
Abstract
Abstract
Many applications of data partitioning (clustering) have been well studied in bioinformatics. Consider, for instance, a set N of organisms (elements) based on DNA marker data. A partition divides all elements in N into two or more disjoint clusters that cover all elements, where a cluster contains a non-empty subset of N. Different partitioning algorithms may produce different partitions. To compute the distance and find the consensus partition (also called consensus clustering) between two or more partitions are important and interesting problems that arise frequently in bioinformatics and data mining, in which different distance functions may be considered in different partition algorithms. In this article, we discuss the k partition-distance problem. Given a set of elements N with k partitions of N, the k partition-distance problem is to delete the minimum number of elements from each partition such that all remaining partitions become identical. This problem is NP-complete for general k > 2 partitions, and no algorithms are known at present. We design the first known heuristic and approximation algorithms with performance ratios 2 to solve the k partition-distance problem in O(k · ρ · |N|) time, where ρ is the maximum number of clusters of these k partitions and |N| is the number of elements in N. We also present the first known exact algorithm in O(ℓ · 2ℓ·k2 · |N|2) time, where ℓ is the partition-distance of the optimal solution for this problem. Performances of our exact and approximation algorithms in testing the random data with actual sets of organisms based on DNA markers are compared and discussed. Experimental results reveal that our algorithms can improve the computational speed of the exact algorithm for the two partition-distance problem in practice if the maximum number of elements per cluster is less than ρ. From both theoretical and computational points of view, our solutions are at most twice the partition-distance of the optimal solution. A website offering the interactive service of solving the k partition-distance problem using our and previous algorithms is available (see http://mail.tmue.edu.tw/∼yhchen/KPDP.html).
1. Introduction
Motivated by the reconstruction of the family structure from a set of individuals in biology, many partitioning (clustering) algorithms have been well studied (Almudevar and Field, 1999; Bagirov and Mardaneh, 2006; Beyer and May, 2003; Konovalov, 2006; Konovalov et al., 2005b; Konovalov et al., 2004). Almudevar and Field (1999), Konovalov et al. (2005b), and Konovalov (2006) provided some reconstructing full sibling clustering algorithms in order to deduce the family relationships of a set of organisms based on DNA markers. Konovalov et al. (2004) implemented a java program for reconstructing clusters of pedigree relationships by estimating an overall likelihood for alternative partitions. Beyer and May (2003) developed a graph-theoretic approach to group a set of individuals into full-sib families using single-locus co-dominant markers. Bagirov and Mardaneh (2006) designed a modified global k-means algorithm applied to analysis of gene expression data.
Different partitioning algorithms may produce different partitions. How to assess the partitions (partitioning algorithms) and find a consensus partition are important and interesting problems after some partitions have been generated. Hence, methods to compare and validate cluster consensus have been widely studied (Almudevar and Field, 1999; Berman et al., 2007; Butler et al., 2004; Goder and Filkov, 2008; Gusfield, 2002; Hirsch et al., 2007; Konovalov et al., 2005a; Swift et al., 2004; Yeung et al., 2001; Yu et al., 2005). Different distance functions between two or more partitions usually need to be computed by different algorithms. In this article, we focus on the partition-distance function which has been introduced by Almudevar and Field (1999), Gusfield (2002), and Konovalov et al. (2005a).
Now, we describe the partition-distance as follows. For two partitions Pu and Pv, the two partitions are identical if and only if every cluster in Pu maps to the same cluster in Pv (the converse is then forced) (Gusfield, 2002). A partition-distance between two partitions is defined as the number of elements that need to be deleted from both partitions such that the remaining partitions are identical. Given a set of elements N and two partitions of N, the partition-distance problem is to delete the minimum number of elements from each partition such that both remaining partitions become identical (Almudevar and Field, 1999). For this problem, Almudevar and Field (1999) gave an exponential-time exact algorithm in order to find a good partition of the individuals (fisheries actually) into sibling groups. Butler et al. (2004) used Almudevar and Field's algorithm to compare four partitions (partitioning algorithms) for reconstructing full-sib pedigrees from DNA marker data. Gusfield (2002) proposed an O(c3 + |N|)-time algorithm by reduction of this problem to the maximum weighted assignment problem (Kuhn, 2005), where c is the sum of the number of clusters of both partitions and |N| denotes the number of elements in N. Konovalov et al. (2005a) also designed an O(c3 + |N|)-time algorithm by reduction of this problem to the minimum weighted assignment problem (Kuhn, 2005). Note that both algorithms run in O(|N|3)-time because c = O(|N|) in the worst case.
Gusfield (2002) also proposed a generalization of the partition-distance problem, called the k partition-distance problem. Given a set of elements N and k partitions of N, k ≥ 2, the partition-distance among these partitions is defined as the number of elements that need to be deleted from each partition such that the remaining partitions are identical. The k partition-distance (k-PD for short) problem is concerned with finding a minimum partition-distance for the k partitions. When k > 2, Gusfield (2002) showed the k-PD problem is NP-complete by reduction from the 3-dimensional matching problem (Garey and Johnson, 1979). An example to illustrate the k-PD problem as follows. Consider the instance shown in Table 1, in which a partition set P = {P1, P2, P3} has three partitions of the set of elements N = {1, 2, 3, 4, 5, 6, 7, 8, 9, 0}. P1 consists of clusters C1,1, C1,2 and C1,3, P2 consists of clusters C2,1, C2,2 and C2,3, and P3 consists of clusters C3,1, C3,2 and C3,3. The optimal solution to the k-PD problem consists in deleting these elements {4, 5, 8, 9, 0} such that P1, P2 and P3 become identical. If we only consider the two partitions P1 and P2, we need to delete the elements {1, 2} such that P1 and P2 become identical.
Except to compare two different partitions for reconstructing full-sib pedigrees from DNA marker data (Almudevar and Field, 1999; Butler et al., 2004; Gusfield, 2002; Konovalov et al., 2005a), another application of the k-PD problem aims at finding the consensus partition (also called the consensus clustering) from multiple partitions (Berman et al., 2007; Goder and Filkov, 2008; Hirsch et al., 2007; Swift et al., 2004; Yeung et al., 2001; Yu et al., 2005). A similar problem was defined by Berman et al. (2007). We briefly describe this problem as follows.
If the number of clusters of the two partitions Pu and Pv are equal, an alignment between both partitions is that each cluster in Pu matches (aligns) to a unique cluster in Pv. Then we can calculate the number of elements of symmetric difference between both clusters that are aligned with each other. After all clusters of both partitions are aligned, another partition-distance between the two partitions is the sum of all number of elements of symmetric difference among all aligned cluster pairs. If there are more than two partitions, we can align all partitions simultaneously. The partition-distance between these partitions is defined to be the total partition-distance summed over all pairs of partitions. Given a set of elements N and k partitions of N containing exactly the same number of clusters, the k partition-clustering problem involves the simultaneous alignment of the k partitions with minimum partition-distance among all possible alignments of these k partitions. Berman et al. (2007) showed that the two partition-clustering problem can be transformed to the 2-PD problem. They also showed that the k partition-clustering problem is Max SNP-hard even when k = 3. Moreover, they proposed a
In this article, we present the first known approximation algorithm with performance ratio 2 for the k-PD problem in O(k · ρ · |N|) time. Then we propose a heuristic algorithm based on the 2-approximation algorithm. The solution of this heuristic algorithm would be closer to the optimal solution of the k-PD problem than the 2-approximation algorithm in practice. Moreover, we design the first known exact algorithm in O(ℓ · 2 ℓ · k2 · |N|2) time which is actually a fixed-parameter algorithm, where ℓ is the partition-distance of the optimal solution to the k-PD problem. Furthermore, performances of our exact and approximation algorithms in testing the simulated and actual sets of organisms based on DNA markers (Konovalov et al., 2005a) are compared and discussed. Finally, a web site offering the interactive service of solving the k partition-distance problem using our and previous algorithms is also gently established.
The rest of this article is organized as follows: In Section 2, we describe our 2-approximation algorithm and our heuristic algorithm based on the 2-approximation algorithm to solve the k-PD problem. In Section 3, we present an exact fixed-parameter algorithm for the k-PD problem. In Section 4, we apply the proposed approximation and heuristic algorithms to some simulated random data with actual sets in bioinformatics (Konovalov et al., 2005a), and then compare with Konovalov et al.'s (2005a) and Gusfield's (2002) algorithms that output an optimal solution of the 2-PD problem and our exact algorithm for the k-PD problem. In Section 4.4., information about a website offering the interactive service of solving the k partition-distance problem using our and previous algorithms is given. Finally, concluding remarks are given in Section 5.
2. A 2-Approximation Algorithm for the k-PD Problem
k-PD problem (k partition-distance problem)
In this section, we first devise a fast 2-approximation algorithm to solve the 2-PD problem. Then we generalize our idea to any k-PD problem for k > 2 such that the performance ratio of 2 still holds. Finally, we modify the 2-approximation algorithm into a heuristic algorithm to improve the performance ratio of the partition-distance in practice.
According to the definition for two partitions Pu and Pv to be identical, it is easy to realize that if some cluster in Pu does not map to some same cluster in Pv, they are not identical. More specifically, any pair of two elements, which reside in one cluster, say Cu,i, in Pu but in two different clusters, say Cv,r and Cv,s where r ≠ s, in Pv, causes Cu,i no way to map to any cluster in Pv. We define such a pair formally as follows:
Definition 1
Given a pair of elements
Apparently, if any migrated pair exists, Pu and Pv would not be identical. In addition, if Pu and Pv are not identical, there must exist at least one migrated pair. On the other hand, it is not hard to see that if all pairs of two elements are not migrated, Pu and Pv are identical. Besides, if Pu and Pv are identical, all pairs of two elements are not migrated. We address these implications in the following lemma:
Lemma 1
Consider two partitions Pu and Pv of N.
Whenever we find any migrated pair {x, y}, which prevents Pu and Pv from being identical, we should consider delete either x or y (or even both) from both Pu and Pv to sustain the possibility for the remaining partitions to be identical. Consequently, deleting at least one element from those migrated pairs turns out to be a “necessary” condition to make the remaining partitions identical.
Lemma 2
Deleting at least one element from any migrated pair in both Pu and Pv repeatedly until no migrated pair exists makes the remaining partitions identical.
Proof
We prove by contradiction. Assume that deleting at least one element from any migrated pair in both Pu and Pv repeatedly till no migrated pair exists cannot guarantee the remaining partitions, namely Pa and Pb, respectively, to be identical. Then by Lemma 1 (a), there exists at least one migrated pair
In fact, Lemma 2 itself infers some constructive algorithms to ensure the remaining partitions of Pa and Pb to be identical after applying Lemma 2. Nevertheless, any algorithm based on Lemma 2 obtains only a feasible solution to the 2-PD problem. The solution quality varies as the order of the deletions of at least one element from migrated pairs in both Pu and Pv changes. Inspired from Lemma 2, we shall devise an efficient way to find effective migrated pairs and then design a 2-approximation algorithm for the 2-PD problem in the next subsection.
2.1. On the 2-PD problem
Given a set of elements N with two partitions Pu and Pv of N, a partition-distance between Pu and Pv is defined as the number of elements that need to be deleted from Pu and Pv such that the remaining partitions are identical. Let
Consider two specific clusters
Lemma 3
{x, y}, in which
By Lemma 3, migrated pairs between Pu and Pv can be found by ▿(Cu,i, Cv,j) and Δ(Cu,i, Cv,j), for 1 ≤ i ≤ α and 1 ≤ j ≤ β. However, we are interested in those migrated pairs that are disjoint, defined as follows:
Definition 2
Any two migrated pairs {a, b} and {c, d} between Pu and Pv are disjoint if and only if {a, b} ∩ {c, d} = φ.
Basically, once ▿(Cu,i, Cv,j) and Δ(Cu,i, Cv,j) have been found for Cu,i and Cv,j, we may determine γ = min{|▿(Cu,i, Cv,j)|,|Δ(Cu,i, Cv,j)|} disjoint migrated pairs by pairing γ elements in ▿(Cu,i, Cv,j) and γ random ones from Δ(Cu,i, Cv,j) if |▿(Cu,i, Cv,j)| ≤ |Δ(Cu,i, Cv,j)|; or γ elements in Δ(Cu,i, Cv,j) and γ random ones from ▿(Cu,i, Cv,j), otherwise. Let us pay attention to these γ disjoint migrated pairs. Following Lemmas 1 and 2, we realize that deleting at least one element from each of the γ disjoint migrated pairs in both Cu,i and Cv,j is necessary to make possible the remaining partitions identical. In fact, the following lemma holds immediately:
Lemma 4
Given γ disjoint migrated pairs in both Pu and Pv, at least γ elements should be deleted to ensure the remaining partitions to be identical.
Lemma 4 also implies that the number of all disjoint migrated pairs between Pu and Pv becomes a lower bound to the optimal solution of the 2-PD problem.
Essentially, our approximation algorithm first constructs disjoint migrated pairs and then deletes both elements in each of them between each pair of
Deletions of the elements in disjoint migrated pairs
Lemma 5 validates the effectiveness and time-complexity of Algorithm 1 in eliminating all migrated pairs.
Lemma 5
No migrated pair exists between Pu′ and Pv′ produced by Algorithm 1 in O(β · |N| + α · |N|) time with respect to the given N and two partitions Pu and Pv of N.
Proof
Consider a pair of clusters
For case (a), γ = (min{|▿(Cu,i, Cv,j)|,|Δ(Cu,i, Cv,j)|} = |Δ(Cu,i, Cv,j)|) disjoint migrated pairs are formed by Step 1.3. All elements in these γ disjoint migrated pairs are deleted from both Cu,i and Cv,j by Step 1.4. Let the resultant clusters be Cu,i′ and Cv,j′, respectively. Then |▿(Cu,i′, Cv,j′)| = |▿(Cu,i, Cv,j)| − γ and Δ(Cu,i′, Cv,j′) = φ. That is, clusters Cu,i′ and Cv,j′ are the same.
Concerning case (b), after deleting all elements of the γ disjoint migrated pairs, ▿(Cu,i′, Cv,j′) = Δ(Cu,i′, Cv,j′) = φ. That means Cu,i′ = φ = Cv,j′.
For case (c), after deleting all elements of the γ disjoint migrated pairs, ▿(Cu,i′, Cv,j′) = φ and |Δ(Cu,i′, Cv,j′)| = |Δ(Cu,i, Cv,j)| − γ. Any element e in Cu,i′ (or Cv,j′) has never been chosen into SAPX (otherwise, they would be deleted in previous iterations), but e will eventually belong to some ▿(Cu,i′, Cv,m) (or ▿(Cu,m, Cv,j′)) in some further iteration (since Pu and Pv are partitions of N) where
Consider a certain migrated pair {x, y} between Pu and Pv such that x and y are both in some Cu,i of Pu, but in Cv,r and Cv,s, respectively of Pv where r ≠ s. According to the above three cases, x and y would be dealt with (as the role of disjoint migrated pair(s)) in the iterations handling (Cu,i, Cv,r) and/or (Cu,i, Cv,s) (note that x and y may be settled in the former iteration), respectively or further iterations as mentioned in case (c) by Algorithm 1. Elements x and y, which may be deleted or left in remaining same clusters, would no more be migrated pair in Pu′ and Pv′. That is, no migrated pair exists between Pu′ and Pv′ after Algorithm 1.
For Step 1.1, to find elements in ▿(Cu,i, Cv,j) and Δ(Cu,i, Cv,j) can be done in O(|Cu,i| + |Cv,j|) time for each pair of clusters
Based upon the above discussions and Lemmas 1 and 5, we have the following lemma:
Lemma 6
Pu′ and Pv′ produced by Algorithm 1 in O(ρ · |N|) time are identical with respect to the given N and two partitions Pu and Pv of N, where ρ = max{α, β}.
Now, we are ready to present our approximation algorithm for the 2-PD problem.
APX-2-PD
Theorem 7
Algorithm APX-2-PD finds a 2-approximation solution to the 2-PD problem in O(ρ · |N|) time, where ρ = max{α, β}.
Proof
Note that the time-complexity of Algorithm APX-2-PD is dominated by Step 3 for running the Algorithm 1 where sorting elements for all clusters of both partitions can be done in O(ρ · |N|) time by some integer sorting algorithms and some data structures for disjoint set (Cormen et al., 2001). Following Lemma 6, we know that Algorithm APX-2-PD solves the 2-PD problem with time-complexity O(ρ · |N|).
Let SOPT be the optimal solution to the 2-PD problem. Recall that in each iteration for each pair of clusters
2.2. On the k-PD problem
In the last subsection, we presented a 2-approximation algorithm for the 2-PD problem. We extend our idea to any general k-PD problem here. Given a set of elements N and a set P of k partitions
First of all, we observe disjoint migrated pairs in each pair of two clusters in any two of the k partitions. Given a set of disjoint migrated pairs, let {x, y} be a disjoint migrated pair between Pu and Pv for 1 ≤ u ≠ v ≤ k. Deleting at least one element of {x, y} from Pu and Pv is “necessary” to make possible the two remaining partitions identical (see Lemma 4), and consequently the k remaining partitions identical. No matter which (or even both) is deleted from Pu and Pv, it should be removed from all other partitions (to further make possible all remaining partitions identical), even for the situation that {x, y} are in the same cluster in all partitions other than Pu and Pv. In short, at least one element of any disjoint migrated pair in any two of the k partitions should be deleted from all partitions before all remaining partitions become identical. This is also a “necessary” condition to any feasible solution to the k-PD problem. In other words, if we have o disjoint migrated pairs, at least o elements must be deleted from P to sustain the possibility for all remaining partitions to be identical. Hence, the following lemma holds immediately:
Lemma 8
Given o disjoint migrated pairs in all pairs of partitions
Lemma 8 also implies that the maximum number of disjoint migrated pairs of an instance of k-PD problem is a lower bound to the optimal solution of the k-PD problem.
For 1 ≤ i ≤ k, let
APX-k-PD
For each 2 ≤ v ≤ k, our algorithm makes the remaining partitions
Theorem 9
Algorithm APX-k-PD finds a 2-approximation solution to the k-PD problem in O(k · ρ · |N|) time, where ρ is the maximum number of clusters of these k partitions.
Proof
We first analyze the time-complexity of Algorithm APX-k-PD as follows. Step 3 can be done in O(k · ρ · |N|). There are (k − 1) iterations in Step 4. Step 4.1 runs in O(ρ · |N|) time by Lemma 6. Step 4.2 and Step 4.3 can be done in O(k · |N|) time. As a result, the time-complexity of Algorithm APX-k-PD is O(k · ρ · |N|).
Next, we prove that the performance ratio of Algorithm APX-k-PD is 2 by mathematical induction. Given a set of elements N with k partitions
Now, we describe a simple heuristic algorithm to improve the performance ratio of the partition-distance in practice. This heuristic algorithm is modified from Algorithm 1. For completeness, we show this algorithm.
For Algorithm APX-k-PD (respectively, Algorithm APX-2-PD), we simply apply Algorithm 2 instead of Algorithm 1 in Step 4.1. (respectively, Step 3) to establish a new heuristic algorithm. Clearly, the performance ratio of the partition-distance will be improved in practice.
Deletions of the elements
3. An Exact Algorithm for the k-PD Problem
In this section, we present the first known exact algorithm for the k-PD problem which is actually fixed parameter algorithm when k > 2. The parameter is the partition-distance of the optimal solution. For any migrated pair {x,y} in N between two partitions
Hence, given an instance of the k-PD problem with a parameter ℓ, PD(k,N,ℓ) can be computed as follows:
For clarification, we describe the recursive procedure PD(k,N,ℓ) next.
PD(k,N,ℓ)
Let T(ℓ) be the time of running PD(k, N, ℓ). Clearly, T(ℓ) can be computed by the following recurrence relation:
Hence, the time-complexity of PD(k, N, ℓ) is O(2ℓ · k2 · |N|2).
Let SOPT be the optimal solution to the k-PD problem. For completeness, we give the exact algorithm for the k-PD problem next.
OPT-k-PD
The backtracking of Step 2.1 is that when PD(k, N, ℓ) ← PD(k, {N\x}, ℓ − 1) (respectively, PD(k, N, ℓ) ← PD(k, {N\y}, ℓ − 1)), put the element x (respectively, y) to SOPT. It takes at most O(|N|) time. Clearly, the time-complexity of Algorithm OPT-k-PD is dominated by the cost of Step 2. Hence, Algorithm OPT-k-PD runs in O(ℓ · 2 ℓ · k2 · |N|2) time.
4. Simulations
In this section, we perform our algorithms and then compare the expected performance measurements (respectively, performance ratios) of our approximation and heuristic algorithms with the expected performance measurements (respectively, performance ratios) of the optimal solution for the k-PD problem. We implement our algorithms in C++ and PHP codes. Then we also implement an exact algorithm for the 2-PD problem. The optimal solution of the 2-PD problem can be transformed to the optimal solution of the maximum (Gusfield, 2002) or minimum (Konovalov et al., 2005a) weighted assignment problem, respectively. Many polynomial-time exact algorithms for the maximum or minimum weighted assignment problem had been studied (Burkard et al., 2009). We implement the Kuhn-Munkres algorithm (Kuhn, 2005) which can solve the maximum or minimum weighted assignment problem in O(c3) time, where c is the sum of the number of clusters of both partitions. The exact algorithm of Section 3 is only used to compare the performance ratio with our approximation and heuristic algorithms for k > 2, since the worst-case running time of the exact algorithm is exponential. All algorithms in this article are also available at http://mail.tmue.edu.tw/∼yhchen/KPDP.html.
Although our approximation and heuristic algorithms obtain larger partition-distance than the exact algorithm, the computational speeds of these algorithms are faster than Gusfield's exact algorithm when the maximum number of elements per cluster is less than ρ in practice, where ρ is the maximum number of clusters of these k partitions. Now, we let D(λ, Nmax) denote that a partition has λ clusters and the maximum number of elements per cluster is Nmax. We use three simulated data sets (Butler et al., 2004; Konovalov et al., 2005a). The first data set is to test one partition D(λ, 1), and others are random creating partitions. The second data set is to test one partition D(λ, 10) and others are random creating partitions. Finally, the third data set is to test one partition D(5, 5) and others are random creating partitions for k = 3, 4, 5. These algorithms run on the same workstation Sun Microsystems Sun4u Sun Ultra 5/10 UPA/PCI, cpu type is UltraSPARC-III 300MHZ, and the operating system is Solaris 7.
4.1. Simulation test D(λ, 1)
The first data set comes from the unrelated individuals with insufficient genetic information (i.e., small number of loci and/or alleles) (Butler et al., 2004; Konovalov et al., 2005a). Hence, we construct the first partition D(λ, 1). Other partitions are constructed by λ elements and randomly assign each element to a cluster. The maximum number of clusters of each random partition is less than or equal to λ and the number of elements per cluster is also less than or equal to λ. In this case, Gusfield's algorithm (Gusfield, 2002) runs in O(|N|3) time but our approximation algorithm runs in O(|N|2) time for the 2-PD problem in the worst case. Note that we do not list the expected time of the exact algorithm of Section 3, since it runs in exponential time in the worst case.
Figure 1 presents a few experimental comparisons of expected performance measurements for our approximation algorithm and Gusfield's (2002) algorithm. For example, Butler et al. (2004) reconstructed 50 unrelated individuals described by four loci, each with four alleles per loci. Hence, an instance of the first partition is D(50, 1). In the case, an expected time of our approximation algorithm runs in 2.6ms and Gusfield's (2002) algorithm runs in 15ms for k = 2. We also simulate our approximation algorithm for k = 5 and k = 10, respectively. It is clear that our approximation algorithm runs faster than Gusfield's (2002) algorithm from Figure 1.
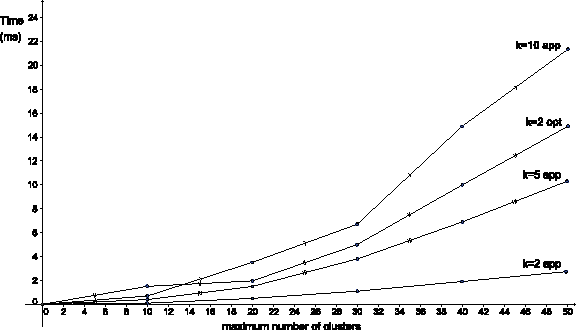
Each performance measurement is obtained to find partition-distance and consensus partition on the simulation set D(λ, 1) and other random partitions. Each point is an average over 100 instances with ± 0.004 SD.
Table 2 shows the performance ratios that are the 2-approximation solution over the optimal solution and the heuristic solution over the optimal solution on the simulation set D(λ, 1) and two random partitions (i.e., k = 3). It is clear that Table 2 shows that the partition-distances of our solutions are at most twice the partition-distances of the optimal solutions.
Each value is an average over 100 instances with ±0.02 SD.
4.2. Simulation test D(λ, 10)
The second data set is settled to simulate possible outcomes of accuracy testing in Butler et al. (2004) and Konovalov et al. (2005a) for a number of clusters, and each cluster contains ten individuals. Hence, we construct the first simulated partition D(λ, 10) which is λ clusters with each cluster containing 10 elements. Other partitions are constructed λ * 10 elements and randomly assign each element to a cluster. The maximum number of clusters of each random partition is less than or equal to λ and the number of elements per cluster is less than or equal to λ. Note that we also do not list the expected time of the exact algorithm of Section 3, since it runs in exponential time in the worst case.
Figure 2 illustrates a few experimental comparisons of expected performance measurements for Gusfield's (2002) algorithm and our approximation algorithm. For example, Konovalov et al. (2005a) reconstructed 50*10 individuals from 50 families each containing 10 full siblings. Hence, an instance of the first partition is D(50, 10). In the case, an expected time of our approximation algorithm runs in 16.3ms and Gusfield's (2002) algorithm runs in 36.3ms for k = 2. We also simulate our approximation algorithm for k = 5 and k = 10, respectively. It is also clear that our approximation algorithm runs faster than Gusfield's (2002) algorithm from Figure 2.

The same as in Figure 1 but for the simulation set D(λ, 10) and other random partitions when k=2, k=5 and k=10. Each value is an average over 100 instances with ±0.005 SD.
Table 3 shows the performance ratios that are the 2-approximation solution over the optimal solution and the heuristic solution over the optimal solution on the simulation set D(λ, 10) and a random partition (i.e., k = 2). It is also clear that Table 3 shows that the partition-distances of our solutions are at most twice the partition-distances of the optimal solutions.
Each value is an average over 100 instances with ±0.02 SD.
4.3. Simulation test for k = 3, 4, 5
In this section, we simulate some random data for k = 3, 4, 5. The third data set is settled to simulate possible outcomes for five clusters and each cluster contains five individuals. We construct the first simulated partition D(5, 5) which is 5 clusters with each cluster containing 5 elements. Other partitions are constructed 25 elements and randomly assign each element to a cluster. The maximum number of clusters of each random partition is less than or equal to 5 and the number of elements per cluster is less than or equal to 25.
Table 4 shows the performance ratios that are the 2-approximation solution over the optimal solution and the heuristic solution over the optimal solution on the simulation set D(5, 5) and other random partitions for k = 3, 4, 5. It is also clear that Table 4 shows that the partition-distances of our solutions are at most twice the partition-distances of the optimal solutions.
Each value is an average over 100 instances with ±0.0018 SD.
4.4. Interactive website version
A website to implement Gusfield's (2002) and our algorithms is available at http://mail.tmue.edu.tw/∼yhchen/KPDP.html. We give five input types: (1) user mode, (2) random mode, (3) D(λ, 1) mode, (4) D(λ, 10) mode, and (5) D(λ, any) mode. And we give four algorithms: (a) 2-approximation algorithm, (b) heuristic algorithm, (c) Gusfield's (2002) algorithm (i.e., an exact algorithm for the 2-PD problem), and (d) exact algorithm for k > 2. Before activating the algorithms on the website, you need to fill in the number of partitions (k), the maximum number of clusters of these k partitions (ρ), the maximum number of elements per cluster (Nmax), the number of elements (|N|), and select an input type. If you select the user mode, you need to fill in each element to its cluster for each partition Pi, 1 ≤ i ≤ k sequentially. If you choose (3) and (4) modes, all partitions are generated by Sections 4.1 and 4.2, respectively. If you choose (5) mode, you need to fill in each element to its cluster for the first partition P1, sequentially. Other partitions are randomly generated. After the aforementioned settings, you merely select one algorithm and enter “Run” button to obtain the corresponding solutions to the k-PD problem.
5. Conclusion
In this article, we have shown the first known exact, heuristic, and 2-approximation algorithms for the k-PD problem. It would be interesting and challenging to find a better exact or approximation algorithm for the k-PD problem. Another interesting topic for future research could involve studying whether the 2-PD problem can be exactly solved in O(ρ · |N|) time.
Footnotes
Acknowledgments
We would like to thank Prof. Shyong Jian Shyu and the anonymous referees, whose useful comments helped to improve this article. This work was supported in part by the National Science Council of the Republic of China under Contract NSC NSC 98-2221-E-133-002.
Disclosure Statement
No competing financial interests exist.