
Abstract
Abstract
In genome rearrangements, the double cut and join (DCJ) operation, introduced by Yancopoulos et al. in 2005, allows one to represent most rearrangement events that could happen in multichromosomal genomes, such as inversions, translocations, fusions, and fissions. No restriction on the genome structure considering linear and circular chromosomes is imposed. An advantage of this general model is that it leads to considerable algorithmic simplifications compared to other genome rearrangement models. Recently, several works concerning the DCJ operation have been published, and in particular, an algorithm was proposed to find an optimal DCJ sequence for sorting one genome into another one. Here we study the solution space of this problem and give an easy-to-compute formula that corresponds to the exact number of optimal DCJ sorting sequences for a particular subset of instances of the problem. We also give an algorithm to count the number of optimal sorting sequences for any instance of the problem. Another interesting result is the demonstration of the possibility of obtaining one optimal sorting sequence by properly replacing any pair of consecutive operations in another optimal sequence. As a consequence, any optimal sorting sequence can be obtained from one other by applying such replacements successively, but the problem of finding the shortest number of replacements between two sorting sequences is still open.
1. Introduction
Most algorithms that solve the genomic sorting problem will report just one out of a possibly very high number of rearrangement sequences, and studies of such a particular sequence are not well suited for drawing general conclusions on properties of the relationship between the two genomes under study. Moreover, there are normally too many sorting sequences in order to enumerate them all (Siepel, 2003). Consequently, people have started characterizing the space of all possible genome rearrangement sequences without explicit enumeration (Bergeron et al., 2002; Braga et al., 2008). This space exhibits a nice sub-structure that allows efficient enumeration of substantially different rearrangement sequences, for example. This may be a good basis for further studies based on statistical approaches or sampling strategies.
Based on the type of genomes and the organism under study, various genome rearrangement operations have been considered. Most results are known for unichromosomal linear genomes, where the only operation is an inversion of a piece of the chromosome. In this model, the space of all sorting sequences has been well characterized, allowing one to group sorting sequences into classes of equivalence (Bergeron et al., 2002). The number of classes of equivalence that can be directly enumerated (Braga et al., 2008) is much smaller than the total number of sequences.
In this article, which is an extended version of Braga and Stoye (2009), we study the space of all optimal sorting sequences under a more general rearrangement operation, called double cut and join (DCJ). This operation was introduced by Yancopoulos et al. (2005) and further studied in Bergeron et al. (2006). It acts on multichromosomal linear and/or circular genomes and subsumes all traditionally studied rearrangement operations like inversions, translocations, fusions, and fissions, as described in Section 2. In Section 3, we give a closed formula for the number of DCJ sorting sequences that is exact for a certain class of instances of the problem, and a lower bound for the general case. Then, in Section 4, we give an algorithm that allows the efficient computation of the number of sequences for the general case. Furthermore, in Section 5, we characterize the sorting sequences and show how to replace a pair of consecutive operations in order to obtain one sorting sequence from another. Finally, in Section 6, we give a simple example to illustrate the presented methods and show the experimental results obtained from the analysis of the space of sorting sequences for three pairwise comparisons: human versus chimpanzee, human versus rhesus monkey, and chimpanzee versus rhesus monkey. Section 7 summarizes all presented results.
2. Genomes, Adjacency Graph, and Sorting By DCJ
A multichromosomal genome A, over a set of markers
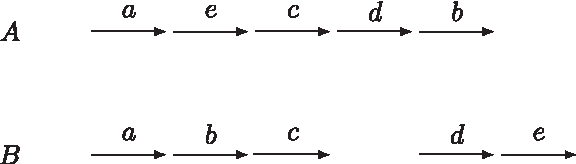
In this graphic representation of the genomes, each arrow represents a marker (from
For each
The two genomes in Figure 1 can be represented by the following sets:
and
A double cut and join (DCJ) operation applied to a genome A is the operation that cuts two elements of V(A) and joins the separated extremities in a different way, creating two new adjacencies. For example, a DCJ acting on two adjacencies pq and rs would create either the adjacencies pr and qs, or the adjacencies ps and qr (this could correspond to an inversion, a reciprocal translocation between two linear chromosomes, a fusion of two circular chromosomes, or an excision of a circular chromosome). In the same way, a DCJ acting on two adjacencies pq and r○ would create either pr and q○, or p○ and qr (in this case, the operation could correspond to an inversion, a translocation, or a fusion of a circular and a linear chromosome). For the cases described so far, we can notice that for each pair of cuts there are two possibilities of joining.
There are two special cases of a DCJ operation, in which there is only one possibility of joining. The first is a DCJ acting on two adjacencies p○ and q○, that would create only one new adjacency pq (that could represent a circularization of one or a fusion of two linear chromosomes). Conversely, a DCJ can act on only one adjacency pq and create the two adjacencies p○ and q○ (representing a linearization of a circular or a fission of a linear chromosome).
Definition 1 (Bergeron et al., 2006)
Given two genomes A and B over the same set of markers 1. The set of vertices is 2. For each
Although an element in V(A) can be identical to an element in V(B), the corresponding vertices in VA and VB are different and |V| = |V(A)| + |V(B)|. For simplicity, we will identify each vertex in VA with the corresponding element in V(A) and each vertex in VB with the corresponding element in V(B).
We know that AG(A, B) is bipartite with maximum degree equal to two (each extremity of a marker appears in one element in V(A) and in one element in V(B)). Consequently, AG(A, B) is a collection of cycles and paths, alternating vertices in V(A) and V(B). The length of a cycle or path is given by the number of edges it contains. A path is said to be balanced when it contains the same number of vertices in V(A) and in V(B), that is, when it contains an odd number of edges. Otherwise the path contains an even number of edges and is said to be unbalanced. We denote by AA-path an unbalanced path with more vertices in V(A), and by BB-path an unbalanced path with more vertices in V(B).
Each path starts and ends in vertices containing the symbol ○. Observe that both A and B have an even number of telomeres; thus, both V(A) and V(B) have an even number of adjacencies containing the symbol ○, and the number of balanced paths in AG(A, B) is even (Bergeron et al., 2006). An example of an adjacency graph is given in Figure 2.
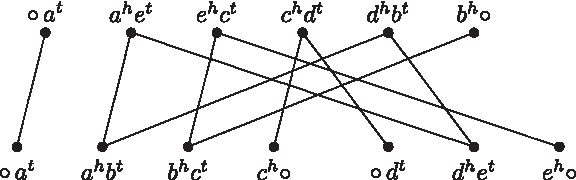
The adjacency graph for the linear genomes A and B from Figure 1, defined by the correponding sets of adjacencies V(A) = {○at, ahet, ehct, chdt, dhbt, bh○} and V(B) = {○at, ahbt, bhct, ch○, ○dt, dhet, eh○}, contains one cycle, one unbalanced BB-path, and two balanced paths.
In the original notation proposed by Bergeron et al. (2006), balanced paths are called odd paths and unbalanced paths are called even paths, in reference to their lengths. However, the sorting by DCJ problem can be also studied with the help of the breakpoint graph (Fertin et al., 2009; Tannier et al., 2009), introduced by Hannenhalli and Pevzner (1995).
Given two genomes A and B, we denote by BG(A, B) the breakpoint graph of A and B. There is a duality between AG(A, B) and BG(A, B), so that AG(A, B) is the line graph of BG(A, B) and an odd path in AG(A, B) is an even path in BG(A, B) (analogously, an even path in AG(A, B) is an odd path in BG(A, B)). Calling these paths balanced and unbalanced is a general notation that is unambiguous, independently of the adopted graph. Moreover, this notation has a meaning with respect to the fact that in balanced paths the genomes are equally represented, while in unbalanced paths one genome is more represented than the other.
The DCJ distance between two genomes A and B, denoted by d(A, B), can be easily computed:
Theorem 1 (Bergeron et al., 2006)
Given two genomes A and B over the same set of markers
where n is the number of markers in
An optimal DCJ operation is a DCJ operation that decreases the DCJ distance by one. Bergeron et al. (2006) observed that an optimal DCJ operation either increases the number of cycles by one or the number of balanced paths by two and proposed a simple greedy algorithm to find one solution to the sorting by DCJ problem, that is, one optimal sequence of DCJ operations to sort A into B.
3. Sorting Components Separately
Although an optimal DCJ sequence sorting a genome A into a genome B can be obtained easily (Bergeron et al., 2006), there are several different optimal sorting sequences, and in this study, we approach the problem of characterizing and counting these optimal solutions. We want to analyze the space of solutions sorting A into B; thus, we consider only operations acting on genome A, or, in other words, acting on vertices of V(A). We adopt the shorter notation A-vertex to refer to a vertex in V(A).
In this section, we focus on DCJ sequences that can be obtained by sorting separately the components of the adjacency graph of two genomes.
Proposition 1
For any pair of A-vertices belonging to the same component of AG(A, B), there is one, and only one optimal DCJ operation. This is also true for any single A-vertex belonging to an unbalanced BB-path of AG(A, B).
Proof
For each pair of A-vertices, such that at most, one contains the symbol ○, we know that there are two different DCJ operations. When the vertices belong to the same component C, one of the two operations simply inverts a segment, not changing the structure of C, and therefore cannot be optimal. The second operation would be an optimal DCJ operation that splits C into a cycle and a smaller component of the same type as C, increasing the number of cycles. This includes all pairs of vertices in cycles, balanced paths and BB-paths, and all pairs of vertices in AA-paths excluding the case where the two vertices contain the symbol ○.
For the two special cases, when both vertices contain the symbol ○ or when a DCJ operation is applied on a single adjacency, there is only one way of joining, thus at most one optimal DCJ operation exists. In the first case, the two vertices can be in the same component only if the component is an unbalanced AA-path. This DCJ operation would close the AA-path into a cycle and is optimal. In the second case, when the DCJ operation is applied on one single adjacency of a component, the operation is optimal (creates two balanced paths) only when the component is a BB-path. ▪
Proposition 2
Given two genomes A and B, any component of AG(A, B) can be sorted separately with only optimal DCJ operations.
Proof
This is a direct consequence of Proposition 1. ▪
Let C be a component in AG(A, B). Due to Proposition 2, we can define as d(C) the DCJ distance of C, that is the number of DCJ operations required to sort C separately. In the same way, we denote by ∥C∥ the number of optimal DCJ sequences that sort C separately.
We know that a component in AG(A, B) is either an even cycle, a balanced path, or an unbalanced path. Let EC2ℓ+2 be an even cycle with 2ℓ + 2 edges and let BP2ℓ+1 be a balanced and UP2ℓ be an unbalanced path with respectively 2ℓ + 1 and 2ℓ edges. We call small components the paths and cycles of AG(A, B) with two vertices (BP1 and EC2) whose distance is zero; the other components are big components. Observe that any unbalanced path is a big component.
Theorem 2
For any integer
Proof
In order to sort a cycle of length 2ℓ + 2, we need to split it into ℓ + 1 cycles of length 2. Each DCJ operation creates one new cycle, thus ℓ operations are required or, in other words, d(EC2ℓ+2) = ℓ.
A balanced path with 2ℓ + 1 edges could be transformed into a cycle with 2ℓ + 2 edges by connecting the two ends of the path (this respects the alternation between vertices of V(A) and V(B)). Each sequence sorting the cycle would correspond to a sequence sorting the original balanced path, thus d(BP2ℓ+1) = d(EC2ℓ+2) = ℓ and ∥BP2ℓ+1∥ = ∥EC2ℓ+2∥. Analogously, an unbalanced path with 2ℓ edges could be transformed into a cycle with 2ℓ + 2 edges by the insertion of an “empty chromosome” vertex on the genome that is under-represented in the path. The two ends of the unbalanced path should then be connected to the new vertex (this also respects the alternation between vertices of V(A) and V(B)) and the new vertex can also be used in optimal DCJ operations within the unbalanced path. Again, each sequence sorting the cycle would correspond to a sequence sorting the original unbalanced path, thus d(UP2ℓ) = d(EC2ℓ+2) = ℓ and ∥UP2ℓ∥ = ∥EC2ℓ+2∥. ▪
An example for the case UP2, BP3 and EC4 is given in Figure 3.

Linking telomeres in the paths of the adjacency graph. We can see here that the structures of an EC4, a BP3, and an UP2 are identical; therefore, these components have the same DCJ distance and the same number of sorting sequences.
Let C1 and C2 be two big components of AG(A, B), with d(C1) = ℓ1 and d(C2) = ℓ2. Moreover, let s1 be a DCJ sorting sequence of length ℓ1 sorting C1 and let s2 be a DCJ sorting sequence of length ℓ2 sorting C2. We can obtain a set of sequences sorting C1 and C2 with the shuffle product of s1 and s2, denoted by s1 ⨂ s2, that corresponds to all possible ways of shuffling s1 with s2, such that s1 and s2 are subsequences of all resulting sequences. The number of sequences in s1 ⨂ s2 is given by the binomial coefficient
For example, if s1 = ρ1ρ2 and s2 = θ1θ2, then s1 ⨂ s2 is composed of the six sequences ρ1ρ2θ1θ2, ρ1θ1ρ2θ2, ρ1θ1θ2ρ2, θ1ρ1ρ2θ2, θ1ρ1θ2ρ2 and θ1θ2ρ1ρ2, and indeed
Observe that the operation ⨂ is commutative, that is, s1 ⨂ s2 = s2 ⨂ s1, and associative, that is, (s1 ⨂ s2) ⨂ s3 = s1 ⨂ (s2 ⨂ s3). In general, the number of ways of shuffling k sequences whose lengths are
Now let S1 be the set of all sequences sorting C1 and S2 be the set of all sequences sorting C2. We can obtain all sequences sorting C1 and C2 by shuffling each sequence in S1 with each sequence in S2. For example, if S1 = {s11, s12, s13} and S2 = {s21}, then the result would be {s11 ⨂ s21, s12 ⨂ s21, s13 ⨂ s21}. We denote this by S1 ⨂ S2, or simply by C1 ⨂ C2. Observe that the operation ⨂ applied to sets is also commutative (C1 ⨂ C2 = C2 ⨂ C1) and associative ((C1 ⨂ C2) ⨂ C3 = C1 ⨂ (C2 ⨂ C3)).
If
Theorem 3
The number of sequences sorting a big cycle EC2ℓ+2 (whose distance is ℓ ≥ 1) is given by ∥EC2ℓ+2∥ = (ℓ + 1)ℓ−1.
Proof
From Proposition 1 we know that, for each pair of A-vertices, the cycle can be broken in only one way. If the cycle has v = ℓ + 1 A-vertices, it has 2v vertices and 2v edges. The result of the break for each pair of vertices are two cycles as follows (each pair of cycles can be obtained in v different ways):
one of size 2 (v′ = 1; ℓ′ = 0) and one of size 2v − 2 (v′ = v − 1; ℓ′ = ℓ − 1); one of size 4 (v′ = 2; ℓ′ = 1) and one of size 2v − 4 (v′ = v − 2; ℓ′ = ℓ − 2); one of size 6 (v′ = 3; ℓ′ = 2) and one of size 2v − 6 (v′ = v − 3; ℓ′ = ℓ − 3);
one of size 2i (v′ = i; ℓ′ = i − 1) and one of size 2(v − i) (v′ = v − i; ℓ′ = ℓ − i).
Thus, the number of sorting sequences can be computed by the following recurrence formula on v:
We know that
This last recurrence formula is identical to the recurrence formula presented by Zeilberger (2010) for counting labeled trees and results in vv−2. Since we have ℓ = v − 1, we get T(v) = (ℓ + 1)ℓ−1. ▪
Observe that the number of sequences sorting a cycle, given by Theorem 3, corresponds to the number of other objects in combinatorics, such as parking functions. The bijection between these objects and the DCJ sorting sequences has been demonstrated in Ouangraoua and Bergeron (2010).
In order to summarize the previous results, the DCJ distance and the number of sequences sorting the different types of big components are shown in Table 1.
Theorem 4
The number of solutions sorting AG(A, B) obtained by sorting each component separately is
where
Proof
We know that the number of solutions obtained by shuffling the sequences sorting the components separately is given by the multinomial coefficient multiplied by the number of sequences sorting each component, the latter being given by Theorems 2 and 3. ▪
4. Recombining Unbalanced Paths
The formula given by Theorem 4 does not correspond to the total number of solutions for a general instance of the problem, due to the recombination of unbalanced paths. More precisely, a pair composed of one AA-path and one BB-path, called a pair of alternate unbalanced paths, can be recombined into two balanced paths and this is an optimal DCJ operation. Figure 4 shows two examples of such recombinations.
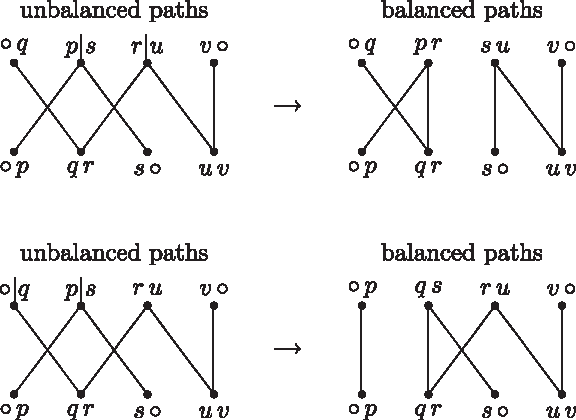
Here we represent two of many ways of recombining a pair of alternate unbalanced paths into a pair of balanced paths.
Proposition 3
Given two genomes A and B, a DCJ operation acting on two A-vertices belonging to two different components of AG(A, B) is optimal, if and only if the two components are alternate unbalanced paths.
Proof
Recall that an optimal DCJ operation either increases the number of cycles by one or the number of balanced paths by two (Bergeron et al., 2006). We need to examine all possible DCJ operations acting on two different components C1 and C2 of AG(A, B). If C1 is a cycle, then the result is one single component that is of the same type as C2. Thus, the cycle C1 disappears and the number of cycles in the graph is reduced. If C1 and C2 are balanced paths, then the result is either one unbalanced path, or two unbalanced, or two balanced paths. In the first and the second case, the number of balanced paths is reduced by two and in the third case it remains unchanged. If C1 is a balanced and C2 is an unbalanced path, then the result is either one balanced path, or one balanced and one unbalanced path. In both cases, the number of balanced paths remains unchanged. And the same happens if C1 and C2 are unbalanced paths that do not form an alternate pair. In this case, the result is either one, or two unbalanced paths. Note that all operations enumerated so far are not optimal. The last possibility is when C1 and C2 are a pair of alternate unbalanced paths. In this case, any operation acting on one A-vertex of C1 and one A-vertex of C2 results in a pair of balanced paths (Fig. 4) and is an optimal DCJ operation. ▪
Proposition 3 guarantees that, if AG(A, B) does not contain any pair of alternate unbalanced paths, the components of AG(A, B) can only be sorted separately.
Corollary 1
Given two genomes A and B, such that AG(A, B) does not contain a pair of alternate unbalanced paths, the formula of Theorem 4 gives the exact number of sorting sequences that transform A into B.
However, although the unbalanced paths can be recombined, they can also be sorted separately. Thus, we have:
Corollary 2
The formula given in Theorem 4 is a lower bound to the number of DCJ sorting sequences for any instance of the problem.
A pair of alternate unbalanced paths can be recombined into two balanced paths at any time and in several different ways, since each one of the unbalanced paths can be reduced before the recombination, by the extraction of cycles. Moreover, two or more different pairs of alternate unbalanced paths can be recombined simultaneously.
Observe, however, that after one recombination we have a pair of balanced paths, so in any optimal sorting sequence an unbalanced path can participate in at most one recombination. Once a recombination occurs, the resulting balanced paths are then sorted separately.
It is possible to design a procedure to count the number of sequences recombining a pair of alternate unbalanced paths, and then combine this with a method to determine all possible simultaneous recombinations to compute the total number of DCJ sequences sorting one genome into another. This is what we do in the following two subsections.
4.1. Recombining one pair of alternate unbalanced paths
First we will analyze how to compute the ways of recombining a single pair of alternate unbalanced paths PA and PB, as shown in Figure 5.

A single pair of alternate unbalanced paths PA and PB.
Observe that for each A-vertex in PA and each A-vertex in PB, there are two optimal DCJ operations:
Proposition 4
The two different DCJ operations acting on one A-vertex in an AA-path and one A-vertex in a BB-path are optimal.
Proof
This can be verified by simple enumeration, as illustrated in Figure 6. ▪
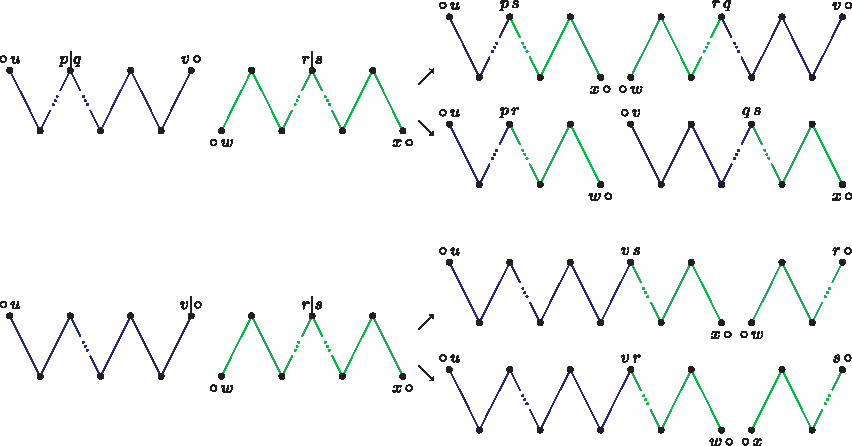
The two ways of recombining a pair of alternate unbalanced paths using vertices pq and rs and the two ways of recombining a pair of alternate unbalanced paths using vertices v○ and rs.
One way of counting the number of DCJ sequences recombining an AA-path PA and a BB-path PB is to link them together into a cycle. In the first way, the first telomere in PA is linked with the second telomere in PB and the second telomere in PA with the first telomere in PB. We denote this cycle by c1(PA, PB). In fact, there are two ways of linking the paths together. The other way would be to link the first telomere in PA with the first telomere in PB and the second telomere in PA with the second telomere in PB, resulting in a cycle denoted by c2(PA, PB). If d(PA) = ℓA and d(PB) = ℓB, then both c1(PA, PB) and c2(PA, PB) have DCJ distance equal to ℓA + ℓB. Figure 7 shows the two ways of linking a pair of unbalanced paths.
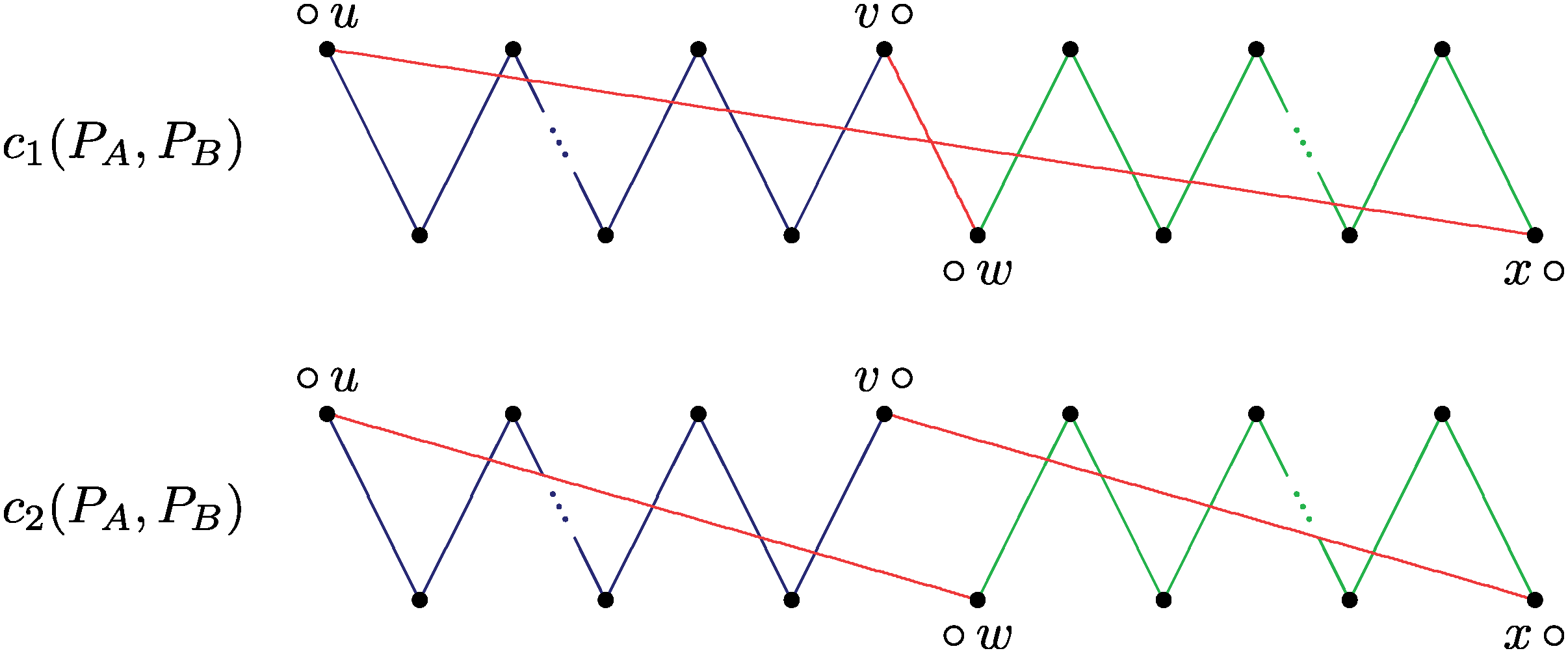
The two ways of linking an AA-path and a BB-path together into a cycle.
Observe that all vertices in PA and all vertices in PB are also present in both c1(PA, PB) and c2(PA, PB).
Proposition 5
Each optimal DCJ operation acting on one A-vertex in an AA-path PA and one A-vertex in a BB-path PB corresponds either to one optimal DCJ operation splitting c1(PA, PB) or to one optimal DCJ operation splitting c2(PA, PB).
Proof
Let pq be an A-vertex in PA and rs be an A-vertex in PB. Both vertices pq and rs are present in both cycles c1(PA, PB) and c2(PA, PB). There are two optimal DCJ operations acting on pq and rs, one creates the vertices pr and qs and the other creates the vertices ps and qr. Without loss of generality, suppose that the first possibility would correspond to a splitting in c1(PA, PB). Then since PB would be inversed in c2(PA, PB) with respect to c1(PA, PB), the second would correspond to a splitting in c2(PA, PB). A similar analysis can be done to the case when v○ is an A-vertex in PA and rs is an A-vertex in PB. ▪
Proposition 5 establishes a relation between an operation recombining two unbalanced paths PA and PB and an operation splitting a cycle whose distance is the sum of the distances of PA and PB. A consequence of this fact is that any optimal sequence of operations that sorts PA and PB and contains a recombining operation would correspond to an optimal sequence of operations sorting a cycle whose distance is the sum of the distances of PA and PB:
Proposition 6
Each optimal DCJ sequence recombining an AA-path PA and a BB-path PB corresponds either to one optimal DCJ sequence sorting c1(PA, PB) or to one optimal DCJ sequence sorting c2(PA, PB).
Corollary 3
The number of sorting sequences recombining an AA-path PA and a BB-path PB whose DCJ distances are, respectively, ℓA and ℓB is bounded by 2 × (ℓA + ℓB + 1)ℓ A +ℓ B −1.
Not all the sequences sorting c1(PA, PB) and c2(PA, PB) correspond to recombining DCJ sequences. Look at the examples in Figure 8.

The first operation sorting c1(PA, PB) does not necessarily recombine. Observe that in (1) the original paths would be clearly sorted separately. In (2) the AA-path is reduced, but the recombination can still occur in a subsequent step.
Observe that in Figure 8 (1), we create the vertex ○○. In this case, the original paths would be clearly sorted separately. On the other hand, an operation that actually recombines the two original paths would separate the vertices containing the symbols ○ and ○ in two different cycles without creating the vertex ○○, as we can see in Figure 9.

The first operation splits c1(PA, PB) and separates the vertices ○ u and v○ in two different cycles, so that the vertex ○○ cannot be created in any subsequent step. In this case, the paths PA and PB are recombined.
Indeed, after the vertices that contain the symbols ○ and ○ are separated in two different cycles, we cannot create the vertex ○○ in any subsequent step. The separation does not need to happen in the first step. We can first apply some operations internal to the original paths, and obtain an intermediary state where the separation can still occur, as in Figure 8 (2). In this case, we have two cycles, but the vertices that contain the symbols ○ and ○ are still in the same cycle, so we can still create the vertex ○○.
Proposition 7
Only the solutions that create the vertex ○○ in some step do not recombine the original paths.
First, we define some operations over a pair of integers [n, ℓ], where n ≥ 1 and ℓ ≥ 0 (usually n gives the number of sequences and ℓ the length of the sequences):
[n1, ℓ] + [n2, ℓ] = [n1 + n2, ℓ] (the addition is only defined when the second value is the same for both pairs); [n1, ℓ] − [n2, ℓ] = [n1 − n2, ℓ] (the subtraction is only defined when the second value is the same for both pairs and n1 > n2); i × [n, ℓ] = [i × n, ℓ] (i ≥ 1 is an integer); [n1, ℓ1] × [n2, ℓ2] = [n1 × n2, ℓ1 + ℓ2] (concatenating n1 sequences of length ℓ1 with n2 sequences of length ℓ2);
Here we denote by
Given an AA-path PA and a BB-path PB, the number of sequences sorting c1(PA, PB) that create the vertex ○○ depends only on the DCJ distances d(PA) = ℓA and d(PB) = ℓB. We denote by
We need
The recurrence for computing
where the first part ([1, 1]) represents the first step and the second part (X + Y + Z = [n, ℓA + ℓB − 1]) considers all possible effects of the first step (all non-recombining steps):
Observe that
Columns 3 and 4 should be given as pairs of integers [n, ℓ], but since ℓ = ℓA + ℓB for both columns, we only give the first value in each pair.
4.2. Computing all simultaneous recombinations
The computation of the number of all DCJ sorting sequences requires the values given by
The most expensive computation would then be the enumeration of all possible simultaneous recombinations. For example, if we have three AA-paths
The simultaneous recombinations can be obtained by the construction of the complete bipartite graph Km,n in which one partition is composed by all m AA-paths and the other is composed by all n BB-paths. The set of all possible matchings in Km,n corresponds to all possible simultaneous recombinations we can do. A matching with k edges represents the sequences in which k recombinations occur simultaneously. Observe that k is bounded by the size of the smaller of the two partitions. The set of all simultaneous recombinations can be computed with Algorithm 1.
Let m and n be, respectively, the number of AA and BB-paths in AG(A, B). Denote by k-matching a matching of size k. The number of 1-matchings is m × n. Then, for each k from 2 to min(m, n), the number of k-matchings is given by the recursion
The number of matchings can also be seen as the number of m × n binary matrices with at most one 1 in each row and column and grows very quickly as m and n grow. Table 3 gives these values for m and n varying from 1 to 10. Observe that we are not interested in simply counting these recombinations, but instead in enumerating all of them in order to count all the optimal DCJ sorting sequences. Unfortunately, this enumeration can be impractical already for relatively low values of m and n. Despite of this problem, this method can be used to analyze real cases of rearrangements, at least with relatively closely related species, as we show in the experimental results presented in Section 6.
5. Transforming One Optimal DCJ Sequence Into Another One
In this section, we will show that it is possible to transform one optimal DCJ sequence into another one, by subsequent replacements of two consecutive operations. The results presented here are more complete and precise than those given in the previous version of this work (Braga and Stoye, 2009).
We represent a DCJ operation by ρ = ({pr, qs} → {pq, rs}). The two adjacencies pr and qs are called the sources, while the two adjacencies pq and rs are called the resultants of ρ. The extremities p, q, r and s are said to be affected by ρ. In the same way, we say that the operation ρ involves the extremities p, q, r and s. Any of the extremities p, q, r and s, affected by ρ, can be equal to ○—a telomere. An extremity that is not a telomere is called a proper extremity.
If ρ is an optimal DCJ operation, ρ involves at most two telomeres. When the adjacency ○○ is a source or a resultant of an operation, it is omitted. With these definitions, we can have four types of optimal DCJ operations:
({pr, qs} → {pq, rs}): has 4 proper extremities, 2 sources and 2 resultants; ({pr, q○} → {pq, r○}): has 3 proper extremities, 2 sources and 2 resultants; ({p○, q○} → {pq}): has 2 proper extremities, 2 sources and 1 resultant; ({pq} → {p○, q○}): has 2 proper extremities, 1 source and 2 resultants.
Two DCJ operations ρ and θ are said to be independent when the set of proper extremities affected by ρ and the set of proper extremities affected by θ are disjoint. Otherwise, an operation can use as a source an adjacency resultant from a preceding operation. Suppose that ρ = ({pv, qr} → {pq, rv}) and θ = ({rv, su} → {rs, uv}). In this case, the adjacency rv is first a resultant from ρ and then a source of θ, and the operations ρ and θ are said to be enchained.
Proposition 8
In any optimal DCJ sorting sequence, two consecutive operations ρ and θ are either independent or enchained.
Proof
The second operation cannot use both resultants of the first, otherwise it would not be part of an optimal sequence. Thus, the second operation either uses one resultant of the first operation or only adjacencies with extremities that were not affected by the first. ▪
Given an operation ρ, we denote by S(ρ) the set containing the sources of ρ and by R(ρ) the set containing the resultants of ρ. Moreover, given two consecutive operations ρ and θ, we define the sources of ρθ, denoted by S(ρθ) as the set containing the sources of ρ and the sources of θ that are not resultants of ρ, that is,
Analogously, the resultants of ρθ, denoted by R(ρθ), are the set containing the resultants of θ and the resultants of ρ that are not sources of θ, that is,
Two pairs of consecutive operations ρ1θ1 and ρ2θ2 are said to be equivalent when S(ρ1θ1) = S(ρ2θ2) and R(ρ1θ1) = R(ρ2θ2). Observe that, when two pairs of consecutive operations are equivalent, but not equal, the replacement of one by the other in an optimal sorting sequence leads to another optimal sorting sequence. ▪
Proposition 9
If two operations ρ and θ are independent, then ρθ is equivalent to θρ.
Proof
When two operations ρ and θ are independent, S(ρ) and S(θ) are disjoint, as well as R(ρ) and R(θ). Consequently, S(ρθ) = S(θρ) and R(ρθ) = R(θρ), showing that ρθ is equivalent to θρ. ▪
For a given set of sources S and a given set of resultants R, the equivalence class of S and R is composed by all pairs of consecutive operations that transform S into R. One pair of consecutive operations is enough to give the set S of sources and the set R of resultants of a class. Thus, with one element we can recover a whole class.
In the following, we show how to find the equivalence class of any pair of consecutive operations.
Class 1
Commutation: Independent operations ρ and θ, such that at least one set among S(ρθ) and R(ρθ) has four elements.
In general, two independent operations ρ = ({pr, qs} → {pq, rs}) and θ = ({tv, uw} → {tu, vw}) have four sources and four resultants, but other possibilities also exist. Considering, for example, ρ = ({pq} → {p○, q○}) and θ = ({rs} → {r○, s○}), then S(ρθ) has only two, but R(ρθ) has four elements. This example respects the condition imposed in Class 1.
Proposition 10
If ρ and θ are two enchained operations, then 2 ≤ S(ρθ) ≤ 3 and 2 ≤ R(ρθ) ≤ 3. Furthermore, if S(ρθ) = 2, then R(ρθ) = 3 and if R(ρθ) = 2, then S(ρθ) = 3.
Proof
By the definition, when two operations are enchained, a resultant from the first is a source of the second, thus S(ρθ) ≤ 3 and R(ρθ) ≤ 3. It is also easy to see that S(ρθ) ≥ 2 and R(ρθ) ≥ 2. The only possibility of having a pair of enchained operations with S(ρθ) = 2 and R(ρθ) = 2 would be a pair with an operation of the type ({p○, q○} → {pq}), followed by an operation of the type ({pq} → {p○, q○}), but if these two operations are enchained, they cannot be optimal. ▪
Proposition 11
Given two independent DCJ operations ρ and θ, such that at least one set among S(ρθ) and R(ρθ) has four elements, then ρθ and θρ are equivalent and there is no other pair of consecutive operations in the same class of equivalence.
Proof
Since ρ and θ are independent, we know from Proposition 9 that ρθ is equivalent to θρ. No other pair of independent operations can be in the same class of equivalence. Moreover, since ρθ has four sources or four resultants, no pair of enchained operations can be in the same class of equivalence, because, from Proposition 10, we know that any pair of enchained operations has at most three sources and three resultants. ▪
The class of equivalence described in Proposition 11 has two elements and is called a commutation class.
Observe that, if ρ = ({ps} → {p○, s○}) and θ = ({q○, r○} → {qr}), ρ and θ are independent, but S(ρθ) and R(ρθ) have three elements each. Actually, this is the only case of two independent consecutive operations that do not have four sources or four resultants and do not form a commutation class. Indeed, in this case, ρθ and θρ are equivalent, but there are also other pairs of enchained operations in the same class of equivalence, defined by the sources S = {ps, q○, r○} and resultants R = {p○, qr, s○}, as we will see later.
When two consecutive operations ρ and θ are enchained, they cannot be simply commuted. However, using the same adjacencies and extremities affected by ρ and θ, we can obtain different pairs of consecutive enchained operations which would be equivalent to ρθ. The next equivalence class includes only enchained operations and has three elements:
Class 2
Alternative splitting: Enchained operations involving at most one telomere, or enchained operations with only two sources and three resultants, or enchained operations with three sources and only two resultants.
Proposition 12
Given the set of sources S = {pv, qr, su} and the set of resultants R = {pq, rs, uv}, such that at most one extremity among p, q, r, s, u, v is a telomere, there are three different pairs of enchained operations that transform S into R. The same is true if we consider the set of sources S = {ps, qr} and the set of resultants R = {pq, r○, s○}, or the set of sources S = {p○, r○, qs} and the set of resultants R = {pq, rs}.
Proof
First consider the case in which the set of sources is S = {pv, qr, su}, the set of resultants is R = {pq, rs, uv} and at most one extremity among p, q, r, s, u, v is a telomere. We know that the first operation will produce only one resultant from R. Since we have three resultants in R and each one can be obtained with only one pair of sources in S, there are only three possibilities for this operation: ρ1 = ({pv, qr} → {pq, rv}), ρ2 = ({pv, su} → {ps, uv}) and ρ3 = ({qr, su} → {qu, rs}). For each ρi we can obtain a subsequent operation θi, such that S(ρiθi) = S and R(ρiθi) = R. For each ρi there is only one possibility of composing θi and we have θ1 = ({rv, su} → {rs, uv}), θ2 = ({ps, qr} → {pq, rs}) and θ3 = ({pv, qu} → {pq, uv}). Thus, the three pairs ρ1θ1, ρ2θ2 and ρ3θ3 are in the same class of equivalence and there are no more elements in this class.
Similar analyses can be done for the cases in which the set of sources is S = {ps, qr} and the set of resultants is R = {pq, r○, s○}, or the set of sources is S = {p○, r○, qs} and the set of resultants is R = {pq, rs}. ▪
The class of equivalence described in Proposition 12 has three elements and is called an alternative splitting class. An example is shown in Figure 10.

Example of equivalence by alternative splitting. Observe that the three pairs of consecutive DCJ operations ρ1θ1, ρ2θ2 and ρ3θ3 transform the adjacencies pv, qr and su into pq, rs and uv.
The last case includes independent and enchained operations whose equivalence classes have six elements:
Class 3
Separation/Recombination: Enchained and independent operations with ps, q○ and r○ as sources and p○, qr and s○ as resultants.
Proposition 13
Given the set of sources S = {ps, q○, r○} and the set of resultants R = {p○, qr, s○}, there are two different pairs of independent operations and four different pairs of enchained operations that transform S into R.
Proof
There are only two independent operations that transform S into R, that are ρsep = ({ps} → {p○, s○}) and θsep = ({q○, r○} → {qr}). Thus, ρsepθsep and θsepρsep are in the class of equivalence of S and R.
Now consider the enchained operations. We know that the first operation will produce only one resultant from R. First we observe that it is not possible to create the resultant qr in the first operation of an enchained pair (if we try to create the resultant qr first, we obtain only the independent pair that was mentioned before). Thus, we can create either the resultant p○ or the resultant s○ in the first operation. Looking to the set of sources we have, we can see that there are two different pairs of sources that could be used in the first operation to create each one of the resultants p○ and s ○. Consequently, there are four possibilities for the first operation of an enchained pair: ρ1 = ({ps, q○} → {p○, qs}), ρ2 = ({ps, q○} → {pq, s○}), ρ3 = ({ps, r○} → {p○, rs}) and ρ4 = ({ps, r○} → {pr, s○}). For each ρi we can obtain a subsequent operation θi, such that S(ρiθi) = S and R(ρiθi) = R. For each ρi there is only one possibility of composing θi and we have θ1 = ({qs, r○} → {qr, s○}), θ2 = ({pq, r○} → {p○, qr}), θ3 = ({q○, rs} → {qr, s○}) and θ4 = ({pr, q○} → {p○, qr}).
Thus, the six pairs ρsepθsep, θsepρsep, ρ1θ1, ρ2θ2, ρ3θ3 and ρ4θ4 are in the same class of equivalence and there are no more elements in this class. ▪
The class of equivalence described in Proposition 13 has six elements and is called a separation/recombination class. An example is shown in Figure 11.
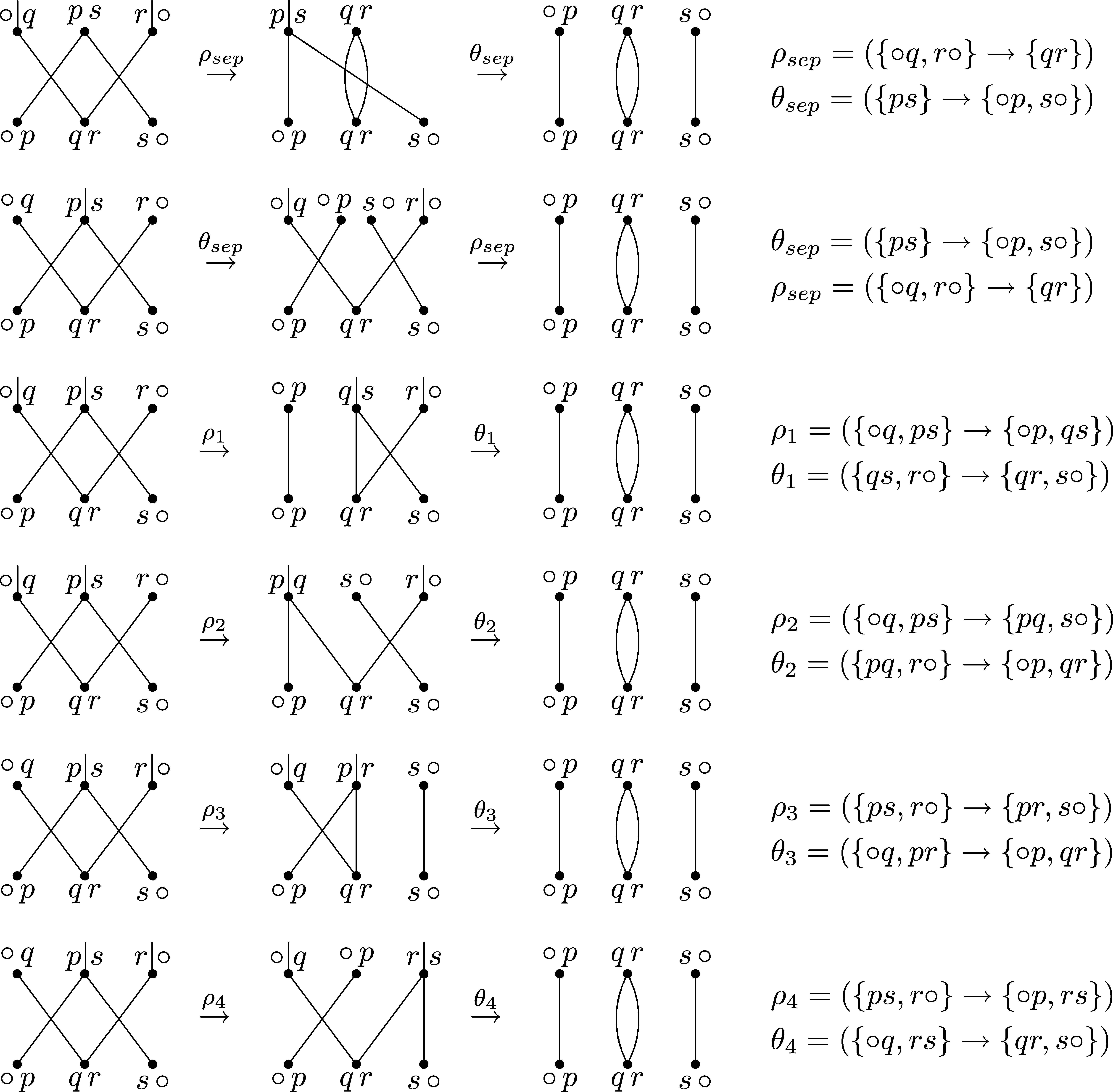
Example of equivalence by separation/recombination. Observe that the six pairs of consecutive DCJ operations ρsepθsep, θsepρsep, ρ1θ1, ρ2θ2, ρ3θ3 and ρ4θ4 transform the adjacencies q○, ps and r○ into p○, qr and s ○.
Theorem 5
In any optimal DCJ sorting sequence, any pair of consecutive operations can be replaced, leading to one, two, or five other optimal DCJ sorting sequences.
Proof
Let ρ and θ be two consecutive operations in an optimal sorting sequence.
If ρ and θ are independent, and ρθ has four sources or four resultants, then ρθ is in a commutation class with θρ (Proposition 11). If ρ and θ are independent, and ρθ has three sources and three resultants, then ρθ is in a separation/recombination class that contains five other elements (Proposition 13). This includes all independent operations.
If ρ and θ are enchained, we also have two possibilities. When ρ and θ involve at most one telomere, then ρθ is in an alternative splitting class that contains two other elements, and the same is true when ρ and θ involve two telomeres, but have only two sources or only two resultants (Proposition 12).
It remains the case of enchained operations involving two telomeres, with ps, q○, and r○ as sources and p○, qr, and s○ as resultants. In this case, ρθ is also in a separation/recombination class that contains five other elements (Proposition 13).
Each possible pair of consecutive operations belongs to one class of equivalence and can be replaced by one (commutation), two (alternative splitting), or five (separation/recombination) other pairs of consecutive operations. ▪
Observe that, in any class of equivalence given by a set of sources S and a set of resultants R, there is at least one pair of consecutive operations that uses each source in S in the first operation, and at least one pair of consecutive operations that uses each source in S in the second operation. Analogously, there is at least one pair of consecutive operations that creates each resultant in R in the first operation, and at least one pair of consecutive operations that creates each resultant in R in the second operation. Consequently, by replacements we can move any adjacency to a particular position in a sorting sequence.
Theorem 6
Any optimal DCJ sequence can be obtained from any other optimal DCJ sequence by successive replacements of pairs of consecutive operations.
Proof
First note that, if both sequences contain no path recombination, in order to transform one sequence into another, we only have to use commutations and alternative splittings to reconstruct the relative order of the operations sorting each component separately. This is also the case of sequences that contain exactly the same path recombinations (with the same orientation for each recombination).
When the sequences differ in the recombinations, then replacements of the type recombination/separation are also necessary and can be done as follows: if a separation is to be performed, we know that the recombined component has two adjacencies p○ and q○ (all other adjacencies contain only proper extremities); then we first need to use commutations and alternative splittings such that p○ and q○ are in consecutive operations, allowing to perform next a separation; after that we can reconstruct the relative order of the parts using commutations and alternative splittings. If a recombination is to be done, we know that in one part we have an operation ρ = {p○, q○} → {pq} and in the other part we have an operation θ = {rs} → {r○, s○}; we can do a recombination using ρ and θ and then reconstruct the relative order of all operations using commutations and alternative splittings.
Finally, we need only commutations to reconstruct the same global order over all parts (components and recombinations). ▪
One critical aspect of replacements, including simple commutations, is that they can change the actual nature of the operations over the genomes, as we can see in Figure 12.
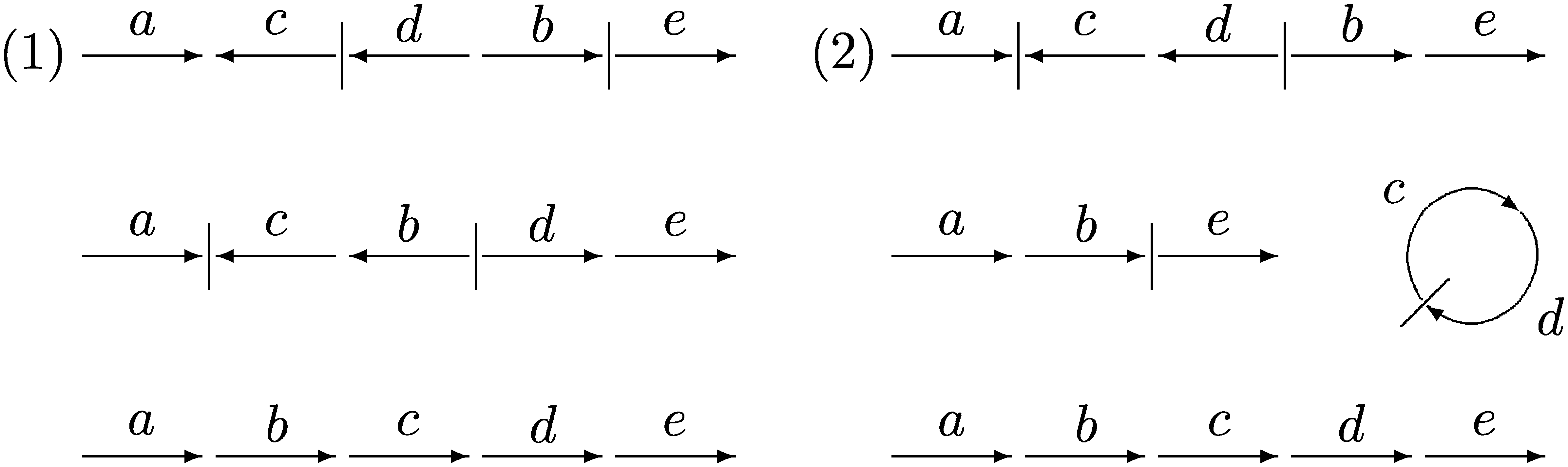
In this graphic representation of the genomes, each arrow represents a marker (from
With the results presented here, we demonstrate that all sorting sequences are vertices in the same connected graph and, for each pair of consecutive operations in each sequence, we have one, two or five edges connecting the corresponding vertex to other vertices in the graph. With the methods given in Sections 3 and 4, we are also able to count the number of vertices in this graph, that corresponds to the total number of sorting sequences. However, some important open questions remain. One is the problem of finding the shortest path, that is, the shortest number of replacements between two sorting sequences. Another question, that is actually related to the first, is the problem of avoiding cycles in a walk in the graph. The solutions to these problems could give a measure of similarity between two sorting sequences, leading to a better characterization of the space of solutions.
6. Experiments
6.1. An example illustrating everything
In this section, we want to illustrate the results we presented with one simple example. Let A and B be two genomes, each one composed by one linear and one circular chromosome. The genomes A and B, represented in Figure 13, are defined by their respective sets of adjacencies:
The adjacency graph AG(A, B), also represented in Figure 13, has one cycle, one AA-path and one BB-path. We will count the total number of solutions for this example and show subsequent replacements that transform a sequence recombining the AA-path and the BB-path into a sequence sorting all components separately.
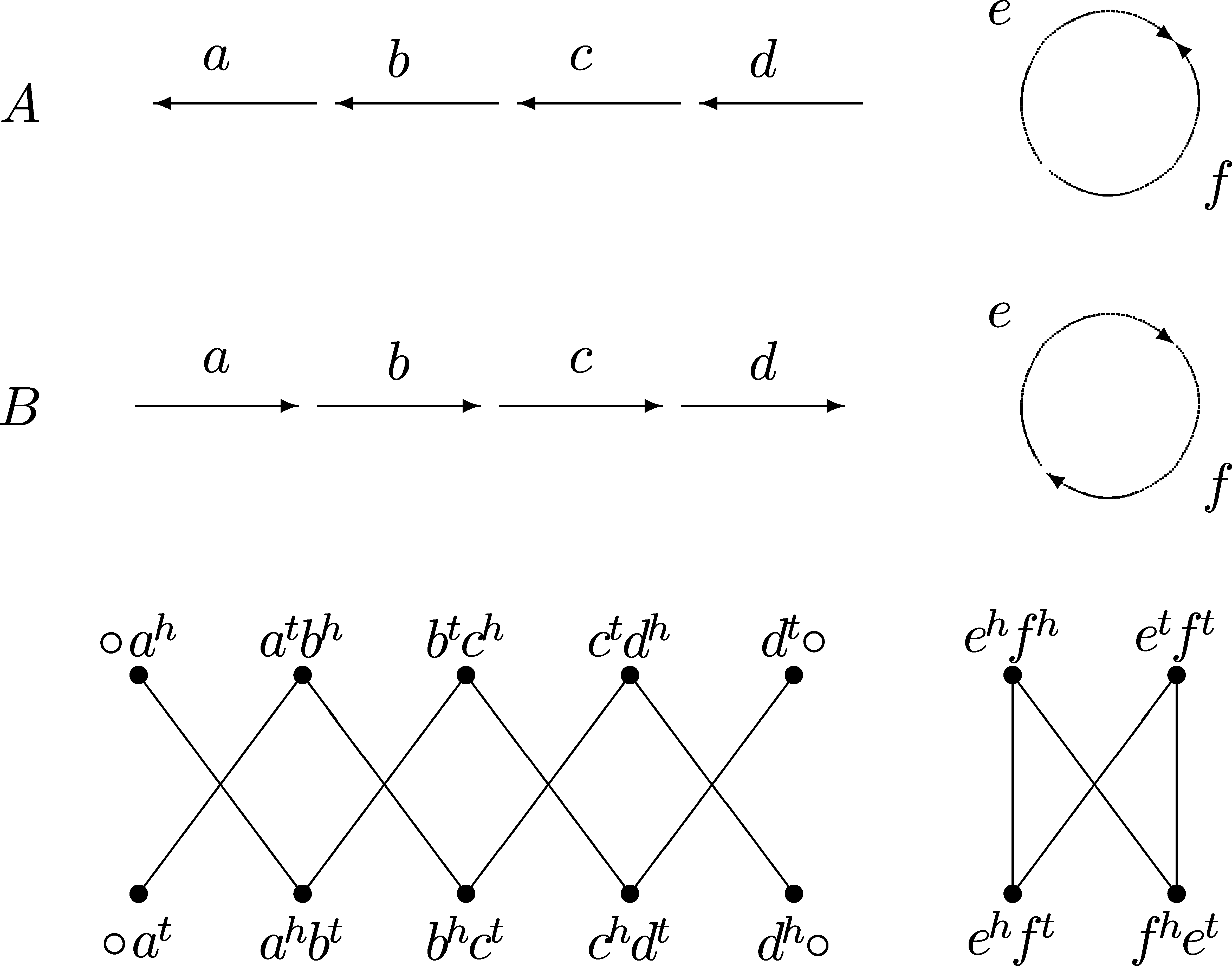
Genomes A and B, defined by the corresponding sets of adjacencies V(A) = {○ ah, atbh, btch, ctdh, dt○, etft, ehfh} and V (B) = {○ at, ahbt, bhct, chdt, dh○, etfh, ehft}, and their adjacency graph that contains one cycle, one AA-path and one BB-path.
We can also compute the number of sequences sorting genome A into B, using the methods described in Sections 3 and 4. The number of sequences that sort A into B without recombining the AA-path and the BB-path is denoted by Ssep:
Thus, we have 270 sorting sequences of length 5 without recombinations. The number of sequences that sort A into B recombining the AA-path and the BB-path is denoted by Srec (the value
This means that we have 1040 sorting sequences of length 5 with recombinations. Consequently, the total number of sequences sorting A into B is 1310.
Observe that, since ρ1 recombines the AA-path and the BB-path, srec is a recombining sorting sequence. If we examine the class of equivalence of each pair of consecutive operations in srec, we have: ρ1ρ2 and ρ4ρ5 are in alternative splitting classes (both pairs are composed by enchained operations), while ρ2ρ3 and ρ3ρ4 are in commutation classes (both pairs are composed by independent operations).
We will show a sequence of five replacements of consecutive operations that transforms srec into a non-recombining sorting sequence ssep:
Replace ρ1ρ2 by
Replace ρ4ρ5 by
Replace Replace
Replace
After the replacements above, we have the sequence of operations
6.2. Comparing human, chimpanzee, and rhesus monkey
From Alekseyev and Pevzner (2009), we obtained a database with the synteny blocks of the genomes of human (Homo sapiens), chimpanzee (Pan troglodytes), and rhesus monkey (Macaca mulatta), and used the methods described in Sections 3 and 4 to compute the number of DCJ sequences for the pairwise comparison of these genomes. The results are shown in Table 4.
For each pairwise comparison, the number of sorting sequences is very large and is thus presented approximately (although it can be computed exactly). Observe that the number of paths is usually much smaller than the number of cycles in all pairwise comparisons. Looking at the human versus chimpanzee comparison in particular, we notice that it results in only one unbalanced path, thus none of its sorting sequences can be obtained by recombining unbalanced into balanced paths. This means that the formula of Theorem 4 corresponds to the exact number of sequences in this case.
We observed that the number of paths and, more particularly, the number of unbalanced paths in the corresponding adjacency graphs is small. Consequently, the enumeration of simultaneous recombinations for these three comparisons do not require space and time consuming computation to be obtained. Comparing the human and chimpanzee genomes, for instance, we have only one unbalanced path, so it is not possible to recombine unbalanced into balanced paths. Since big paths occur when some extremities of linear chromosomes are different in the two analyzed genomes, our results suggest that this is unlikely to happen when the genomes are closely related.
7. Conclusion
In this work, we studied the solution space of the sorting by DCJ problem. We proposed a formula that gives a lower bound to the number of all optimal DCJ sequences sorting one genome into another. This formula can be easily and quickly computed and corresponds to the exact number of sorting sequences for a particular subset of instances of the problem. We could also identify the structures of the compared genomes that cause the increase of the number of solutions with respect to the given lower bound, designing an algorithm to compute the number of DCJ sorting sequences to any instance of the problem. We used this algorithm to compute the number of sequences for three pairwise comparisons: human versus chimpanzee, human versus rhesus monkey, and chimpanzee versus rhesus monkey.
Furthermore, we were able to demonstrate that all sorting sequences are connected, that is, any optimal sequence can be transformed into any other one by replacements (due to commutation, alternative splitting or separation/recombination) of pairs of consecutive operations. However, the problem of finding the shortest number of replacements between two sorting sequences is still open. The solution to this question could give a measure of similarity between two sorting sequences, leading to a better characterization of the space of solutions.
Footnotes
Acknowledgments
We are grateful to Aïda Ouangraoua and Anne Bergeron for helpful discussions about the recombination of a pair of unbalanced paths and useful comments on an earlier version of the manuscript.
Disclosure Statement
No competing financial interests exist.