital-based controls (homozygote genetic model: OR=0.43, 95% CI=0.14–1.32, p=0.14; dominant genetic model: OR=0.79, 95% CI=0.54–1.15, p=0.22; recessive genetic model: OR=0.52, 95% CI=0.17–1.59, p=0.25) (Table 3).
There were no substantial interstudy heterogeneities in the above analyses (Fig. 3). In addition, no publication bias was detected by either the funnel plot (Fig. 7) or the Egger's test (p=0.682).
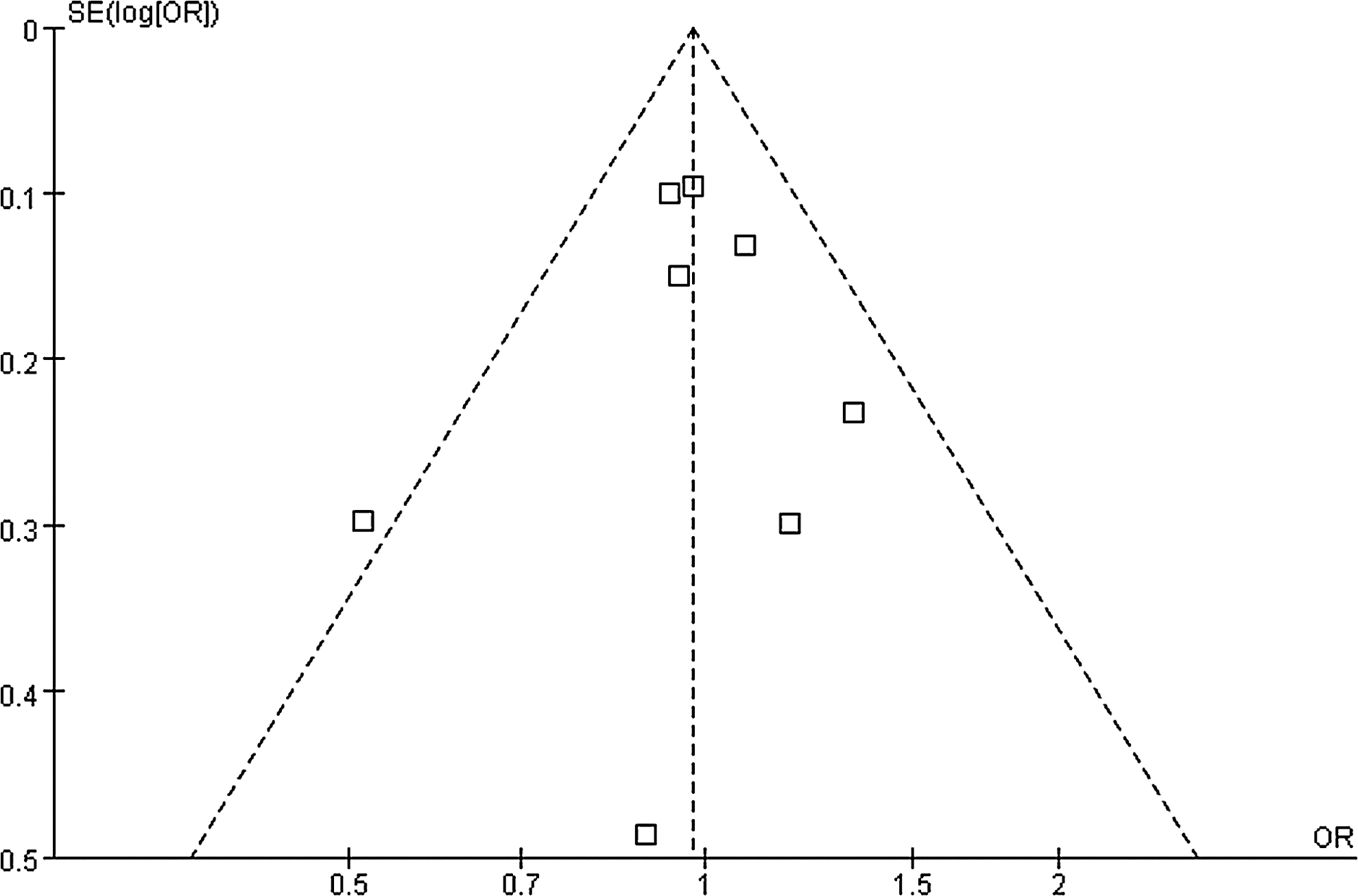
Funnel plot of publication bias analysis for the associations between the polymorphism of p27V109G and cancer risks (TG+GG vs. TT, fixed effect model). OR, odds ratio.
Discussion
To the best of our knowledge, our study is the first available meta-analysis that comprehensively evaluated the associations between the p27V109G polymorphism and the overall cancer risk. With eight case–control studies containing 3591 cases and 3799 controls, we report that the polymorphism of p27V109G was not associated with the cancer risk. Analyses in different cancer types revealed that the p27V109G polymorphism does not associate with the breast cancer risk, but it seemed to be associated with a decreased prostate cancer risk in a dominant genetic model (TG+GG vs. TT). However, the latter one needs to be interpreted with caution for two reasons. First, the sample size used for this analysis is relatively limited (286 cases and 397 controls); second, if the G allele is indeed associated with a decreased prostate cancer risk, one would expect the p-value from a homozygote genetic model-based analysis to be also statistically significant, which was not the case. Collectively, we conclude that the p27V109G polymorphism does not correlate with the overall cancer risk in the general population.
Functional polymorphisms of p27, a putative tumor suppressor, cancer prognostic factor, and a therapeutic target, 28 –30 can influence the expression of protein, and then contribute to the susceptibility and severity of cancer. Several SNPs of p27 have been found, and some of them were confirmed to be correlated with a low level of p27 protein, especially the V109G polymorphism. The p27V109G polymorphism is located at a region that physically interacts with the JAB1. It has been speculated that the p27V109G polymorphism can lead cell cycle to out of control and more cells to transit from the G1 to S phase by enhancing protein degradation of p27 triggered by JAB1, so the p27V109G polymorphism can enhance the tumor genesis and development. The associations between the p27V109G polymorphism and the risk of cancer have been extensively studied, and inconsistent results have been reported. Therefore, we employed a meta-analysis to explore a more precise evaluation for the associations.
Although we are reporting a negative association, it is necessary to point out that a few drawbacks may mask a potential true association. First, we only included studies published in English. Second, populations included in this meta-analysis consisted exclusively of Caucasians and Asians. The distribution of genetic alleles may greatly vary by geography (genetic alleles frequencies of T, G were 0.768, 0.232 and 0.839, 0.161 in Caucasians and Asians populations), so the results of this meta-analysis might be biased. Third, only breast cancer, prostate cancer, pancreatic cancer, and oral squamous cell cancer are included in this meta-analysis, whereas many other types of cancer (lung cancer, gastric cancer, colorectal cancer, etc.) are not, due to availability. Fourth, our results are based on unadjusted OR estimates, because not all studies included in this meta-analysis provided adjusted ORs, and the ORs were not adjusted by the same potential confounders (such as TNM stage, age, sex, and other environmental factors) in those did. Since the susceptibility of cancer is influenced by numerous factors, the adjustments can be very important. Fifth, meta-analysis is a type of retrospective study, and limited by the quality of primary studies.
Overall, our meta-analysis does not support that the p27V109G polymorphism increases the cancer risk. However, future prospective studies with large sample sizes and better study designs are required to confirm our findings.
Footnotes
Acknowledgments
This project is supported by grants from the National Natural Science Foundation of China (81141094, 30870962, to X. Guan), Natural Science Foundation of Jiangsu Province (BK2011656, to X. Guan).
Disclosure Statement
The authors declare that there are no financial or other conflicting interests in the present work.