
Abstract
Abstract
1. Introduction
1.1. Secondary structure lattice models
These pseudo-2D1 representations can be slightly regularized without much loss of detail by fixing the coordinates on a regular grid, or secondary structure lattice, with a 5Å spacing between β-strands and double between all other SSEs. This regularized simple representation of a protein structure has been shown to be reasonable by the reconstruction of the full protein structure using the SSE-lattice coordinates as a starting point. Proteins up to almost 200 residues have been regenerated from their lattice fold specification resulting in models within 5Å RMSD of the native structure (Taylor et al., 2008, 2009) and additional refinement to main-chain level allows reasonable side-chain positions to be added (MacDonald et al., 2009).
1.2. Exhaustive fold enumeration
The regeneration of protein structrures from their secondary structure lattice specification implies that this very simple representation provides a valid tool to explore the conformational freedom of protein structures at the level of the chain fold. This exploration can be viewed in terms of an abstract fold-space in which distinct folds are embedded with the most similar folds lying adjacent (Orengo et al., 1993; Hou et al., 2003; Taylor, 2007). In this representation, features of the space can be investigated, such as how the number of folds depends on the starting configuration or how interconnected the space is. Two approaches to this exploration are possible: one would be to specify a set of edit and move operations for the SSEs over the lattice similar to those used in residue-level lattice simulations or to use vertex displacement over the discrete space of a polyhedron (Hinds and Levitt, 1992; Luo et al., 1993), and use these to stochastically explore the space starting from known points. Alternatively, since the proteins considered are relatively small and computers are relatively fast, it is possible to exhastively enumerate all possible arrangements of the given SSEs over a lattice.
Previous investigations in this direction have been made with a view to the elimination of secondary structure combinations that are rarely, if ever, seen in known protein structures with the hope that this will improve the chance of predicting a correct tertiary structure (Cohen et al., 1980; Woolfson et al., 1993; Ruczinski et al., 2002; Taylor et al., 2008). Typically, these investigations identified ad hoc “rules” that were valid given the then current range of structures seen in the protein databank. With the less ambiguous registration of strands in a sheet compared to α-helix-packing, most of these studies also focused on β-sheet topology. Although some of the early “rules” appear to remain valid over time, such as the avoidance of “pretzel” topologies (proposed by Cohen et al. and still seen to be avoided by Ruczinski et al. more than 20 years later), the reliability of others, such as the avoidance of cross-over connections (Cheng and Grishin, 2005) and even the hand of connection between strands in the sheet (Sternberg and Thornton, 1977; Hutchinson and Thornton, 1993) have increasing numbers of exceptions.
In this study we focus mainly on the two-layer protein architectures (βα and ββ), with some limited consderation of the three-layer αβα architecture. We do not consider proteins that contain a β-barrel or those with specialist arrangements (such as the β-propellor). It is also beyond the scope of our methods to analyse the all-α proteins as these do not have sufficiently well defined layers, however, polyhedral models may provide a route towards including this class (Murzin and Finkelstein, 1988). Our approach in this study is to accept the ad hoc source of the various topological rules that have accumulated over the years and to test them both singly and in combinations to evaluate their power at reducing the number of possible folds while eliminating as few known folds as possible. In this way, we can then develop a set of fold filters that may have some use in restricting the list of candidate folds for structure prediction or, if embedded in a fold generating function, of only generating folds which have a good chance of being correct.
2. Basic Methods and Preliminary Results
2.1. Protein data
To enumerate protein topologies we need to reduce the three dimensional structure to a string of text that contains the topological information about the connections of the secondary structure layouts. For this we adopted the method outlined in the introduction in which a protein structure is reduced to a simplified coordinate representation based on layers of secondary structures in which secondary structure elements (SSEs) are represented by line-segments in an idealised lattice (called an “Ideal Form”) (Taylor, 2002a). The resulting pseudo-2D representation corresponds directly to topology cartoons in which α-helices are represented by circles and β-strands by a square or triangle (Nagano, 1977; Sternberg and Thornton, 1977; Flores et al., 1994).
Each layer of secondary structures in the Ideal-form is labelled alphabetically, with the top and bottom alpha layers as “A” and “C” respectively and the top and bottom beta layers “B” and “E” respectively (or just “B” if there is only one β-sheet). The first element along the chain to enter each layer is labelled “+0” and the other elements in the layer are labelled relative to this, taking right as the positive direction. The orientation of each element is given by the sign proceeding the letter. See Figure 1 for an example.

Example of reduction from 3D structure (
Matches to the Ideal Forms were generated for all domains in the SCOP40 non-redundant database which is selected to exclude any pair of proteins with more than 40 percent sequence identity (Murzin et al., 1995). Of the 9,479 domains in the set 7,117 were found to have at least one form match. Matches were sorted by a score based on the packing between elements, endpoint RMSDs and a density term dependent on local structure (more fully described in [Taylor, 2002b]) and the best scoring form hit for each domain was retained. In total there were matches to 5,543 unique domains by three-layer forms and 1,600 to four-layer forms. No topology strings were generated for barrel forms. Since the relationship between form matches and domains can be many-to-one all matches were retained.
Each topology string resulting from an ideal form match was used to generate a series of subtopologies by deletion from the termini of the string (which are the same as the sequence termini), using the requirements of compactness and good packing to ensure that the deletions would not generate gaps in sheets or delete strands on either side of a helix without also deleting the helix. The strings generated were (typographically) rotated to ensure that no duplications or ambiguities were possible by ensuring that the first strand is in layer ‘B’ position 0 and the first helix is in layer ‘A’ position 0, (except where there were four strands, in which case the alpha-layering was defined by the position relative to the two beta layers). These rules are sufficient to resolve ambiguities except where there is only a single sheet, in which case the additional requirement was made that the second strand must be to the right of the first.
A program was written using the Perl module Math::Combinatorics to find all the possible topological structures a protein could adopt for each of several secondary structure layouts comprising: βββ – βββ, ββββ – ββββ, α – ββββ, αα – ββββ and ααα – ββββ (where a dash separates the number of SSEs in each of two layers). When calculating all possible topologies it was important to take account of symmetry in each layout to avoid double counting identical folds. The number of structures for each secondary structure layout are given in Table 1.
2.2. Topological filters
There are many rules which have been identified over the years which describe the way in which secondary structure elements can connect and pack with each other. Our aim is to encode and apply these rules to our unconstrained topologies (the full set). From the literature, we identified three main general filters that apply to the local configuration of a few SSEs:
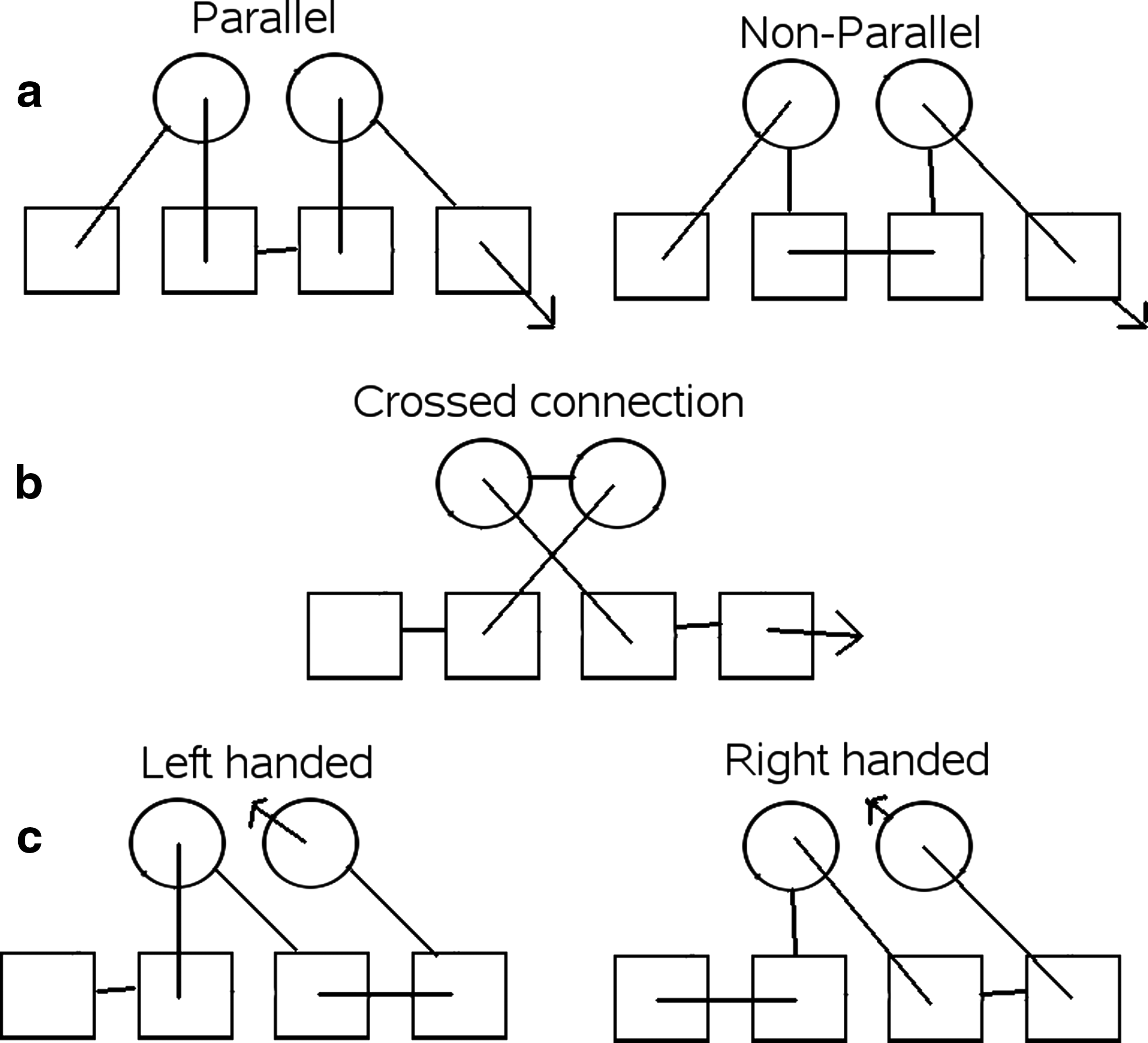
Structure examples.
We eliminated folds with any of these undesirable characteristics for the αα – ββββ and the ββββ – ββββ secondary structure layouts initially. Removing strings with these characteristics from the full set of topologies yields a 99.9% reduction in the number of allowed folds for the ββββ – ββββ string and 98.8% for αα – ββββ. (Table 2).
3. Results and Discussion
3.1. Filtering known structures
The large reductions in the number of topologies caused by applying the filters are only useful if they do not eliminate a significant proportion of known topologies. For this reason, we tested the filters on topology strings taken from Protein Data Bank (PDB) structures (Taylor et al., 2009). (Data included as Supplementary Material; see online at www.liebertonline.com)
For the ββββ – ββββ string 81.5% were eliminated and for the αα – ββββ string, only 90.0% were eliminated (Table 2). While large, these are lower percentages than those seen for the full set and confirms that loop crossing, left handed and parallel connections are quite unfavorable.
Examination of the known folds that failed to pass the filters revealed that many had parallel connections. Despite a clear bias for non-parallel connections (Table 3), this “preference” is not strong enough to justify the elimination of all structures with parallel connections. For example if we make the simple assumption that the connections are distributed randomly throughout the structures then by considering a binomial distribution we would expect to see at least one parallel connection in each structure for all the secondary structure layouts we are considering.
The basic filters tested here have previously been evaluated by others (Finkelstein and Ptitsyn, 1987; Woolfson et al., 1993), with similar conclusions being drawn. However, a loss rate of 80–90% of valid folds would be quite unacceptable in a realistic structure prediction exercise and a less strict filtering strategy is clearly required.
3.2. Additional and revised filters
Taking a closer look at the structures with parallel connections revealed that the parallel connections mostly occur on the edge of the structure. For the ββββ – ββββ derived folds, only 22.6% have parallel connections not on an edge and 26.1% for αα – ββββ. This motivated us to change the filter that removes all structures with parallel connections to one that distinguishes between parallel on the edge and parallel connections through the middle of the structure.
Parallel connections within the same β-sheet can be left or right handed (Richardson, 1976). However, our topological model is unable to establish the handedness of these connection as it does not specify whether the connection will go above or below the sheet. To overcome this limitation we assumed that all parallel beta sheet connections are right handed. This assumption allows us to apply the clash filter defined by Ruczinski et al. (2002), which eliminates structures where parallel beta connections cross over. This filter is different from the previously mentioned crossover filter as the connections bridge ends of the same layer rather than different layers.
The “pretzel” is a filter used by Cohen et al. (1982), which eliminates structures based on the order in which the β-strands are connected within a sheet. If i,j,k,l are sequential strands in a sheet, then the filter eliminates structures where the strands occur in the following orders k,i,l,j and j,l,i,k. Another filter which is related to the “pretzel” filter eliminates structures where the connections between secondary structure elements in the same layer crossover (Ruczinski et al., 2002), we call this filter the “layer crossover.”
Another filter we tested checks the connections between elements in the same layers that jump over other SSEs (Woolfson et al., 1993; Ruczinski et al., 2002). Woolfson also mentions several filters that apply to beta sandwich structures (Woolfson et al., 1993), which can in principle be extended to αβ structures.
These revised and additional filters are itemized below specifying the configuration that they eliminate, along with the one or two letter memnonic that will be used to refer to them. Some are illustrated in Figure 3.

Examples of topological filters described in the text are depicted on a two-layer αβ layout. Each filter is identified by a code that corresponds to the list of filters in the text.
3.3. Evaluation of the individual filters
Figure 4 displays several graphs illustrating how well each filter performs when measured by the relative numbers of known folds that pass the filters and the number eliminated from the full set.
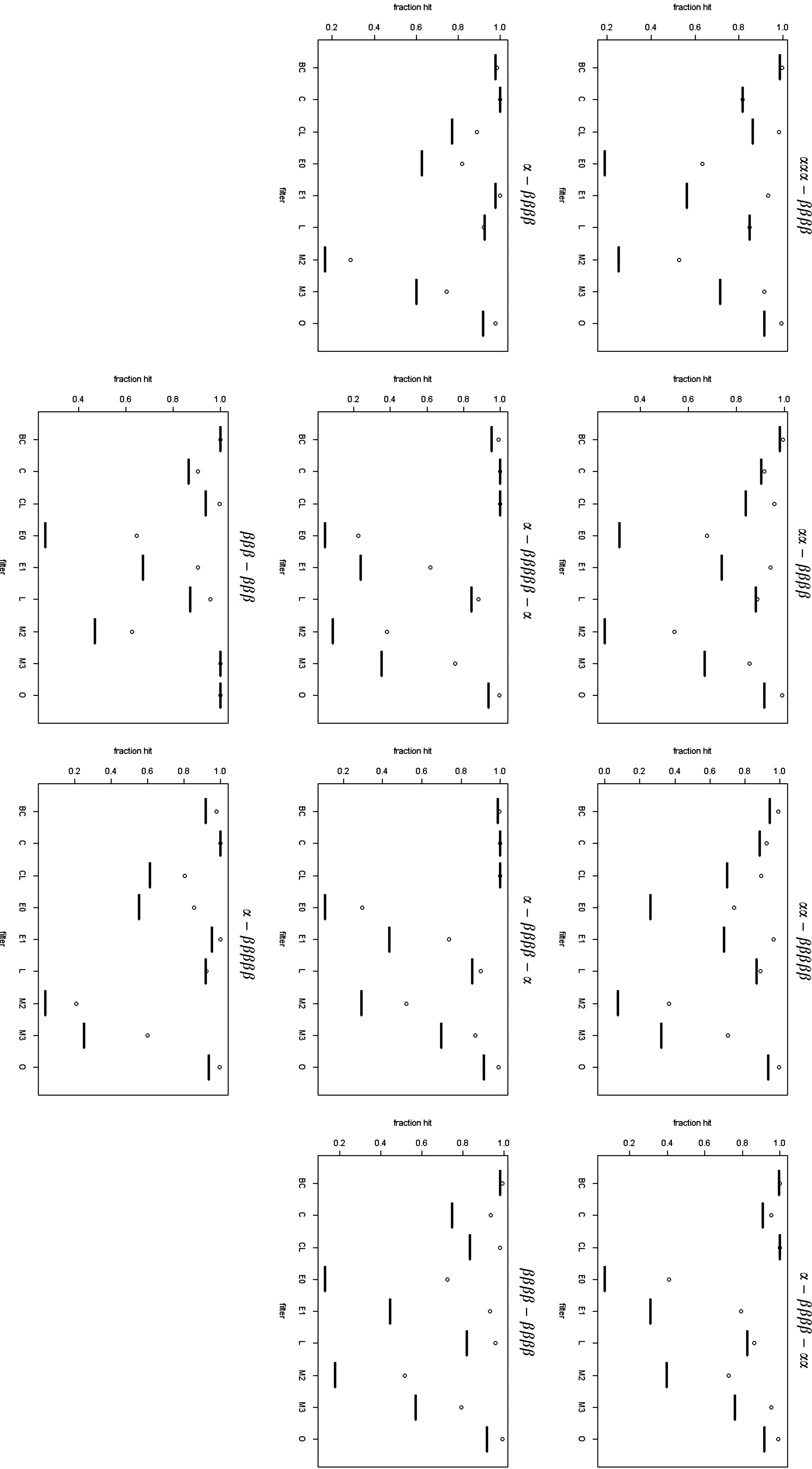
For each secondary structure layout the black bar represents the proportion of the full set remaining after the filter and the white dot represents the proportion of the known structures remaining after the filter. Key to filters: O, pretzel; CL, clash; BC, beta crossover; C, crossver; M, jump; E, non-edge parallel connection; L, left-handed connection.
3.4. Evaluation of filter combinations
In the structure prediction process, it would be useful to have a method (or mathematical model) that selects topologies based on the filters. However, before such a method can be realized we need to decide which filters should be used. Applying the parallel connection filter (see Section 2) to the full set and the known structures would appear to increase the probability of a random topology occuring in the known structures, but the 80–90% decrease in known structures caused by this filter is an unacceptable loss. To overcome this problem, we will introduce a limiting probability for each layout which is determined using the mutual information. Levels for filters considered are shown in Table 4.
There are some dependencies between the filters, Layer crossover and Pretzel for example. However, if interaction terms are added to the model they have very little effect on the probabilities generated and were therefore omitted for simplicity.
3.4.1. Setting a limiting probability by mutual information
Mutual information, I, is a measure of the similarity between two probability distributions (X, Y), quantifying the extent to which knowing the value of one variable reduces our uncertainty about the value of another. It takes values from 0 (independence) to H(X), H being the entropy of one of the distributions, which must be identical where I is maximum. This can be used to measure the overall power of a set of topology filters by considering how application of the filter reduces our uncertainty of whether a random topology picked from a generated set will be found in nature (or our sample of it). Intuitively, the mutual information measures the difference between the affect a filter has on the full set and the affect it has on the known structures.
We calculate the mutual information by considering two quantities: Pp - the probability that a random topology from a particular set is found in the PDB, P j - the probability that a random topology from a particular set will be removed by the filter.
These can be used to define four quantities:
P1: The probability that a random topology is known and removed, P
p
× P
f
(FP) P2: The probability that a random topology is known and not removed, P
p
× (1 − P
f
) (TN) P3: The probability that a random topology is unknown and removed, (1 − P
p
) × P
f
(TP) P4: The probability that a random topology is unknown and not removed, (1 − P
p
) × (1 − P
f
) (FN)
The mutual information for these probabilities is then calculated to determine how far they deviate from independence. As indicated, these could also be thought of as false positives (FP), true negatives (TN), true positives (TP) and false negatives (FN), respectively, although in a strict sense this only applies if we believe our sampling of natural topologies to be complete. Since the power of the filters and the chance of finding a topology vary according to the layout of secondary structures the set in consideration is all possible topologies for a particular secondary structure layout, e.g. two three-stranded sheets.
To find the mutual information for a filter combination applied to a particular SSE layout the set of all topologies for this layout is generated. The filters are applied and the four values P1–4 above can be found by simple enumeration. The probabilities of knowing a topology (P5) and filtering a random topology (P7) and their complements (P6, P8) are then found by summation of the relevant values (e.g. P5 = P1 + P2). The mutual information is then the sum of P j log2Pi minus the sum of Pj log2 Pj for i = 1–4 and j = 5–8. This gives us a single number which expresses the effect of the filter on both the known and unknown topologies.
In applying a filter we are most interested in maximising the probability that a topology from the set passing the filter will be found in the PDB (Pp). Unfortunately this cannot be considered in isolation since a filter which removed all but one structure, that structure being found in the PDB, would appear perfect by this measure and yet would not be very useful since it would remove almost all known structures as well. The mutual information allows us to circumvent this problem if we consider the relationship with Pp: if the size of the known set is constant (i.e. we do not filter any known structures) then as Pp increases so must I. If we hold Pp constant and reduce I then we must be removing known structures since the entropy of the set (hence its size) is decreasing. Thus the maximum Pp we can have without removing structures is the Pp corresponding to maximum I. All combinations of filters that have a higher Pp and a lower I must be discarding more known structures.
As outlined above, the mutual information was calculated using the formula:
where i = 1, 2 and j = 1, 2 i refers to whether or not a random structure is removed by the filter and j refers to whether or not a random structure is in the known structures. For example, P12 is the probability that a random structure is in the known structures, and it would not have been removed by the filter. Pi = ∑ j Pij and Pj = ∑ i Pij. The mutual information is always positive, however, it the filter reduces the known structure hits by a larger percentage than it reduces the full set then we think of it as having negative information and therefore assign a negative value to the mutual information.
When the mutual information is plotted against the probability that a random structure occurs in the PDB, we see a clear maximum in the mutual information. (See supplementary material for a full set of filter combinations). The probability that achieves this maximum will be taken to be the limiting probability. The filters which return probabilities greater than the limiting one generally reduce the known structures by too much. For example, the parallel connection filter from section 2 is one such filter. All sets of filters which give probabilities greater than the limiting probability will be disallowed.
Supplementary Figure 1 shows the mutual information plotted against the probability that a random structure picked from a given subset of the full set, defined by a set of filters, occurs in the PDB. In each case, we see a clear maximum in the mutual information. The probability that achieves this maximum will be taken to be the limiting probability. The filters which return probabilities greater than the limiting one generally reduce the known structures by too much. For example, the parallel connection filter from Section 2 is one such filter. All sets of filters which give probabilities greater than the limiting probability will be disallowed.
3.5. Fitting a model to the probability a known fold
3.5.1. The model
We used standard general linear model theory (implemented in the “
where
The model defines a probability that a given string will be found in the PDB by finding parameters for the logit function using the observed probability that a string chosen randomly from the subset of possible topologies defined by the filter combination for a given layout will be found in the PDB.
3.5.2. Analysis of the model
Figure 5 shows the results for the above model fitted to the αα – ββββ, αα – ββββ – α and βββ – βββ layouts. We see that the αα – ββββ and αα – ββββ – α layouts seem to have better fits than the βββ – βββ layout, this is probably due to a large proportion of the filters not affecting the βββ – βββ layout. Consistently, in the two layouts relevant to the layer crossover filter, the corresponding coefficient is estimated to be relatively small. This supports our earlier observation that the layer crossover filter provides little information. For the αα – ββββ layout, the model fits very well; by comparing the residual deviance to the relevent χ2 distribution, we found that our model would not be rejected. The fit is not so good for the βββ – βββ and αα – ββββ – α layouts, but we still see a strong positive correlation in Figure 6. The weaker fit is explained by not all the filters applying to the βββ – βββ and αα – ββββ – α layouts. Finally, the reason that the probabilities for each set of filters seems to be very small is because for a set of plausable topologies only a small number are realized in the known structures, this could be because these structures are yet to be discovered (Taylor et al., 2009) or because there are some subtle filters yet to be identified.

True probabilities plotted against the fitted values obtained by the binomial model.

Probabilities of belonging to the PDB for ideal folds. Those with a known folds are plotted in orange and novel folds in yellow.
3.5.3. Generalizing the model
Ideally, we would like a model that is applicable to all secondary structure layouts. This is a difficult goal to realize because when the secondary structure layouts get large, the number of known structures hits gets much smaller and the number of possible topologies gets much larger. This rules out the option of generating a random sample of topologies as they would almost certainly be unrepresentative. Table 5 shows the correlation coefficients for the fitted models plotted against all the other secondary structure layouts. From this, it can be seen that the models roughly generalize to the other secondary structure layouts. The most general model appears to be the one fitted to the ααββββ layout. It also appears that the αβββββ layout does not fit any of the models very well, this could be explained by it not being a well-packed structure. Therefore we can conclude that applying any one of our fitted model to any topology will give a rough idea of how probable it is for a given fold to be present in the PDB. The coefficients in Equation 4 for the three discussed models are given in Table 6.
Each coefficient (α and β) correspond to those included in the linear model expressed in Equation 4. In each of the layouts, the following terms have all been absorbed into the intercept term and so have zero coefficients:
3.6. Application to ideal folds
Combinatorical methods similar to those described here have previously been used to generate a vide variety of plausible protein folds (Taylor et al., 2009). These were comapred to known folds from PDB, and matches were found to only 10% of the generated models. The remainder were referred to as “novel folds,” or by analogy with unexplained cosomological matter, “dark folds.” To test the degree to which these novel folds conform to the probabilistic models developed in this work, we applied the two more relevant linear models based on the two-layer αβ and the three-layer αβα layouts (Table 6) to their topologies. The results, shown graphically in Figure 6, were compared to the 10% of artificial models that had a corresponding fold in the PDB. This indicated that the “dark folds” are just as likely to be belong to the PDB, indeed slightly more likely, than those that have a fold that exists in the PDB. Examples of topologies with the highest and lowest probabilities from each set are shown in Figure 7.
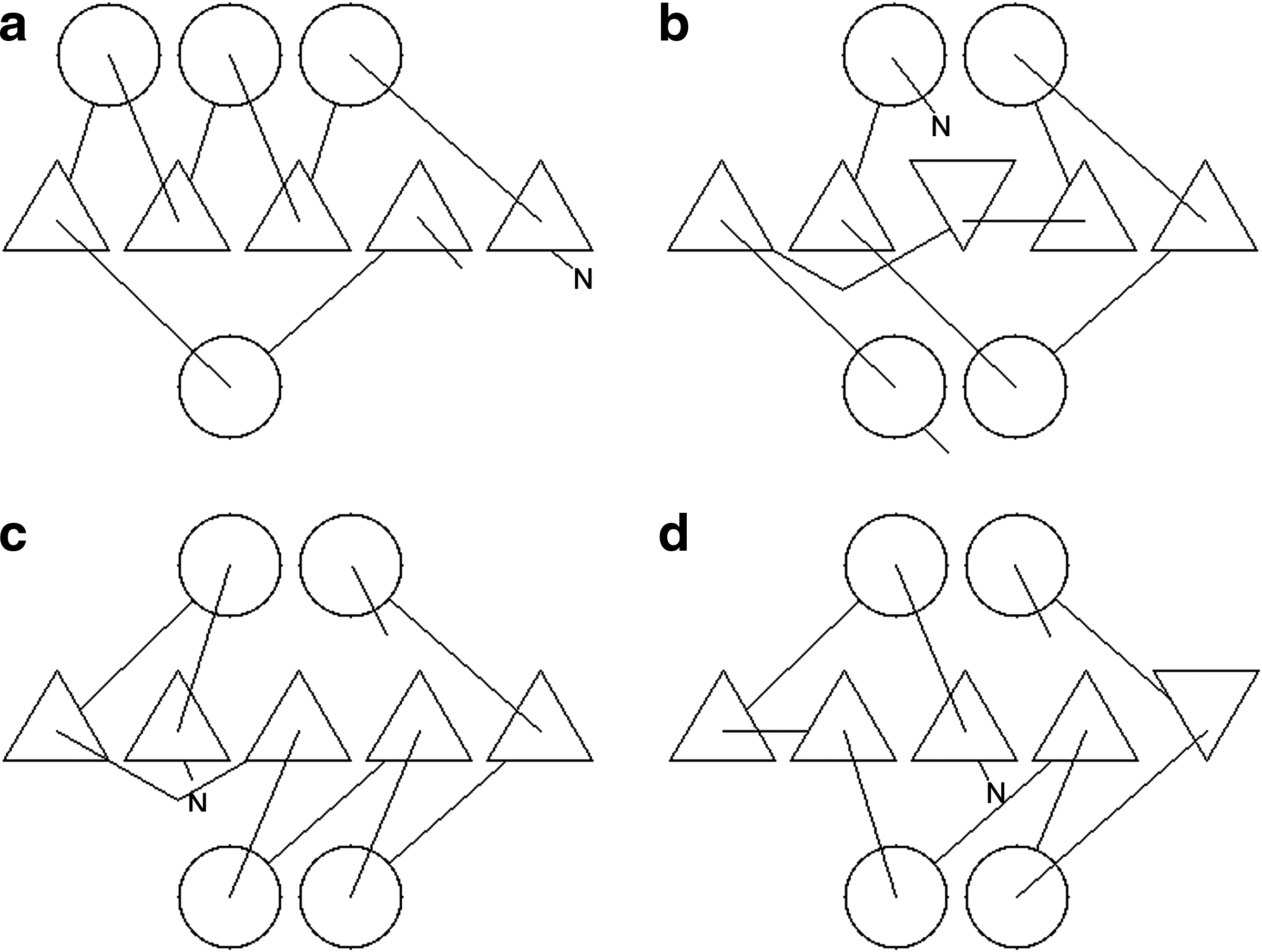
Most
4. Conclusion
In this work, we have shown that some of the accepted “rules” of protein topology that have been used over many years remain largely valid, while others lost discriminative power as increasing numbers of exceptions have been found. Those that remain are typically more complex, such as the “no-pretzel” rule, while the simpler rules (such as “no loop crossovers” or “no left-hand connections”) now have more violations.
Using these given rules, we fitted a general linear model to generate probabilities that could be used to assess known structures and others generated by structure prediction methods that included a large sample of folds not observed in the PDB. We found that most of these novel folds were equally likely under our model as those with known folds, indicating that their absence from the observed repertoire is not the result of any obvious bias in their construction.
Footnotes
Acknowledgments
The work was supported by the MRC National Institute for Medical Research, UK (U117581331). Inge Jonassen, James MacDonald and Jotun Hein are thanked for valuable discussion and comments.
Disclosure Statement
No competing financial interests exist.
1
They are not a true 2D representation as the information about whether the connections between SSEs pass over or under each other is retained.
2
To understand from a thermodynamic viewpoint why non-parallel structures are favorable we must look at the free energy of the structure and the fact that structures with low free energy are favorable [Finkelstein & Ptitsyn, 1987]. Using the “persistent chain model” [Flory, ![]() ] we see that the free energy of the connection is:
] we see that the free energy of the connection is:
where R is the gas constant, T is the absolute temperature, a is the persistent length, ![]() ]. This gives us considerable reason to favor non-parallel connections.
]. This gives us considerable reason to favor non-parallel connections.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.