
Abstract
Abstract
Imposing constraints in the form of a finite automaton or a regular expression is an effective way to incorporate additional a priori knowledge into sequence alignment procedures. With this motivation, the Regular Expression Constrained Sequence Alignment Problem was introduced, which proposed an O(n2t4) time and O(n2t2) space algorithm for solving it, where n is the length of the input strings and t is the number of states in the input non-deterministic automaton. A faster O(n2t3) time algorithm for the same problem was subsequently proposed. In this article, we further speed up the algorithms for Regular Language Constrained Sequence Alignment by reducing their worst case time complexity bound to O(n2t3/log t). This is done by establishing an optimal bound on the size of Straight-Line Programs solving the maxima computation subproblem of the basic dynamic programming algorithm. We also study another solution based on a Steiner Tree computation. While it does not improve the worst case, our simulations show that both approaches are efficient in practice, especially when the input automata are dense.
1. Introduction
Arslan (2007) introduced the Regular Expression Constrained Sequence Alignment Problem. Here, the constraint is given in the form of a non-deterministic finite automaton (NFA). An alignment satisfies the constraint if a segment of it is accepted by the NFA in each aligned sequence (Fig. 1). Arslan's dynamic programming algorithm is based on applying an NFA, with scores assigned to its states, to guide the sequence alignment. This NFA accepts all alignments of the two input strings containing a segment that fits the input regular language. The algorithm yields O(n2t4) time and O(n2t2) space complexities, where n is the sequence length and t is the number of states in the NFA expressing the constraint. The algorithm simulates copies of this automaton on alignments, updating state scores, as dictated by the underlying scoring scheme. Chung et al. (2007b) proposed an improvement to the above algorithm, yielding O(n2t3) time and O(n2t2) space complexities, in the general case, by splitting the computation into two steps. This algorithm is described in detail in Section 1.3.

Examples of a sequence alignment and a regular language constrained sequence alignment. Sequence alignment and a regular language constrained sequence alignment on the two strings CACGAG and CAGCGCGA, with a scoring matrix (−1 for mismatch/insert/delete, 1 for match).
1.1. Our contribution
In this article, we further speed up the algorithms for Regular Language Constrained Sequence Alignment by reducing their worst case time complexity bound to O(n2t3/ log t). This is done by establishing an optimal bound on the size of Straight-Line Programs (SLP) solving the maxima computation subproblem of the basic dynamic programming algorithm. We also study another solution based on a Steiner Tree computation. While it does not improve the worst case, our simulations show that both approaches are efficient in practice, especially when the input automata are dense.
1.2. Preliminaries and definitions
Let Σ be a finite alphabet. Let
Let LR be a regular language and let A = (Q, Σ, δ, q0, FA) be an NFA with t states, such that L(A) = LR. We use a fixed numbering of the states in Q,
Definition 1
(Regular Language Constrained Sequence Alignment). Given two strings a and b, over a fixed alphabet Σ, a scoring function s and an NFA A. Find an alignment (X, Y) of a and b such that it is the alignment with the maximal score under s which satisfies the following condition: indices i and j exist such that
1.3. An overview of previous work
Arslan's algorithm defines an NFA M, such that the states of M are the ordered pairs of states of A, therefore, it has O(t2) reachable states. M is defined over the alphabet Σ′ × Σ′. For every two transitions
In the following recurrence formula for Ti,j, we move from the notion of the alignment automaton M in Arslan to a simpler formulation. As a first step, we add to A transitions
The initialization consists of assigning 0 to T0,0(q0, q0) and − ∞ elsewhere. We define max ∅ = − ∞. The optimal alignment score is
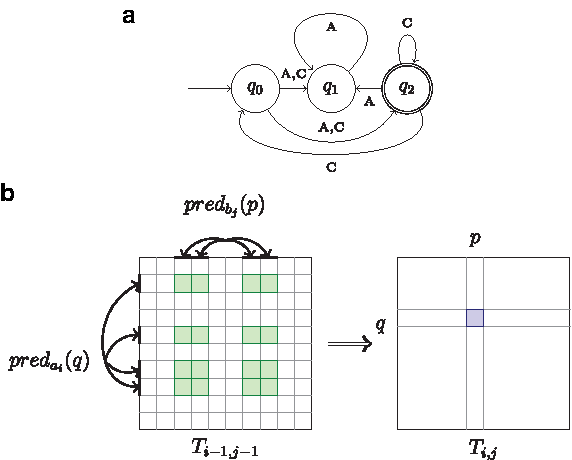
The algorithm of Chung et al. (2007b) exploits the following redundancy: Given that M is an NFA with |δ| = O(t2) states, and assuming no additional knowledge of M, it can be concluded that M can potentially have O(t4) transitions. Thus, Arslan's algorithm iterates over all possibilities of two states of M in each Ti,j calculation. However, it is known, according to the way M was built, that each transition in M originates from at most two transitions in A. The iteration over the two possible transitions can be done independently of each other.
Chung et al. (2007b) improved the time complexity of Arslan's algorithm by removing redundant computations which were due to the fact that the computed value is based on two independent optimum calculations, one for each of the compared strings. We next describe Chung et al.'s algorithm using our own notation, in Eq. 3 and Eq. 4. The calculation of (*) is split into two steps using an intermediate table L (Fig. 3).
In the first step (Eq. 3), the size of the set, over which the maximum is calculated for every pair of states (q, p′), depends on the existing transitions with the letter ai. Since the size of the set is bounded (i.e., |predai(q)| ≤ t), this step takes O(t3) time. The same argument holds for the second step (Eq. 4). In summary, their algorithm improved the time complexity to O(n2t|δ|) = O(n2t3), while maintaining the same space complexity.
2. A Faster Algorithm
2.1. Eliminating duplicate computations
It is apparent from Eq. (3) and Eq. (4) that the calculation of Li,j, for a specific value of p′ and ranging over q, computes the maximum for subsets of indices of column p′ of Ti−1,j−1, while the calculation of Ti,j, for a specific value of q and ranging over p, computes the maximum for subsets of indices of the qth row of Li,j (Fig. 3). The structure of the NFA transition table, namely the relations between the predc sets, can be used to reduce the number of components required in consecutive subset maxima calculations. For instance, let us assume that a state q′ is included both in predc(q1) and predc(q2) for q1 ≠ q2. Then, for a given state p, the score Ti−1,j−1(q′, p) is taken into account in calculations of both Li,j(q1, p) and Li,j(q2, p) (Fig. 4). By minimizing the repetition of score usage, the efficiency of the calculation of Eq. (3) and Eq. (4) can be improved.
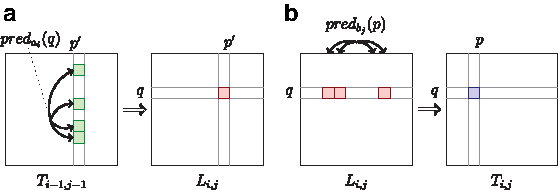
Score calculation performed by Chung et al.'s algorithm.
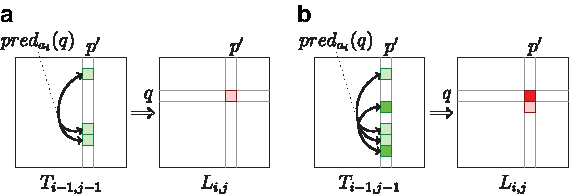
Similar and duplicate score calculations in Chung et al.'s algorithm can be reused.
Following this observation, the goal of speeding up the calculation of Eq. (3) and Eq. (4) can be formulated as a question: What is the most efficient way to calculate maximum values over given, possibly overlapping, sets of scores? Thus, the general subproblem underlying the speed up of these algorithms can be formulated as follows.
Definition 2
(Subsets Maxima Problem). Let W be a set of scores, with |W| = t and let
For Eq. 3, having fixed values of i, j and p′, the set of scores W consists of t scores in Ti−1, j−1 and V consists of scores which correspond to all possible
The values of W and V are similarly established for Eq. 4.
We represent each subset vk in V by a Boolean vector, where the lth bit reflects the membership of the lth score in the subset
2.2. An algorithm based on a Steiner minimal directed tree
In this section, we explore the possibility of employing Steiner minimal directed trees to solve the Subsets Maxima Problem. We show that the size of a Steiner minimal directed tree for a tuple of Boolean vectors S, as described above, is not greater than the number of transitions of the NFA. Thus, using a heuristic algorithm for Steiner minimal directed trees improves the run-time of our solution to Regular Language Constrained Alignment in practice, as demonstrated by our simulations (see Section 3). But first, we give a formal definition of Steiner minimal directed trees and review related work.
There are several Steiner tree problems studied in the literature. The general Steiner tree problem is the problem of spanning a subset of vertices of a (directed or undirected) graph, while including a minimal number of additional nodes. The problem is NP-hard (Bern and Plassmann, 1989; Shi and Su, 2006). Here, we are interested in the Steiner minimal directed tree problem in a specific graph, namely the Hamming hypercube. In the Hamming hypercube, the Hamming distance between any two adjacent nodes of the tree, v and u, is 1. That is, either u has exactly one 1-valued bit which is 0-valued in v or vice versa. This version of the Steiner minimal tree problem is also NP-hard (Foulds and Graham, 1982). There are several heuristic solutions for these problems (Jia et al., 2004; Lin and Ni, 1993; Sheu and Yang, 2001).
Definition 3
(The Steiner Minimal Directed Tree Problem for Hamming Hypercubes). Given a set S of k d-dimensional points, find a rooted tree in the Hd Hamming hypercube that spans S, has the minimal possible size N and all edges are directed away from the root (For all v and u such that v is the parent of u in the tree, u has exactly one 1-valued bit which is 0-valued in v.)
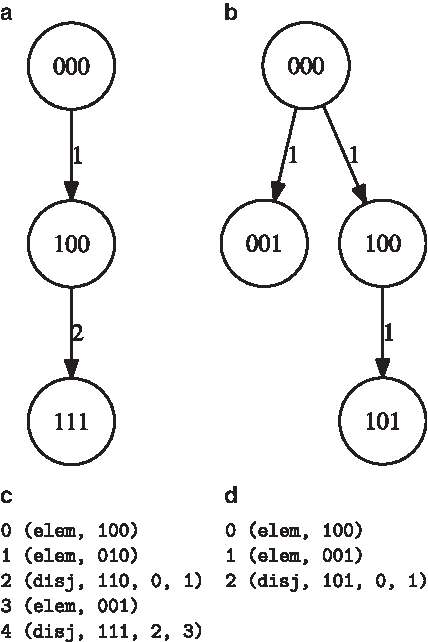
Given a Steiner minimal directed tree for a tuple of Boolean vectors, S, the subsets maxima of the corresponding weight-subsets tuple, V, can be calculated by traversing the tree in a top-down fashion. The reader is referred to Figure 5a,b for an example of the construction of Steiner trees for a specific NFA.
Theorem 1
(upper bound of |δ| for the size of the Steiner Minimal Directed Tree). Let A = (Q, Σ, δ, q0, FA) be an NFA and let Sc, for
Theorem 2
(lower bound). The size of the minimal Steiner tree for a set S of size t is N = Ω(t2).
From theorems 1 and 2, it follows that the size of the Steiner minimal tree is N = Θ(t2) in the worst case. Thus, our Steiner-based algorithm, in the framework of Chung et al., runs in O(n2t3) time. In Section 3, we compare the sizes of heuristic Steiner directed trees with the sizes of the corresponding transition tables for simulated NFAs. Our simulations show that, even though the Steiner-based algorithm does not yield the theoretical bounds obtained for SLPs, in practice it performs very well.
2.3. A solution to subsets maxima via SLPs
We start by introducing the notion of a Straight-Line Program with Boolean operations.
Definition 4
(SLP with Boolean operations). We are given a tuple of t Boolean vectors
An SLP computes the left-hand side vectors of its instructions
The Subsets Maxima Problem can be reduced to the problem of finding the shortest possible SLP with Boolean operations. In order to use SLPs for the task of subsets maxima calculation, we represent V as a tuple of Boolean vectors, S, as described in Subsection 2.1. Given an SLP for S, the subsets maxima can be calculated by following the SLP in linear order: if βh is an elementary vector, having the ith bit equal to 1, the vector is assigned the value of the ith score and if βh is a binary disjunction of βj and βk, then it is assigned the value of the maximum of their assigned scores. If βh represents a subset from V, its score is reported.
The reader is referred to Figure 5c,d for an example of the constructions of SLPs for a specific NFA. These constructions take as input the example NFA appearing in Figure 2a. SLP operation types “elementary vector” and “disjunction” are abbreviated.
For the purpose of utilizing SLPs for the Subsets Maxima Problem, in the rest of this section we address the following goal: given a tuple S of t Boolean vectors of length t, construct an SLP for S of minimal length. This goal is achieved via the following two theorems.
Theorem 3
(upper bound). An SLP for S can be generated such that: (1)
Split each vector of S into b = t/ log t blocks of length log t. Each block has 2log t = t possible values. For each i = 1.b, consider the set of all block vectors, denoted Wi, such that block i takes all possible values and the other blocks are all 0-valued bits. All vectors of Wi can be generated incrementally with t operations (in a bottom-up fashion): First all vectors in Wi which have a single 1-valued bit are generated, then all vectors in Wi which have two 1-valued bits are generated by the disjunction of two vectors in Wi with a single 1-valued bit. In general, all vectors in Wi which have j + 1 1-valued bits are generated by adding disjunction operations between vectors in Wi which have j 1-valued bits and vectors in Wi with one 1-valued bit. Therefore, there are a total of
Each vector of S can then be generated in b − 1 disjunction operations from pre-computed block vectors and there are t vectors in S. All the vectors of S are, therefore, computed by adding t(b − 1) ≤ t2/log t operations to the SLP.
The length of the underlying SLP constructed here, equals the number of disjunction and elementary operations, summed over both stages (block vector creation plus computing S from the block vectors), which is at most
The above bound is very close to the information-theoretic lower bound, as shown below.
Theorem 4
(lower bound). An SLP for S requires
There are t distinct elementary vector type instructions and, in the minimal SLP, each of them occurs at most once. Without loss of generality, we assume that the initialization instructions form the t first instructions in the SLP in any fixed order.
Let q be the number of disjunction instructions, i.e., N = t + q. There are at most N2 possibilities for each disjunction instruction and, therefore, there are at most (N2)
q
= N2q different SLPs of length N. On the other hand, there are (2
t
)
t
= 2t2 different tuples S. We then should have
Resolving the above inequality with respect to q gives a lower bound, matching that of Theorem 3 up to a constant factor. Specifically, this implies that, for any ɛ > 0 and for almost any tuple S, the size of the minimal SLP for S is at least
Finally, we conclude that Theorems 3 and 4 improve the worst case bounds of Regular Language Constrained Alignment by a logarithmic factor.
Theorem 5.
Regular Language Constrained Alignment can be computed in
To summarize our algorithm: SLPs are constructed according to the NFA graph structure for each letter in the alphabet. These SLPs facilitate a faster solution to the Subset Maxima Problem of specific score subsets, during each dynamic programming step.
In Figure 5, we give an example of the construction of Steiner trees and SLPs for a specific NFA. These constructions take as input the example NFA appearing in Figure 2a. For this NFA, predA sets are ∅, {q0, q1, q2}, and {q0}, represented by the Boolean vectors 000, 111, and 100, respectively, and predC sets are {q0}, {q2}, and {q0, q2}, represented by 100, 001, and 101 (vector indices are displayed from left to right). Comparing the sizes of the various data structures we have: For predA, there are four transitions in the NFA with letter A, the SLP has five lines, while the Steiner tree size is 3. For predC, there are four transitions in the NFA, the Steiner tree size is 3, while the corresponding SLP, of length 3, has a single disjunction line and two elementary lines. The reader is referred to Figure 6a for an example of the Four Russians SLP construction.

3. Experimental Results
We implemented several algorithms in Java: (1) the algorithms of Arslan, (2) the algorithm of Chung et al., (3) our algorithm based on Four Russians based SLPs, and (4) our algorithm based on Steiner trees. The programs can be activated through a web interface and are also available for download via our web page http://www.cs.bgu.ac.il/∼http://negevcb/RL-CSA/index.php. We added to the preprocessing stage of the Four Russians based SLPs a trimming step, in which unused lines are removed from the SLP. Trimming an SLP can be done by locating all lines that take part in the construction of one of the required vectors in S (described in Subsection 2.1) and removing the rest (Fig. 6a,b).
Figure 6a,b shows an example of Four Russians based SLP construction and trimming. This example has Boolean vectors of length 8. The untrimmed SLP (Fig. 6a) has 23 lines, where the first 17 lines are block vector lines. The blocks are of length 3, so lines 1–7 enumerate all possible values in bits 0–2 (displayed left to right), lines 8–14 enumerate all possible values in bits 3–5, and lines 15–17 enumerate all possible values in the remaining bits 6–7. During the trimming step, five unused block vector lines are removed, yielding the trimmed SLP (Fig. 6b). For example, line 5 is not used in any disjunction operation nor is it one of the output vectors.
We compared the relative efficiency, as explained below, of heuristic Steiner minimal directed trees and Four Russians based SLPs as a function of NFA density (Fig. 7). To measure this, we randomly generated NFAs, constructed their corresponding data structures (Steiner minimal trees and SLPs) and measured their sizes. This simulation was repeated 100 times for each NFA size t, for different automata sizes t = 20, 40, 100, 160. We measured the relative efficiency of a data structure as 1 − N/|δ|, where N is its size (i.e., the size of the constructed Steiner directed tree, the length of the constructed Four-Russians SLP). The relative efficiencies of the different data structures were compared as a function of the density of the NFA. The density of the NFA equals |δ|/t2. The random NFAs were constructed as follows. We created automata without transition labels, since they are irrelevant, and constructed only their graph structure. This is due to the fact that, at each step of the algorithm, transitions labeled by a single specific letter are used (see Eq. 3 and Eq. 4). We created an NFA transition table, where each transition exists with a probability of a randomly chosen density. Only NFAs with t reachable states were considered.
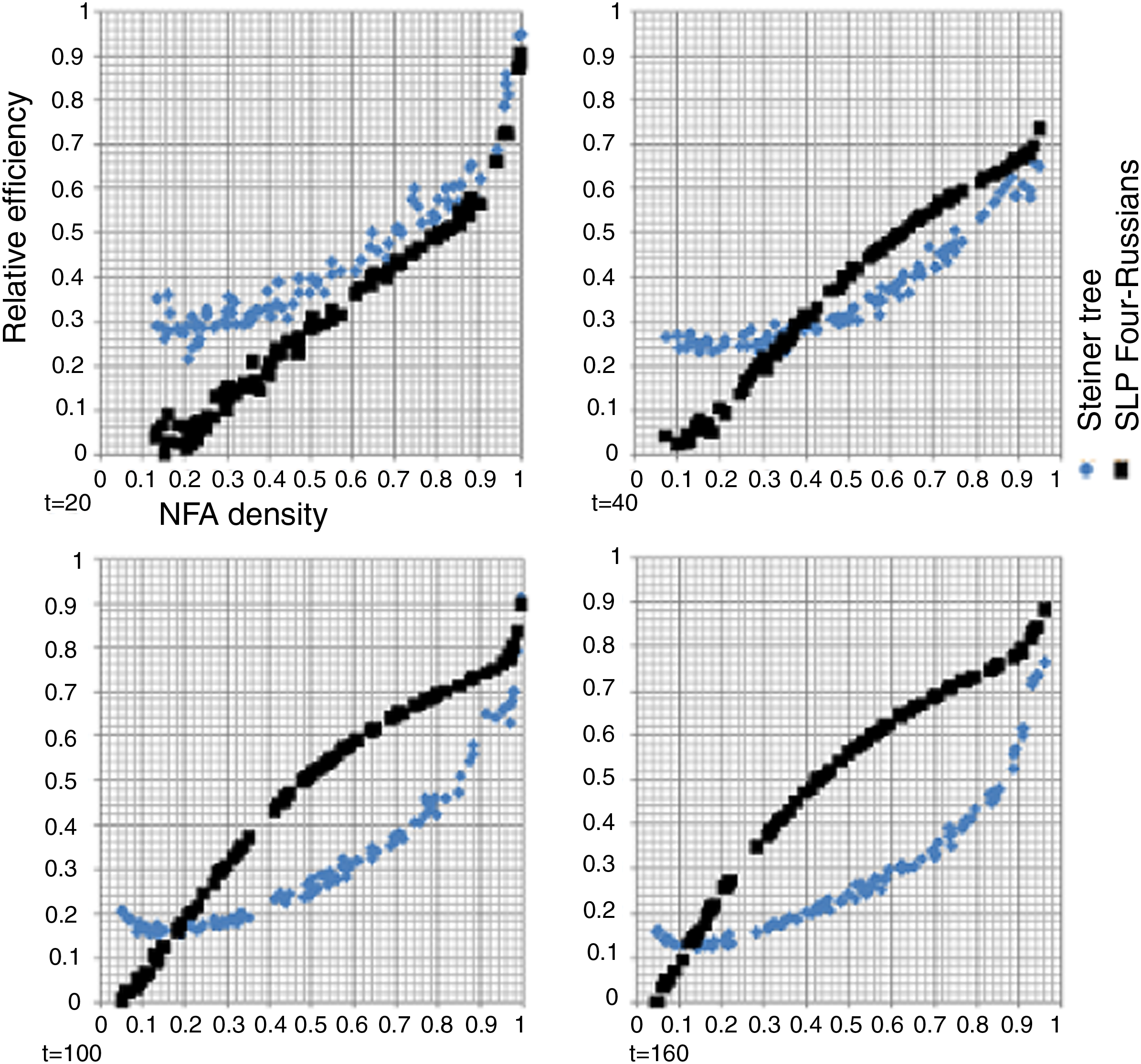
Efficiency comparison of different data structures as a function of NFA density. The simulation was repeated for number of states, t = 20, 40, 100, 160, each containing 100 randomly generated NFAs with t states and their corresponding data structures. Blue diamond, heuristic Steiner minimal directed tree; black square, SLP Four-Russians construction.
For each NFA, a Steiner directed tree was constructed, using the heuristic algorithms of Lin and Ni (1993) and Sheu and Yang (2001), with a minor modification that forces the constructed tree to be directed. Also, for each NFA, a corresponding Four-Russians based SLP was constructed, as described in Theorem 3, and then unused vectors were trimmed from it. Since the size of the trimmed Four-Russians based SLP is better than min
Our simulations show that both proposed data structures are smaller than the size of the transition table, which is a factor in the time complexity of the algorithm of Chung et al. Both have an increased efficiency as NFA density increases (Fig. 7). The heuristic Steiner minimal directed tree dominates for small values of t and low NFA density while the Four Russians SLP construction, described in Theorem 3, dominates for large values of t and high NFA density.
We conclude this section by demonstrating the performance of the three algorithmic approaches using part an example given in Chung et al. (2007a). The calculation of constrained sequence alignment on the AtGST and SsGST glutathione S-transferase (GST) sequences that appear in the example of Chung et al. (2007a), with regular expression constraint (S | T).2(D | E), yields 225370 max operations using our implementation of the algorithm of Chung et al., 211370 max operations using our Steiner tree based algorithm and 187606 max operations using our Four-Russians SLP based algorithm. The PAM250 scoring matrix, used in this example, gives a score of − 22. The alignment is given here:
4. Conclusion
We have revisited the problem of Regular Language Constrained Sequence Alignment with focus on improving the dense NFA case. While Chung et al.'s algorithm yields O(n2|Q| · |δ|) = O(n2t3) time and O(n2t2) space, we achieved a bound of O(n2t3/logt) time and O(n2t2) space for the same problem. The above contribution is interesting when the input automaton is dense, i.e., when |δ| is asymptotically larger than
We also implemented all four algorithms—Arslan (2007); Chung et al. (2007b), our SLP-based algorithm, and our Steiner-based algorithm—and made them available for public use on the Internet. Our experimental results, based on these implementations, indicate that the two approaches suggested in this article are also useful in practice.
We note that, in addition to the general result of Chung et al. mentioned above, they also gave an O(n2t2 log t)-time algorithm for the special case where t = O(log n) and assuming a unit cost RAM model (Chung et al., 2007b). Our algorithm does not assume a unit cost RAM model nor any restriction on the ratio between the size of the automaton t and the length of the sequences n.
We further note that, in the case where the input is given in the form of a regular expression rather than an automaton, the complexity analysis of the algorithm can be expressed in terms of the length of the input regular expression. This is achieved based on recent algorithms which take as input a regular expression of length r and convert it into an ε-free NFA with O(r) states and O(r log 2r) transitions (Hromkoviěc et al., 2001; Schnitger, 2006; Geffert, 2003). This yields an O(n2r2 log 2r) time and O(n2r2) space complexities for the algorithm of Chung et al. We note that this was not observed by Arslan and Egecioglu (2005) and Chung et al. (2007b).
Footnotes
Acknowledgments
We are grateful to Gregory Kabatiansky for his help on Theorem 2. The research of T.P. and M.Z.U. was partially supported by ISF (grant 478/10) and the Frankel Center for Computer Science at Ben Gurion University of the Negev.
Disclosure Statement
No competing financial interests exist.