
Abstract
Abstract
RNA interference (RNAi) can modulate gene expression at post-transcriptional as well as transcriptional levels. Short interfering RNA (siRNA) serves as a trigger for the RNAi gene inhibition mechanism, and therefore is a crucial intermediate step in RNAi. There have been extensive studies to identify the sequence characteristics of potent siRNAs. One such study built a linear model using LASSO (Least Absolute Shrinkage and Selection Operator) to measure the contribution of each siRNA sequence feature. This model is simple and interpretable, but it requires a large number of nonzero weights. We have introduced a novel technique, sparse logistic regression, to build a linear model using single-position specific nucleotide compositions which has the same prediction accuracy of the linear model based on LASSO. The weights in our new model share the same general trend as those in the previous model, but have only 25 nonzero weights out of a total 84 weights, a 54% reduction compared to the previous model. Contrary to the linear model based on LASSO, our model suggests that only a few positions are influential on the efficacy of the siRNA, which are the 5’ and 3’ ends and the seed region of siRNA sequences. We also employed sparse logistic regression to build a linear model using dual-position specific nucleotide compositions, a task LASSO is not able to accomplish well due to its high dimensional nature. Our results demonstrate the superiority of sparse logistic regression as a technique for both feature selection and regression over LASSO in the context of siRNA design.
1. Introduction
U
Researchers have discovered some siRNA sequence characteristics known to contribute to siRNA efficacy (Li and Cha, 2007; Amarzguioui and Prydz, 2004; Holen, 2006). Using Artificial Neural Networks, Huesken et al. (2005) revealed that highly potent siRNAs contain A/U at position 1, A at position 10, and U at position 2. Other motifs which are overrepresented in potent siRNAs and underrepresented in ineffective siRNAs included U at position 7, U at position 11, and C at position 19. Reynolds et al. (2004) formulated eight rules based on experimental evidence that also involve position specific requirements for functional siRNAs. Some machine learning techniques, such as Support Vector Machines and Artificial Neural Networks, can predict siRNA potency with high accuracy, but their results are difficult to interpret (Peek, 2007; Huesken et al., 2005). Biologists need simple guides or rules to help design siRNA of great potency and specificity for use in RNAi experiments. Tibshirani (1996) proposed the LASSO (Least Absolute Shrinkage and Selection Operator) method as a feature selection technique using L1 penalty. This method is attractive since it can shrink coefficients for some of the predictors to exactly zero. Using LASSO linear regression, Vert et al. (2006) proposed a sparse linear model to provide a direct quantitative estimate of siRNA sequence feature's contribution to siRNA efficacy. The main advantages of this model were interpretability and accuracy.
In Frutiger et al. (2008), we used a simplified version of genetic algorithm to build a sparse linear model for siRNA sequence features. Our main idea was to use the Pearson correlation value between the predicted and real efficacy values as the fitness to directly search for better weights than the weights obtained from LASSO as in Vert et al. (2006). In this article, we also built a sparse linear model, but using sparse logistic regression method implemented by Cawley and Talbot (2006).
Shevade and Keerthi (2003) first proposed an algorithm for sparse logistic regression with L1-norm regularization. Their implementation depended on the parameter of L1-norm regularization. To find the best parameter for their regression model, a computationally expensive search based on cross-validation was needed. Cawley and Talbot (2006) made use of the fact that L1-norm regularization problems can be reframed as Bayesian regularization problems so the regularization parameter can be integrated out analytically. Their approach completely eliminated the need for seeking the best parameters
The sparse logistic regression is a technique for regression as well as feature/variable selection. In this article, we decided to explore its dual functions to predict the efficacy of siRNA sequences and to select the siRNA sequence features that are influential on siRNA efficacy. We conducted a numerical analysis on each siRNA sequence feature based on position specific nucleotide compositions and dual-position specific nucleotide compositions. The efficient algorithm of Cawley and Talbot (2006) made it possible for applying the sparse logistic regression to the high (3360) dimensional space data in this study.
2. Methods
In the current study, we used the siRNA data set from Huesken et al. (2005). This data set consists of a total of 2431 randomly selected siRNA sequences targeting 34 mRNA species, assayed through a high-throughput fluorescent reporter gene system. The efficacies of these siRNA sequences had been experimentally determined. The data, referred to as dataset 2431, was split by Huesken et al. (2005) into a training set of 2182 siRNA sequences and a test set of 249 siRNA sequences.
In this article, we will always refer to the nucleotides in the antisense guide strand, with positions in the sequence ordered in the 5' → 3' direction on the guide strand. To encode the single position features of siRNA sequences of length 21, we used a binary feature vector of dimension 84 (4 × 21) that indicates the presence (1) or absence (0) of each nucleotide at each of the 21 positions. To encode dual-position features, we use aibj to represent any combination of the two letters, say a and b, from the alphabet set, A, C, G, and U. Index i is the position for a and j is the position for b, 1 ≤ i ≤ 20, 2 ≤ j ≤ 21, and i < j. Each siRNA sequence of length 21 is then encoded as a binary feature vector of 3360 binary digits ((1 + 2 + 3 + … + 20) × 16 = 3360).
The least squared linear regression method applied to siRNA efficacy regression can be described as follows:
Given a dataset
where
This constraint on α produces a sparse model; i.e., many components of α can be zero. The sparsity of LASSO makes it an ideal technique for feature selection.
Following the idea of LASSO, Shevade and Keerthi (2003) studied the following problem for sparse logistic regression, when
where g(ξ) = log(1 + e
ξ
) which is the negative log-likelihood function associated with the probability model:
The problem in (1) is equivalent to the following unconstrained optimization problem:
Shevade and Keerthi (2003) used a time-consuming cross-validation procedure to find a good value for γ. Cawley and Talbot (2006) used a Bayesian marginalization technique from Buntine and Weigend (1991) and Williams (1995) to transform problem in (2.2) into the following problem, thus eliminating parameter γ
where N is the number of active (nonzero) model parameters
Logistic regression takes input with binary dependent values (y values), so we converted the continuous potency values in dataset 2148 into binary. To this end, we chose the value of 0.45 as our threshold value for high potency or low potency of siRNA sequences. Any siRNA sequence with potency values greater than 0.45 will be assigned + 1, and any siRNA sequence with potency values equal to or less than 0.45 will be assigned −1 in our logistic model.
3. Results
3.1. Biological significance of the weights produced by sparse logistic regression
Our weights, as shown in Figure 1, give a clear, concise, and quantitative picture of all the siRNA sequence single-position features that are influential on siRNA efficacy. They imply that the two ends and the seed region (2–7 positions) of the siRNA sequences are important for functional siRNAs with an apparent emphasis on strict low GC content in the seed region. In the study of the thermodynamic stability profiles for siRNAs, Shabalina (2006) discovered that the Gibbs free energy is always lower from positions 1–7 for effective siRNAs, which is in agreement with our weights from positions 1–7. The accessibility of the siRNA and the target mRNA for hybridization, as measured by folding free energy change, is shown to be significantly correlated with efficacy (Lu and Mathews, 2008). Birmingham (2006) noted that off-target gene silencing is associated with the presence of one or more perfect 3' untranslated region (UTR) matches with the seed region of the antisense strand of the siRNA. These studies proved the significance of the seed region for siRNA efficacy. In contrast to Birmingham (2006), our numerical analysis hints that the relevant seed region of siRNAs may consist of six (positions 2–7) rather than seven nucleotides (positions 2–8).
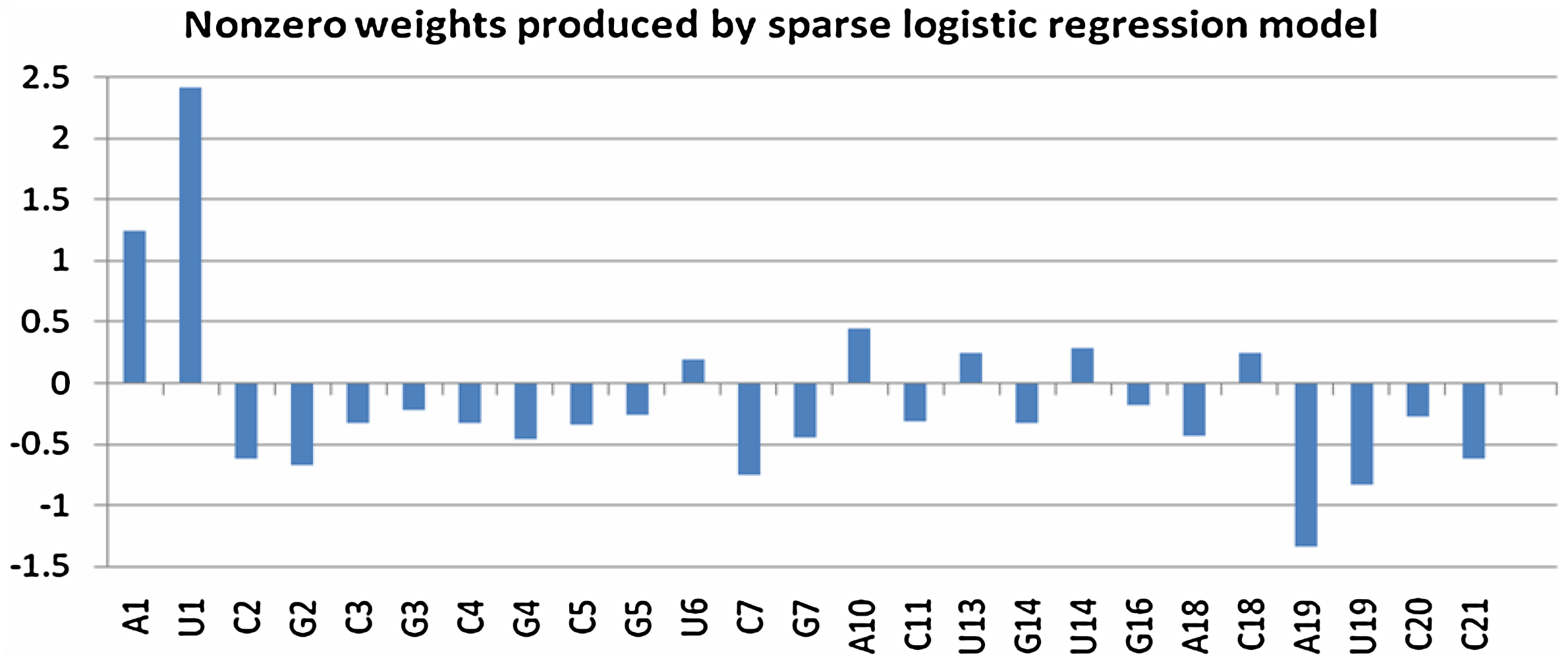
This plot displays only the nonzero weights on single-position specific features of siRNA sequences in the training data of dataset 2147 produced by sparse logistic regression. This plot shows that only a few positions, i.e., the 5’ and 3’ ends and the seed region (2–7 positions), are critical for functional siRNAs. The y-axis represents the weight values.
Furthermore, our weights confirm, as in Ui-Tei (2004), that potent siRNAs should have low GC content at the 5' end and high GC content at the 3' end. Our nonzero weights are all negative on G and C features except for C18 and are all positive on A and U features except for A18, A19, U19, indicating that potent siRNAs should have overall low GC content and, more importantly, the well-known asymmetric requirement of GC content at the two ends (Ui-Tei, 2004). Vert et al. (2006) noticed that the two negative weights on C20 and C21 explain why more accurate models are obtained from adding the two overhangs.
Vert et al. (2006) had the zero weights for the following single-position specific features, a total of 30:
C1, A2, U3, U4, G5, C6, G6, U7, A8, C8, A9, C9, G10, U10, G11, A12, C12, U13, C14, A15, G15, U15, C16, U16, A17, C17, G18, U19, G20, U21
Our weights in Table 1 are all zero for these features except for G5 (weight value −0.2598), U13 (weight value 0.2464), and U19 (weight value −0.8379). These three weights still reflect the need for overall low GC content and high GC content at 3’ end.
Single-position weights measure the importance of each nucleotide in the siRNA sequence. The dual-position weights measure the importance of the presence of two nucleotides in the siRNA sequence. From Table 2, we can see that there is only one feature U3U6, which means U at positions 3 and 6, contributes positively to the siRNA functionality. The top negative features are G1A19, G1U19, C1A19, C1U19, and G1G19, which implies that the two ends of siRNA sequences are important for siRNA functionality. These pairs again show the asymmetric requirement of GC content at the two ends.
The dual-position weights offer new insight into the siRNA functionality. G1 and G19 were weighted zero in single-position weights, but when combined together, they make quite negative contribution to siRNA functionality. A19 and U19 have very negative values in single-position weights, and also have negative values in dual-position weights when combined with C1 and G1. Of the 28 nonzero dual-position weights, there were three negative features, C1C20, G7C21, and C7C21, that involve the two overhangs, which suggests that these overhangs don't play primary roles, but rather secondary roles in siRNA functionality.
3.2. Evaluation of efficacy prediction accuracy of different weights
The linear model based on LASSO has 54 nonzero values out of total 84 weights, while the sparse logistic model has 25 nonzero values, a 54% reduction of nonzero weights. Each weight numerically measures the contribution of each sequence feature.
Peek (2007) tested individual siRNA sequence features for their significance of correlation to siRNA efficacy and listed the t-test values of significance for these features. In this study, we used these t-test values of significance as weights to compare with our weights. A small discrepancy is that these t-test values were calculated using all the sequences in dataset 2148 (see Figure 1 in Peek, 2007), while the weights produced by LASSO and our weights were all based on the 2182 sequences in the training data of dataset 2148 since our primary goal is compare our weights with those produced by LASSO.
To illustrate the differences of the three sets of weights, we plotted them in Figure 2. They share the same general trend, but ours are much sparser than the other two. The numerical values of our weights are also displayed in Table 1.
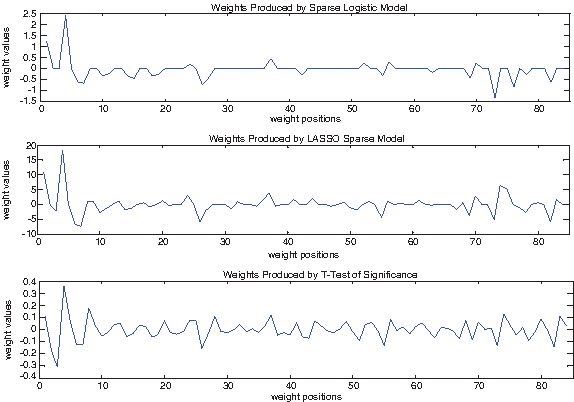
These three plots display the three sets of weights on single-position features of siRNA sequences in dataset 2147 using sparse logistic regression, LASSO, and t-test values of signific ance respectively. The three sets of weights share the same general trend, but our sparse logistic weights are much sparser than the other two.
In order to assess the prediction performance of these weights, we first need to explain how the predictions are made in both models: the linear model and the logistic model.
Under the linear model, the predicted efficacy value of a siRNA sequence xi is obtained with the formula:
and under the logistic model, predicted efficacy value is obtained with the formula:
When tested on the 249 sequences in the test set of dataset 2147, the weights produced by LASSO have Pearson value of 0.6487, under the liner model. Ours have Pearson value of 0.652 under the logistic model and Perason value of 0.6407 under the linear model. The weights based on t-test (Peek, 2007), trained on the whole dataset 2147, have Pearson value of 0.6663 under the linear model.
Our main goal in this section is to fairly compare our weights with those based on LASSO under the same linear model.
To further measure the prediction performance of these three sets of weights, we used another independent set of 579 siRNA sequences of 19 nucleotides in length from Sætrom (2004) referred to as dataset 579.
Under the linear model, when tested on dataset 579, our weights have Pearson value of 0.5053, while weights based on LASSO have Pearson value of 0.5066 and weights based on t-test (Peek 2007) have 0.4725. There might be two reasons for the performance drop. The first reason is that the dataset 579 is independent. The second reason is that dataset 579 has sequences of length 19, i.e., without the two overhangs. As observed in Huesken et al. (2005), the inclusion of the 2 overhang nucleotides improves prediction accuracy.
The weights based on t-test (Peek, 2007) have a high Pearson value partially due to the fact that they were trained on the whole dataset 2147, and showed a lower Pearson value when tested on the independent dataset 579.
Dual-position weights are produced by sparse logistic regression from the training data in dataset 2147 and then tested on the test data of dataset 2147. These weights have 3360 positions and have 28 nonzero values. The weights have Pearson value of 0.5616 under linear model. We applied LASSO to the same training data, and obtained 1953 nonzero weights with Pearson value of 0.2248, which makes these weights infeasible for any practical use. This demonstrates the better performance of sparse logistic regression as a feature selection method than LASSO.
Both Vert et al. (2006) and Peek (2007) studied the predictive power of position independent sequence motifs (N-grams) and showed that the inclusion of these motifs can improve the prediction accuracy, but the primary factor is still position specific nucleotide compositions. In this article, we only explored the position specific features of siRNAs.
3.3. Evaluation of the robustness of different weights under the change of data
In this section, we assess the advantage of our sparse logistic model, which is much sparser than LASSO model, in terms of stability of its numerical calculation. We added dataset 279 to the training data of dataset 2147, restricted to the first 19 nucleotides, and examined how weights in different models respond to this change. Here we use Pearson values to measure the similarity of two sets of weights, not for prediction accuracy. As seen in Figure 3, sparse logistic weights have Pearson value of 0.9226 for the two sets of weights obtained before and after adding dataset 279 to the training data of dataset 2147. The weights based on LASSO have only Pearson value of 0.7024 before and after. They can be easily influenced by change of data, while sparse logistic weights are more resilient to such changes and therefore are more stable.
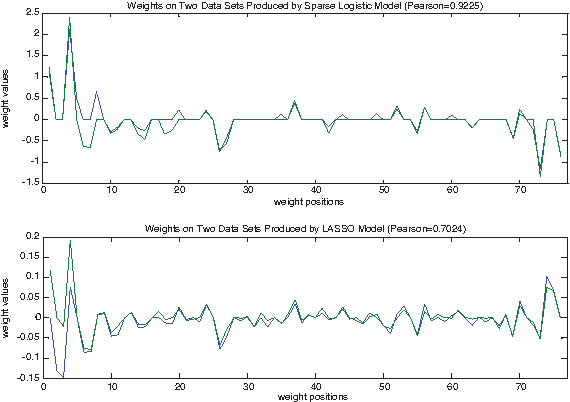
In this experiment, we observed the LASSO weights changed their values at 66 positions out of 76 positions, while sparse logistic weights only changed at 31 positions out of 76 positions. Sparse logistic weights were less perturbed than the LASSO weights.
LASSO weights produced from the training data of dataset 2147 have Pearson value 0.6487 on the test data of dataset 2147. The predictions of LASSO weights trained on the same training set but restricted to the first 19 nucleotides have Pearson value of 0.6251 on the same test data, restricted to the first 19 nucleotides. After adding dataset 249 to the same training set, the new weights based on LASSO have Pearson value 0.6280 on the same test data, increasing the Pearson value by 0.0029. Sparse logistic weights changed their Pearson value from 0.652 to 0.6216 after switching from 21 to 19 nucleotides. After adding dataset 249, the new weights have Pearson value of 0.6404, increased by 0.0153. The sparse logistic weights generalize better than LASSO weights (0.0153 compared to 0.0029).
4. Conclusion
In this article, we tackled the siRNA design problem by utilizing sparse logistic regression technique developed by Cawley and Talbot (2006). Our results suggest that only a few positions, i.e., the 5’ and 3’ ends and the seed region (2–7 positions) of siRNA sequences, are critical for siRNA functionality. Our sparse linear model has a much smaller set of features, compared to LASSO model, for biologists to use when designing potent siRNA sequences. These features better represent the characteristics of effective siRNAs, validated by their efficacy prediction accuracy, robustness to change of data, and consistency with previous findings. Occam's Razor tells us that if two models both can explain the same data equally well, the simpler one is preferred. Our results imply that sparse logistic regression is an effective tool in the study of functional siRNA sequence properties.
Footnotes
Acknowledgments
W.H. thanks Houghton College for providing financial support.
Disclosure Statement
No competing financial interests exist.