
Abstract
Abstract
The Median M-N rule is a feature detection algorithm to detect peptide signals in Liquid Chromatography/Mass Spectrometry (LC/MS) images. As the procedure does not adequately control the statistical errors, we investigate an extension of the Median M-N rule to compute a statistical bound on the false-positive rate. We then study the false-negative rate and provide insights on the types of signal that can be detected by the M-N rule and the limit of detection. The resulting feature detection algorithm, which we term Quantile M-N rule, can be used in most feature detection algorithms to provide statistical control of the false-positive and false-negative rate. Supplementary Material is available at www.liebertonline.com/cmb.
1. Introduction
When the sample enters the mass spectrometer, the molecules are ionised, accelerated and the instrument records the intensity of the resulting ion beam in a range of mass-to-charge values. This first-stage experiment produces mass spectrometry (MS) spectra. However, current technologies are not sufficient to identify all the peptides that are present in a complex sample (Aebersold and Mann, 2003). Peptides (and hence proteins) are usually identified by a subsequent second-stage experiment which breaks the amino acid chain between the residues and produces fragmentation spectra (also called MS/MS or tandem MS spectra) (MacCoss, 2005). Many methods and algorithms for interpreting these fragmentation spectra are available, either de novo (Frank et al., 2007) or starting from a reference database containing the relevant/potential proteins—Sequest (Eng et al., 1994) and Mascot (Perkins et al., 1999). For a review, see Sadygov et al. (2004).
Although the above MS/MS approach is now mainstream and has provided many results, there is interest in analyzing MS spectra. For example, the retention time and mass-to-charge location of a signal may be sufficient to identify the corresponding peptide sequence, as has been demonstrated in the AMT approach by Smith et al. (2002). Due to reproducibility issues, however, this kind of procedure currently relies on high-precision instrumentation and tightly controlled LC elution (Norbeck et al., 2005; Vandenbogaert et al., 2008).
The MS spectra also represent the primary source of quantitative measures (Bantscheff et al., 2007), although alternatives approaches are gaining ground (ITRAQ [Wiese et al., 2007] and MRM [Kitteringham et al., 2008]). Last, but not least, the acquisition of MS/MS spectra is a major bottleneck in high-throughput analyses; not performing the time-consuming MS/MS fragmentation can provide a significant decrease in instrument time.
The present article examines a preprocessing algorithm to enhance the analysis of MS spectra acquired on LC/MS platforms. Prior to identification and quantification, peptide signals need to be extracted from the dataset, (i.e., a list of features of interest needs to be built). This consists of two steps, usually implemented in the same software. First, the LC/MS data is quickly scanned for candidate signals. Then more computationally intensive procedures (“template matching”) are used to precisely quantify diverse characteristics of each feature such as m/z value, retention time, charge state, and area under the curve. For a survey of available methods and software), see Yang et al. (2009).
Current approaches for candidate selection are mostly based on local maxima, either in the measured intensity (Yasui et al., 2003; Tibshirani et al., 2004; Noy and Fasulo, 2007; Kalousis et al., 2005; Mantini et al., 2007; Wang et al., 2006; Yu et al., 2006; Katajamaa and Oresic, 2005) or in the wavelet transform of the signal (Randolph and Yasui, 2006; Lange et al., 2006; Bellew et al., 2006; Tautenhahn et al., 2008; Morris et al., 2005; Noy and Fasulo, 2007). In both cases, local maxima contain high numbers of false positives, and the list of candidates is filtered based on signal-to-noise ratio (Morris et al., 2005; Noy and Fasulo, 2007; Mantini et al., 2007; Wang et al., 2006), peak width (Yu et al., 2006; Katajamaa and Oresic, 2005), or based on the reproducible presence of the peak in adjacent MS spectra (Kalousis et al., 2005; Mantini et al., 2007; Wang et al., 2006). The approach presented by Radulovic et al. (2004), which we will here call Median M-N rule, does not require the candidate to be a local maximum, but focuses on high-intensity peaks that appear in consecutive MS scans.
For accurate determination of the peak characteristics and especially the m/z ratio of the peak centroid, most methods match a template to the observed intensity values. There are several models available for individual peaks, including double Gaussian functions (Kempka et al., 2004; Strittmatter et al., 2003; Leptos et al., 2006), asymmetric Lorentzian or sech functions (Lange et al., 2006), and exponentially modified Gaussian functions (Naish and Hartwell, 1988; Jin et al., 2008; Li, 2002). However, the template approach is best used to match the patterns of peaks created by isotopes (Noy and Fasulo, 2007; Gras et al., 1999; Jaitly et al., 2004).
As indicated by Du et al. (2006), the performance of feature detection directly affects the subsequent processes, such as retention time alignment (Jeffries, 2005), protein identification (Rejtar et al., 2004), and biomarker identification (Li et al., 2005). However, due to the complexity of the signals and multiple sources of noise in MS spectra, high false-positive peak identification rate is a major problem, especially in detecting peaks with low amplitudes (Hilario et al., 2006).
Candidate selection drives the performance of feature detection in terms of sensitivity and selectivity whereas the second step determines the precision of identification and quantification. Among the various possibilities, we evaluate the Median M-N rule (Radulovic et al., 2004) as a candidate selection algorithm because it is computationally efficient and also amenable to statistical analysis. We first show that the original formulation allows a limited level of control of the false-positive rate. To improve upon this, we present an extended M-N rule and compute its statistical properties. We first compute the false-positive rate and propose guidelines to improve the number of true positives. We then demonstrate its application to an experimental data set.
Supplementary Material is available at www.liebertonline.com/cmb.
2. Methods
2.1. Feature detection with the Median M-N rule
Radulovic et al. (2004) present the following feature detection algorithm. A peptide signal is detected by the Median M-N rule if the intensity in N consecutive MS spectra exceeds the threshold M × C where C is 30% of the trimmed mean or the median. The authors claim that the parameters (M = 3, N = 3) can be used in many different contexts with low false-positive rate.
When applying the Median M-N rule, we have observed that the false-positive rate may depend on the m/z value (Fig. 1). This suggests that the false-positive rate in the Median M-N rule is not well controlled. Consequently, the algorithm may provide an unspecified number of undesirable entries in the peak list, which may result in false identifications and wrong biomarkers. We defer the details of the estimation of the false-positive rate to Section 3.4 because it builds on concepts and hypotheses provided in the rest of this section.
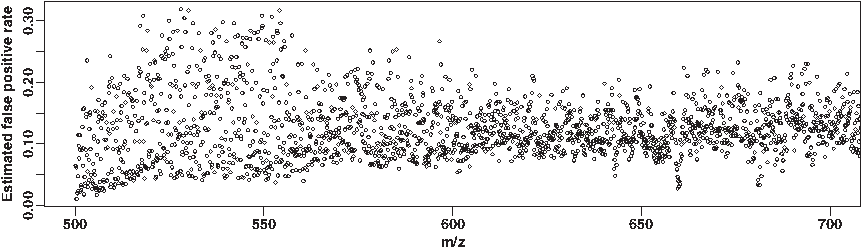
False-positive rate in Radulovic et al. (2004). The data set and the estimation procedure are described in Sections 3.1 and 3.4.
2.2. Extended M-N rule
In this article, we propose the following generalization of the M-N rule. A peptide is detected by the extended M-N rule if the intensity in N consecutive scans exceeds the threshold H. The Median M-N rule in Radulovic et al. (2004) corresponds to using the threshold H = M × C. In Section 2.5, we will present an alternative choice for H, which we call the Quantile M-N rule, and show how it improves the control of the false-positive rate.
In Radulovic et al. (2004), the Median M-N rule adapts to local noise characteristics, although the parameters M and N are fixed for the entire data set. This is because the actual threshold H = M × C is a function of retention time and m/z through the median noise intensity C(t, m). The extended formulation allows H to be an arbitrary function H(t, m) of the position in the LC/MS image.
2.3. LC/MS data model
Computing the statistical properties of the detector requires a model of the signal generated on the LC/MS platform (described in this section) and procedures to estimate the model parameters (described in Section 3.2). We assume that the measured intensity
Both the Median M-N rule and the extended M-N rule only take into account intensity in the same m/z bin; we will therefore drop the variable m and write
As we analyze each m/z bin independently, a model for the m/z separation is not necessary. In the following, we describe the standard model for chromatography elution profiles presented in Snyder et al. (1997) and a model for the background noise process
2.3.1. Elution profile model
In the linear model of chromatography, each peptide produces a Gaussian-shaped elution profile (Snyder et al., 1997; Felinger, 1998). This model has also been used to generate synthetic LC/MS images (Schulz-Trieglaff et al., 2008). We assume that in each m/z bin, the signal
where Γ k (t) is the Gaussian trace of peptide k in the current m/z bin, and the sum iterates over the peptides that have a trace in the bin.
Each Gaussian profile Γ
k
(t) is a positive real function of the chromatography time
where μk is the retention time of peptide k and the parameters σk and Ak represent the standard deviation of the profile and its area under the curve respectively. In particular, in LC/MS experiments, Ak is commonly assumed to be proportional to the concentration of peptide k in the sample.
In the standard model, the physical processes in distillation columns lead to the following relation between retention time and standard deviation:
where P is the plate number of the column. P measures the separation power of the chromatography; the elution profile is tighter (σk smaller) with increased values of P.
The plate number is commonly used to describe other types of columns, including those used in LC/MS experiments. However, the use of solvent gradients may invalidate Equation (1) by modulating the retention of peptides on the LC column (μk) or the degree of separation (σk) during the course of the chromatography. Therefore, we do not use Equation (1) and we expect different possible values for σk.
2.3.2. Background noise model
Most methods dealing with background noise in LC/MS images attempt to remove it from the data using with various mathematical tools: wavelets (Coombes et al., 2005; Zhu et al., 2003a; Qu et al., 2003), Fourier transform (Kast et al., 2003), local noise statistics (Satten et al., 2004; Williams et al., 2005), and time series analysis (Andreev et al., 2003; Liu et al., 2003; Howard et al., 2003; Zhu et al., 2003b; Malyarenko et al., 2005). However, removing background noise is difficult because chemical noise produces patterns that are similar to real signals (Andreev et al., 2003). For example, noise patterns are known to have a 1-Da periodicity similar to isotope patterns (Piening et al., 2006).
To control the false-positive rate in feature detection, we use the a contrario detection approach from image analysis introduced in Desolneux et al. (2000, 2001). This approach is based on detecting image features as exceptional configurations in random images. As such, it requires that the noise characteristics be known a priori or estimated from the image. Several models for the background noise distribution in LC/MS images have previously been proposed (Anderle et al., 2004; Hastings et al., 2002; Wallace et al., 2004; Shin et al., 2007) but are difficult to use in a contrario detection.
Instead of detailed modeling of the background noise, we use few hypotheses so that the approach remains generic. We simply assume that the random noise is an independent process and that all the pixels in the same horizontal line have the same distribution. Consequently, we will write
2.4. Statistical testing framework
Let us define a pamphlet of width N as a series of N intensity values
The models in Section 2.3 describe two different scenarios for the signal intensity in a given pamphlet. We say that the intensity follows the hypothesis H0 when there is no peptide signal in the pamphlet (i.e., the measured intensity corresponds only to chemical or electronic noise). Conversely, the pamphlet follows the hypothesis H1 when some peptide signals contribute to the intensity. This translates more precisely into:
The M-N rule is a statistical test that decides whether a given pamphlet is under H0 or H1. It is iterated over all the possible pamphlets in the LC/MS image. In the following, we compute its false-positive rate, i.e., the probability that the M-N rule detects a signal in a pamphlet under H0, and then a lower bound on its power, i.e., the probability of not detecting a signal under H1. The hypotheses H0 and H1 are complimentary because S(t) is a sum of Gaussian profiles. These are either always strictly positive, or always equal to 0.
The M-N decision rule corresponds to T = N, i.e., we expect that H1 is true when T = N and that H0 is true when T < N. Under H0, T is a binomial random variable with parameters
2.5. Selectivity of the M-N rule.
Given a pamphlet of width N, the false-positive rate α is the probability that T = N, i.e., that the noise exceeds the threshold H in all N consecutive scans. Following the hypothesis that the noise is independent identically distributed, we obtain:
or equivalently
where
By Equation (3), the value for the threshold H in the Quantile M-N rule depends on the number of consecutive scans N. Increasing the value of N yields a lower threshold H (i.e., we can relax the threshold condition while maintaining the same false-positive rate.) This improves the detection of low-abundance signals, but only under certain conditions, as discussed in the next section.
2.6. Sensitivity of the M-N rule
The sensitivity (test power) of the M-N rule is the ability to detect a peptide in a given pamphlet (i.e., it is the probability that T = N under H1). Contrary to the false-positive rate, which only depends on the noise characteristics, the sensitivity also depends on the actual shape of the signals in the pamphlet. A high-intensity signal is easier to detect. In the following, we study the limit of detection as a function of signal shape (i.e., we try to determine the shapes with lowest area that can be detected reliably).
With most noise processes, any shape is detectable with a non-zero probability if the false-negative rate of detection β is unrestricted (potentially small). Consequently, we focus on shapes that are detected with probability at least 1 − β, with β > 0 a user-defined parameter. In the statistical testing framework, this corresponds to shapes for which the test has power or sensitivity above 1 − β. The limit of detection is the lowest area under the curve A (with fixed σ) that can be detected with less than β false negatives. This definition corresponds to the IUPAC recommendations, as stated in Currie (1999).
As described in Section 2.3, we model the elution profile of a signal with a Gaussian function that is characterized by three numbers: the retention time μ, the standard deviation σ, and the area under the curve A. Detectability does not depend on μ because we obtain an equivalent situation by translation, so we suppose from now on that μ = 0. We suppose that there is only a single peptide signal in the sliding window. This corresponds to the following intensity:
With the same notations as in the previous section, we solve
which leads to
or equivalently
The complete derivation of Equations (4) and (5) can be found in the Appendix.
This is a conservative approximation. Peptide signals with area A and standard deviation σ are guaranteed to be detected with a probability greater than 1 − β if Equation (4) is verified. Peptides with lower area can still be detected, albeit with lower probability.
The right-hand side of Equation (5),
Equation (5) leads to the definition of the Signal-to-Noise ratio as
In this expression, the signal intensity is represented by the area under the curve A. This can easily be interpreted because A is proportional to the peptide concentration in LC/MS experiments. The noise intensity is represented by the quantile difference
Several shortcomings of the classical Signal-to-Noise ratio (maximum/standard deviation) are addressed in the new definition. First, the classical expression is derived from an analysis of Gaussian-distributed noise whereas our definition is valid for all noise distributions. Second, the intensity of the signal is represented by the area under the curve, which relates to the peptide concentration better than the maximum of the peak. Finally, the noise intensity is controlled by two quantiles that can be interpreted in terms of false-positive rate and false-negative rate and can be controlled independently. Note that the mean noise intensity does not appear in the Signal-to-Noise ratio. Consequently, baseline removal has no effect in peptide detection.
For a peptide signal to be detected, the corresponding Signal-to-Noise ratio must exceed the threshold F. Conversely, F expresses how well the detector is suited to the shape. Detection is easiest when F is minimal, i.e. when σ = N/2. However, the converse is not true, and given σ, the detector with parameter N/2 may not be optimal. For example, on Figure 2, the detector (H = 4, N = 7) performs best on elution profiles with σ = 3.5. As the dotted line is lower, there exists a different set of parameters that can detect lower-intensity signals.
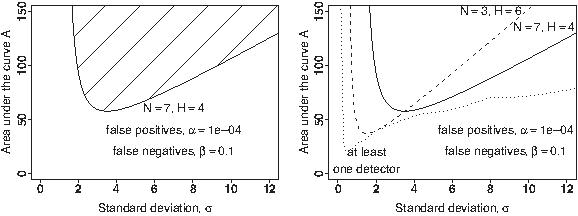
Limit of detection of the M-N rule. The shading lines indicate the set of shapes (A, σ) that a given detector can recall with probability greater than 90% based on Equations (3) and (4).
F does not depend on the noise distribution, but only on the Gaussian shape of the signals. As a consequence, a given detector is suited to a range of shapes that is roughly independent of noise distribution. More precisely, the two quantiles of the noise distribution
To draw Figure 2, we assume that
We observe that no single detector is universal because it is not suited to arbitrarily small values of σ or large values of σ. This motivates the use of several detectors with varying values of N to increase coverage. However, the statistical analysis of combining the sets of detections obtained by different algorithms is again a multiple testing problem and is outside the scope of the present article.
Instead of using Poisson noise as the distribution of
3. Results and Discussion
3.1. Description of the data set
We use the data set published in Klimek et al. (2008). A mix of 18 proteins was prepared and run on several mass spectrometry platforms including different types of instruments and replicates. The complete list of proteins in the standard sample is available, along with the experimental procedures used on each platform.
To evaluate the M-N rule feature detection algorithm, we focus on data acquired on a Q-TOF instrument. The illustrations in this article were generated using the file QT20060926_mix4_19.mzXML from mix4. This instrument has sufficient resolution to distinguish isotope patterns, and the data is acquired in profile mode rather than centroid mode. Note that this dataset contains intensity values that are all integers.
Centroiding is a signal processing algorithm that reduces the complexity and size of the data set. In doing so, it strongly affects MS signals and our binning procedure by shifting the position of data points. Moreover, it affects the background noise distribution by aggregating MS peaks; in particular, we can observe empty noise regions alongside high-intensity peaks in centroided data. This results in a unexpectedly high number of zeroes in the observed noise distribution. Centroiding is usually selected as a default option in manufacturer software and cannot be undone.
3.2. Feature detection
We chose a narrow mass bin width of 0.1 Da, because at that resolution we can observe a 1 Da periodicity in the noise distribution and take it into account in the estimate of the parameter H. The periodicity is related to the background noise being chemical noise (i.e., random fragments of molecules including peptides). At the same time, the QTOF is an instrument with mass precision on the order of 50 ppm and provides many values for summing. Summing has two effects. First, it is a rudimentary smoothing operation that reduces the noise standard deviation with respect to its intensity. Second, due to the Central Limit Theorem, the noise distribution after summing is closer to Gaussian, which reduces quantization effects in the considered dataset and improves the estimation of the noise quantiles.
The empirical quantile provides an estimate of H that is unbiased when there are no peptide signals in the m/z bin, and conservative in the presence of peptides. This is because peptide signals can only increase the quantile
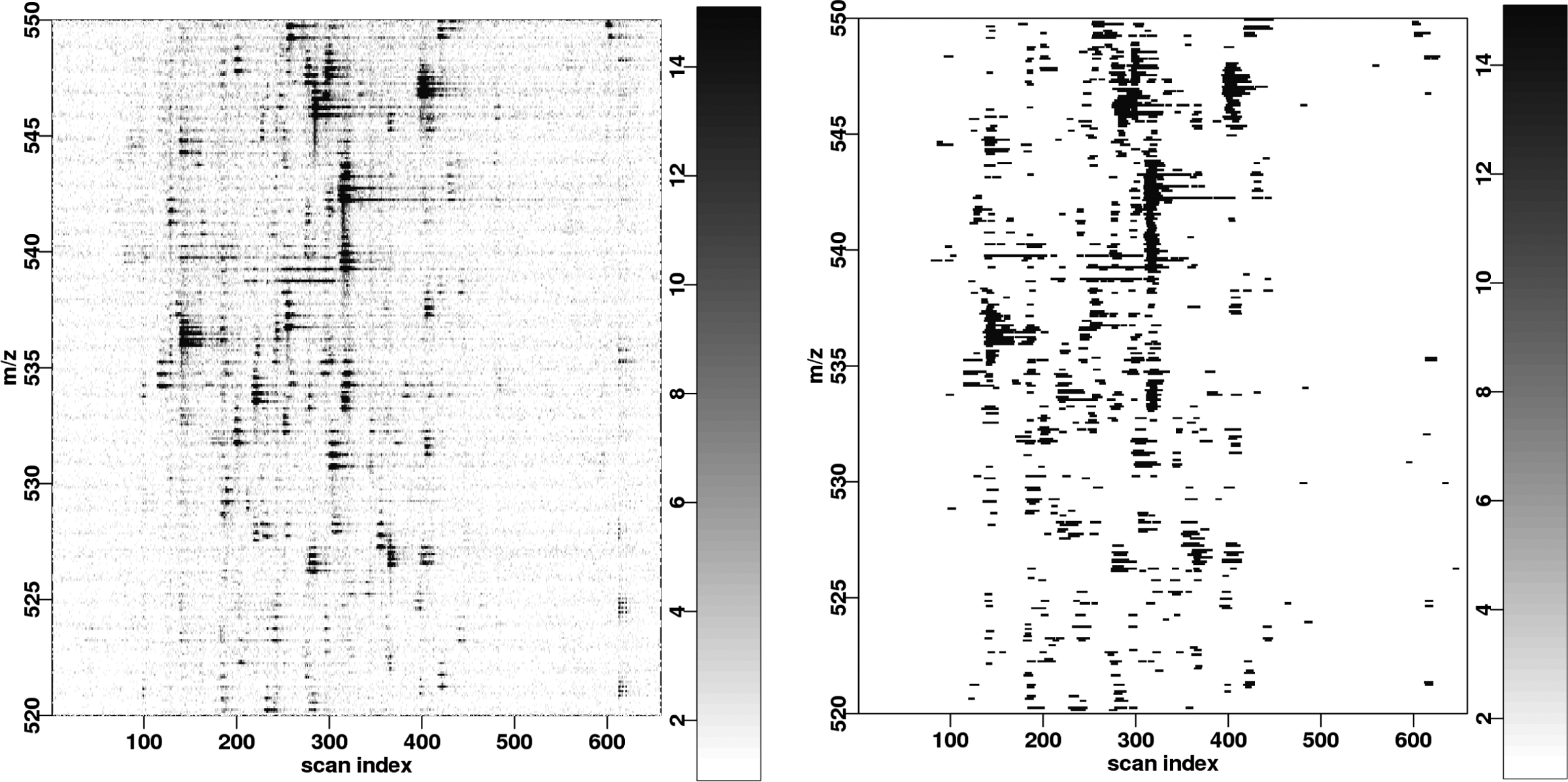
Detection results with N = 7 and
In Figure 4, we show that α effectively controls the false-positive rate by displaying the detection results for several values for α. The user can set the false-positive rate regardless of the noise level and the detector adapts automatically by adjusting the threshold H. With higher false-positive rate, the detector is able to recall lower-intensity signals, which are not significant under stricter constraints. The predicted number of false positives (0.657 when α = 0.001) per line roughly matches the observations.
Detection results with varying false-positive rate
3.3. Adjusting performance to signal shape
As emphasized in Section 2.6, the detector's performance is dependent on the signal shape. In this section, we compare three choices of the detector parameter
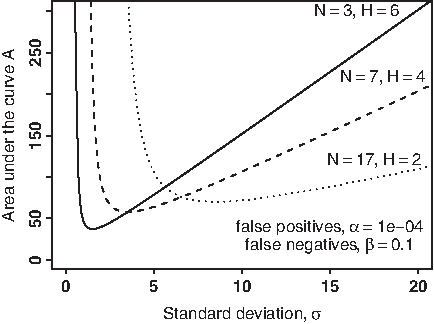
Theoretical detection range.
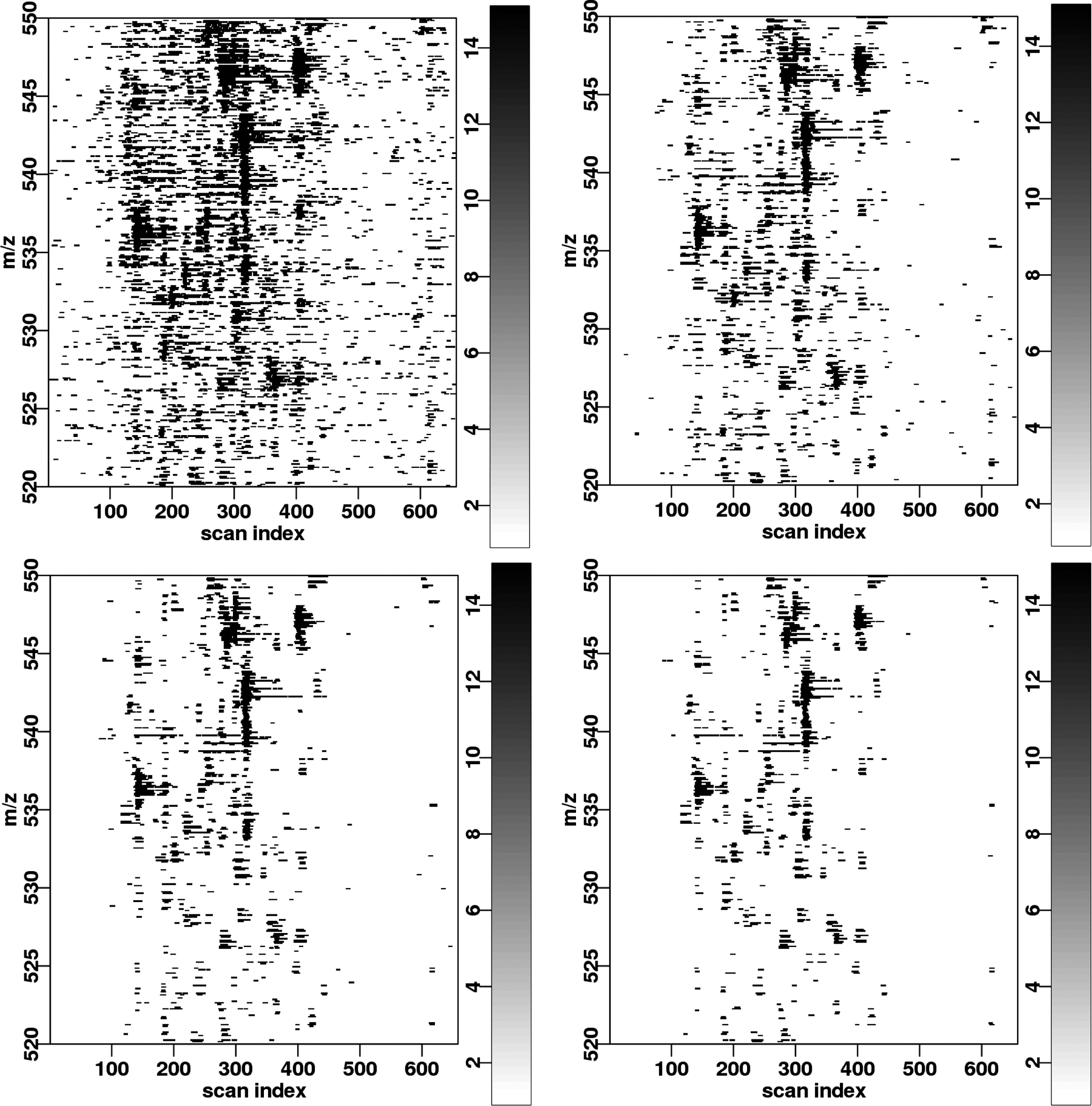
The selected detectors are suited to different ranges of σ. As a consequence, they do not detect the same peptide signals in the LC/MS image as shown in Figure 6. The (N = 3) detector is able to recall an isotopic pattern at (rt = 110, m/z = 707Da) which is missed by the (N = 17) detector. Conversely, the (N = 17) detector is able to recall signals of lower intensity at (rt = 50, m/z = 710Da) and especially the tails of the elution profiles. In this LC/MS image, the (N = 7) detector seems to be a good compromise.

Detection results with length parameter
As indicated in Section 2.6, the M-N rule detector with parameters (N, H) is best suited for detecting Gaussian shapes of standard deviation σ = N/2. For other values of σ, the limit of detection is higher (increased area under the curve A). A reasonable heuristic for choosing N in practice thus consists in setting
3.4. Comparison of the median and quantile M-N rule
In Radulovic et al. (2004), the authors propose using the Median M-N rule with the parameters (N = 3, H = 3*C), where C is 30% of the trimmed mean or the median. In this section, we discuss the advantages and the drawbacks of our proposed extension.
We compare the following two instantiations of the M-N rule:
• Quantile M-N rule with N = 3, • Median M-N rule with N = 3, H = 3 × C where C is the trimmed mean.
Both C and
In the original publication, the Median M-N rule is used after smoothing the intensities. This preprocessing step is not necessary for studying the properties of the M-N rule and is thus left out in the present article. Smoothing can be applied before both algorithms with the following caveat. Smoothing reduces the noise variance, but introduces correlation between adjacent pixel intensities. As the pixel intensities are no longer independent, the false-positive rate computation in Section 2.5 is not valid. Consequently, smoothing may introduce artifacts in the detections for both the median M-N rule and the quantile M-N rule.
As seen in Section 4, the choice H = M × C in the Median M-N rule is not generic. It provides a uniform false-positive rate when the background noise distribution is Gaussian with mean C and standard deviation C, in which case • In the case of baseline variations, the mean background noise intensity is affected but not its standard deviation. If the mean intensity increases, then the median M-N rule becomes too strict. • The next paragraph discusses in detail the case where N(t) is a Poisson random variable. • Figure 7 uses a real dataset.
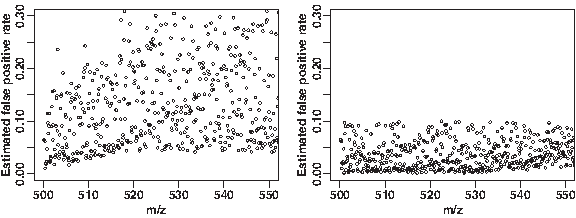
False-positive rate as a function of m/z for the Median M-N rule
Suppose that N(t) is a Poisson random variable with mean C between 5 and 10. We take N = 3 and α = 0.01. We set the remaining parameters for C = 7 which corresponds to a middle scenario between 5 and 10. The quantile M-N rule corresponds to (N = 3, H = 9). The median M-N rule corresponds to (N = 3, H = M × C) and we take M = 9/7 so that both have the same false-positive rate. In the regions of the LC/MS image where the noise intensity is lower, we have C = 5. The corresponding threshold for the quantile M-N rule is
On a real data set, we can illustrate the situation by deriving a theoretical value for the false-positive rate based on the local threshold used by each algorithm. For each algorithm, we compute the threshold H(m) in each mass bin, and use Equation (3) to obtain the predicted false-positive rate. In Figure 7, we observe that the computed false-positive rate for the Median M-N rule is very high and very variable as a function of m/z. On the other hand, the false-positive rate of the Quantile M-N rule obeys the selected bound α. The variations of the false-positive rate are due to quantisation in TOF data.
In Figure 8, we show the detection results obtained by the two algorithms on the same LC/MS image. In particular, we observe a periodic pattern with the original M-N rule that corresponds to the periodic behavior of the noise. This shows that the variations in noise intensity are not properly taken into account in the median M-N rule. A periodic pattern is not discernible in the results of the quantile M-N rule. In both cases, the high-intensity signals are adequately detected.
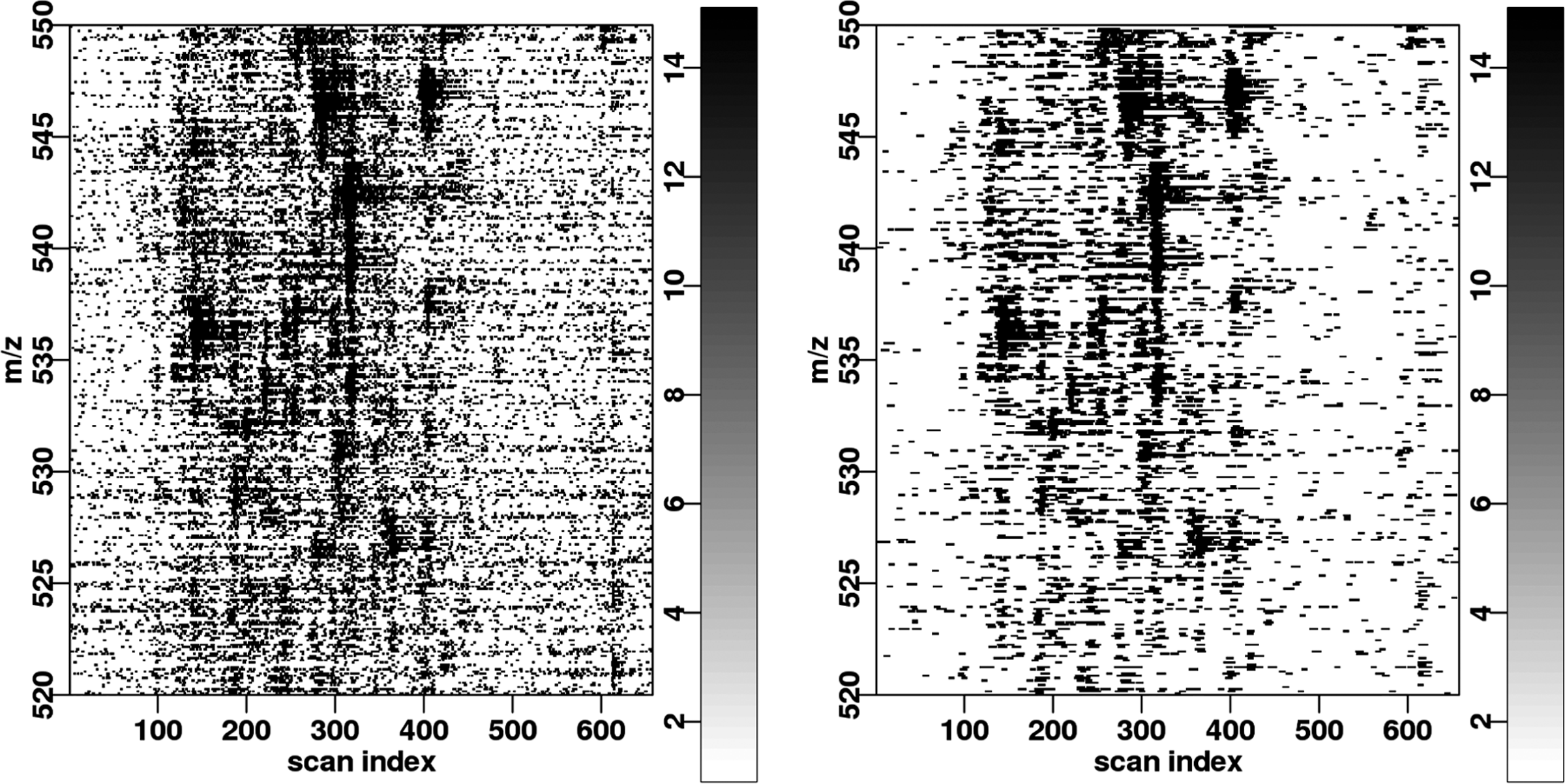
Detection with the Median M-N rule with parameters (N = 3, M = 3) and the Quantile M-N rule with parameters
3.5. Discussion
The feature detection algorithm presented in this paper is generic and can be applied in many contexts. While we use normalized data to facilitate estimation of the noise level and its quantiles, only the hypothesis that noise intensities are independent is compulsory for the bound on the false-positive rate in Equation (4). Likewise, it can be applied to centroided data, although we expect the centroiding to affect the estimation of the noise quantiles. It guarantees a uniform false-positive rate in the LC/MS image, but also between images.
In Section 3.2, we assume that, after cropping, the data is normalised and that the noise component
Independence is a critical assumption, which amounts to the absence of a memory effect between
We analyzed the performance of the detector assuming a Gaussian model for the peak elution profile. Although this seems restrictive, it is useful and easy to interpret in terms of a Signal-to-Noise ratio. Violations of this assumption do not impact the computations in Section 2.5, so the bound on the false-positive rate is still assured, but the false-negative rate may be higher than expected. The detected features are not restricted to Gaussian signals and can address other (e.g., asymmetric) types of signal. (See Figure 9 in Supplementary Material, available at www.liebertonline.com/cmb.) The Signal-to-Noise ratio defined in Equation (5) remains valid under the condition that the elution profile width at height H matches that of a Gaussian function.
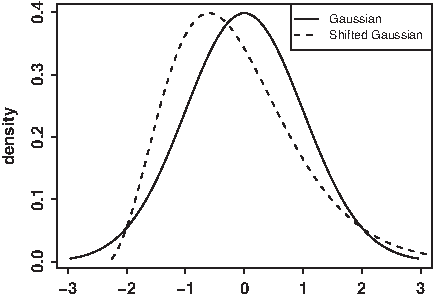
The computations for the specificity of the quantile M-N rule are still valid for non-Gaussian signals that have the same width at any height H. This includes asymmetric signals. The shifted signal in the example was obtained by replacing the x values with x + 0.15x2 − 0.6.
Plots similar to Figure 2 may be used to compare different feature detection algorithms. However, fair comparison is only possible between algorithms with the same false-positive rate.
4. Conclusion
The Median M-N rule is a feature detection algorithm that can effectively recall low-intensity peptide signals in LC/MS images. In this article, we extend the original formulation and provide a precise account of the effect of the new parameters H and N on the detection results. N controls the standard deviation of the elution profiles that can be detected reliably, while H controls the selectivity of the algorithm. We provide guidelines for choosing N for a given LC/MS image and compute H from the local noise distribution. The resulting Quantile M-N rule is guaranteed to yield a false-positive rate bounded by a user-defined parameter α.
Feature detection with the M-N rule does not provide precise values for the signal retention time and m/z ratio. It does not tackle the deconvolution of overlapping features, nor does it take isotope patterns into account. When using the M-N rule, these tasks need to be handled by another algorithm with greater attention to individual pixel intensities in the pamphlet. However, the M-N rule can be used as a filtering step prior to accurate peak picking to provide a statistical control of the false-positive rate.
5. Appendix
Sensitivity of the M-N rule
In this section, we justify our approach to the computation of the sensitivity of the M-N rule. In a horizontal line, the recorded intensity is modeled as:
where
Given a false-positive rate α and the M-N rule parameters H and N, we compute the probability that a Gaussian signal with area under the curve A and standard deviation σ is detected by the M-N rule:
The lower bound is obtained because the Gaussian function Γ(t) is above the value Γ(N/2) in the range
Given the false-negative rate β, we solve the following inequality:
In conclusion we obtain:
Footnotes
Acknowledgments
We thank the anonymous reviewer for very helpful comments. This work was supported by a Ph.D. thesis allowance from the French Ministry of Higher Education and Research.
Disclosure Statement
No competing financial interests exist.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.