
Abstract
Abstract
Rooted, leaf-labeled trees are used in biology to represent hierarchical relationships of various entities, most notably the evolutionary history of molecules and organisms. Rooted Subtree Prune and Regraft (rSPR) operation is a tree rearrangement operation that is used to transform a tree into another tree that has the same set of leaf labels. The minimum number of rSPR operations that transform one tree into another is denoted by drSPR and gives a measure of dissimilarity between the trees, which can be used to compare trees obtained by different approaches, or, in the context of phylogenetic analysis, to detect horizontal gene transfer events by finding incongruences between trees of different evolving characters. The problem of computing the exact drSPR measure is NP-hard, and most algorithms resort to finding sequences of rSPR operations that are sufficient for transforming one tree into another, thereby giving upper bound heuristics for the distance. In this article, we present an O(n4) recursive algorithm D-Clust that gives both lower bound and upper bound heuristics for the distance between trees with n shared leaves and also gives a sequence of operations that transforms one tree into another. Our experiments on simulated pairs of trees containing up to 100 leaves showed that the two bounds are almost equal for small distances, thereby giving the nearly-precise actual value, and that the upper bound tends to be close to the upper bounds given by other approaches for all pairs of trees.
1. Introduction
The subtree prune and regraft (SPR) distance is a well-known tree distance measure that has been applied for comparison of biological trees, especially for finding differences between phylogenetic trees, for example, when the accuracy of tree inference method is compared to a standard solution or when phylogenies of different characters are compared to find the amount of disagreement between topologies; this disagreement can be the evidence of bias of the data or of unusual evolutionary events, such as hybridization or horizontal gene transfer (Hein, 1990; Wang et al., 2001; Song and Hein, 2005; Baroni et al., 2005). When applied to rooted trees, the distance takes the form of a rooted Subtree Prune and Regraft (rSPR) operation, which is a rearrangement that detaches a subtree from the tree and attaches it on another branch of the tree (see below for the formal definition). The rooted SPR measure, drSPR between two trees which have the same set of leaf labels is the minimum number of rSPR operations that transform one tree into another. In the case of phylogenetic trees, the sequence of transforming operations can be used to identify the lineages involved in horizontal gene transfer (Than et al., 2008).
The problem of computing the drSPR distance was shown in Bordewich and Semple (2004) to be a NP-hard. They also proved that the problem is fixed parameter tractable with respect to the unknown distance k, (i.e.) there is an algorithm whose computational complexity is (56 k) p(n), where p(n) is a polynomial in n, the number of leaves shared between the trees. Heuristic algorithms to compute the drSPR distance between trees include upper bound finding algorithms, namely LatTrans (Hallett and Lagergren, 2001), HorizStory (MacLeod et al., 2005), EEEP (Beiko and Hamilton, 2006), TNT (Goloboff, 2007), and the RIATA-HGT (Nakhleh et al., 2005) algorithm in the Phylonet software (Than et al., 2008). All of them provide sequences of rSPR operations that transform one tree into another, and thereby give upper bounds for the measure. Another class of algorithms, such as SPRDist (Wu, 2009) and SPRIT (Hill et al., 2010) give the exact distance between the trees. SPRDist employs an integer programming approach that uses the connection between the maximum agreement forest (MAF) (Hein et al., 1996) and the drSPR distance. Although finding the drSPR distance using this approach is also NP-hard, it has been shown that SPRDist runs efficiently for trees with 40 or fewer leaves and for tree pairs with small drSPR values. However, the algorithm does not provide the set of rSPR operations for the transformation. The most recent algorithm SPRIT uses an exhaustive method and utilizes a conjecture to reduce the search space, to provide the exact distance and the minimum number of transforming operations.
In this work, we provide a new algorithm D-Clust that gives both an upper bound and a lower bound for the drSPR distance for a pair of trees that share leaf labels, as well as the sequence of operations that transforms one tree into another and whose number of operations is equal to the upper bound. We examined the accuracy of D-Clust on the simulated trees with known drSPR and found that its upper bound is very close to that given by the other algorithms. Moreover, for the small values of drSPR and large values of n, i.e., the situation mimicking the low level of horizontal gene transfer between genomes, the lower bound is efficiently computed by D-Clust and tends to be the same as the upper bound, thus providing the actual distance.
2. Methods
2.1. Definitions
We denote the set of all binary trees with a given set X as B(X). Throughout the paper, let the cardinality of X be denoted as n. For the upcoming discussions, let
Descendant and ancestor of a vertex in T
Let u, v be two vertices in T. We say that v is a descendant of u if the path from the root to v contains u, and an ancestor of u if the path from the root to u contains v.
Subtrees of a tree rooted at a vertex
We call the induced subgraph of T that contains the vertex v of T and all its descendants, as the subtree of T rooted at v and denote it by Sv (Fig. 1).

In the tree T, C : = {a, b, c} is the set of all label descendants of the vertex 1, and hence it is a cluster in T. The subgraph S1 of T inside the triangle is the subtree of T rooted at the vertex 1. Also note that S1 = T|C.
Clusters in a tree
A cluster C in T is the subset of X such that C is a set of all label descendants of a vertex in T (Fig. 1). We call the cluster X and all the singleton clusters as trivial clusters in T, and the remaining clusters as non-trivial. We denote the set of all non-trivial clusters in T as C(T). Note that the tree topology of T can be revealed by listing all the clusters in T.
Subtree of a tree induced by a leaf set
Suppose Y is a subset of X. Let
SPR operation on a tree
Let e = (u, v) be an edge in T such that v is a descendant of u. A rooted SPR operation (rSPR) on the binary tree T is performed by first removing the edge e that results in a graph with two components, one of which is Sv (the subtree rooted at v), and T − Sv; and then performing one of the two steps:
(i) replace an edge e = (a, b) in T − Sv by the edges (a, u′) and (u′, b), where u′ is a new vertex, and add the edge (u′, v), thus connecting Sv and T − Sv, or (ii) add a dummy leaf with label “r” incident at the root of T − Sv, add an edge between r and v and let r be the root of the new tree.
The resulting tree is also a rooted binary tree with n leaves and the subtree Sv is called the rSPR subtree. We also refer to a rSPR subtree by the subtree T|C, where C is the set of all leaves of Sv. See Figure 2 for an illustration of two rSPR operations—the first using the step (ii) and the second using the step (i)—performed on a tree.
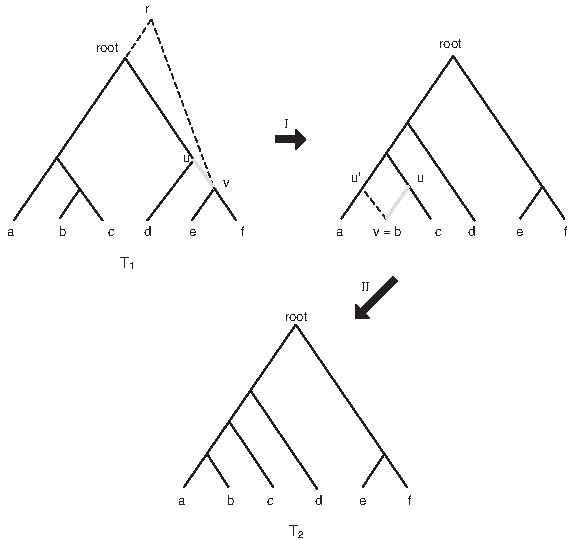
The tree T1 undergoes two rSPR operations and is transformed into the tree T2; the drSPR(T1, T2) = 2. The edges that are removed in the operations are showed in thick grey lines and the edges that are added are shown in dotted lines. In the first operation (I), the subtree restricted to {e, f} is the rSPR subtree and in the second (II), the subtree restricted to {b} is the rSPR subtree.
The drSPR distance
For trees T1 and
Common and differing clusters between trees
For
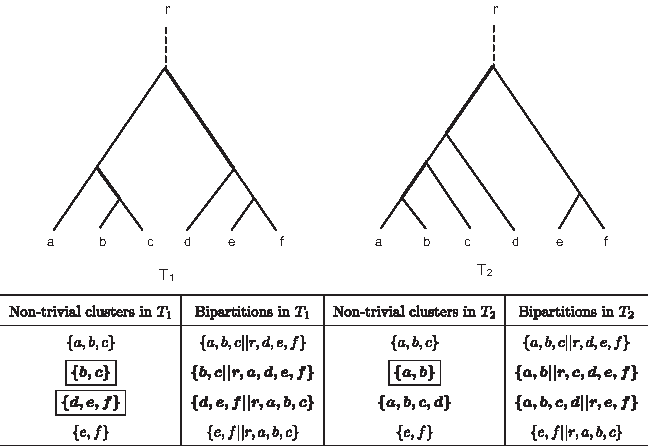
Two trees T1 and T2 with the same set of six leaf labels a − f. The non-trivial clusters of T1 and T2 are shown in the table. The clusters {a, b, c} and {e, f} are the same in both trees. All other non-trivial clusters are the (T1, T2)-differing clusters and (T2, T1)-differing clusters (shown in bold type). Cluster {a, b}, {b, c}. {d, e, f} (enclosed in boxes) are the (T1, T2) and (T2, T1)-minimal differing clusters. There are two (T1, T2)-differing clusters, hence dCI(T1, T2) = 2. Also shown in the table are the bipartitions of the leaf set {r, a, b, c, d, e, f} obtained as a result of removing different edges in the tree. The symmetric difference between the trees is the number of bipartitions in one tree that is not in the other (shown in bold type). The edges that create the “differing” bipartitions are highlighted in bold in the trees. Each bipartition is listed by the side of the non-trivial cluster which forms a part of the bipartition. With this correspondence, we notice the conceptual similarity of the symmetric difference distance and the dCI distance. There are two (T1, T2)-minimal differing clusters and one (T2, T1)-minimal differing cluster hence dPCI(T1, T2) = max{2, 1} = 2.
Minimal differing clusters between trees
A minimal (T1, T2)-differing cluster is a (T1, T2)-differing cluster in T1 that does not contain any other (T1, T2)-differing cluster. Figure 3 shows two trees and the differing and minimal differing clusters between them.
We use minimal differing clusters between T1 and T2 in our main algorithm. We also define a new distance measure that counts the minimal differing clusters between trees. For {i,j} = {1,2}, let MDC(T
i
, T
j
) be the set of all minimal (T1, T2)-differing clusters. Let
We first prove that dPCI satisfies the mathematical conditions to be called a metric. We use this fact to prove
Lemma 1
dPCI is a metric in the space of B(X).
(i) dPCI(P, Q) ≥ 0 (non-negativity), (ii) dPCI(P, Q) = 0 if and only if P = Q (identity of indiscernibles), (iii) dPCI(P, Q) = dPCI(Q, P) (symmetry), (iv) dPCI(P, R) ≤ dPCI(P, Q) + dPCI (Q, R) (triangle inequality).
Let
*A cluster
This fact will be used throughout the proof for any possible pairs of trees (i): Since m(P, Q), m(P, Q) ≥ 0, we have
(ii): MDC(P, Q) = φ and MDC(P, Q) = φ if and only if P and Q are identical; i.e., m(P, Q) = 0 and m(P, Q) = 0 if and only if P = Q. (iii): Since
we have
(iv): Without loss of generality, let dPCI(P,R) = m(P,R). We will give an one-to-one function
since
and since
Let
Case (a): Suppose
Subcase (i): If
Subcase (ii): If 1. Suppose 2. Suppose
Thus
Case (b): Suppose
Subcase (i): Suppose there exists
Subcase (ii): Suppose Subcase (i) does not hold but there exists
Subcase (iii): If the above two subcases do not hold, then
Thus, for each
Moreover,
Theorem 1
Let T1 and
Suppose k = 1. In this proof, we identify the clusters using the labels specified to them. Figure 4 shows a pair of trees, T1 and T2 in which the labels A, B, C, D,

This figure shows two trees T1, T2 with common clusters A, B, C, D and X; all clusters contained in each of them are also assumed to be common. Then drSPR(T1, T2) = 1 with the subtree corresponding to X as the rSPR subtree.
Now, let us assume that k > 1. There are k rSPR operations between T1 to T2 with trees
and by
Lemma 1
, dPCI satisfies the triangle inequality, and thus we have
2.2. D-Clust: an algorithm to estimate the drSPR distance
In this section, we describe our algorithm D-Clust that finds the lower and the upper bounds for the drSPR distance and how it finds a sequence of rSPR operations that transform one tree into another.
D-Clust uses a result given by Bordewich and Semple (2004), which suggested an approximation algorithm. We now review this result and algorithm and then describe D-Clust, which improves the accuracy of that approximation.
Bordewich et al. proved that if
The above set of inequalities suggests an algorithm that first chooses a common cluster C and breaks the problem into two sub-problems, one of which calculates
Choosing the common clusters is crucial to stop the recursion as early as possible, thus providing useful heuristics for the distance. In D-Clust, we make use of the minimal differing clusters to identify the appropriate common clusters. For this, we need some additional definitions. For
In other words, we have
The main idea in D-Clust consists of: first, finding a pair of nested clusters from {T1, T2} such that k = d(C′, C″) is minimized, and then subdividing the problem into k + 1 subproblems of finding each of
We now show that D-Clust is an extension of APPROX-SPR that narrows the range of values for the actual distance. We first note that the common clusters
Another useful implication of (2) has to do with the inference of the transforming rSPR operations. The inequalities in (2) suggest that a sequence of operations that transform T1|C into T2|C, combined with a sequence of operations that transform

In the top two trees (T1 and T2), x1 and x2 are two leaf labels and C1,C2 and C3 are common clusters in T1 and T2. Thus, C′ : = {x1, x2} is a minimal differing cluster in T1 and
In the Appendix, we discuss some implementation details and show that the algorithm runs in O(n4) time.
3. Experimental Results
3.1. Performance of D-Clust on tree-pairs with small drSPR distances
To test the accuracy of our algorithm, we generated synthetic datasets with specific drSPR distances. We first produced 100 random trees in B(n) for each of
The upper and lower bounds of D-Clust were always equal to 1 for trees with distance 1. For distances 2 and 3, the picture was slightly more complicated. As can be seen from Table 1, the upper bound was typically near the exact distance, whereas the number of tree pairs for which D-Clust was able also to accurately estimate the lower bound, and therefore the exact distance, depended on the number of leaves in the tree and the actual distance. When the number of leaves was relatively small, the lower bound was lower than the actual value, but the bound abruptly became much tighter when the number of leaves increase to ∼50 or more. Thus, the ability of D-Clust to find the exact answer using the equality of the bounds depends on the ratio of the drSPR distance to the number of leaves, the lower the ratio the better is the accuracy.
Next, we considered the 320 benchmark tree pairs used in Hill et al. (2010) to compare the accuracy of the various algorithms. The dataset was formed by first taking a set of 320 trees and randomly performing certain specific number of rSPR operations on each of them. Tables 2 and 3 contain the results of D-Clust for these tree pairs. SPRDist was used to find the exact distance between the trees (not included) and for rare number of cases (∼10), D-Clust was used to confirm the exact distance. We noticed that the upper bounds of D-Clust match the exact distances for most tree pairs (310), consisting of all pairs with 50 or more leaves. With a very few (∼3) exceptions, a similar trend is followed by the lower bounds. For 382 pairs consisting of almost all the tree pairs with 50 or above leaves, the bounds coincided with the exact distance. Comparing these results with the results given in Hill et al. (2010) for the other algorithms, we conclude that the upper bounds given by D-Clust are close to the actual answer and the estimates given by the other heuristic algorithms; and in some cases, especially when the number of leaves and the distance are large, D-Clust gives the best solution. Furthermore, the lower bounds are equal to the upper bounds in such cases, thus providing the best results when other algorithms either give loose upper bounds and/or fail to compute the distance in reasonable space and time. D-Clust was able to compute the bounds on an average in ∼12 seconds and in less than 150 seconds for each tree pair, using less than 1 GB of RAM.
Each row presents the result for 10 tree pairs (third column) with the given number of leaves (second column), whose distance is at most the number given in the first column. The fourth column and the fifth column give the number of tree pairs for which the upper and lower bounds respectively of D-Clust matched the exact distance. Shown in the parenthesis in these columns average errors of the bounds for the tree pairs whose respective bounds did not match the exact distance. The sixth column shows the number of tree pairs whose lower and upper bounds both coincided with the exact distance. The contents of the table are continued in Table 3.
3.2. Performance of the bounds of D-Clust for random pairs of trees with unknown drSPR distances
In order to empirically determine the differences in values between the lower and upper bounds of D-Clust, we ran the algorithm for random tree pairs. Figure 6 shows the estimated values using both D-Clust and RIATA-HGT. We first observe that in general, the upper bound estimates of D-Clust are close to that of RIATA-HGT, with the estimates given by RIATA-HGT being slightly lower than that for D-Clust. In contrast, D-Clust outputs smaller upper bounds compared to RIATA-HGT for some trees pairs with large number of leaves and large distances between them (data not shown). Secondly, we observe that the lower bounds are very close to the upper bounds for trees with smaller number of leaves, and the upper bounds are about 7-fold larger than the lower bounds. From this, we conclude that D-Clust is currently most useful for computing the actual distance using equality of the bounds for relatively highly similar trees. On the other hand, RIATA-HGT and other approaches can find tight upper bounds efficiently, but are typically unable either to guarantee their solutions or to deliver the transforming operations. In order to improve the accuracy of the future approaches for large distances, it appears to be important to improve the lower bound.
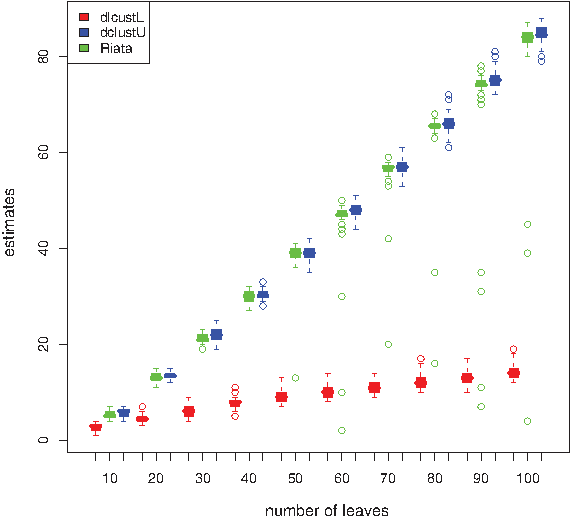
Box plot of the estimates by D-Clust and RIATA-HGT for 100 random pairs of trees for each
4. Discussion
In this article, we gave a recursive algorithm D-Clust for the lower and upper bound heuristics for the NP-hard problem of computing the rSPR distance between trees. The algorithm runs in O(n4) time. We also provided empirical evidence that, in general, the upper bound is comparable to other upper bound heuristics, and that the lower and the upper bounds tend to coincide for the trees with small distances, with particularly good estimates for the trees with large number of leaves. Interestingly, a pair of trees with the large number of leaves and relatively small value of distance between the trees may model a common situation when a species tree and a gene tree, or two gene trees, are compared in search of a horizontal gene transfer event. Indeed, whereas the absolute number of the horizontal gene transfer events in the history of life may have been very large, the distribution of these events across the genomes and gene families may have been skewed, so that the vast majority of gene families appear to have experienced only a low rate of horizontal transfer (Lerat et al., 2005; Glazko et al., 2007; Molina and van Nimwegen, 2008). Thus, D-Clust may perform well for detecting horizontal gene transfer in the majority of gene/protein families. For large distances, the upper bounds are close to other upper bound heuristics, with large range of values between the bounds, suggesting that methods to compute better lower bound heuristics are desirable. Incorporating the D-Clust algorithm in any upper bound heuristic would provide a method for verifying the correctness of the heuristic and to improve the accuracy of calculating the exact distance. D-Clust also gives a sequence of rSPR operations that transform one tree into another tree which would be helpful in keeping track of the subtrees and the operations that are responsible for the differences between the trees.
A R program implementing the D-Clust algorithm is available upon request from one author (L.K.).
5. Appendix
5.1. Empirical distributions of the dPCI, drSPR, and dCI measures on random trees
The values of dPCI, drSPR and dCI measures between trees in B(X) all take values from 0 to n − 2, where n is the number of leaves in the trees. To obtain a more quantitative picture of the behavior of dPCI, drSPR and dCI, we compared these distances between simulated trees. We first generated 1000 pairs of trees with random topology in B(X) with |X| = 10 and calculated dPCI, drSPR and dCI between each pair of trees. Computing dCI and dPCI are straightforward, as they can be found easily by listing the clusters in each tree. To compute drSPR, we used the SPRDist program (Wu, 2009). Figure 7 shows the distribution of these distances for the 1000 tree pairs. The distributions of dPCI and drSPR have similar shapes and ranges, with the peak of the former and the latter being, respectively, at 3 and 5, dPCI being a lower bound for 2drSPR distance for any tree pair. In contrast, the distribution of the dCI values is shifted towards larger values since it counts all differing clusters. A similar trend was observed on all tree pairs for a wide range of n up to 110 (data not shown).
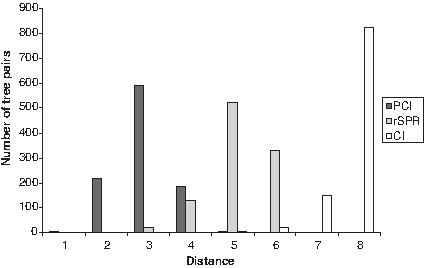
The frequency distributions of dPCI, drSPR, and dCI measures for 1000 random pairs of trees in B(X), with |X| = 10.
5.2. D-Clust: an algorithm that provides a lower bound and an upper bound for the drSPR distance
Given
We now prove the recursion that the algorithm uses. For
Let (i) The leaf sets (ii) For all (iii) The trees in
A maximum-agreement forest (MAF) of (T1, T2) is an agreement forest
Lemma 2
Let (C′, C″) be a pair of nested clusters from {T1T2} such that
Suppose the second inequality is an equality, then
Let us label the least common ancestor of C as ‘v’ in both T
1
and T
2
. Let
be a MAF of
be a MAF of (T1|C, T2|C). By (5), there exists a
is a MAF of (T1, T2). Since the cluster C″ contains C in Tj and since C′ is a minimal differing cluster in Ti, we have
Theorem 2
Let (C′, C″) be a pair of nested clusters from {T1, T2} such that
But, by induction hypothesis, we have
Substituting the upper and lower bounds of
5.2.1. Time complexity
Below are some implementation details and a justification for the complexity of O(n4) for D-Clust.
The computationally intensive part in each recursive step in D-Clust is to find a pair (C′, C″) of nested clusters from opposite trees (T1, T2) such that d(C′, C″) = k is minimum. For this, we need to first find the differing and common clusters, second compute the minimal differing clusters, third list the nested clusters, fourth find the minimum number of common clusters in each pair of nested clusters. For this, we maintain a 3-dimensional array M. In other words, M is a matrix whose entries are lists of leaf labels. The row indices of M corresponds to the clusters of T1 arranged in an increasing order of the cluster size and the column indices represents the clusters of T2 arranged in increasing order of the cluster size, and the entries of M contains the set union of the two clusters corresponding to the row and column. Note that each entry of M can be computed in O(n) time and thus it takes O(n3) time to compute the entries of M.
To find the common clusters, it is enough to traverse the entries in M and see if the entries are equal to their corresponding column and row (takes, O(n2) time). The clusters that are not common are differing.
To find minimal differing clusters, the differing clusters are compared with the other clusters in both the trees, thus taking O(n3) time.
To find the nested pairs of clusters, the rows and columns corresponding to each minimal differing cluster C′ can be traversed to find a cluster C″ of minimum size in the opposite tree that contains the cluster. This takes O(n) time for each minimal differing cluster if the lengths of the entries of M are also stored. Since the number of minimal differing clusters is O(n), finding all nested pairs has a complexity of O(n2).
To find the minimum k, for each nested pair (C′, C″ it is enough to traverse the row or column in M corresponding to C″ in the reverse order (bigger common cluster to smaller) to find the common clusters
Thus, each recursive step has a complexity of O(n3). Since there can be be at most n recursive steps, the complexity of D-Clust is O(n4).
An implementation of D-Clust in R can be found at http://sourceforge.net/projects/dclust.
Footnotes
Acknowledgment
We thank Boris Rubinstein for critical reading of this manuscript.
Disclosure Statement
No competing financial interests exist.