
Abstract
Abstract
Sequence alignment (the grouping of homologous bases into one column) is fundamental to almost any task in comparative genomics. This translates to positing gaps in the genomic sequences to account for events of insertions and deletions (indels). The interrelationship between sequence alignment and phylogenetic reconstruction has drawn substantial attention recently with works showing the significance of differences in alignments. One of the plausible approaches in this direction is to grade the suitability of a tree to an associated alignment and vice verse. We here present a combinatorial (as opposed to statistical) approach based on the indel history. We show—both by simulations and by using real biological data from the Encyclopedia of DNA Elements (ENCODE)—that this criterion is sound. The novelty of our approach is the distinguishing between insertions and deletions, and augmenting the analysis with a dimension of “depth,” extending it from the sequence space to the phylogenetic space. Using this approach, we perform a comprehensive study of indel characteristic behavior among mammals in both coding and non-coding regions. Our results show significant differences in indel patterns between coding and non-coding regions. We also show other characteristic patterns of indel evolution in the depth of the underlying phylogeny.
1. Introduction
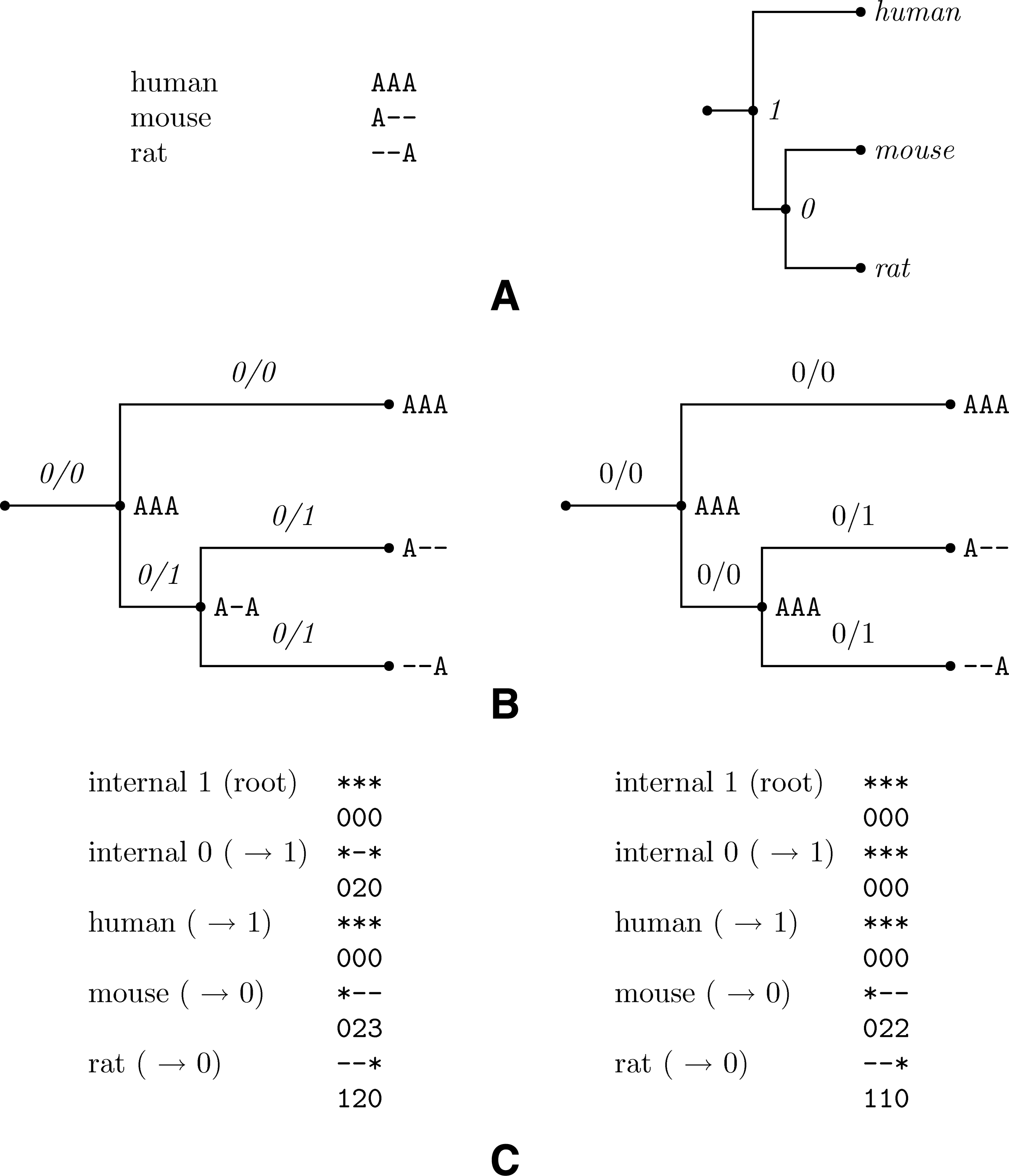
Greedy MP fails to obtain the most parsimonious history.
It is important to note that the most parsimonious solution (history) is not necessarily unique and sometimes the real history is not among the most parsimonious solutions. This is in particular prominent in multi event sites (see Results, where we demonstrate such a scenario). However, most parsimonious solutions never claim to be the real scenarios neither even the most likely. Our simulation results confirm that this criterion reconstructs the real history fairly well.
A naive straightforward implementation of the parsimony approach for optimal indel history search, requires time that is exponential in the length of the alignment. This observation has already been utilized in the simplest cases. For example, as part of a broad analysis of microevolutionary features across the genomes of the human, mouse, and rat, Cooper et al. (2004) studied micro-indels and their variability, and found a constant ratio between the rates of indel events and point substitutions along the mouse and rat lineages. Taylor et al. (2004) restricts analysis to human and rodent coding sequences, in particular to 8148 orthologous genes among the three genomes. Only codon indel events (nucleotides sequences of size divisible by 3) were examined. Among their main findings was that slippage like (see J.M. and A.P., 2000, for more details) indel events are substantially more frequent than expected. We also confirm this observation by identifying indel hotspots. A comprehensive study of indels in the human genome was done by Clark et al. (2007) based on the ENCODE data. This study contrasted indel behavior to point mutations and inferred results similar to ours regarding the density of events. Interestingly, indel inference was not done along a tree rather by shotgun re-sequencing reads. Micro-indels have also been considered by Blanchette et al. (2004) in the context of reconstructing large portions of the ancestral mammalian genome. Although the main goal was not the study of indels, their work was the first to deal with indel evolution in a non-trivial set of species and with a large dataset. For their purpose, a heuristic was devised in order to infer a plausible indel history and subsequently reconstruct the ancestral sequences at ungapped positions. They showed by simulations that this heuristic is accurate in general. Finally, we mention that micro-indel modeling is also significant for modeling context-dependent mutation (Siepel and Haussler, 2004; Hwang and Green, 2004), where the substitution probability of a nucleotide depends on its flanking nucleotides. To the best of our knowledge, indels have not been thoroughly considered in this line of research.
In this article, we make use of the notion of most parsimonious indel history (Kim and Sinha, 2007; Snir and Pachter, 2006). We confirm with a simulation study that for evolutionarily closely related regions (that have not been subjected to many mutational events), our approach accurately reconstructs the true indel history. For example, in coding-like regions we are able to reconstruct 97% of the events and in non-coding-like regions, 88% of the events. Our model of evolution is a restricted tree alignment model (Sankoff and Cedergren, 1983), where gap extensions receive no penalty. We argue that this specialization is biologically interesting, and computationally appealing. In particular, in the Methods Section, we develop, via a series of simplifications, an algorithm for inferring an optimal indel history. The running time of this algorithm is bounded by the number of events occurred during the history. Our model differs from other, statistical or discrete tree alignment models (Holmes, 2003), in that it assumes the sequences at the leaves are already aligned and the task is to find the sequences at the internal nodes of the tree. This type of input was already considered in other works (Chindelevitch et al., 2006; Fredslund et al., 2003); however, the underlying assumptions on the required solution were different. In particular, Chindelevitch et al. (2006) considers anchors between which the cost of insertions and deletions is computed, regardless of the permutations of sites between the anchors. Our definition does not assume these anchors and in particular, permuting columns can affects substantially the score. Fredslund et al. (2003), as opposed to us, works on unrooted trees which allows bigger freedom on the position of the indel and does not distinguish between an insertion and a deletion.
For results reliability, we chose to work with coding sequences from the ENCODE project (ENCODE Project Consortium, 2004; 2007) as well as non-coding sequences from multiple primates. This choice is important, as it improves the reliability of alignments (Boffelli et al., 2003; Chen et al., 2009), which is crucial for obtaining meaningful results in the analysis of indels. In the Results Section we also compare our results with previous studies. Specifically, our findings extend the results of Clark et al. (2007), Taylor et al. (2004), and Cooper et al. (2004), who investigated separately either coding or non-coding regions. Our findings enable us to compare and contrast indel events in both these regions. The ability to work with multiple sequences allows us to refute an assumption made by Saitou and Ueda (1994) that indel rates are approximately fixed even when the mutation rate changes (Blanchette et al., 2004) and allows us to show that indel events are not neutral. In particular, we show that indel hotspots do occur at a higher rate than expected by chance. As our findings reveal that deletions dominate insertions in both coding and non-coding regions and along all tree branches, the question of reliable ancestral reconstruction emerges.
Additionally, the use of our algorithm, both the exact and the heuristic, can contribute to the growing study on the interrelationship between phylogenetic and MSA inference (Liu et al., 2009) as it can rank the fitness of a given tree and an MSA, where preference is given to more parsimonious explanations.
2. Results
2.1. Phylogenetic profiling of insertions and deletions
The analysis of indels among multiple sequences related by a phylogeny begins with a set of globally aligned sequences, together with a phylogenetic tree representing the evolutionary history of the sequences (Semple and Steel, 2003). Note that any given sequence in the multiple alignment may contain the gap (-) character, and to distinguish such sequences from raw DNA sequences we refer to sequences in an alignment as extended sequences. Therefore, a global multiple alignment consists of a collection of extended sequences, all of the same length.
Figure 2 (left) depicts a simple example consisting of extended sequences of length nine representing an alignment of the human, chimp, galago, mouse, and rat, and Figure 2 (right) depicts a phylogenetic tree for these sequences. Internal nodes in that phylogenetic tree represent hypothesized extinct species, ancestral to the species at the leaves of the tree. A key concept is a history with respect to the input, by which we mean extending the given input by assigning extended sequences to the internal nodes. Therefore, a history is the input tree with the input aligned (extended) sequences assigned to the appropriate leaves and arbitrary extended sequences assigned to internal nodes. The number of indel events in a history is given by the insertions and deletions, which are uniquely defined once the history is given (to be defined precisely shortly). Our goal is to find a history that minimizes the number of indel events. Such a history, which we refer to as maximally parsimonious (MP) may not correspond to the actual history, but is likely to be reasonably accurate assuming that indel events are rare; this is indeed the case. See Table 1 for a comparison between indel rates and mutation rate as well as results from Clark et al. (2007).
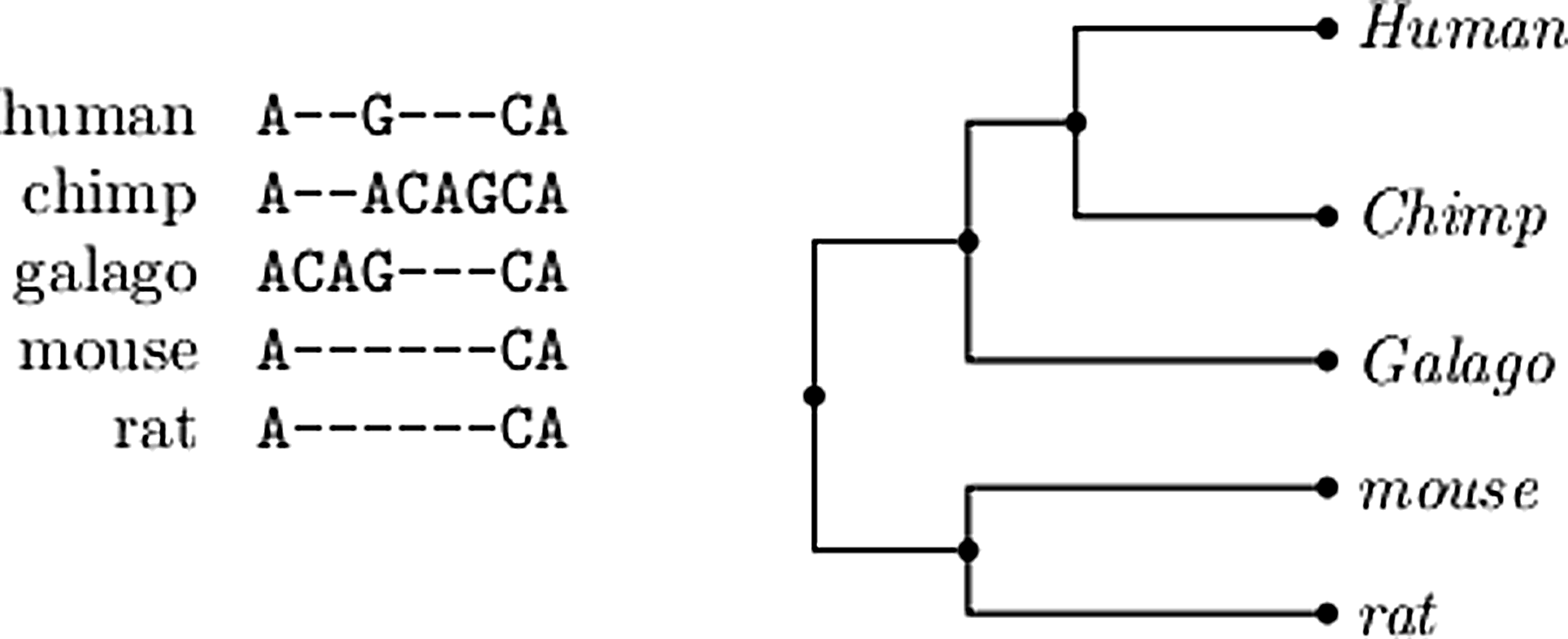
An example input to the indel history problem: An alignment of homologous extended sequences on the left, and the evolutionary tree for the species in the alignment on the right.
The numbers for the coding regions were taken from a data set from ENCODE for the species human, chimp, galago, rat, mouse, and dog. The total number of events includes, in addition to insertions and deletions, also root events, which are events that cannot be determined uniquely as either insertions or deletions. The numbers for the non-coding regions were taken from non-coding regions around the CFTR gene for various primates.
Note that we are not interested in the assignment of nucleotides to ungapped positions in the history; rather we simply care about the gaps. For this reason, we indicate ungapped positions by “*.” Figure 3 describes a possible history to the input of Figure 2.

history describing the input alignment of Figure 2 with respect to the given tree. As can be seen, the symbols at internal nodes distinguish only between a missing and existing base. The numbers along the branches indicate the number of insertions and deletions along each branch summed over the whole length of the alignment (in the form ins/dels). According to that history there was an insertion of AGC at sites 5–7 along the branch leading to the chimp and a deletion at sites 2,3 along the branch to the human-chimp ancestor.
For a given history, an insertion at some node is a succession of ungapped sites for which the same sites in the parent sequence are gaps. An example of an insertion is shown in Figure 3 in the sequence of the chimp where the inserted sequence is CAG at sites 5–7. Similarly, a deletion is a succession of gaps for which the parent sequence contains no gaps. An example of a deletion is shown in the ancestral sequence of the chimp and human, at sites 2–3. There is always ambiguity at the root of the tree as to whether an indel is an insertion or deletion, so such events are denoted by gaps. Every insertion, deletion or a gap constitutes an event. The score of a history is the number of events it induces on the input. A different view of our task is demonstrated by Figure 4. Indels create “holes” in the given alignment. Our task is to cover all the holes by associating events to the tree branches. Every event on an edge is associated with starting and ending column that indicate what hole it covers.

Another view of the input to the problem.
We developed software, which takes as input an alignment and a phylogeny and produces an optimal history for that input. The output is in the form of an alignment including the inferred ancestral sequences. It is convenient to display summaries of the output, as in Figure 3. Figure 5 shows a toy example of an output of our software for finding a maximal history for a given input. The upper part of the figure shows a forty site alignment of human cow and dog and the corresponding phylogeny. The lower part shows the output produced by the software. In this example, there are five events and therefore the largest event number is five. The numbers under every site indicate the event associated with the site. As was explained above, a star represents an existence of a nucleotide and a “-” the opposite. However, in places where there was an insertion, the inferred base is plotted in uppercase letters, and in case of a deletion, it is plotted in lowercase.
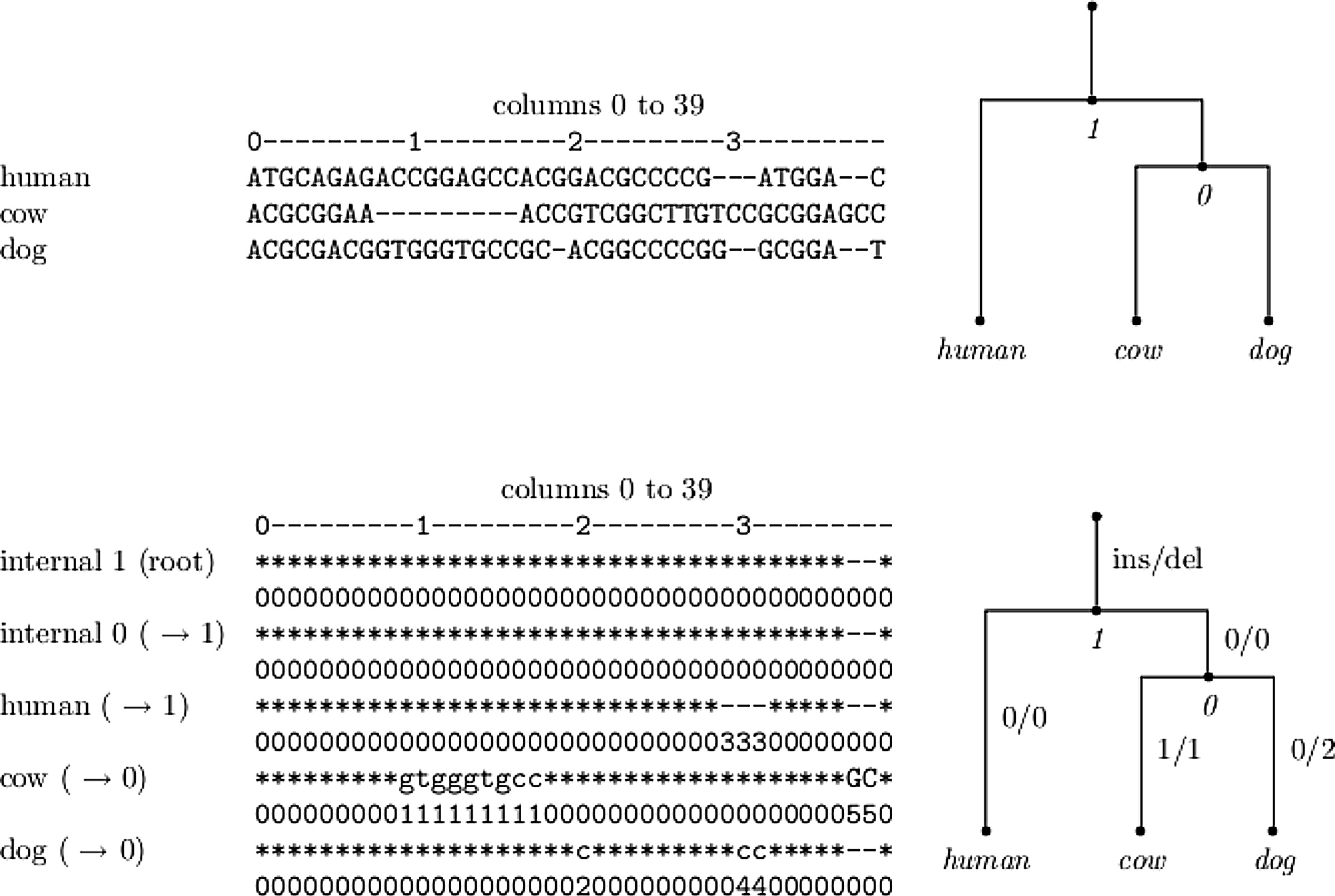
A toy example of the software output. On top, a 40-sites-long alignment of human, cow, and dog is displayed
2.2. Previous work
Our aim here is to show how our findings compare to previous findings obtained on related data, first to show relevance of our approach, but also to enhance these results. We started with the deletion/insertion proportion compared in previous studies. Previous studies have already indicated the excess of deletions in comparison to insertions in both coding (Taylor et al., 2004) and non-coding regions (Thomas et al., 2003). We enforce these results but also reveal differences between the two types of regions. We start with coding regions. We applied our software to alignments of coding regions from ENCODE (see Methods) and obtained the number of events along all branches not emanating from the root. Since Taylor et al. (2004) considered only codon insertion and deletion events (i.e., indels of length divisible by 3), we filtered out all events of other lengths. The distribution of events obtained along the tree branches is shown in Figure 6 (top tree). The first value we examined is the ratio between insertions and deletions along each branch of the tree. The del/ins ratio at the mouse lineage is 1.05 (versus 1.1 obtained by Taylor et al. [2004]) and 1.5 at the rat (versus 1.7 obtained by Taylor et al. [2004]). The second value we measured is the frequency of events along a sequence. This measure should not be confused with the rate of events along a branch in the tree. The latter indeed measures the number of events with respect to the edge length (and therefore is proportional to evolutionary distance (Felsenstein, 2003), while the frequency of events ignores this factor. In our data, there were 108,000 codons for the rat and mouse sequences (twice the alignment length, 156,000 for both rat and mouse divided by 3) and a total of 73 events (sum of events for rat and mouse), yielding a frequency of one event per 1,479 codons (versus 1,736 obtained by Taylor et al. [2004]). The agreement is striking considering that our trees contain more than twice the number of species and four-fold more branches (eight vs. two, not counting branches emanating from the root), and events could have been attributed to other branches of the tree. While in Taylor et al. (2004), a gap in the mouse and human is automatically inferred as an insertion in the rat, in our method, based on the whole set of sequences, this scenario can be interpreted as a multi event site (see exact definition in the sequel) in which both mouse and human exhibit two different deletion events at that site.
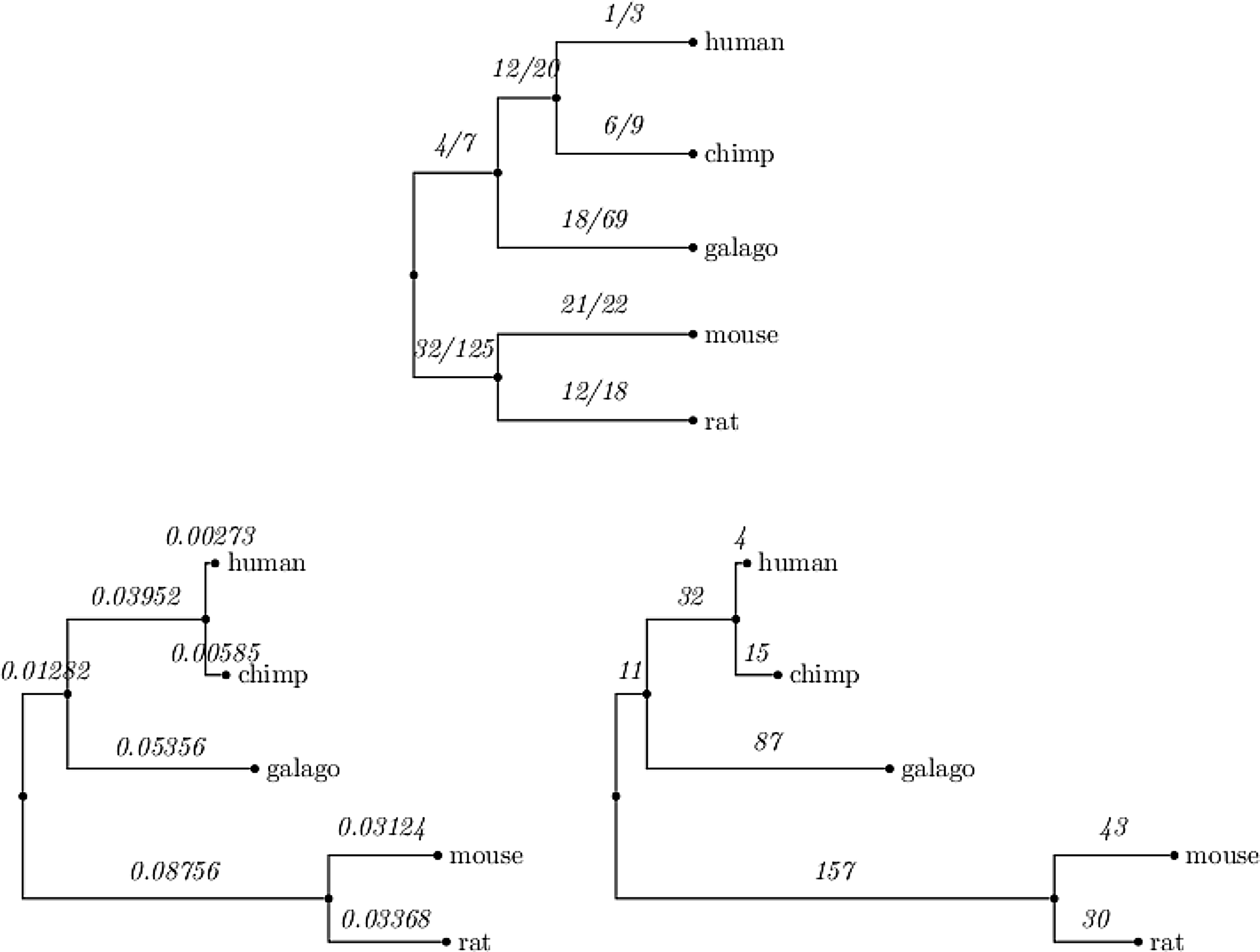
Indel and point mutation statistics along the tree branches at coding regions.
Coding regions were also studied by Clark et al. (2007) on the human genome on the same data set we used the ENCODE. Indels were inferred by the shutgun re-sequencing reads and compared to point mutations. Although there was no distinction between insertions and deletions, the data relevant to our study is the distribution of indels in general along the genome. Clark et al. (2007) found that there are approximately 15 indel events per 100 kilo bp. This number is significantly smaller than our findings (Table 1). However, a closer look reveals that since our study included two rodent species and a galago that exhibit rates about 10 fold faster than human, a similar result is obtained. This also holds for average number of inserted bases that were found to be 43 per 100 kilo bp.
Our next comparison was to Cooper et al. (2004), who studied indel events among mouse, rat and human, and found a constant ratio between them to substitutions events. In Cooper et al. (2004), the rate of indel events is measured as the number of events per site, and substitution events are the rate of point substitutions per site (expressed as the length of the tree branch). This ratio, calculated only in the two pendant mouse and rat branches and along the whole genome, was found to be 0.05. Since our non-coding data was comprised of different, but closer species, we cannot make an exact comparison. Our non-coding data (on which we compared indels to branch lengths) is of two alignments of primate sequences in which ratios of 0.11 and 0.07 were found. Cooper et al. (2004) eliminated regions heavily gapped in either rodent, leading to an artificial reduction in the ratio computed, so we believe the agreement is satisfactory.
Cooper et al. (2004) present an exponentially decaying curve, describing the frequency of events as a function of their length. Figure 7 plots our findings with respect to this point in both coding and non-coding regions. The shape of the curve is very similar to the one in Cooper et al. (2004). We stress that our data summarizes events along all tree branches and hence endows it some more reliability.
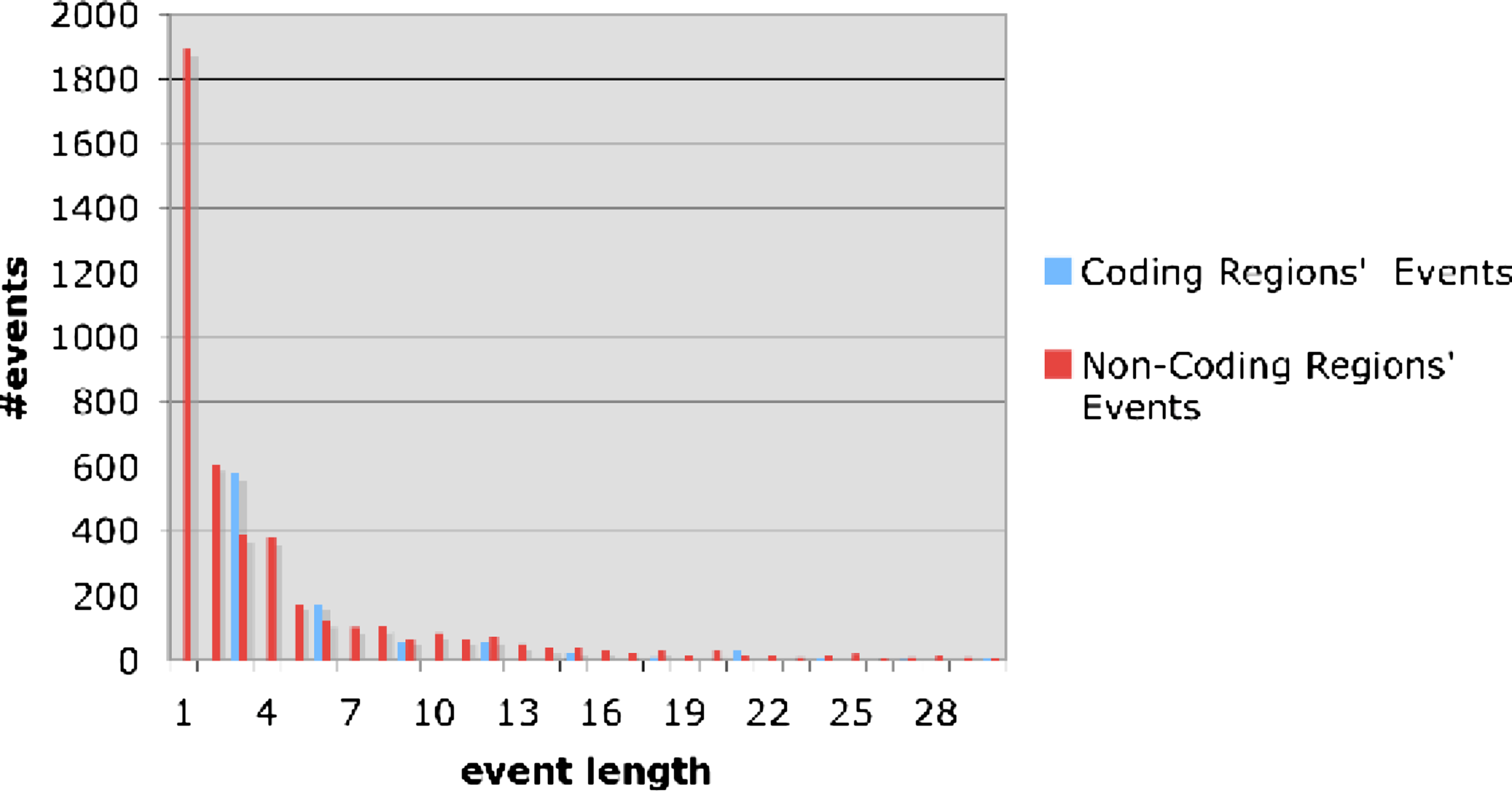
The distribution of the total number of events (insertions and deletions) as a function to event lengths. Red and blue blocks correspond to non-coding and coding regions respectively. Data obtained for all species and regions analyzed (not restricted to the species at Figs. 6 and 12). As can be noticed, frequency decreases exponentially with length.
2.3. Coding regions
As coding and non-coding regions differ both in the type of analysis and results, we report them separately. Figure 8 and Table 2 summarize our finding in coding regions. Both insertion and deletion frequencies decay exponentially with length. An exception to this exponential decay in the length is events of 7 codons (21 bases) that stand out in both insertions and deletions. We do not have an explanation for this. It can also be seen that deletions are slightly longer on average than insertions. We also wanted to measure if, and how, the rate of indels changes along the branches of the tree. We normalized the number of events on each tree edge, by the length of the edge. This measurement enables us to estimate the correlation between the length of an edge (the expected number of substitutions on the edge) and the number of indel events accumulated on it. Another question we examined is whether the indel process is homogeneous over time, or changes along different lineages of the tree. The ENCODE data contains many genes and different sets of species. In order to obtain enough information we concatenated multiple genes over a common set of species. Figure 6 at the top shows the number of indels along each edge of the tree. We used the same data in order to obtain the edge lengths corresponding to the tree, by ML estimate according to the HKY (Hasegawa et al., 1985) model. As the dog served as an outgroup to the rest of the species it was excluded from the figure. The tree on the bottom left of the figure shows the edge lengths inferred for the tree (measured by the expected number of substitutions along an edge). The edge lengths of the tree at the right bottom of the figure correspond to the number of indel (insertions plus deletions) events along the edges. The correlation between the edge length and the number of events is notable. Specifically, for every edge e, we computed the ratio ide/le where ide is the expected number of indel events per site along e and le is the length of e (the expected number of substitutions per site along it). We performed a linear regression between the ide and le values along the different edges. We found a ratio of 0.01 between ide and le with p ¡ 0.001 (Fig. 9). These results confirm the constant ratio found by Cooper et al. (2004), however, only at the two rodents branches whereas here we report this also for internal edges.
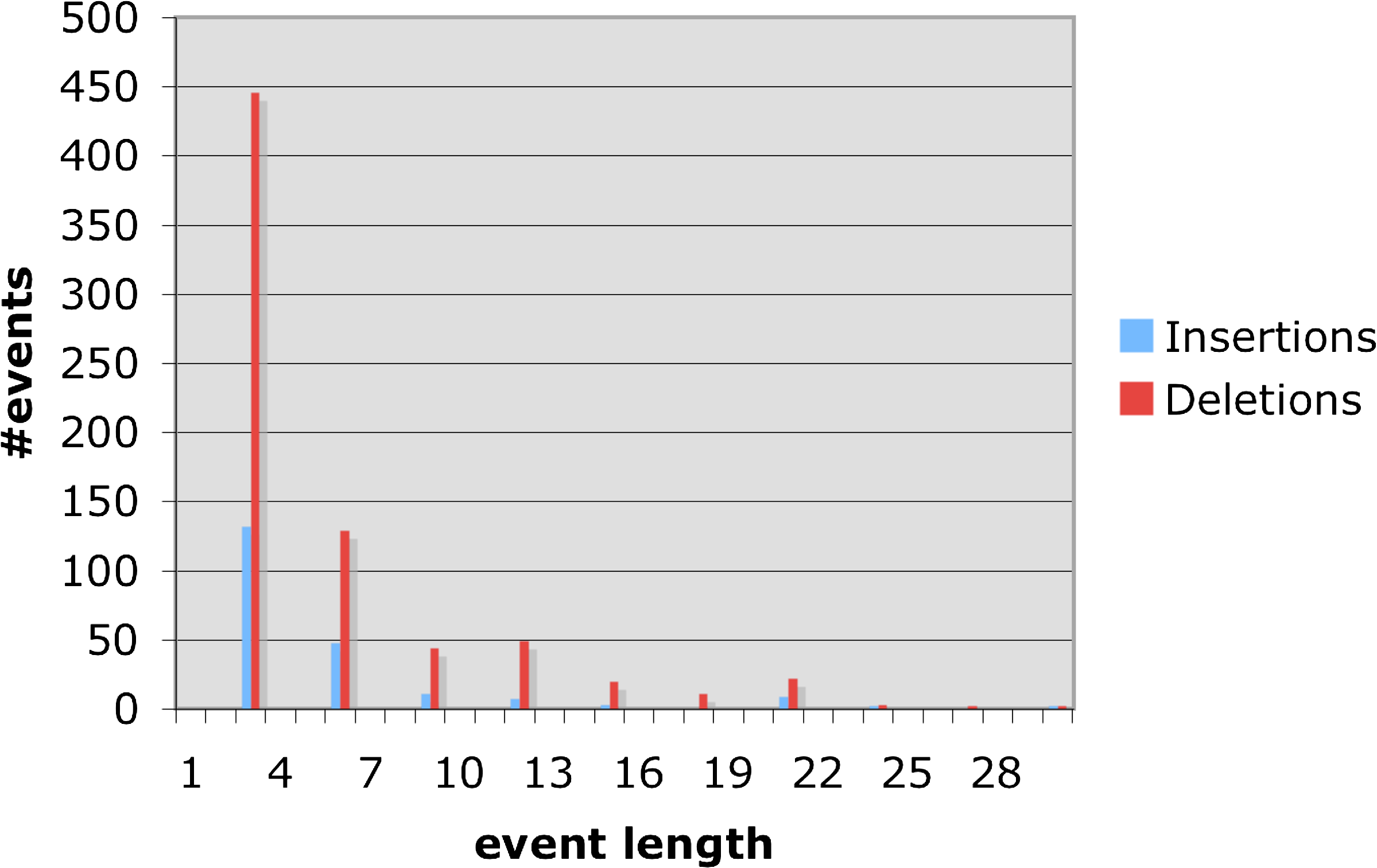
Frequencies of insertions/deletions in coding regions. Only events of length 0 mod 3 are reported.
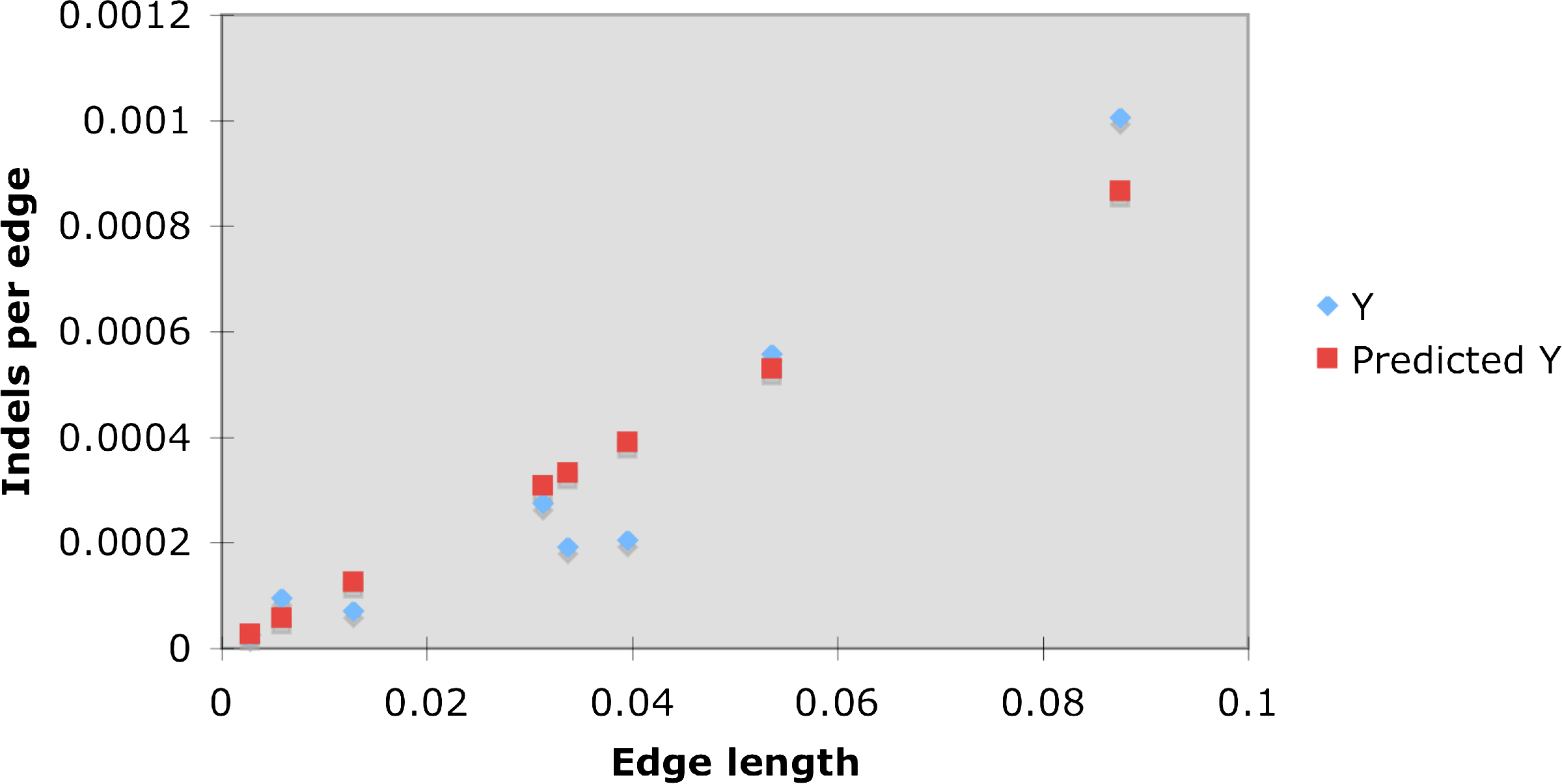
The linear regression analysis for the indel/mutation ratio at coding regions. The red line is the inferred ratio with slope 0.01 and p-value 0.0003 (confidence level 95%).
Except for events of 7 codons, the number of events decays exponentially with the length of the event. The average length of an event is 5.78 where average insertion is 5.65 bases and deletion 5.82 bases. The insertions/deletions ratio is 3.4.
In Saitou and Ueda (1994), it was postulated that the indel process obeys a molecular clock. This means that if we measure the length of the path along the tree, from any internal node to any of its descendants, this length will be the same. It is well known (Wu and Li, 1985) that with respect to point substitutions, this hypothesis does not apply to the set of species we investigated here. There was an acceleration in the rate of mutations in the rodents lineage after the speciation event from the primates. This causes a substitution rate twice as large in the rodents, than in the primates. The approximately constant ratio between ide to le refute the hypothesis of Saitu and Ueda (1994). In particular, it can easily be seen that the number of events on the path from the root to the mouse is exactly 200 while to the human it is only 47.
At the amino acid level, we examined whether there was a preference for certain kinds of insertions or deletions. The composition of amino acids in insertion and deletion events is depicted in Table 3. We inferred amino acid insertion/deletion in both extant species (i.e. in the aligned sequences) and the ancestral nodes. An event is determined to be an insertion/deletion by the optimal history (see Methods). The second and the third columns in the table display the actual number of times amino acids deleted/inserted respectively. The fourth and fifth columns display its relative weight in the insertion/deletion (respectively) processes. The sixth column is its frequency in the sequences examined (i.e. the background frequency). The last two columns normalize columns four and five by the background frequency. This allowed us to check whether an amino acid is over or under represented in either process. Figure 10 depicts the last two columns of Table 3 graphically. The green line at level of 1 signifies neutrality. It is notable that some amino acids maintain the same ratio in both processes (e.g., Arginine, Serine, Threonine), although this deviates from a neutral rate of relative value of one (e.g., Arginine, Serine, Phenylalanine). Another characteristic is that most of the amino acids are either overrepresented or underrepresented in both insertions and deletions. Since both insertions and deletions are almost uniformly distributed on both sides of the neutrality line, the probability of observing sixteen out of the twenty amino acids over or under represented by chance in both processes is 0.0046. Exceptions include Cysteine, Valine, and Glutamic Acid that are overrepresented in one process but underrepresented in the other. Table 4 depicts the distribution of the bases in the indel process. It can be seen that G-C are overrepresented (above their relative frequency in the population) in both insertions and deletions, while T is underrepresented in both processes and A is underrepresented in deletions and almost neutral in insertions.
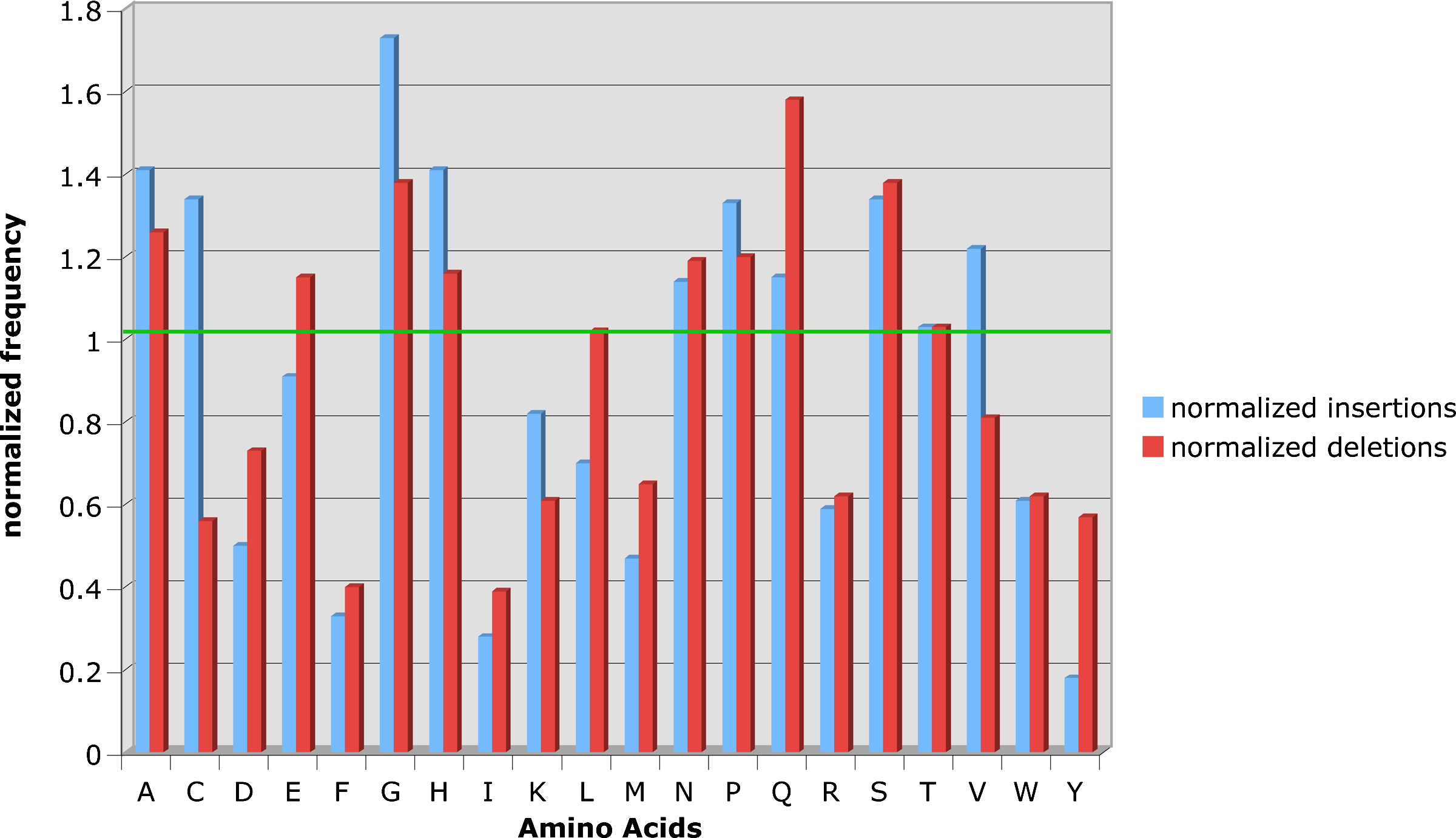
Normalized representation of amino acids in insertions and deletions. The frequency of an amino acid in either process was normalized in its background frequency. The green line represents neutrality, meaning an amino acid is inserted/deleted the same as it appears in the population. It can be seen that most of the amino acids are either over or underrepresented in both insertions and deletions.
The second and the third columns in the table display the actual number of times amino acids deleted/inserted respectively. The fourth and fifth columns display its relative weight in the insertion/deletion (respectively) process. The sixth column is its frequency in the sequences examined (i.e. the background frequency). The last two columns normalize columns four and five by the background frequency.
Table 5 and Figure 11 depict the statistics obtained for the non-coding regions we analyzed. There were 4465 events with a total length of 19534 bases, yielding an average of 4.37 bases per event. Events of a single base comprised 42.4 percent of the total number of events and of length two, 13.5 percent. Of the total number of events, there were 362 insertion events with a total length of 1697, yielding an average insertion size of 4.68 bases. There were 4103 deletion events with a total length of 17837, yielding an average deletion length of 4.34 bases.
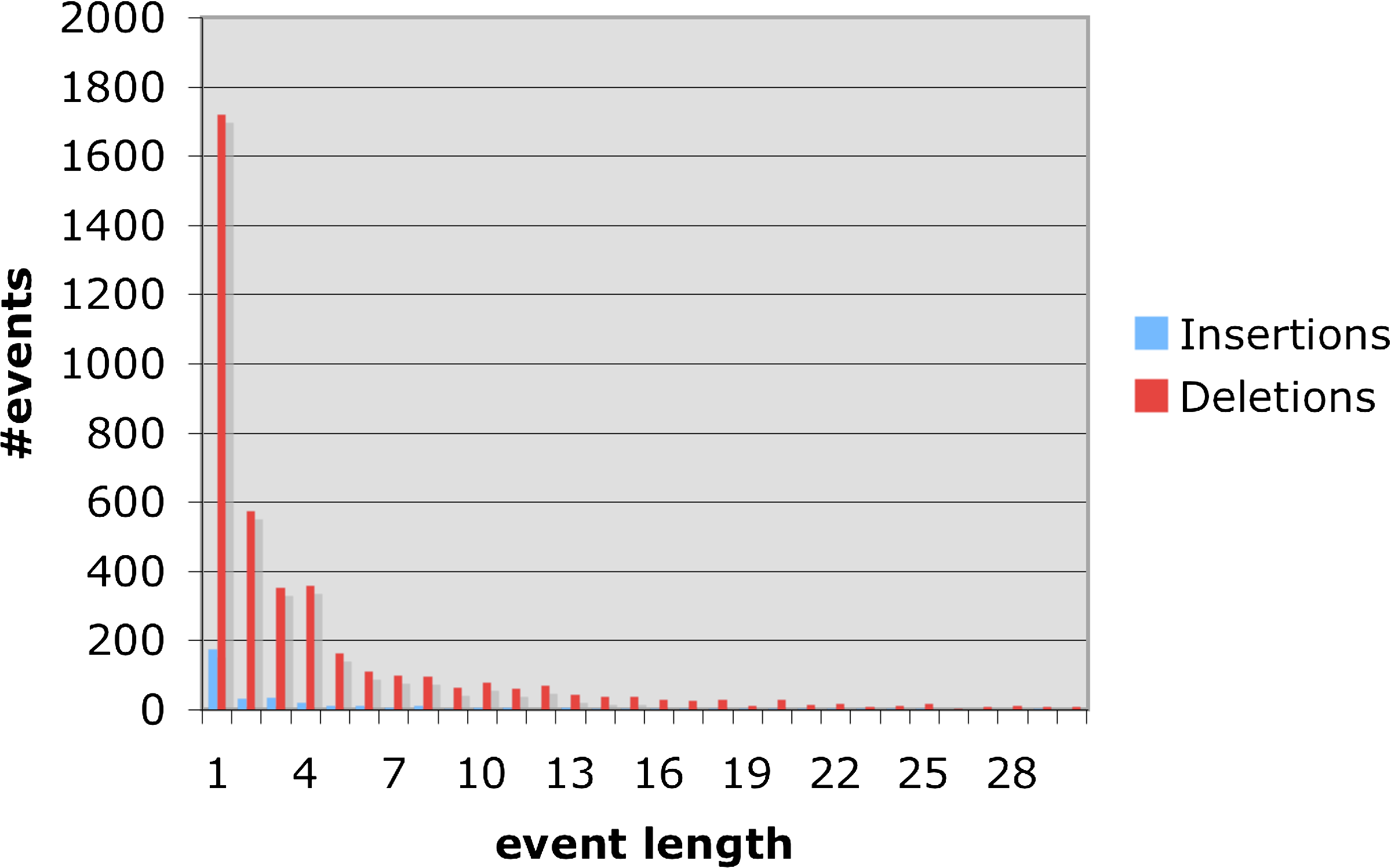
Frequencies of insertions/deletions in non-coding regions.
Table 6 depicts statistics of the composition of the bases in the indel events in non-coding regions. We used the same method here for the inference of the content of the indel events as for coding regions, except for the fact that we did not eliminate events with lengths not divisible by 3. We found that the GC content in indels was lower than the genome frequency. In insertion events, C is substantially underrepresented (0.81 of its genome frequency), while T is similarly overrepresented (1.13). In deletion events, both A and T are similarly overrepresented (around 1.05 of their background frequency) while C and G are similarly underrepresented (0.92). C and T exhibit the largest variation between insertions and deletions.
Similarly to coding regions, we wanted to measure the correlation between rate of indel events to the rate of point substitutions along the tree branches. Figure 12 depicts our findings in the CFTR region (ENCODE region number 1). The upper part of the figure depicts the distribution along the tree edges. The edge lengths of the tree in the lower left part correspond to the point substitution probabilities and at the lower right side, to the total number of indel events. As can be evidenced, both trees are more “clock like.” We were interested in the ratio ide/le for every edge e. Again by linear regression we obtained a value 0.11 with p-value 4.3E-7 (Fig. 13).

Indel and point mutation statistics for non-coding regions, taken from around the CFTR gene. The interpretation of the figure is identical to that of Figure 6 except that all events were counted. A significant bigger indel/mutation rate ratio of 0.11 is obtained (Fig. 13). Indels on branches were normalized by alignment length of 209,000 bases.

The linear regression analysis for the indel/mutation ratio. The red line is the inferred ratio with slope 0.01 and p-value 0.0003 (confidence level 95%).
2.4. Multi-event sites
From probabilistic perspective, several events occurring at the same site are not very likely. We denote these as multi-event sites (MES); that is, sites where indel events have occurred on more than one branch of the tree. Indel events (as opposed to the sites) at MES sites are called parallel events. For a deletion, this definition is straightforward: A deletion event at a branch is parallel (to another event) if it deletes a nucleotide that was either inserted at some ancestral branch or has a homolog that was deleted at a non-ancestral branch. However, as for insertions, this definition is a bit more complicated. An insertion at a branch is considered parallel to another insertion event if it occurs between the sites flanking the other event (note that if the other event is not ancestral to the first, the two sites flank both events). An insertion at a branch is considered parallel to ancestral deletion if it occurs between the sites flanking the deletion, and parallel to a non-ancestral deletion if the sites deleted flanking the insertion.
MES can cause confounding input to our algorithm that might yield a wrong history. Consider the case of insertion inside an insertion as illustrated in Figure 14. The root node has two nucleotides “15,” an insertion of “24” results in “1245” at a descendant, and the second subsequent insertion of “3” results in “12345” at a descendant of the later. Note however that the problem of inferring optimal history is not constrained to specific sequences at ancestral nodes, as is described in the Method section, rather only to sequences at the leaves. Hence, translating the scenario above to a representative input yields the input at Figure 14A, where the sequences at the root and its direct descendant sit at leaf children of each such node. The real history appears at Figure 14B. It is important to note that this history yields a sequence of three events by the scoring algorithm, which is in contrast to the sequences that gave rise to that history. However, a closer look reveals that this input admits a different, more parsimonious history of two events as illustrated in Figure 14C. This example demonstrates that indeed the most parsimonious history is not necessarily the correct history, but the number of events produced is not larger than the number of original events.
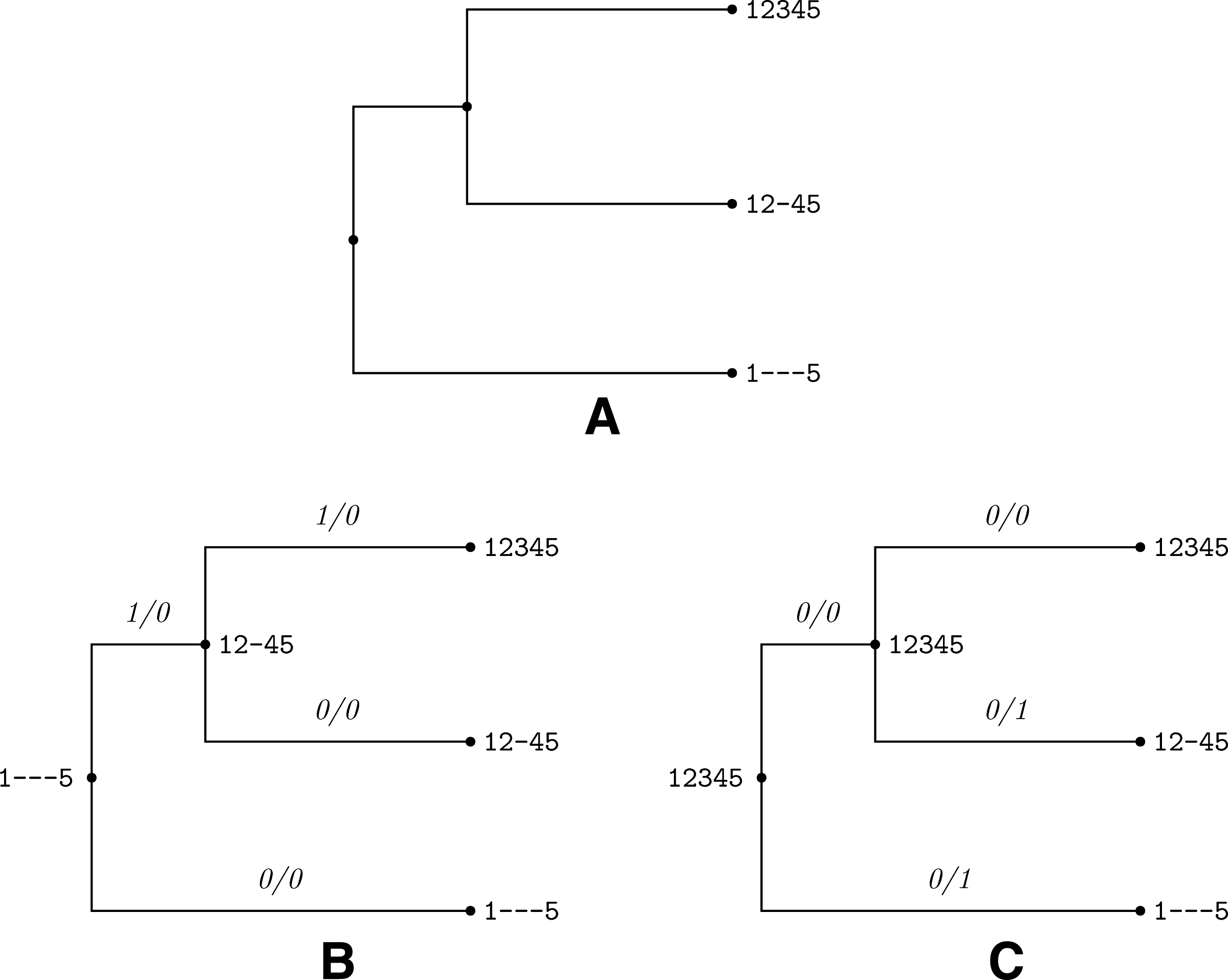
The most parsimonious history is not necessarily the true scenario.
Since alignment programs never place parallel insertions at the same sites (since this causes non-homologous bases to overlap), our calculations underestimate the number of parallel events. However, as insertions are less frequent than deletions and in particular insertions occurring in parallel to other events, we believe our estimates are fairly accurate. Our findings show that in both datasets, the frequency of parallel events was above two fold the expected value. Specifically, for coding regions, the number of sites containing a single event was 9,553, yielding an expected value of 0.0295 (the total number of sites in all datasets analyzed was 323,673) and a probability of 0.000871 of finding a parallel event at a site. The actual number of sites containing parallel events was 1093, yielding a frequency of 0.00337 parallel events per site, 3.876 times its expected value. For non-coding regions, we found 30,616 sites containing an event, yielding a frequency of 0.0714 sites containing events, and a probability of 0.0051 for a parallel event at a site. The actual frequency of parallel events was 0.0111, which is 2.178 times the expected value. These findings are consistent with the findings of Taylor et al. (2004) about the effect of slippage at indel events. Taylor et al. (2004) found that the frequency of indel events is about 50% higher than expected in proximity to small regions where the same amino acid is duplicated. As we have shown, such indel “hot spots” are also evident in non-coding sites. It is interesting to note that Lytynoja and Goldman (2005) argue against evidence for indel hot spots, suggesting that they are the result of alignment artifacts. While we do not argue with Lytynoja and Goldman (2005) findings, we believe that our results confirm the existence of indel hotspots.
3. Conclusions
In this work, we have used the algorithm developed in our previous work for further studying of most parsimonious indel history. We demonstrated by simulation that this approach is sound when the analyzed data pertains to evolutionarily closely related species. Subsequently, we analyzed alignments taken from both coding and non-coding regions and discussed implications stemming from multi-event sites. The points below summarize several issues arising from this research.
3.1. Differences between coding and non-coding regions
Table 1 depicts major differences we found between indels inside coding and non-coding regions.
3.1.1. Insertion/deletion ratio
The difference between the rates of insertions and deletions has been mentioned many times in the past; however, it was believed to be constant in different regions (Blanchette et al., 2004). Our first remarkable observation is that the ratio between the rates of insertions and deletions changes substantially from 2.47 del/ins in coding regions to 11.23 del/ins in non-coding regions. We note that we did not find significant shifts in the behavior of the processes along the tree branches in both regions. We comment that indel variation was also observed by Chen et al. (2009); however, our analysis extends theirs also to the tree branches.
3.1.2. Indels average length
The average length of events differs between coding and non-coding regions. In general, the average length of an event is larger in coding regions and is 5.78 versus 4.37. This can be attributed directly to the prevalence of single base events in non-coding regions where these events are deleterious in coding regions. Another interesting difference is the ratio between the lengths of an average insertion to average deletion in both regions. While in coding regions the average insertion length is 5.649 and 5.826 for deletion, in non-coding regions, insertion length is 4.68 versus 4.34 for deletion.
3.1.3. Ratio between indel events rate to mutation rate
The ratio between indel events rate to mutation rate, ide/le also changes substantially between the two region types. Indeed this ratio at non-coding regions is also changing among the different data sets we considered (CFTR, LDLR, CETP, APOA1, etc.). However, the variability was relatively moderate centered around the value of 0.13. This is to be compared to a ratio of 0.013 in coding regions (0.01 disregarding non 0 mod 3 events). Some explanation to this is the fact that while coding regions are under very high selective pressure against indels in general and non 0 mod 3 specifically, they allow for a high rate of synonymous point substitutions that may cause a shift down in the value of ide/le at these regions.
3.2. Estimating the size of ancestral genomes
Since we know the ratio between point mutation rate and indel rate, and have noted that this ratio is unchanged with time, we can compute how many indel events are accumulated in a certain amount of time. Knowing the ratio between the rates of insertions and deletions and the average lengths of both events, enables us to calculate by how much the genome is contracting due to indels. A similar question was studied by Grover et al. (2008) focusing on two cotton species by considering also large scale mutational events. The question was also addressed from a different point of view by Petrov et al. (2000) who tried to explain differences in genome sizes of the Drosophila and Hawaiian crickets (Laupala) by the differences in the indel profile (ide/le, differences between insertion and deletion rates, differences in average sizes). We pursue a similar approach with the aim of estimating DNA loss due to indels.
Since coding regions comprise a small amount of the genome, and in addition both the rate of indels ide/le is low and the difference between insertion and deletion rate is small, it suffices to consider only non-coding regions. We rely on our finding that there has been no significant shift in the effects of indel processes with time, and take the ide/le value obtained for the CFTR region: 0.11. In non-coding regions we have a ratio of approximately 11 between deletions to insertions, yielding an expected decrease of 3.58 bases per indel event [(11*4.34 4.68)/12]. This boils down to a decrease of 0.394 bases (0.11*3.58) per one expected substitution. This implies that for an evolutionary distances of 1 expected substitution per site, only 0.606 of the bases that existed in the ancestral sequence even survived. ENCODE region 1 contains data from various species for the CFTR extended region. The length of the path from the human to the human- zebrafish ancestor in the tree is 0.891. By the above analysis we find that 0.35 of the human-zebrafish ancestral sequence disappeared due to micro-indels events. Of course, the extant genomes have also been subjected to transposable element duplication, and other large scale duplications which have presumably drastically altered the size and content of the genomes.
4. Methods
4.1. The Data
As was explained above, our approach requires working with evolutionarily close sequences. Hence alignments for coding regions of a set of vertebrates were obtained from the ENCODE project (ENCODE Project Consortium, 2004, 2007) (http://genome.ucsc.edu/ENCODE/). These alignments were re-aligned to ensure consistency of codon alignments. For non-coding regions, a large set of primate sequences was required. ENCODE region 1 contains aligned sequences of ten primates. Additionally, sequences flanking various genes such as LDLR, CETP, APOA1, etc., in primates were obtained from the Programs for Genomic Applications (PGA) database at Lawrence Berkeley National Laboratories (http://pga.jgi-psf.org/seq/). These were aligned with MAVID (Bray and Pachter, 2004) (http://bio.math.berkeley.edu/mavid/download/). We also made use of two recent primate intron data sets from the PAX9 gene and the MSX1 gene, analyzed by Perry et al. (2006). These alignments contain 15 and 14 species, respectively.
4.2. Computing the optimal history
We now describe our algorithm for computing the optimal history for a given alignment of length n (number of sites) for a set of m species, and a phylogeny for the species. As was mentioned above, a history is an assignment of extended sequences (sequences composed of stars for base presence, and dashes for absence) to the internal nodes of the phylogeny. The length of the history is defined to be the length of the alignment, or alternatively, the length of each extended sequence in the history. A position is defined as a specific site at a sequence (either from the alignment, or from the extended sequences of the history). The ancestor of a position p at sequence s, denoted a(p), is the position of the same site at the sequence ancestral to s (as defined by the phylogeny). The left of a position p at sequence s, denoted l(p), is the position at the same sequence but one site before.
We start by describing a simple algorithm to compute the score of a given history of length n. (Note that this is not an algorithm for finding an optimal history rather for evaluating a given history.) Given a history, the number of events in the history can be computed by proceeding along the history from left (site number 1) to right. At every site, for every position p, with ancestral a(p), we define the sign of the position p as follows:
Note that sign is computed at every site and every node, except the root of the tree (because the root has no ancestral node). Given a history h, after computing the sign of a position p under h, it is possible to compute the event number at p, denoted event(p). The event number at every position at the roots extended sequence is defined to be 0. The event at every position at the first site (site 1) is determined by a top down fashion as follows:
The process continues now from left to right and top to bottom. For a position p for which the event number of its ancestral position a(p) and the position to its left l(p) have already been determined, the event number is computed by:
Upon completing the last site, the cost of the given history is the number of new events. As can be evidenced from the algorithm, this cost is computed by the cost of the site previous (or left) to the site currently checked, plus the cost of moving to the current site (that is, the number of new events incurred by that move). This defines a recurrence relation to compute the cost of a history. However, finding the optimal assignment (history) is a more complicated task even though it uses the same recurrence relation. For this end, we define the notion of a slice of a history. The slice of a history h at a site s, is the value (under h) of all the positions at s. For two slices at two adjacent sites, with history slices s and s, we define the cost of the two slices as follows:
where
It can be noted that cost(s, s) is the number of new events introduced by moving from slice s to s. Eventually, we define by opt(s, i) the cost of the optimum history up to site i under the constraint that the slice at character i is s. Then we can see that:
That is, opt(s, i) is obtained by finding the slice s that minimizes the number of events up to site i1 plus the number of events introduced by moving from s to s. Assume now that the length of the alignment is n and we define by opt the score of the optimal history. Then we find:
After the last character has been processed, the most parsimonious history found is reconstructed by tracing backward the optimal solutions that constituted the final solution.
The uniqueness of the solution is a serious issue in this type of computation. A solution is unique if when tracing backward to reconstruct the optimal solution, at every site i for which the optimal solution inferred the slice s, there is a unique s′ satisfying opt(s, i) = opt(s, i − 1) + cost(s, s). Our algorithm keeps the first optimal value encountered. This might lead to a discrepancy between two optimal solutions as to the specific events along the tree edges (although, not as to the whole tree, by definition of the optimality). In practice, we computed two extreme optimal solutions and took the average. In brief, one approach is star-favoring while the other is dash-favoring. Except for branches emanating from the root the difference between the two solutions was not significant.
The running time of the algorithm on an input alignment of m species and n sites is O(n2m − 2) since for every two adjacent sites we check for all possible history slices for these sites which amount to 22m − 2 (we considered only binary trees in which the number of internal nodes is m − 1). More details are available in Snir and Pachter (2006).
4.3. Simulation results
In order to test the viability of our approach, we designed a sequence simulator tailored specifically for our purposes. The simulator distinguishes between coding to non-coding regions and generates events according to the event frequencies we observed in both regions (see Results). The input to the simulator contains a phylogeny with branch lengths, an indication for coding or non-coding region and event length distribution tables for insertions and deletions. The simulator generates an indel history in a top-down manner as follows:
∘ The root of the tree is assigned a sequence of ungapped bases. ∘ For every node whose ancestor has been processed: Let pe be the event probability for the edge (obtained by the ide/le ratio for the region simulated times the length of the edge entering the node). At every ungapped base, with probability pe open an event. Otherwise, copy the type of base at the ancestral node. ∘ Output the (aligned) sequences at the leaves.
Given the simulator output to an algorithm, we consider a reconstruction to be correct if for both insertions and deletions the number of events inferred for every length is the same as was generated by the simulator (note that this does not require a perfect reconstruction of the original history). We believe this is a more accurate measure than counting the percentage of positions at which the original value (star or dash) was reconstructed.
We tested our algorithm on with two trees of ten species. The first tree was chosen from the 27 vertebrates tree from ENCODE region 1 with accumulated edge length of 3.56. The second was derived from the 15 primates tree of Perry et al. (2006) with accumulated edge lengths of 0.49. We used the first tree to simulate events in coding regions and the second in non-coding regions. For each region, 30 alignments were generated. In the coding experiment 3211 events were simulated out of which 97% were reconstructed. In the non-coding regime, 1399 events were simulated, out of which 88% were reconstructed. Due to the stringent comparison metric, we believe this is a fairly good reconstruction ratio.
4.4. Scalability
The current phase of the ENCODE project was a pilot for a whole genome analysis. We therefore considered practical approaches for scaling our analyses. A first significant improvement is achieved by the following property: it can be shown that there exist optimal histories in which identical adjacent sites induce the same ancestral history. That means that by advancing along identical sites in the alignment, we do not acquire new events. Therefore, we can contract every two adjacent identical sites in the input alignment into one. The above operation yields an alignment in which every two adjacent columns (sites) are non identical. After the optimal history is found, the compact alignment is expanded to its original form. Moreover, since at every site in the compact alignment, at least one event is either starting or terminating, the length of this alignment is at most twice the number of events in the optimal history. This improvement was particularly useful in coding regions where it rendered about 100 fold shorter alignments (mostly due to very long segments without any gap).
The exponential factor in the running time can pose a serious drawback on the method and makes it prohibitively slow for large number of species. In order to be able to process larger numbers of sequences we also tested the following heuristics: At every site, we computed the greedy MP assignment at internal nodes by the Fitch algorithm (Fitch, 1971) in a fashion similar to the algorithms described above. When at some position p the MP assignment was not unique, we set the state at p to the one at l(p). The running time of the heuristic grows linearly with the size of the alignment (number of species times the alignment length). The heuristic was compared to the exact algorithm on the two primate intron data sets of the PAX9 gene and the MSX1 gene. The results are shown in Table 7.
In both cases, the inferred histories (exact and heuristic) contain fairly similar events (especially for PAX9 where the difference is negligible).
4.5. Realignment of coding regions
As the raw ENCODE alignment was done by large-scale aligners oblivious to the type of sequence being aligned, coding sequences often contain gaps of size not divisible by 3. Therefore, for every transcript, we analyzed, the aligned sequences were re-aligned with CLUSTALW (Thompson et al., 1994). This correction substantially reduced alignment artifacts. Furthermore, as ENCODE provides us with the exact reading frame (RF) of every gene, we strove to have all 0 mod 3 gaps aligned with the human RF. Note that such a gap can be either 0,1 or −1 displaced from the RF, meaning it starts exactly on the RF, one nucleotide before or one nucleotide after, respectively. Our correction strategy was to shift each such unaligned gap sequence by one either backward or forward as necessary. The number of such corrections performed was about 6000 over a total length of over 74,000 bases.
4.6. Obtaining point substitution information
In order to obtain the edge lengths of the trees corresponding to the data we analyzed, we constructed the maximum likelihood (ML) trees for the species under study. We used HKY (Hasegawa et al., 1985) substitution model implemented by the PAML (Yang, 1997) software. As the rodents are difficult to correctly place in the tree construction (Al-Aidroos and Snir, 2005), we imposed the tree topology depicted in Figure 6. Since the substitution matrix S is obtained by the formula S = exp(tQ) where Q is a rate matrix and t is the edge length, Q is multiplied by a constant so that the average substitution rate is 1 and therefore t represents the expected number of substitutions per site along the edge.