
Abstract
Abstract
Cryo-electron microscopy (cryo-EM) plays an increasingly prominent role in structure elucidation of macromolecular assemblies. Advances in experimental instrumentation and computational power have spawned numerous cryo-EM studies of large biomolecular complexes resulting in the reconstruction of three-dimensional density maps at intermediate and low resolution. In this resolution range, identification and interpretation of structural elements and modeling of biomolecular structure with atomic detail becomes problematic. In this article, we present a novel algorithm that enhances the resolution of intermediate- and low-resolution density maps. Our underlying assumption is to model the low-resolution density map as a blurred and possibly noise-corrupted version of an unknown high-resolution map that we seek to recover by deconvolution. By exploiting the nonnegativity of both the high-resolution map and blur kernel, we derive multiplicative updates reminiscent of those used in nonnegative matrix factorization. Our framework allows for easy incorporation of additional prior knowledge such as smoothness and sparseness, on both the sharpened density map and the blur kernel. A probabilistic formulation enables us to derive updates for the hyperparameters; therefore, our approach has no parameter that needs adjustment. We apply the algorithm to simulated three-dimensional electron microscopic data. We show that our method provides better resolved density maps when compared with B-factor sharpening, especially in the presence of noise. Moreover, our method can use additional information provided by homologous structures, which helps to improve the resolution even further.
1. Introduction
B-factor sharpening (DeLaBarre and Brunger, 2006; Rosenthal and Henderson, 2003; Fernández et al., 2008) is often advocated as a method for improving the resolution of density maps. The method operates in the frequency domain and applies a negative B-factor to the Fourier coefficients of the density map. This has the effect that high-frequency components encoding high-resolution features are amplified. B-factor sharpening has several limitations: First, the underlying model of the PSF is an isotropic Gaussian whose width is determined by the magnitude of the overall B-factor (the Fourier transform of a Gaussian is a Gaussian with inverted width); this assumption may be inappropriate for anisotropic data such as 2D crystals. Second, the method suffers from amplification of noise; noise in density maps contributes high-frequency components, which are weighted up when applying a negative B-factor. Third, it is not possible to incorporate prior knowledge to regularize the recovered high-resolution density map; for example, the B-factor sharpened density map is not guaranteed to be nonnegative.
In this article, we present a novel algorithm to sharpen electron density maps. The algorithm remedies some of the shortcomings of thermal factor sharpening. The underlying assumption is that low- to intermediate-resolution density maps can be viewed as distorted or “blurred” versions of high-resolution maps. Mathematically, this blurring process is modeled as a convolution
where y denotes the observed blurry and noisy low-resolution map, x the true high-resolution map, f the linear shift-invariant blur kernel or point spread function (PSF), and * the linear convolution operator.
We propose a blind deconvolution method (BD) to sharpen electron density maps. BD aims to invert the blurring process and thereby recover the high-resolution map without any knowledge on the degradation or blur kernel. It does so by estimating the sharpened density map and the PSF simultaneously. In this article, we are interested in BD algorithms that do not assume a particular structural model and that are in this sense parameter-free. The recovered high-resolution map will be useful for density map interpretation and model fitting.
Blind deconvolution is a severely ill-posed problem, because there exists an infinite number of solutions and small perturbations in the data lead to large distortions in the estimated true map. The ill-posedness may be alleviated by confining the set of admissible maps to those that are physically plausible through the introduction of additional constraints. One such constraint is that electron density maps are inherently nonnegative. We show that nonnegative blind deconvolution (NNBD) can be cast into a set of coupled quadratic programs that are solved using the multiplicative updates proposed in Sha et al. (2007). No learning rate has to be adjusted, and convergence of the updates is guaranteed. By iterating between an update step for x and f, we obtain an efficient BD algorithm that allows for straightforward incorporation of prior knowledge such as sparseness and smoothness of the true map and/or the PSF.
Blind deconvolution is a valuable tool in many image and signal processing applications such as computational photography, astronomy, microscopy, and medical imaging, and thus has been treated in numerous publications. Many blind deconvolution algorithms have been proposed in various fields of research (Kundur and Hatzinakos, 1996; Starck et al., 2002; Sarder and Nehorai, 2006; Levin et al., 2009). However, to our knowledge, it has never been proposed in the field of cryo-EM.
2. Blind Deconvolution by Nonnegative Quadratic Programming
Our generative model underlying the image formation process is
where the degraded map y, the PSF f and the true map x are n-dimensional.1 Assuming additive Gaussian noise with zero mean and variance τ−1, the likelihood of observing y is given by
where ‖·‖ denotes the L2-norm and Z the normalizing partition function, which depends only on the precision τ. As a prior, we constrain f and x to be of finite size and to lie in the nonnegative orthant: p(x) ∝ χ(x ≥ 0) and p(f) ∝ χ(f ≥ 0) where χ is the indicator function. Computation of the maximum a posteriori (MAP) estimate of f and x is equivalent to the nonnegatively constrained problem of minimizing the negative log-likelihood viewed as a function of the unknown parameters f and x:
Here, the negative log-likelihood L is expressed in units of τ and constants independent of f and x have been dropped. Because of the interdependence of f and x through the convolution, optimization problem (2) is non-convex and a globally optimal solution cannot be found efficiently. Fortunately, the objective function L(f, x) is sufficiently well-behaved as it is convex in each variable separately if the other is held fixed. This observation suggests a simple alternating descent scheme: instead of minimizing (2) directly, we iteratively solve the minimization problems minf ≥ 0 L(f) and minx ≥ 0 L(x), where L(f), L(x) denotes L(f, x) for fixed f, x, respectively. If we can ensure descent in each step, we will obtain a sequence of estimates {f(k), x(k)} that never increase the objective L(f, x). Due to the symmetry of the convolution operation, f * x = x * f, we can restrict our exposition to the optimization of x; equivalent results will hold for f.
Because convolution is a bilinear operation, the problem of optimizing x can be written in matrix notation:
where in this formulation y, x, and f are zero-padded vectors stacked in lexicographical order and F is a block-Toeplitz structured matrix. In the following, we will use both notations interchangeably; the type of the involved quantities will be clear from the context. Minimizing (3) is equivalent to solving a quadratic program with nonnegativity constraint (NNQP)
with A = FTF and b = −FTy. Recently, a novel algorithm for solving NNQPs based on multiplicative updates has been proposed (Sha et al., 2007). In the derivation of the updates, only the positive semidefiniteness of A is required. In particular, A may have negative entries off-diagonal. The key idea is to decompose A into its positive and negative part, i.e., A = A+ − A− where
As shown in Sha et al. (2007), a valid auxiliary function for (4) is given by
Minimization of (5) with respect to its first argument yields the update:
The symbol ⨀ denotes voxel-wise multiplication; also, division and square root are understood voxel-wise. For a nonnegative observed map y with A+ = FTF, A− = 0 and b = −FTy, update (6) reads
Contrary to previous approaches to NNQP (Johnston et al., 2000), no learning rate is involved that needs adjustment. Furthermore, convergence to a global optimum is guaranteed. Note that, as f * x approaches y, the multiplicative factor in (7) tends to one. The update rules can be computed very efficiently using the Fast Fourier Transform (Press et al., 2007) because
and
where
Coming back to our original problem, namely solving (2) jointly in x and f, we propose to iterate between update steps in x and f. Cycling between (7) and (8) ensures that both f and x will remain in the nonnegative orthant. Although multiplicative updates guarantee convergence to a global optimum in the case of NNQP, the proposed NNBD scheme only ensures convergence to a stationary point. Therefore, the solution might be sensitive to the initial values of x and f. In our experiments, however, initialization was never a problem: choosing flat maps for the initial x and f always led to good results. Algorithm (1) summarizes our NNBD approach.
Nonnegative Blind Deconvolution
3. Incorporation of Prior Knowledge
In the absence of noise as well as in the case of high signal-to-noise ratios2 (SNRs), our algorithm correctly decomposes a blurry observation into the true underlying map and the corresponding PSF.3 Figure 1 shows a simulated one-dimensional toy example, where x is an equispaced sample of a Gaussian mixture model and f is chosen such that it is irreducible.4 The estimated map
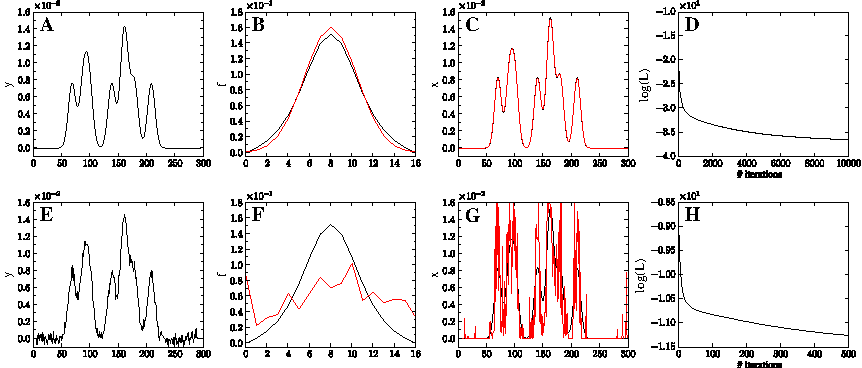
One-dimensional toy example. Top row: Results of NNBD at SNR of 60 dB. Bottom row: SNR 20 dB. (
To further constrain the space of admissible solutions, additional knowledge about the unknown map and the PSF has to be utilized. This knowledge will be represented by non-uniform prior distributions p(f|θ) and p(x|θ) on f and x, respectively, involving hyperparameters θ. With p(θ) denoting the prior of the hyperparameters, the joint posterior is proportional to:
In the following, we describe prior distributions that are compatible with the multiplicative updates for f and x derived in the previous section. Again, because of the symmetry of (2) in f and x, we will restrict ourselves to the incorporation of prior knowledge on the unknown map x.
Incorporating priors on x introduces additional terms in (3) that have to be taken into account in the computation of the MAP estimate. In the derivation of the multiplicative update rule (6), we minimized the auxiliary function (5) defining an upper bound on L(x). A close look reveals that all priors whose negative logarithm comprises terms that are either linear, quadratic, or logarithmic in x can be incorporated into (5) and hence are compatible with the update (6). This includes the following priors:
Note that ‖∇x‖2 can be rewritten as xTΔx where
where the second equality holds for nonnegative maps.
We treat the background as a variable that we learn along with f and x using analogous multipli-cative updates. In the following, we will refer to this regularization term as orthogonality constraint. Of course, z could be constant if such knowledge is available.
The Burg entropy ∑ i log xi is compliant with the auxiliary function G(x, x′) and favors maximum entropy maps, i.e., constant maps. Entropy and sparseness/orthogonality can be combined into a single prior density: a voxel-wise Gamma distribution.
Table 1 summarizes the presented prior distributions and the required modifications in (6).
Δ+ and Δ− refer to the decomposition of the negative Laplacian Δ = Δ+ − Δ−. diag{x} is a diagonal matrix with entries xi.
3.1. Estimation of hyperparameters
An important aspect is the estimation of the unknown hyperparameters. Instead of resorting to heuristics or cross-validation, we use Bayesian inference to estimate the hyperparameters θ. For all hyperpriors introduced in the previous section, the Gamma distribution G(θ|α,β) is a conjugate prior. The ideal approach to hyperparameter estimation would be to calculate their marginal posterior distribution
and determine the mean or mode (Mackay, 1996). In our case, however, exact integration over f and x is infeasible. One would have to resort to computationally intensive methods like Markov chain Monte Carlo or alternatives such as variational (Molina et al., 2006) or approximate inference (Lin and Lee, 2005). Therefore, we pursue the much simpler approach of computing the MAP estimate of the joint posterior, i.e.,
where
3.2. Remarks
Let us come back to the one-dimensional toy example at low SNR (Fig. 1).
Figure 2A–D shows how enforcing smoothness of the signal using prior (10) prevents unfavorable noise-fitting, and effectively helps us to recover the original signal and the PSF from the blurred and noisy observation. We further investigated the estimation of the regularization parameter λ. We tested different fixed values for λ and compared the reconstruction error of and the correlation with the true signal when applying our hierachical Bayes approach. Figure 2E, F shows that the Bayes procedure yields a minimal reconstruction error and a maximal correlation for a wide range of fixed λ values. The evolution of the regularization parameter (Fig. 2G) reveals an important feature of our deconvolution algorithm. Starting at a small initial value, the regularization parameter increases rapidly within a few iterations, after which it gradually converges to a smaller optimal value. This finding may justify the heuristic regularization scheme of Shan et al. (2008), which seems to be crucial for the success of their BD algorithm on natural images (Levin et al., 2009). Shan et al. (2009) propose to start the deconvolution with a large value of λ—a conservative choice that puts higher weight on the prior than on the data. As the deconvolution improves, the regularization parameter is decreased to put more and more weight on the data. This is similar to simulated or deterministic annealing, which aims to avoid trapping in sub-optimal local minima. The advantage of our approach is that, contrary to Shan et al. (2008), we do not need to choose a schedule for adjusting λ. Rather, our update procedure automatically balances the influence of the data versus the importance of the prior.
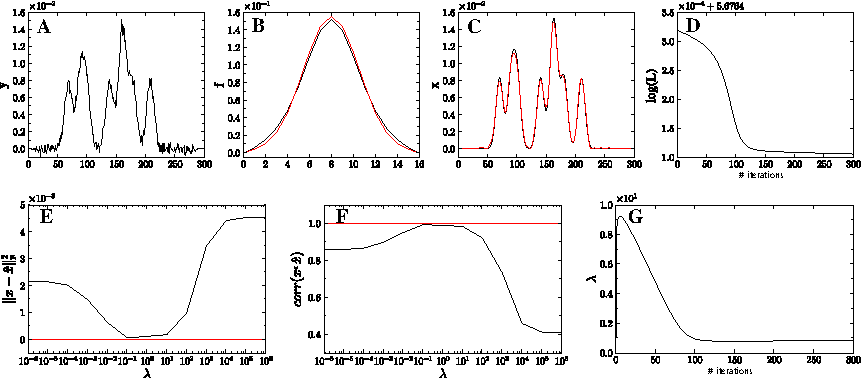
One-dimensional toy example. Top row: Results of NNBD at a SNR of 20 dB.
4. Applications
To evaluate the performance of our model and verify its validity, we applied our algorithm to simulated three-dimensional density maps with a sampling of 1 Å/voxel. We used the program pdb2mrc from the EMAN software package (Ludtke et al., 1999) for density map simulation. First, we use nonnegative blind deconvolution to sharpen electron density maps. In the second application, we demonstrate the capabilities of our approach and the usefulness of the orthogonality prior by incorporating homologous structure information in the deconvolution.
4.1. Electron density maps of proteins
For validation, we used a monomer of the trimer of the bluetongue virus capsid protein VP7 (PDB ID: 2BTV) (Grimes et al., 1998). Figure 3A shows the molecular structure, Figure 3B the simulated electron density map at 10 Å resolution, and Figure 3C the corresponding PSF. Figure 3D–F shows the density map reconstructed with NNBD, the molecular structure fitted into it, and the estimated PSF. The sharpened map reveals the nature of most secondary structure elements, whereas the original density map provides ambiguous secondary structure information. Also side chains become visible, which is important for modeling atomic details. To quantify the gain in resolution, we computed the correlation coefficient between the sharpened map and density maps simulated at higher resolutions. Figure 3G shows that the correlation coefficient is highest for a density map at a resolution of 6 Å. Hence, our algorithm is able to sharpen the original map and to improve its resolution by almost a factor of two. Figure 3C,F depicts the true and estimated PSFs. The overall shape and functional form is determined correctly; however, the estimated bandwith appears to be smaller. This shrinkage of the PSF is largely due to the smoothness prior that downweights high-frequency components, which causes a loss of structural details but, at the same time, prevents amplification of noise. In this sense, underestimation of the bandwidth is conservative and should be viewed as a feature rather than a shortcoming.

NNBD for the electron density map of the monomer of the bluetongue virus outer shell coat protein VP7 (PDB ID: 2BTV). Top row: (

Further insight is obtained by looking at the Guinier plot (Fig. 3H) showing the radially averaged power spectrum against the squared resolution. In physical terms, the Guinier plot quantifies the map's energy content at various spatial frequencies. Blurring has the effect that the Guinier plot drops off quite rapidly; convolution with a broad PSF acts as a low-pass filter that deletes all information above a certain cutoff frequency. The NNBD algorithm is able to recover high-frequency information to a large extent and lifts the Guinier curve above the curve of the simulated density map at a resolution of 6 Å (orange line in Fig. 3H).
To study the influence of noise, we corrupted the simulated density maps with Gaussian noise at different SNRs. We used the program proc3d from the EMAN software package (Ludtke et al., 1999) for noise corruption. Figure 4A shows a noisy 10 Å-density map at a SNR of 6 dB. Figure 4B shows the corresponding NNBD reconstruction using a smoothness prior (10). For comparison, Figure 4C shows the density map sharpened with embfactor (Fernández et al., 2008; Rosenthal and Henderson, 2003), the state-of-the-art method within the field.
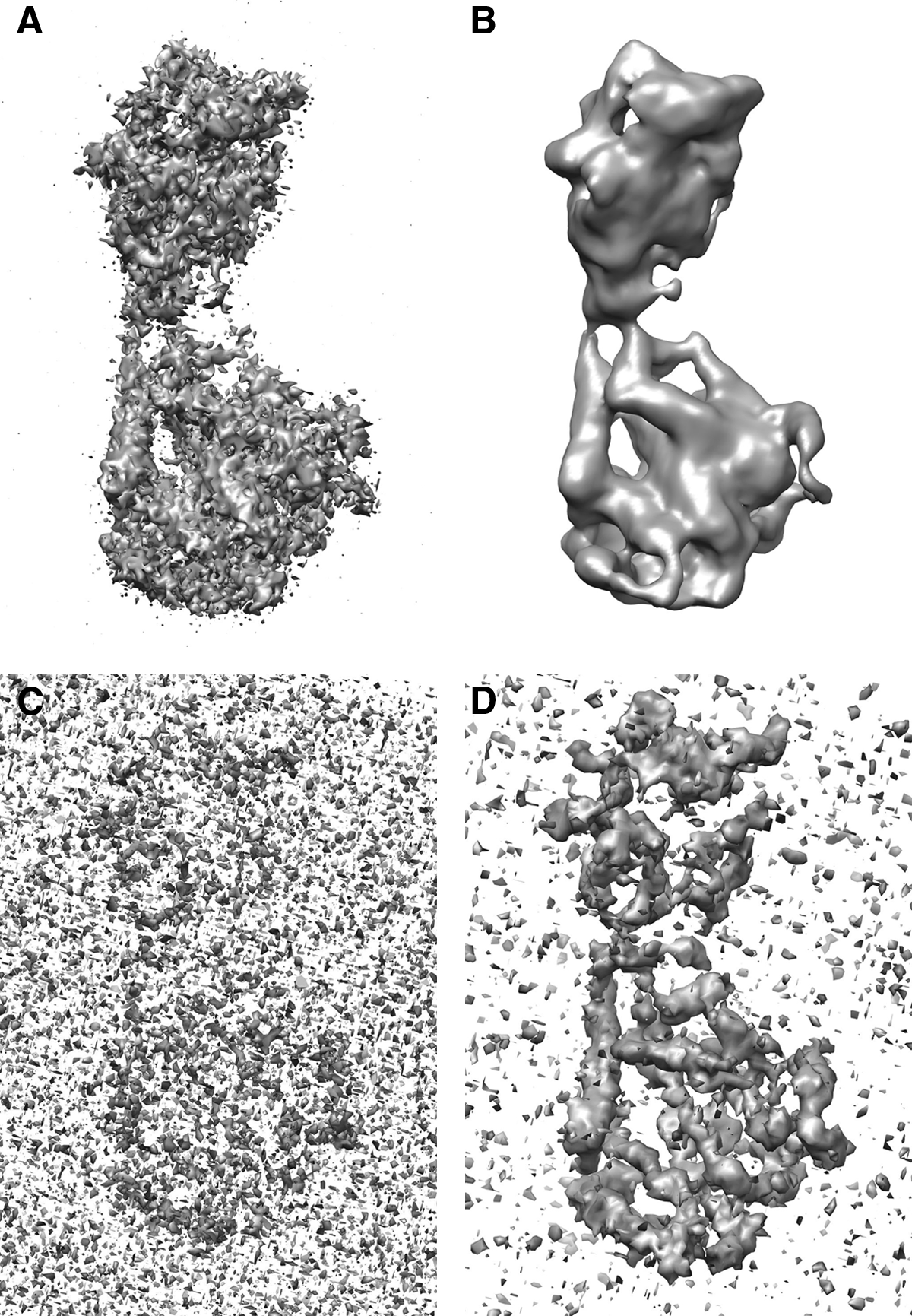
NNBD for the electron density map of the monomer of the bluetongue virus outer shell coat protein VP7 (PDB ID: 2BTV).
4.2. Incorporating homologous structure information
We now demonstrate how additional information from homologous structures can be incorporated to aid the deconvolution process and to detect secondary structure. We use the trimeric structure of the bluetongue virus capsid protein VP7 (PDB ID: 2BTV) as an example. Figure 5A–C shows the molecular structure, and a top and side view of the simulated density of 2BTV at a resolution of 8 Å. The protein is made up of β-sheets and α-helices in the upper and lower domains, respectively. The African horse sickness virus capsid protein (PDB ID: 1AHS) is a close structural homologue (RMSD: 1.4 Å) to the all-beta domain of 2BTV. Figure 5D–F displays the molecular structure, the simulated density at a resolution of 8 Å, and the fit of 1AHS into 2BTV provided by FOLDHUNTER (Jiang et al., 2001). In B-factor sharpening, information from homologous folds is used to compute the optimal B-factor for density sharpening. In our blind deconvolution approach, we model the observed density map as being composed of the homologous structure simulated at a higher resolution and the remainder density of 2BTV. The density of the homologous fold is held fixed; only the missing density and the PSF are estimated during the deconvolution. As initial PSF, we use a Gaussian at 6 Å resolution corresponding to the resolution difference between the high-resolution density of 1AHS at 2 Å and the experimental density. During reconstruction, we apply the orthogonality constraint (12) to enforce that the 1AHS density and the unexplained region of 2BTV do not overlap. The result of NNBD is shown in Figure 5G–I. As visible in the closeup (Fig. 5I), the sharpenend density map reveals sidechains and information with almost atomic resolution. Figure 6A–C compares the true PSF and the PSFs estimated by NNBD with and without homologous structure. As in the previous example, the width of the PSF is underestimated due to the smoothness prior. However, the additional structural information facilitates a more accurate estimation of the PSF (Fig. 6C) and thereby allows the restoration of a high-resolution density map (Fig. 5I). The Guinier plot (Fig. 6D) illustrates the improved recovery of high-frequency information and the increase in resolution.
NNBD for the electron density map of the bluetongue virus capsid protein (PDB ID: 2BTV) using additional structural information from a homologous fold. Top row:

Comparison of true PSF
5. Conclusion
We propose a new method for improving the resolution of cryo-EM density maps by nonnegative blind deconvolution. We provide an iterative algorithm for learning simultaneously the sharpened density map and the blur kernel. We illustrate the generality of the proposed framework and show that the derived updates allow for easy incorporation of prior knowledge such as smoothness and sparseness.The updates are multiplicative and do not require the adjustment of a learning rate, as opposed to previously proposed gradient descent techniques. In addition, the updates ensure the nonnegativity of the sharp map and the PSF and guarantee convergence to a stationary point. A hierarchical Bayesian formulation also allows us to derive update rules for the hyperparameters; thus, the method is fully parameter-free. The simplicity of the multiplicative updates allows for straightforward implementation. By employing the Fast Fourier Transform, we can reduce the computational complexity to a large extent, such that even medium and large sized problems (number of voxels > 107) can be tackled efficiently. Computation time is typically on the order of minutes to hours for large-density maps (> 4003) depending on the number of iterations one is willing to perform. Since our method allows the inspection of intermediate results, the user can decide when to stop, either by visual inspection or by a user-set threshold of the monotonically decreasing cost function. We illustrate the performance and versatility of our algorithm by sharpening simulated electron density maps of the bluetongue virus capsid protein VP7 and by incorporating homologous structure information into the deconvolution process. We are currently applying our method to experimental density maps. Initial results confirm that NNDB is a flexible and generic tool to improve the resolution of electron density maps.
Footnotes
Disclosure Statement
No competing financial interests exist.
New affiliation: Max Planck Institute for Metals Research, Stuttgart, Germany.
1
The convolution is assumed to be non-circular and its value is taken only on its valid part, i.e. in the one-dimensional case, if
2
Here, we define the SNR of a signal as
3
Note that this is true only up to an overall scaling factor, because for each estimate
4
A signal x is irreducible, if it cannot be decomposed into two or more nontrivial components